基于路径预取的树型索引查询优化
2024-10-14来逸瑞李永坤许胤龙

摘 要:在树型内存索引的研究过程中,由于传统的片上预取不能适应索引的局部性,导致访存成为该类型内存索引的性能瓶颈。提出了一种基于软件层面的路径预取算法,使用预取加速内存索引的访问,并使得该算法可以快速部署到现实机器上。该算法基于对树型索引访存流程的分析,通过预取表保存键与索引访问路径的关系,通过基于键切片哈希的匹配算法对预取表中的数据进行匹配,显著提高了索引性能。在当前较为先进的树型内存索引上实现了该算法并进行了实验评估,结果表明该算法在不同数据量和读写混合负载下提升了索引器的访问性能。因此,基于路径预取的算法可以有效加速树型内存索引的访存速度,提升索引器性能。
关键词:内存索引; 预取; 缓存; 内存层次结构
中图分类号:TP391.9 文献标志码:A
文章编号:1001-3695(2024)10-030-3093-07
doi:10.19734/j.issn.1001-3695.2024.02.0051
Tree-based in-memory index query optimization based on path prefetching
Lai Yirui, Li Yongkun, Xu Yinlong
(School of Computer Science & Technology, University of Science & Technology of China, Hefei 230027, China)
Abstract:In the process of researching tree-based in-memory indexes, traditional on-chip prefetching cannot adapt to the locality of index accesses, resulting in memory accesses becoming a performance bottleneck of this type of memory index. This paper proposed a path prefetching scheme at the software level to accelerate memory index accesses by prefetching, and enabled the algorithm to be quickly deployed on real machines. Based on the analysis of the tree-based indexes memory access process, this algorithm used a prefetch table to save the relationship between keys and index access paths, and matched data in the prefetch table through a matching algorithm based on key slice hashing. This paper implemented and evaluated the algorithm on current advanced tree-based memory indexes.The results indicate that it maintains stable performance improvement under different data scale and read-write-mixed workloads. Therefore, the algorithm based on path prefetching can effectively accelerate the memory access speed of tree-based in-memory index and improve index performance.
Key words:memory index; prefetch; cache; memory hierarchy
0 引言
内存索引被广泛地使用在各种需要管理数据的场合,例如数据库、文件系统、缓存系统等应用中。以B+树和字典树为代表的树型内存索引,在提供高性能的点查询访问的同时,还可以支持高效的范围查询请求,在各个领域获得了广泛的研究和使用。在树型内存索引中,中间节点和叶节点通过指针连接,形成一个树型结构,通过从树根到叶节点的查询来进行访问。由于树型内存索引的访存自上而下的特点,在树结构中向下查找时会产生大量的缓存缺失,影响了索引的性能表现。现有的预取技术[1~4]无法对内存索引的访问提供正确的预测,或是由于采用了硬件预取方案[5],无法部署到实际应用中,所以无法解决这一问题。本文提出了一种软件层面实现的路径预取算法,通过键与树型索引访问时的搜索路径的关系,对索引节点进行预取,并通过高效的预取表和匹配算法设计,保证了算法在各种场景下的性能。不同于其他使用硬件预取算法的研究,该算法无须特殊硬件支持,并且可以快速地部署至各种环境中。本文在HOT索引上实现了该算法,实验结果表明,该算法能提供15%~20%的读性能提升,同时不影响写性能。
1 研究背景
1.1 树型内存索引
常见的内存索引通常以B+树、字典树和哈希索引为代表。本文重点讨论以B+树和字典树为代表的,能够提供范围查询的有序索引。这一类索引是通过多层树型结构有序地组织数据,以提供较为高效的访问,因此在下文中会将B+树索引和字典树索引统称为树型索引。
B+树是一个经典的树型索引。一棵m阶的B+树中,每个叶节点存储指向数据的指针,中间节点不存储数据,只存储指向树的下一层的指针。每个中间节点的孩子数量不小于m/2,同时不大于m。所有的叶节点通过一系列next指针组织成一个链表结构,以加快对数据的范围查询。相比B-树,B+树由于只在叶节点存储数据,所以在同样的树高下可以存储更多数据,同时中间节点的大小更小,有利于加速查询。
字典树,又叫trie树、单词查找树或者前缀树,是一种用于快速检索的多叉树结构。与二叉树不同,字典树的键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。GPT(generalized prefix tree)[6]是最早出现的将字典树作为通用的数据库的内存索引的尝试。GPT将数据库的主键通过前部添加0的方式固定到同一长度y,以支持可变长的键。在GPT中,每个层固定比较k个比特位的数据,最终树上每个节点至多有2k个子节点,树高为y/k,这个k值又被称为span。GPT的节点大小是固定的,因此选择较大的k会带来较大的内存浪费,较小的k会导致树高较大,点查询的内存访问次数较多,k的选择需要在内存使用量和访问性能之间进行平衡。
随着研究的进一步深入,越来越多针对字典树的优化技术被提出,字典树结构的内存占用和访问性能都得到了极大的优化。这些优化可以大致分为通过优化树结构提高字典树性能和通过压缩节点减少字典树的内存使用两类。
通过优化树结构提高字典树性能的工作中,较为典型的有ART[7]和HOT[8]。ART(adaptive radix tree)通过路径压缩和延迟扩张,消除在原始的字典树中只包含单个子节点的节点,以减少树高。HOT(height optimized trie)在ART的基础上进一步降低树高以优化字典树性能。HOT放弃了传统字典树的固定span值的思想,通过采用可变的span值,将每个中间节点的子节点数,即fanout值限制在确定的范围。fanout值的限制是通过一个类似平衡树的插入算法实现的,这使得所有中间节点的fanout的最小值不小于预设值的一半。HOT的树高相比ART减少了50%,也因此获得了相似量级的性能提升。HOT与其他B+树以及B+树与trie混合结构的工作(例如STX B+ tree[9]、Masstree[10])也进行了性能上的比较,结果表明,HOT可以在读、写、范围查询方面达到优于B+树类型索引的性能,同时具有更低的内存占用量。同时,最新的字典树索引研究[8,10]中已经摈弃了统一键长度的操作,而直接使用变长键进行数据存储,因此在键长度变化较大时,字典树相比B+树也能更好地进行索引工作。
通过压缩节点减少字典树的内存使用的工作中,较为典型的有Hyperion[11]和Hybrid Indexes[12]。Hyperion通过将树结构的指针替换为偏移量,并将部分节点于它的子节点压缩合并,来减少内存开销。Hybrid Indexes则是将树分为冷热两部分,热树采用传统的内存索引,而冷树改为只读的索引。由于冷树只读的特性,可以进行大量的压缩合并工作以减少内存使用。
1.2 预取技术
在存储层次结构中,预取是一种将数据从慢速介质提前读取到快速介质,以加速数据访问的技术。这一技术被广泛地用于内存-磁盘和L3缓存-内存等不同层次之间。在本文中主要讨论L3缓存-内存之间的预取。
从实现方式层面,预取技术可以分为软件预取和硬件预取。软件预取是通过系统提供的特定接口,由编译器自动,或由用户指定的方式,将特定数据从内存中预取至L3缓存。硬件预取则是由CPU片上电路实现,通过特定硬件和电路保存一定数量的访问信息,并以此为依据直接进行预取。这两种方式最大的不同在于,用户可以自行决定软件预取的实现细节,并可以将其部署在不同机器上;而硬件预取则是无法由用户修改,且不同的CPU默认搭载的预取算法也有所不同。学术界中现有的预取技术[1~5]都属于硬件预取。对这些预取算法进行的实验评估都需要在模拟CPU运行的模拟器例如McSimA+[13]和ChampSim中进行,只有被硬件制造商实现后才能用于实际应用。
从依据的访存局部性层面,常见的通用预取算法主要有以下几种:a)基于时间相关性的预取算法[14,15],主要是基于最近一段时间访问的数据,来推测未来可能被访问的数据,并将其载入快速介质中;b)基于空间相关性的预取算法,以SMS[16]和STeMS[17]为代表,它们是针对磁盘数据库等在块设备上工作的任务设计的预取算法,基于访问的数据在块中的位置,和访问的空间相关性来推测;c)基于指针的预取算法,以Jump-pointer prefetching[18]和Pointer Cache[19]为代表,是针对链表等依赖指针结构设计的预取算法,通过建立指针和被指向的数据对象的相关性,或者提前记录将链表中的后续数据,来预测后续的访问地址。
2 问题分析
2.1 树型内存索引的访存瓶颈
点查询是树型索引中的核心操作,对应于索引的获取和插入操作。其访问特性为从根节点开始,根据提供的键值,在子节点中进行搜索,直至找到目标或达到叶节点。因此,一次点查询可能涉及多次内存访问,平均访问次数与树的平均高度成正比。基于这一特性,诸如ART和HOT等研究试图通过降低树的平均高度来减少访问次数,从而提高索引性能。
然而,这种访问模式导致下一层需要访问的节点在本层搜索完成后才能确定。此外,由于上层应用提供给索引器的负载具有不确定性,系统管理的L1至L3缓存对这些节点的缓存效果不佳。这导致每次索引点查询操作中,多个内存访问会导致多个缓存未命中(cache miss),CPU必须等待数据从内存加载到缓存后才能继续执行,这无疑增加了索引查询的时间开销。
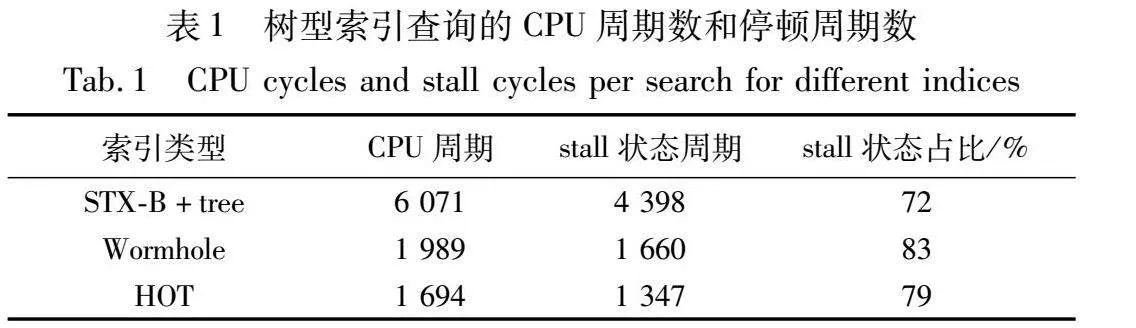
为了验证这一点,本文使用了一个包含2亿条8 Byte键的数据集,对STX B+树、Wormhole[20]和HOT树型内存索引进行了测试。Wormhole是一种混合了B+树、字典树和哈希表的树型内存索引结构。通过CPU计数器,本文统计了平均每次访问所需的CPU周期数以及CPU处于停顿状态的周期数,结果如表1所示。停顿状态主要由CPU等待内存访问结果引起,由分支预测错误引起的停顿周期数小于10%。测试结果显示,这些内存索引在停顿状态中浪费的CPU时间占总CPU时间的70%~80%,这与学术界的其他研究结果[21]一致,表明了访存延迟是制约树型内存索引的一个瓶颈。
2.2 现有的预取算法在索引预取时的问题
现有的预取算法主要基于时间相关性、空间相关性和指针相关性三类局部性。但是,这些局部性并不能正确概括索引的访问特征,导致传统的预取算法在内存索引的工作场景中性能不佳。具体分析如下:
首先,树型内存索引的结构由内存中的节点组成,这些节点通过指针相互连接,形成一个多叉树的结构。尽管基于B+树和字典树的索引在节点内部结构和孩子数量等方面有所不同,但它们都属于这种结构。由于节点被分配到不同的内存位置,并不具备块设备上数据位于固定偏移量的特性,所以基于空间相关性的预取算法无法有效地工作。
其次,索引的工作负载是由外部应用提供的键值序列,其不确定性较高。即使是确定访问冷热分布的负载,也不会出现严格的访问顺序,因此基于时间相关性的预取算法同样无法有效工作。
最后,多叉树结构可以视为由大量具有公共节点的链表组成的集合,这似乎为基于指针的预取算法提供了应用场景。然而,树型索引的一个节点往往拥有数十个子节点,例如HOT的平均子节点数量为18,基于指针的预取算法对特定的指针只能给出一个后继的预测。这意味着基于指针的预取算法只能对少量的访问进行预测,而对大部分访问则效果有限。
学术界的其他研究[5]也针对这些预取算法在树型索引中的准确率和覆盖率进行了测试。基于时间相关性或空间相关性的预取算法的覆盖率约为25%的同时,准确率在40%~50%,反映出它们对索引局部性的预测缺陷;而基于指针的预取算法虽然准确率超过90%,但覆盖率低于10%,反映出它对索引中庞大路径的预测缺陷。由于这些预取算法的固有缺陷,将其应用于索引时的性能提升小于3%。
3 算法设计
3.1 针对索引的预取算法的三个挑战
第2章深入探讨了内存索引所面临的问题,即访存瓶颈的问题。现有的预取算法在处理这一问题时效果并不理想。为了显著提升内存索引的性能,必须通过预取策略降低缓存缺失的数量,从而加速内存访问。要实现该目的,需要面临以下三个挑战:
a)设计适应内存索引访问特性的预取算法。索引的内存访问模式并不仅仅由其自身的结构决定,还受到外部应用提供的工作负载的影响。因此,为了构建适用于索引的预取算法,需要深入研究并理解内存索引的独特访问模式,并根据这些模式的访存特性进行针对性的设计。
b)优化预取表的结构与访问方式。预取要实现其预期的性能提升,前提是预取表访问和预测算法的运行成本必须低于通过预取加速内存访问所带来的收益。在实际的索引访问过程中,除了从树根到叶节点的常规内存访问外,还包括键解析、节点内部查询以及最终验证键值正确性等多个步骤。以HOT索引为例,在处理包含1亿个键值对的数据集时,单次读取操作的平均时间在500~700 ns。如果预取算法能够在每次访问中,通过将所需数据提前加载到L3缓存中,平均减少一次缓存缺失,那么每次访问的时间节约量可达到约100 ns。这就要求在设计预取表结构和访问方式时,必须将预取表访问等操作的代价控制在百纳秒量级内。尽管学术界已经有一些针对索引设计的预取算法[5],但由于在控制预取表访问成本方面的不足,这些算法在数据量增长时性能下降较快。具体来说,当处理的键值对数量从1百万增长到1亿时,它对B+树索引性能的提升幅度由50%降低到了10%以下。因此,为了构建适用于索引的预取算法,本文需要设计出高效的预取表结构和访问方式。
c)实施基于软件的预取方案。在当前的云存储时代,越来越多的数据库选择在云上存储数据。在这种环境下,用户很难要求云服务提供商对硬件进行深度定制和改造,以实现特定的硬件预取算法。这就要求所设计的预取方案应当主要基于软件层面。在现有对预取领域的学术研究中,绝大多数是基于硬件预取的实现方案 [1~4],这些方案只能依托McSimA+[13]等模拟程序进行实现和测试,无法部署到实际机器中进行性能对比。例如Li等人[5]针对索引设计的预取算法是硬件层面的方案,通过在芯片上增加一组存储器作为预取表,通过截获CPU发送给L1缓存的内存访问指令和L3缓存发送给内存的缓存缺失信号来进行预取操作。该方案也仅仅通过模拟软件对其进行了测试,而未能将其实际部署到任何硬件中。因此,为了构建一个可推广的内存索引预取算法,需要设计一个基于软件的预取方案。
3.2 基于路径的预取算法
前文详细分析了实现内存索引的预取设计的几个关键挑战,其中最核心的一点是预取算法需要紧密贴合内存索引的访问模式。为了更有效地提高索引的性能,需要同时提高预取的准确率和覆盖率,从而真正实现预取对索引的内存访问速度的提升。在深入研究了索引的结构和访问特征后,本文决定采用路径预取算法来加速内存索引的访问。
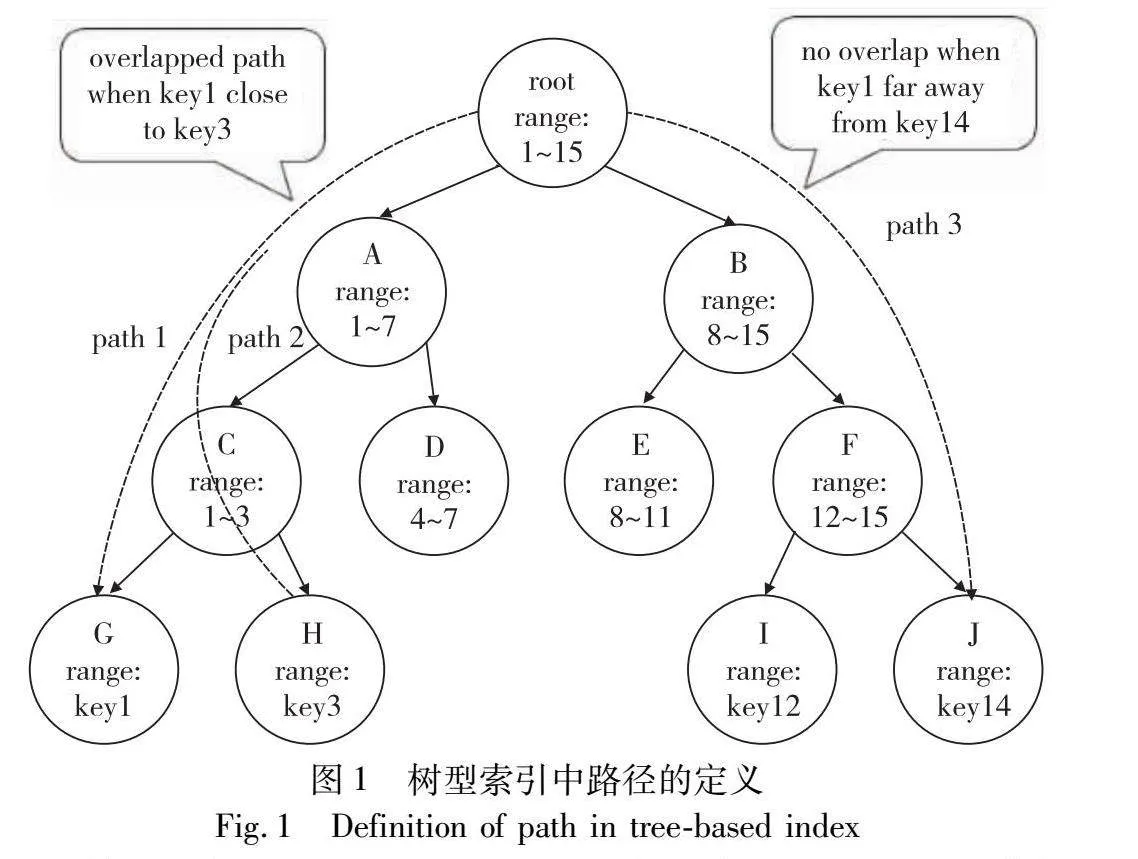
路径预取算法的核心思想是利用键和路径之间的对应关系进行预取。具体来说,对于某个键,其路径被定义为从根节点到存储该键的节点所需要访问的节点序列。例如,在图1中,可以看到一个树型索引中保存了从1到15的不同键。为了简洁起见,图中省略了部分节点和节点内部存储的值信息。通过图示,可以清晰地看到键1对应的路径是从根节点开始,经过节点A、C、G共四个节点。同样地,键14的路径是从根节点开始,经过节点B、F、J共四个节点。在这种索引结构下,键和路径之间可以建立一一对应的关系:每个键拥有一个唯一的路径,而根据这个路径可以准确地访问到存储该键的节点。
值得注意的是,无论是基于B+树的索引还是基于字典树的索引,其本质都是有序结构的树型索引。在这种结构下,越接近的两个键往往具有更相似的访问路径。图1标出了键1、3、14对应的路径。可以观察到,键1和3的路径中存在根节点、节点A、C三个相同的节点;而键1和14的路径中仅存在根节点这一个相同节点。在字典树结构中,不同的键是根据其前x个比特分散到不同的子节点中,对应到它们的访问路径上则是:具有更长相同前缀的两个键,它们的路径中相同的节点会更多。
正是基于这种规律,可以通过保存键与路径的关系来进行预取操作。首先,记录部分键及其对应的路径。当新的访问请求到来时,查询该键是否已被记录。如果是,则将其路径预取至L3 cache中;如果不是,则在已记录的键中寻找一个与当前要访问的键具有最长公共前缀的键x,并根据两者的相似程度选择将键x的部分路径预取到L3 cache中。
路径预取算法通过关注树型内存索引中键和路径的对应关系,成功捕捉到了树型索引的局部性由键控制的特性。这使得该算法可以获得远超基于时间相关性或空间相关性的预取算法的准确率。同时,基于公共前缀提供的模糊匹配能力,使得路径预取不需要保存所有键-路径的对应信息,只需保存部分信息就能对大量请求进行预测,从而获得了远超基于指针的预取算法的覆盖率。
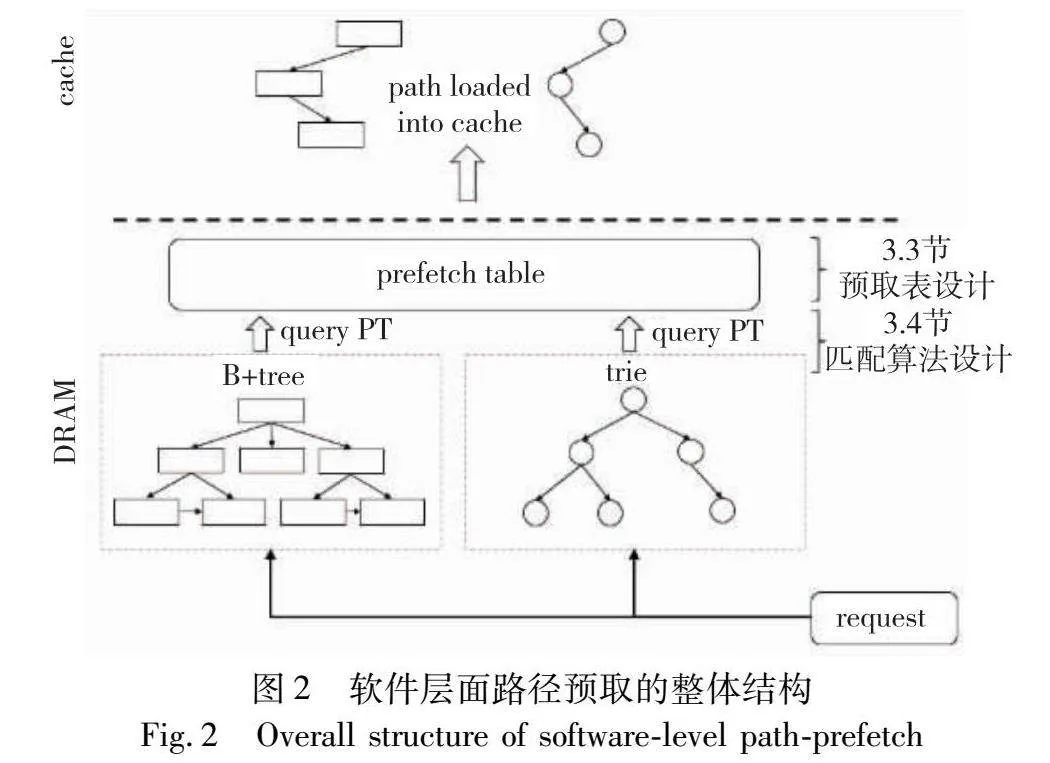
使用了软件层面路径预取的索引结构架构如图2所示。在路径预取中,需要保存键与路径的对应关系,以供后续预取使用,本文称保存这一对应关系的数据结构为预取表。为获得更好的访问性能,预取表被放置在内存的一块连续区域中。在索引查询发生时,需要在预取表中匹配一个与查询键相似的键,该算法在下文中称为匹配算法。本文将在3.3节和3.4节详细介绍预取表设计和匹配算法设计。
3.3 预取表设计
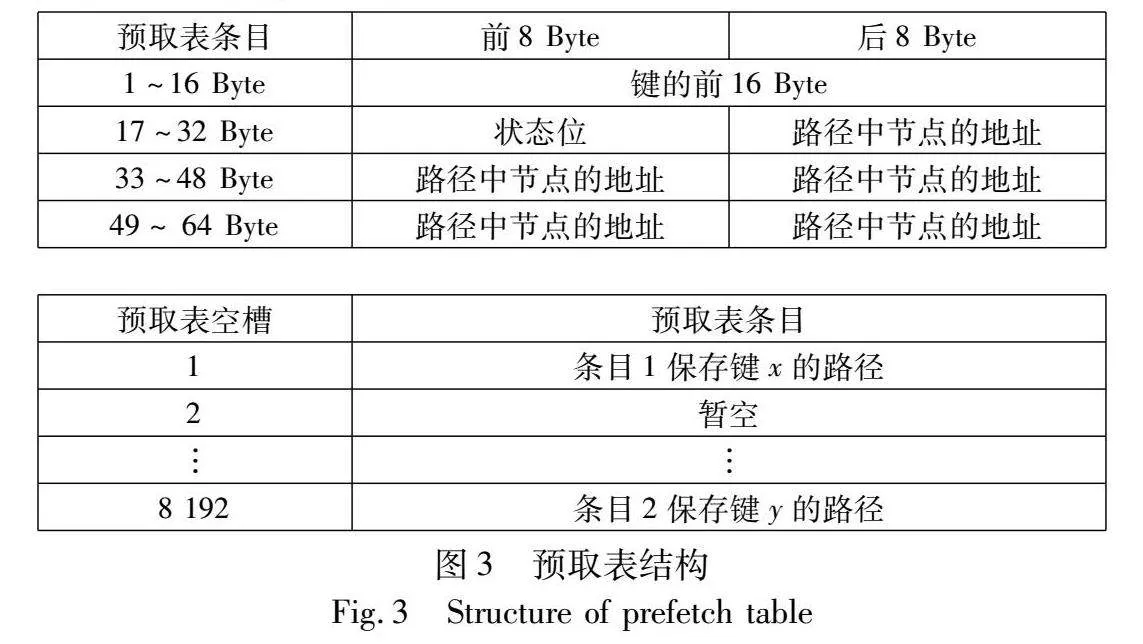
预取表(prefetch table,PT)是一块位于内存中的连续区域,用于保存键和路径的对应关系。预取表的内部结构如图3所示。预取表由若干个64 Byte的条目构成,以符合目前大多数CPU的cacheline大小,加快访问速度,默认有8 192个条目。每个条目由键key slice、路径path和标志位flags三个部分组成。将条目设计为64 Byte的目的是和缓存行对齐。key slice部分共16 Byte,保存了键的前16 Byte,若不足16 Byte则在后部补0。对于超过16 Byte的键,这些键往往是以字符串形式出现的变长键,对其进行压缩的效果不佳,因此决定仅保存前16 Byte。路径部分共40 Byte,用于存储5个8 Byte的指针,这些指针分别指向了该键对应路径中,除根节点之外的前5个节点。由于在索引中,根节点位于所有节点的共同路径上,所以无须存储,而又由于根节点被频繁访问而有极大概率位于片上缓存中,所以也无须对其进行额外的预取操作。在现代高性能的内存索引中,由于树高和单次查询的代价成正比,所以大量的工作都试图降低树高,以HOT索引为例,该索引在数据量为1亿个键值对时,树高为6。一般来说,基于B+树的结构会拥有稍小于字典树的树高。因此可以认为,保存的路径长度为5已经足够应对大多数的情况。同时,由于路径预取的特殊性,有大量的请求是通过对相似键-路径对的部分预取进行的,所以即使对于树高更高的索引,保存更长的路径也不能更有效地提高性能。标志位则是用于保存部分控制信息和统计信息。一个预取表默认由8 192个条目组成,在这一设置下预取表的大小为0.5 MB,现代服务器CPU的L3缓存一般为20 MB以上,保持一个较小的预取表有助于保证预取表本身能常驻在L3缓存中而无须进行其他额外的预取工作,提高预取表的访问性能; 同时较小的预取表也可以减少对索引和其他任务的L3缓存的抢占。
3.4 基于键切片哈希的匹配算法设计
匹配算法是路径预取的核心,负责将本次要访问的键与预取表中的键进行匹配,从而选择合适的键-路径对进行预取。理想情况下,匹配算法能够找到与当前要访问的键具有最长公共前缀的键。
一些常见的思路是扫描全表匹配,使用组相联的预取表,在预取表中构建有序索引或通过键的哈希值进行匹配。通过分析这些设计的缺陷,并提出本文方案。对于扫描全表匹配,在面对一个拥有8 192个条目的预取表时,其计算成本过高。为了进行一个粗略的估计,本文实验测得访问单个预取表条目并完成匹配的相关工作需要20 ns以上。如果进行全表扫描,意味着要对比8 192个条目,这明显超过了单次索引访问所需的600 ns时间。学术界也有研究使用了组相联的预取表结构[5],该文使用了一个8路组相联的预取表,但在组内依然需要进行完整的扫描,代价较高。该设计导致了其预取性能随数据量提高而快速降低,第4章的实验中验证了这一观点。如果在预取表上构建一个小型的树型索引用于搜索,假设每个节点的平均子节点数量为4,那么也需要7次访问,共140 ns的时间。这样的代价很难通过预取来弥补。如果采用一个简单的哈希索引,将每个键计算出一个1~8 192的哈希值,然后映射到对应的条目,由于哈希索引的性质,即使两个键仅最后一比特不同,它们也会被映射到完全不同的条目,无法达到将当前要访问的键映射到与其有相同前缀的键的目的。
从上述讨论中可以看出,虽然全文匹配或有序索引可以更好地进行匹配,但它们的计算成本过高,很难实现整体性能的提升。而简单的哈希索引虽然只需要一次预取表访问,但无法满足前缀匹配的要求。
因此,本文设计了一种基于哈希的匹配算法,即算法1。该算法的核心是对部分键进行哈希运算。在创建索引时,选择一个哈希函数,将任意长度的二进制序列映射到1~8 192这一区间上。本文取键的前k个比特参与哈希运算,将这个参数称为k值。在键-路径对需要写入预取表时,先取键的前k个比特,使用预先选定的函数进行哈希运算,将其映射到1~8 192中的一个值,然后将该键-路径对存储到该值对应的预取表条目中。在查询预取表时,本文选择要访问的键的前k个比特,使用同一个哈希函数计算哈希值,然后读取该值对应的预取表条目中存储的内容,最后将该条目中的键与要访问的键进行比较,通过两者的相似度(即相同前缀的长度)来决定需要预取的节点数量。
通过这种算法,可以在仅进行一次预取表访问的情况下,将要访问的键映射到预取表的一个条目中。在未发生哈希碰撞的情况下,要访问的键应当与条目中存储的键的前k比特完全相同。这相当于通过一个O(1)的算法找到了一个与要访问的键至少有前k比特共同前缀的键。显然,k值的选择会对该算法的效果产生显著的影响。在本文的测试中,当键是随机产生的均匀分布64 bit整数时,k值取16可以得到最佳的预取效果。
算法1 预取表查询算法
输入: 待查询键request key。
输出: 可能包含该键的预取表条目entry,和一个表示查询键与该条目相关性的match值。
1 初始化KeySlice=request key[0…k]
2 h=hash(KeySlice)%8192
3 entry=PT.GetEntry(h) //从预取表中获取第h个entry
4 CompareKey=entry.Key
5 match=0
6 for i=1 to 5 do //开始匹配request key与entry.Key的前缀
7 if i*k/2<request key.size
8 if CompareKey[(i-1)*k/2…i*k/2]==request key[(i-1)*k/2…i*k/2] /*每有一段长度为k/2的key前缀相同,就多预取一个索引节点*/
9 match=match+1
10return entry, match
3.5 软件层面的路径预取工作流程
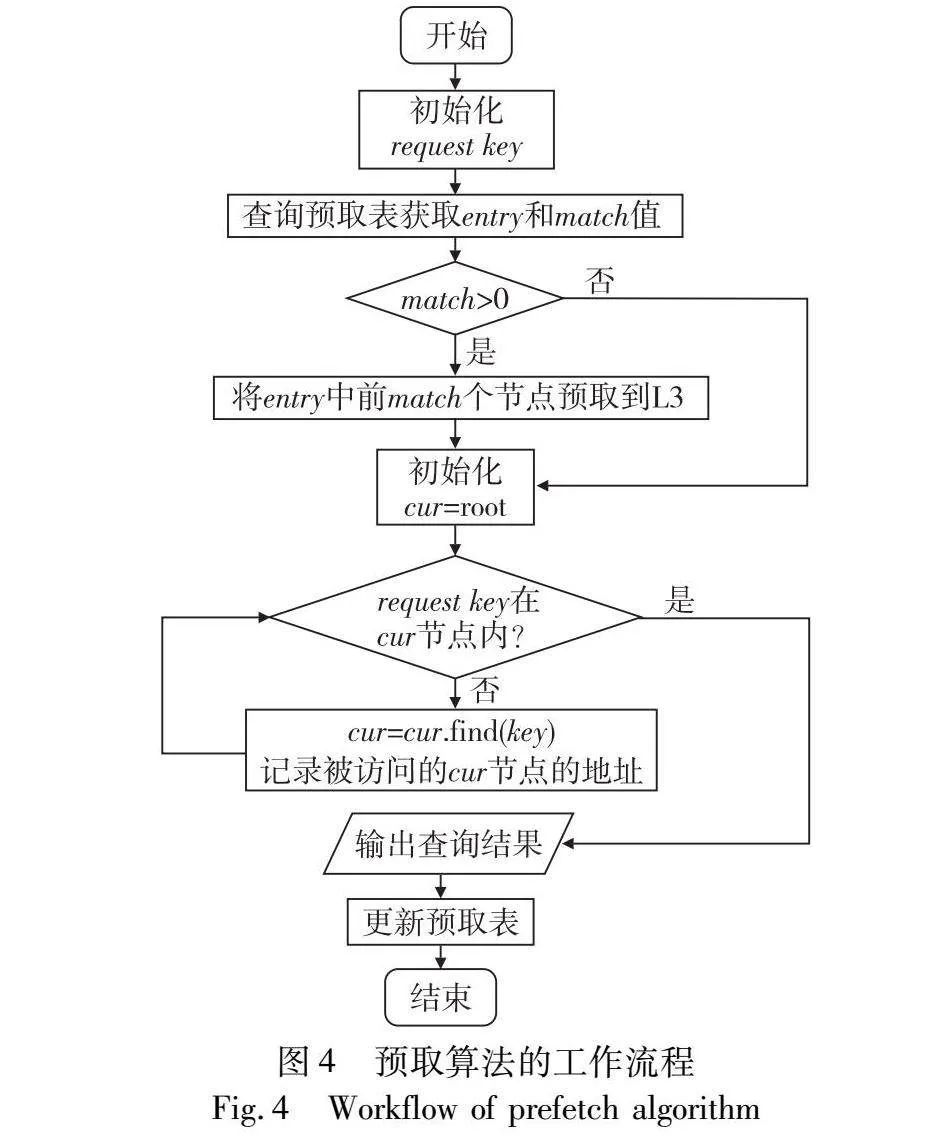
预取算法主要在索引读请求时工作,其工作流程见图4。当索引接收到新的读请求时,首要是对预取表进行查询。查询方法如3.4节所述,基于键的前缀进行哈希运算。查询预取表后,将本次要访问的键与表中的键进行比较,通过比对相同前缀的长度,得出一个0~5的匹配值,即算法1中的match值。该值表示预取表中对应键所对应的路径中需要预取的节点数量。若匹配值为0,则表示完全不进行预取,可能原因是哈希碰撞导致的完全不匹配或预取表中无相关数据。在确定需要预取的节点数量后,调用编译器提供的预取接口,将预取表中存储的路径上的节点预取至L3缓存。随后,从根节点开始,发起一次索引查找过程,逐级向下查找数据。在此过程中,部分节点可能已被缓存在L3缓存中,从而减少了访问时间。此外,还会记录本次查找中实际访问的索引节点的地址。查询结束后,根据实际访问情况,需要对预取表进行更新。
更新情况主要有以下几种:
a)通过哈希查找到的条目中无数据,此时需要将本次访问的键-路径关系插入到预取表中,通过哈希运算确定条目位置后写入数据。
b)匹配值为0,表示本次访问的键与预取表中对应条目的键发生哈希碰撞。需要在预取表对应条目的标记位中记录这种情况的发生次数,当次数达到阈值时,将该条目更新为本次访问的键和它的路径。
c)匹配值大于0,但实际访问路径和预取路径完全不重合。这可能是由于索引结构改变等原因,导致预取表中存储的键-路径关系过时。此时需要将该条目更新为本次访问的键和它的路径。
路径预取设计的主要目的是提升索引的读性能。但在索引写入时,查找插入位置的过程同样可被预取加速。因此,本文在此预留了一个可开启的预取选项。不过,在索引载入数据时,由于从零开始构建索引会导致索引节点的频繁分裂、移动等操作,使得大量的预取条目失效,在索引载入数据时该选项默认关闭。
4 实验评估
4.1 实验环境和设置
本文选择了学术界较为先进的HOT索引,以此为基础来实现路径预取算法,并将这一实现称为HOT-with-PF。在单机的环境下,由于内存大小的限制,HOT索引管理的数据量通常在1 G个键值对以内,在该情况下的HOT树高为6~7,而根节点由于被频繁访问,无须预取。因此在实践中本文选择了在预取表的条目中存储长度为5的路径。对于预取表条目数量的选择,默认的8 192个会带来较优的性能,具体原因将在4.4节中讨论。在k值的选择上,对64 bit整数键的情况进行了分析,发现k值取16能获取最好的性能。
学术界中最新的预取算法大多为硬件预取,对它们的性能评估通常使用模拟器模拟CPU的环境,运行特定的操作记录来进行,无法与实际机器中的性能直接对比。作为对照,本文选择了同样针对索引设计的针对索引的硬件预取技术[5],并将其算法实现在软件层面,将这一实现称为HOT-HD。本文实现了该算法的8路组相联预取表和匹配算法,具体参数选择与其论文中的默认设置相同。
本次测试的CPU配置为Intel Xeon Gold 5218R CPU @ 2.10 GHz 2×20 core,2×6通道96 GB内存;操作系统配置为Ubuntu 20.04,内核版本为Linux 5.4.72。涉及测试的索引分别为:
a)HOT[8]。一个基于字典树的高性能内存索引,通过优化的插入算法使得树高降低,从而提高访问性能。
b)HOT-HD。在HOT基础上,在软件层面实现已有工作[5]的预取算法,进行软件层面预取的索引。
c)HOT-with-PF。在HOT基础上实现的,增加了软件层面路径预取功能的索引。
测试中使用的键值对为8 Byte键+8 Byte值的组合,其中键为随机生成的不重复的uint64整数。使用这一设置的原因是,分析了各种系统中索引的角色后发现,大多数情况下索引保存的是哈希值+指针的键值对,而非原始的键+值,这是由于初始的键-值往往是不定长的数据,存储键-指针是一个更常用的方案。在测试过程中,将每个索引器分配在固定的CPU核心上,避免进程被调度至不同核心带来的性能误差。
4.2 路径预取的性能表现
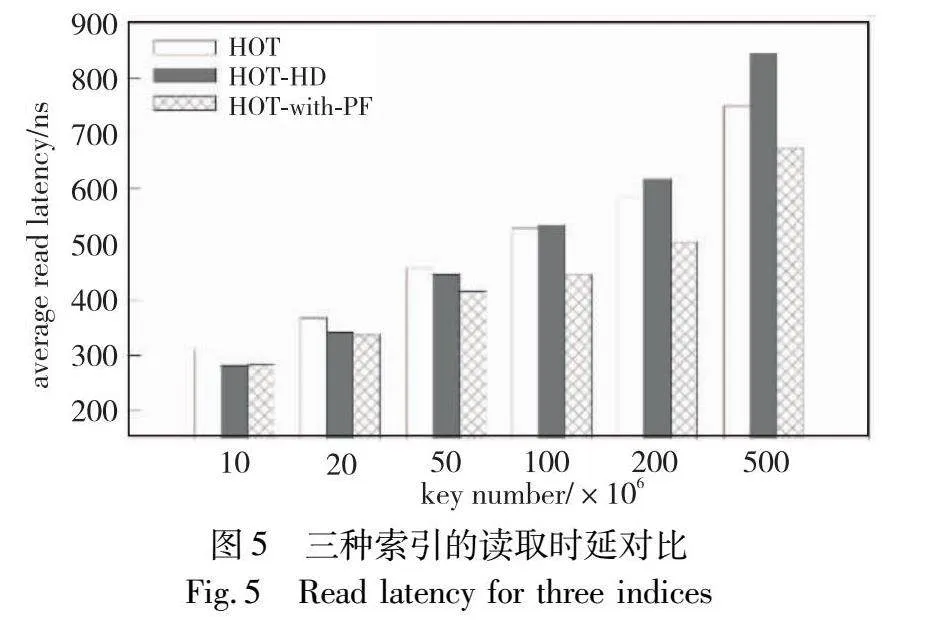
首先测试了在只读场景下的读性能对比,实验结果如图5所示。
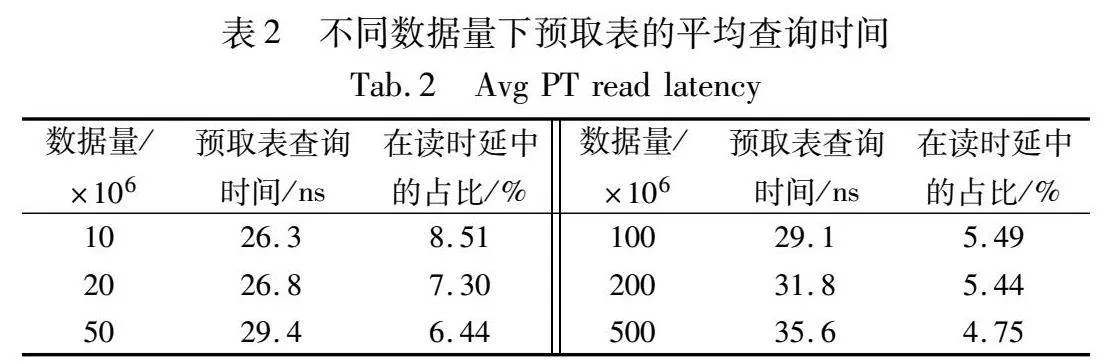
从图5可以看出,HOT-with-PF在不同数据量下相比HOT有10%~20%的读性能提升,数据量越大,提升效果越高。而HOT-HD由于使用的匹配算法较为低效,在数据量较小时能获得与HOT-with-PF类似的性能提升,但在数据量较高时性能劣于HOT本身。同时,如表2所示,在不同的数据量上,本文保证了预取表访问的平均代价始终处在30 ns左右的一个水平,这表明本文设计的高性能的预取表结构达成了目的。
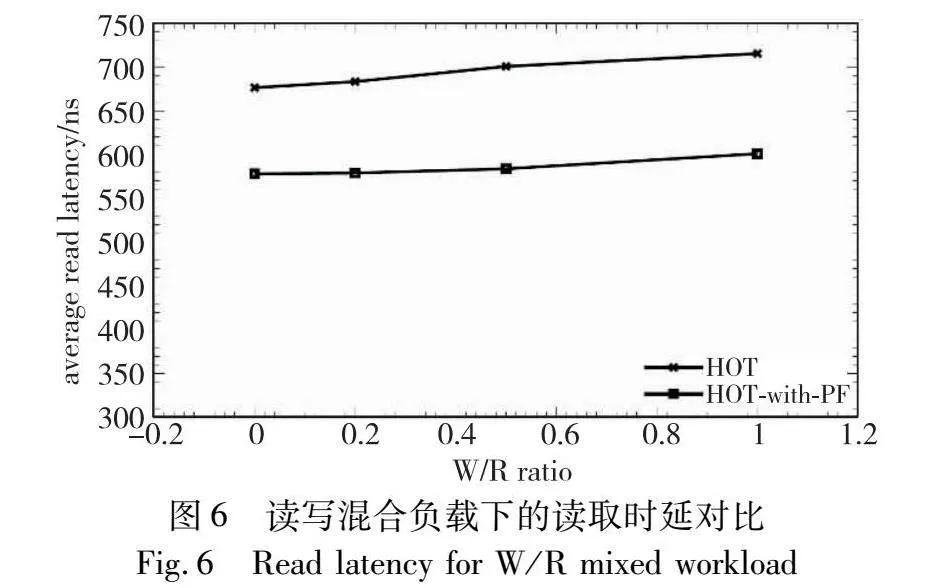
本文同样测试了在读写混合场景下,预取算法的表现。测试方式为:先向空索引中载入1亿条数据,数据来自集合S1。再在该索引中进行1亿次读请求(读取S1中的数据)和一定次数的写请求(写入集合S2,与S1无交集),读写请求交替进行。统计了该种工作条件下,索引的读取时延。在当前条件下,写请求并不会增加额外的树高,整体树高始终为6,不会由于数据量增加影响读操作性能。测试结果如图6所示。
从图6可以看出,读写混合的负载对HOT-with-PF的读性能不会产生影响。分析了预取算法的数据后,本文发现原因在于使用“存储部分key对应的路径”这一方法的前提下,能正确预取的最长路径平均长度在4左右。这导致预取实际上只能加速从树根开始的4层节点的访问; 而更向下的访问既无法被加速,对它们的修改也不会影响预取的性能。在读写混合情况下,每次写入只会修改被写入的叶节点,平均每20次写入才会修改一个中间节点,因此读写混合负载对HOT-with-PF的读取性能几乎不产生影响。
4.3 YCSB测试
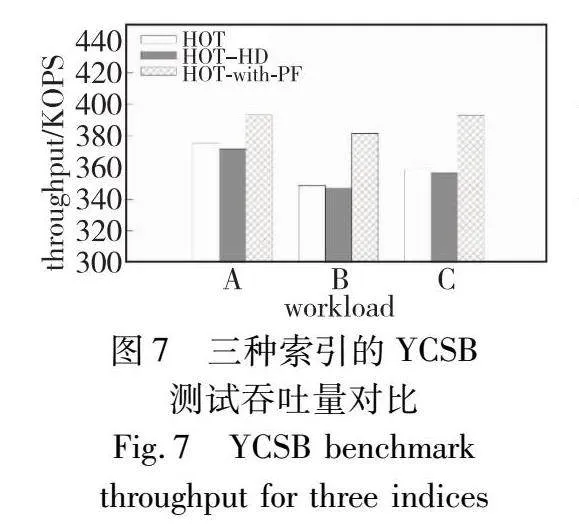
YCSB基准测试是数据库领域常用的基准测试工具,最初由Yahoo公司的实际负载产生,被学术界和工业界广泛使用。本文测试了上文提及的三种索引在YCSB数据集测试中的性能。YCSB测试的参数为: 5亿个键值对,值的平均长度为20 Byte,整体数据量为10 GB,进行的操作数量为1亿次。由于本文聚焦于索引的点查询性能优化,同时未对索引的写、范围查询流程进行改动,所以本文并未测试着重于更新的Workload D和着重于范围查询的Workload E。使用的工作负载为以下几个:a)workload A:50%读,50%写;b)workload B:95%读,5%写;c)workload C:100%读。
实验结果如图7所示。从图中可以看出,HOT-with-PF通过在索引性能上的提高,使得其整体吞吐量相比其他两种索引更高。HOT-HD受限于其在大数据量下的性能问题,吞吐量逊于HOT本身。同时,由于在YCSB这一模拟实际数据库的测试中,存在值读取、值验证等索引之外的数据库操作开销,导致HOT-with-PF的性能优势相比纯索引测试略有降低。
4.4 预取表大小对性能的影响
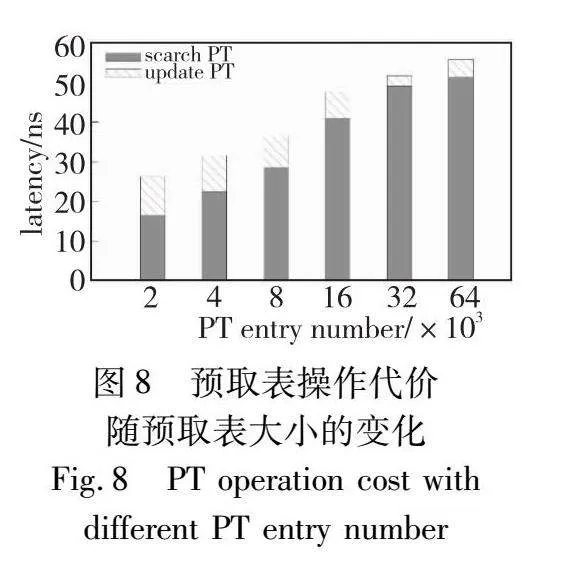
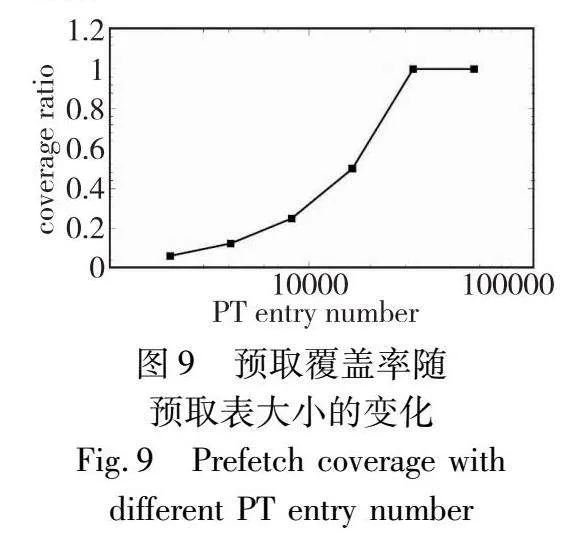
本节测试主要探讨预取表条目数量,下文称PT entry number对性能的影响。在当前设计下,该值与预取表的整体大小成正相关关系。因此,本组实验的目的是讨论预取表大小对预取性能的影响,并佐证本文设计的合理性。在本组实验中,本文向HOT-with-PF中载入1亿个KV对后,进行1亿次的索引读访问,访问数据均匀分布在整个数据集上,并统计了使用不同数量PT entry number时,读性能和与预取相关的各项参数。结果如图8、9所示。
读操作可以分为进行预取表查找和预取的search PT阶段、在树结构进行搜索的读取段和读取后更新预取表的update PT段,其中search PT和update PT两段时间直接与预取表相关,而读取段的运行时间与树高、cache miss等多方面因素相关。图7结果表示search PT和update PT两段时间与预取表条目数量参数的关系。由图8可知,越大的预取表条目数量,在访问时的时间开销越高; 同时预取表条目数量越大,发生哈希冲突的几率也在降低,带来的预取表更新次数减少,导致平均更新时间减少。两者共同影响下,预取表条目数量越小,预取表带来的额外开销也越小。
预取覆盖率coverage的定义为:预取表能给出预测的请求占所有读请求的比例。从图8、9可以发现,虽然越小的预取表,额外开销越低,但覆盖率也会降低,从而带来的加速效果会降低。因此预取表的大小并非越小越好,而是需要在预取表开销和预取效果中进行取舍。
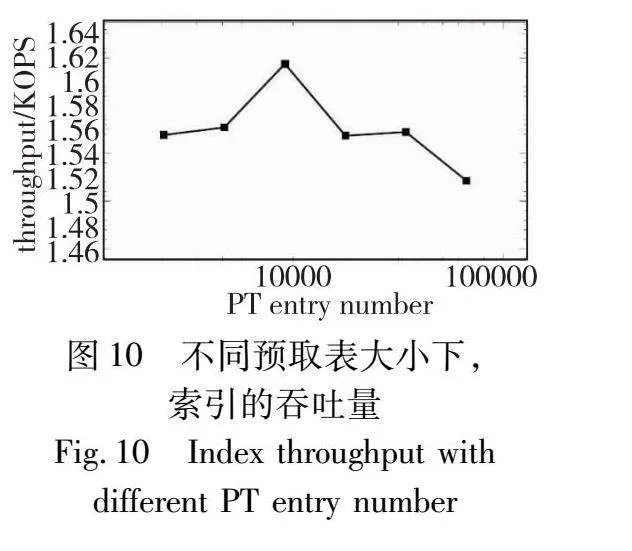
本文也测量了不同条目数量下,索引器的整体吞吐量。从图10可以发现,预取表条目数量为8 192时,索引器性能最优,是因为该值可以兼顾预取效果和预取表开销。因此,本文的默认设置中,将预取表大小设置为了8 192个条目,共0.5 MB,这是一个兼顾了预取表访问性能和预取覆盖率的选择。
5 结束语
本文对当前主流的树型内存索引进行了深入研究,发现其普遍存在的访存瓶颈。为了解决这一问题,本文提出了一种基于软件层面路径预取的优化方案,旨在通过正确地预测来提升索引性能。本文核心在于利用高效的预取表结构和匹配算法,实现对键与路径关系的准确记录与快速查询。实验结果表明,该方案在不同数据量和读写混合负载下均表现出良好的性能提升效果。
尽管本文预取算法在许多方面都取得了优化,但仍存在一些局限性。在变长字符串键的工作负载下,面临的挑战是准确率的下降。由于字符串键的长度可变,数据的分布变得难以预测,导致使用固定k个比特计算哈希的方法将许多键映射到同一位置。为了解决这一问题,未来的研究方向是记录和分析工作负载,支持动态调整各种参数,包括k值和预取表大小,以适应不同的工作负载。
综上所述,本文路径预取方案在树型内存索引的性能优化方面取得了显著成果。然而,针对变长字符串键的工作负载,仍需进一步研究以实现更准确的哈希匹配算法。未来研究将致力于改进预取算法以适应不同数据分布的工作负载,并优化参数调整机制,以提高索引性能的稳定性和适应性。
参考文献:
[1]Jiang Shizhi, Yang, Qiusong, Ci Yiwei. Merging similar patterns for hardware prefetching[C]//Proc of the 55th IEEE/ACM International Symposium on Microarchitecture. Piscataway, NJ: IEEE Press, 2022: 1012-1026.
[2]Navarro-Torres A, Panda B, Alastruey-Benedé J, et al. Berti: an accurate local-delta data prefetcher[C]//Proc of the 55th IEEE/ACM International Symposium on Microarchitecture. Piscataway, NJ: IEEE Press, 2022: 975-991.
[3]Bakhshalipour M, Shakerinava M, Lotfi-Kamran P, et al. Bingo spatial data prefetcher[C]//Proc of IEEE International Symposium on High Performance Computer Architecture. Piscataway, NJ: IEEE Press, 2019: 399-411.
[4]Vavouliotis G, Chacon G, Alvarez L, et al. Page size aware cache prefetching[C]//Proc of the 55th IEEE/ACM International Sympo-sium on Microarchitecture. Piscataway, NJ: IEEE Press, 2022: 956-974.
[5]Li Shuo, Chen Zhiguang, Xiao Nong, et al. Path prefetching: acce-lerating index searches for in-memory databases[C]//Proc of the 36th IEEE International Conference on Computer Design. Piscataway, NJ: IEEE Press, 2018: 274-277.
[6]Boehm M, Schlegel B, Volk P B, et al. Efficient in-memory indexing with generalized prefix trees[C]//Proc of the 14th BTW Conference on Database Systems for Business, Technology, and Web. 2011: 227-246.
[7]Leis V, Kemper A, Neumann T. The adaptive radix tree: artful indexing for main-memory databases[C]//Proc of the 29th IEEE International Conference on Data Engineering. Piscataway, NJ: IEEE Press, 2013: 38-49.
[8]Binna R, Zangerle E, Pichl M, et al. HOT: a height optimized trie index for main-memory database systems[C]//Proc of International Conference on Management of Data. New York: ACM Press, 2018: 521-534.
[9]Kallman R, Kimura H, Natkins J, et al. H-store: a high-performance, distributed main memory transaction processing system[J]. Proceedings of the VLDB Endowment, 2008,1(2): 1496-1499.
[10]Mao Yandong, Kohler E, Morris R T. Cache craftiness for fast multicore key-value storage[C]//Proc of the 7th ACM European Confe-rence on Computer Systems. New York: ACM Press, 2012: 183-196.
[11]Msker M, Sü T, Nagel L, et al. Hyperion: building the largest in-memory search tree[C]//Proc of International Conference on Ma-nagement of Data. New York: ACM Press, 2019: 1207-1222.
[12]Zhang Huanchen, Andersen D G, Pavlo A, et al. Reducing the sto-rage overhead of main-memory OLTP databases with hybrid indexes[C]//Proc of International Conference on Management of Data. New York: ACM Press, 2016: 1567-1581.
[13]Ahn J H, Li Sheng, Seongil O, et al. McSimA+: a manycore simulator with application-level+simulation and detailed microarchitecture modeling[C]//Proc of IEEE International Symposium on Performance Analysis of Systems and Software. Piscataway, NJ: IEEE Press, 2013: 74-85.
[14]
Wenisch T F, Somogyi S, Hardavellas N, et al. Temporal streaming of shared memory[C]//Proc of the 32nd International Symposium on Computer Architecture. Piscataway, NJ: IEEE Press, 2005: 222-233.
[15]Jain A, Lin C. Linearizing irregular memory accesses for improved correlated prefetching[C]//Proc of the 46th Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway, NJ: IEEE Press, 2013: 247-259.
[16]Somogyi S, Wenisch T F, Ailamaki A, et al. Spatial memory strea-ming[J]. ACM SIGARCH Computer Architecture News, 2006, 34(2): 252-263.
[17]Somogyi S, Wenisch T F, Ailamaki A, et al. Spatio-temporal memory streaming[J]. ACM SIGARCH Computer Architecture News, 2009, 37(3): 69-80.
[18]Roth A, Sohi G S. Effective jump-pointer prefetching for linked data structures[C]//Proc of the 26th Annual International Symposium on Computer Architecture. Piscataway, NJ: IEEE Press, 1999: 111-121.
[19]Collins J, Sair S, Calder B, et al. Pointer cache assisted prefetching[C]//Proc of the 35th Annual IEEE/ACM International Symposium on Microarchitecture. Piscataway, NJ: IEEE Press, 2002: 62-73.
[20]Wu Xingbo, Ni Fan, Jiang Song. Wormhole: a fast ordered index for in-memory data management[C]//Proc of the 14th EuroSys Confe-rence. New York: ACM Press, 2019: 1-16.
[21]Zeitak A, Morrison A. Cuckoo trie: exploiting memory-level paralle-lism for efficient DRAM indexing[C]//Proc of the 28th Symposium on Operating Systems Principles. New York: ACM Press, 2021: 147-162.
