融合信息扰动与特征解耦的单样本语音转换
2024-10-14王光刘宗泽董浩姜彦吉






摘 要:单样本语音转换的特性是利用单条目标说话人的语音样本即可实现身份的转换,但由于声学特征呈现复杂的相互作用和动态变化,现有方法难以充分将单样本语音中的说话人音色与其他声学特征解耦,导致转换音频在听觉上仍与源说话人的音色特征相似,存在说话人音色泄露情况。为此提出一种融合信息扰动与特征解耦的单样本语音转换模型,即IPFD-VC模型。首先,引入信息扰动模块对语音信号进行三次扰动操作,去除输入内容和韵律编码器中的冗余信息;其次,将处理后的语音信号送入各编码器,并结合最小化互信息策略进一步解耦声学特征,降低不同特征与说话人音色特征的相关性;最后通过解码器及声码器输出转换音频。实验结果表明:IPFD-VC模型转换音频的语音自然度和说话人相似度分别达到3.72和3.68,与目前先进的UUVC模型相比,梅尔倒谱失真降低0.26 dB。该模型能够有效对声学特征进行解耦,捕获目标说话人音色特征,同时保持源语言内容和韵律变化,降低说话人音色泄露风险。
关键词:单样本语音转换; 信息扰动; 特征解耦; 说话人音色泄露
中图分类号:TP391 文献标志码:A
文章编号:1001-3695(2024)10-028-3081-06
doi:10.19734/j.issn.1001-3695.2024.02.0034
One-shot voice conversion integrating informationperturbation and feature decoupling
Wang Guang1, Liu Zongze1, Dong Hao2, Jiang Yanji1
(1.College of Software, Liaoning Technical University, Huludao Liaoning 125105, China; 2.Suzhou Automotive Research Institute, Tsinghua University, Suzhou Jiangsu 215134, China)
Abstract:The characteristic of one-shot voice conversion is the ability to transform identity using only a single speech sample from the target speaker. However, the intricate interactions and dynamic variations of acoustic features pose challenges for existing methods to fully disentangle the speaker’s timbre from other acoustic features, resulting in the leakage of the original speaker’s timbre in the converted audio. To tackle this challenge, this paper proposed the IPFD-VC model to incorporate information perturbation and feature decoupling. The model initiated three perturbation operations to the voice signal through an information perturbation module in order to remove redundant information from input and the prosody encoder. Then it enabled to feed the processed signal into each encoders. The model employed a strategy of minimizing mutual information to further decouple the acoustic features, thereby diminishing their correlation with the speaker’s timbre characteristics. The decoder and vocoder subsequently output the convert audio. The experiments show that the IPFD-VC model achieves scores of 3.72 for voice naturalness and 3.68 for speaker similarity. In comparison to the advanced UUVC model, the model reduced the Mel-cepstral distortion by 0.26 dB. The IPFD-VC model effectively decouples acoustic features, captures the target speaker’s timbre, preserves the source language content and rhythmic variations, and mitigates the risk of speaker timbre leakage.
Key words:single-sample voice conversion; information perturbation; feature decoupling; speaker voice leakage
0 引言
语音转换(voice conversion)是一种在保持语言内容和韵律变化的情况下,将源说话人的声音转换为目标说话人的技术[1],在多媒体娱乐、智能家居、医疗辅助等多个领域中具有广泛的应用。随着深度学习的发展,研究方向已从低效的参数方法[2,3]转向基于神经网络的语音转换技术[4,5],语音转换质量得到较大提升,但是需要丰富且高质量的标准录音数据集进行训练。然而在个性化语音交互的实际场景中,目标说话人的语音样本采集难度大、成本高,用于深度学习模型训练的样本数不足,易导致过拟合。
因此如何在有限的样本下进行高质量语音转换引发了人们的探索。单样本语音转换(one-shot voice conversion)又被称为任意到任意(any-to-any)的语音转换,旨在转换过程中,仅使用来自任意目标说话人的单条语音样本,即可实现从任何源说话人到任意目标说话人的身份转换,该技术对语音样本数量要求较低,因此更加适用于实际场景中。为实现单样本语音转换,较为流行的方法是采用特征解耦,模型需要学习源说话人与目标说话人语音中所有的潜在声学特征,并将说话人音色特征与其他声学特征尽可能地分离,解耦是否充分对于实现单样本语音转换至关重要。早期特征解耦方法主要采用联合说话人编码器,将说话人音色特征与内容特征分离,AutoVC[6]通过结合生成对抗网络(GAN)和条件变分自动编码器(CVAE),在内容编码器上提取不同维度的瓶颈特征,使内容特征与说话人音色特征进行分离。Liu等人[7]采用i-vector表示源说话人音色特征,并利用语音后验图(PPG)表示与说话人无关的特征,以实现特征的解耦。AGAIN-VC[8]通过自适应实例归一化,可以较好地分离说话人音色特征和内容特征。矢量量化 (VQ)是一种有效的数据压缩技术,可以将连续数据量化为离散数据[9]。VQVC[10]仅通过重建损失解开内容特征和说话人音色特征。VQVC+[11]通过学习矢量量化表示,以及使用U-Net网络结构进一步改进了内容特征分离。但由于VQ的离散性,内容信息提取完整较为困难。Zhang等人[12]对源说话人音色特征进行解耦,并引入目标说话人嵌入进行对抗性训练,保留了较好的内容特征。
为了提升转换音频的自然度,科研人员开始尝试对韵律特征解耦,Helander等人[13]研究发现韵律在构成完整的语音中起着关键作用,与表达内容密切相关,是提高转换音频自然度的重要因素之一。Wang等人[14]将经过目标说话人归一化的音高轮廓输入解码器,并进行语音重建。SpeechSplit[15]对内容、说话人音色和音高进行独立建模,通过分阶段地将对应特征输入编码器,并手动微调从中提取的瓶颈特征,以实现更为有效的解耦。AutoPST[16]利用基于相似性的重采样技术,通过自动编码器对韵律特征进行单独建模。SpeechSplit2.0[17]与SpeechSplit具有相似的结构,无须调整自动编码器的瓶颈特征。SRDVC[18]利用基于梯度反转层的对抗性互信息学习,对音高及节奏进行建模。最新的研究UUVC[19]采用级联模块化结构,旨在实现音调和说话人音色的解耦,该系统通过自监督学习的方法,利用离散语音单元作为语言表示,从而进行单样本语音转换。
上述方法为高质量单样本语音转换提供良好的开端,但解耦程度难以衡量,同时在训练过程中未对说话人音色、内容和韵律之间的相关性进行约束,导致解耦不充分,造成说话人音色泄露的问题[20],即转换音频呈现源说话人或介于两者之间的音色,从而导致语音转换性能下降。
在前人的研究基础上,结合对语音声学特征的分析,如说话人音色、内容和韵律特征,设计融合信息扰动与特征解耦的单样本语音转换模型,即IPFD-VC模型,采用端到端结构。IPFD-VC在时域和频域上对语音信号进行三次信息扰动[21],对语音信号中冗余的声学特征进行调整,引导编码器专注于学习稳定特征,并排除无关信息,为后续解耦提供坚实基础;在训练期间,通过最小化互信息的变分对比对数上界(vCLUB)[22],进一步将声学特征进行解耦,减少不同声学嵌入之间的相关性。
本文的主要工作如下:a)设计了一种新颖的单样本语音转换模型,可在个性化语音数据有限的实际场景中,实现任意说话人之间的语音转换;b)提出一种融合信息扰动与结合最小化互信息策略的特征解耦的方法,能够对提取到的特征进行相关性约束,使编码器专注于处理对应的声学特征。实验结果表明,IPFD-VC模型转换的音频拥有更好的语音相似度和语言自然度,可以有效缓解说话人音色泄露问题。
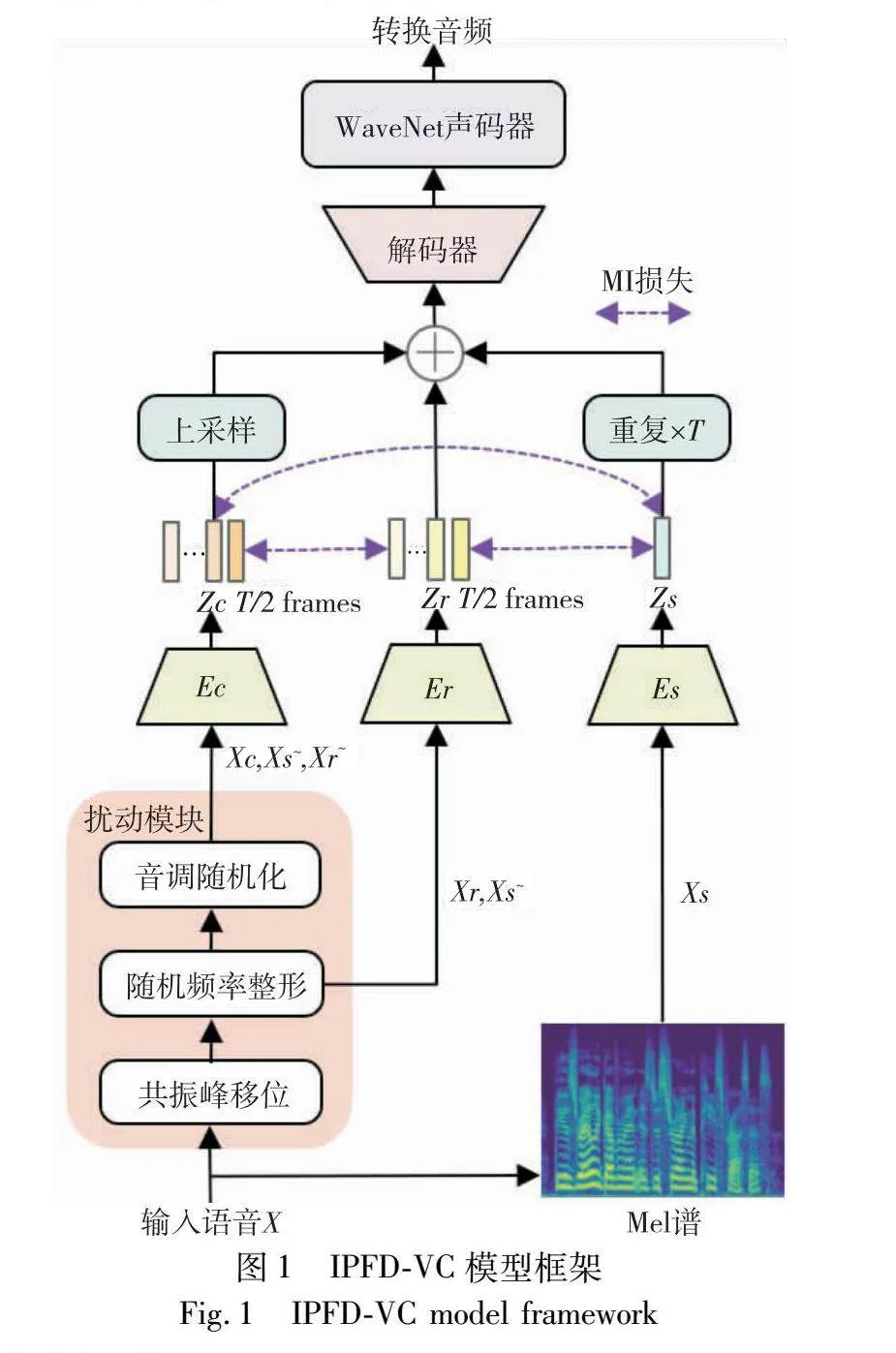
1 IPFD-VC模型
本章介绍融合信息扰动与特征解耦的高质量单样本语音转换模型的过程方法。
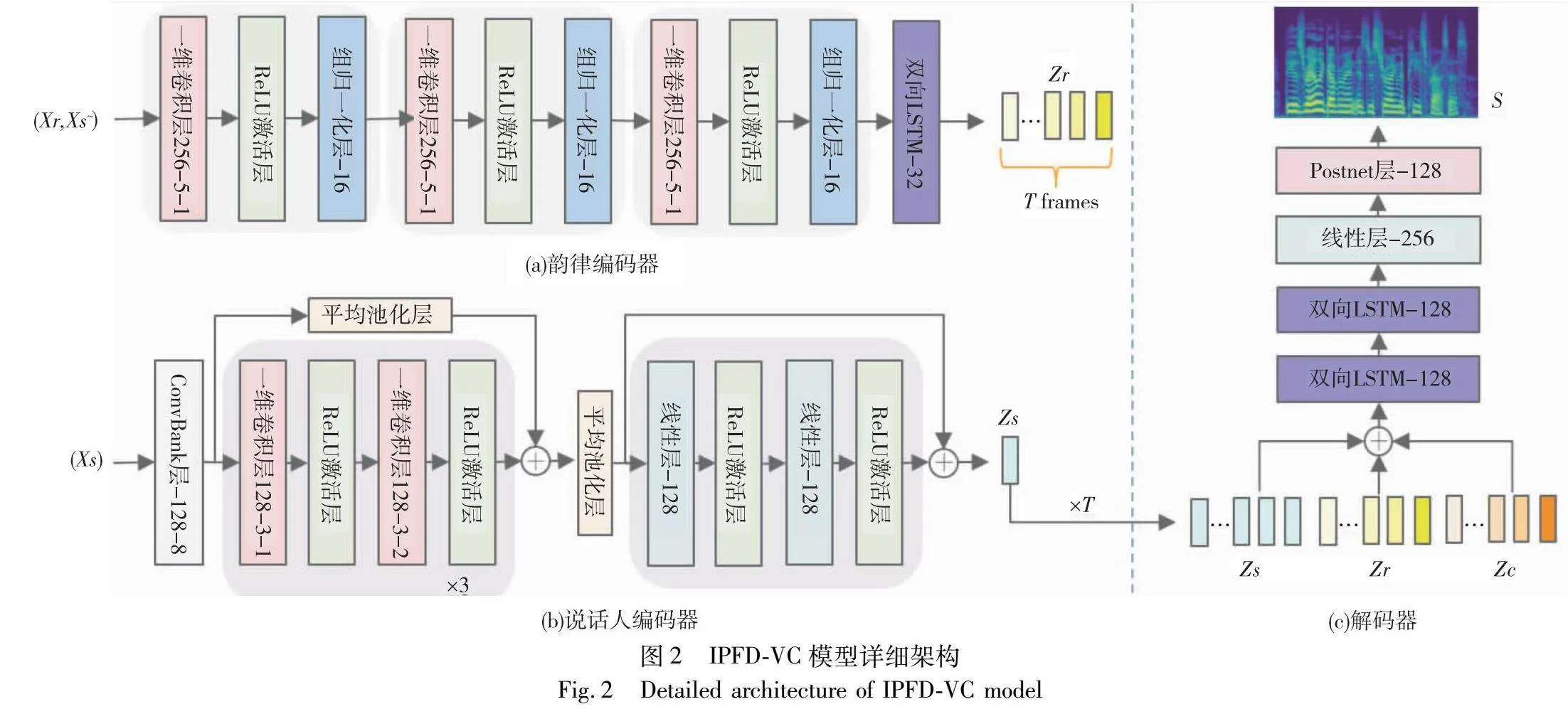
单样本语音转换模型的性能取决于对声学特征的解耦程度以及重构能力。由于声学特征之间解耦不充分,从源说话人语音中提取的内容特征与韵律特征仍掺杂源说话人的音色信息,并与目标说话人的音色特征一同送入解码器和声码器进行语音转换,导致转换后的音频在听觉上仍与源说话人的音色特征相似,造成说话人音色泄露。IPFD-VC为消除转换音频中说话人音色泄露问题,首先采用信息扰动模块,去除送入内容编码器和韵律编码器中的冗余信息,使编码器专注于提取对应类别特征;其次使用最小化互信息的变分对数上界,进一步将说话人音色特征与其他声学特征进行解耦,IPFD-VC模型框架如图1所示。
1.1 信息扰动
语音中融合多种声学特征,展现出复杂的相互作用和动态变化,Choi等人[23]将未经处理的语音梅尔谱图送入wav2vec内容编码器提取特征,并将其输入神经网络进行训练,成功实现梅尔谱图的重构。这证实内容编码器不仅捕捉到丰富的内容信息,同时掺杂了与音调和说话人身份相关的特征[24]。当仅使用音高编码器进行特征提取,并尝试重建梅尔谱图时,仍然可以观察到与说话人身份相关的信息[25],导致说话人音色特征泄露。为了提高模型性能,并确保各编码器能够专注学习特定目标,本模型采用信息扰动方法,有针对性地消除源语音中存在的冗余信息,从而避免模型学习无关特征。
具体而言,内容编码器旨在从源语音中提取与内容相关的特征,而韵律编码器专注于捕捉与韵律有关的特征。IPFD-VC模型在训练内容编码器和韵律编码器之前,设计了信息扰动模块,包含三种语音信号扰动函数,确保模型的训练过程更为精准和高效。通过引入共振峰移位(fs)[26]函数,从均匀分布U(1.2,1.5)中随机选取共振峰移位的比率,对源语音的共振峰进行调整,从而直接改变说话人的音色特质。通过引入参数均衡器(peq)[27]进行随机频率整形,进一步为防止说话人音色泄露到内容与音高中,删除与说话人相关的特征,随机频率整形过程描述如下:
HPEQ=HLSHHS∏8i=1HPeaki(1)
其中:HLS是低倾斜滤波器;HPeak代表峰值滤波器;HHS是高倾斜滤波器,每个滤波器都是二阶IIR滤波器。HLS和HHS的截止频率分别固定为60 Hz和10 kHz。HPeaki的中心频率以均匀分布在倾斜滤波器对数尺度上。
音调是韵律表达的关键要素之一,通过引入音调随机化(pr)[26]技术,从均匀分布U(1.1,1.6)和U(1.1,1.5)中随机选取基音平移比和基音范围比,使得源语音摆脱对特定音调范围的依赖,消除韵律特征,从而确保语音信号仅保留内容信息。
如图2所示:给定一段语音X,提取梅尔谱图X={x1,x2,…,xT},其中T是语音帧的总数,而Xc、Xs和Xr分别表示包含内容、说话人音色和韵律信息的梅尔谱图。Xs~和Xr~分别代表包含使用信息扰动模块进行处理后的说话人音色信息和韵律信息的梅尔谱图。IPFD-VC模型的信息扰动模块具体实现过程为:将语音沿时间维度进行两段信息扰动操作,第一阶段使用共振峰移位与随机频率整形的组合,消除源说话人的音色,而保留其韵律特性;该阶段获取韵律特征Xr的过程描述如下:
Xr=peq(fs(X))(2)
其中:Xr不包含源语音中与说话人相关的信息,随后将Xr作为韵律特征输入到韵律编码器中。
在第二阶段采用音调随机化的方法,消除源说话人音高,同时确保内容信息得以保留,该阶段获取内容特征Xc的过程描述如下:
Xc=pr(peq(fs(X)))(3)
其中:输出的Xc不包含源语音的说话人音色信息及韵律信息。将调整后的Xc送入内容编码器进行特征提取,使得内容编码器能够专注于学习和捕捉语言内容特征。
1.2 模型架构
在IPFD-VC模型结构中,包含信息扰动模块、编码器、解码器和声码器四个核心部分。其中编码器由内容编码器、韵律编码器和说话人编码器组成。
在SpeechSplit的模型基础上,内容编码器(Ec)沿用SpeechSplit的架构进行内容特征提取,将经过扰动处理的语音(Xc,Xr~,Xs~)参数化为梅尔谱图(Xc,Xr~,Xs~),并将其输入到卷积层进行特征提取,随后送入两个双向LSTM层进行前后文整合,最后通过下采样将时间维度减半至T/2,在保留内容特征的同时,提高模型的计算效率和性能,提取的内容嵌入(Zc)表示如下:
Zc=Ec(Xc,Xr~,Xs~)(4)
为了增加转换音频的自然度,IPFD-VC模型中引入韵律编码器(Er),对话语级的韵律特征进行单独建模。首先将经过扰动处理的语音(Xr,Xs~)参数化为梅尔谱图(Xr,Xs~),并将其输入到韵律编码器中。该编码器由三个5×1的卷积层构成,采用ReLU激活函数,并在每层之后进行组归一化处理,该方法对小批量或大尺寸数据具有优势,可提高训练速度并增强模型泛化能力。经过组归一化后的输出被送入一个双向LSTM层,以减少特征维度。韵律编码器的详细设计如图2(b)所示,提取的韵律嵌入(Zr)表示如下:
Zr=Er(Xr,Xs~)(5)
说话人编码器由以下四个部分组成:ConvBank层、三个一维卷积与激活函数的组合、线性层与激活函数的组合,以及平均池化层。ConvBank层用于从输入序列中精确提取局部特征和上下文信息,扩大感受野范围,进而增加对长时序信息的捕获能力,为后续阶段提供更深入和全面的特征表示;一维卷积与ReLU激活函数组合优化特征提取的非线性能力;平均池化层强化对全局信息的关注,精确捕捉说话人身份特征;线性层与ReLU激活函数进一步提升映射能力,确保说话人编码器的高效性和准确性。说话人编码器的详细设计如图2(b)所示,提取的说话人嵌入(Zs)表示如下:
Zs=Es(Xs)(6)
为确保内容、说话人和韵律嵌入具有相同的时间维度,采取以下策略:将内容嵌入上采样至T帧,说话人嵌入被复制T次,将三种嵌入进行连接,并一同送入解码器。解码器对隐藏嵌入进行沿通道维度连接,随后将其送入两个双向LSTM层、线性层以及Postnet层。线性层用作调整特征维度,Postnet层通过其卷积操作进一步细化和优化解码器的输出,解码器详细结构如图2(c)所示。解码器Ds重建语音频谱图S的表示如下:
S=Ds(Zc,Zs,Zr)(7)
在训练过程中,解码器Ds的输出旨在学习准确地重构输入的频谱图S,为实现这一目标,解码器与编码器联合训练,通过最小化重建损失来优化模型性能:
LDs=Euclid Math TwoEAp[‖S-X‖21+‖S-X‖22](8)
1.3 损失函数
互信息(mutual information,MI)描述的是衡量随机变量相互依赖的程度。两个不同变量之间依赖关系的度量可以表述为
I(X,Y)=∫X∫YP(X,Y)logP(X,Y)P(X)P(Y)(9)
其中:P(X)和P(Y)分别是X和Y的边缘分布;P(X,Y)表示X和Y的联合分布。通过对比学习的策略,利用正样本和负样本之间的条件概率差异,使用变分对比对数上界(vCLUB)作为计算不相关信息的互信息上限的估计量。互信息的vCLUB无偏估计定义为
I^(X,Y)=Euclid Math TwoEApp(X,Y)[log qθ(X|Y)]-
Euclid Math TwoEApp(X)Euclid Math TwoEApp(Y)[log qθ(X|Y)](10)
其中:X,Y∈{Zc,Zs,Zr},qθ(X|Y)是一个变分分布,用参数θ来近似p(X|Y)。无偏估计样本{xi,yi}的vCLUB的无偏估计量表示为
I^(X,Y)=1N2∑Ni=1∑Nj=1[log qθ(xi|yi)-log qθ(xj|yi)](11)
其中:xi、yi∈{Zci,Zsi,Zri },通过最小化式(11),可以有效减少不同语音表示之间的相互依赖。
本模型引入说话人MI损失,在训练过程中,可以通过最小化MI损失来降低内容、韵律特征与说话人音色特征之间的相关性,解决特征之间的信息交叉或泄露问题。将说话人MI损失应用于内容嵌入(Zc)、说话人嵌入(Zs)、韵律嵌入(Zr),说话人MI损失(LSMI),如式(12)所示。
LSMI=I^(Zs,Zc)+I^(Zs,Zr)+I^(Zc,Zr)(12)
在每次迭代的训练中,首先进行变分近似网络的优化,其目标是最大化给定条件下的对数似然函数log qθ(X|Y),随后进行IPFD-VC模型的优化。IPFD-VC模型的总体损失可以计算为
LALL=LDs+λSMILSMI(13)
其中:λSMI是来调节说话人MI损失以增强解耦的权重参数。
1.4 IPFD-VC模型工作流程
IPFD-VC模型的工作流程包括训练阶段和转换阶段。在模型的训练阶段,首先对源语音和经过扰动处理后的语音进行预处理并提取梅尔谱图,随后将梅尔谱图分别输入说话人编码器、韵律编码器和内容编码器中,以分离和学习语音中的不同特征,通过迭代计算损失函数不断优化模型,最后训练得到能够精确捕捉和再现语音特征的说话人编码器Es、韵律编码器Er、内容编码器Ec和解码器Ds。
算法1 IPFD-VC模型的训练算法
输入:梅尔谱图(Xc,Xr~,Xs~)、(Xr,Xs~)、Xs,学习率参数为α和β。
输出:训练得到Es、Er、Ec和Ds。
a)i=1 //设置迭代次数
b)for i≤N do
c) Zc←f{(Xc,Xr~,Xs~);Ec};Zr←f{(Xr,Xs~);Er};
Zr←f{Xs;Es};
d) θX,Y←θX,Y+αθX,YLX,Y,X,Y∈{Zc、Zr、Zs}
//每次进行更新时, 计算对数似然函数LX,Y=log qθ(X|Y)
e) θ←θ-βθLALL,θ∈{Es、Er、Ec、Ds}
//每次进行更新时, 计算模型的整体损失LALL
f)end for
g)return Es、Er、Ec、Ds
在转换阶段,将源说话人和目标说话人的语音同时输入进IPFD-VC模型中,得到由编码器重构的转换音频梅尔谱图,随后,将重构的梅尔谱图输入到预先训练好的神经声码器中,最终生成转换音频。
2 实验及结果分析
2.1 实验设置
实验选取语音转换研究主流使用的CSTR-VCTK语料库[28],该数据集包括109位英语说话人的语音样本,每位说话人阅读约400个句子。随机选取89位说话人作为训练集,10位说话人作为验证集,其余10位说话人用于测试集。
将所有语音下采样至16 kHz,对音频进行预加重、分帧,并进行加窗操作,采用窗口大小为1 024,滑动大小为256的Hann窗,并进行短时傅里叶变换后,随后采用FFT大小为1 024的短时傅里叶变换,用来计算梅尔谱图,使用跨度为90 Hz~7.6 kHz的80通道梅尔滤波器组将STFT幅度转换为梅尔标度。
IPFD-VC模型在单个NVIDIA 3060 GPU上进行训练,并使用ADAM优化器,学习率为E-4,β1=0.9,β2=0.98,批量大小为16,设置λSMI=0.01,并使用预训练的WaveNet声码器[29]将输出的梅尔谱图转换回波形。
在实验中选取AutoVC[6]、AGAIN-VC[8]、SRDVC[18]和UUVC[19]等先进的基线模型进行比较,所有基线模型均使用与IPFD-VC相同的训练集、验证集和测试集。
2.2 语音转换效果评价
2.2.1 主观评价
实验采用的主观评价指标为语音自然度平均意见得分(MOS)和说话人相似度平均意见得分(SMOS)。测试人员使用五分制对转换后的语音进行评分,评分标准如下:5分代表“优秀”,4分表示“良好”,3分为“一般”,2分对应“差”,1分表示“很差”。分数越高表明转换方法性能越好,转换音频听起来更自然,转换音频与目标说话人的音色更为接近。
主观测试共有15名20~30岁的研究生听众参与,其中10人(5男5女)具有语音测评经验,另外5人(2男3女)则为随机选取。在转换场景为Seen-Seen、Seen-Unseen和Unseen-Unseen的测试中,Seen代表说话人出现在训练集中,Unseen表示说话人从未在训练集中出现过,即任意说话人。每个场景分别随机选取10个语音对,每个语音对包含源音频、目标说话人音频,以及使用IPFD-VC与基线模型分别对同一条语音进行转换后得到的音频。15名听众采用MOS评分与SMOS评分依次进行评价。
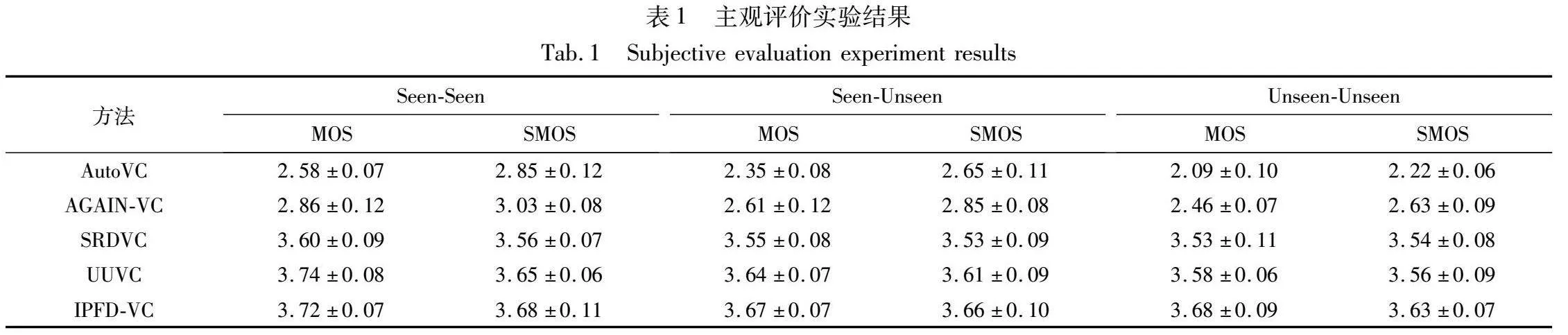
在语音自然度测试中,听众需听取每个语音对中,按照随机顺序排列的不同模型转换产生的音频,对音频质量进行打分,并计算MOS评分。在说话人相似度测试中,给出源说话人和目标说话人的真实语音,随后听众需要听取每个语音对中按照随机顺序排列的不同模型转换产生的音频,与真实语音的音色进行对比并打分,计算SMOS评分,实验采用的置信区间为95%。语音自然度测试和说话人相似度测试的实验结果如表1所示。
在三种不同的场景中,IPFD-VC的MOS评分分别达到了3.72、3.67和3.68,评分仅在Seen-Seen场景中低于UUVC模型0.02,其余场景均超越三种基线模型,在Unseen-Unseen场景中,领先UUVC模型0.10,表明IPFD-VC模型在音频转换质量方面具备的显著优势,将通过扰动处理后的语音送入话语级韵律建模的编码器,能够准确地捕捉源说话人语音的韵律和细节,使得转换后音频更加真实和自然。
IPFD-VC的SMOS评分在Seen-Seen和Seen-Unseen的情境中领先三种基线模型0.03以上;在Unseen-Unseen的情境中,IPFD-VC较UUVC提升0.07,呈现出领先的性能水平。值得注意的是,IPFD-VC在这三种情境中的SMOS评分都非常接近,这表明IPFD-VC能够有效地分离声学特征,并成功将目标说话人的音色特征转移至源语音中。这不仅提高了转换音频的说话人相似度,同时降低说话人音色特征泄露的风险。
2.2.2 客观评价
在本实验中,客观评价指标使用以下三种方法:梅尔倒谱失真(MCD)、单词错误率(WER)和logF0的皮尔森相关系数(logF0 PCC)。
梅尔倒谱失真(MCD): 其是一种衡量语音信号质量的指标,计算公式如下。
MCD=10ln 10 2∑Nn=1(Cc-Ct)2(14)
其中:Ct表示目标语音的梅尔倒谱系数;Cc表示转换后的语音梅尔倒谱系数。MCD数值越低,失真程度越小,代表转换音频更接近自然语音,同时MCD用于计算转换语音频谱和真实目标语音频谱之间的距离,也可以代表转换音频与目标说话人的相似程度。
单词错误率(WER):验证转换音频是否能够保留源语音的语言内容,其中WER是由ESPnet2模型中基于Transformer的自动语音识别(ASR)模块[30]计算得到,该模块由Librispeech语料库进行训练。
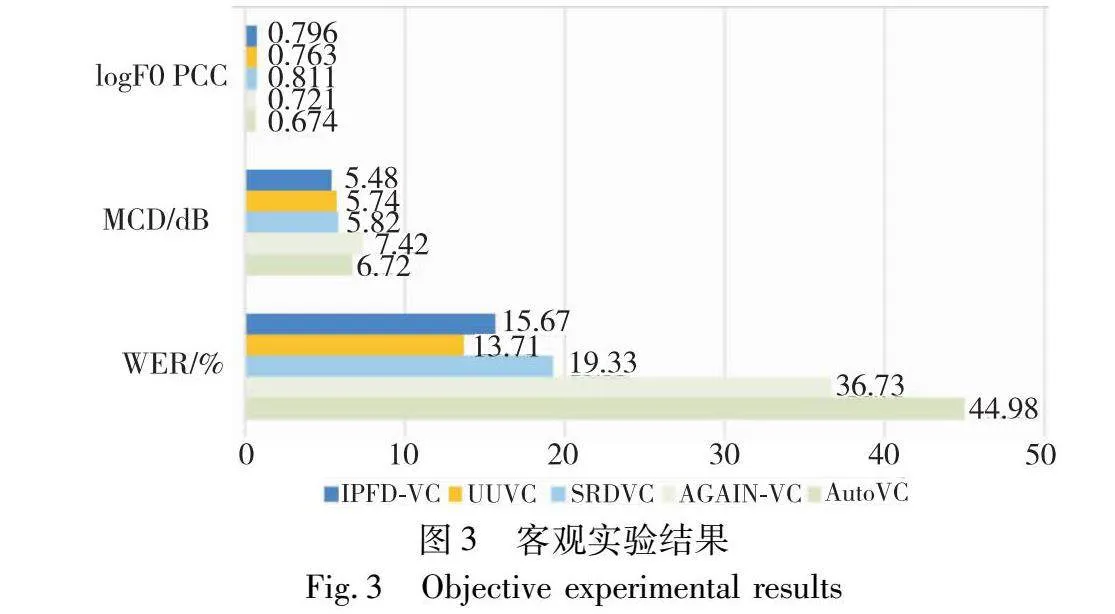
logF0的皮尔森相关系数(logF0 PCC):用于验证语音信号中基频(F0)的相关性,即验证转换音频的语调变化,计算源语音和转换后语音的F0之间的皮尔森相关系数,并对系数进行对数转换,将取值控制在[-1,1],其中1表示完全正相关,-1表示完全负相关,0表示没有线性关系。在转换场景为Seen-Seen、Seen-Unseen和Unseen-Unseen的测试中,每个场景分别随机选取50个语音对,并计算三种客观指标的平均值,实验结果如图3所示。
在MCD对比实验中,IPFD-VC模型呈现出最低的MCD值,仅为5.48 dB,相较于性能先进的UUVC模型,IPFD-VC的MCD值减少0.26 dB,证明IPFD-VC模型可以提高转换语音的质量,提升语音自然度。
在进行WER测试中,IPFD-VC与UUVC相比具有相似的单词错误率,与SRDVC相比,单词错误率降低3.66%,并远低于AutoVC和AGAIN-VC模型,进一步证明了其在信息扰动和特征解耦过程中,能够更有效地保留源语音的内容信息,保持内容相似度。
在logF0 PCC的对照实验中,IPFD-VC模型与SRDVC展现出相似的性能,都能有效地转换并保留从源语音到目标语音的韵律特性。但SRDVC较IPFD-VC在数值上提升0.015,因为SRDVC的音高表示直接从给定的音高轮廓中提取的,而未进行特征解耦与编码过程。IPFD-VC仍高于另外三种基线模型,较高的logF0 PCC表明经过扰动处理后的音频可以很好地保持目标说话人的韵律特征,从而提升语音的相似度和可理解性。
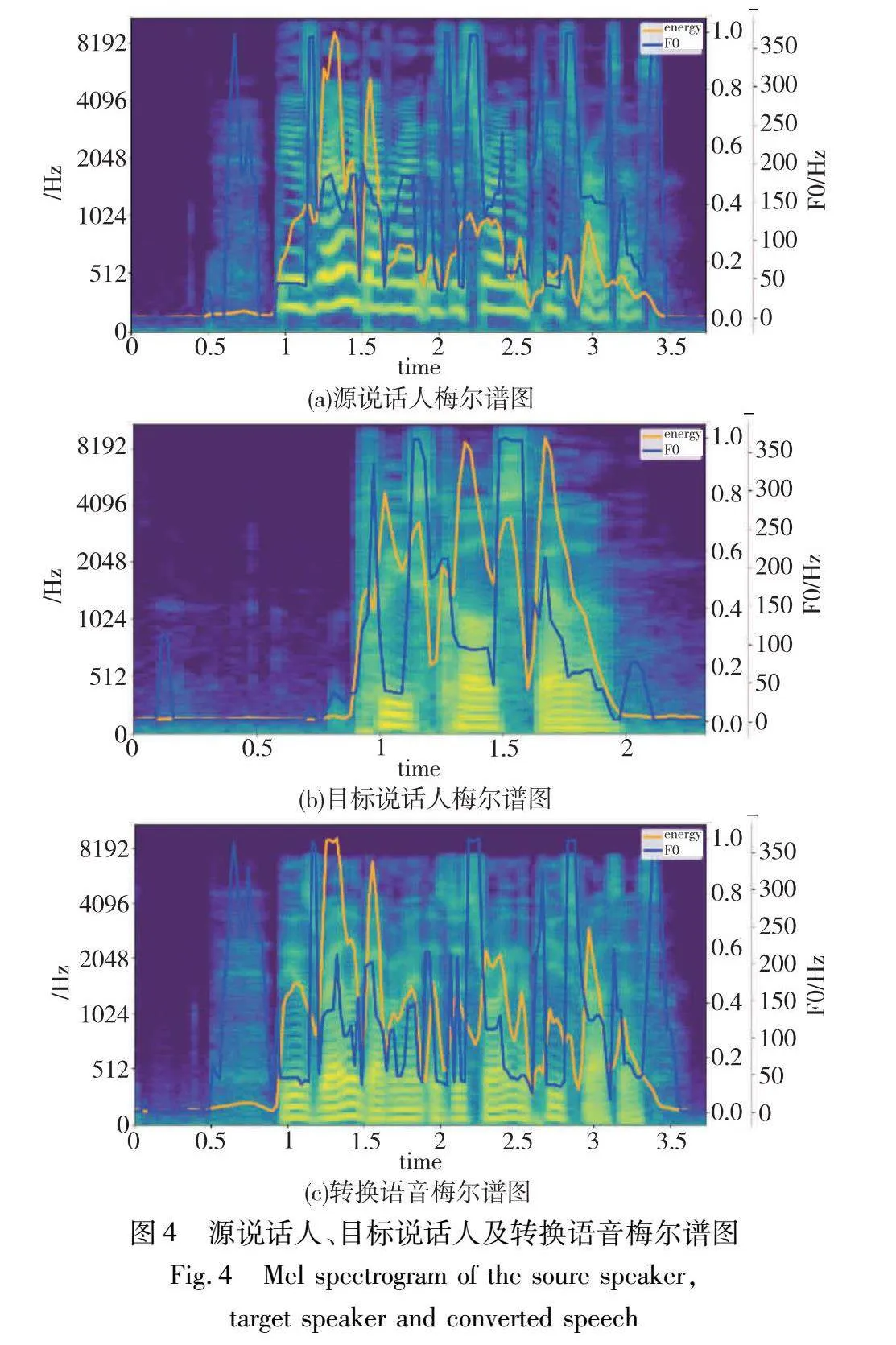
2.3 频谱分析
图4显示了本模型在转换阶段生成的梅尔谱图,其中图(a)是来自女性源说话人的梅尔谱图,图(b)是男性目标说话人的梅尔谱图,图(c)是转换音频的梅尔谱图。横轴代表时间,纵轴代表频率。蓝色为音高曲线,黄色为能量曲线。
如图所示,可以观察到源语音的梅尔谱图峰值间隔相对较短,而经过IPFD-VC转换后的梅尔谱图显示其峰值间隔更接近于目标说话人。在低频区域,转换语音的条纹宽度和波动趋势更加接近目标说话人,这表明在特定频率范围内的声学特征得到了有效转换。而在高频区域,源说话人的能量曲线呈下降趋势,而IPFD-VC转换后的语音与目标说话人的能量曲线更为相似和饱满,表明能够很好地保留目标说话人的韵律特征。
在音调方面,源说话人的基频曲线具有明显的尖锐特点,而经过IPFD-VC转换后的语音基频曲线与目标说话人均略微平缓,符合源说话人与目标说话人的性别特性。实验表明IPFD-VC可以进一步保持源语言内容和韵律变化,增加说话人相似性,减少说话人音色特征泄露问题。
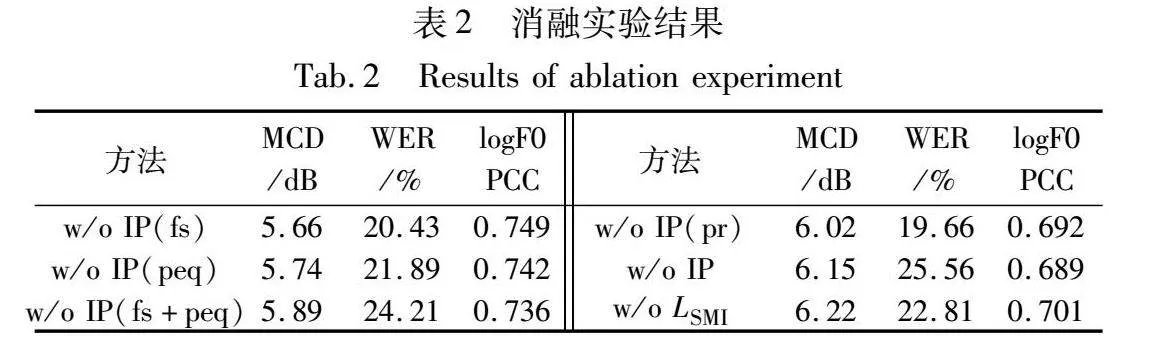
2.4 消融实验
本节对单样本语音转换任务中各模块的性能影响进行深入的分析。消融实验在Unseen-Unseen情境中进行消融实验,验证信息扰动模块和说话人MI损失模块对模型性能的影响。w/o IP表示去除信息扰动模块,w/o IP(fs)表示去除信息扰动共振峰移位模块,w/o IP(pr)表示去除信息扰动音调随机化模块,w/o IP(peq)表示去除信息扰动随机频率整形模块,w/o LSMI表示去除说话人MI损失模块,结果如表2所示。
在MCD得分方面,去除说话人MI损失模块与去除整体信息扰动模块相比仅相差0.07 dB,与IPFD-VC相比MCD上升0.74,表明这两个模块对保持转换语音频谱和真实目标语音频谱之间的距离都具有积极意义,能够进一步进行特征解耦,并拥有较好的重构能力。
在WER得分方面,去除整体信息扰动模块与去除共振峰移位+随机频率整形模块的效果相似,与IPFD-VC相比单词错误率上升了9.89%,这一变化相比去除说话人MI损失模块的影响更为显著,表明该模块能够很好地去除冗余信息,对于保留语音内容具有重要作用。
在logF0 PCC得分方面,去除整体信息扰动模块和去除音调随机化模块的效果相似,logF0 PCC下降至0.689,表明音调随机化模块能够很好地去除冗余信息,为后续模块进一步特征解耦提供了支持。
3 结束语
本研究针对现有单样本语音转换模型在执行转换任务过程中出现的说话人音色泄露问题,提出了IPFD-VC模型。该模型通过结合信息扰动和最小化互信息策略,有效减少不同声学特征之间的相互依赖,使得编码器能够更专注于处理特定的声学特征。实验结果表明,相较于现有先进的基线模型,IPFD-VC模型的转换音频在主观评价中,说话人相似度和语言自然度方面均表现出显著优势,在客观评价中,MCD仅为5.48 dB,单词错误率降低3.66%,logF0 PCC与基线模型具有相似的性能。在消融实验中,表明信息扰动模块与最小化互信息策略能够提升特征解耦的性能,同时有效地降低了说话人音色特征泄露的潜在风险。尽管如此,转换后的语音与真实目标语音仍存在一定的差距,在未来的工作中,需要进一步提高模型性能,以达到无限接近真实语音的效果,能够满足个性化真实场景的需要。
参考文献:
[1]Sisman B, Yamagishi J, King S, et al. An overview of voice conversion and its challenges: from statistical modeling to deep learning[J]. IEEE/ACM Trans on Audio, Speech, and Language Proces-sing, 2020, 29: 132-157.
[2]Godoy E, Rosec O, Chonavel T. Voice conversion using dynamic frequency warping with amplitude scaling, for parallel or nonparallel corpora[J]. IEEE Trans on Audio, Speech, and Language Processing, 2011, 20(4): 1313-1323.
[3]Wu Zhizheng, Virtanen T, Chng E S, et al. Exemplar-based sparse representation with residual compensation for voice conversion[J]. IEEE/ACM Trans on Audio, Speech, and Language Proces-sing, 2014, 22(10): 1506-1521.
[4]Fang Fuming, Yamagishi J, Echizen I, et al. High-quality nonparallel voice conversion based on cycle-consistent adversarial network[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2018: 5279-5283.
[5]Ding Shaojin, Gutierrez-Osuna R. Group latent embedding for vector quantized variational autoencoder in non-parallel voice conversion[C]//Proc of InterSpeech. 2019: 724-728.
[6]Qian Kaizhi, Zhang Yang, Chang Shiyu, et al. AutoVC: zero-shot voice style transfer with only autoencoder loss[C]//Proc of International Conference on Machine Learning. 2019: 5210-5219.
[7]Liu Songxiang, Zhong Jinghua, Sun Lifa, et al. Voice conversion across arbitrary speakers based on a single target-speaker utterance[C]//Proc of InterSpeech. 2018: 496-500.
[8]Chen Yenhao, Wu Dayi, Wu Tsunghan, et al. AGAIN-VC: a one-shot voice conversion using activation guidance and adaptive instance normalization[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2021: 5954-5958.
[9]Chorowski J, Weiss R J, Bengio S, et al. Unsupervised speech representation learning using WaveNet autoencoders[J]. IEEE/ACM Trans on Audio, Speech, and Language Processing, 2019, 27(12): 2041-2053.
[10]Wu Dayi, Lee Hungyi. One-shot voice conversion by vector quantization[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2020: 7734-7738.
[11]Wu Dayi, Chen Yenhao, Lee H. VQVC+: one-shot voice conversion by vector quantization and U-Net architecture[EB/OL]. (2020-06-07). https://arxiv.org/abs/2006. 04154.
[12]Zhang Haozhe, Cai Zexin, Qin Xiaoyi, et al. SIG-VC: a speaker information guided zero-shot voice conversion system for both human beings and machines[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2022: 6567-65571.
[13]Helander E E, Nurminen J. A novel method for prosody prediction in voice conversion[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2007: IV-509-IV-512.
[14]Wang Disong, Deng Liqun, Yeung Y, et al. VQMIVC: vector quantization and mutual information-based unsupervised speech representation disentanglement for one-shot voice conversion[EB/OL]. (2021-06-18). https://arxiv.org/abs/2106.10132.
[15]Qian Kaizhi, Zhang Yang, Chang Shiyu, et al. Unsupervised speech decomposition via triple information bottleneck[C]//Proc of International Conference on Machine Learning. 2020: 7836-7846.
[16]Qian Kaizhi, Zhang Yang, Chang Shiyu, et al. Global prosody style transfer without text transcriptions[C]//Proc of International Confe-rence on Machine Learning. 2021: 8650-8660.
[17]Chan Chakho, Qian Kaizhi, Zhang Yang, et al. SpeechSplit2.0: unsupervised speech disentanglement for voice conversion without tuning autoencoder bottlenecks[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2022: 6332-6336.
[18]Yang SiCheng, Tantrawenith M, Zhuang Haolin, et al. Speech representation disentanglement with adversarial mutual information learning for one-shot voice conversion[EB/OL]. (2022-08-18).https://arxiv.org/abs/2208.08757.
[19]Chen Liwei, Watanabe S, Rudnicky A. A unified one-shot prosody and speaker conversion system with self-supervised discrete speech units[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2023: 1-5.
[20]Karlapati S, Moinet A, Joly A, et al. Copycat: many-to-many fine-grained prosody transfer for neural text-to-speech[EB/OL]. (2020-04-30).https://arxiv.org/abs/2004.14617.
[21]Lei Yi, Yang Shan, Zhu Xinfa, et al. Cross-speaker emotion transfer through information perturbation in emotional speech synthesis[J]. IEEE Signal Processing Letters, 2022, 29: 1948-1952.
[22]Cheng Pengyu, Hao Weituo, Dai Shuyang, et al. Club: a contrastive log-ratio upper bound of mutual information[C]//Proc of Internatio-nal Conference on Machine Learning. 2020: 1779-1788.
[23]Choi H S, Lee J, Kim W, et al. Neural analysis and synthesis: reconstructing speech from self-supervised representations[J]. Advances in Neural Information Processing Systems, 2021, 34: 16251-16265.
[24]Li Jingyi, Tu Weiping, Xiao Li. FreeVC: towards high-quality text-free one-shot voice conversion[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway,NJ:IEEE Press, 2023: 1-5.
[25]Lian Zheng, Zhong Rongxiu, Wen Zhengqi, et al. Towards fine-grained prosody control for voice conversion[C]//Proc of the 12th International Symposium on Chinese Spoken Language Processing. Piscataway,NJ:IEEE Press,PejjatBluc5NPh46k670lnyP26GxNmGdekdR918gAms= 2021: 1-5.
[26]Jadoul Y, Thompson B, De Boer B. Introducing Parselmouth: a Python interface to Praat[J]. Journal of Phonetics, 2018, 71: 1-15.
[27]Zavalishin V. The art of VA filter design[M]. Berlin: Native Instruments, 2012.
[28]Yamagishi J, Veaux C, MacDonald K. CSTR VCTK corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92)[D]. Edinburgh: University of Edinburgh, 2019: 271-350.
[29]Van Den Oord A, Dieleman S, Zen H, et al. WaveNet: a generative model for raw audio[EB/OL]. (2016). https://arxiv.org/abs/1609. 03499.
[30]Li Chengda, Shi Jing, Zhang Wangyou, et al. ESPnet-SE: end-to-end speech enhancement and separation toolkit designed for ASR integration[C]//Proc of IEEE Spoken Language Technology Workshop. Piscataway,NJ:IEEE Press, 2021: 785-792.
