标签噪声下结合对比学习与邻域样本分析的故障诊断方法
2024-10-14金泽中叶春明







摘 要:当前基于深度学习的故障诊断方法依赖于标注完备的训练样本,当数据集中存在噪声标签时,模型会对噪声数据过拟合,影响泛化能力。为实现模型在采用标签噪声进行训练的情况下对设备运行工况的精确识别,提出一种结合对比学习与邻域样本分析的故障诊断方法。首先采用对比学习方法对模型进行预训练,拉近模型特征空间中的相似样本映射距离,实现判别能力增强;随后,基于特征相似度寻找每个样本最相似的近邻用以计算训练标签可靠性并据此执行样本划分以及标签纠正,构建更为可靠的训练子集;最后在训练过程中引入标签重加权以及一致性正则化操作增强模型鲁棒性。此外,通过同时训练两个网络模型以交替构建训练子集用于另一网络训练过程,缓解单网络模型训练框架易引起的认知偏差问题。在公共数据集上进行实验验证,结果表明所提方法能够有效识别并纠正噪声标签,在较高噪声标签情况下仍能保持良好的诊断性能。
关键词:对比学习;标签噪声;标签纠正;故障诊断
中图分类号:TH133.33 文献标志码:A 文章编号:1001-3695(2024)10-023-3044-09
doi:10.19734/j.issn.1001-3695.2024.02.0036
Fault diagnosis method via contrastive learning and neighborhood sample analysis under label noise
Jin Zezhong,Ye Chunming
(Business School,University of Shanghai for Science & Technology,Shanghai 200093,China)
Abstract:Nowadays due to the dependence of fault diagnosis method based on deep learning on well-labeled training dataset,which will lead to the problem that deep neural network can easily overfit those noisy labels and affect the generalization of network under the condition of label noise.In order to achieve accurate recognition of equipment operating conditions in the network trained with label noise,this paper proposed a fault diagnosis method via contrastive learning and neighborhood sample analysis.Firstly,the method used contrastive learning to pre-train the model,which could reduce the embedding distance of similar samples in the feature space and achieved improving the ability of optimizing the feature representation ability of the network.Then,the method utilized the feature similarity to find each sample’s closest neighbors to estimate the reliability of training labels which could separate all training samples into a clean or noisy subset and implemented label correction on noisy subset.After that,it established a more reliable training subset.Lastly,the proposed method made use of label reweighting and consistency regularization to enhance robustness of network.In particular,two networks got trained simultaneously where each network used the dataset division from the other network during the training process,which could mitigate confirmation bias caused by single network model training framework.The experimental results on public dataset demonstrate that proposed method can verify and correct the noisy labels impressively well and maintain great fault diagnosis performance under the condition of high-level noisy labels.
Key words:contrastive learning;noisy label;label correction;fault diagnosis
0 引言
轴承作为机械传动的关键零件,被广泛应用于各种机械设备中,其健康状况对于机械设备的安全性与稳定性具有重要影响[1]。然而设备在一些恶劣环境下运行时,轴承将会不可避免地发生退化,产生裂纹、磨损等。一旦发生故障将直接影响整个设备的正常运行,轻则给企业造成经济损失,重则引发事故,威胁生命安全[2,3]。因此,有必要对传动系统中的轴承展开系统性的故障诊断。
当前基于深度学习的故障诊断方法因能有效对故障信息进行表征而被广泛应用于故障诊断领域[4]。Zhang等人[5]提出一种基于通道-空间注意力机制与特征融合的深度残差故障诊断网络,诊断准确率可达99.87%。Xu等人[6]针对复杂环境下系统故障诊断中多尺度模型外推效率低的问题,提出权重软投票的多尺度决策加权融合模型,该模型能够有效地捕获采集多尺度的时间与频率信息,具有较为良好的泛化能力。然而,以上这些框架大多基于标签正确标注的前提,而忽略了存在标签噪声的情况。
在实际工业活动中,一方面由于部分故障特征微弱且处于不断发展的状态,使得故障模式与相应的故障表征信息映射关系模糊,导致故障模式标注工作困难;另一方面由于机械设备系统日趋复杂化,故障模式增多,在标注人员缺乏相关专业知识的情况下,易赋予故障模式错误的标签分类[7]。因而在真实的工业数据集中,标注错误即标签噪声问题是不可避免的。然而,当前大多数基于数据驱动的故障诊断方法依赖标注完备的数据集,当存在着标签噪声时,模型会因拟合于噪声标签数据而导致模型特征表达能力不足,即认知偏差问题,影响诊断精度。因此,研究一种对于噪声标签数据具有较好鲁棒性的故障诊断算法,能够有效减少人力、物力资源投入,缓解实际生产活动中故障信息分辨标注困难问题。
近年来,标签噪声学习方法引起广泛关注,当前故障诊断领域对于标签噪声问题的研究主要围绕构建鲁棒性损失函数以及元学习等方面展开。Wang等人[8]针对交叉熵损失函数易导致模型对噪声数据过拟合的现象,提出多级对抗损失函数,在训练初期采用广义交叉熵作为损失函数,防止模型迅速拟合噪声数据,随后引入逆交叉熵项以减少噪声样本梯度表示,有效地平衡了模型的鲁棒性与学习性。Liang等人[9]将双温逻辑损失函数引入故障诊断模型训练中,减少了噪声标签数据的负面影响。Zhang等人[10]通过引入加权网络并采用元学习方法构建样本标签分布以动态调整损失函数,避免模型过拟合于噪声数据。上述方法虽然在一定程度上能够减少标签噪声的负面影响,但仍存在诸多不足,例如采用鲁棒性损失函数易使得模型产生欠拟合现象,无法对故障信息进行有效表征;基于元学习的方法仍需正确标记的训练子集数据用于权值更新。
目前,基于噪声样本划分的方法引起广泛关注,其核心思想是依据噪声数据验证策略将原始训练样本数据集划分为正确标签样本组以及噪声标签样本组,随后将噪声标签样本组予以舍弃或参照半监督学习范式为其赋予伪标签以参与训练,避免模型在训练过程中记忆原始错误标签[11]。根据模型训练过程总是先学习真实标签样本,再对噪声标签样本进行暴力拟合,使得正确标注样本在训练早期阶段具有较小的损失,即损失较小的样本较有可能为正确标注样本的发现[12],Han等人[13]提出协同学习策略,即同时训练两个网络,在每个批量训练过程中,网络将损失值较小的样本视为可用样本,并且把这些样本送到对等网络中更新参数。两个网络具有不同的初始化参数与训练批次,因而具有不同的学习能力,能够有效筛选出噪声样本,减少在训练过程中产生的认知偏差问题。INCV[14]方法随机划分标签噪声数据以应用交叉验证计算每个样本损失,对具有较大损失的样本予以剔除。Li等人[15]提出Dividemix框架,采用高斯混合算法(Gaussian mixture model,GMM)对样本损失进行建模,将训练样本动态划分为具有正确标签样本组以及无标签的噪声样本组,然后以半监督学习的方法对模型进行训练。Wei等人[16]利用模型历史预测的波动情况以划分出噪声数据,并采用FixMatch[17]范式进行半监督学习训练。然而,上述方法在标签噪声率较高的情况下划分效果欠佳[18]。
对比学习[19]作为特征表示学习的一种,能够通过构建正负样本对以执行实例判别任务使得模型以无监督学习的方式使得模型获得良好特征表示,其特征学习过程能够有效避免标签噪声影响。Li等人[20]通过对比学习优化模型特征空间,并通过集成训练样本的邻域样本预测值逐步纠正错误标签。Tan等人[21]在噪声标签学习训练过程中引入对比学习框架以维持样本在特征空间映射中的结构相似性,避免模型过度拟合错误样本信息。Huang等人[22]根据对比学习损失动态划定样本置信度以执行噪声标签纠正。因此,如何利用对比学习所取得的良好特征表示优化噪声样本划分方法值得进一步探究。
据此,本文提出一种结合对比学习与邻域样本分析(CLNSA)的故障诊断方法以增强模型在噪声标签情况下的鲁棒性。首先通过对比学习对故障判别网络进行预训练,使得模型充分挖掘故障信号内在的判别信息,增强模型特征表达能力。随后参照文献[13]采用两个网络模型交替式训练的方式在特征空间中选取邻近样本进行邻域样本划分与纠正构建训练子集。并对得到的训练子集引入标签重加权以及一致性正则化以进一步增强模型鲁棒性。在帕德博恩大学以及凯斯西储大学轴承数据集中进行实证分析,结果表明本文CLNSA方法在较高噪声率情况下仍能保持良好的诊断精度。
1 问题描述及相关工作
1.1 问题描述
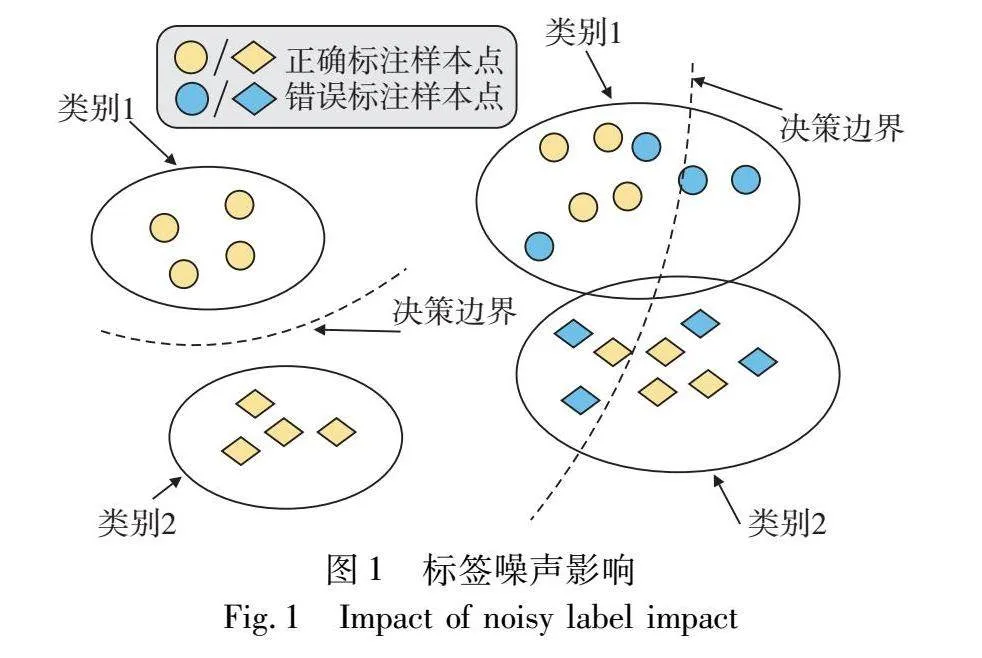
标签噪声问题[11]可以定义为在监督学习情况下,假设带噪数据集Dtrain={(x(i),y(i))}li=1,其中x(i)为其训练样本而y(i)∈y={1,…,C}为相应的噪声标签,C为其故障类别数,值得注意的是y(i)可能并不为x(i)的真实样本标签而具有被错误标记的可能,即噪声标签数据。故障诊断模型f由特征编码模块f(·)以及分类层c(·)组成,模型将轴承振动信号作为输入,并通过f(·)将其映射至高维特征空间,再经分类层c(·)解码,输出最后分类结果。如图1所示,在采用具有标签噪声数据集进行模型训练时易使得模型根据样本标注错误标签进行分类,构建错误决策边界。为此本文旨在设计对于噪声标签具有较高鲁棒性的学习算法训练模型,以避免噪声标签负面影响,实现对于待测故障信号的精确诊断。
1.2 相关工作
针对标签噪声问题,目前主流的标签噪声学习方法可以分为鲁棒性损失函数、噪声转移矩阵、正则化方法以及噪声样本划分[11]。由于分类任务中所常用的交叉熵损失函数非对称且无界,所以对于噪声标签较为敏感,鲁棒性损失函数旨在修正模型最小化风险损失,使得模型在噪声标签情况下的最小化风险与标注正确情况下一致,Ghosh等人[23]证明对称式损失函数具有较好的噪声鲁棒性,并由此设计平均绝对误差以及逆交叉熵损失,但模型在训练过程易产生欠拟合现象。Zhang等人[24]在此基础上将平均绝对误差与交叉熵损失结合,提出了广义交叉熵损失函数,提高了模型学习拟合速度。Ma等人[25]提出主动被动损失(active passive loss,APL),结合两个对称式损失函数,较好地平衡了模型学习能力与噪声鲁棒性。噪声转移矩阵方法通过模型预测或其特征表示构建各类别样本被错误标记的概率矩阵以探索噪声标签的分布,Zhu等人[26]通过执行相似表征匹配探索模型特征空间中邻近样本标签一致性概率以推测训练样本噪声转移矩阵,并据此修正模型训练过程中输出预测值。正则化方法通过分析深度学习模型在标签噪声情景下的学习特性并以隐式或显式的方法避免模型过度拟合噪声数据。MixUp[27]作为一种典型的隐式正则化方法,通过加权组合不同类别样本数据,在各类之间的决策边界中进行线性转换,使得模型趋向于学习结构化特征,限制其过拟合于非结构化标签噪声信息。LSR[28]通过标签平滑(label smoothing)引入收缩正则化,使得模型权重收敛于小范数解,避免产生过度自信现象。显式正则化方法通过修改模型训练损失函数,例如添加正则化项以根据模型训练状况动态调整梯度更新。Lu等人[29]根据模型早期学习的特点,设计注意力权重分支以表征模型对噪声数据以及正确标注样本学习情况,并将其作为正则化项引入损失函数,减少了噪声数据的梯度表示。Iscen等人[30]将高维特征嵌入空间中邻域样本特征相似性作为正则化项,减少了标签噪声的负面影响。基于噪声样本划分的方法由于能够划分出噪声样本,促使模型在学习过程中的训练样本趋向于真实分布,减少了标签噪声的影响。Arazo等人[31]采用贝塔混合模型(beta mixture model,BMM)对训练损失进行建模以划分正确标签样本组以及噪声样本组,并根据其划分结果赋予各样本组样本以不同置信度权重。Zhang等人[32]选取每个类别中模型输出置信度较高的样本视作标注正确训练集,随后采用K-means算法将置信样本划分为每类K个的训练子集,并获得其聚类中心的原型特征向量,对于待测样本根据特征空间中邻近原型特征向量投票结果划分其标签属性。Karim等人[33]通过衡量模型预测与标注标签的JS散度动态划分训练数据集。
2 本文方法描述
2.1 对比学习预训练
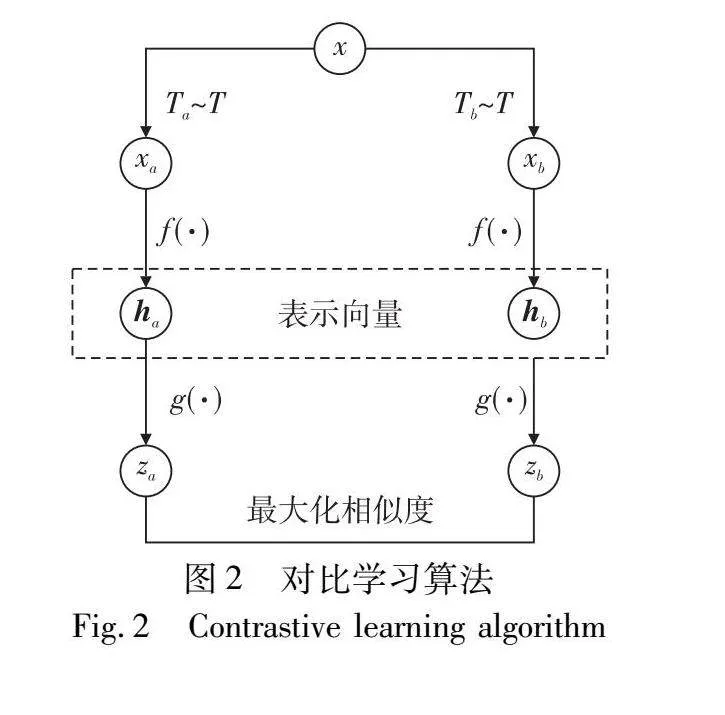
对比学习(contrastive learning,CL)[19]的提出,主要是为了解决基于监督学习的深度学习方法依赖于大量标注完备数据的问题。对比学习旨在构建映射函数,将输入信息映射至超球体空间,通过构建正负样本对以执行实例判别任务,拉近正样本对在超球体空间中的映射距离、推远负样本特征距离,优化特征空间以增强模型特征表达能力。SimCLR[34]作为一种经典对比学习算法,通过对样本进行组合数据增强,将同一样本经不同增强方式进行数据增强后的样本作为正对,并最大化其互信息,不断减小相似样本度量距离,实现同类样本特征表示相似,不同类特征表示互异。算法流程如图2所示。当前对比学习因其强大的特征提取能力而被广泛应用于噪声标签学习领域。
在对比学习训练过程中,首先随机抽样N批次大小的故障信号样本{x(i)}Ni=1,i∈{1,2,…,N},对于批次中每个样本实行两种不同数据增强方法Ta,Tb~T以获得其相关实例{x(1)a,…,x(N)a,x(1)b,…,x(N)b}。对于其中一个样本x(i)a,可以与其余2N-1个样本组成样本对,其中(x(i)a,x(i)b)为正样本对,相较于余下的2N-2样本为负样本。随后将其引入特征编码模块f(·)提取特征表示,对于得到相应表示向量:h(i)a=f(x(i)a),随后参照文献[34]通过引入投影层g(·)将特征h映射至单位超球体空间,以获取其表示向量z(i)a=g(h(i)a),并在单位超球体向量空间中采用余弦相似度以衡量各表示向量相似程度:
sim(z(i)a,z(j)b)=(z(i)a)T(z(j)b)z(i)az(j)b(1)
随后采用InfoNCE作为损失函数:
lai=-logexp(sim(z(i)a,z(i)b)/τ)∑Nj=1[[j≠i]exp(sim(z(i)a,z(j)a)/τ)+exp(sim(z(i)a,z(j)b)/τ)](2)
lbi=-logexp(sim(z(i)a,z(i)b)/τ)∑Nj=1[[j≠i]exp(sim(z(i)b,z(j)b)/τ)+exp(sim(z(i)a,z(j)b)/τ)](3)
其中:τ为对比学习温度系数;[j≠i]为指示函数。为了识别整个数据集中的所有正对,以获得更多实例之间的关系,在每个增强样本上计算实例级对比损失:
Lc=12N∑Ni=1(lai+lbi)(4)
在完成对比学习预训练后,能够有效拉近同类健康状态样本在特征空间中的嵌入距离,增强模型特征判别能力,随后将训练好特征提取网络f(·)嵌入到2.2节中,为后续邻域样本分析算法提供更为良好的初始化特征表示。
2.2 邻域样本分析算法
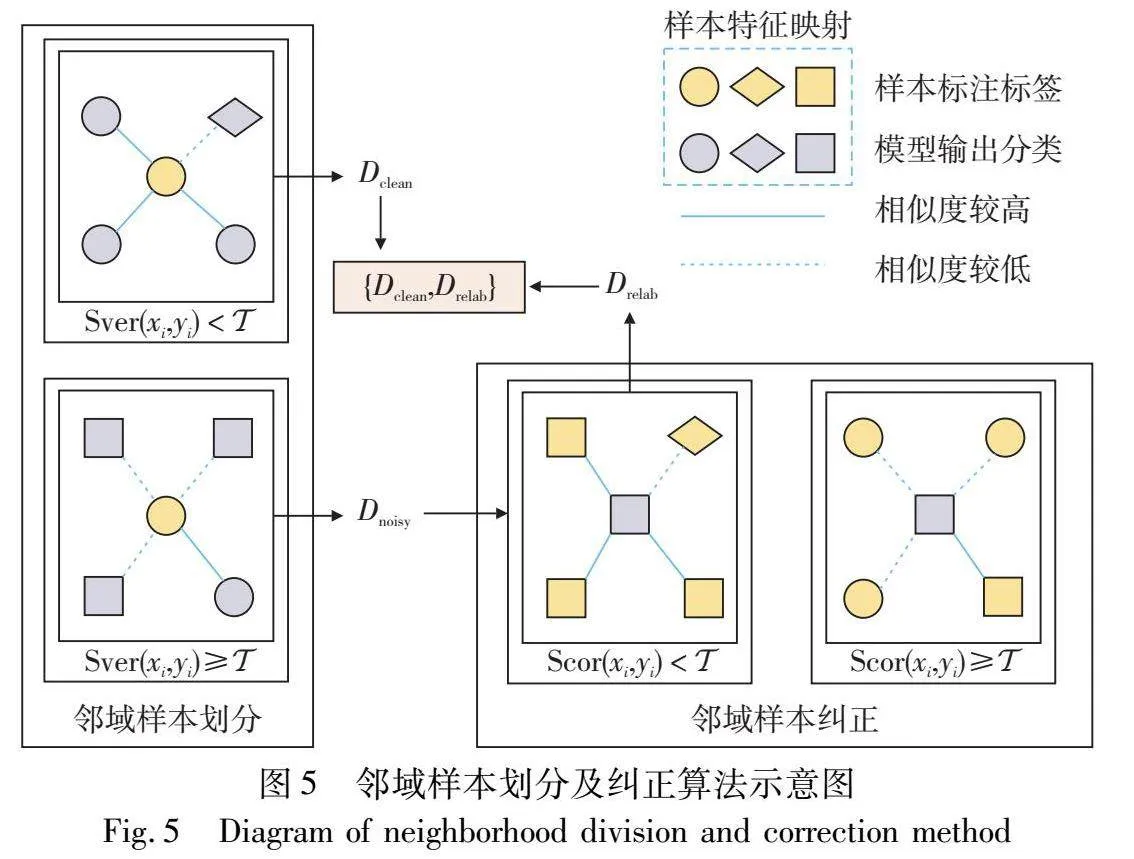
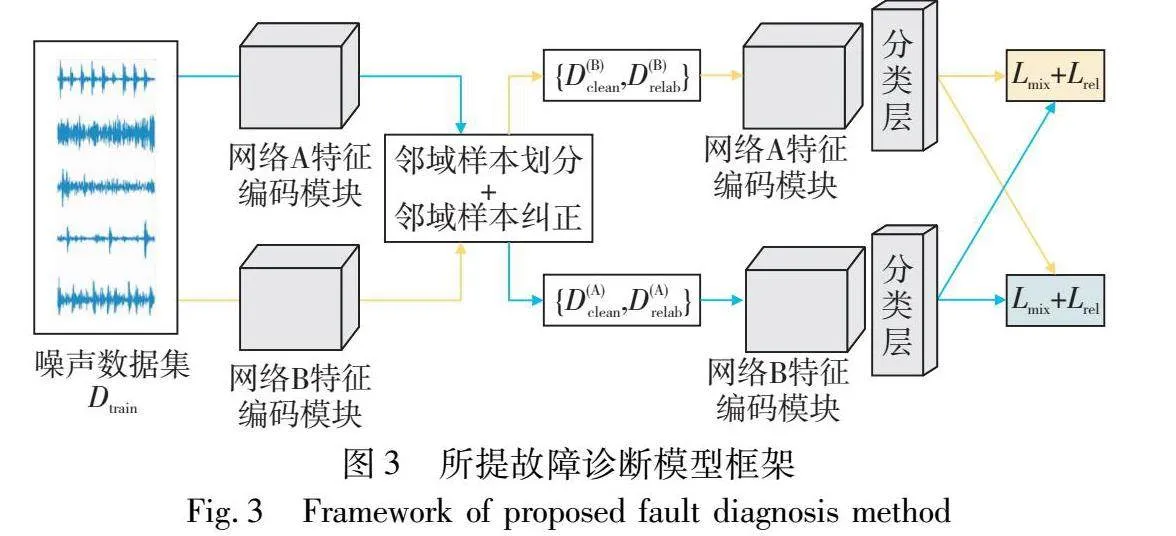
针对实际机械设备系统检测数据集中存在着标签误标记的问题,提出一种邻域样本分析算法,参照文献[13],本文通过引入两个相同结构网络模型fA、 fB并同时执行标签噪声训练以避免模型记忆错误样本的认知偏差问题。如图3所示,所提方法训练过程包括邻域样本划分、邻域样本纠正和鲁棒性训练三个阶段。
2.2.1 邻域样本划分
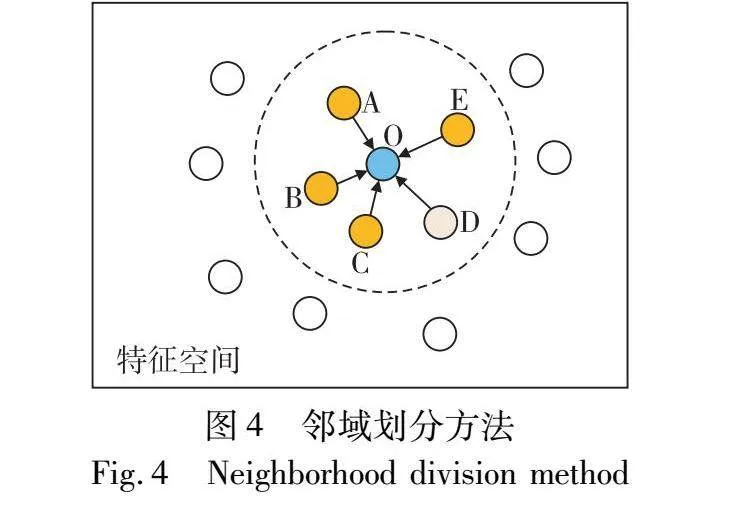
在模型经对比学习进行预训练后,能够有效使得同类样本在特征空间内聚集,为充分利用模型特征信息以执行样本划分,本文参照文献[35,36]通过衡量特征空间中邻近样本预测与其标签分布不一致特性以判断样本标签可信度执行样本划分。以图4为例,O为待测样本,虚线框内其他样本为其最近邻样本A~E,其在特征空间中彼此接近。不同的颜色表示不同的标签(模型预测标签或标注标签),考虑到同类样本在特征空间内的映射距离更为接近,因而对于待测样本O,若其标注标签与邻域样本集预测标签差异较大,则该样本更有可能为噪声标签样本。
对于待测样本(x(c),y(c))∈Dtrain,本文根据余弦相似度在特征空间中搜寻其K个最近邻样本以构建邻域样本集。
{x(c)k},k=1,…,K←KNN(x(c);Dtrain;K)(5)
其中:KNN(x(c);Dtrain;K)表示通过挖掘待测样本x(c)k在Dtrain数据集中特征空间中K个最相似的样本构建邻域样本训练子集。
随后采用JS散度计算其样本标签不确定度:
J(pi,pj)=12KL(pi‖pi+pj2)+12KL(pj‖pi+pj2)(6)
Sver(x(c),y(c))=1K∑Kk=1J(py(y(c)),p(y|x(c)k))(7)
其中:KL(·‖·)表示KL散度,J(·,·)为JS散度,用于衡量两个概率分布的相似性,其取值为0~1,J(pi,pj)→0表示pi与pj较为相似,而当J(pi,pj)→1则表示两个样本分布差异较大;py(y(c))为待测样本的标注标签的独热编码;p(y|x(c)k)表示模型fA或fB对于所构建邻域样本集第k个邻域样本输出的分类概率分布。通过集成多个邻近样本与待测样本的标签不确定度进行样本划分能够有效避免因过度依赖单个样本预测而引起的认知偏差问题。
在计算每个待测样本的样本标签不确定度后,若待测样本的训练标签与其邻域样本的模型预测值差异度较高(Sver(x(c),y(c))→1),则该待测样本较为可能为标签噪声样本。因此,本文通过设置筛选阈值,即当Sver(x(c),y(c))≥Euclid Math OneTAp时,将候选样本x(c)划分为噪声样本,否则将其归类为标注正确样本。可据此可将样本划分为
Dclean←{(xi,yi)|Sver(xi,yi)<Euclid Math OneTAp,(xi,yi)∈Dtrain}Dnoisy←{(xi,yi)|Sver(xi,yi)≥Euclid Math OneTAp,(xi,yi)∈Dtrain}(8)
值得注意的是,若存在噪声样本被错误地分组于Dclean中,模型易逐渐过度拟合这些错误标记的样本并错误拉近其在特征空间中的距离。为了克服这个问题,本文通过引入双网络协同学习方法,即两个网络框架模型fA和fB,并同时训练,一个网络由另一个网络所划分的样本数据进行训练以及参数更新[13]。由于两个具有不同的训练批次以及初始化参数,缓解单网络模型记忆错误标签样本的问题,避免认知偏差现象。
2.2.2 邻域样本纠正
在邻域样本划分阶段之后,本文对于被划分为Dnoisy中的样本标签予以舍弃,以防止模型过拟合于噪声样本数据,分别将Dclean和Dnoisy中的样本分别视为标记和未标记的样本。同时考虑到在较高标签噪声率情况下,仅采用原始噪声数据作为训练集时,虽能有效保证模型的鲁棒性,但由于可用的正确标注样本过少,无法有效地使得模型预测趋于样本真实分布。本文进一步设置了邻域样本纠正阶段以充分利用未标记的样本特征信息,该阶段依靠特征空间中邻近正确标记样本执行噪声标签数据纠正,以获取更为无偏的伪标签。
{(x(u)k,y(u)k)},k=1,…,K←KNN(x(u);Dclean;K)(9)
在邻域样本纠正过程中,首先对于每个待测样本x(u)∈Dnoisy,在训练子集Dclean中选取K个邻近样本(x(u)k,y(u)k)构建邻域样本数据集。随后,对于每个待测样本与其邻近样本之间执行以下标签一致性检验,以进一步挖掘在特征和标签结构空间中与其相邻样本相似的噪声标签样本:
Scor(x(u))=1K∑Kk=1J(p(y|x(u)),py(y(u)k))(10)
其中:J(p(y|x(u)),py(y(u)k))为模型fA或fB对于待测样本x(u)所输出概率分布与其邻域样本数据集中第k个邻近样本标注标签的独热编码的一致性。当Scor(x(u))趋近于1时表明待测样本的预测值与其邻近样本的差异性较大,即该待测样本可能位于模型的决策边界附近,易被赋予错误样本标签。为进一步提升所构建训练子集伪标签准确率,本文通过引入纠正阈值Euclid Math OneTApr,即对于满足Scor(x(u))≥Euclid Math OneTApr的样本予以剔除,而对于满足Scor(x(u))<Euclid Math OneTApr的待测样本更有可能远离决策边界,并且可以从其邻近样本推导出更为可靠的伪标签。在此基础上,本文对于满足Scor(x(u))<Euclid Math OneTApr的待测样本执行以下标签纠正操作:
(u)=argmaxc∑Kk=1w(x(u);k)×py(y(u)k)(11)
其中:(u)表示为待测样本x(u)经邻域样本纠正后的标签,并采用w(x(u);k)=1-J(p(y|x(u)),py(y(u)k))以表示第k个邻近样本标签可靠性。基于以上筛选标准,可得以下重标记训练子集:
Drelab←{(xi,i)|Scor(xi)<Euclid Math OneTApr,xi∈Dnoisy}(12)
值得注意的是,与邻域样本划分过程相同,在邻域样本纠正过程中,本文同样采用双网络协同学习方法,将一个网络模型所划分样本交予另一模型进行训练以及参数更新以避免认知偏差问题。邻域样本划分及纠正算法如图5所示。
2.2.3 鲁棒性训练
在经过邻域样本划分以及邻域样本纠正后,可得训练子集Dclean以及Drelab,为进一步增强模型鲁棒性,本文参照文献[36]分别对Dclean以及Drelab执行标签重加权以及一致性正则化以减轻训练过程中误标记对模型产生的负面影响。
对于训练子集Dclean中的数据,本文首先对其执行以下标签细化操作:
=(1-Sver(x,y))py(y)+Sver(x,y)py(y|x)(13)
其中:py(y)表示为标签的独热编码,(1-Sver(x,y))为另一网络模型所输出的标签可靠性,减少因错误划分样本而引起的负面影响。
随后对其进行锐化操作以降低其熵:
y=Sharpen(,T)=c1T/∑Cc=1c1T c=1,…,C(14)
其中:T为温度系数。
最后采用MixUp[27]方法加权组合不同类别样本数据,构建更为平滑的决策边界,限制模型过拟合于非结构化噪声标签,在Dclean同一训练批次量为B的批次中,随机选取训练样本xi、xj以及相应经细化和锐化操作的训练标签yi、yj,对其进行权值为λ的加权组合:
=λxi+(1-λ)xj,=λyi+(1-λ)yj(15)
其中:参数λ服从Beta分布:λ~Beta(α),α为其标量参数。其加权训练样本及其加权标签损失函数为
Lmix=-∑Bb=1blogp(y|b)(16)
对于训练子集Drelab,本文通过对其引入一致性正则化即对输入样本施行数据增强并迫使模型输出相同目标分类值,实现判别能力增强,以避免模型产生过度拟合于噪声标签数据[37],进一步提升模型鲁棒性:
Lrel=∑B′b′=1py(yb′)logp(y|Aug(xb′))(17)
其中:B′为训练批量大小;Aug(·)表示对样本进行数据增强操作。
总体训练目标为最小化以下综合损失:
L=Lmix+Lrel(18)
对于测试样本数据xtest,模型对其输出预测test为fA以及fB的集成预测值:
test=12(fA(xtest)+fB(xtest))(19)
所提邻域样本分析算法如算法1所示。
算法1 邻域样本分析算法
输入:训练集故障诊断模型fA以及fB;总训练轮次Ttr;模型采用交叉熵损失函数预热轮次Twu。
输出:训练完备模型fA以及fB。
a)while t<Ttr do
b) if t<Twu
c) fA,fB=WarmUp(CE,fA,fB) /*采用交叉熵损失对模型进行预热训练*/
d) else
e) 采用fB执行式(8)邻域样本划分与式(12)邻域样本纠正划分fA的训练子集{D(A)clean,D(A)relab}
f) 采用fA执行式(8)邻域样本划分与式(12)邻域样本纠正划分fB的训练子集{D(B)clean,D(B)relab}
g) for k in A,B do
h) 对于训练子集D(k)clean,采用式(15)获取其加权样本以及加权标签
i) 对于训练子集D(k)relab,获取其数据增强样本Aug(x)
j) L(k)=Lmix+Lrel
k) end for
l) L=12(L(A)+L(B))
m) fA,fB=SGD(L,fA,fB)//采用随机梯度下降更新模型参数
n)end while
3 实验验证
本文在公共数据集上对所提CLNSA方法进行验证以进一步证明方法有效性。首先对数据集进行系统性介绍,然后提供模型框架及其相关参数设置,最后阐述了本文算法与其他方法的比较实验结果,并开展消融实验以验证所提不同模块有效性。
3.1 实验数据集介绍
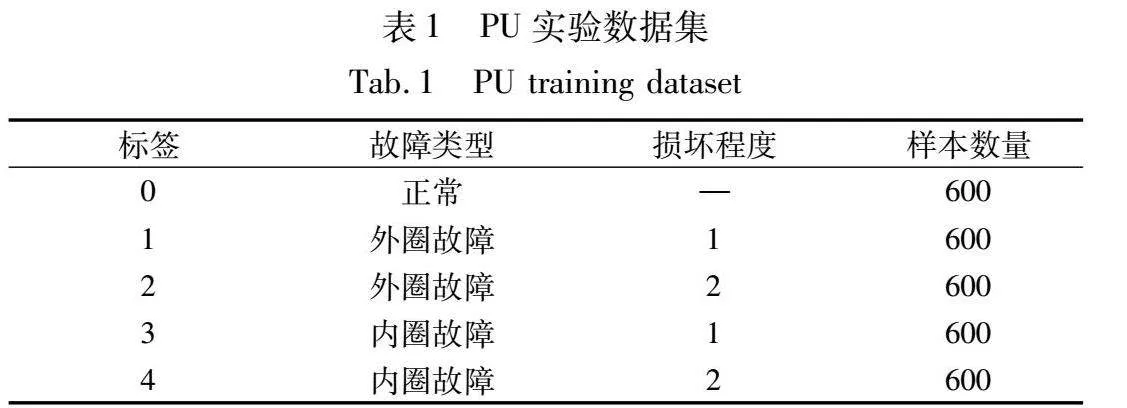
a)德国帕德博恩大学(Paderborn University,PU)轴承数据集,其实验台主要由轴承测试模块、扭矩测量轴以及电机组成。实验轴承为6203型球轴,采样频率为64 kHz。根据轴承故障位置及损坏尺度可将其划分为如表1所示的5类健康状态。
b)凯斯西储大学(Case Western Reserve University,CWRU)轴承数据集,实验台主要由电机、扭矩传感器以及控制电子设备组成。轴承型号为深沟球轴承SKF6205,采样频率为12 kHz。实验中通过电火花加工技术模拟常见轴承故障类型,每种故障类型的损伤直径分别为0.18 mm、0.36 mm、0.54 mm三种尺寸,此外包括正常运行状态的轴承振动信号,如表2所示共计10种健康状态,每类状态训练样本数为100。
表2 CWRU实验数据集
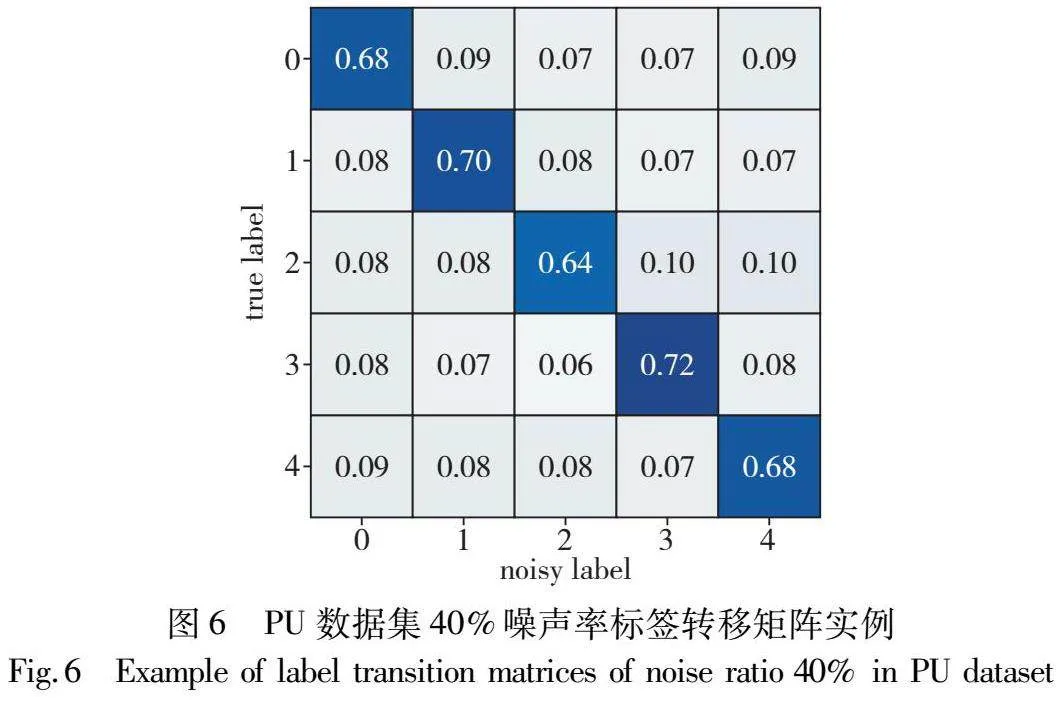
参照文献[7]对训练数据集标签进行随机翻转以引入标签噪声。图6为PU数据集40%噪声率情况下的标签转移矩阵。
(i)=y(i)→(i)with probability 1-ηy(i)→(j)j∈C,j≠i,with probability η/(C-1)(20)
其中:η为噪声率;C为样本类别数。
3.2 模型参数设置
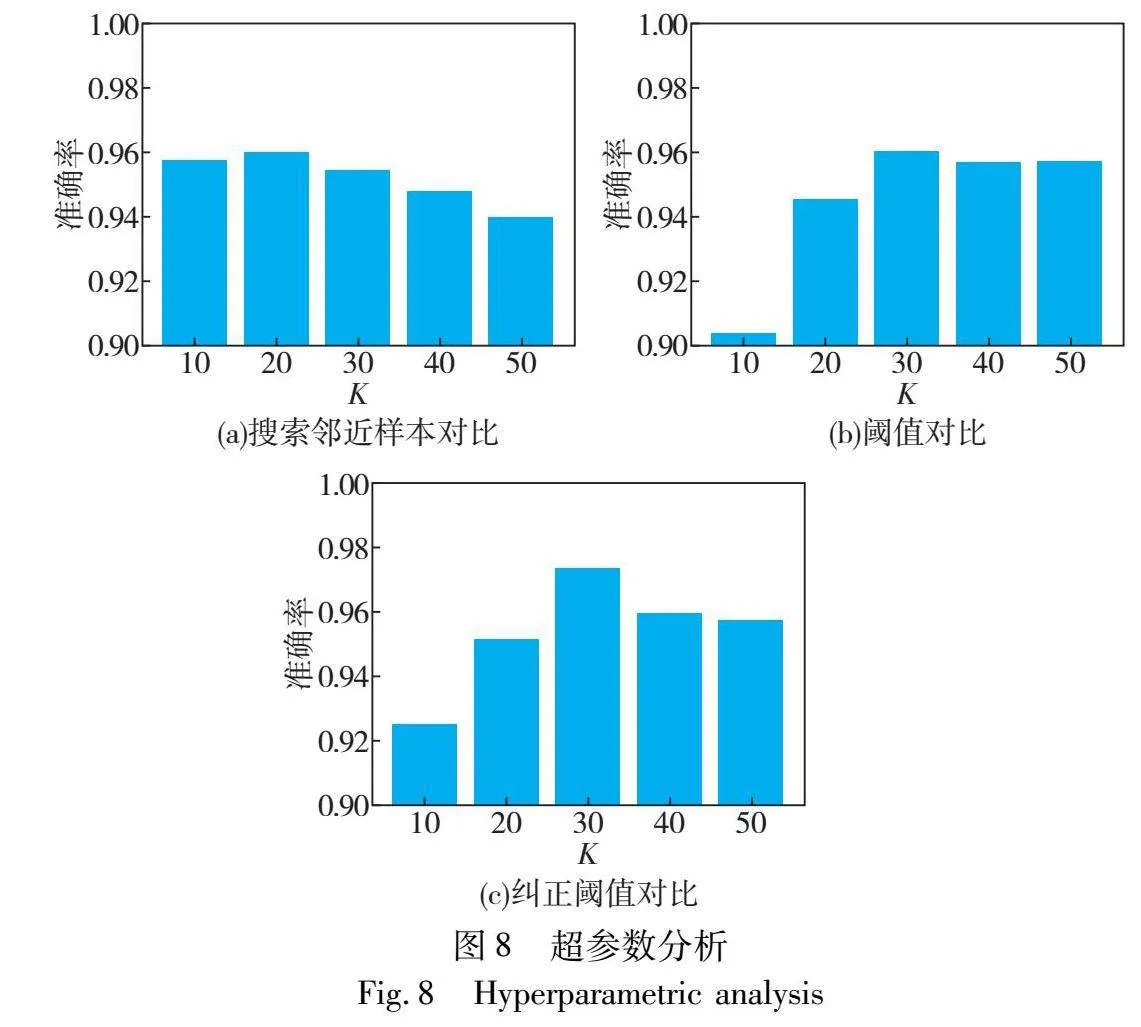
本文所提故障诊断特征提取网络由一维残差神经网络[38]构成,模型结构如图7(a)所示,投影层由两层全连接层构成,隐藏层维度为512维,输出128维低维嵌入向量。同时为更好地提取故障信号中的时域信息,本文采用经Z-score归一化的一维振动信号作为模型输入。模型对比学习预训练过程中所用优化器为Adam优化算法,学习率设置为0.02,对比温度参数设置为0.2,迭代轮次为200。并选取序列转置、加入高斯噪声、信号放缩、随机信号置零作为增强方式,数据增强效果如图7(b)所示。在对比学习预训练结束后,将获得的特征提取主干网络引入邻域样本分析任务中。模型首先采用交叉熵损失函数进行预热(warm up)10轮后执行邻域样本分析算法。为使故障诊断模型效果达到最佳诊断精度,本文在CWRU数据集中80%噪声率下对3个关键超参数进行对比实验,获得了其在设置不同搜索邻近样本数量K、阈值Euclid Math OneTAp以及纠正阈值Euclid Math OneTApr下的诊断精度,结果如图8所示。最终确定搜索邻近样本数量K为20,阈值Euclid Math OneTAp以及纠正阈值Euclid Math OneTApr分别设置为0.7和0.01。标签重加权过程中温度系数Euclid Math OneTAp设置为0.5,标量参数α设置为4,PU数据集中迭代轮次设置为50,CWRU数据集迭代轮次设置为150。
3.3 实验结果与分析
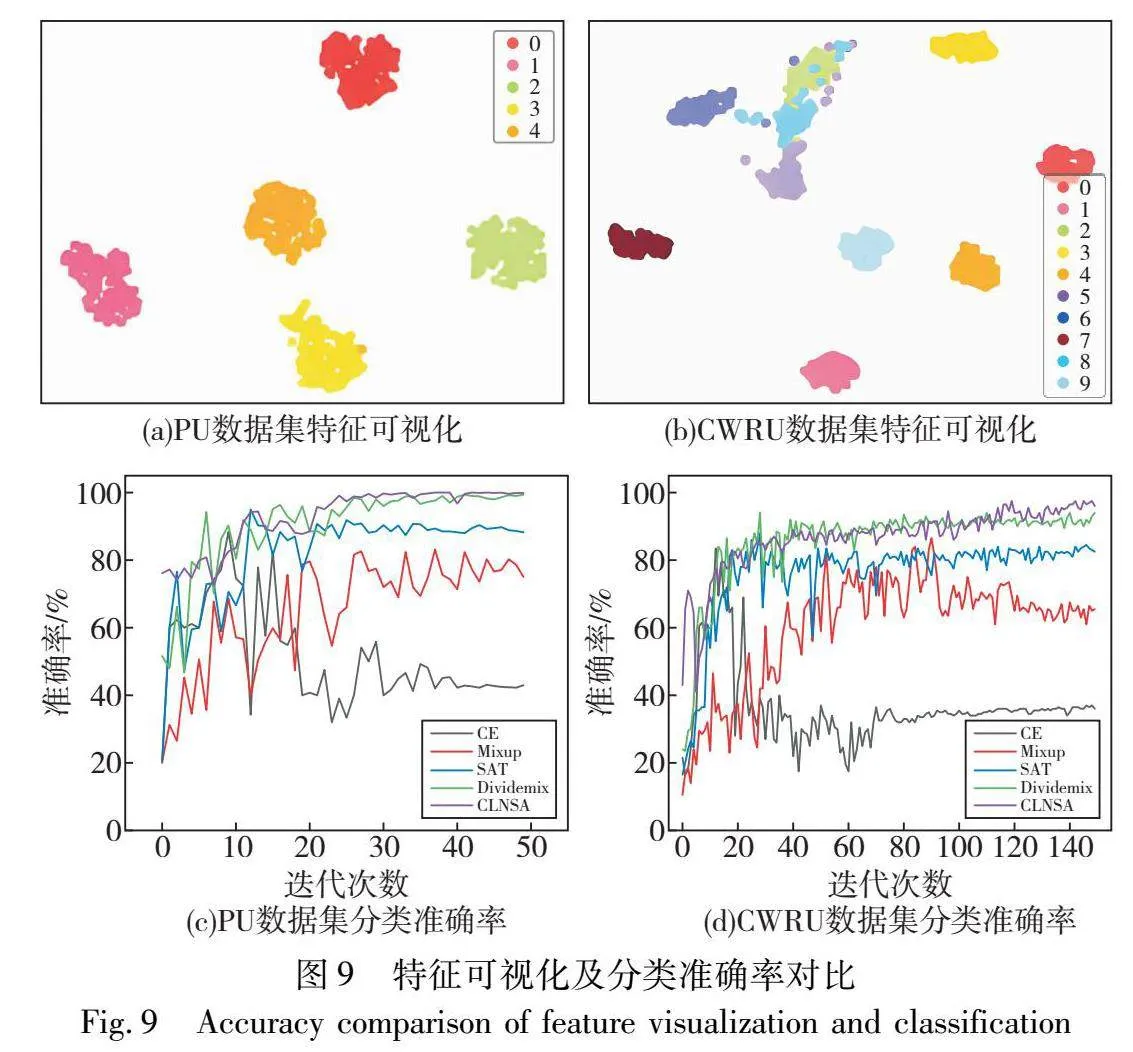
本文将采用交叉熵损失(cross entropy,CE)训练模型的方法作为基准故障诊断方法,并选取APL[25]、Coteaching+[39]、MixUp[27]、SAT[40]、NAL[29]、DivideMix[15]作为对比方法,在四种标签噪声率下进行故障诊断实验,实验结果如表3所示,经对比学习预训练后的特征t-SNE可视化图如图9(a)(b)所示,80%k73fL7ekVYYQ9VEnWMjLbA==噪声率情况下各方法分类准确率对比图如图9(c)(d)所示。
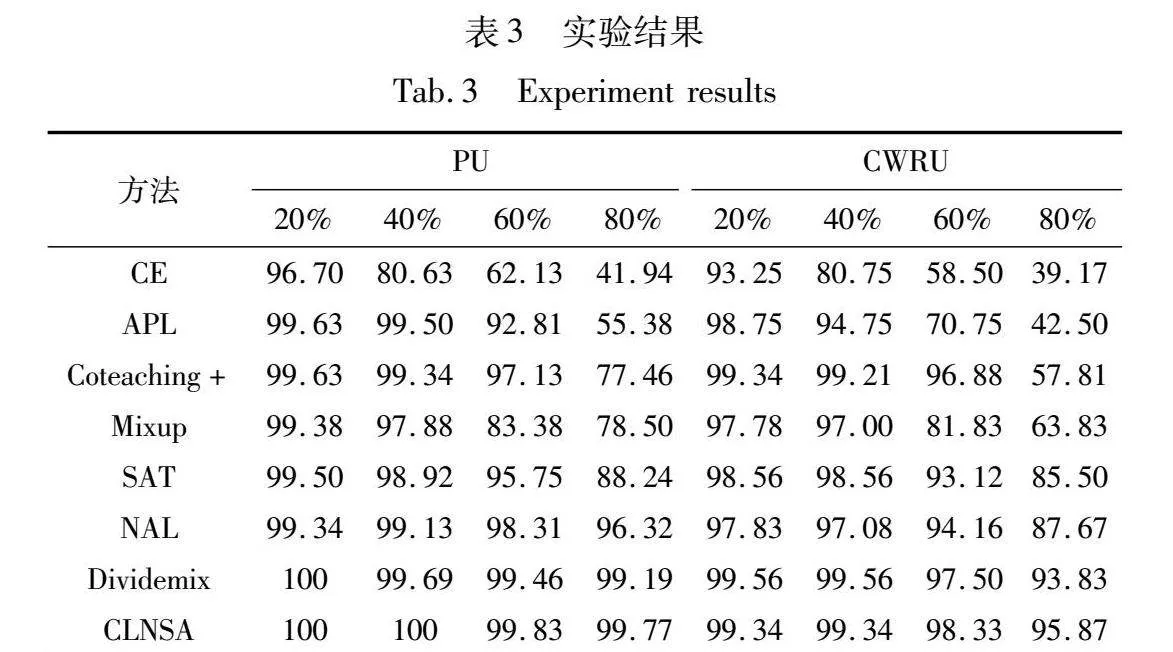
仅采用交叉熵进行模型训练的方法易因过拟合于噪声数据而使得诊断精度急速下降,进一步说明传统的深度学习方法对于标签噪声数据鲁棒性较差。而APL通过采用鲁棒性损失函数增强了模型在较低噪声率情形下的诊断精度,然而在较高噪声率情况下仍易产生欠拟合现象,无法有效表征故障信息。MixUp通过加权组合不同类别样本数据,在各类数据之间的决策边界中进行线性转换,使得模型趋向于学习结构化特征,限制其过拟合于非结构化标签,有效增强模型对于标签噪声的鲁棒性。通过小损失准则进行样本筛选,Coteaching+在低中等噪声率情形下实现了良好的诊断结果。然而,随着噪声率的增加,训练数据的丢弃比例以及识别噪声样本难度随之提高,使其在一些高噪声情况下表现不佳,在PU以及CWRU数据集中80%噪声率情况下故障诊断精度仅为77.46%以及57.81%。SAT通过分析模型早期学习特性,通过集成模型预测以纠正训练样本标签,防止模型过度拟合原始噪声标签,在各噪声率情况下均取得了良好的效果。NAL通过分析模型对于噪声样本早期训练状况,引入注意力权重分支以表征模型对噪声数据以及正确标注样本学习情况,并将其输出注意力权重值作为正则化项引入损失函数,减少了噪声数据的梯度表示。DivideMix通过高斯混合算法分离噪声样本,并采用MixMatch算法增强其对噪声样本鲁棒性,在各种噪声率情况下均能取得良好的诊断精度。本文CLNSA方法采用对比学习预训练增强模型特征表示,能够基本实现同类样本在特征空间的聚集,并采用双网络协同学习策略,有效减缓了模型认知偏差问题,在此基础上结合邻域样本分析算法以及鲁棒性学习策略充分利用样本特征空间信息以构建完备标签空间映射关系,在各噪声率下均能达到最优诊断精度。
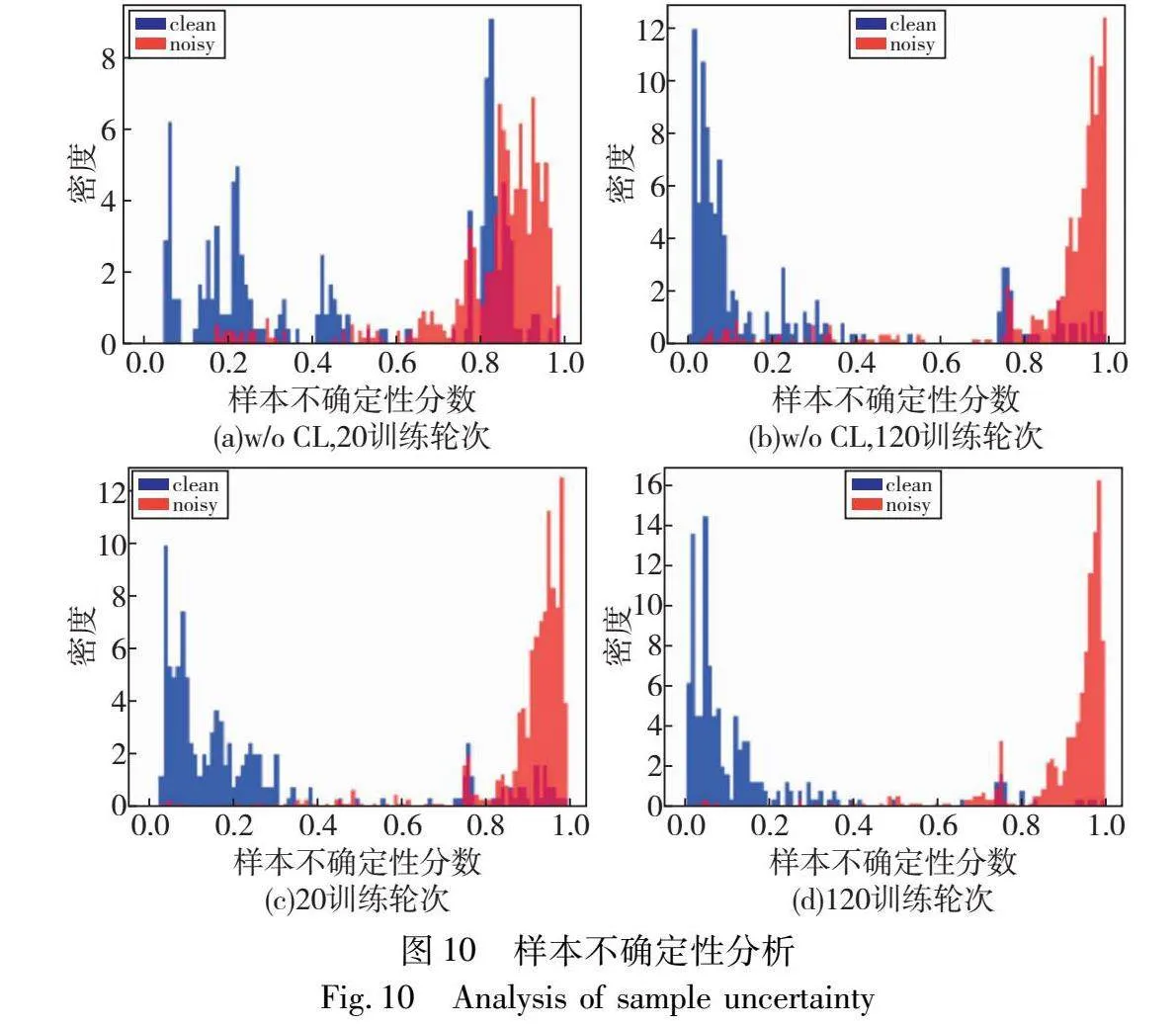
为进一步证明本文CLNSA方法划分标签噪声的有效性,采用式(8)对CWRU数据集80%噪声率情况下训练轮次为20,以及120情况下样本标签不确定性进行分析,如图10所示,clean代表标注正确样本,noisy代表标注错误样本,图(a)(b)为不采用对比学习预训练的本文方法,图(c)(d)为本文方法,可知所提邻域样本划分方法能够较好地识别噪声样本,并给予其较大的样本不确定性,从而有效地划分噪声样本以及正确标注样本。同时,在模型经过对比学习预训练后,能够有效提升模型划分噪声样本的能力,减少了其错误拟合于噪声样本的可能,进一步增强模型噪声鲁棒性。
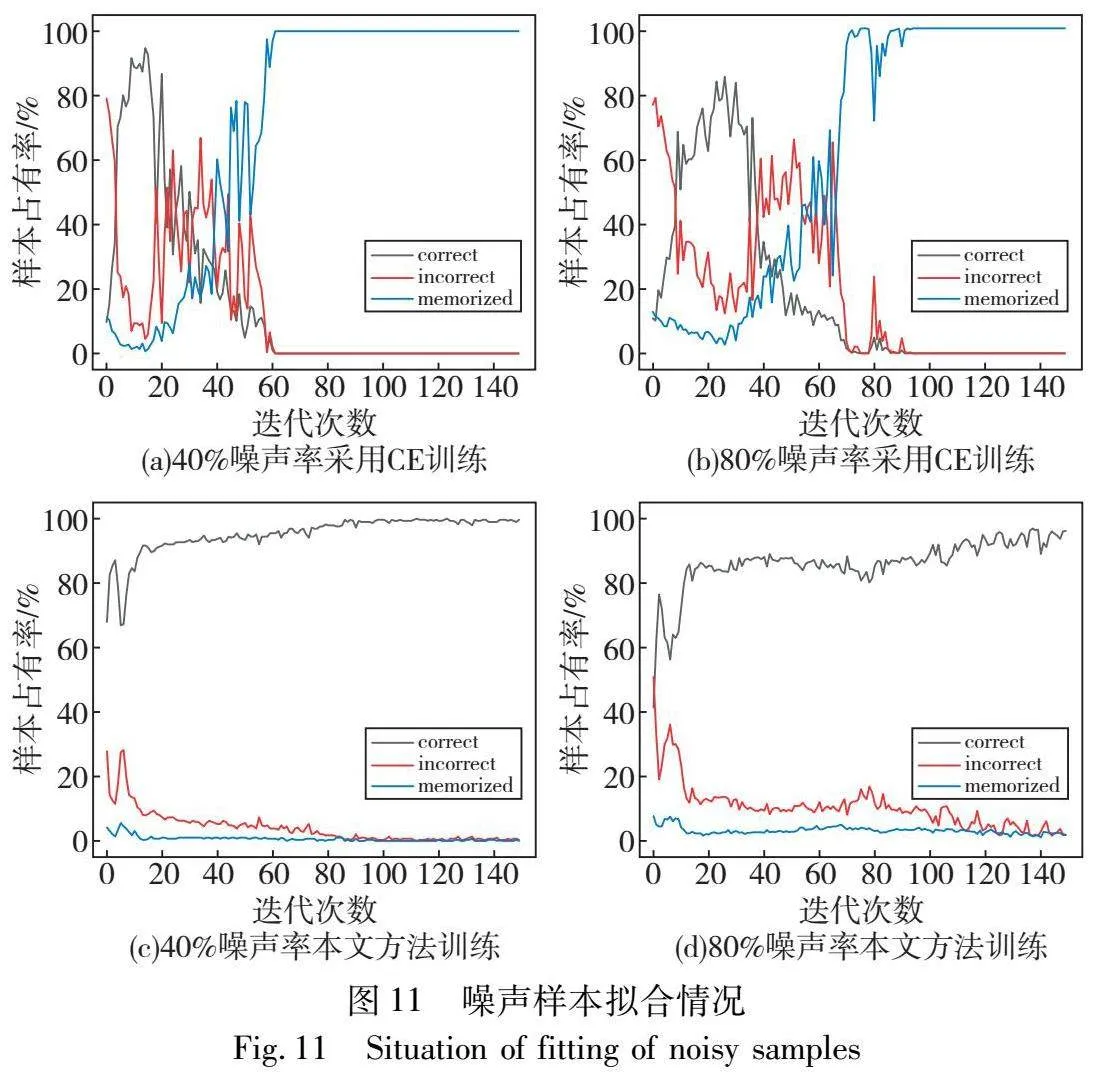
为进一步探究本文所提CLNSA方法在标签噪声情况下的鲁棒性,参照文献[29,41],对标签噪声下模型对训练样本拟合过程进行分析,如图11所示,图(a)(b)为CWRU数据集在40%以及80%噪声率下采用交叉熵损失函数训练所得各参数示意图,其中correct代表模型对于标注错误样本输出正确预测值的样本个数占总标注错误样本的比例,memorized代表模型输出与标注错误样本标签一致的比例,incorrect代表模型输出预测既与样本实际标签不一致,也与错误标注标签不一致的比例。可知采用交叉熵进行模型训练的方法在早期训练阶段会首先学习正确标注样本,而对错误标注样本输出正确预测值,但随着训练轮次的增加,模型会因标签噪声影响使得特征表示受损,习得特征表述逐步偏离真实特征分布,并最终完全拟合于噪声样本分布,使得分类精度不佳。图(c)(d)为采用CLNSA进行训练的噪声数据拟合状况,可知本文方法受标签噪声样本影响较小,具有较为良好的标签噪声鲁棒性。这可能是由于本文方法开始逐步拟合于噪声样本前执行邻域样本划分以及邻域样本纠正方法,分离噪声样本,减少模型记忆错误样本数量,缓解了噪声样本对模型特征表示训练的负面影响,使得模型训练样本趋向于样本真实分布,缓解了模型认知偏差问题,具有较好的鲁棒性。
3.4 消融实验
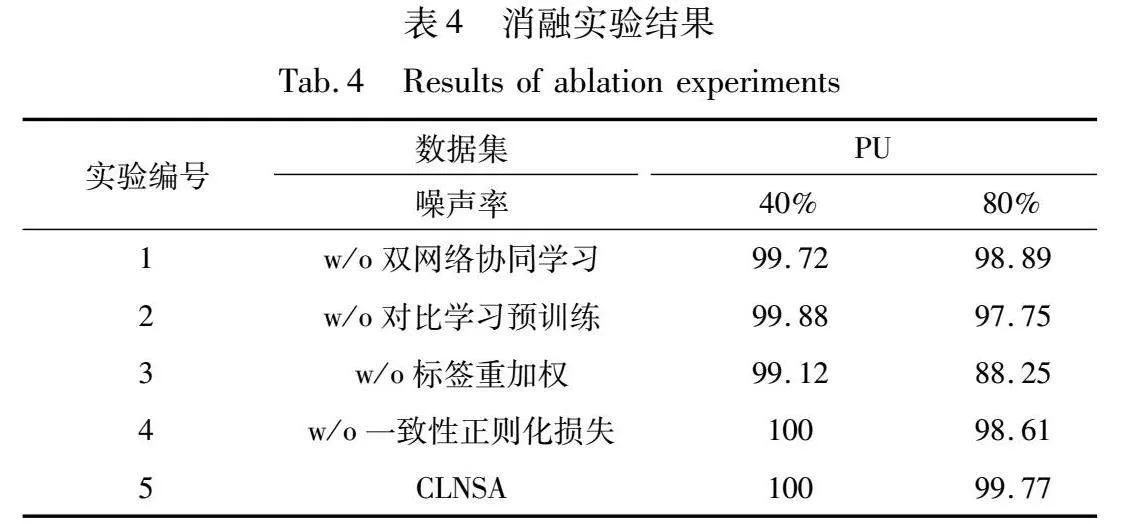
为进一步验证本文所提模块:双网络协同学习、对比学习预训练、标签重加权以及一致性正则化,通过设计以下五组对比实验以探究各模块效果,消融实验结果如表4所示,w/o代表移除该模块。
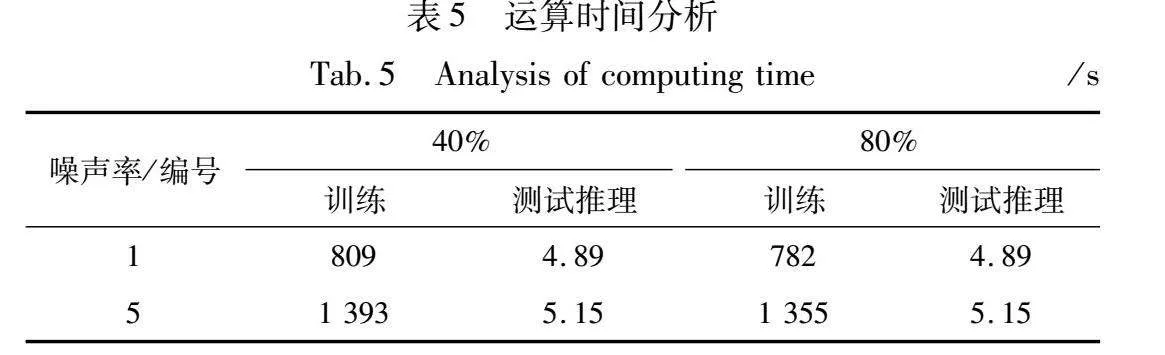
a)双网络协同学习策略。采用单网络训练框架架构在训练过程中易受错误样本划分及伪标签纠正影响,通过双网络协同学习策略,能够有效减轻模型认知偏差问题,分别在40%以及80%噪声率情况下提高0.28%以及0.88%的诊断精度。考虑到采用双网络协同学习需要同时训练两个网络,会带来额外的运算成本,本文对模型运行时间以及测试推理时间进行进一步分析,如表5所示。可知虽然采用协同学习策略使得模型训练时间增长,但在测试推理环节,所用时间相差无几,且采用协同学习方法能够实现更为可靠的故障诊断,能够达成较为迅速且准确的故障推理。
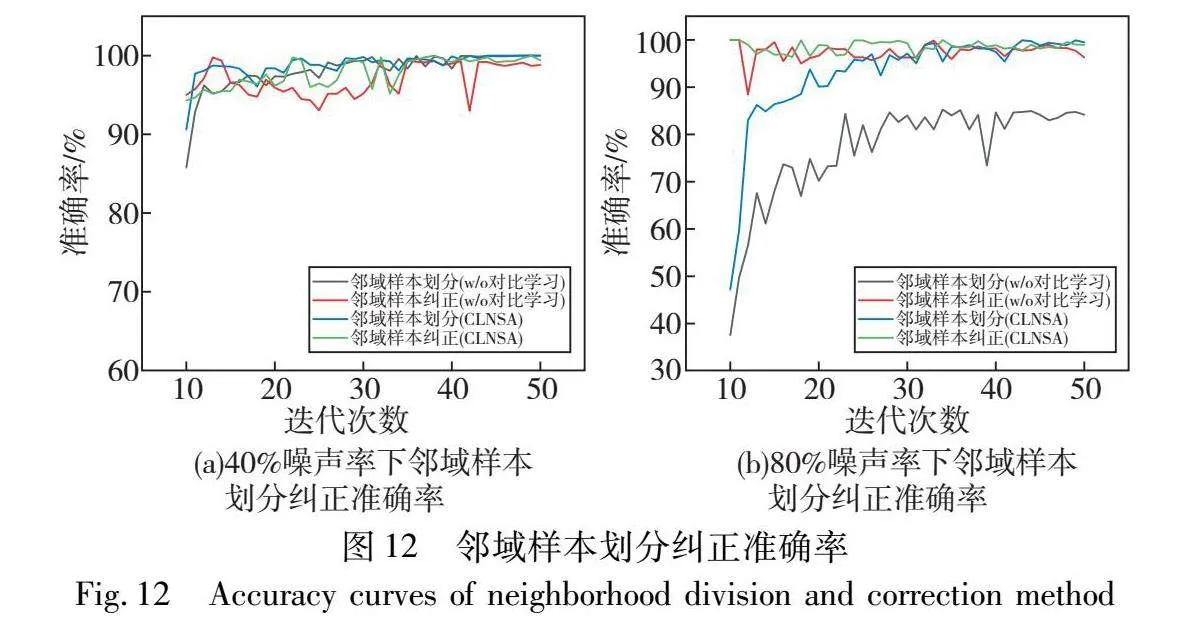
b)对比学习预训练。在经对比学习进行预训练后模型在各噪声率水平情况下故障诊断精度均有提升,邻域样本划分及纠正准确率如图12所示,在引入对比学习预训练过程后,能够减少错误样本划分,使得模型训练样本趋向于真实分布,进一步提高模型从噪声数据集中的学习故障信息的能力和稳定性。
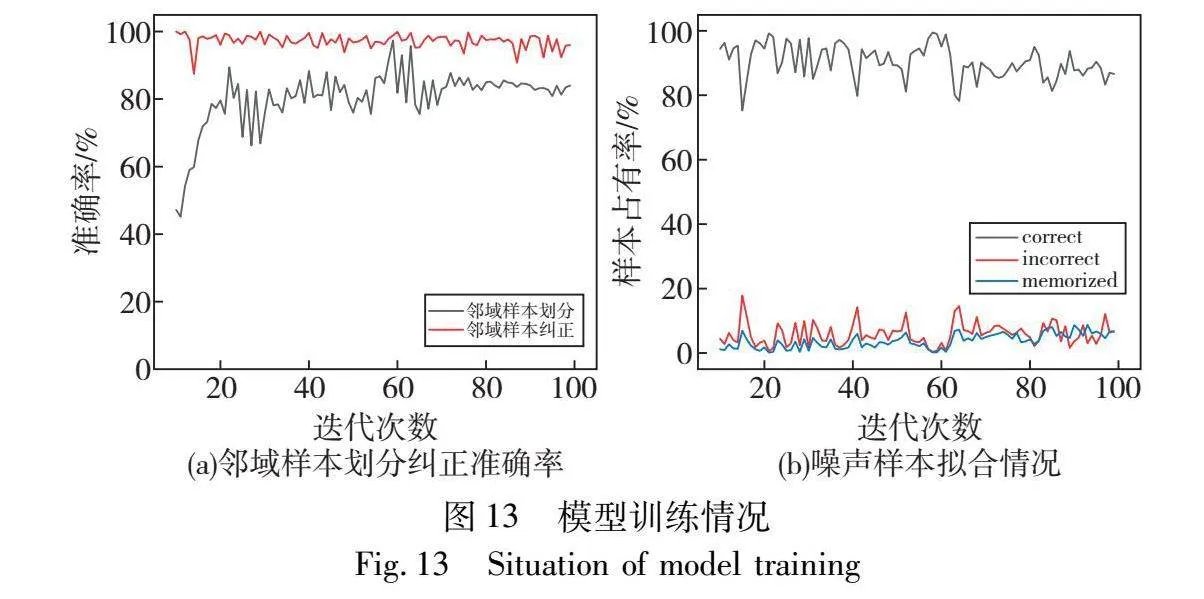
c)标签重加权。为进一步验证标签重加权方法的有效性,对80%噪声率下的邻域样本划分和纠正准确率以及模型训练样本拟合情况进行分析,如图13所示。可知模型在训练初期无法较好地拟合样本分布,易导致大量数据被错误划分,仅采用交叉熵损失进行训练易使得模型逐渐拟合于噪声样本数据,并逐渐损害模型特征表示,而通过引入标签重加权机制能够有效结合标签不确定性并采用MixUp正则化方法对于所构建划分样本子集鲁棒性,减少模型因错误划分样本而引起的梯度表示。分别在40%以及80%噪声率情况下提高模型0.88%以及11.52%的诊断精度。
d)一致性正则化。在邻域样本纠正过程中,仍有部分样本会被赋予错误标记样本,通过引入一致性正则化能够有效使得模型趋向于学习结构化特征,进一步提升模型泛化能力。
4 结束语
针对实际故障数据集中因人工误标而引起的标签噪声,导致模型特征表达能力减弱,诊断精度下降的问题,本文提出一种结合对比学习与邻域样本分析(CLNSA)的故障诊断方法。首先通过引入对比学习预训练方法,为后续邻域样本分析算法提供较为良好的特征表示,提升所构建训练子集标签可靠性,减少噪声数据的负面影响。其次提出邻域样本分析方法,通过分析特征空间中同类样本具有更为相近的映射距离的特点,执行邻域样本划分及纠正,并针对所构建训练子集提出鲁棒性训练方法,增强模型鲁棒性。此外,通过引入双网络协同学习策略,减少训练过程中所引起的认知偏差问题。最后通过分析与实验验证,证明了本文方法的有效性。然而,在数据标注过程中,同样可能将与目标标注样本特征分布不一致的分布外样本(out of distribution,OOD)误标注为目标标注样本,即分布外噪声标签数据问题[42],在未来的研究中将进一步探究如何解决分布外噪声标签问题。
参考文献:
[1]曹正志,叶春明.基于并联CNN-SE-Bi-LSTM的轴承剩余使用寿命预测[J].计算机应用研究,2021,38(7):2103-2107.(Cao Zhengzhi,Ye Chunming.Prediction of bearing remaining useful life based on parallel CNN-SE-Bi-LSTM[J].Application Research of Computers,2021,30(3):126-133.)
[2]曹正志,叶春明.改进CNN-LSTM模型在滚动轴承故障诊断中的应用[J].计算机系统应用,2021,30(3):126-133.(Cao Zhengzhi,Ye Chunming.Application of improved CNN-LSTM model in fault diagnosis of rolling bearings[J].Computer Systems & Applications,2021,30(3):126-133.)
[3]曹正志,叶春明.考虑转动周期的轴承剩余使用寿命预测[J].计算机集成制造系统,2023,29(8):2743-2750.(Cao Zhengzhi,Ye Chunming.Prediction of bearing remaining useful life involving rotation period[J].Computer Integrated Manufacturing Systems,2023,29(8):2743-2750.)
[4]周华锋,程培源,邵思羽,等.基于动态卷积多层域自适应的轴承故障诊断[J].计算机应用研究,2022,39(7):2098-2103.(Zhou Huafeng,Cheng Peiyuan,Shao Siyu,et al.Bearing fault diagnosis based on dynamic convolution multi-layer domain adaptive[J].Application Research of Computers,2022,39(7):2098-2103.)
[5]Zhang Shuo,Liu Zhiwen,Chen Yunping,et al.Selective kernel convolution deep residual network based on channel-spatial attention mecha-nism and feature fusion for mechanical fault diagnosis[J].ISA Transactions,2023,133:369-383.
[6]Xu Zifei,Bashir M,Zhang Wanfu,et al.An intelligent fault diagnosis for machine maintenance using weighted soft-voting rule based multi-attention module with multi-scale information fusion[J].Information Fusion,2022,86:17-29.
[7]Nie Xiaoyin,Xie Gang.A novel framework using gated recurrent unit for fault diagnosis of rotary machinery with noisy labels[J].Measurement Science and Technology,2021,32(5):1271-1288.
[8]Wang Huan,Li Yanfu.Robust mechanical fault diagnosis with noisy label based on multistage true label distribution learning[J].IEEE Trans on Reliability,2022,72(3):1-14.
[9]Liang Pengfei,Wang Wenhui,Yuan Xiaoming,et al.Intelligent fault diagnosis of rolling bearing based on wavelet transform and improved ResNet under noisy labels and environment[J].Engineering Applications of Artificial Intelligence,2022,115:105269.
[10]Zhang Kai,Tang Baoping,Deng Lei,et al.A fault diagnosis method for wind turbines gearbox based on adaptive loss weighted meta-ResNet under noisy labels[J].Mechanical Systems and Signal Proces-sing,2021,161:107963.
[11]Song Huanjun,Kim M,Park D,et al.Learning from noisy labels with deep neural networks:a survey[J].IEEE Trans on Neural Networks and Learning Systems,2022,34(11):1-15.
[12]Arpit D,Jastrzbski S,Ballas N,et al.A closer look at memorization in deep networks[C]//Proc of the 34th International Conference on Machine Learning.[S.l.]:JMLR.org,2017:233-242.
[13]Han Bo,Yao Quanming,Yu Xingrui,et al.Co-teaching:robust trai-ning of deep neural networks with extremely noisy labels[C]//Proc of the 32nd Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2018:8527-8537.
[14]Chen Pengfei,Liao Benben,Chen Guangyong,et al.Understanding and utilizing deep neural networks trained with noisy labels[C]//Proc of the 36th International Conference on Machine Learning.[S.l.]:PMLR,2019:1062-1070.
[15]Li Junnan,Richard S,Steven C H.DivideMix:learning with noisy labels as semi-supervised learning[C]//Proc of the 8th International Conference on Learning Representations.[S.l.]:OpenReview.net,2020:1-13.
[16]Wei Qi,Sun Haoliang,Lu Xiankai,et al.Self-filtering:a noise-aware sample selection for label noise with confidence penalization[C]//Proc of the 17th European Conference on Computer Vision.Berlin:Springer,2022:516-532.
[17]Kihyuk S,David B,Nicholas C,et al.FixMatch:simplifying semi-supervised learning with consistency and confidence[C]//Proc of the 34th International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2020:596-608.
[18]Zheltonozhskii E,Chaim B,Avi M,et al.Contrast to divide:self-supervised pre-training for learning with noisy labels[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2022:1657-1667.
[19]Wang Tongzhou,Isola P.Understanding contrastive representation learning through alignment and uniformity on the hypersphere[C]//Proc of the 37th International Conference on Machine Learning.[S.l.]:PMLR,2020:9871-9881.
[20]Li Junnan,Xiong Caiming,Steven C H.Learning from noisy data with robust representation learning[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:9485-9494.
[21]Tan Cheng,Xia Jun,Wu Lirong,et al.Co-learning:learning from noisy labels with self-supervision[C]//Proc of the 29th ACM International Conference on Multimedia.New York:ACM Press,2021:1405-1413.
[22]Huang Bin,Alhudhaifet A,Fayadh A,et al.Balance label correction using contrastive loss[J].Information Sciences,2022(607):1061-1073.
[23]Ghosh A,Kumar H,Sastry P S.Robust loss functions under label noise for deep neural networks[C]//Proc of the 31st Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2017:1919-1925.
[24]Zhang Zhilu,Sabuncu M R.Generalized cross entropy loss for training deep neural networks with noisy labels[C]//Proc of the 32nd Confe-rence on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2018:8778-8788.
[25]Ma Xingjun,Huang Hanxun,Wang Yisen,et al.Normalized loss functions for deep learning with noisy labels[C]//Proc of the 37th International Conference on Machine Learning.[S.l.]:JMLR.org,2020:6543-6553.
[26]Zhu Zhaowei,Song Yiwen,Liu Yang.Clusterability as an alternative to anchor points when learning with noisy labels[C]//Proc of the 38th International Conference on Machine Learning.[S.l.]:PMLR,2021:12912-12923.
[27]Zhang Hongyi,Cisse M,Dauphin Y N,et al.MixUp:beyond empirical risk minimization[C]//Proc of the 6th International Conference on Learning Representations.[S.l.]:OpenReview.net,2018:1-13.
[28]Lukasik M,Bhojanapalli S,Menon A K,et al.Does label smoothing mitigate label noise?[C]//Proc of the 37th International Conference on Machine Learning.[S.l.]:JMLR.org,2020:6404-6414.
[29]Lu Yangdi,Bo Yang,He Wenbo.Noise attention learning:enhancing noise robustness by gradient scaling[C]//Proc of the 36th Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2024:23164-23177.
[30]Iscen A,Valmadre J,Arnab A,et al.Learning with neighbor consistency for noisy labels[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:4662-4671.
[31]Arazo E,Ortego D,Albert P,et al.Unsupervised label noise modeling and loss correction[C]//Proc of the 36th International Conference on Machine Learning.[S.l.]:PMLR,2019:465-474.
[32]Zhang Ziyi,Chen Weikai,Fang Chaowei,et al.RankMatch:fostering confidence and consistency in learning with noisy labels[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2023:1644-1654.
[33]Karim N,Rizve M N,Rahnavard N,et al.UNICON:combating label noise through uniform selection and contrastive learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:9666-9676.
[34]Chen Ting,Kornblith S,Norouzi M,et al.A simple framework for con-trastive learning of visual representations[C]//Proc of the 37th International Conference on Machine Learning.[S.l.]:JMLR.org,2020:1575-1585.
[35]Ortego D,Arazo E,Albert P,et al.Multi-objective interpolation trai-ning for robustness to label noise[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:6602-6611.
[36]Li Jichang,Li Guanbin,Liu Feng,et al.Neighborhood collective estimation for noisy label identification and correction[C]//Proc of the 17th European Conference on Computer Vision.Cham:Springer,2022:128-145.
[37]Englesson E,Azizpour H.Consistency regularization can improve robustness to label noise[EB/OL].(2021-10-04).https://arxiv.org/abs/2110.01242.
[38]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Identity mappings in deep residual networks[C]//Proc of the 14th European Conference on Computer Vision.Cham:Springer,2016:630-645.
[39]Yu Xingrui,Han Bo,Yao Jiangchao,et al.How does disagreement help generalization against label corruption?[C]//Proc of the 36th International Conference on Machine Learning.[S.l.]:PMLR,2019:7164-7173.
[40]Huang Lang,Zhang Chao,Zhang Hongyang.Self-adaptive training:beyond empirical risk minimization[C]//Proc of the 34th Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associa-tes Inc.,2020:19365-19376.
[41]Liu Sheng,Niles-Weed J,Razavian N,et al.Early-learning regularization prevents memorization of noisy labels[C]//Proc of the 34th Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2020:1-12.
[42]Wu Zhifan,Wei Tong,Jiang Jianwen,et al.NGC:a unified framework for learning with open-world noisy data[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:62-71.
