考虑多交互关系与情感倾向的微博用户可信度评估算法
2024-10-14王梓宁张国防



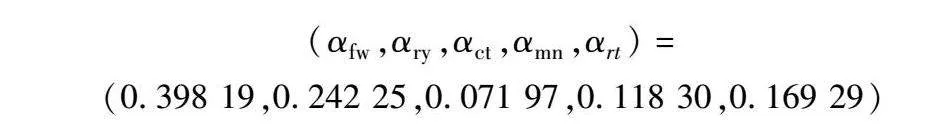




摘 要:探究综合考虑多交互关系与情感倾向因素的微博用户可信度评估方法。首先基于用户间交互关系的类型和频率,得到用户交互度与参与度;然后根据情感词典计算用户间评论、回复等文本内容的情感得分,并据此判断用户情感倾向;其次以PageRank算法为基础,从用户资料、博文中提取特征,计算每个用户的个体可信度作为初始PR值,并将用户交互度和情感倾向融合调整PR值分配权重、使用参与度修正阻尼系数,实现对PageRank算法的改进;最终,改进的PageRank算法迭代稳定后得到待评估用户的可信度。实验结果显示,与未考虑用户间多交互关系以及情感倾向的方法相比,所提方法在AUC值、查准率、查全率和F1值上均取得了更好的效果,最高提升了13.86%。综合考虑用户间多交互关系和情感倾向可以提高微博用户可信度评估效果。
关键词:微博用户;多交互关系;情感倾向;交互度;参与度
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)10-017-3000-08
doi:10.19734/j.issn.1001-3695.2024.03.0049
Microblog users’ credibility evaluation algorithm considering multi-interaction relationships and emotional tendencies
Wang Zining,Zhang Guofang
(School of Cyberspace Security & Computer,Hebei University,Baoding Hebei 071000,China)
Abstract:This paper proposed a new algorithm of the credibility evaluation concerning microblog users,based on their multiple interactive relationships and emotional tendencies.Firstly,the algorithm calculated the interaction degree and participation degree of users by analyzing the types and frequency of interactions among users.Secondly,this algorithm made the emotional scores of the textual contents including comments and replied among users by using a sentiment dictionary,and assessed users’ emotional tendencies.Thirdly,based on the PageRank algorits5UOywq2fA5yPx9b+/IBew==hm,the new algorithm extracted the features from user profiles and blog posts in order to compute the initial PageRank value for representing individual user credibility,adjusted the distribution of PageRank weights by integrating the user interaction degree and emotional tendencies,and modified the damping factor in accordance with the participation degree.Finally,the proposed algorithm made the credibility of the evaluated users after the iterative stabilization.The experimental results show that,compared to methods that overlook multi-interaction relationships and emotional tendencies,the new algorithm achieves better results with an improvement of up to 13.86% in terms of AUC value,precision,recall,and F1-measure.The method that considers multiple interaction relationships and emotional tendencies can enhance the effectiveness of microblog user credibility evaluation with respect to microblog users.
Key words:Microblog users;multi-interaction relationship;emotional tendency;interaction degree;participation degree
0 引言
微博平台是国内重要的信息服务提供者之一,截至2023年第二季度末,其月活跃用户已达5.99亿[1]。然而微博用户的信用状况良莠不齐,一些用户造谣诽谤、煽动仇恨,损害网络生态[2]。为维护网络生态环境,我国2022年8月颁布了《互联网用户账号信息管理规定》,要求互联网信息服务提供者建立完善的用户账号信用管理体系,根据用户账号信用状况提供相应服务[3]。有效的微博用户可信度评估方法有助于平台管理者更好地了解用户账号信用状况,及时发现微博网络中的不可信用户,净化网络环境,相关研究已经受到广泛的关注[4]。
早期的可信度评估方法集中于用户个体层面,从用户资料或博文中提取特征评估用户可信度。Castillo等人[5]从用户资料中提取平均博文数量、平均粉丝数量等特征作为用户可信度的评估指标;文献[6]进一步选取用户认证情况、教育经历等特征识别不可信用户。除用户资料外,Abu-Salih等人[7]认为在过多领域发布博文的用户不可信,根据用户博文得到用户感兴趣的主题数量、每个主题下发布内容的单词数等特征度量用户可信度;Wanda等人[8]从用户历史博文中提取博文发布规律、语言风格等特征判断用户是否可信。但是这类方法忽略了用户的社会属性,仅依赖于用户提供信息的真实性和完整性,其准确率较低[9]。随着用户之间的交互增多,一些学者注意到了用户通过交互形成的拓扑图,并根据用户的社交关系图结构来判断他们是否可信。李志宏等人[10]提出节点的结构重要性越高,该节点的影响力也越高,并据此利用中介中心性、紧密中心性和点度中心性等指标来发现水军用户;杨艳萍[11]利用局部最小路径搜索算法,计算以指定用户为根节点的“朋友圈”中该用户与其他用户之间的可信度关系图生成规则。通过社交网络图的拓扑结构判断用户是否可信相对较为客观。然而,仅仅依靠网络拓扑结构可能无法完全了解节点的内部特征,同时这些方法也未考虑其他节点对评估的影响。近年来,一些研究人员发现用户更倾向于与可信度相似或更高的用户建立关联[12],因此从用户交互层面出发,提出基于信任传播的可信度评估方法。这类方法是一种通过分析社交网络图中的信任传递过程来评估节点可信度的方法,利用了节点可信度不仅受节点自身特征影响,还受到其周围节点可信度和信任关系影响的思想[13],其中常见的方法是以PageRank算法为基础的改进算法[14]。李付民等人[15]基于PageRank算法提出用户可信度评价模型user-rank,首先从用户资料中提取特征,得到用户自评价可信度,然后利用用户关注网络中其他用户节点的自评价可信度对待分析用户节点的可信度进行综合评价;Zare等人[13]进一步利用了用户属性,首先对相似用户进行聚类,然后依托用户关注关系构造网络,最后根据用户资料计算得分来改进PageRank算法中节点PR值的分配方式,以找出网络中的异常用户;兰玮等人[16]注意到不同用户之间可信度影响程度不同,因此将用户关注关系视为无向边构造网络,通过用户信息提取得到用户脆弱度和相似度作为权重改进PageRank算法计算用户可信度。这些方法虽注意到了社交网络图中用户邻居节点信息对评估的影响,但是在度量用户可信度受其邻居节点影响的程度时存在明显的不足:a)这些方法或将邻居节点视为同等重要,或根据相似程度进行区分,并没有考虑相邻节点间的连接强度,也没有考虑目标节点在整体网络中所处位置,因此评估的准确性不足[17];b)这些方法未考虑用户间的信任情况,若目标节点不被其邻居节点信任,则其可信度可能降低[18]。
在微博中,用户间可以通过转发、评论和回复等交互行为分别建立转发、评论和回复等关系[10]。这些交互关系可以体现用户间密切程度以及用户参与交互的积极程度的不同[19,20],是衡量用户之间影响与被影响程度的一个重要因素[21]。因此,在度量用户可信度受其他用户影响的程度时有必要考虑用户间错综复杂的多交互关系。此外,Qazvinian等人[22]认为分析社交网络中的用户信任关系时需要考虑情感倾向的影响。用户之间的交互在情感方面并非都表现出认同的倾向,也有反对的情况,不同的倾向体现了用户间信任情况的不同,进而对评估的影响不同[23]。基于此,本文提出一种考虑多交互关系与情感倾向的微博用户可信度评估方法,以基于改进PageRank算法的评估策略为切入点,在度量用户可信度受关联用户影响程度时考虑了用户间多种交互关系与情感倾向,提高了评估的准确性。
1 研究框架
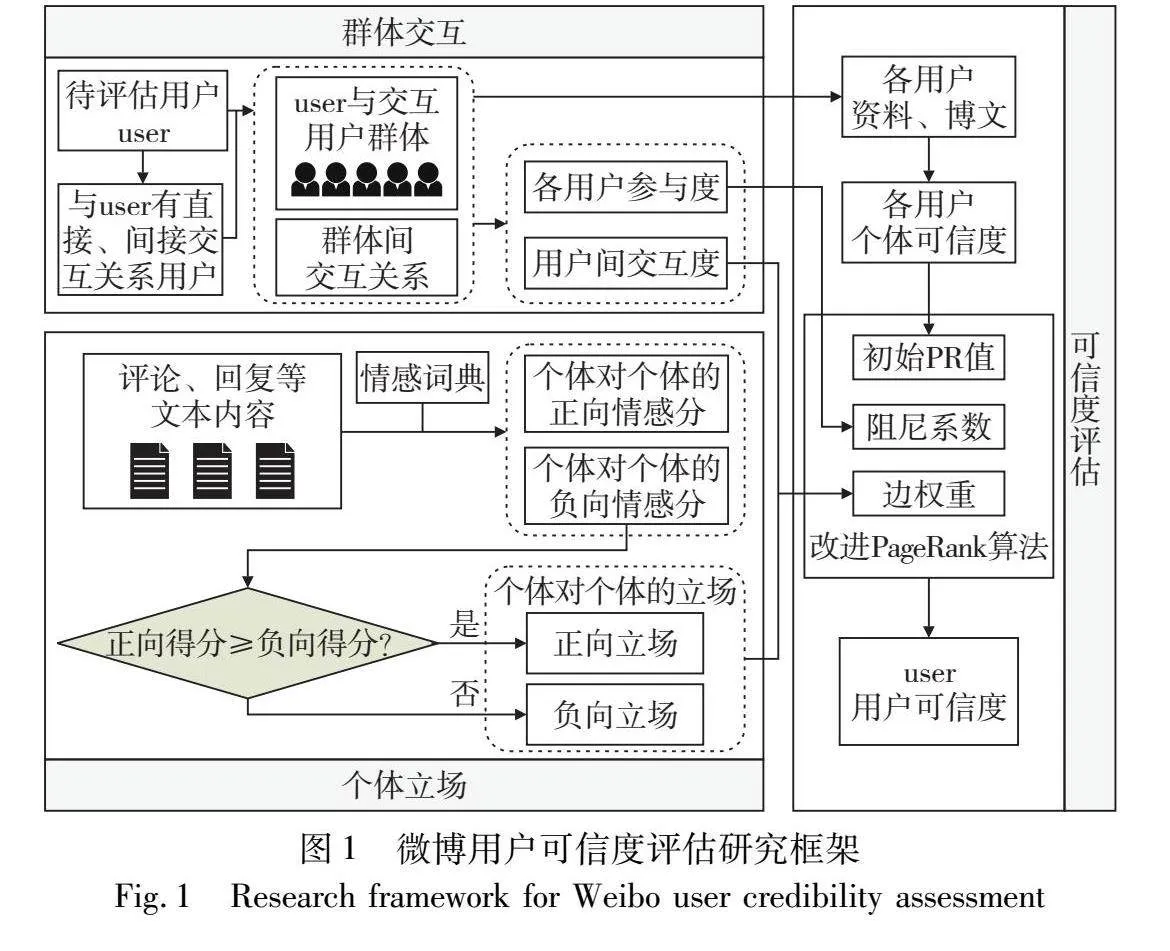
本文研究框架如图1所示。整体上分为三个部分:a)交互关系的量化。依据用户间的关注、转发、评论和回复等交互行为,分析相应的交互关系,量化用户对用户的交互度和用户对交互的参与度。b)情感倾向的判断。根据用户间评论、转发等文本内容计算用户间情感得分,进而判断用户的情感倾向是正向或负向。c)用户可信度评估。首先根据用户资料、博文计算每个用户的个体可信度,其次根据用户的个体可信度、交互度、参与度与情感倾向对PageRank算法进行改进,最终多次迭代后得到待评估用户的可信度。
2 考虑多交互关系与情感倾向评估用户可信度
2.1 交互关系的量化
在微博中,人们更倾向于与自己可信度接近或更可信的用户形成关系,信任程度与关系强度呈正相关[24],因而与用户关系越紧密的用户,对其可信度评估的影响越大[25]。基于此,本文综合考虑微博用户间关注、转发、评论、回复和提及五种交互关系,并定义交互度来计算用户间关系强度。
定义1 交互用户、目标用户。若用户ui对uj有关注、转发、评论、回复或提及等交互行为,则称用户ui是uj的交互用户,称用户uj是ui交互的目标用户。
定义2 交互用户对目标用户的交互度。交互用户ui对其目标用户uj的交互度可定义为uj收到的所有交互中来自ui的比例,其计算公式如式(1)所示。
w(ui,uj)=αfwNfw(ui,uj)+αryNry(ui,uj)+αrtNrt(ui,uj)+αmnNmn(ui,uj)+αctNct(ui,uj)∑ue∈Uj[αfwNfw(ue,uj)+αryNry(ue,uj)+αrtNrt(ue,uj)+αmnNmn(ue,uj)+αctNct(ue,uj)](1)
其中:Uj是用户uj的交互用户集合;Nfw(ui,uj)、Nry(ui,uj)、Nrt(ui,uj)、Nmn(ui,uj)和Nct(ui,uj)分别表示用户ui关注、回复、转发、提及和评论用户uj的次数,值得注意的是关注次数Nfw(ui,uj)的取值只有取0或1;αfw、αry、αrt、αmn和αct分别是关注、回复、转发、提及和评论五种关系的权重,且αfw+αry+αrt+αmn+αct=1。
用户参与交互有主动参与和被动参与两种形式[26]。用户越积极与其他用户交互,其主动参与程度越高,该用户更有可能发起、参与热点话题传播,其自身因素在评估中更重要[20]。用户接受其他用户所发出关系的数量、类型越多,其被动参与程度越高,则该用户在网络中的地位更高,那么由该用户传递的其他用户的可信度更可能被接受[18]。基于此,本文首先给出用户主动参与度与被动参与度的定义与计算方法,然后在其基础上给出用户参与度的定义与计算方法。
定义3 用户主动参与度。用户ui的主动参与度可描述为其主动对其他用户交互的程度,记为a(ui)。
用户ui的主动参与度由ui对其他用户交互的次数与权重度量,计算公式如式(2)所示。
a(ui)=Nout(ui)max(Nout)+[αfwactfw(ui)+αryactry(ui)+αrtactrt(ui)+αmnactmn(ui)+αctactct(ui)](2)
其中:Nout(ui)是用户ui对其他用户交互的次数;max(Nout)表示所有用户中,对其他用户交互次数的最大值;actfw(ui)、actry(ui)、actrt(ui)、actmn(ui)、actct(ui)分别表示用户ui是否对其他用户有关注、回复、转发、提及和评论行为,以actfw(ui)为例,计算公式如式(3)所示。
actfw(ui)=1ui对其他用户有关注行为0其他(3)
定义4 用户被动参与度。用户ui的被动参与度描述了其被动接受其他用户交互的程度,记为p(ui)。
用户ui的被动参与度通过其他用户对用户ui交互的次数与权重度量,计算公式如式(4)所示。
p(ui)=Nin(ui)max(Nin)+[αfwpasfw(ui)+αrypasry(ui)+αrtpasrt(ui)+αmnpasmn(ui)+αctpasct(ui)](4)
其中:Nin(ui)是用户ui接受其他用户交互的次数;max(Nin)表示所有用户中,接受其他用户交互次数的最大值;pasfw(ui)、pasry(ui)、pasrt(ui)、pasmn(ui)、pasct(ui)分别表示是否有其他用户对用户ui有关注、回复、转发、提及和评论行为,以pasfw(ui)为例,计算公式如式(5)所示。
pasfw(ui)=1其他用户对ui有关注行为0其他(5)
定义5 用户参与度。用户ui的参与度定义为其主动参与度与其主动、被动参与度之和的比值,计算公式如式(6)所示。
d(ui)=a(ui)a(ui)+p(ui)(6)
2.2 情感倾向的判断
用户情感倾向是交互用户对其目标用户所持有的赞同、中立或反对立场。微博用户评论、回复、提及和转发追加的文本内容中隐含着能够反映该用户对其目标用户的情感倾向:正向的情感倾向通常表明交互用户对目标用户的认可与信任,可能会增加目标用户的可信度[23];负向的情感倾向表明交互用户与目标用户之间存在分歧或不信任,可能降低目标用户的可信度[27]。因此,对用户可信度进行评估需要考虑其他用户对该用户的情感倾向[28]。
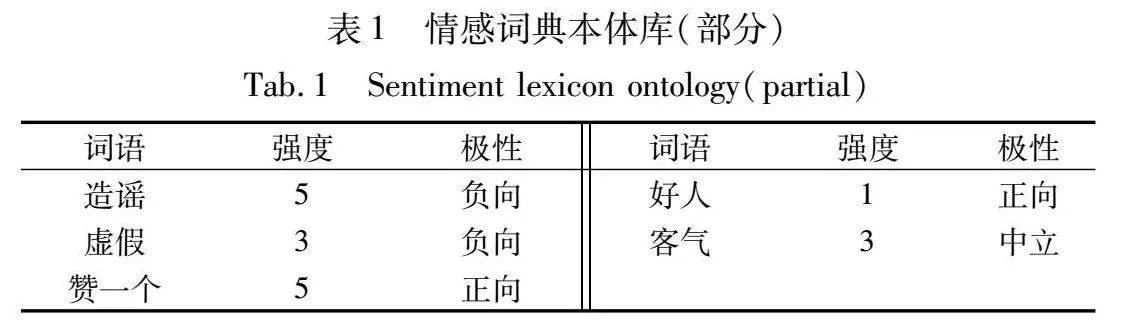
本文采用情感词典的方法判断交互用户ui对其目标用户uj的情感倾向,使用包含情感词汇相对较多的大连理工大学中文情感词典本体库[29]作为情感词典,基本格式如表1所示。
首先,将用户ui对uj评论、回复、提及和转发追加的文本内容进行预处理,以标点符号为分割标志将文本分为若干个分句。再对分句进行分词和去停用词处理,通过对比情感词典找出每个分句中的正向词汇和负向词汇,并以词汇为基准寻找其所在分句中的否定词。依据词汇的强度得分、极性与分句中否定词数量计算每个情感词汇的得分,计算公式如式(7)所示。
sen(wordk)=str(wordk)×pol(wordk)×(-1)n(7)
其中:sen(wordk)表示情感词wordk的情感分;str(wordk)表示wordk在词典中的强度得分;pol(wordk)表示wordk在词典中的极性,正向极性取值为1,负向极性取值为-1;n是wordm所在分句中的否定词数量。
然后,分别将所有分句中情感分为正的情感词与情感分为负的情感词的得分求和,计算用户ui对uj的正向情感值和负向情感值,计算公式分别如式(8)(9)所示。
scorepos(ui,uj)=∑sen(wordk)>0sen(wordk)(8)
scoreneg(ui,uj)=∑sen(wordk)<0sen(wordk)(9)
其中:scorepos(ui,uj)是用户ui对uj的正向情感值;scoreneg(ui,uj)是用户ui对uj的负向情感值。
最后,将用户ui对uj的正向情感值和负向情感值进行比较,当正向情感值大于或等于负向情感值时认为用户ui对uj情感倾向s(ui,uj)为正,取值为1,否则s(ui,uj)取值为-1,计算公式如式(10)所示。
s(ui,uj)=1scorepos(ui,uj)≥scoreneg(ui,uj)-1scorepos(ui,uj)<scoreneg(ui,uj)(10)
2.3 微博用户可信度评估
用户可信度评估既涉及用户自身因素,也和与其交互的用户相关[18],基于这一思想,本文以PageRank算法为基础,提出一种考虑多交互关系和情感倾向的微博用户可信度评估方法,通过邻居节点的可信度迭代计算目标节点的可信度。
2.3.1 PageRank算法
经典的PageRank算法同时考虑了节点随机跳转其他网页的固定概率以及其邻居节点的质量计算页面排名顺序,计算公式如式(11)所示。
PRt+1(vi)=d×1N+(1-d)×∑vj→viPRt(vi)out(vj)(11)
其中:PRt+1(vi)代表节点vi在t+1次迭代时的PR值;N是网页总数;1/N表示当前网页随机跳转其他网页的概率,同时也是每个节点的初始PR值;out(vj)是节点vj的出链数量;d是阻尼系数,用于平衡节点自身随机跳转概率和邻居节点质量对计算的影响,一般取0.15[15]。
2.3.2 考虑多交互关系和用户情感倾向的可信度评估方法
PageRank算法同时考虑了节点自身随机跳转概率和邻居节点质量,本文以式(14)得到的用户个体可信度替代节点自身随机跳转概率,并作为节点初始PR值。同时,将交互度与情感倾向的乘积作为边权重,修正用户的交互用户对其可信度的贡献。交互度体现了用户的交互用户对其可信度影响程度的大小[24],情感倾向决定了交互用户对其可信度的影响是正向或是负向[23]。此外,积极与其他用户交互的用户其个体因素在评估中的影响更大[19],被动接受其他用户交互的用户传递其他用户的影响更大[20]。所以选择式(2)计算得到的用户参与度作为阻尼系数平衡用户个体可信度与邻居节点可信度对评估的影响。最终,本文用户可信度评估方法的迭代公式如式(12)所示。
rt+1(ui)=d(ui)×ru(ui)+[1-d(ui)]×∑uj∈Uirt(uj)×w(uj,ui)×s(uj,ui)(12)
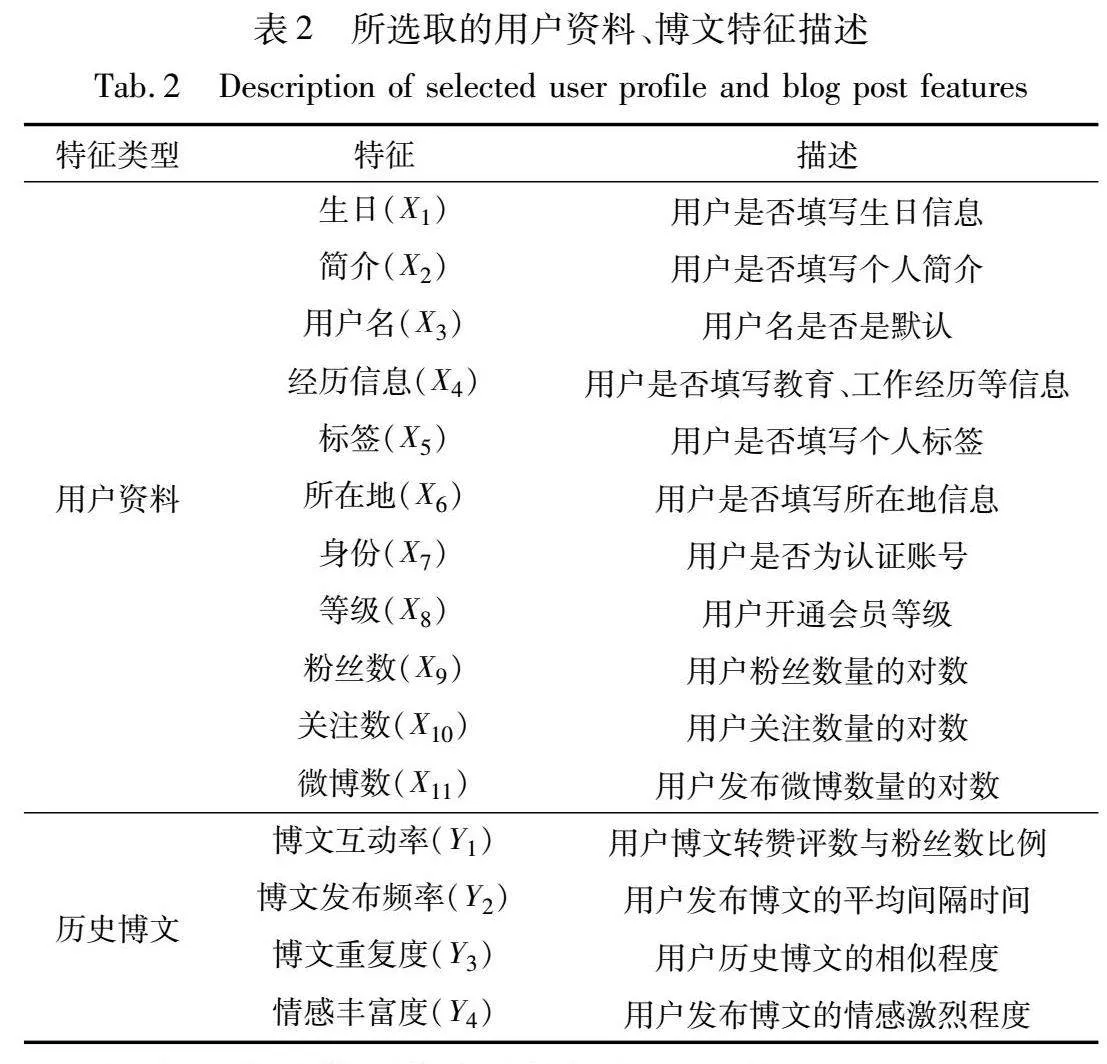
其中:t是迭代次数;rt+1(ui)是t+1次迭代时用户ui的可信度;Ui是用户ui的交互用户集合;d(ui)是用户ui的参与度;w(uj,ui)是用户uj对ui的交互度;s(uj,ui)是用户uj对ui的情感倾向;ru(ui)是用户ui的个体可信度,根据用户资料、历史博文提取特征计算得到,所选取的特征如表2所示。
用户ui的个体可信度计算如式(13)所示。
ru(ui)=γ×[21+e-∑11j=1Xj(ui)-1]+(1-γ)×∑4k=1[βk×Yk(ui)](13)
其中:∑11j=1Xj(ui)是用户ui资料提取特征得分的和;Yk(ui)是用户ui历史博文提取特征得分;参数β、γ为权值系数,满足β,γ∈(0,1),其值将通C5H9WI0nxtNTT8rdTotWKg==过实验获取。
本文微博用户可信度评估算法(UCEM-IGIS)的具体过程如算法1所示。
算法1 考虑多交互关系和情感倾向的可信度评估算法
输入:待评估用户user;与user交互的用户集U;交互关系集I;博文集C。
输出:user的可信度。
a)在交互关系集I中,根据式(1)计算用户间交互度;
b)在交互关系集I中,根据式(2)~(6)计算各用户的参与度;
c)提取交互关系集I包含的文本内容,根据式(7)~(10)判断用户情感倾向;
d)提取user与交互用户集U中用户资料、博文特征,根据式(12)(13)计算用户个体可信度;
e)根据步骤b)c)得到的交互度和参与度确定节点间边的权重;
f)根据式(12)迭代计算每个节点的可信度;
g)重复步骤f)直到每个用户节点的可信度不再变化;
h)得到user的可信度。
3 用户可信度评估实验和分析
3.1 实验数据
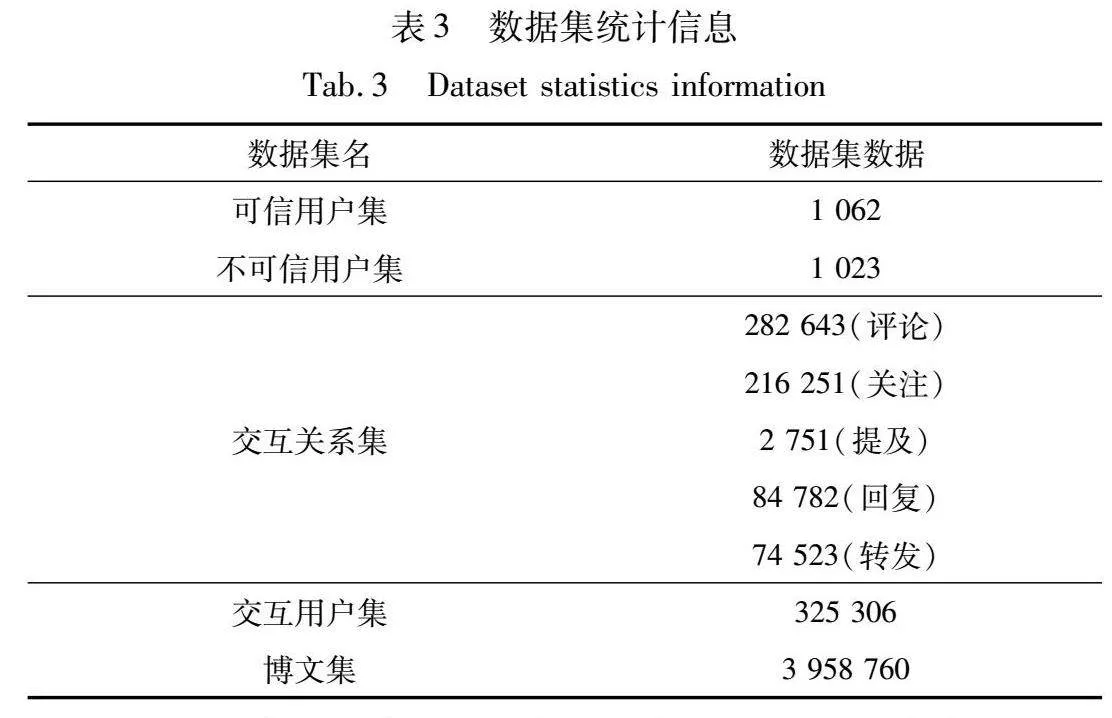
目前尚无用于微博用户可信度评估的权威数据集,因此本文参考文献[30]给出的数据集构建方式,通过新浪微博平台提供的API接口和爬虫工具爬取真实数据用于研究。实验数据包括:可信用户集、不可信用户集、交互用户集、交互关系集和博文集。为了使用户分类更符合真实情况,不可信用户集中的用户为随机爬取的2021年2月到2023年2月微博社区管理中心中被多次举报的用户,可信用户集中的用户为同一时间段内微博热门随机爬取的用户。交互用户集由与这些用户有直接或间接交互关系的用户构成,交互关系集收集了上述所有用户间的交互数据,博文集由上述所有用户在同时间段内发布的原创博文构成。表3列出了本文所构建数据集的详细统计数据。
其中,可信用户集、不可信用户集以及交互用户集中数据包括用户名、粉丝数等表2涉及到的用户资料信息,博文集中数据包括博文内容、发布者id、发布时间以及转赞评数量信息,交互关系集包括交互用户id、目标用户id、交互关系类型以及文本内容信息。
3.2 评价指标
本文评价指标选择查准率(Pre)、查全率(Rec)、F1值(F1-scroe)和AUC值,对应计算公式分别如式(14)~(17)所示。
Pre=TPTP+FP(14)
Rec=TPTP+FN(15)
F1=2×Pre×RecPre+Rec(16)
AUC=∑样本i∈正样本ranki-P×(P+1)2P×N(17)
其中:P表示不可信用户数;N表示可信用户数;TP表示正确识别为不可信用户数;TN表示正确识别为可信用户数;FP表示将可信用户识别为不可信用户数;FN表示将不可信用户识别为可信用户数;ranki表示样本i的排序位置;F1值是查准率和查全率的综合值。
3.3 参数设置
本文用到的相关参数有交互行为权重α、博文特征权重β和用户个体可信度权重γ三个。
1)交互行为权重α
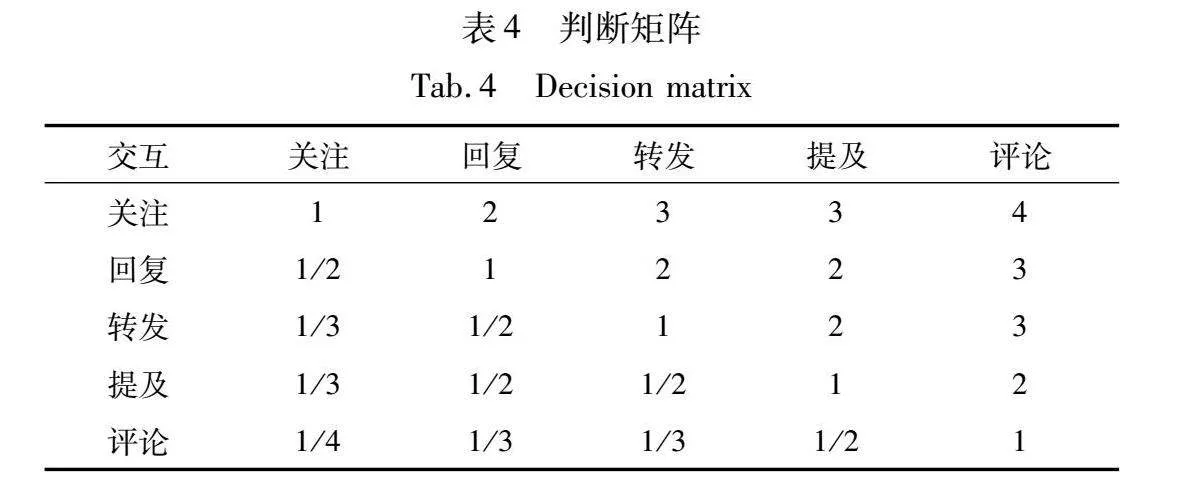
交互行为权重α通过层次分析法计算,五种交互行为权重大小依次为关注、回复、转发、提及和评论[31,32],其判断矩阵如表4所示。
通过计算,得到矩阵的最大特征值为5.111 1,一致性比率CR=0.025,远小于0.1,符合一致性检验要求,说明矩阵是合理的。最终计算得到,在本文实验中它们的值为
(αfw,αry,αct,αmn,αrt)=(0.398 19,0.242 25,0.071 97,0.118 30,0.169 29)
2)博文特征权重β
博文特征权重β采用熵权法确定,其中,粉丝活跃度为正向指标,博文发布频率、博文重复度和情感丰富度为负向指标。经计算得到博文重复度、博文发布频率、博文互动率和情感丰富度的权重分别为0.224 9,0.129 8,0.275 1,0.370 2。
3)用户个体可信度权重γ
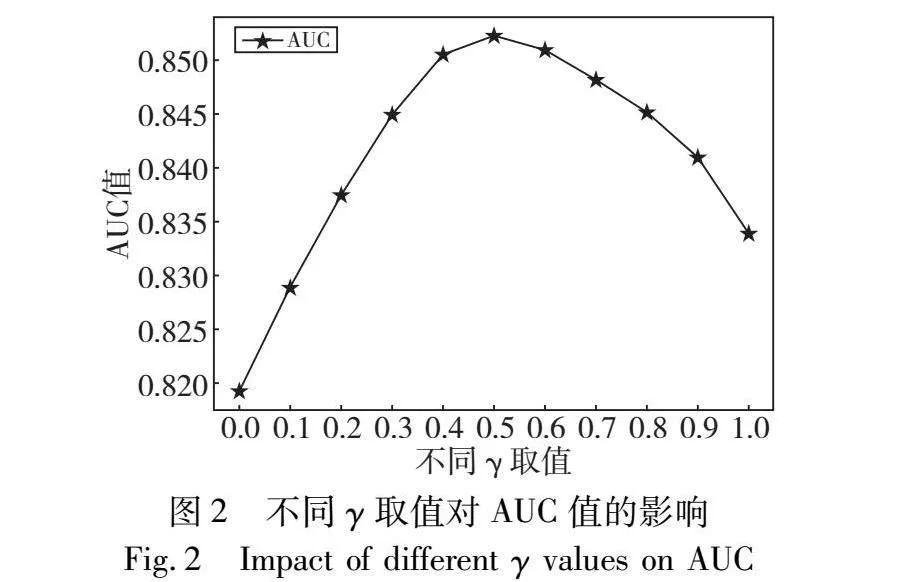
图2给出了在交互行为权重α和博文特征权重β确定的情况下,不同γ值对AUC值的影响。
从图2可以看出:在γ取0时,即在计算个体可信度时仅考虑用户历史博文特征,此时效果最差;在γ取1时,即在计算个体可信度时仅考虑用户资料特征,此时效果比γ取0好,说明相比用户博文特征,用户资料特征对可信度评估准确性的影响更大;在γ取0.5时,评估效果达到了最优,表明此时评估方法相比其他参数取值效果更好,因此将参数γ设为0.5。
3.4 实验结果及分析
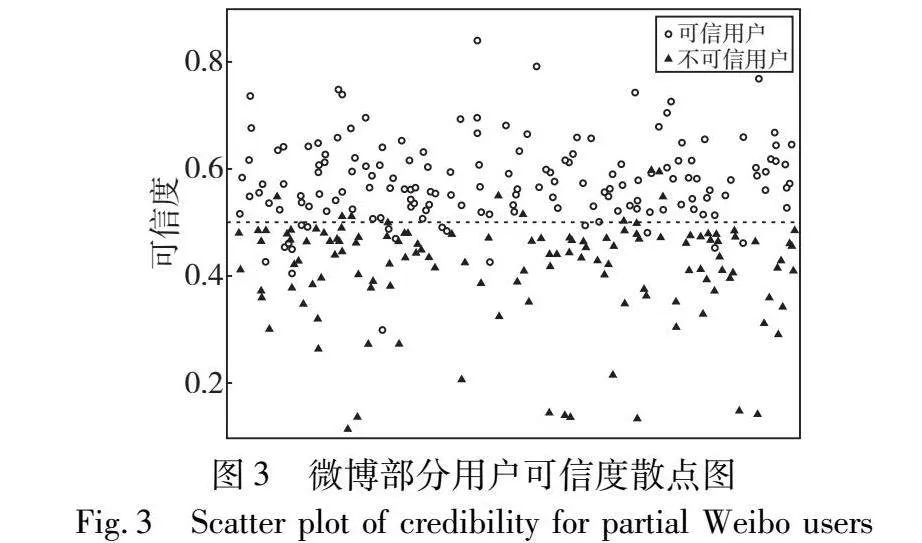
从数据集中随机抽取300名用户,将计算得到的可信度绘制成散点图,结果如图3所示。
图3中,每个点表示一个用户,空心圆代表该用户是可信用户,实心三角代表该用户是不可信用户。纵坐标对应的值是本文方法计算出该用户的可信度。通过分析图3可以发现,将可信度阈值设为0.5时,可信用户和不可信用户的区分效果最好,因此本文将分类阈值设置为0.5。
为验证评估方法性能,实验分为五部分:a)本文方法与官方排名的比较;b)本文评估方法与其他方法在AUC值、查准率、查全率和F1值上的比较;c)本文评估方法的消融实验;d)选取代表性用户进行案例分析;e)本文方法的泛化性分析。
3.4.1 本文方法与官方排名的比较
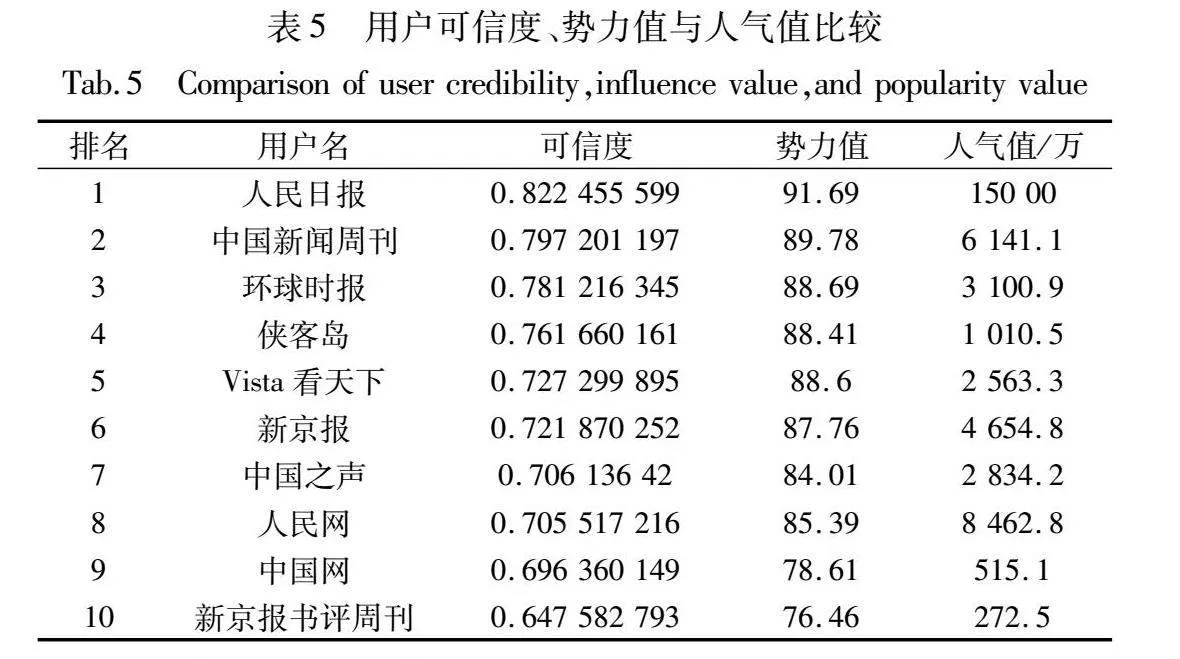
新浪微博的人气榜根据用户粉丝数排名,媒体势力榜根据内容质量、传播影响力和粉丝影响力三个指标计算综合得分。表3所示数据为2023年3月24日新浪微博媒体势力榜中十名上榜官方认证报纸媒体,这些媒体经过新浪认证,其势力值一定程度上可以反映其可信度[15]。表5列出了十名媒体报纸用户的势力值、人气值和按本文方法计算得到的可信度值,按照可信度由高到低排序。
从表5可以看出,对于受信赖的报纸媒体,本文方法得到的可信度符合实际情况。用户可信度与势力值变化趋势大致相同,势力值一定程度上能体现媒体的可信度,而媒体的人气值(粉丝数)与可信度值之间并非线性关系。
3.4.2 本文方法与其他方法的比较
为了进一步评估本文用户可信度评估方法,选择了其他三种考虑关联用户信息的方法进行对比,如表6所示。
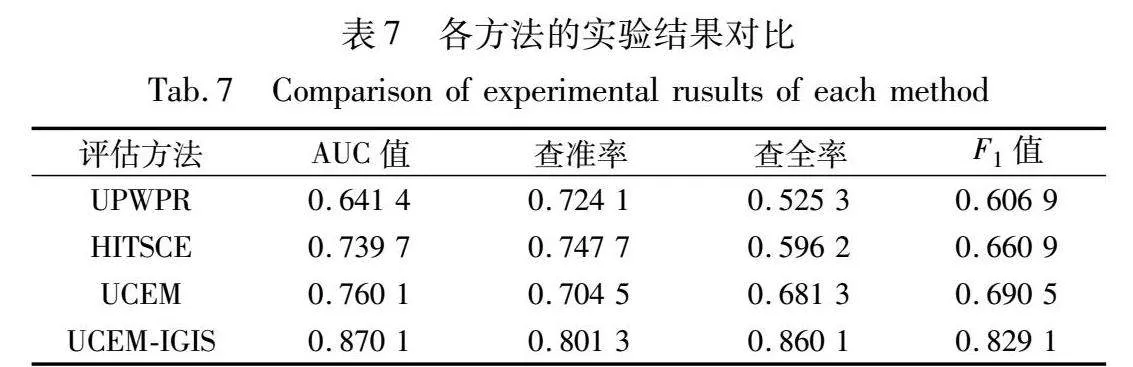
表6中:UPWPR[33]在PageRank的基础上将链入用户属性得分作为PR值分配的权重;HITSCE[34]在HITS算法的基础上考虑用户相似度,越相似的用户分配权重越高;UCEM是在PageRank基础上仅利用个体可信度初始化PR值,不考虑交互度、参与度以及用户间的情感倾向;UCEM-IGIS是本文方法。实验结果如表7所示。
从表7可以看出,与未考虑多交互关系和用户情感倾向的UPWPR、HITSCE和UCEM相比,UCEM-IGIS在各项指标的比较中均取得了更好的实验效果。在AUC值上,本文方法分别提升了0.228 7、0.130 4和0.11,在F1值上分别提升0.222 2、0.168 2和0.138 6,表明本文方法对可信用户和不可信用户的区分能力最好,对用户可信度的评估最合理。UPWPR在查全率、AUC值和F1值上的表现最差,表明UPWPR在评估用户可信度时,可能会错误地提高一些不可信用户的可信度,这是因为数据集中的不可信用户为微博中被多次举报成功的用户,这些用户中存在拥有水军、僵尸粉的营销号,而UPWPR受节点入链数量的影响较大,因此对这些用户的评估效果较差。HITSCE在各项指标上优于UPWPR,这是因为HITSCE还考虑了链入节点的出度,相对而言受虚假关系的影响小于UPWPR。UCEM只关注用户及其交互用户的个体可信度,受节点入链、出链数量影响较小,拥有水军、僵尸粉的营销号其交互用户群体的可信度较低,UCEM面对这些用户表现较好。但UCEM在查准率方面表现较差,表明该方法可能会错误地将一些可信用户判定为不可信用户,这是因为UCEM只关注用户及其交互用户的个体可信度,可能会将一些拥有不活跃粉丝的正常用户误判为不可信用户。
3.4.3 消融实验
为验证多交互关系与用户情感倾向对评估结果的影响,对本文方法进行消融实验,消融后的方法如表8所示。
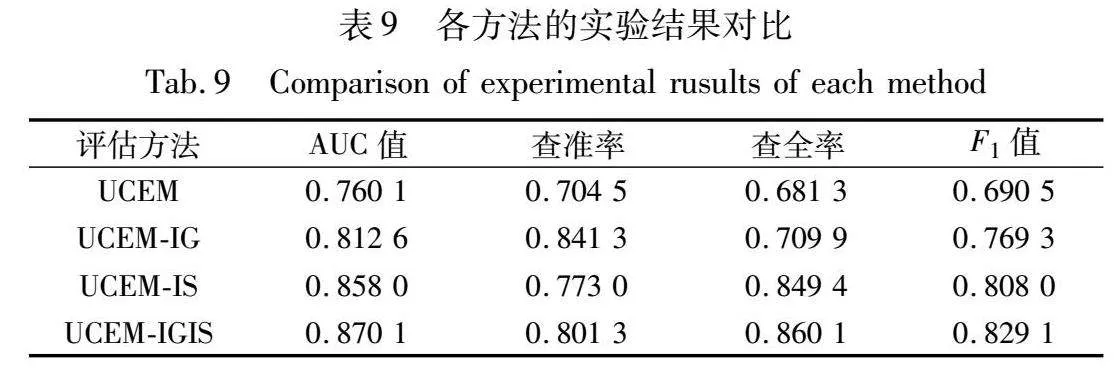
表8中,UCEM-IG是在UCEM基础上,考虑了基于多交互关系得到的交互度、参与度的方法,UCEM-IS是在UCEM基础上,考虑了用户情感倾向的方法,实验结果如表9所示。
从表9可以看出,考虑多交互关系与用户情感倾向的UCEM-IGIS总体上取得了更好的实验效果。与UCEM、UCEM-IG和UCEM-IS相比,UCEM-IGIS在AUC值上分别提升了0.11、0.057 5和0.012 1,在F1值上分别提升了0.138 6、0.159 8和0.021 1,表明考虑多交互关系与情感倾向因素会提高用户可信度评估的效果。在查准率的表现上,UCEM-IG表现最好,与未考虑多交互关系的UCEM相比提高了0.136 8,这是因为UCEM-IG比UCEM考虑了更多因素,对权重的分配更合理,一些拥有不活跃粉丝的可信用户不会被误报。在查全率的表现上,UCEM-IGIS表现较好,这是因为UCEM-IS融入了用户情感倾向,可以发现受公众反对的不可信用户,而UCEM-IGIS在其基础上还考虑了多交互关系的影响,关系密切的交互用户反对的影响将更大,因此能更准确地对不可信用户的可信度进行评估。综上所述,多交互关系与情感倾向均可提高用户可信度评估效果,考虑多交互关系因素能够提高评估方法的查准率,考虑用户情感倾向因素可以提高评估方法的查全率,将二者同时考虑的方法通过少量牺牲多交互关系提升的查准率,换得了查全率更高的提升,并获得了最优的效果与最稳定的性能。
3.4.4 泛化性分析
为了更加全面评价改进算法的性能,对本文方法进行泛化性分析。将本文数据集按照不同规模划分为五个测试集,测试本文方法在不同规模数据集上的表现,实验结果如表10所示。
表10中,测试集5的待评估用户数最少,平均交互关系数远高于其他测试集,而其在AUC值上的表现最好,这是因为交互数据的丰富性有助于算法更好地评估用户的可信度。交互关系数的增多使得AUC值也得到了提高,这一结果符合预期,因为更多的交互数据可以提供更多的信息,从而提高算法识别用户的能力。测试集1和2的表现低于其他测试集,这是因为虽然用户数较多,但交互数据较少,算法结果更偏向于由其自身因素得出的个体可信度。此外,尽管测试集的规模和交互关系数存在显著差异,但AUC值始终保持在0.8以上,这表明算法具有较好的稳定性,在不同规模的数据集上都能取得良好的效果。
结合本文方法在表10中交互信息较少的测试集1上的表现,以及4.3节参数设置中不同γ值对AUC值的影响可以发现,本文从用户资料、博文中提取常用于可信度评估的特征计算用户的个体可信度,而个体可信度的准确性会对结果产生影响。因此,选取更多、更有效的特征或采用更准确的融合方法可以进一步提高本文方法的准确性。
此外,本文选择新浪微博平台作为研究对象,而提出算法在设计时考虑的因素使其具有良好的扩展性,包括用户特征的选择、交互关系的选择等,因此可以将算法用于其他领域,例如在电子商务领域,用户的评分和评论可以被用来计算交互强度和情感倾向,帮助识别可信的买家和卖家;对于新闻网站、博客等内容平台,用户的评论和参与度可以用于评估内容的可信度,以及用户对特定内容的信任度;通过考虑不同文化背景下的交互习惯和情感表达方式的差异,可以使算法在不同国家和地区的用户可信度评估中都能发挥作用。
3.4.5 案例分析
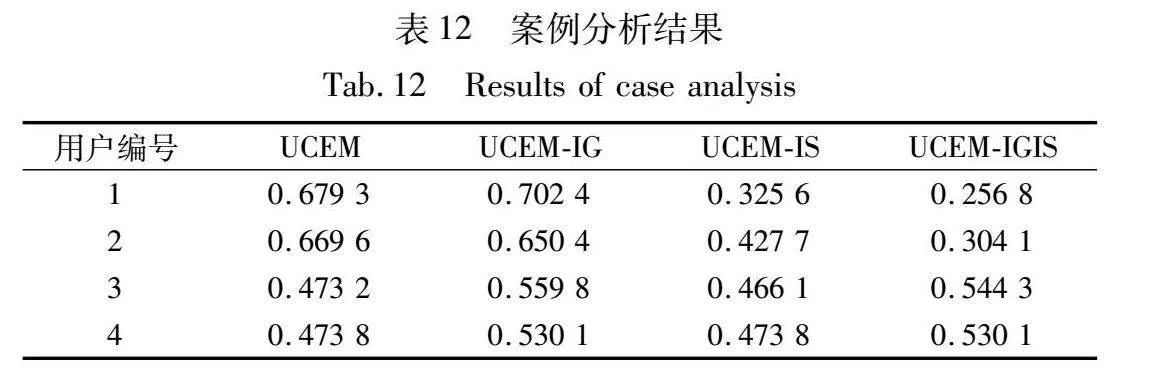
为了进一步说明本文方法的有效性,从数据集中选取4名代表性用户进行案例分析,选取用户信息如表11所示。
表11中,用户1曾因对山东某高校发布多条造谣微博而被举报,对其评论、回复等内容中存在多条反驳文本。用户2曾因对唐山某事件发布多条造谣微博而被举报,对其评论、回复等内容中存在多条辟谣、质疑等文本。用户3是某市级消防机构官方账号,用户4是某运营商官方账号。案例分析结果如表12所示。
表12中,UCEM和UCEM-IG将用户1与2误判为HoYcBS2L1TFbgCjcz/+xbg==可信用户,这是因为存在高可信度的用户对其微博发布辟谣、反驳评论或回复,不考虑情感倾向的UCEM和UCEM-IG将这些用户视为增加可信度的因素,从而提高了他们的可信度评分。而UCEM-IS和UCEM-IGIS考虑了情感因素,因此能够较好地反映两个用户的真实可信度。用户3和4为机构认证账号,二者评论中下属单位账号可信度较高且高度活跃,但其粉丝活跃度较低,且评论、转发用户中存在广告、抽奖账号,不考虑用户交互强度的UCEM和UCEM-IS将所有用户的贡献视为平等,因此产生了误报。而考虑交互关系的UCEM-IG和UCEM-IGIS增加了与二者关系紧密的高可信度用户的贡献,因此能够相对准确的对用户3和4进行评估。
4 结束语
研究微博用户可信度评估有助于帮助平台管理者更好地了解用户账户信用情况,进而维护微博网络生态环境,具有重要的现实意义。本文利用用户间多种交互关系量化出用户间的交互程度和用户对交互的参与程度,再结合用户情感倾向改进PageRank算法,用于评估微博用户可信度。经过实验证明,用本文方法评估微博用户可信度是行之有效的。相比于一般的用户可信度评估方法,本文方法在AUC值、查准率、查全率和F1值上具有更加良好的表现,既能更准确地找出高可信度的用户,又能减少对低可信度用户的误判。在消融实验中发现,用户间多交互关系与用户情感倾向都对评估准确率有着重要影响,将二者结合能够获得最优的评估效果。本文方法可以选取其他特征进行结合,具有良好的扩展性,进行相应扩展后可以应用于一些其他研究工作:
a)本文未考虑主题对用户可信度评估的影响,但用户在不同主题下的可信度可能是不同的,可以考虑划分主题后分别计算用户在各主题下的可信度;
b)本文方法在选取特征对用户个体可信度计算时,可以考虑加入更多特征或结合机器学习方法,提高评估的准确性;
c)本文方法可以应用于其他领域,结合不同的特征可以用来识别社交网络中的意见领袖、发现专利引文网络中的核心专利以及找出贸易网络中的关键企业等。
参考文献:
[1]新浪财经.微博月活跃用户近6亿[EB/OL].(2023-11-22).https://finance.sina.com.cn/jjxw/2023-08-25/doc-imziknyi9001689.shtml.(Sina Finance.Weibo has nearly 6 million monthly active users[EB/OL].(2023-11-22).https://finance.sina.com.cn/jjxw/2023-08-25/doc-imziknyi9001689.shtml.)
[2]Verma P K,Agrawal P,Madaan V,et al.UCred:fusion of machine learning and deep learning methods for user credibility on social media[J].Social Network Analysis and Mining,2022,12(1):54-64.
[3]国家互联网信息办公室.互联网用户账号信息管理规定[EB/OL].(2023-11-22).https://www.gov.cn/zhengce/zhengceku/2022-06/28/content_5698179.htm.(Cyberspace Administration of China.Internet user account information management regulations[EB/OL].(2023-11-22).https://www.gov.cn/zhengce/zhengceku/2022-06/28/content_5698179.htm.)
[4]Li Junhao,Paananen V,Suryanarayana S A,et al.It is an online platform and not the real world,I don’t care much:investigating Twitter profile credibility with an online machine learning-based tool[C]//Proc of Conference on Human Information Interaction and Retrieval.New York:ACM Press,2023:117-127.
[5]Castillo C,Mendoza M,Poblete B.Information credibility on Twitter[C]//Proc of the 20th International Conference on World Wide Web.New York:ACM Press,2011:675-684.
[6]Al-Khalifa H S,Al-Eidan R M.An experimental system for measuring the credibility of news content in Twitter[J].International Journal of Web Information Systems,2011,7(2):130-151.
[7]Abu-Salih B,Qudah D A,Al-Hassan M,et al.An intelligent system for mfef447ceb29740da5c7e82412bb44b561267fa4afbc9f109e4ac361acdf86ae1ulti-topic social spam detection in microblogging[J/OL].Journal of Information Science.(2022-09-15).https://doi.org/10.1177/01655515221124062.
[8]Wanda P,Jin Jiehuang.DeepProfile:finding fake profile in online social network using dynamic CNN[J].Journal of Information Secu-rity and Applications,2020,52:102465.
[9]沈旺,代旺,高雪倩,等.基于多重图的社交网络用户可信度评价方法研究——网络欺凌与隐私泄露视角[J].现代情报,2020,40(8):27-37.(Shen Wang,Dai Wang,Gao Xueqian,et al.Research on credibility evaluation method of social network users based on multigraph[J].Journal of Modern Information,2020,40(8):27-37.)
[10]李志宏,庄云蓓.基于水军信任惩罚的多维用户影响力度量模型[J].系统工程理论与实践,2017,37(7):1820-1832.(Li Zhihong,Zhuang Yunbei.Multidimensional user influence measurement model based on spammer trust punishment[J].Systems Engineering-Theory & Practice,2017,37(7):1820-1832.)
[11]杨艳萍.基于双向加权图的社交网络用户可信度算法研究[J].信息网络安全,2017(7):40-44.(Yang Yanping.The algorithm of social network users reliability based on bidirectional weighted graph[J].Netinfo Security,2017(7):40-44.)
[12]阳雨,胡亚洲,郭勇,等.基于在线社交网络的用户信任传递建模与分析[J].计算机工程,2018,44(11):265-270.(Yang Yu,Hu Yazhou,Guo Yong,et al.Modeling and analysis of user trust transfer based on online social network[J].Computer Engineering,2018,44(11):265-270.)
[13]Zare M,Khasten S H,Ghafouri S.Automatic ICA detection in online social networks with PageRank[J].Peer-to-Peer Networking and Applications,2020,13:1297-1311.
[14]尚丽维,张向先,卢恒,等.在线社区信息交互关系网络关键节点研究综述[J].情报科学,2020,38(8):170-177.(Shang Liwei,Zhang Xiangxian,Lu Heng,et al.A review of research on key nodes in online community information interaction network[J].Information Science,2020,38(8):170-177.)
[15]李付民,佟玲玲,杜翠兰,等.基于关联关系的微博用户可信度分析方法[J].计算机应用,2017,37(3):654-659.(Li Fumin,Tong Lingling,Du Cuilan,et al.Weibo users credibility evaluation based on user relationships[J].Journal of Computer Applications,2017,37(3):654-659.)
[16]兰玮.面向在线社交网络的虚假用户攻击及检测研究[D].西安:西安电子科技大学,2022.(Lan Wei.Research on fake user attack and detection for online social networks[D].Xi’an:Xidian Univer-sity,2022.)
[17]琚春华,赵凯迪,鲍福光.融入紧密度中心性与信用的社交网络用户影响力强度计算模型[J].情报学报,2019,38(2):170-177.(Ju Chunhua,Zhao Kaidi,Bao Fuguang.A user influence strength model in e-commerce social networks based on closeness and users’credit[J].Journal of the China Society for Scientific and Technical Information,2019,38(2):170-177.)
[18]景东,张大勇.社交媒体环境下用户信任度评估与传播影响力研究[J].数据分析与知识发现,2018,2(7):26-33.(Jing Dong,Zhang Dayong.Assessing trust-based users’ influence in social media[J].Data Analysis and Knowledge Discovery,2018,2(7):26-33.)
[19]Zheng Qiong,Qu Song.Credibility assessment of mobile social networking users based on relationship and information interactions:evidence from China[J].IEEE Access,2020,8:99519-99527.
[20]韩忠明,苑丽玲,杨伟杰,等.加权社会网络中重要节点发现算法[J].计算机应用,2013,33(6):1553-1557,1562.(Han Zhongming,Yuan Liling,Yang Weijie,et al.Algorithm for discovering influential nodes in weighted social networks[J].Journal of Computer Applications,2013,33(6):1553-1557,1562.)
[21]段震,倪云鹏,陈洁,等.基于多关系网络的话题意见领袖挖掘[J].数据采集与处理,2022,37(3):576-585.(Duan Zhen,Ni Yunpeng,Chen Jie,et al.Topic opinion leader mining based on multi-relational networks[J].Journal of Data Acquisition and Proces-sing,2022,37(3):576-585.)
[22]Qazvinian V,Rosengren E,Radev D,et al.Rumor has it:identifying misinformation in microblogs[C]//Proc of Conference on Empirical Methods in Natural Language Processing.Stroudsburg,PA:Association for Computational Linguistics,2011:1589-1599.
[23]肖宇,许炜,夏霖.一种基于情感倾向分析的网络团体意见领袖识别算法[J].计算机科学,2012,39(2):34-37,46.(Xiao Yu,Xu Wei,Xia Lin.Network groups opinion leader identification algorithms based on sentiment analysis[J].Computer Science,2012,39(2):34-37,46.)
[24]徐建民,申永平,吴树芳.基于分层社交关系的微博推荐算法[J].计算机应用研究,2021,38(12):3597-3603,3610.(Xu Jianmin,Shen Yongping,Wu Shufang.Algorithm of micro-blog recommendation based on hierarchical social relationships[J].Application Research of Computers,2021,38(12):3597-3603,3610.)
[25]琚春华,陶婉琼,马希骜.基于关系圈与个体交互习惯的用户关系强度计算方法[J].情报学报,2019,38(9):974-987.(Ju Chunhua,Tao Wanqiong,Ma Xi’ao.User relationship strength estimation model in online social networks based on fusion of activity field classification and indirect relationship[J].Journal of the China Society for Scientific and Technical Information,2019,38(9):974-987.)
[26]乐洪舟,何水龙,王敬.基于抖音共同联系人的群体用户关系分析[J].计算机研究与发展,2022,59(4):796-812.(Yue Hongzhou,He Shuilong,Wang Jing.Analysis of group users’relationship based on TikTok mutual contacts[J].Journal of Computer Research and Development,2022,59(4):796-812.)
[27]张亚楠,何建佳.基于网民心理的微博舆论传播模型及仿真研究[J].计算机应用研究,2018,35(5):1298-1303,1319.(Zhang Yanan,He Jianjia.Spreading model and simulation analysis of microblog public opinion based on psychology of netizen[J].Application Research of Computers,2018,35(5):1298-1303,1319.)
[28]Cho J H,Chan K,Adali S.A survey on trust modeling[J].ACM Computing Surveys,2015,48(2):1-40.
[29]徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[J].中文信息学报,2008,22(1):116-122.(Xu Linhong,Lin Hongfei,Zhao Jing.Construction and analysis of emotional corpus[J].Journal of Chinese Information Processing,2008,22(1):116-122.)
[30]冯兰萍,董陈超,徐绪堪.基于混合神经网络的突发公共卫生事件微博谣言识别研究[J].情报杂志,2022,41(12):81-88.(Feng Lanping,Dong Chenchao,Xu Xukan.Research on Weibo rumor identification in public health emergencies based on hybrid neural network[J].Journal of Intelligence,2022,41(12):81-88.)
[31]张继东,段小萌.基于移动社交平台的用户信任度分析研究[J].现代情报,2017,37(9):93-96,102.(Zhang Jidong,Duan Xiaomeng.Research on analysis of user trust degree based on mobile social platform[J].Journal of Modern Information,2017,37(9):93-96,102.)
[32]朱侯,方清燕.社会化媒体用户隐私计算量化模型构建及隐私悖论均衡解验证[J].数据分析与知识发现,2021,5(7):111-125.(Zhu Hou,Fang Qingyan.Quantifying and examining privacy paradox of social media users[J].Data Analysis and Knowledge Discovery,2021,5(7):111-125.)
[33]Alhaidari F,Alwarthan S,Alamoudi A.User preference based weighted page ranking algorithm[C]//Proc of International Conference on Computer Applications & Information Security.Piscataway,NJ:IEEE Press,2020:1-6.
[34]Tibermacine O,Tibermacine C,Kerdoudi M L.Reputation evaluation with malicious feedback prevention using a HITS-based model[C]//Proc of IEEE International Conference on Web Services.Piscataway,NJ:IEEE Press,2019:180-187.
