融合背景知识和常识感知的对话生成
2024-10-14汪红松叶浩贤李嘉展








摘 要:基于背景对话的关键问题之一是知识抽取,但由于有些会话的信息量不足,特别是在一些对话信息较少的情况下,选择恰当的知识变得尤为困难,且目前的生成方式缺乏动态选取背景知识的能力。针对这些问题,提出了KIF模型,引入知识增强库和知识向量并提出知识追踪模块和知识情感反馈模块去解决上述问题。该模型通过双重匹配矩阵的方式获得外部知识与背景知识的权重向量并进行知识选择,在每个解码步长内会根据历史会话和外部知识进行会话生成。最后,在Holl-E和WoW数据集上进行实验,实验结果表明KIF模型相比于之前的模型有明显的性能提升。
关键词:背景知识;对话系统;自然语言处理
中图分类号:TP183 文献标志码:A 文章编号:1001-3695(2024)10-016-2993-07
doi:10.19734/j.issn.1001-3695.2024.03.0048
Integration of background knowledge and common sense perception for dialogue generation
Wang Hongsong,Ye Haoxian,Li Jiazhan
(School of Software,South China Normal University,Foshan Guangdong 528225,China)
Abstract:One of the key issues in background-based conversation is knowledge extraction.However,due to the insufficient information in some conversations,especially when there is less information in certain dialogues,choosing the appropriate knowledge becomes particularly challenging.Furthermore,the current generation methods lack the capability to dynamically select background knowledge.To address these issues,this paper proposed the KIF model,which incorporated a knowledge enhancement library and knowledge vectors and introduced a knowledge tracking module and a knowledge sentiment feedback module to solve the aforementioned problems.The model obtained weight vectors of external knowledge and background know-ledge through a dual matching matrix method and performs knowledge selection.For each decoding step,the model generated conversation based on historical dialogues and external knowledge.Finally,experiments on the Holl-E and WoW datasets show that the KIF model significantly outperforms previous models.
Key words:background based;dialogue systems;natural language processing
0 引言
对话系统是目前NLP研究的热门之一。研究[1]表明,在2021年底已有80%的企业配备聊天机器人(对话系统),并且市场规模将在2024年发展到94亿美元。文本生成任务的一个基本定义是根据给定的序列生成一个预期的输出序列,称为序列到序列的任务。得益于深度学习的发展,人们提出了各种可用于对话系统的深度学习网络如递归神经网络(RNN)、卷积神经网络(CNN)和Transformer等。虽然已经有许多模型都已经有不错的性能,但由于传统的序列到序列模型中输入文本本身包含的知识量较少,所以传统的模型不能很好地理解话语,生成的响应也趋向于一般性的回复,例如新提出的序列到序列模型[2]能够动态地捕捉局部上下文的范围,可以更好地提取语义信息,但由于缺乏外部知识,只能生成“我不知道”等无意义的回复。为了解决这种问题,一些引入外部知识的模型就应运而生,同时也有研究证明了引入外部知识能够增强性能。
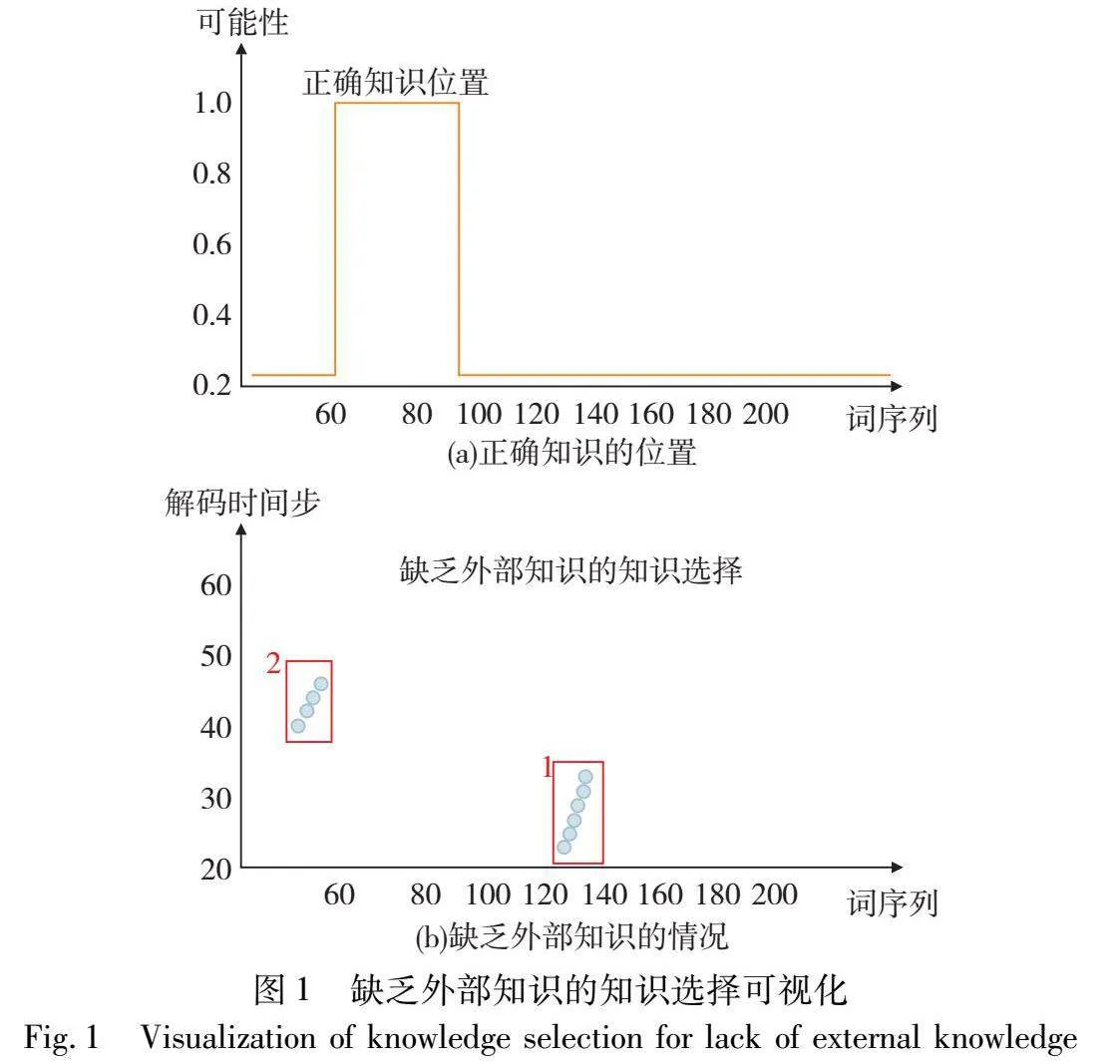
基于背景知识的对话研究任务是:根据给定一些背景知识(非结构化的知识)和一段对话,生成合理且含有信息性的响应。因此,知识选择是基于背景知识的对话中最关键的一个模块,它需要根据会话从背景知识中找出合适的知识,这直接影响着生成响应的质量。根据现有的研究,基于背景对话按照生成方式大致可分为基于提取的方式和基于生成的方式两种。基于提取的方法最早在机器阅读理解研究中提出,它通过预测开始和结束两个指针,然后根据位置提取背景知识并作为回复。这种方法能够很好地利用背景知识,例如BiDAF[3]、R-Net[4]等,但是却不适用于会话之中,因为区别于阅读理解,会话是没有正确答案的,通过这种方式生成的回复是不自然的。基于生成的方式是根据上一步的解码状态来生成当前的令牌,即回复的生成有先后顺序,是一个接一个令牌的生成。这种生成方式的优点是能够生成自然流畅的响应,但由于其生成只与上一个解码状态有关,缺乏知识选择的能力,所以不能及时地找到合适的知识背景。以GTTP[5]为例,如图1中横坐标表示词序列的位置,(a)的纵坐标表示正确的知识选择概率,(b)的纵坐标表示解码时间步长。图1中(a)表示正确的知识在背景中的位置,(b)表示GTTP选择背景知识的概率,其中蓝色的点表示在解码过程中使用到的背景知识,红框表示选择知识的范围。从图1中可以看出,传统的生成模型无法选择合适的知识背景进行回答。因此目前需要提出一种新的机制将高效的知识选择与生成方式结合在一起。
基于背景对话研究是一种外部知识增强研究,与传统非知识增强方法相比,基于背景对话的优势就是采用了非结构化的外部知识。最近的研究表明,单一知识来源的覆盖度是不够的,多个研究结果表明,使用更多的知识来源能够提高知识增强对话模型的性能[6]。人类对话中的一个重要特征就是语言带有情感,这种情感也可以认为是外部知识的一种,使用适当的外部知识增强能够使模型生成的回应隐含情感,就能够生成更加合适流畅的回应。对此,根据先前的研究,本文根据当前对话中包含的实体,从外部知识库中找到相关的知识和概念,通过引入带有情感的外部知识,不仅能够丰富对话的信息量,提升模型性能,还能使回复更加符合实际。
综上所述,本文提出一个知识融合及反馈的对话模型(knowledge integration and feedback,KIF)来解决上述问题。该模型通过引入常识知识库ConceptNet[7]和情绪情感词典NRC_VAD[8]结合最新一轮对话,使得语句中蕴涵情感知识。为了充分地利用到所有的信息(会话历史、背景知识、外部知识),本文提出了双重匹配的方式将信息融合在一起进行知识选择,搭配知识追踪模块提升知识选择的性能。在进行知识选择的时候,该模型会分别对会话历史和背景知识进行编码,然后使用双重匹配得到会话历史、背景知识、情感之间的相关性权重,并经过知识选择后得到知识主题转换向量,在生成回复的时候应用到知识情感反馈模块生成富有信息性、流畅的回复。
本文模型在Holl-E[9]和WoW[10]数据集上进行了实验分析。实验结果表明,KIF在机器评估方面优于基线模型,知识选择的性能更强,能够生成更加合适的响应。此外本文还抽样进行案例分析,表明KIF能够生成自然流畅的响应。
本文的贡献总结如下:a)提出一个知识融合及反馈的对话模型(KIF),引入非结构化的背景知识,结合ConceptNet和NRC_VAD引入外部结构化知识,通过双重匹配矩阵对两种不同结构的知识进行知识融合;提出了知识追踪模块,通过KL散度拉近回复-背景与会话-背景之间的分布,明确了回复与知识之间的关系,提高知识选择的性能。b)在生成框架上提出了知识情感反馈模块,能在每一个解码时间步中动态调节知识选择,优化了响应的生成。
1 相关研究
1.1 开放域对话
在开放域对话中,基于序列到序列的模型广泛应用于各个研究领域。随着深度学习的发展,有许多学者将深度学习与对话系统联系起来[11]。例如Huang等人[12]提出了增强型多域状态发生器去改进对话状态跟踪模块,提升了模型在小数据集中的性能;Ma等人[13]将RNN作为对话表示模型的一部分,提出了PR嵌入,捕获两个词之间的关系。在Transformer出现之前,大多数的研究都是将循环神经网络与注意力的机制结合在一起,使用循环神经网络的优势在于它的序列长度是灵活的,但缺点是不能够并行训练。直到2017年提出了Transformer,学者开始利用自注意力机制对全局进行编码,还有研究[14]利用这种特性提高对话系统的性能,例如使用堆叠的Transoformer用于各种类型的对话系统,并引入了潜变量改进生成模块。Li等人[15]提出了使用动态对话流的机制提高性能。
虽然上述模型都取得了不错的成果,但由于缺乏外部信息,导致可能生成通用无意义的响应,所以,很多学者都引入外部知识来解决这一问题。
1.2 引入外部知识的对话系统
有研究表明,引入知识库及知识图谱能够提升聊天的深度和广度,在回复用户的时候外部知识是一个重要的知识来源[16]。引入文本外部知识有很多种方法,大致可以分为引入知识图谱和引入非结构化的知识。Lin等人[17]结合复制与检索的方法进行回复生成,其中检索则是基于知识图谱的相关知识检索,最后综合计算生成流畅回复。Ren等人[18]针对一些基于背景的对话模型存在缺乏全局视角的问题,为了提高知识选择的正确率,提出了全局视角进行知识选择(GLKS)。通过给定一个对话上下文和背景知识,GLKS会学习到将背景的主题用于每个编码时间段去指引本地的知识选择。这种方法虽然能够对不同主题和背景知识进行识别,但是它缺乏跟踪机制,因此Chen等人[19]提出了响应感知反馈机制(RFM),他提出的响应感知反馈权向量通过修正背景知识生成更自然和适当的响应。虽然RFM在响应生成过程中对所选的背景知识进行修正,但这也可能同时产生一些不相一致的响应。基于知识库的基础对话确保了知识的丰富性和有效性,Zhan等人[20]发现以前的基于知识的研究缺乏对知识选择和对话的细粒度控制,最终导致生成与知识无关的问题。Prabhumoye等人[21]提出基于文档的生成任务是使用文档中提供的信息来改进文本生成,研究的重点是在预训练模型的基础上构建文档的上下文驱动表示,并使人们对文档中的信息有特定的关注。Lin等人[22]提出了一种基于生成对话网络(GCN)的元学习方法,以生成基于非结构化文本知识的会话数据,这种方式能够只使用少量的数据集就可以生成高质量的数据,并应用于知识选择的实验。
提升知识选择的性能目前仍是热点之一。Yang等人[23]设计了主题转移感知知识选择器,在检测到对话知识主题变化后,会选择自动合适的知识片段。Ma等人[24]提出了全局和局部的交互匹配模型,利用词-句的方式进行知识匹配。Sun等人[25]表明了端到端的方式能够明确知识片段之间的交互,提出了能够通过上下文生成知识的模型。Qian等人[26]考虑到了情感知识,设计了一个模仿人类的两阶段对话模型,有效利用了情感知识并减少了模型对情感语料库的需求。同时有学者也针对知识选择训练的方式进行改进。Zheng等人[27]提出了知识项权重模型,可以看作是知识选择后的一项优化工作,在训练时侧重于相关的术语。Zhao等人[28]发现了现有的生成范式会限制知识选择以及生成的多样性,并提出了使用对抗性网络进行训练。Xu等人[29]也设计了序列后验证的推理模型,能够通过后验分布抽样选择知识和生成对话。Wilie等人[30]提出了一个生成评分框架,可以直接使用在各种模型上而不需要对数据重新处理或对模型调优。使用GPT类作为生成模型也是一种方式[31],Deng等人[32]对部分语言模型进行了总结。
从目前引入外部知识对话系统的研究现状来看,在引入外部知识的角度来说,一般只会单独引入结构化或非结构化的知识,在进行知识选择的过程中也忽略了回复与所选知识的关系。在生成的过程中分为基于抽取式和基于生成式两种方式,这两种方式各有优劣,基于抽取式的方式能够更好地从背景中提取知识,基于生成式的方式能够生成自然流畅的语句。同时,大部分的模型缺乏在生成过程中动态调整所选知识的能力。因此,本文提出了双重匹配矩阵进行知识融合,使用知识追踪模块学习回复与所选知识之间的关系,同时结合抽取式和生成式的方式进行回复生成,在生成过程中通过知识情感反馈矩阵动态调整知识选择。
2 模型方法
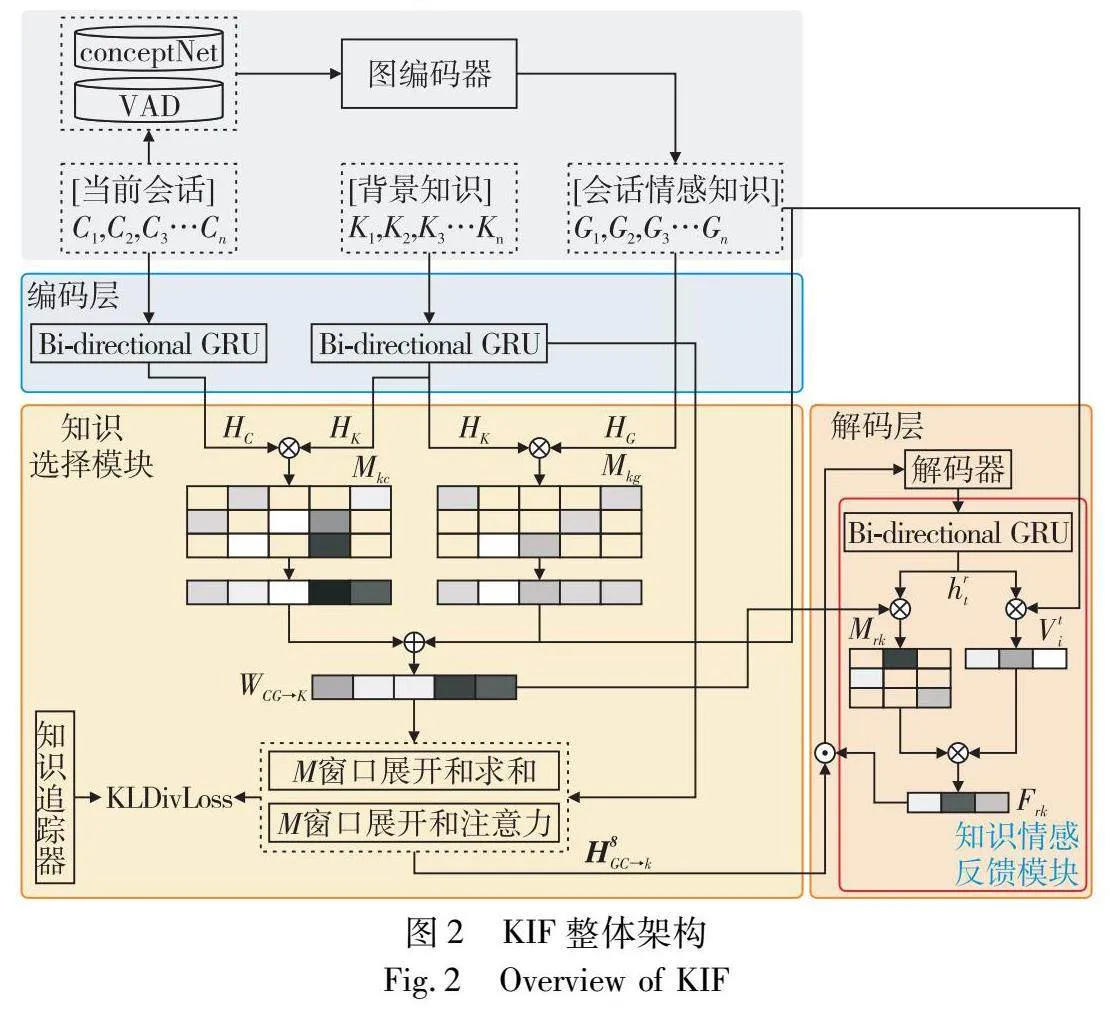
本文模型在基于背景知识的前提下,结合外部知识去提高知识选择的合理性,并生成符合逻辑的回应。形式上本文先给出符号定义。给定一个会话C={c1,c2,c3,c4,…,c|C|},其中cn代表第n个单词,类似地,对于非结构化的背景知识有K={k1,k2,k3,k4,…,k|K|},其中kn代表了第n个单词。本模型会根据会话和背景知识生成回应R={r1,r2,r3,r4,…,r|R|},rn代表了第n个单词。本章将介绍本文模型整体的模型框架,如图2所示。它主要包括四个大模块。
a)背景上下文编码器。使用两个独立的编码器,对给定的历史会话和背景知识进行编码,然后进行聚合操作得到历史会话和背景知识的潜在表示HC和HK。
b)情感背景图和图编码器。使用ConceptNet和NRC_VAD这两个情感增强库与会话历史C构成情感背景图G,然后放入到图编码器中得到图特征表示HG。
c)知识选择模块。使用双重匹配矩阵对历史会话HC、图特征表示HG与背景知识的潜在表示HK进行匹配操作,然后进行知识选择得到知识主题转换向量HsGC→k。
d)响应解码器。将知识主题转换向量HsGC→k和图特征表示HG拼接在一起得到情感主题指导向量HgGCK,该模块会根据此向量进行词汇生成。
总流程可以概括为,将历史会话C和背景知识K放入背景上下文编码器中,将会话历史结合知识库经过图编码层得到特征表示,然后经过知识选择模块选择出合适的知识,用于指引响应解码器生成最终的回复。
2.1 背景上下文编码器
本模型使用两个独立的双向GRU分别对会话历史C和背景知识K进行编码得到hC={hc1,hc2,hc3,hc4,…,hc|C|}和hK={hk1,hk2,hk3,hk4,…,hk|K|}。其中hct如式(1)所示。
hct=BIGRUc(e(ct),hct-1)(1)
式(1)中两个GRU的参数是不共享的;t代表第t个令牌,且hK也是用相似的方式得到。
接下来分别对这两个向量进行高速转换,并与双向GRU的每一层输出进行聚合操作,得到历史会话和背景知识的潜在表示HC和HK用于接下来的匹配操作。其中Hkt如式(2)所示。
Hkt=gk(Wl[hkt,hx|x|]+b)+(1-gk)tanh(Wnl[hkt,hx|x|]+b)(2)
其中:gk=σ(Wl[hkt,hx|x|]+b);Wl、Wnl、Wg都是可学习的参数;σ是激活函数。
2.2 情感背景图和图编码器
该模块使用ConceptNet和NRC_VAD结合对话C去构造情感图G。受Li等人[33]启发,结合对话C的每个非停用词和ConceptNet里面的关键词构造出一系列的候选元组Ti={tki=(ci,rki,xki,ski)}k=1,2,3,…,K,然后根据以下规则筛选候选元组:a)只保留置信度得分大于0.1的元组(ski>0.1);b)使用NRC_VAD计算情感强度值(μ(xki)),并选出最高分的k个元组。根据候选元组和对话进行构图,有以下规则:a)相邻的两个单词会按顺序指向下一个单词;b)选出来的候选情感词会指向它的关键词(ci)。对于图编码器,首先需要将情感图G的每个顶点像Transformer模型一样使用位置嵌入层和词嵌入层去进行转换,另外还需要使用顶点状态嵌入,因此整个顶点的向量表示由三个嵌入组成,如式(3)所示。
vi=Ew(vi)+Ep(vi)+Ev(vi)(3)
接着进入到多头图注意力机制得到每个顶点的深层表示,如式(4)(5)所示。
i=vi+‖Hn=1∑j∈AianijWnvvj(4)
anij=an(vi,vj)(5)
其中:H代表了多头的数目;Ai是G的邻接矩阵;an就是每个头的自注意力模块。为了获得全局的上下文表示,在经过了多头的图注意力层后,本模型使用Transformer的编码层进行全局建模,得到情感上下文图表示hg={vi},计算公式为
hlg=LayerNorm(l-1i+MHA(l-1i))(6)
li=LayerNorm(hlg+FNN(hlg))(7)
其中:l代表了编码层数的第l层;MHA代表了多头注意力模块;FNN表示以ReLU作为激活函数的两层前馈网络。
2.3 知识选择模块
这个模块使用到双重匹配矩阵,第一个匹配矩阵Mkc的构造需要用到2.1节得出的历史会话和背景知识的潜在表示HC和HK,如式(8)所示。
Mkc[i,j]=VMtanh(Wm1Hki+Wm2Hcj)(8)
其中:VM是可学习的向量;Wm1和Wm2是可学习的参数。为了能让情感图特征与背景特征作匹配,本模块首先使用一个多层感知机(MLP)对3.2节中的情感上下文图表示hg进行变换,得到HG,如式(9)所示。
HG=MLP(hg)(9)
使用类似的方法可以得到第二个匹配矩阵Mkg,计算为
Mkg[i,j]=VMgtanh(Wmg1Hki+Wmg2Hgj)(10)
接着沿X轴方向对上述两个矩阵使用最大池化层获得两个感知背景权重的特征表示,特征里的每个元素代表了与背景相关性的权重,权重越大代表了相关性越大,如下:
WC→K=maxX(Mkc)(11)
WG→K=maxX(Mkg)(12)
最后将这两个感知背景权重特征表示合在一起得到情感上下文背景感知权重向量WCG→K。虽然这个向量能够捕捉到上下文、情感图和背景之间的关系,但是它只考虑了单词方向上的关系分布,缺少全局视角,不能正确地得出知识选择的概率分布。因此,该模块采用滑动窗口的思想进行全局知识选择。本文使用以大小为m的窗口对权重向量进行展开求和计算,以大小为m的窗口对向量进行展开做注意力的操作。前者是为了获取全局的语义信息,后者是为了得到全局的注意力权重。
接着对WCG→K以大小为m的窗口对向量进行展开求和计算,得到滑动语义表示W′CG→K,如式(13)所示。
W′CG→K=([W′CG→K]0:m,…,[W′CG→K]N:N+m,…)(13)
其中的每个窗口都使用求和的操作,即如式(14)所示。
[W′CG→K]N:N+m=∑N+mi=NWCG→K[i](14)
对于第二个操作也采取同样的思想,对最后一层的背景知识表征hk使用窗口注意力操作得到全局的注意力H′K,计算为
H′K=([h′K]0:m,…,[h′K]N:N+m,…)(15)
[h′K]N:N+m=∑N+mi=Naihki(16)
ai=att(hc|C|,[hkm…hkN+m])(17)
其中:ai代表了会话与背景知识的注意力权重。使用这两个操作可以得到全局信息,再结合背景知识K生成知识主题转换向量HsGC→k,如式(18)和(19)所示。
HsGC→k=∑NP(KN:KN+m|C)[h′K]N:N+m(18)
P(KN:KN+m|C)∝softmax([W′CG→K]N:N+m)(19)
2.4 知识追踪模块
在以往的研究中,模型的训练方式都会选择最大似然估计损失去优化知识选择,这种方式就会导致模型只从生成的角度上训练,缺乏生成的多样性,同时也没有明确跟踪回复中使用了什么知识。为了让知识选择模块能够捕捉到回复与背景知识之间的内在关系,本文提出了知识追踪模块。该模块主要由先验知识追踪和后验知识验证组成,先验知识是指根据当前会话和背景知识所选择的知识概率分布,后验知识是指在原来的基础上在加入正确的回复所得到的知识概率分布。首先将当前会话和背景知识输入先验网络中得到先验知识概率分布:
Ppri(Kt-1)=softmax(QpriKTpri)(20)
Qpri=mlp(Hct-1)(21)
Kpri=mlp(Hkt-1)(22)
其中:Ppri(Kt-1)代表先验知识概率分布;mlp(X)=WX+b表示多层感知机。接着将加入回复与会话连接在一起,根据2.3节的步骤输入到知识选择模块上获取到知识向量WrCG→K。将获得的知识选择向量输入到后验网络中获得后验知识分布:
Ppos(Kt-1)=softmax(QposKTpos)(23)
其中:Ppos(Kt-1)代表后验知识概率分布。最后使用KL散度的方式缩小先验知识和后验知识的分布差距:
Lkl(θ)=1|M|∑|M|m=1Dkl(Ppri|Ppos)(24)
2.5 响应解码器
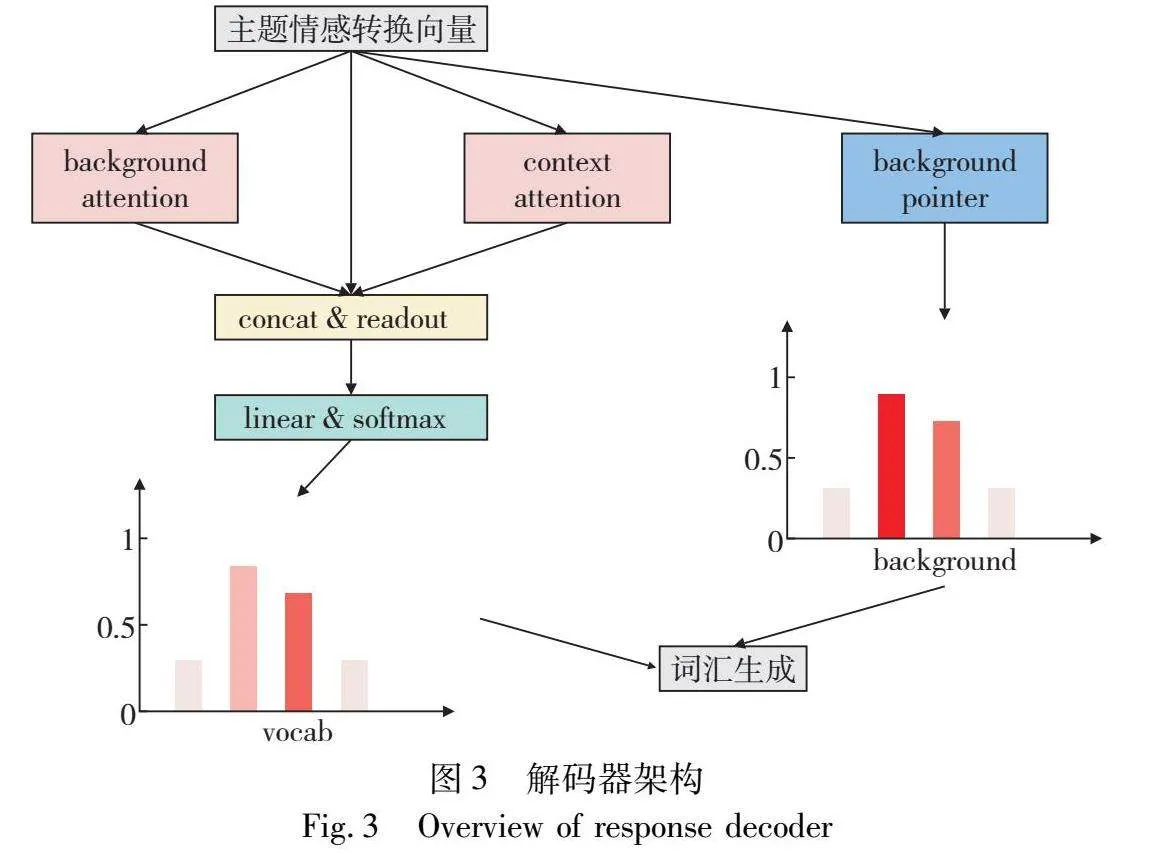
响应解码器模块结合了生成机制和复制机制。在每一个解码时间轴t中,先根据式(18)中知识主题转换向量HsGC→k与式(9)中的HG进行拼接,得到情感主题指导向量HgGCK。再根据该情感主题指导向量,得到从词汇表里生成的概率和直接从背景中截取的概率,并通过一种门机制最终决定如何生成。响应解码器如图3所示。具体过程如下:
首先将上一个时间步生成的解码状态码与HsGC→k、HG连接起来,如式(25)所示。
HgGCKt=[HsGC→k,HG,e(rt-1)](25)
其中:e(rt-1)代表了上一个时间步生成出来的向量。
然后使用注意力模块将知识情感主题向量与背景知识K做一个注意力操作,会得到背景指导向量Kt。类似地使用注意力模块与会话历史C做一个注意力操作,得到会话指导向量Ct,如式(26)(27)所示。
Kt=∑|K|i=1aKihKi(26)
aKi=attention(HgGCKt,hK)(27)
接着对得到的两个指导向量与知识情感主题向量连接起来并使用一个readout层得到一个整体的特征向量rt。
rt=readout(HgGCKt,Kt,Ct)(28)
将特征向量rt放入线性层中再经过一个softmax层得到从词汇表中生成单词的概率Pv(rt),如式(29)所示。
Pv(rt)=softmax(Wvrt)(29)
对于直接从背景知识中截取复制的概率Pk(rt),该模块对背景知识使用一个注意力模块学习截取的开始位置指针和结束位置指针,如式(30)所示。
Pk(rt)=attention(HgGCKt,hK)(30)
最终结合两个概率Pv(rt)和Pk(rt),通过以下结合方式得到最终的生成概率P(rt),如式(31)所示。
P(rt)=gPv(rt)+(1-g)Pk(rt)(31)
2.6 知识情感反馈模块
为了能更准确地进行知识选择,知识情感反馈模块在每一个解码时间步长中会根据之前生成的令牌与背景知识向量和情感知识向量相结合,后续会根据反馈模块得出来的权重向量进行生成。
首先使用GRU对回复进行编码,得到前一个时间步长的特征性向量hrt:
hrt=BIGRUc(e(ct),hrt-1)(32)
其中:hr0由一个线性层初始化。
接着将hrt与情感上下文背景感知权重向量WCG→K相乘得到反馈知识权重矩阵Mrk:
Mrk=WTCG→Khrt-1(33)
这个特征矩阵可以评估背景知识和生成回复之间的相关程度。为了能够利用到会话中暗藏的情感知识,将反馈知识权重矩阵与会话情感向量vi相乘得到富有额外信息的反馈知识权重向量:
Frk=MrkVTi(34)
最后在解码过程中会根据反馈知识权重向量与整体的特征向量rt相结合,得到反馈修正后向量进行回复生成。
2.7 训练方法
基于背景知识的对话任务就是根据指定的背景知识生成内容更丰富的回复,因此本文的训练目标就是最大化生成响应R的概率,本文使用到三种目标函数:最大似然估计损失(Lmle(θ))、远程监督损失(Lds(θ))、最大因果熵损失(Lα(θ)),最终的目标函数是这三个损失函数的线性组合,如式(35)所示。
L(θ)=Lmle(θ)+Lds(θ)+Lα(θ)(35)
其中:θ是本文模型KIF所有参数的组成,所有的参数都能够通过反向传播进行学习。最大似然估计损失是用来最大化最终生成概率的一个损失,定义如式(36)所示。
Lmle(θ)=-1|M|∑|M|m=1∑|R|t=1log P(rt|HgGCK)(36)
其中:M为训练样本的个数;R是生成回应的长度。从上述公式可以发现,最大似然估计是从词级的角度进行训练,它缺乏全局视角。因此,需要对知识选择模块中的全局操作设立远程监督损失函数,利用2.3节得出的滑动语义表示W′CG→K和H′K,得到P(H′K)的概率分布如式(37)所示。
P(H′K)=softmax(W′CG→K)(37)
同时通过数据集中正确的知识选择标签T来最大化与背景知识的表征hK之间的关系,定义Q(H′K)表示真实标签T与hK的相似性,如式(38)所示。
Q(H′K)=softmax((Jaccard(hK,T))(38)
其中:Jaccard代表了雅卡尔相似度。本文使用KL散度的方式缩小两个概率分布的距离,得到远程监督损失Lds(θ)。
Lds(θ)=1|M|∑|M|m=1Dkl(P(H′K)|Q(H′K))(39)
由于在计算Q(H′K)的时候使用到雅卡尔相似度,这是一种基于距离的计算方式,所以最后需要引入最大因果熵损失(Lα(θ))去减少噪声,如式(40)所示。
Lα(θ)=1|M|∑|M|m=1∑|R|t=0∑w∫VP(rt=w)log P(rt=w)(40)
其中:V表示词汇表中单词的集合。
3 实验分析
3.1 数据集
为了能够更好地体现模型的性能,本文选择Holl-E和维基百科向导(WoW)这两个数据集进行比较实验。数据集的样本数目如表1所示。
Holl-E是一个带有正确标签的数据集,它含有背景知识和正确的知识选择标签。该数据集重点关注电影部分,里面是两个人在对电影情节进行对话,每个回应都会是更改或者复制背景知识进行回复。背景知识由四个部分组成:电影情节、评论、专业点评和与电影相关的一些事实表。本文的实验采用Holl-E的oracle background(背景长度256),根据它原始的分割方法对数据集分割成三份,训练集含有34 486个样本,验证集含有4 388个样本,测试集含有4 318个样本。
维基百科向导(WoW)数据集中对话的二人分别扮演老师和学生,学生根据给定的主题向老师提问,老师的回答是从维基百科上选择一些含有知识的句子或生成进行回复,其中学生是不能够获取知识的,因此,每个轮次中都会用到背景知识。WoW数据集中,训练集包含了18 340轮对话,验证集包含1 948轮对话,测试集(看不见)包含930轮对话,测试集(看不见)包含913轮对话。测试集(看不见)是从未出现在训练集或者验证集中的对话轮次。
3.2 基线模型
a)使用GPT生成系列模型:KnowledGPT[34]、KnowExpert[35]、MSDP[36]、MixCL[37]、MIKe[38]。
b)使用正确的背景知识进行生成的模型:GTTP[5]、BiDAF[3]、Cake[39]、RefNet[40]、GLKS[18]、CET2[41]、RFM[19]、KWD[42]和KCTS[42]。
3.3 评估方法
在机器评估指标上,本文使用F1、ROUGE-L、BLEU2、BLEU4、MT评估指标作为对比,其中F1是计算生成的文本和真实文本之间的单值F1;MT(meteor)扩展了BLEU有关“共现”的概念。由于生成响应具有多样性,本文最后根据案例分析对此进行说明。
3.4 实验设置
为了让本节模型能与基线的模型进行公平的比较,采用与它们相同的超参数进行实验。单词嵌入大小设为300,隐藏层大小设为256,词汇的数量限制在26 000左右,会话历史的长度限制在65以内,背景知识的长度限制在256。优化器使用的是Adam,批处理大小设为32。整个模型训练的轮次为20次,在评估阶段采取最高分数进行比较。
3.5 实验结果
实验结果如表2、3所示。
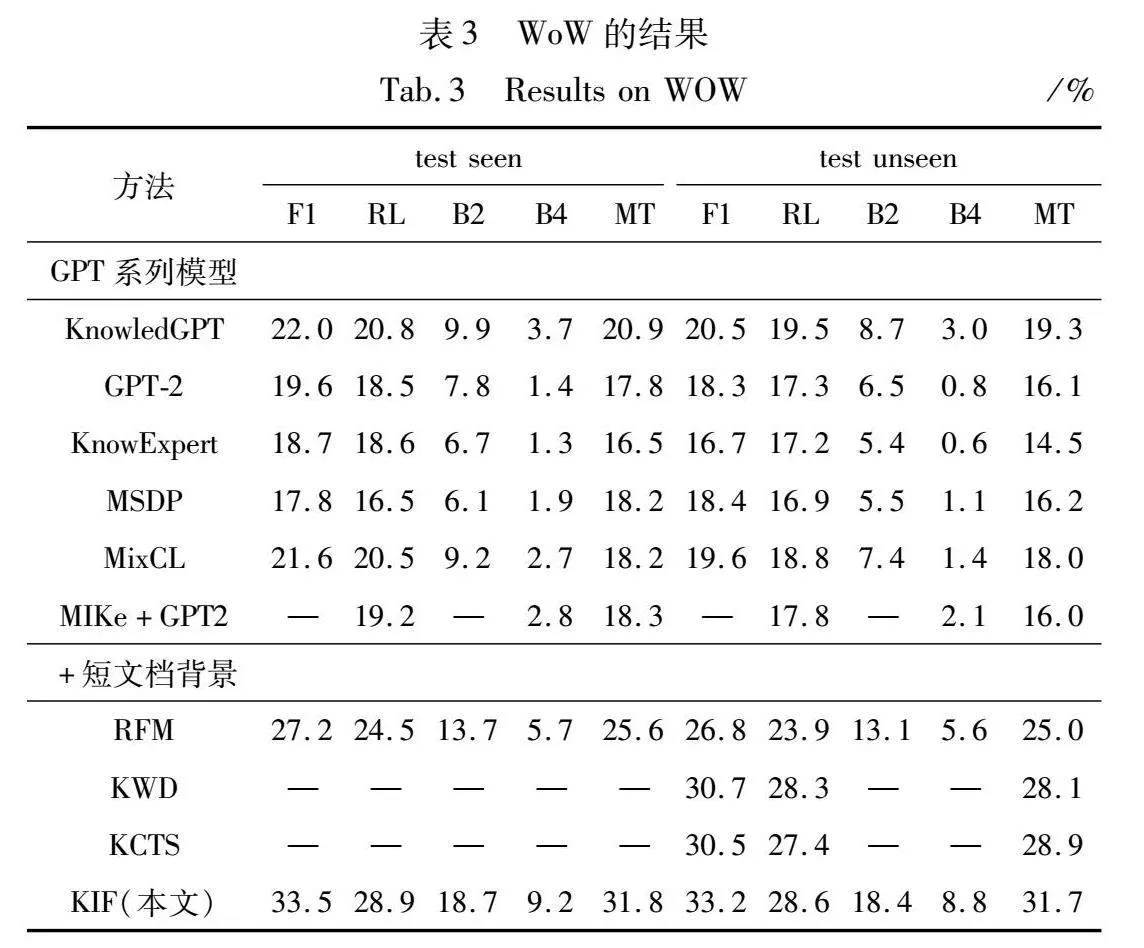
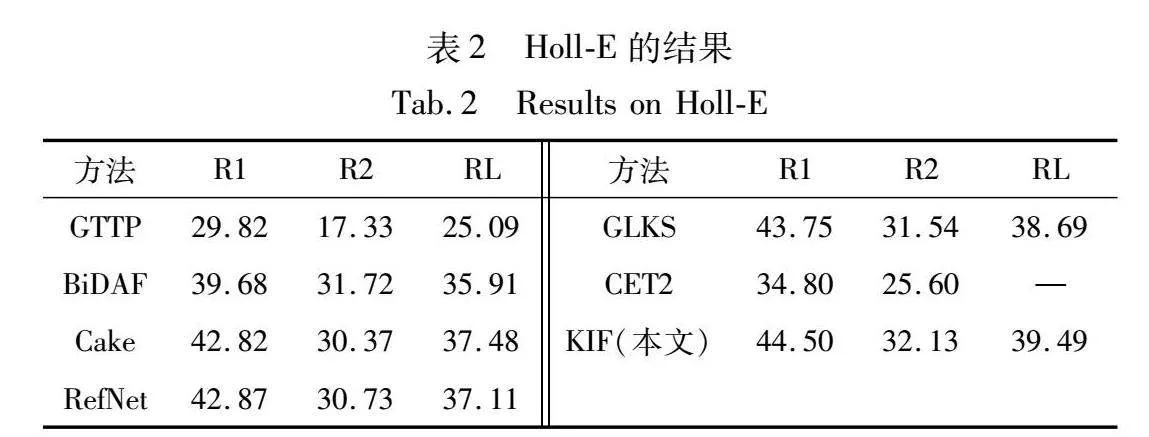
在表2中,KIF在Holl-E上的各项指标都优于基线模型,R1、R2、RL比之前最好的模型分别提高了1.7%、1.3%和2.1%。与BiDAF(基于提取式生成方法)相比,得益于结合抽取式和生成式的方法,KIF生成的响应更加合理和自然,同时能够很好地利用背景知识。RefNet使用到了跨度注释,而KIF不需要用到额外的标注信息并且能更好地定位到正确的背景知识位置,这是因为本文在生成的过程中使用了指导向量并学习两个指针去定位背景知识。同时KIF要优于所有基线模型,这说明KIF融合结构化知识的方式更加合理化,使用双重匹配矩阵融合结构化知识和非结构化知识提升知识信息量,能够显著地增加知识选择的性能,也不会生成空洞的回复。
在表3中,KIF在所有评估指标上都优于基线模型,特别是在F1和MT指标上,在看不见的测试集中达到33.2和31.7,比第二好的分数提升了约8%和9.7%。与利用GPT进行生成的模型相比,KIF都有显著的提升,这得益于引入了段落背景知识和常识知识增加了会话的知识量,同时使用了知识追踪模块让模型能够识别到回复与背景知识的关系,提升了模型知识选择的性能。相较于使用预训练语言模型生成的方式,引入外部知识且使用知识情感反馈模块能够解决回复空洞问题。与MIKe的混合知识选择相比,KIF的知识情感反馈模块能够更灵活地及时调整背景知识的选择。与加入短文档作为背景知识的模型相比,KIF在所有指标上都优于基线模型,这证明了KIF能够提升知识选择的性能,并生成更加合适的反应。与RFM相比,本文模型增加了会话中额外的情感知识,并且因为知识追踪模块在知识选择方面有更好的性能。同时KIF在看不到的数据集中表现也是相当优异,能够与在看得见的数据集上表现相差无几,这也证明了KIF促进了知识选择的性能,从而使模型拥有更好的普适性。
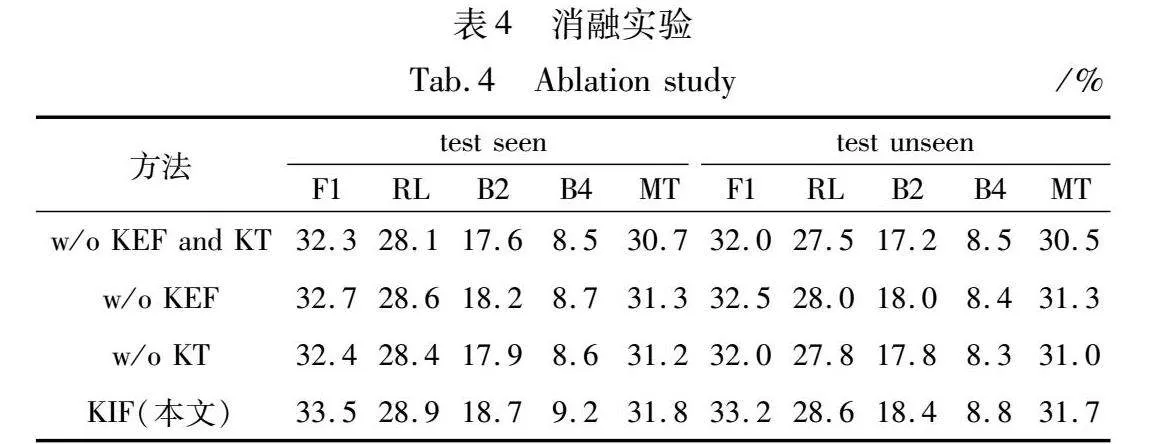
3.6 消融实验
消融实验部分将在WoW数据集上进行实验。本节将从以下三个方面进行分析:没有知识情感反馈和知识追踪模块(w/o KEF and KT)、没有知识情感反馈(w/o KEF)、没有知识追踪(w/o KT)。实验结果如表4所示,知识情感反馈和知识追踪模块都对最终的分数有一定程度的影响,删除任何一个都会降低性能。其次单独去除知识追踪(w/o KT)直接进行知识选择的话,性能的下降最为明显,这证明了知识追踪模块能够捕捉到回应与背景知识之间的联系,因此相关性更高,蕴涵准确的知识量也更多,提升了模型性能。其次为了验证知识情感反馈模块的有效性,在生成过程中去掉知识情感反馈模块(w/o KEF),结果证明,加入知识情感反馈能够提升生成模块的性能,在每个解码时间步长中充分利用到外部知识,在生成回应的时候提升知识的利用率,也使回复更加合理正当。
3.7 案例分析
本节的案例是从WoW上随机抽取一个样例进行分析。为了验证KIF能够生成更加流畅合理的结果,本节将与RFM以及数据集中的正确回答进行对比分析。图4中双下画线的部分是从背景知识中提取出的正确答案,斜体是模型生成的部分。以图4为例,与RFM相比,KIF的双下画线部分会更加完整,表示能够从背景中获得更多更正确的背景知识;与正确回答相比,KIF的斜体部分会更加自然,并且会进行符合逻辑的扩充。案例分析说明了KIF的知识选择能力相较于RFM有很大的提升,而且得益于知识结合的方式和知识情感反馈模块,KIF能够生成更自然合理的结果。
4 结束语
本文使用了常识知识库和情绪词典让对话具有额外的知识,提出了双重匹配矩阵将背景知识与情感向量结合起来,设计知识追踪模块,增加知识选择的性能。在生成方面设计了知识情感感知模块,提升了知识的利用率以及响应生成的自然性。KIF在Holl-E和WoW数据集上都优于基线模型,证明了模型的有效性,同时通过案例分析能得出,生成的响应是自然且符合逻辑。本文使用的模型以及词向量维度相对大模型来说都是较小的。目前是大模型的时代,下一步的重点工作是融合大模型,提升模型性能。
参考文献:
[1]Abro W A,Aicher A,Rach N,et al.Natural language understanding for argumentative dialogue systems in the opinion building domain[J].Knowledge-Based Systems,2022,242:108318.
[2]Xu Mayi,Zeng Biqing,Yang Heng,et al.Combining dynamic local context focus and dependency cluster attention for aspect-level sentiment classification[J].Neurocomputing,2022,478:49-69.
[3]Seo M,Kembhavi A,Farhadi A,et al.Bidirectional attention flow for machine comprehension[C]//Proc of International Conference on Learning Representations.2016.
[4]Wang Wenhui,Yang Nan,Wei Furu,et al.Gated self-matching networks for reading comprehension and question answering[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).2017:189-198.
[5]See A,Liu P J,Manning C D.Get to the point:summarization with pointer-generator networks[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).2017:1073-1083.
[6]赵梦媛,黄晓雯,桑基韬,等.对话推荐算法研究综述[J].软件学报,2022,33(12):4616-4643.(Zhao Mengyuan,Huang Xiaowen,Sang Jitao,et al.A survey of conversational recommendation algorithms[J].Journal of Software,2022,33(12):4616-4643.)
[7]Speer R,Chin J,Havasi C C.5.5:an open multilingual graph of general knowledge[C]//Proc of the 31st AAAI Conference on Artificial Intelligence.2016:4444-4451.
[8]Mohammad S.Obtaining reliable human ratings of valence,arousal,and dominance for 20 000 English words[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics(Volume 1:Long Papers).2018:174-184.
[9]Moghe N,Arora S,Banerjee S,et al.Towards exploiting background knowledge for building conversation systems[C]//Proc of Conference on Empirical Methods in Natural Language Processing. 2018:2322-2332.
[10]Dinan E,Roller S,Shuster K,et al.Wizard of Wikipedia:knowledge-powered conversational agents[C]//Proc of International Conference on Learning Representations.2018.
[11]曹亚如,张丽萍,赵乐乐.多轮任务型对话系统研究进展[J].计算机应用研究,2022,39(2):331-341.(Cao Yaru,Zhang Liping,Zhao Lele.Research progress on multi-turn task-oriented dialogue systems[J].Application Research of Computers,2022,39(2):331-341.)
[12]Huang Yi,Feng Junlan,Hu Min,et al.Meta-reinforced multi-domain state generator for dialogue systems[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.2020:7109-7118.
[13]Ma Wentao,Cui Yiming,Liu Ting,et al.Conversational word embedding for retrieval-based dialog system[C]//Proc of the 58th Annual Meeting of the Association for Computational Linguistics.2020:1375-1380.
[14]Xu Fuyong,Xu Guangtao,Wang Yuanying,et al.Diverse dialogue generation by fusing mutual persona-aware and self-transferrer[J].Applied Intelligence,2022,52(5):4744-4757.
[15]Li Zekang,Zhang Jinchao,Fei Zhengcong,et al.Conversations are not flat:modeling the dynamic information flow across dialogue utterances[C]//Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing(Volume 1:Long Papers).2021:128-138.
[16]许璧麒,马志强,周钰童,等.知识驱动的对话生成模型研究综述[J].计算机科学与探索,2024,18(1):58-74.(Xu Biqi,Ma Zhiqiang,Zhou Yutong,et al.A survey of knowledge-driven dialogue generation models[J].Journal of Computer Science and Exploration,2024,18(1):58-74.)
[17]Lin S C,Yang J H,Nogueira R,et al.Multi-stage conversational passage retrieval:an approach to fusing term importance estimation and neural query rewriting[J].ACM Trans on Information Systems,2021,39(4):1-29.
[18]Ren Pengjie,Chen Zhumin,Monz C,et al.Thinking globally,acting locally:distantly supervised global-to-local knowledge selection for background based conversation[C]//Proc of AAAI Conference on Artificial Intelligence.2020:8697-8704.
[19]Chen Jiatao,Zeng Biqing,Du Zhibin,et al.RFM:response-aware feedback mechanism for background based conversation[J].Applied Intelligence,2023,53(9):10858-10878.
[20]Zhan Haolan,Zhang Hainan,Chen Hongshen,et al.Augmenting knowledge-grounded conversations with sequential knowledge transition[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.2021:5621-5630.
[21]Prabhumoye S,Hashimoto K,Zhou Yingbo,et al.Focused attention improves document-grounded generation[C]//Proc of Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies.2021:4274-4287.
[22]Lin Y T,Papangelis A,Kim S,et al.Knowledge-grounded conversational data augmentation with generative conversational networks[C]//Proc of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue.2022:26-38.
[23]Yang Chenxu,Lin Zheng,Li Jiangnan,et al.TAKE:topic-shift aware knowledge selection for dialogue generation[C]//Proc of the 29th International Conference on Computational Linguistics.2022:253-265.
[24]Ma Hui,Wang Jian,Lin Hongfei,et al.Global and local interaction matching model for knowledge-grounded response selection in retrieval-based chatbots[J].Neurocomputing,2022,497:39-49.
[25]Sun Weiwei,Ren Pengjie,Ren Zhaochun.Generative knowledge selection for knowledge-grounded dialogues[C]//Findings of the Association for Computational Linguistics.2023:2077-2088.
[26]Qian Yushan,Wang Bo,Ma Shangzhao,et al.Think twice:a human-like two-stage conversational agent for emotional response generation[C]//Proc of International Conference on Autonomous Agents and Multiagent Systems.2023:727-736.
[27]Zheng Wen,Milic'-Frayling N,Zhou Ke.Knowledge-grounded dialogue generation with term-level de-noising[C]//Findings of the Association for Computational Linguistics.2021:2972-2983.
[28]Zhao Xueliang,Fu Tingchen,Tao Chongyang,et al.There is no stan-dard answer:knowledge-grounded dialogue generation with adversarial activated multi-reference learning[C]//Proc of Conference on Empi-rical Methods in Natural Language Processing.2022:1878-1891.
[29]Xu Yan,Kong Deqian,Xu Dehong,et al.Diverse and faithful know-ledge-grounded dialogue generation via sequential posterior inference[C]//Proc of the 40th International Conference on Machine Lear-ning.2023:38518-38534.
[30]Wilie B,Xu Yan,Chung W,et al.PICK:polished & informed candidate scoring for knowledge-grounded dialogue systems[C]//Proc of the 13th International Joint Conference on Natural Language Proces-sing and the 3rd Conference of the Asia-Pacific Chapter of the Associa-tion for Computational Linguistics(Volume 1:Long Papers).2023:980-995.
[31]林晟.ChatGPT:新一代信息技术变革下的开放教育——机遇与挑战[J].福建开放大学学报,2024(1):29-32.(Lin Sheng.ChatGPT:open education under the revolution of new information technology—opportunities and challenges[J].Journal of Fujian Open University,2024(1):29-32.)
[32]Deng Yang,Lei Wenqiang,Lam W,et al.A survey on proactive dialogue systems:problems,methods,and prospects[C]//Proc of the 32nd International Joint Conference on Artificial Intelligence.2023:6583-6591.
[33]Li Qintong,Li Piji,Ren Zhaochun,et al.Knowledge bridging for empathetic dialogue generation[C]//Proc of AAAI Conference on Artificial Intelligence.2022:10993-11001.
[34]Zhao Xueliang,Wu Wei,Xu Can,et al.Knowledge-grounded dialogue generation with pre-trained language models[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2020:3377-3390.
[35]Xu Yan,Ishii E,Cahyawijaya S,et al.Retrieval-free knowledge-grounded dialogue response generation with adapters[C]//Proc of the 2nd DialDoc Workshop on Document-grounded Dialogue and Conversational Question Answering,2022:93-107.
[36]Liu Zihan,Patwary M,Prenger R,et al.Multi-stage prompting for knowledgeable dialogue generation[C]//Findings of the Association for Computational Linguistics.2022:1317-1337.
[37]Sun Weiwei,Shi Zhengliang,Gao Shen,et al.Contrastive learning reduces hallucination in conversations[C]//Proc of the 37th AAAI Conference on Artificial Intelligence and the 35th Conference on Innovative Applications of Artificial Intelligence and the 13th Symposium on Educational Advances in Artificial Intelligence.2023:13618-13626.
[38]Meng Chuan,Ren Pengjie,Chen Zhumin,et al.Initiative-aware self-supervised learning for knowledge-grounded conversations[C]//Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval.2021:522-532.
[39]Zhang Yangjun,Ren Pengjie,De Rijke M.Improving background based conversation with context-aware knowledge pre-selection[C]//Proc of IJCAI Workshop SCAI:the 4th International Workshop on Search-Oriented Conversational AI.2019.
[40]Meng Chuan,Ren Pengjie,Chen Zhumin,et al.Refnet:a reference-aware network for background based conversation[C]//Proc of AAAI Conference on Artificial Intelligence.2020:8496-8503.
[41]Xu Lin,Zhou Qixian,Fu Jinlan,et al.CET2:modelling topic transitions for coherent and engaging knowledge-grounded conversations[J].IEEE/ACM Trans on Audio,Speech,and Language Processing,2023.
[42]Choi S,Fang Tianqing,Wang Zhaowei,et al.KCTS:knowledge-constrained tree search decoding with token-level hallucination detection[C]//Proc of Conference on Empirical Methods in Natural Language Processing.2023:14035-14053.
