基于主动学习的深度半监督聚类模型
2024-10-14付艳艳黄瑞章薛菁菁任丽娜陈艳平林川









摘 要:深度半监督聚类旨在利用少量的监督信息达到更好的聚类效果。然而,由于标注成本昂贵,监督信息的数量往往是有限的。因此,在监督信息有限的情况下,如何选择对聚类最有价值的监督信息变得至关重要。针对以上问题,提出了基于主动学习的深度半监督聚类模型(DASCM)。该模型设计了一种主动学习方法,能够挑选出蕴涵丰富信息的边缘文本,并进一步生成蕴涵边缘文本的高价值监督信息。该模型利用这些监督信息指导聚类,从而提升聚类性能。在5个真实文本数据集上的实验表明,DASCM的聚类性能有显著提升。这一结果验证了利用主动学习方法生成的涵盖边缘文本的监督信息对于提升聚类效果是有效的。
关键词:深度半监督聚类;主动学习;边缘文本
中图分类号:TP181 文献标志码:A 文章编号:1001-3695(2024)10-011-2955-07
doi:10.19734/j.issn.1001-3695.2024.01.0025
Deep active semi-supervised clustering model
Fu Yanyan Huang Ruizhang Xue Jingjing Ren Lina Chen Yanping Lin Chuana,b,c
(a.Text Computing & Cognitive Intelligence Engineering Research Center of National Education Ministry, b.State Key Laboratory of Public Big Data, c.College of Computer Science & Technology, Guizhou University, Guiyang 550025, China)
Abstract:Deep semi-supervised clustering aims to achieve better clustering results using a small amount of supervised information. However, the amount of supervised information is often limited due to the expensive labelling cost. Therefore, with limited supervised information, it becomes crucial to select the most valuable supervisory information for clustering. To address the above problem, this paper proposed a deep active semi-supervised clustering model(DASCM) which designed an active learning method that was able to select marginal texts containing rich information and further generated high-value supervised information containing edge texts. The model used this supervised information to guide the clustering, thus improving the clustering performance. The experimental results on five real text datasets show that the clustering performance of DASCM is signi-ficantly improved. This result verifies that supervised information generated using active learning methods that cover marginal text is effective in improving clustering.
Key words:deep semi-supervised clustering; active learning; marginal text
0 引言
聚类是数据挖掘领域中一个非常重要且十分具有挑战性的任务[1],旨在将数据在无监督的情况下划分为不同的类簇[2]。半监督聚类方法[3]通过给予少量监督信息可以进一步提高聚类的准确性。近年来,随着深度学习的发展,结合神经网络[4]的半监督深度聚类模型逐渐成为该领域研究热点。
由于标注成本昂贵,现有深度半监督聚类方法的监督信息数量往往是有限的[5]。在这种情况下,如何挑选高质量的监督信息变得至关重要。为了解决这一问题,主动学习成为一种有效的策略。主动学习旨在利用少量的标记数据最大程度提升模型性能[6]。通常,它选择最有价值的样本进行标注,以达到预期效果。关于主动学习的研究不得不面临一个关键的问题,即在聚类任务中,如何挑选最有价值的信息。
对于文本聚类任务,处于类簇边缘且难以明确判定其所属类簇的边缘文本对聚类效果的影响较大。正如图1所示,被红色(见电子版)圆圈标记的文本位于类簇边界,其所属类簇的划分也显得极为模糊,这些文本被称为边缘文本。边缘文本呈现出较高的不确定性,其所属的类簇难以确定。在信息论[7]中,数据的不确定性越高,其蕴涵的信息量就越大。面对聚类任务时,具有更高不确定性的边缘文本能够提供更丰富的信息,因而具有更高的价值。现有深度半监督聚类方法往往忽视了这些边缘文本的存在,其监督信息也未涵盖拥有丰富信息量的边缘文本,从而影响最终的聚类效果。
针对该问题,本文设计了基于主动学习的深度半监督聚类模型(deep active semi-supervised clustering model, DASCM)(图2),利用主动学习方法有效提高深度半监督聚类的监督信息质量,明显提升了聚类性能。DASCM构造了一个基于主动学习的半监督信息生成器,该生成器包含了两个模块。a)边缘文本挑选模块。该模块基于主动学习的思想,设计了面向聚类任务的挑选机制,旨在挑选出具有丰富信息量的边缘文本,即主动学习中的有效信息,并进一步构造“边缘文本-中心文本”问题。b)基于主动学习的监督信息生成模块。该模块使用主动学习的思想,旨在生成涵盖边缘文本的高质量监督信息进而指导聚类。根据输入的有关边缘文本的问题,获取真实的边缘文本与类簇中心文本的关系,从而构建“边缘文本-中心文本”的关系对。此外,半监督重构目标更新模块将“边缘文本-中心文本”的关系对作为半监督聚类的监督信息,从而进一步提升聚类性能。DASCM面向聚类任务,利用主动学习方法生成关于边缘文本的高质量监督信息,提升了聚类效果。
本文的主要工作如下:
a)设计并实现了一个基于主动学习的深度半监督聚类模型,能够使用少量的监督信息最大程度地提升模型聚类性能;
b)提出了一种面向聚类结构的主动学习方法,能够自动选择对聚类任务最具价值的样本;
c)提出了一种监督信息的生成方法,通过利用主动学习方法挑选出的样本生成高质量的聚类监督信息,进一步提升了聚类性能。
1 相关工作
1.1 半监督聚类
半监督聚类结合了聚类和半监督学习的思想[8],通过数据集中少量的标签数据[9]或约束信息[10]来提高聚类性能。
大多数半监督聚类方法主要是在已有的经典聚类方法的基础上,通过添加约束信息来优化聚类结果[11]。当约束信息是独立的类标签时,Basu等人[12]基于Seeds集对K-means进行改进,提出了Seeded-Kmeans算法,其基本思想是将标记样本引入K-means[13]。Wagstaff等人[14]提出的COP-Kmeans算法将成对约束引入到K-means算法中,不同点在于要求数据必须满足ML(must-link)或CL(cannot-link)约束,即任意两个数据样本要么满足ML约束(这两个样本一定属于同一类),要么满足CL约束(这两个样本一定不属于同一类),其聚类思想与K-means一致。
随着深度神经网络的发展,深度聚类已经取得了显著的效果。目前比较有代表性的深度半监督聚类是SDEC(semi-supervised deep embedded clustering)[15],在DEC(deep embedded clustering)的基础上将成对约束引入到特征学习过程中。Ohi等人[16]提出的AutoEmbedder能够基于成对约束生成可聚类的嵌入点,这些嵌入点不仅维度更低,而且更能体现样本点之间的联系。Wang等人[17]提出的PCSA-DEC基于成对约束构造了一个约束损失函数。该损失函数可以确保同类样本的相似性远高于其他样本。
半监督聚类有效利用了监督信息,相较于无监督聚类,其聚能性能得到了显著提升。现有方法主要通过随机选取样本进行标注以获取监督信息,这使得监督信息的质量难以保证。
1.2 主动学习
主动学习在机器学习领域中被广泛研究,通过标注尽可能少的样本,最大程度地提高模型的性能[18]。Lewis[19]提出基于池的主动学习查询如何标记最不确定的样本。Seung等人[20]提出的QBC(query-by-committee)算法基于一个委员会模型,委员会对候选样本的标签投票,被选出来的样本是那些意见最不一致的数据样本。Settles等人[21]提出用于判别概率模型类别的期望梯度长度(expected gradient length,EGL)方法,主要思想是挑选能够给当前模型带来最大变化的样本。Settles等人[22]又提出信息密度框架,其基本思想是挑选的样本不仅是不确定的,而且还应该代表输入数据的分布情况。
近年来,随着深度学习的发展,结合神经网络的深度主动学习逐渐成为领域研究热点。Sinha等人[23]提出的VAAL模型引入生成对抗网络用于标记样本的扩充。VAAL可以在大规模数据集上学习有效的低维潜在表示,并通过联合数据表示和不确定性进一步提供了一种有效的采样方法。后续Kim等人[24]提出TA-VAAL模型,同时利用了全局数据分布和模型不确定性共同进行样本挑选。Cho等人[25]提出一种快速且易实现的框架,称为主动学习的最大分类器差异(MCDAL)。该框架考虑利用多个分类器预测的差异性来构建主动学习的采样函数,以挑选最不确定的样本进行标记。
主动学习能够使用较少的标记样本训练出优秀的模型,从而在降低标记成本的同时不牺牲性能。但是,在半监督聚类任务中,主动学习如何挑选有价值的信息,目前的研究尚未提供清晰的解决思路。
2 模型设计
DASCM主要有文本语义表示学习模块、基于主动学习的半监督信息生成器和聚类模块三个部分组成,如图2所示。
2.1 文本语义表示学习模块
为了方便聚类,本文利用词袋模型[26]对文本数据进行编码,得到原始的向量表示X={x1,x2,…,xn}。
由于真实文本数据转为向量后,维度通常会变得很高。所以,本文利用自动编码器(auto-encoder,AE)对输入向量X={x1,x2,…,xn}降维并提取文本语义表示[27]。自动编码器使用了一组神经网络对输入数据进行非线性映射fθ:X→Z,其中θ是可学习的参数,Z就是网络学习到的文本语义表示。
AE主要分为编码器和解码器两个部分,其工作过程描述为
H(l)=φ(W(l)H(l-1)+b(l))(1)
其中:φ表示ReLU激活函数;W(l)和b(l)分别为第l层的权重和偏置。
AE通过缩小神经网络的输出X^和训练目标X的差距,根据式(2)优化神经网络参数,使其学习到更能代表原始数据的文本语义表示Z。
LAE=1n‖X-X^‖2F(2)
2.2 基于主动学习的半监督生成器
2.2.1 边缘文本挑选模块
在监督信息数量有限的情况下,所选择的监督信息应该对优化类簇结构具有较高的价值。在半监督聚类任务中,处于类簇边界的边缘文本具有极高的不确定性,蕴涵了更丰富的信息。因此,若监督信息涵盖边缘文本,则能为类簇的划分提供更多的信息,帮助优化类簇结构。本文提出的边缘文本挑选模块设计了基于主动学习方法的挑选机制,旨在发现类簇中蕴涵丰富信息的边缘文本,从而构建关系问题,进一步生成涵盖边缘文本的高质量监督信息。根据观察结果,本文所挑选的边缘文本满足以下特点:边缘文本大多处于两个或两个以上的类簇边界处,它们属于周围类的概率是相似的。例如,考虑第i个样本是边缘文本,该样本位于空间位置上第j和k个类的类簇边缘。在这种情况下,第i个样本同时属于第j和k个类的概率非常接近。这意味着边缘文本对于其所属类簇的归属是极其不确定的。基于上述特性,本文构造了式(3)来发现边缘文本。
E=argminxi-∑nj=1p(yj|xi)lg(p(yj|xi))(3)
其中:yj表示样本被分配到第j个类的事件;p(yj|xi)表示xi这个样本被分配到第j个类这个事件的概率;∑ni=1 ∑nj=1p(yj|xi)反映了当前聚类结构分布情况。本文基于最小化信息熵,挑选一批不确定性最高的边缘文本。
在半监督聚类中,监督信息多以约束对的形式出现。因此在挑选出边缘文本E={e1,e2,…,en}后,还需进一步使用边缘文本生成合适的约束对。本文的思路是:a)根据当前类簇划分确认聚类中心文本,即与聚类质心最相似的文本,聚类中心文本可以按照式(4)求得(μj表示第j个簇的聚类质心,sim(·)表示相似度的度量,从X={x1,x2,…,xn}中选择出文本ci,使得式(4)成立,即文本ci与聚类质心μj有最大相似度,那么文本ci被认定是第j个簇的中心文本)。b)构建关于边缘文本和中心文本的约束对。本文将获取边缘文本和中心文本的真实关系,进一步形成边缘文本-中心文本的关系对。这些关系对将作为半监督聚类中的监督信息,以优化类簇结构,提升聚类效果。
因此,如何获取边缘文本和聚类中心文本的关系尤为重要。本文首先设计一批关于边缘文本-中心文本的问题,该问题将边缘文本与中心文本一一对应,以关系对〈ei,cj〉的形式呈现,并将这些关系问题作为后续模块的输入,后续模块将给出明确的关于关系的答案。
argmaxci∑kj=1sim(ci,μj)(4)
2.2.2 基于主动学习的监督信息生成模块
本节基于主动学习的思想,旨在生成涵盖边缘文本的高质量监督信息,并利用该监督信息指导聚类过程。首先,将上一模块构建的关系问题通过标注过程,查询边缘文本与中心文本之间的真实关系,从而构建边缘文本-中心文本关系对。具体来说,如果当前的边缘文本ei与中心文本cj属于同一个类,那么在本文中,认为它们是存在联系的,将它们形成的关系对〈ei,cj〉加入到关系对集合R当中。最终,将得到一批涵盖了边缘文本的关系对,这批关系对能为聚类提供更丰富的信息。
接下来,要考虑如何将关系对用于指导聚类,帮助优化类簇结构。DASCM利用关系对构造半监督信息矩阵,用于引导聚类。半监督信息矩阵为n×n的对称矩阵M,Mij记录了样本xi与xj之间的关系。在本文中,设定有两种关系:a)ML约束,表示样本xi与xj属于同一类;b)CL约束,表示样本xi与xj不属于同一类。对称矩阵的构造如下:
Mij=1 (xi,xj)∈R0(xi,xj)R(5)
根据已获取的关系对,本文将属于同一类的边缘文本ei和中心文本cj对应的半监督信息矩阵的第i行和第j列的值设置为1,由于半监督信息矩阵为对称矩阵,Mji的值也设置为1。不属于同一类的文本所对应的值设置为0。
DASCM利用监督信息更新重构目标,以此学习到更好的文本语义表示,从而提升聚类效果。本文设计了式(6),利用半监督信息矩阵更新文本表示学习模块的训练目标,监督自编码器对文本语义表示的学习。
Y=M·X+X(6)
其中:M表示半监督信息矩阵;X表示文本向量表示。本文将重构目标更新,从而引导学习到的文本语义表示改变,进一步提升聚类效果。
本文利用主动学习方法发现类簇中蕴涵丰富信息的边缘文本,并通过查询边缘文本与中心文本的实际关系,构建基于边缘文本的关系对。本文利用这些关系对构造半监督信息矩阵,并利用这些监督信息指导聚类,从而提升聚类性能。
2.3 聚类模块
本节将学习到的文本语义表示点进行聚类,并不断调整参数得到更好的聚类结果。
在得到新的训练目标Y后,根据式(2),可进一步得到如下所示的目标函数:
LAE=1n‖X^-(M·X+X)‖2F(7)
其中:X^是AE的输出;M是利用监督信息生成的半监督信息矩阵,用于更新原来的重构目标。通过最小化损失函数LAE(式(7))得到所期望的文本语义表示Z。
给定文本语义表示学习模块学习好的文本语义表示和初始聚类质心,本文使用两个步骤交替的算法来改进聚类。a)计算文本语义表示点和类簇质心之间的软分配,即文本语义表示点属于每个类的概率;b)更新深度映射fθ,即更新神经网络的参数,旨在调整文本语义表示点以更好地对应聚类质心,并且利用辅助目标分布来优化聚类质心。交替进行这个过程,直到满足收敛标准。
t-分布能够减少异常点的影响,为了更好地适应不同分布的数据,本文采用t-分布来计算zi和μj之间的软分配。qij表示第i个文本属于第j个类的概率,公式如下:
qij=(1+‖zi-μj‖2/α)-α+12∑j′(1+‖zi-μj′‖2/α)-α+12(8)
其中:α是t-分布的自由度,在本文中设置为1。为了优化聚类质心,使用了如下所示的辅助目标分布。
pij=q2ij/fj∑j′q2ij′/fj′(9)
其中: fi=∑jq2ij是软类簇分配概率,辅助目标分布pij能够帮助强化预测。
DASCM通过匹配软分配与辅助目标分布来训练,为此,定义聚类损失函数为软分配和目标分布之间的KL散度损失(式(10))。
L=KL(P‖Q)=∑i ∑j(pijlogpijqij)(10)
算法1 DASCM模型的运算过程
输入:文本数据集;关系对数量b;最大迭代次数 MaxIter,预训练次数epochs,待学习的DASCM模型。
输出:文本聚类结果。
1)文本语义表示的学习
while 训练次数< epochs:
do 根据式(2)训练文本表示模块,更新模块神经网络参数W(l),b(l)
end
依据训练好的文本表示模块,根据式(1)得到初步的文本表示H
return H
2)聚类
使用K-means算法初始化聚类中心μ
while迭代次数< MaxIter:
do 使用式(8),根据Z和μ计算Q分布
使用式(9),根据分布Q计算目标分布P
根据式(10),更新模型参数
end
return 聚类结果
3)边缘文本挑选
根据得到的聚类结果,利用式(3)发现类簇边缘文本E
利用式(4)计算得到所有中心文本c,将每个边缘文本ei与中心文本cj一一对应,生成关系问题〈ei,cj〉
4)基于主动学习的监督信息生成
将所有关系问题组通过标注查询得到边缘文本与中心文本的实际关系,属于同一类的〈ei,cj〉加入关系对集R,最终得到数量为b的关系对
使用关系对集R通过式(5)构造半监督信息矩阵M
通过式(6),计算得到新的训练目标Y
return Y
将新的训练目标Y用于替换文本语义表示学习中的训练目标
再次运行1)2)两个过程
return 聚类结果
2.4 参数优化
在本文中,主要利用半监督信息矩阵M更新训练目标,利用损失函数(式(7))使得AE能够进一步学习到更好的文本语义表示Z。AE的参数为W,偏置为b,给定神经网络输出X^计算如式(11)所示。
X^=WX+b(11)
利用随机梯度下降(stochastic gradient descent,SGD)优化深度神经网络参数。损失函数LAE关于神经网络参数W求导为
LAE W=2n(WX+b-(MX+X))·XT(12)
对神经网络参数b求导,如式(13)所示。
LAE W=2n(WX+b-(MX+X))(13)
参数W的更新如下所示,其中η为学习率。
Wnew→Wold-η· LAE W(14)
参数b的更新如下所示。
bnew→bold-η· LAE b(15)
由于蕴涵丰富信息的半监督矩阵M参与了神经网络参数的更新,模型生成的高价值监督信息将正向引导神经网络训练。这能够帮助AE学习到更好的文本语义表示Z,使用更新的Z可以促进类簇的划分,从而达到更好的聚类效果。
2.5 模型时空复杂度分析
为了更好地阐明DASCM的效率,本文对该模型的时间和空间复杂度进行了分析。
本文设定输入数据的维度为d,数量为n。对于文本语义表示模块,设神经网络层数为L,各层输出维度分别为d1,d2,…,dL。时间复杂度为O(nd21d22…d2L),空间复杂度为O(nd)。对于聚类模块,设定类簇数量为k, 该模块与DEC的时空复杂度一致。时间复杂度为O(kn+n ln(n)),空间复杂度为O(kn)。
对于基于主动学习的监督信息生成模块,设定关系对数量为b,类簇数量为k。首先是边缘文本挑选部分,时间消耗主要在于边缘文本的挑选过程,时间复杂度为O(kn)。该部分需要存储边缘文本和中心文本,因此空间复杂度为O(b/k+k)。然后是基于主动学习的监督信息生成部分,因为本文模型将边缘文本和中心文本一一对应构造成关系对,所以时间复杂度为O(b),空间复杂度为O(b)。因为本文模型直接存储了关系对所对应的索引,所以半监督信息矩阵的时间复杂度为O(b),空间复杂度为O(n2+b)。
综上所述,本文DASCM总的时间复杂度为O(nd1d2…dL+2kn+n ln(n)+2b),总的空间复杂度为O(n2+(d+k)n+b/k+k+2b)。
3 实验与结果分析
本章将分析实验所需数据集,并在此基础上验证DASCM的效果,分别从数据集描述和评估方法、模型参数设置、结果和分析三个部分进行描述。
3.1 数据集描述
a)Abstract数据集(https://www.aminer.cn)。该数据集包含来自Aminer网站的 4 306 篇论文,从信息通信、数据库和图形三个研究领域中随机选择而来。该数据集通常应用于文本聚类任务,可参考文献[28]。
b)BBC数据集(http://mlg.ucd.ie/datasets/bbc.html)。该数据集包含来自BBC新闻网站的2 250条文本数据,对应商业、娱乐、政治、体育和科技五个主题。BBC数据集不同类别的文章数量相同,且文本主题特征比较明显,因此常被用于文本聚类任务,可参考文献[29]。
c)ACM数据集(https://paperswithcode.com/dataset/acm)。该数据集选择了在KDD、SIGMOD、SIGCOMM、MobiCOMM和VLDB上发表的3 025篇英文论文,并根据研究领域将论文分为数据库、无线通信和数据挖掘三类。数据集适用于文本聚类任务,可参考文献[30]。
d)Citeseer数据集(https://paperswithcode.com/dataset/ citeseer)。该数据集是一个引文网络,包含3 327条数据,涉及代理、人工智能、数据库、信息检索、机器语言和人机交互六个领域。数据集常应用于文本聚类任务,可参照文献[31]。
e)Reuters-10k数据集(https://github.com/slim1017/VaDE /tree/master/dataset/reuters10k)。该数据集选取了来自路透社的10 000条英语新闻故事,包含公司/工业、政府/社会、市场和经济这四个类别,常用于文本聚类或分类任务,可参考文献[2]。
3.2 评测指标
本文使用三种测量指标来评价聚类效果,分别是聚类精度(accuracy, ACC)、归一化信息(normalized mutual information,NMI)、调整兰德系数(adjusted Rand index,ARI)。
1)NMI
NMI用于衡量聚类的预测结果与标准结果之间的相似性,NMI 的取值在[0, 1],值越高表示预测的聚类结果越接近标准结果。计算如式(16)所示。
NMI(C;K)=2I(C;K)H(C)+H(K)(16)
其中:H(C)为预测聚类结果C的熵;H(K)为标准结果K的熵。计算如式(17)所示。
H(C)=-∑ni=1p(ci)log p(ci)(17)
其中:I(C;K)是C和K之间的互信息,代表联合分布p(C,K)与乘积分布p(C)p(K)的相对熵,其计算如式(18)所示。
I(C;K)=∑c ∑kp(c,k)logp(c,k)p(c)p(k)(18)
2)ACC
ACC是一种用于衡量聚类算法性能的指标,类似于分类问题中的准确率。它衡量的是聚类结果中被正确归类的样本所占的比例,其计算如式(19)所示。
ACC=maxm∑ni=11{li=m(ci)}n(19)
其中:li是真实标签;ci是模型预测的聚类分配;m(·)按照真实标签的排列方式,将聚类分配映射成标签结果。
3)ARI
调整兰德系数是一种用于衡量聚类算法性能的指标,通常用于评估聚类结果与真实标签之间的相似度。它的值越接近1,说明聚类结果越接近真实情况,计算如式(20)所示。
ARI=RI-E(RI)max(RI)-E(RI)(20)
RI(Rand index)是兰德系数,E(RI)是RI的期望。RI为
RI=TP+TNTP+FP+TN+FN(21)
其中:TP表示在真实标签中属于同一个类簇且在聚类结果中也被分到同一个簇的样本对的数量,这是聚类结果和真实标签都正确的样本对的数量;TN表示在真实标签中属于不同类簇且在聚类结果中也被分到不同簇的样本对的数量,这是聚类结果和真实标签都正确的样本对的数量;FP表示在真实标签中属于不同类簇但在聚类结果中被分到同一个簇的样本对的数量,这是聚类结果中错误分类的样本对的数量;FN表示在真实标签中属于同一个类簇但在聚类结果中被分到不同类簇的样本对的数量,这是聚类结果中错误分类的样本对的数量。
3.3 参数设置
本文使用自动编码器对数据集进行预训练,编码器维度设置为d-500-500-500-10,其中d为数据集的维度,解码器为编码器的镜像网络。针对所有数据集,均采用学习率η=0.01,β=0.9的优化器,批次大小为256,收敛阈值为0.1%。所有数据集的关系对数量b取1 000。每个数据集结果总共运行 10 次,并去掉最高值和最低值后算平均值,避免产生极端情况。
3.4 实验分析
3.4.1 文本聚类实验
本文在Abstract、BBC、ACM、Citesser、Reuters-10k共五个文本数据集上验证DASCM的聚类性能,并选择了三类聚类模型进行对比,分别是经典的深度聚类模型、发掘文本之间关联信息的聚类模型、深度半监督聚类模型和带主动学习模型。
a)经典的深度聚类模型。本文选择了三个经典的深度聚类模型作比较。AE[32]是学习文本语义表示并进行聚类的两阶段深度聚类模型。DEC基于AE引入KL散度,以联合优化文本语义表示和聚类两个过程。IDEC[33]对DEC进行改进,当学习文本语义表示时,在特征空间中保留了数据的局部结构信息。
b)发掘文本之间关联信息的聚类模型。GAE[34]将AE中的编码器和解码器换成图卷积网络(GCN)以学习图结构信息,SDCN[31]同时学习文本语义表示和文本结构表示,并采用双重自监督以优化学习表示和聚类两个过程。
c)半监督聚类模型。SDEC[15]是半监督的深度聚类模型,它基于DEC引入先验知识,以进一步优化模型提高聚类效果。
d)带主动学习的模型。ADC(active deep image clustering)[35]模型提出了一种新颖的深度主动聚类方法,该模型能主动选择关键数据进行人工标注,并用以改进深度聚类。
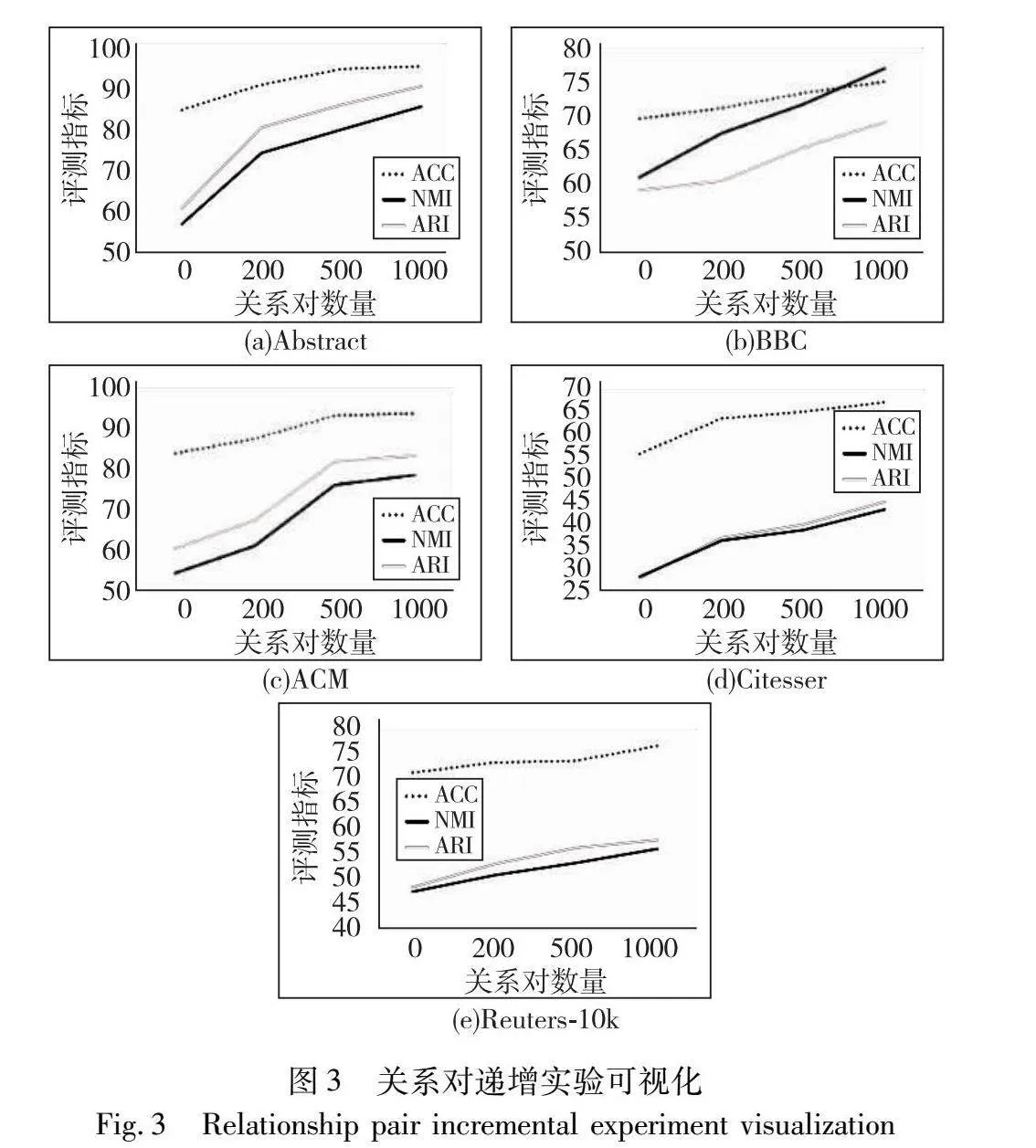
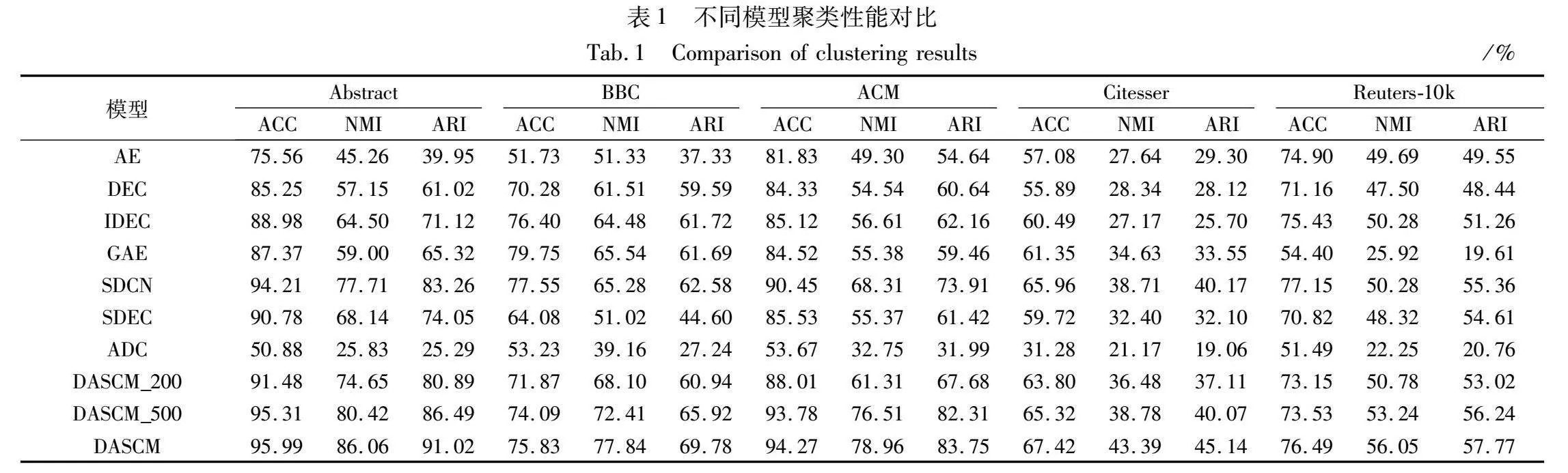
其他模型按照其文献给出的最优参数进行实验,ADC的约束对数量设置为1 000,训练轮次和批次的设置与DASCM一致。为进一步验证通过主动学习发现的边缘文本与聚类性能提升的相关性,DASCM选取不同数量的关系对(b=200、b=500、b=1 000)进行实验对比,实验结果如表1所示。
在五个真实数据集上的实验证明,DASCM 相较于其他无监督聚类模型在文本聚类结果的各项评测指标上都有明显提升,相较于所有模型中最优的聚类结果,NMI 指标分别提升了8.35,12.3,10.65,4.68和5.77百分点,这是因为本文提出的主动学习能够挑选出蕴涵丰富信息的边缘文本,并生成了涵盖边缘文本的高质量监督信息,从而进一步提升了聚类性能。这也证明了DASCM的有效性。
DASCM的各项评测指标也高于同为深度半监督聚类模型的SDEC,说明了基于主动学习的半监督信息生成器产生的监督信息比随机产生的监督信息对聚类更有意义。
然而含有主动学习的ADC表现较差,大概率是因为它是为处理图像数据而设计的,所以在文本数据集上表现不佳。
为了更加直观地展示模型性能随着关系对数量变化而变化,本文绘制了各指标对比的折线图,如图3所示。随着关系对数量的增加,各项指标也随之提升,这是因为给的关系对越多,所提供的信息越丰富。对聚类任务而言,蕴涵更多信息的关系对具有更高的价值,对聚类的指导作用更大。这一结果也证明了本文设计的主动学习方法的有效性。但同样可以观察到随着关系对数量的增加,各项聚类指标逐渐趋于平缓。这是因为随着关系对数量的增加,所生成的关系对可能会包含那些蕴涵信息量较少的样本,对聚类的指导作用不大,性能提升也不明显。
3.4.2 消融实验
为了验证基于主动学习的半监督信息生成器每个部分的有效性,本文在同样的5个数据集上对每个部分逐一消融实验,并与原模型的聚类性能对比,如表2所示。如果聚类性能都比原模型的低,则表明每个部分都是有效的。
DASCM-a去掉了基于主动学习的监督信息生成部分,其他部分与参数均与原模型保持一致。DASCM-a实验结果明显低于原模型,这是因为该模型没有生成涵盖边缘文本的监督信息,未能对聚类进行有效指导。
在DASCM-r中,边缘文本不再通过主动学习方法进行挑选,而是随机选取,其数量与DASCM模型中的设置保持一致。此外,DASCM-r的其余部分和参数也和原模型保持一致。DASCM-r的聚类性能同样也比原模型低,这是因为随机挑选的文本质量不佳,而通过主动学习方法挑选出的边缘文本蕴涵更丰富的信息。对聚类任务而言,涵盖边缘文本的监督信息也具有更高的价值,能更好地指导聚类。
3.4.3 可视化实验
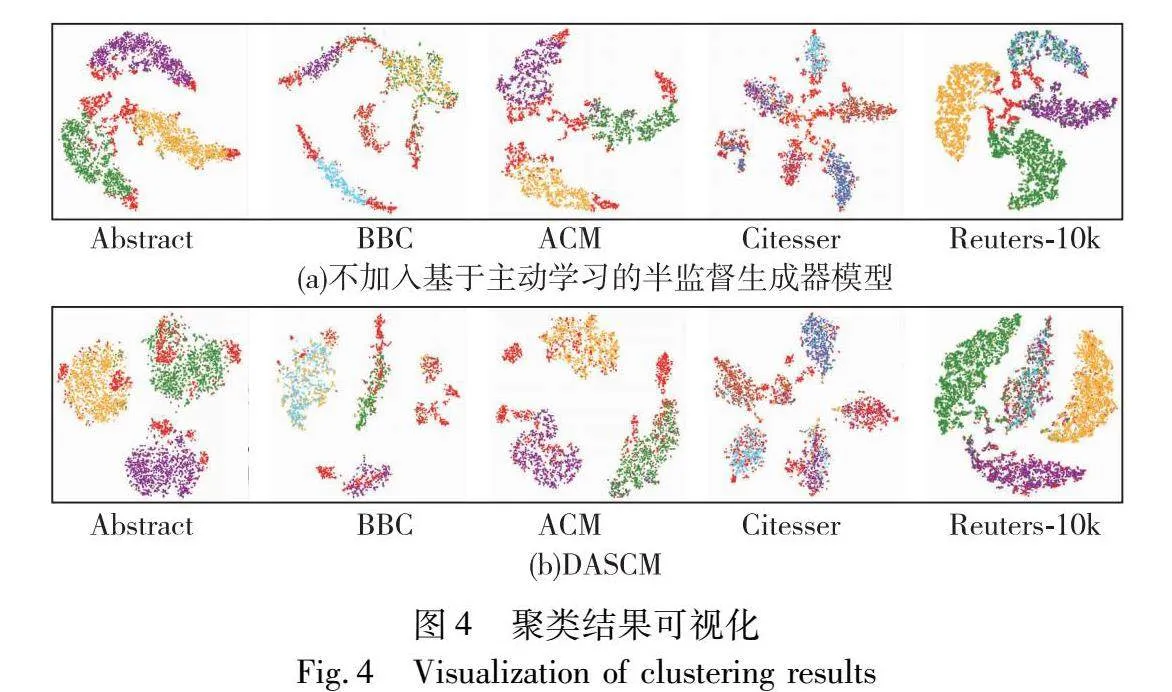
为了更加直观体现模型的有效性,本文对比了去除基于主动学习的半监督信息生成器的模型与DASCM的可视化聚类结果,可以直观感受到DASC模型有效提升了聚类性能。
图4展示了可视化聚类结果,其中图(a)表示未加入基于主动学习的半监督信息生成器的模型聚类结果,图(b)展示了DASCM的聚类结果。图4中红色的点(见电子版)表示边缘文本,在未加入基于主动学习的半监督生成器时,类簇的边界之间存在许多边缘文本,严重影响了聚类结构的清晰度。
加入基于主动学习的半监督生成器之后,聚类结构清晰度大大提升了,这是因为模型利用主动学习方法挑选出蕴涵丰富信息的边缘文本,并生成监督信息用于指导聚类过程。高价值的监督信息对聚类起到了正向引导作用,使得边缘文本所属类簇更加明确,类簇结构更加清晰。
3.4.4 主动学习代价分析
DASCM的代价主要由文本语义表示学习代价、主动学习挑选代价、标注代价和聚类代价四个部分组成。其中,文本语义表示学习成本和聚类成本类似于其他深度聚类模型。利用主动学习方法进行挑选的代价与数据集的规模密切相关。以BBC数据集为例(表3),可以观察到使用主动学习进行挑选的代价在整个模型中占比较小。
在主动学习中,人工标注是不可避免的,并且其成本也与数据规模有关,较大规模的数据集将需要更多的时间和资源进行标注。然而,相较于其他监督模型和半监督模型,DASCM花费同样的代价却能更大程度地提升模型性能。如表4所示,本文对比使用随机方法选取1 000对关系对作为监督信息(DASCM-r)和用主动学习方法选取1 000对关系对(DASCM)的聚类结果。可以注意到,当花费相同代价时,使用主动学习方法的模型性能可以得到更大提升。此外,本文挑选的关系对均为1 000对,而每个数据集可以组成上百万的关系对(n×n对),相较而言,这个代价也是可接受的。
3.5 实现过程
本文以Abstract数据集为例,详细描述DASCM的实现过程。如图2所示,首先模型学习数据的文本语义表示,接着将学习到的文本语义表示进行聚类,得到初步的聚类结果。最后,DASCM根据当前聚类结果挑选边缘文本。如图5所示,图5(a)展示了基于初步聚类结果挑选边缘文本的结果。本文将每个类的边缘文本颜色高亮展示,以示区分。
边缘文本处于各个类的交界处,具有极高的不确定性,同时它们也蕴涵丰富的信息。为了进一步利用这些边缘文本指导聚类。本文选择将它们与中心文本(第一幅图中加粗加黑的文本点)对应,以关系对的形式作为监督信息。图5(b)展示了关系对的构造过程(因边缘文本太多,本文只随机选取5个边缘文本点进行演示)。本文将边缘文本(红圈标明部分,参见电子版)与全部的中心文本一一对应,将这些文本对通过人工标注,标注过程详见2.2.2小节。接着本文根据关系对构造了一个半监督信息矩阵,该矩阵是一个n×n的对称矩阵,维度与数据集大小一致。
随后矩阵将被用于更新重构目标,方法如式(6)所示。本文选取其中一个边缘文本观察其重构目标的高频词变化(图5(c))。该边缘文本真实的类别应该为数据库,更新后增加了table、data等与数据库主题相关的词语,能够帮助学习到更好的文本语义表示。最后模型将根据更新后的重构目标学习新的文本语义表示,进而将其用于聚类。图5(d)展示了新的聚类结果,与图5(a)比较,边缘文本更加靠近其所属类簇,类簇划分也更加清晰。
4 结束语
本文提出一种基于主动学习的深度半监督聚类模型(DASCM),该模型利用主动学习方法挑选出类簇的边缘文本,并构建了边缘文本-中心文本关系对,为半监督聚类提供了高质量的监督信息。本文利用这些关系对进一步构建了半监督信息矩阵,显著提升了聚类效果。
在五个真实数据集上的实验结果证明,相较于其他模型,DASCM在聚类性能上有明显提升。然而,DASCM关系对的数量是给定的,当聚类结果中边缘文本数量较少时,模型仍会挑选出给定数量的边缘文本,这可能导致资源的浪费。因此,下一步的研究方向是设计一种衡量已挑选的样本和未挑选样本之间关联度的方法,以避免选取对类簇划分贡献相似的样本。此外,在训练过程中,该方法设置合适的条件,一旦选取的样本不再对类簇划分产生优化或其作用变得微不足道,将停止选取。
参考文献:
[1]Ezugwu A E, Ikotun A M, Oyelade O O,et al. A comprehensive survey of clustering algorithms: state-of-the-art machine learning applications, taxonomy, challenges, and future research prospects[J]. Engineering Applications of Artificial Intelligence, 2022, 110: 104743.
[2]Xie Junyuan, Girshick R, Farhadi A. Unsupervised deep embedding for clustering analysis [C]// Proc of the 33rd International Confe-rence on Machine Learning. [S.l.]: PMLR, 2016: 478-487.
[3]Cai Jianghui, Hao Jing, Yang Haifeng,et al. A review on semi-supervised clustering[J]. Information Sciences, 2023, 632: 164-200.
[4]Liu Yuqiao, Sun Yanan, Xue Bing,et al. A survey on evolutionary neural architecture search[J]. IEEE Trans on Neural Networks and Learning Systems, 2021, 34(2): 550-570.
[5]张贤坤, 刘渊博, 任静, 等. 主动纠错式半监督聚类社区发现算法[J]. 计算机应用研究, 2019, 36(9): 2631-2635, 2660. (Zhang Xiankun, Liu Yuanbo, Ren Jing,et al. Active error-correcting community discovery algorithm based on semi-supervised clustering[J]. Application Research of Computers, 2019, 36(9): 2631-2635, 2660.)
[6]Ren Pengzhen, Xiao Yun, Chang Xiaojun,et al. A survey of deep active learning[J]. ACM Computing Surveys, 2021, 54(9): 1-40.
[7]Menin B. Unleashing the power of information theory: enhancing accuracy in modeling physical phenomena[J]. Journal of Applied Mathematics and Physics, 2023, 11(3): 760-779.
[8]李静楠, 黄瑞章, 任丽娜. 用户意图补充的半监督深度文本聚类[J]. 计算机科学与探索, 2023, 17(8): 1928-1937. (Li Jingnan, Huang Ruizhang, Ren Lina. Semi-supervised deep document clustering model with supplemented user intention[J]. Journal of Frontiers of Computer Science and Technology, 2023, 17(8): 1928-1937.)
[9]Bair E. Semi-supervised clustering methods[J]. Wiley Interdisciplinary Reviews: Computational Statistics, 2013, 5(5): 349-361.
[10]Taha K. Semi-supervised and un-supervised clustering: a review and experimental evaluation[J]. Information Systems, 2023, 114: 102178.
[11]Shen Baohua, Jiang Juan, Qian Fuan,et al. Semi-supervised hierarchical ensemble clustering based on an innovative distance metric and constraint information[J]. Engineering Applications of Artificial Intelligence, 2023, 124: 106571.
[12]Basu S, Bilenko M, Mooney R J. Comparing and unifying search-based and similarity-based approaches to semi-supervised clustering[C]// Proc of ICML-2003 Workshop on the Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining Systems. New York: ACM Press, 2003: 42-49.
[13]Kodinariya T M, Makwana P R. Review on determining number of cluster in K-means clustering[J]. International Journal, 2013, 1(6): 90-95.
[14]Wagstaff K, Cardie C. Clustering with instance-level constraints[C]// Proc of the 7th International Conference on Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc., 2000: 1103-1110.
[15]Ren Yazhou, Hu Kangrong, Dai Xinyi,et al. Semi-supervised deep embedded clustering[J]. Neurocomputing, 2019, 325: 121-130.
[16]Ohi A Q, Mridha M F, Safir F B,et al. AutoEmbedder: a semi-supervised DNN embedding system for clustering[J]. Knowledge-Based Systems, 2020, 204: 106190.
[17]Wang Yalin, Zou Jiangfeng, Wang Kai,et al. Semi-supervised deep embedded clustering with pairwise constraints and subset allocation[J]. Neural Networks, 2023, 164: 310-322.
[18]Nguyen V L, Shaker M H, Hüllermeier E. How to measure uncertainty in uncertainty sampling for active learning[J]. Machine Learning, 2022, 111(1): 89-122.
[19]Lewis D D. A sequential algorithm for training text classifiers: corrigendum and additional data[C]// Proc of ACM SIGIR Forum. New York: ACM Press, 1995, 29(2): 13-19.
[20]Seung H S, Opper M, Sompolinsky H. Query by committee[C]// Proc of the 5th Annual Workshop on Computational Learning Theory. New York: ACM Press, 1992: 287-294.
[21]Settles B, Craven M, Ray S. Multiple-instance active learning[C]// Proc of the 20th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc., 2007: 1289-1296.
[22]Settles B, Craven M. An analysis of active learning strategies for sequence labeling tasks[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2008: 1070-1079.
[23]Sinha S, Ebrahimi S, Darrell T. Variational adversarial active lear-ning[C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2019: 5972-5981.
[24]Kim K, Park D, Kim K I,et al. Task-aware variational adversarial active learning[C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2021:8166-8175.
[25]Cho J W, Kim D J, Jung Y,et al. MCDAL: maximum classifier discrepancy for active learning[J]. IEEE Trans on Neural Networks and Learning Systems, 2022, 34(11): 8753-8763.
[26]Gálvez-López D, Tardós J D. Real-time loop detection with bags of binary words[C]// Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2011: 51-58.
[27]任丽娜, 秦永彬, 黄瑞章, 等. 基于多层子空间语义融合的深度文本聚类[J]. 计算机应用研究, 2023, 40(1): 70-74, 79. (Ren Li’na, Qin Yongbin, Huang Ruizhang,et al. Deep document clustering model via multi-layer subspace semantic fusion[J]. Application Research of Computers, 2023, 40(1): 70-74, 79.)
[28]黄瑞章, 白瑞娜, 陈艳平, 等. CMDC: 一种差异互补的迭代式多维度文本聚类算法[J]. 通信学报, 2020, 41(8): 155-164. (Huang Ruizhang, Bai Ruina, Chen Yanping,et al. CMDC: an iterative algorithm for complementary multi-view document clustering[J]. Journal on Communications, 2020, 41(8): 155-164.)
[29]Greene D, Cunningham P. Practical solutions to the problem of diagonal dominance in kernel document clustering[C]// Proc of the 23rd International Conference on Machine Learning. New York: ACM Press, 2006: 377-384.
[30]Wang Xiao, Ji Houye, Shi Chuan,et al. Heterogeneous graph attention network[C]// Proc of World Wide Web Conference. New York: ACM Press, 2019: 2022-2032.
[31]Bo Deyu, Wang Xiao, Shi Chuan,et al. Structural deep clustering network[C]// Proc of Web Conference. New York: ACM Press, 2020: 1400-1410.
[32]Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[33]Guo Xifeng, Gao Long, Liu Xinwang,et al. Improved deep embedded clustering with local structure preservation[C]// Proc of the 26th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2017: 1753-1759.
[34]Wang Wei, Huang Yan, Wang Yizhou,et al. Generalized autoenco-der: a neural network framework for dimensionality reduction[C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE Press, 2014: 496-503.
[35]Sun Bicheng, Zhou Peng, Du Liang,et al. Active deep image clustering[J]. Knowledge-Based Systems, 2022, 252: 109346.
