基于多视图证据融合的社交水军检测
2024-10-14张东林徐建










摘 要:为克服单视图水军检测方法在处理复杂多样的社交网络数据时所存在的局限性,并解决现有多视图融合方法未能充分考虑视图间质量差异导致的信息丢失和噪声干扰等问题,提出一种基于多视图证据融合(multi-view evidence fusion,MVEF)的社交水军检测方法。该方法综合分析社交关系、行为特征和推文内容三个视图并提取关键证据,通过Dirichlet分布参数化来评估每个视图在分类决策中的类别可信度和整体不确定性。通过高效的证据融合机制,巧妙地利用不确定性整合各视图中的关键证据,构建一个全面而可靠的分类决策框架。实验结果显示,MVEF在两个真实世界的Twitter数据集上的表现均优于现有方法,有效提升了水军识别的准确率和鲁棒性。
关键词:社交水军检测;多视图;证据融合;不确定性
中图分类号:TP391.4 文献标志码:A 文章编号:1001-3695(2024)10-009-2939-08
doi:10.19734/j.issn.1001-3695.2024.02.0039
Social spammer detection based on multi-view evidence fusion
Zhang Donglin, Xu Jian
(School of Computer Science & Engineering, Nanjing University of Science & Technology, Nanjing 210094, China)
Abstract:To address the limitations of single-view spammer detection methods in processing complex and diverse social network data, and the issues of information loss and noise interference due to existing multi-view fusion methods not fully consi-dering the quality differences between views, this paper proposed a social spammer detection method based on MVEF. The method integrated and analyzed three views: social relationships, behavioral characteristics, and tweet content, to extract pi-votal evidence. It employed Dirichlet distribution parameterization to assess the category credibility and overall uncertainty of each view in classification decisions. Through an efficient evidence fusion mechanism, the method skillfully utilized uncertainty to integrate key evidence from various views, constructing a comprehensive and reliable classification decision framework. Experimental results demonstrate that MVEF outperforms existing methods on two real-world Twitter datasets, effectively enhancing the accuracy and robustness of spammer detection.
Key words:social spammer detection; multi-view; evidence fusion; uncertainty
0 引言
近年来,随着智能手机和移动互联网的普及,社交平台如Twitter和Facebook已成为人们日常交流和信息分享的重要渠道。然而,这些平台庞大的用户基数和低成本的信息发布特性,也吸引了大量水军。这些水军通过发布虚假信息、恶意评论和刷点赞等行为,试图操纵网络舆论,制造虚假声势。这些恶意行为不仅影响用户体验,而且严重破坏公信力,冲击正常的网络秩序。因此,研究如何从众多社交媒体账户中有效地检测出水军已成为一个紧迫的问题。
社交水军检测问题本质上是一个二元分类问题。早期研究通常集中于分析用户在某一特定方面的信息,即利用单一视图特征检测账户类别。这些方法依据水军和普通用户在社交平台上的不同行为模式和关注关系等,试图揭示它们之间的显著差异。虽然这些单一视图方法在一定程度上能够识别出水军,但由于水军策略的不断演变和技术的快速发展,这些方法的准确性和鲁棒性面临着严峻的挑战。
针对单视图方法难以全面、及时地捕捉水军的特征,一些学者开始探索多视图融合方法来解决这一问题。例如,Chen等人[1]尝试手动构建多维度特征并应用主动学习与协同训练算法,但这种方法在处理社交关系和推文数据时,往往难以捕捉复杂的非线性关系。Li等人[2]则从不同视图中提取特征,采用相关梯形网络和过滤门组件捕捉跨视图相关性进行特征学习,但可能因特征差异或冗余引入噪声。Liu等人[3]利用用户个人特征和消息内容特征计算先验类别,再利用社交网络将稀疏标签扩散到未标记的样本。虽然可以应对大数据稀疏标签的挑战,但是对初始先验标签的依赖较大。这些尝试表明,尽管特征级的多视图融合方法在理论上能提供更丰富的信息,但在实际应用中仍面临诸多挑战,如特征融合的有效性、不同视图间质量的平衡和噪声处理等。
在探讨多视图融合方法时,还需指出传统的决策级融合方法的一些局限。这些算法多采用固定权重分配,一些算法假设所有视图对样本分类的影响相同,从而分配相等权重。另一些算法则根据视图间整体的质量差异调整权重分配。然而,实际数据集中不同样本的视图间质量差异往往不同。如果简单地利用固定权重加权每个视图的分类结果,最终可能得到不可靠的分类决策。
为解决上述挑战,本文提出了一种多视图证据融合方法(MVEF),旨在高效精准地检测社交平台上的水军。该方法首先根据不同视图数据的独特性质,采用专门的基础分类器来学习视图特征,并通过非负激活函数提取决策所需的关键证据;接着,利用Dirichlet分布模拟类概率的分布,从多个视图角度出发对证据进行参数化,进而对视图预测的类别可信度和总体不确定性进行精确建模;最后,综合考虑不同视图证据间的相似性和冲突性,通过基于Dempster-Shafer(DS)理论的合并规则,有效地整合多方证据以形成最终分类决策。综上所述,本文的具体贡献有:
a)引入了基于证据的不确定性估计[4]技术,有效量化视图分类的不确定性,反映视图间的质量差异和噪声水平,为融合过程中的风险评估提供可靠基础,增强了方法的鲁棒性。
b)创新性地提出了一种决策级的证据融合算法用于社交水军检测。与现有的决策级融合模型不同,该算法特别关注每个视图的决策风险,并综合考虑它们间的共同支持,从而生成可信且可靠的分类决策。
c)实验表明,MVEF方法显著优于现有方法,在Twitter SH和1KS-10KN两个真实世界的Twitter数据集上的准确率分别达到了93.95%和97.41%。
1 相关工作
随着社交网络的快速发展,社交水军的检测已经引起了广泛的关注。现有的水军检测方法主要分为基于单一视图和基于多视图融合两类。
1.1 基于单一视图
单视图方法根据数据源的不同主要分为内容分析、用户行为分析和社交关系分析三类。内容视图通过深入探索文本的语义、情感和主题分布等特征,可以有效揭示水军发布内容的特殊模式,如文本的重复性、含恶意链接[5]和强烈情感极性[6]等。例如,Ghanem等人[7]应用Bi-LSTM和上下文嵌入技术,挖掘推文的语义特征。用户行为视图专注于分析水军的个人资料和日常行为特征,如关注数、粉丝数、发布频率[8]、转发次数[9]等,以识别异常活动。这种方法可以直接反映出水军的特异行为和社交模式。例如,Yin等人[10]提出一种多层次依赖模型,通过分析用户行为关系序列,有效识别水军行为特征。社交关系视图则侧重于挖掘用户间的社交互动,如关注和转发行为,来识别社交网络中的异常组织结构[11]。其优势在于可以通过网络结构洞察水军的协调和执行策略。例如,李宁等人[12]基于评论者的共评关系时序网络形成时序邻居序列,进而生成候选群组集合,最后通过造假指标排序识别出游离水军群组。Wang等人[13]基于社交网络中的有向图,利用成对马尔可夫随机场和环形信念传播来模拟用户状态的联合概率。尽管这些方法能够提供针对单一视图的深入洞察,但在识别水军的多样性和复杂性上不足,影响了识别的准确性和效率。
1.2 基于多视图融合
为应对日益狡猾且多样化的水军行为,一些学者考虑采用多视图融合的方式来解决这个问题,具体又可以分为特征级融合和决策级融合两种。在表1中,详细列出了目前基于多视图融合的方法所采用的视图,以及它们所属的类别。
特征级融合旨在整合不同视图的信息,构建全面的特征集,以提高水军行为检测的效率和准确性。为捕捉跨视图的相关性,Li等人[2]采用了相关梯形网络对单视图的特征进行深入学习,并通过过滤门组件实现了多视图数据的有效整合。张琪等人[14]结合评论者关系网络和评论行为特征,通过构建评论者关系图和利用标签传播方法检测社区,有效地识别出水军群组。Zhang等人[15]从用户的四个不同维度提取特征,并运用CatBoost算法结合半监督下的最大对比悲观似然估计进行分类。Deng等人[16]提出一种马尔可夫驱动图卷积网络,充分利用富文本特性和用户关注关系,极大地提高了水军检测的能力。而Shen等人[17]则使用矩阵分解技术深度挖掘推文内容信息,并与社交互动数据相结合,优化社交用户的特征表示。
在决策级融合的方法中,不同的视图由各自的分类器独立处理,避免了视图间噪声和误差的累加,其结果通过一系列策略集成,以期获得更精准的检测结果。例如,Chen等人[18]利用基础分类器获取各视图的分类结果,并通过线性加权求和函数结合学习到的固定权重,实现预测结果的动态整合,但其权重的静态性会限制其适应水军策略变化的能力。Wu等人[19]利用半监督学习框架协同训练垃圾信息发送者分类器和垃圾信息分类器,并通过多个正则化项控制用户间关注关系、消息间的连接关系以及用户和消息之间的发布关系以实现决策级融合,但是同样存在动态适应性较差的问题。另外,Liu等人[20]提出了一种基于证据推理(evidential reasoning,ER)规则的多分类器信息融合模型,将不同视图的分类结果转换为信念度分布,并在决策层利用ER规则进行整合。
与现有工作不同,多视图证据融合方法(MVEF)有效克服了特征级融合中的特征冗余和视图质量不平衡问题,提高了方法对社交网络数据的适应性和鲁棒性。与其他决策级融合方法相比,MVEF根据社交用户各个视图中提取的证据,动态地获取视图的类别信念质量和不确定性以整合多视图的决策,使得其在面对各视图质量显著差异时,可以灵活调整以利用视图间的互补性,确保了整体预测的可靠性和稳健性。
2 背景知识
2.1 不确定性与证据理论
在深度学习中,softmax激活函数被广泛用于将神经网络输出转换成概率分布。然而它有一个潜在的缺陷,即可能导致模型过度自信[21],无法有效反映预测的不确定性。为解决这一问题,Sensoy等人[4]提出了证据深度学习(evidence deep learning,EDL)的概念,旨在量化分类任务中的不确定性。EDL基于DS理论构建,后者定义证据为对一组假设的信念强度,代表可能的真实情况。以二元分类为例,假设框架包含两个代表不同类别的基本假设。EDL应用主观逻辑(subjective logic,SL)将DS理论中的信念分配在识别框架中形式化为Dirichlet分布,并实现了可信度和不确定性的量化。对于K分类中每个样本,SL分配了K个类别的可信度ck和不确定性u,并满足
u+∑Kk=1ck=1(1)
其中:当k=1,…,K时,u≥0,ck≥0。在单个实例中,主观逻辑首先利用αk=ek+1将证据集e=[e1,e2,…,eK]转换为Dirichlet分布的参数α=[α1,α2,…,αk]。然后,可信度ck和整体不确定性u可以很容易地通过对应类的证据计算出:
ck=ekS=αk-1S(2)
u=KS(3)
其中:S=∑Kk=1(ek+1)=∑Kk=1αk为Dirichlet强度。由式(2)可以发现,第k类提供的证据越多,其分配到的可信度就越高。而式(3)则表明所有类别提供的证据总和越多,那么分类的总体不确定性就越低,从而得到更加可信的分类结果。
2.2 Dirichlet分布与证据理论的结合
Dirichlet分布是一种用于描述概率质量函数p可能取值的概率密度函数。在K分类问题中,可以通过以下公式定义:
D(p|α)=1B(α)∏Kk=1pαk-1k for p∈SK
0otherwise(4)
其中:B(α)是K维多项Beta函数;而SK是K维单位单纯形。在此框架中,p∈△K-1,给定一种观点,第k个单例的期望概率k等于对应Dirichlet分布的均值,计算公式为
k=αkS=ek+1∑Kk=1ek+K(5)
在证据深度学习(EDL)框架内,样本数据中与特定类别相关的特征构成“证据”,促使该类别对应的Dirichlet参数增加。随着证据的不断积累,参数的变化反映了对分类概率分布的动态理解与调整,使得Dirichlet分布成为量化分类预测不确定性的关键工具。
3 方法
3.1 问题描述
在社交水军检测背景下,社交网络S表示为S=(U,R,B,T,Y),在这个网络中包含有一组社交用户u∈U={u1,u2,…,un},一组用户节点的社交关系嵌入向量r∈R,一组用户行为特征向量b∈B,以及一组用户推文特征向量t∈T,以及一组用户标签y∈Y。基于给定符号,社交水军检测的问题正式定义如下:
给定一组标签用户UlU,标签用户的社交关系矩阵Rl,行为特征矩阵Bl,推文特征矩阵Tl,以及他们的身份标签YlY,社交水军检测的目标是在未标记的用户集合Uul=U-Ul中准确识别水军。形式上,水军检测旨在学习社交网络中用户的联合概率分布,这一分布取决于用户的社交关系嵌入、行为特征以及推文内容特征,即p(yU∣rU,bU,tU),然后根据预测出的最高概率类别来判定一个社交用户是水军还是合法用户。
3.2 方法框架
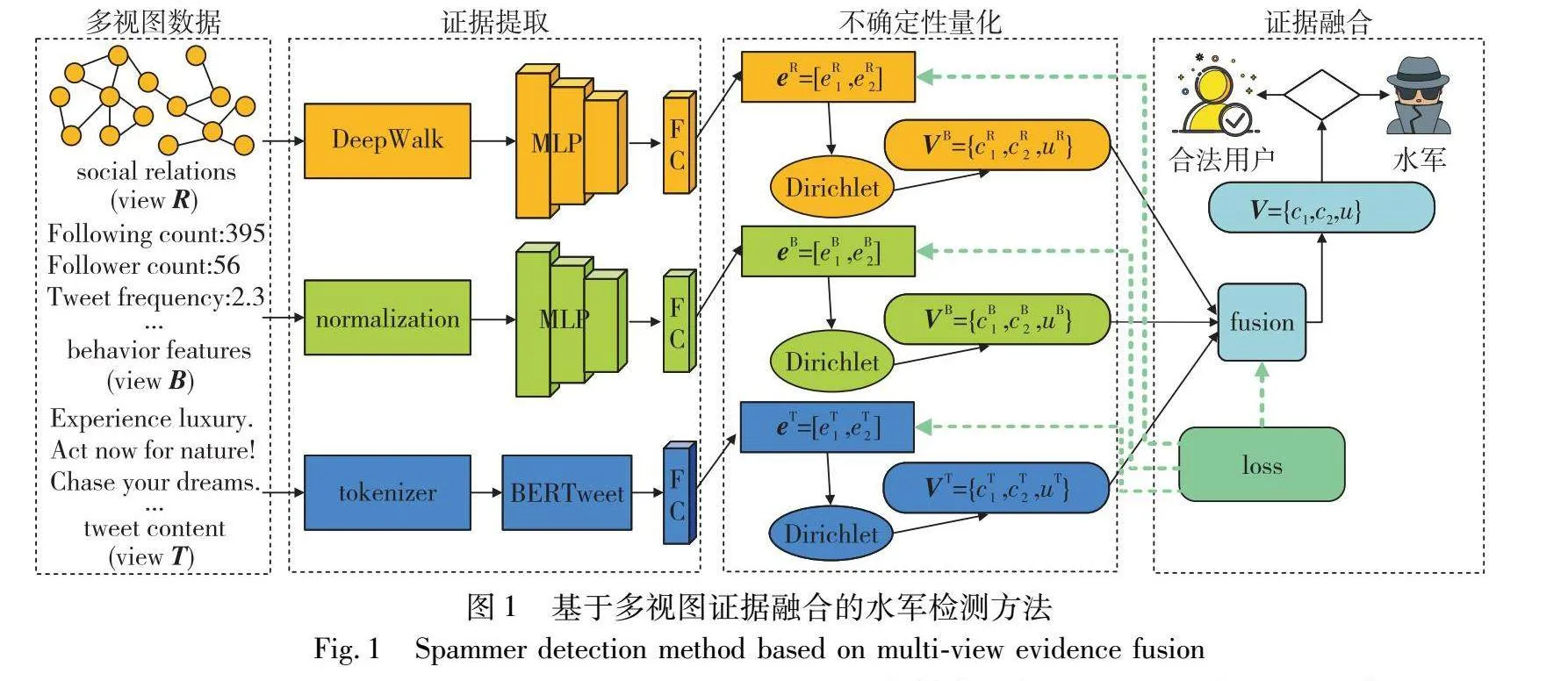
如图1所示,MVEF方法主要由三部分构成。第一部分是证据提取。对给定输入社交网络的三个视图数据进行预处理以满足分类器的输入需求。如,对社交关系网络生成节点嵌入,对行为特征进行标准化处理,将原始推文输入tokenizer处理。随后,在社交关系视图和行为特征视图中,应用多层感知机(multilayer perceptron,MLP)来学习特征。对于推文内容视图,则利用BERTweet预训练模型来深入挖掘文本特征。最后都将学习到的特征传输到具有非负激活函数的全连接层,以提取用于不确定性计算的证据。第二部分是不确定性量化。将各个视图获取到的证据参数化Dirichlet分布,以推导对应的类别可信度和整体不确定性。第三部分是证据融合。设计一个组合规则,根据每个视图的不确定性,并结合它们的类别可信度,从而推断出多视图融合后的类别可信度和总体不确定性,以判断用户的最终类别(水军或合法用户)。这一策略能够充分利用每个视图的不确定信息,降低决策风险,从而生成可信的分类结果。
3.3 证据提取
3.3.1 社交关系视图
社交关系网络定义为一个有向图G=(V,E)。其中:V是节点集合,代表社交网络中用户;E是边集合,表示用户之间的关注关系。传统方法主要关注数据集内部节点V之间的直接关系,可能无法获取到全面丰富的社交关系信息。为解决这一问题,转向社交网络同质性理论[22]的应用。该理论基于一个关键假设,即社交网络中的用户倾向于和与自己有相似特征或行为的用户建立联系。如果两个用户没有直接联系,但他们有许多共同的朋友,那么这两个用户之间可能存在某种形式的间接关系。
为了将这一理论应用于方法,定义了一种新的社交关系提取方法。
算法1 包含直接和间接关系的社交关系提取方法
输入:原始有向图G=(V,E)。
输出:扩展的有向图G=(V,E)。
1 初始化:V′=V,E′=E,V″=empty,E″=empty
2 for u in V:
3 for v not in V:
4 if u follows v or v follows u: /*寻找u所有不在V中的关注节点和粉丝节点*/
5 V′.add(v) //添加到新的节点集V′
6 E′.add((u,v)) or E′.add((v,u))
7 for v in (V′-V):
8 inDegree, outDegree=calculate_degree(v) /*计算节点的入度和出度*/
9 if inDegree >= 2 or outDegree >= 2:
10 V″.add(v) // 添加到共享邻居集V″
11 for (u,v) in E′:
12 if (u in V and v in V″) or (v in V and u in V″):
13 E″.add((u,v)) // 添加到新的扩展边集
14 V=V∪V″
15 E=E∪E″
16 return G=(V,E)
鉴于新扩展的社交关系图G可能包含大量的间接关系,从而显著增加了图的规模,而DeepWalk的高效率和低计算复杂度使其特别适合处理这种大型图,同时能够有效地捕捉节点间的结构特性。因此,将社交关系网络转换为无向图,并使用DeepWalk算法(使用了PecanPy,可以通过并行化和优化加速DeepWalk算法)来生成节点嵌入,可以形式化表示为
R=DeepWalk(G,l,r,d)(6)
其中:l是随机游走的长度,设为80;r是每个节点的游走次数,设为20;d是每个节点生成嵌入向量的维度,设为256;R∈Euclid ExtraaBpn×d是生成的节点嵌入矩阵。
为有效处理这些高维数据,避免因模型过于复杂而导致的过拟合问题,采用多层感知机(MLP)作为主干网络来学习这些节点嵌入。MLP的多层结构和非线性激活函数使其能够有效捕捉和转换节点嵌入中的非线性关系,这对于深入理解社交网络的复杂动态并准确地进行分类至关重要。在MLP的基础上,进一步通过一个全连接层(fully connected layer,FC)和非负激活函数Softplus来生成社交关系视图的证据。基于这些考虑,社交关系视图部分的模型结构可以简洁地表示为
OutR=ReLU(Linear(…ReLU(Linear(r))…))(7)
eR=Softplus(FC(OutR))(8)
其中:r∈Euclid ExtraaBp1×d是DeepWalk算法生成的单个节点嵌入向量;OutR是主干网络MLP的输出;eR则是社交关系视图提取的证据。
3.3.2 行为特征视图
借鉴现有文献特征工程提取的行为特征,并注意到在预处理原始推文时常忽略含有重要信息的社交媒体符号,又从推文视图中额外补充三个关键特征。综合这些,共筛选出九个重要特征,并在表2中进行了详尽展示。所选特征在量纲和分布范围上存在较大差异,因此采用了标准化处理以统一特征的数值范围到相同标准尺度,从而构建行为特征矩阵B。
由于这些行为特征具有多样性和复杂性等特点,使用与社交关系视图相同的神经网络结构,包括MLP、FC和Softplus激活函数,来生成行为特征视图的证据。其网络结构可以表示为
OutB=ReLU(Linear(…ReLU(Linear(b))…))(9)
eB=Softplus(FC(OutB))(10)
其中:b是单个社交用户的特征向量;eB则是行为特征视图的证据。
3.3.3 推文内容视图
数据集中一般包含每个用户发布的若干条推文,单独处理每条推文将难以与其他视图的数据有效整合。为此,将同一用户的所有推文按时间逆序拼接,从而创建一个综合的用户文本表示。由于推文中的语言和表达形式通常与传统书面语料库中的文本有所不同,所以如何有效地理解用户在社交媒体上发布的文本内容是关键问题。为此,选择了BERTweet[23]作为推文内容视图部分的模型,与通用的BERT和RoBERTa模型不同,它是专门针对推文优化的预训练模型(https://huggingface.co/vinai/bertweet-large)。这种针对性的训练使其在理解和处理推文特有的非标准语言和表达方式方面表现卓越,能够更准确地从文本中提取丰富的语义信息及上下文关系。所以,首先使用BERTweet的tokenizer将这个长句子转换成模型可处理的格式:
(input_ids,attention_mask)=tokenizer(Tweet)(11)
其中:Tweet是用户所有推文拼接后的长文本;input_ids是标记化文本的索引序列;attention_mask是二进制掩码,用于控制模型的注意力机制。然后,通过BERTweet预训练模型对预处理后的文本进行特征学习,并通过全连接层和Softplus激活函数生成视图的证据:
BERTweetOut=BERTweetinput_ids,attention_mask(12)
eT=Softplus(FC(BERTweetOut))(13)
其中:eT表示从推文内容视图中提取的证据。
3.4 不确定性量化
通过证据提取模块,社交关系视图R、行为特征视图B和推文内容视图T三个关键视图,均贡献了一组独特的证据,分别用eR、eB、eT表示。这些证据不仅捕捉了各视图的独特属性,也为后续的分析提供了关键的信息。接着,根据第2章讨论的原理,特别是引用式(2)和(3),将这些证据巧妙地映射到各自视图的类别可信度和不确定性上。具体来说,对于社交关系视图R,将其证据eR映射为VR={cR1,cR2,uR};行为特征视图B的证据eB映射为VB={cB1,cB2,uB};推文内容视图T的证据eT映射为VT={cT1,cT2,uT}。
3.5 证据融合
在MVEF方法中,针对社交网络的多视图数据,采用了一种基于DS理论的创新证据融合策略。该策略通过合并规则整合来自不同视图的证据,评估证据间的相似性和冲突性,生成综合的信任度函数,为最终分类提供量化的置信度。为了应对二元分类问题的特殊需求,设计了简化的Dempster组合规则,以减少输入证据的数量并降低融合过程的复杂性。这种简化在降低计算难度的同时,仍保留了DS理论的核心—不确定性融合,确保了更可信的分类结果。
具体地,在不确定量化后,得到三个视图的观点VR={cR1,cR2,uR},VB={cB1,cB2,uB},VT={cT1,cT2,uT},并据此计算了融合后的决策观点V={c1,c2,u},计算如下:
ck=1λ cRkcBkcTk+(1-uR)cRk+(1-uB)cBk+(1-uT)cTk(14)
u=1λ(1-uR)(1-uB)(1-uT)(15)
λ=(1-uR)(1-uB)(1-uT)+(1-uR)2+
(1-uB)2+(1-uT)2+∑2k=1cRkcBkcTk(16)
这里的λ是一个规范化因子,确保融合后的观点满足式(1)。经过证据融合后,拥有最大证据的类即为最终的预测标签,而Dirichlet分布参数则用于计算损失。第k类的证据ek和Dirichlet分布参数αk可以由式(17)和(18)计算:
ek=Sck=Kuck(17)
αk=ek+1=Kuck+1(18)
该融合策略不仅强调了视图间对同一分类结果的共同支持,而且非常重视每个视图的类别可信度与不确定性。式(14)中的cRkcBkcTk项突出了多视图数据在形成统一分类决策时的集体作用,促使模型在预测时作出更一致和准确的判断。例如,当所有视图对某一类别预测都表现出较高的可信度时,这一项乘积会增大,从而促使融合后ck和ek相对增大。另一方面,(1-uR)cRk+(1-uB)cBk+(1-uT)cTk则优先考虑那些既可信又确定的视图。当一个视图的不确定性较低(即更确定)时,它为各类别分配的可信度在融合中的权重就越大。这样有助于提高模型对分类结果的整体信心,特别是在面对不同视图间的可信度和确定性存在显著差异时。
在处理不确定性u的融合时,特别注意到了直接相乘不确定性(uRuBuT)的潜在缺陷,即在所有视图均表现出较高不确定性或较低不确定性的情况下,这种方法可能导致最终的不确定性u变得极端大或极端小。与用于判定最终分类结果的可信度ck不同,融合后的不确定性u直接影响到Dirichlet分布的参数αk,进而对融合后的损失函数产生显著影响。所以,这种极端值的出现可能会导致融合后的损失函数变得不稳定,从而影响模型的整体训练效果。
为有效地避免极端值问题,采用(1-uR)(1-uB)(1-uT)来计算融合后的不确定性。在所有视图的不确定性都较高时,这种融合方式降低了总体不确定性,体现出一种逻辑:通过整合视图可以找到更稳健的共识。相反,在各视图的不确定性较低时,融合策略适度提升了不确定性,从而在多个视图之间找到平衡,避免对任何单一视图的过度自信。这种融合方式不仅有助于更全面地考虑来自不同视图的信息,而且确保了融合后的损失函数能够稳定地反映多视图数据的整体特性,从而优化整体模型性能。
3.6 损失函数
在MVEF方法中,由于采用了非负激活函数代替传统的softmax算子,标准的交叉熵损失函数不适用于模型训练。为此,本文采取了不同的方法,将每个样本由模型输出的证据映射到Dirichlet分布D(p|αi)的参数上,并据此计算交叉熵损失的贝叶斯风险[24]:
Euclid Math OneLApcebr(αi)=∫Euclid Math OneLApceD(p|αi)dp=
∫(-∑Kj=1yijlog(pij))D(p|αi)dp(19)
由于p是遵循D(p|αi)分布的随机变量,并且log pij作为Dirichlet分布的充分统计量,可以利用指数族分布的差分性质来导出log pij的期望值的解析形式[25]:
Euclid Math TwoEApD(p|αi)(log pij)=∫(log pij)D(p|αi)dp=
ψ(αij)-ψ(S)(20)
其中:ψ(·)是digamma函数,在(0,+∞)上单调递增;S是前文提到的Dirichlet强度。在此基础上,考虑到Euclid Math OneLApcebr(αi)捕捉的是样本属于正类的整体概率,即关注的是正类损失,将其重新标记为Euclid Math OneLAppc(αi)。接下来,借助式(20),式(19)可以将Euclid Math OneLApcebr(αi),即Euclid Math OneLAppc(αi)进一步展开:
Euclid Math OneLAppc(αi)=-∑Kj=1yij∫(log pij)D(p|αi)dp=
∑Kj=1yij[ψ(Si)-ψ(αij)]
(21)
Euclid Math OneLAppc(αi)专注于增强模型在正类识别上的精确度和置信度,因此还需要计算样本的负类损失,对过度自信的错误类别预测进行惩罚[26]。参考上述正类损失函数的形式,负类损失函数Euclid Math OneLApnc(αi)可以表示为
Euclid Math OneLApnc(αi)=∑Kj=1(1-yij)1ψ(Si)-ψ(αij)(22)
为全面评估模型在所有类别上的分类性能,总体损失函数Euclid Math OneLAp(α)综合了正类损失Euclid Math OneLAppc(αi)和负类损失Euclid Math OneLApnc(αi),确保在正类和负类间的有效平衡。因此,损失函数的表达式为
Euclid Math OneLAp(α)=∑Ni=1(Euclid Math OneLAppc(αi)+Euclid Math OneLApnc(αi))(23)
基于整体的MVEF方法而言,为最大化各视图对水军检测的贡献,并通过融合不同视图的信息来增强方法的整体性能,设计了一个多视图全局损失函数Euclid Math OneLApglobal。该损失函数综合来自不同视图的单独损失,并加入融合视图的损失,具体表达式为
Euclid Math OneLApglobal=Euclid Math OneLApR+Euclid Math OneLApB+Euclid Math OneLApT+Euclid Math OneLApfused=
Euclid Math OneLAp(αR)+Euclid Math OneLAp(αB)+Euclid Math OneLAp(αT)+Euclid Math OneLAp(αfused)(24)
其中:Euclid Math OneLApR、Euclid Math OneLApB、Euclid Math OneLApT分别代表社交关系视图、行为特征视图和推文内容视图的独立损失;Euclid Math OneLApfused则代表这些视图经过证据融合后的综合损失,它考虑了这些视图间的交互和补充信息。
4 实验
4.1 实验设置
4.1.1 数据集
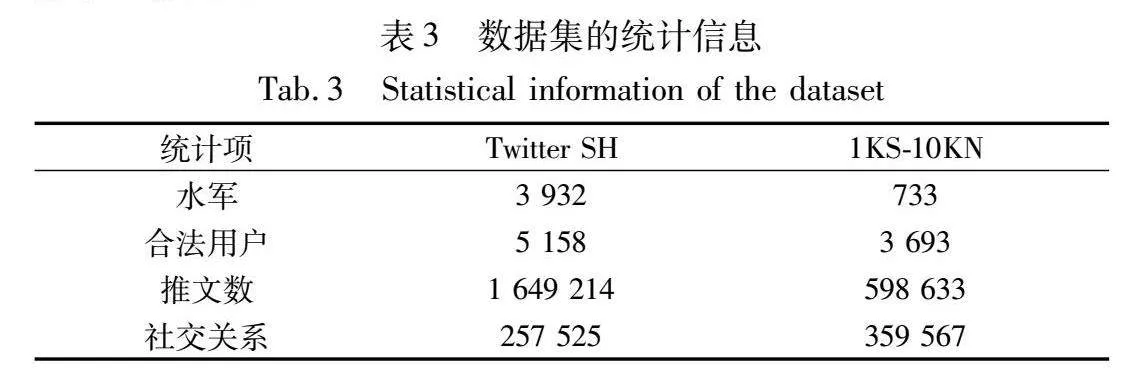
使用两个公共数据集来评估MVEF方法:Twitter社交蜜罐数据集(Twitter SH)[27]和Twitter 1KS10KN数据集(1KS-10KN)[28]。考虑到Twitter SH数据集中用户社交关系的缺乏,使用外部Twitter社交图数据集[29]来补充它的社交网络。根据实验需要采样得到最终的实验数据集,它们的具体统计情况如表3所示。
4.1.2 对比基线
将MVEF与以下基线进行比较,包括最先进的水军检测方法。
LR(logistic regression)是一种广泛使用的线性分类算法,适用于二分类问题。
SVM(support vector machine)是一种强大的分类器,通过找到最佳的决策边界来区分不同类别。
RF(random forest)是一种基于树的集成学习方法,通过构建多个决策树并进行投票或平均来提升预测性能。
XGBoost是一种先进的梯度增强算法,旨在通过正则化和并行处理提高模型的准确性和训练效率。
以上的单视图方法均使用行为特征视图构建的特征进行实验。
GANG[13]是一种基于有向图的社交网络欺诈用户检测方法,通过创新地运用成对马尔可夫随机场和环形信念传播来建模用户状态的联合概率分布。
MDGCN[16]是一种结合自适应奖励马尔可夫随机场和图卷积网络的先进模型,有效融合了用户关系网络和富文本特性。
SSDMV[2]是一种基于多视图数据融合的半监督深度学习模型,通过相关梯形网络和过滤门组件获得用户的联合表示,然后进行标签推理。
SSCF[18]是一种半监督线索融合方法,通过一个线性加权求和函数融合来自多个视角的综合线索,以获取最终结果。由于SSCF原本是针对微博平台设计的特征提取,其在Twitter上应用效果不佳。所以,在后续实验中,改用SSDMV的推文嵌入作为其推文视图特征,同时使用MVEF的行为视图特征和社交关系视图特征作为对应的视图特征。
4.1.3 评价指标
按照以往的文献,使用准确率(accuracy)、精度(precision)、召回率(recall)和F1值(F1-score)。
4.1.4 参数设置
GANG、MDGCN、SSDMV、SSCF的参数均参照原论文进行设置。对于MVEF,在处理社交关系视图时,设计了一个包含三层的MLP(含最后一个全连接层,以下均包含该层),结构为[256,128,2],其隐藏层采用ReLU激活函数。为增强模型的性能和泛化能力,在隐藏层集成了BatchNorm1d以加快训练过程,并在输入层以及隐藏层之间嵌入dropout机制(比例分别为0.2和0.5),以防止出现过拟合现象。在行为特征视图处理中,根据数据集特性对网络结构进行调整,Twitter SH数据集使用[9,6,4,2]的四层MLP,1KS-10KN数据集使用[9,8,7,6,4,2]的六层MLP。隐藏层同样采用ReLU激活函数,并在最后一个隐藏层后添加BatchNorm1d和Dropout层。推文内容视图则利用BERTweet模型提取特征向量,后接一个全连接层。为进一步降低过拟合风险,在该层前引入dropout(比例为0.2)。
为优化模型的任务适应性,对BERTweet进行微调,采用了误差修正、weight-decay (L2正则化)和warmup等策略。在模型训练阶段,为避免BERTweet微调对整体模型参数更新的影响,为BERTweet部分设置专用的AdamW优化器,而对其他网络部分则使用标准的Adam优化器。
4.2 对比实验
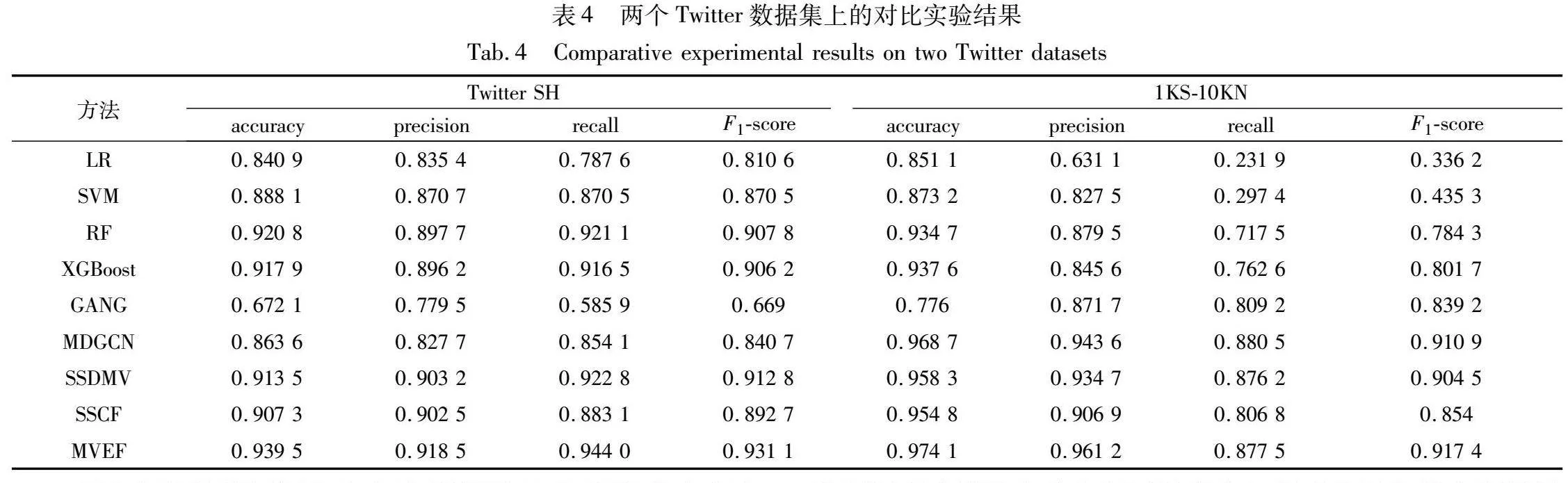
在这一部分,将MVEF与现有的先进水军检测方法进行比较。随机选择80%的用户作为训练集,其余20%作为测试集在两个数据集上评估MVEF和上面列出基线的性能。结果显示在表4中。可以注意到,MVEF方法不仅在类别分布相对平衡的Twitter SH数据集上取得了高质量的分类结果,在类别分布不平衡的1KS-10KN数据集上同样展示了其强大的检测能力。这一发现进一步证明了MVEF在社交水军检测领域的实用性。
LR和SVM这两个经典的机器学习算法在两个数据集上表现很差,尤其是在1KS-10KN数据集上的F1值均低于0.5,因为它们在处理高度不平衡的社交网络数据时具有局限性,倾向于过度拟合多数类而忽略少数类。相比之下,集成学习算法RF和XGBoost表现更好,在Twitter SH数据集上的准确率和F1值均在0.9以上,因为集成学习可以通过组合多个弱学习器从而形成一个强学习器。它们还通过特有的机制如类别权重调整和改进的损失函数,来应对数据不平衡带来的挑战,所以在类别极度不平衡的1KS-10KN数据集上,F1值也达到了08左右。GANG和MDGCN这两种方法通过有效利用社交网络的紧密连接来学习用户特征和标签依赖。因此,相较于社交网络较为稀疏的Twitter SH数据集,它们在社交联系更加紧密的1KS-10KN数据集上展现了更加卓越的性能。尤其是MDGCN整合了图卷积网络和马尔可夫随机场的优势,在学习特征表征的同时对关系型用户的依赖性进行建模,其在1KS-10KN数据集上的F1值高达0.910 9。
对比先进的特征级融合方法SSDMV和决策级融合方法SSCF,MVEF性能表现更优异。特别是在Twitter SH数据集上,MVEF的准确率超过这两个融合方法2%以上,在1KS-10KN数据集上也高出了1.5%以上。尽管SSDMV能够探索跨视图的特征交互,但在处理视图间噪声和质量差异方面可能存在不足。与之相对,MVEF独立评估每个视图的预测结果,并用不确定性量化视图质量差异,保证了最终决策的可靠性。SSCF虽然采用了决策级融合策略,但其固定的权重参数限制了模型在不同数据分布下的适应能力。而MVEF通过分析每个样本的视图证据动态调整权重,使得模型在综合多视图信息时更加精准。
4.3 消融实验
为评估每个部分对方法性能的贡献,进行了一系列消融实验,分别移除了特定的视图数据以及方法的核心模块—证据融合模块,并观察方法的性能变化。
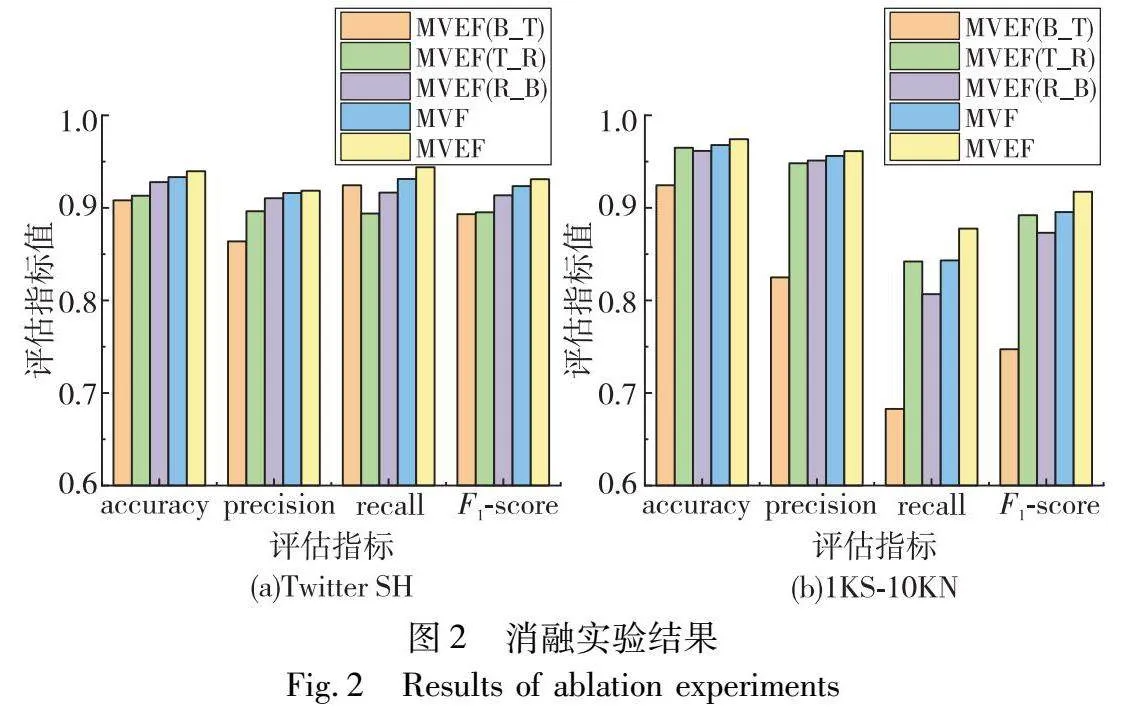
具体而言,对比完整的多视图证据融合方法MVEF与其四种消融变体,即MVEF(B_T)、MVEF(T_R)、MVEF(R_B)和MVF。前三种消融变体分别移除社交关系视图R、行为特征视图B、推文内容视图T,旨在评估这些视图对MVEF方法性能的贡献,探究视图数量对融合模型效果的影响,以及不同视图组合在模型性能中的相对重要性。而MVF方法则移除了证据融合模块,其中各视图的基分类器在全连接层之后直接采用softmax函数输出分类概率,然后以相等权重组合形成最终预测概率,并采用交叉熵损失函数进行优化。该变体的目的是检验证据融合模块在整合多视图信息和提升方法性能方面的重要性。
如图2所示,MVEF方法在不同消融设置下的性能表现出了明显的差异。从三视图融合方法MVEF中移除任意一个视图时,性能指标均有所下降,这表明每个视图都为模型提供了独特而有价值的信息。然而,性能的下降程度并不一致,反映出不同视图对模型性能贡献的重要性不同。其中,社交关系视图S对模型的整体性能有显著影响。在所有移除某一视图的消融实验设置中,无论是结合行为特征视图MVEF(R_B),还是推文内容视图MVEF(T_R),包含社交关系视图的组合均展现出较高的性能指标,它们在Twitter SH数据集上的准确率与完整模型相比仅相差约2%,在1KS-10KN数据集上的差距更是缩小至1.5%以内。这凸显了社交关系视图在区分水军和合法用户中的重要作用,它依托社交网络同质性理论深入分析用户之间的互动和共性特征,捕捉到用户紧密的社交联系,极大地提升了模型识别水军的能力。与此相比,MVEF(B_T)在两个数据集上的性能普遍低于包含社交视图的组合,特别是在1KS-10KN数据集上,其F1值与完整模型相比下降了15%,远高于其他消融变体的下降幅度。这可能是因为行为特征和推文内容虽然能提供用户的静态属性和内容信息,但缺乏社交关系视图所具有的用户间动态交互的信息,而这种交互信息对于揭示潜在的水军网络特别关键。
此外,特别关注了去除核心模块—证据融合模块的MVF方法的性能表现。结果表明,MVF方法虽然在某些性能指标上优于只包含两个视图的证据融合方法,但仍然不及完整的MVEF方法。例如,其在1KS-10KN数据集上的F1值仍比MVEF方法低约2%。这表明单纯的视图特征提取和简单的输出组合,虽然能够在一定程度上捕获视图间的互补性,但无法深入挖掘和利用视图间的复杂相互作用。相比之下,MVEF方法的主要优势在于其证据融合机制,该机制不仅评估每个视图的独立贡献,还深入考虑视图间的相互作用和联系。这使得MVEF能够更全面地整合多视图数据,有效地捕获每个视图的独特信息。
总体而言,消融实验结果突显了MVEF在多视图数据整合上的独特优势,特别是其证据融合模块在提升分类性能方面的关键作用。
4.4 鲁棒性实验
在现实世界中,社交数据往往包含各种噪声,为此,需要一个鲁棒的水军检测方法能够适应这些数据偏差。为评估方法在各种数据偏差下的性能,进行了鲁棒性实验。在测试数据集中故意引入不同比例(10%、20%、30%和40%)的噪声,模拟现实世界中的数据质量问题。具体方法包括:
a)行为特征视图(view B):在标准化后的数据上添加服从标准正态分布(均值为0,方差为1)的高斯噪声。
b)社交关系视图(view R):通过随机删除和添加社交网络中的关注关系来引入噪声。
c)推文内容视图(view T):通过随机删除和添加单词、使用同义词替换,以及在单词中插入随机字符来添加推文的噪声。
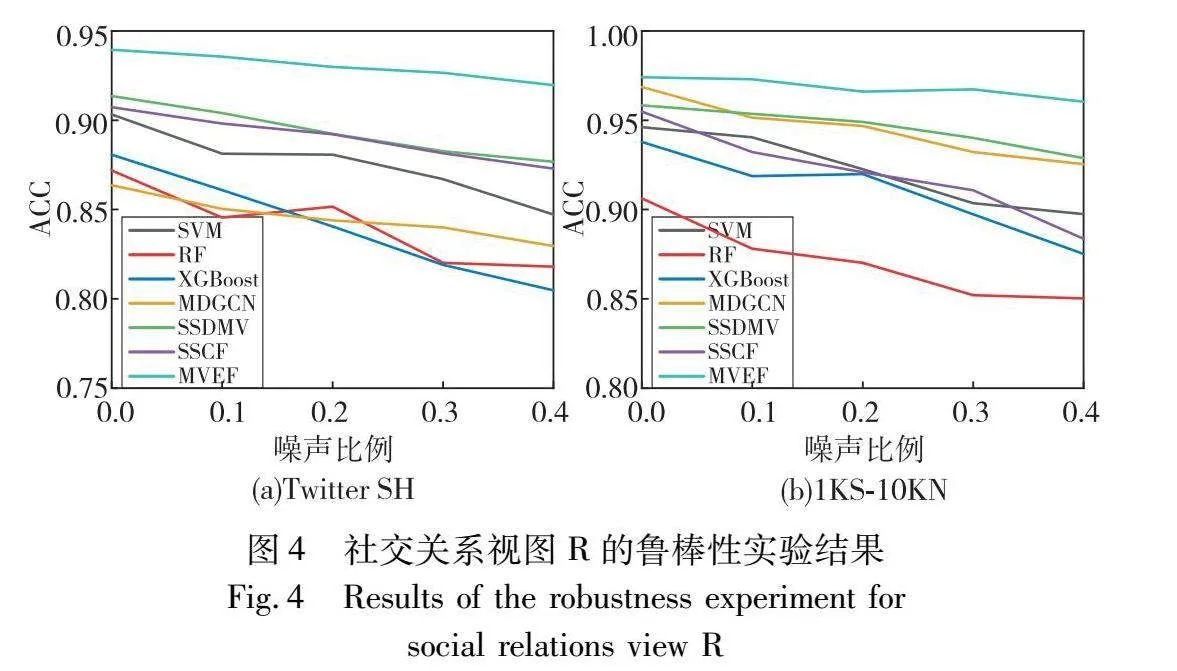
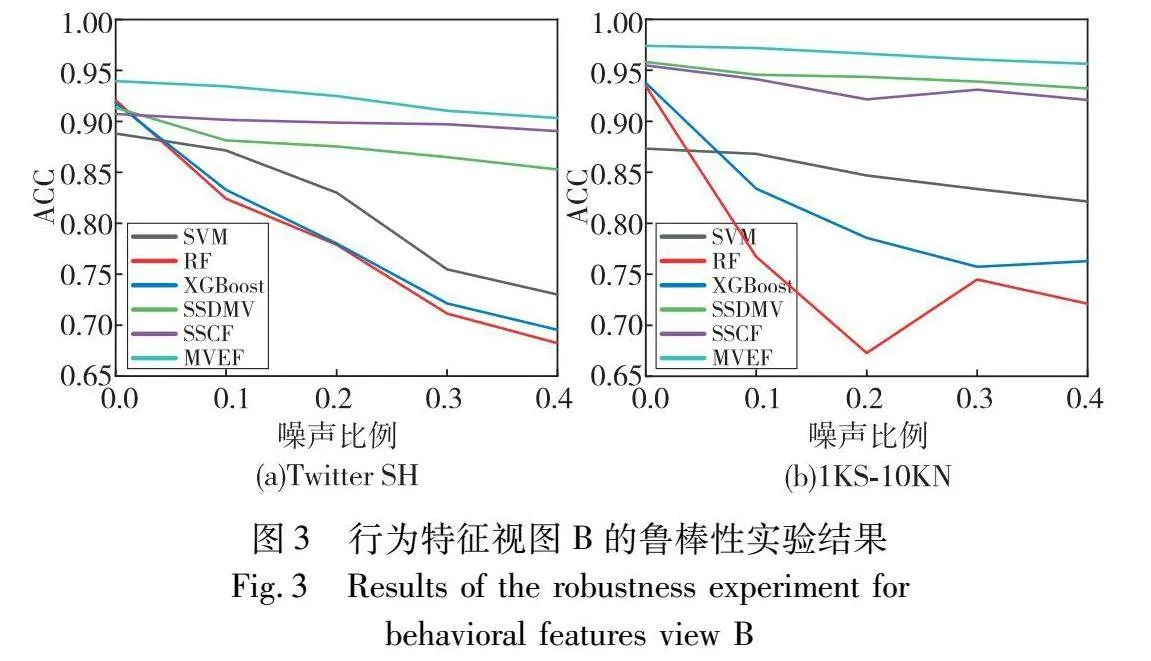
如图3所示,在面对不同程度行为特征的噪声时,多视图融合方法SSDMV、SSCF以及MVEF在两个数据集中均展示出较好的稳健性。特别是MVEF,在面对高达40%的噪声比例下,性能下降幅度在两个数据集上均未超过4%。与此相比,SSCF虽然在Twitter SH数据集上的性能降幅最小(未超过2%),但在1KS-10KN数据集上表现最差。这种差异可能源于两个数据集中行为特征视图的不同贡献度以及通过训练固定视图权重所带来的影响。在Twitter SH数据集中,行为特征视图被赋予较低的权重,为模型提供一层缓冲,减轻了噪声对整体性能的影响。对于传统的单视图方法,如SVM、RF和XGBoost,在Twitter SH数据集上的性能降幅相对更为明显。尤其是RF,在40%噪声条件下性能下降超过25%,说明这些方法对噪声非常敏感。而在1KS-10KN这个极端不平衡的数据集中,SVM的性能下降则相对缓慢,这可能是因为其核函数和间隔最大化的特性,能够在一定程度上抵御噪声带来的干扰。
在添加噪声的社交关系视图实验中,利用MVEF方法的社交关系节点嵌入为单视图方法SVM、RF和XGBoost提供特征。如图4所示,MDGCN在面对噪声时的性能下降较SSDMV和MVEF偏大,这可能是由于其对用户间关系和依赖性的学习受到图结构变化的影响。单视图方法(如SVM、RF)在社交关系视图添加噪声时的性能下降并不像在行为特征视图中那样显著,这归功于它们使用的高质量节点嵌入,这些嵌入通过增加节点间的间接关系和共享邻居来生成,从而在噪声条件下为模型提供较为稳定的特征表示。
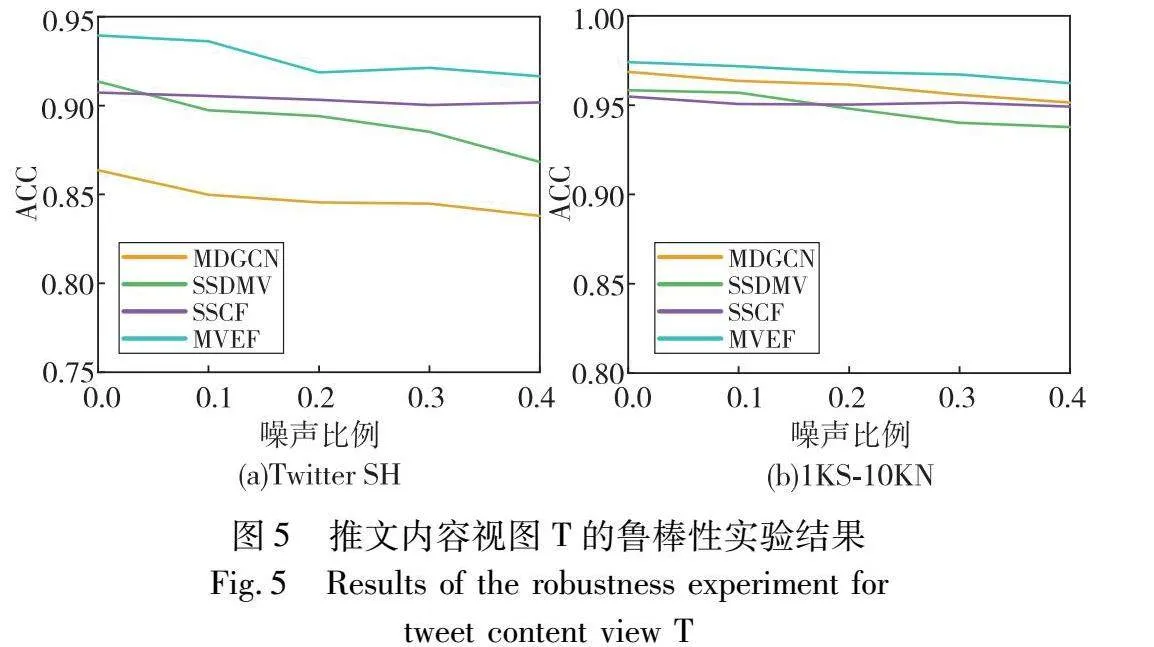
结合图4和5来看,SSDMV、MDGCN、SSCF以及MVEF等多视图融合方法在高噪声环境下相较于SVM、XGBoost等单视图方法表现出更优越的性能。这是因为多视图方法能够综合多个数据源的信息,使得在一个视图中出现的噪声可以被其他视图中的准确信息补偿。特别注意到,SSCF这一决策级融合方法在处理不同视图的噪声时,其性能表现出了不同程度的敏感性。当社交关系视图遭受噪声干扰时,其性能显著降低,而对推文视图中的噪声所受影响却十分小。这一观察可能指向了模型在训练过程中对社交关系视图赋予较高的权重,认为其特征表达具有较高的质量,而相对地,推文视图的权重被设置得很低。这也揭示了SSCF的固定权重分配机制在处理视图噪声时的局限性,其未能充分激发多视图融合的潜力,特别是在各视图质量差异显著时,无法灵活调整以利用视图间的互补性。相比之下,MVEF以其独特的不确定性量化方法和有效的融合策略使其在对抗噪声方面表现更为卓越,从而在数据质量变化的环境中保持高稳定性和准确性。
5 结束语
本文提出了一种基于多视图证据融合(MVEF)的社交水军检测方法,用于高效准确地检测社交平台上的水军。该方法综合分析用户行为、社交关系和推文内容三个关键视图,以提取决策所需的证据。然后,将其参数化为Dirichlet分布,准确量化每个视图在分类决策中的整体不确定性与类别可信度。在核心的证据融合环节,MVEF利用各视图的不确定性动态调整决策权重,形成全面可信的分类结果。实验结果显示,MVEF在两个数据集上的性能均优于现有的先进方法,证明了其在准确性、鲁棒性和可靠性方面的显著优势。未来的工作将探索优化视图融合策略,以适应更加多样化的数据环境并进一步提升方法性能。
参考文献:
[1]Chen Ailin, Yang Pin, Cheng Pengsen. ACTSSD: social spammer detection based on active learning and co-training [J]. The Journal of Supercomputing, 2022, 78(2): 2744-2771.
[2]Li Chaozhuo, Wang Senzhang, He Lifang,et al. SSDMV: semi-supervised deep social spammer detection by multi-view data fusion [C]// Proc of the 18th IEEE International Conference on Data Mi-ning. Piscataway, NJ: IEEE Press, 2018: 247-256.
[3]Liu Bo, Sun Xiangguo, Ni Zeyang,et al. Co-detection of crowdturfing microblogs and spammers in online social networks [J]. World Wide Web, 2020, 23(1): 573-607.
[4]Sensoy M, Kaplan L, Kandemir M. Evidential deep learning to quantify classification uncertainty [C]// Proc of the 32nd Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates, 2018: 31.
[5]Krestel R, Chen Ling. Using co-occurrence of tags and resources to identify spammers [C]// Proc of ECML/PKDD Discovery Challenge Workshop. Berlin: Springer, 2008: 38-46.
[6]Hu Xia, Tang Jiliang, Gao Huiji,et al. Social spammer detection with sentiment information [C]// Proc of the 14th IEEE International Conference on Data Mining. Piscataway, NJ: IEEE Press, 2014: 180-189.
[7]Ghanem R, Erbay H. Spam detection on social networks using deep contextualized word representation [J]. Multimedia Tools and Applications, 2023, 82(3): 3697-3712.
[8]Zhang Xianchao, Li Zhaoxing, Zhu Shaoping,et al. Detecting spam and promoting campaigns in Twitter [J]. ACM Trans on the Web, 2016, 10(1): 1-28.
[9]Stafford G, Yu L L. An evaluation of the effect of spam on Twitter trending topics [C]// Proc of International Conference on Social Computing. Piscataway, NJ: IEEE Press, 2013: 373-378.
[10]Yin Jun, Li Qian, Liu Shaowu,et al. Leveraging multi-level depen-dency of relational sequences for social spammer detection [J]. Neurocomputing, 2021, 428: 130-141.
[11]Jeong S, Noh G, Oh H,et al. Follow spam detection based on cascaded social information [J]. Information Sciences, 2016, 369: 481-499.
[12]李宁, 梁永全, 张琪. 一种基于时序邻居序列的游离水军群组检测方法 [J]. 计算机应用研究, 2023, 40(3): 776-785. (Li Ning, Liang Yongquan, Zhang Qi. Method for detecting free spammer groups based on temporal neighbor sequence [J]. Application Research of Computers, 2023, 40(3): 776-785.)
[13]Wang Binghui, Gong N Z, Fu Hao. GANG: detecting fraudulent users in online social networks via guilt-by-association on directed graphs [C]// Proc of the 17th IEEE International Conference on Data Mining. Piscataway, NJ: IEEE Press, 2017: 465-474.
[14]张琪, 纪淑娟, 张文鹏, 等. 考虑结构与行为特征的水军群组检测算法 [J]. 计算机应用研究, 2022, 39(5): 1374-1379. (Zhang Qi, Ji Shujuan, Zhang Wenpeng,et al. Group spam detection algorithm considering structure and behavior characteristics [J]. Application Research of Computers, 2022, 39(5): 1374-1379.)
[15]Zhang Xulong, Jiang F, Zhang Ran,et al. Social spammer detection based on semi-supervised learning [C]// Proc of the 20th IEEE International Conference on Trust, Security and Privacy in Computing and Communications. Piscataway, NJ: IEEE Press, 2021: 849-855.
[16]Deng Leyan, Wu Chenwang, Lian Defu,et al. Markov-driven graph convolutional networks for social spammer detection [J]. IEEE Trans on Knowledge and Data Engineering, 2022, 35(12): 12310-12322.
[17]Shen Hua, Wang Bangyu, Liu Xinyue,et al. Social spammer detection via convex nonnegative matrix factorization [J]. IEEE Access, 2022, 10: 91192-91202.
[18]Chen Hao, Liu Jun, Lyu Yanzhang,et al. Semi-supervised clue fusion for spammer detection in Sina Weibo [J]. Information Fusion, 2018, 44: 22-32.
[19]Wu Fangzhao, Wu Chuhan, Liu Junxin. Semi-supervised collaborative learning for social spammer and spam message detection in microblogging [C]// Proc of the 27th ACM International Conference on Information and Knowledge Management. New York: ACM Press, 2018: 1791-1794.
[20]Liu Shuaitong, Li Xiaojun, Hu Changhua,et al. Spammer detection using multi-classifier information fusion based on evidential reasoning rule [J]. Scientific Reports, 2022, 12(1): 12458.
[21]Moon J, Kim J, Shin Y,et al. Confidence-aware learning for deep neural networks [C]// Proc of the 37th International Conference on Machine Learning. New York: PMLR, 2020: 7034-7044.
[22]Koggalahewa D, Xu Yue, Foo E. An unsupervised method for social network spammer detection based on user information interests [J]. Journal of Big Data, 2022, 9(1): 1-37.
[23]Nguyen D Q, Vu T, Nguyen A T. BERTweet: a pre-trained language model for English Tweets [EB/OL]. (2020-10-05). https://arxiv.org/abs/2005.10200.
[24]Charpentier B, Zügner D, Günnemann S. Posterior network: uncertainty estimation without OOD samples via density-based pseudo-counts [C]// Proc of the 34th Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates, 2020: 1356-1367.
[25]Lin Jiayu. On the Dirichlet distribution [EB/OL]. (2016). https://api.semanticscholar.org/CorpusID:45761615.
[26]Zhao Kun, Gao Qian, Hao Siyuan,et al. Credible remote sensing scene classification using evidential fusion on aerial-ground dual-view images [J]. Remote Sensing, 2023, 15(6): 1546.
[27]Lee K, Eoff B, Caverlee J. Seven months with the devils: a long-term study of content polluters on twitter [C]// Proc of the 5th International AAAI Conference on Web and Social Media. Palo Alto, CA: AAAI Press, 2011: 185-192.
[28]Yang Chao, Harkreader R, Zhang Jialong,et al. Analyzing spammers’ social networks for fun and profit: a case study of cyber criminal ecosystem on Twitter [C]// Proc of the 21st International Confe-rence on World Wide Web. New York: ACM Press, 2012: 71-80.
[29]Kwak H, Lee C, Park H,et al. What is Twitter, a social network or a news media? [C]// Proc of the 19th International Conference on World Wide Web. New York: ACM Press, 2010: 591-600.
