基于医疗临床数据的两阶段专业级大语言模型微调
2024-10-14孙丽萍童子龙钱乾陆鑫涛凌晨方诚汤其宇蒋晓


摘 要:通用大语言模型(large language model,LLM)缺乏对专业领域知识理解的深度和广度,对专业领域问题回答的准确度不够,常常产生幻觉,阻碍了大语言模型的商业应用落地。因此,基于专业领域特有数据提高大型语言模型的专业性成为当前大语言模型应用落地的关键挑战。针对通用大语言模型在特定领域知识理解与生成内容专业性不够的问题进行了研究。基于P-Tuning v2与Freeze两种参数高效微调方法,提出了一种专业级大语言模型的两阶段微调框架。依赖该框架与肝胆科临床数据对ChatGLM-6B进行微调,得到一个针对肝胆专科的专业级大语言模型,命名为MedGLM.H。根据实验显示,微调后的大语言模型对于肝胆专科问题的准确率从31%提升到了62%;得分率从57%提升到了73%。在进行两阶段微调后,模型在肝胆专科的问答中表现出更高的准确性与专业性,根据三名临床医生进行的对话实验,证明了微调后的模型在更专业的医疗场景中具备应用潜力。
关键词:大语言模型;微调;肝胆科;人工智能
中图分类号:TP391.1 文献标志码:A 文章编号:1001-3695(2024)10-004-2906-05
doi:10.19734/j.issn.1001-3695.2024.03.0071
Two-phases fine-tuning of professional large language model via clinical data
Sun Liping1, 2, Tong Zilong3, Qian Qian3, Lu Xintao3, Ling Chen1, Fang Cheng4, Tang Qiyu4, Jiang Xiao5
(1.Medical Instrumentation College, Shanghai University of Medicine & Health Sciences, Shanghai 201318, China; 2.School of Information Science & Technology, Fudan University, Shanghai 200433, China; 3.School of Health Sciences & Engineering, University of Shanghai for Science & Technology, Shanghai 200093, China; 4.Third Affiliated Hospital of Naval Medical University, Shanghai 200438, China; 5. 905th Hospital of PLA, Shanghai 200052, China)
Abstract:General large language model (LLM) lacks the depth and breadth of understanding of domain-specific knowledge, resulting in insufficient accuracy in addressing domain-specific questions and often leading to illusions, which hinders the commercial deployment of large language models. Therefore, enhancing the professionalism of large language models based on domain-specific data has become a key challenge for the practical application of large language models. This study aimed to address the issue of insufficient domain-specific knowledge understanding and content professionalism of general large language models in specific domains. This paper proposed a two-stage fine-tuning framework for professional large language models based on the efficient parameter fine-tuning methods of P-Tuning v2 and Freeze. This framework, relying on clinical data from hepatobiliary specialties, fine-tuned ChatGLM-6B to obtain a professional-level large language model for hepatobiliary specialties, named MedGLM.H. According to the experiments, the fine-tuned large language model exhibited an increase in accuracy for hepatobiliary specialist questions from 31% to 62%, and the scoring rate increased from 57% to 73%. After two-phase fine-tuning, the model demonstrates higher accuracy and professionalism in hepatobiliary specialty QA. Dialogue experiments conducted with three clinical doctors confirm the application potential of the fine-tuned model in more specialized medical scenarios.
Key words:large language model; fine-tune; hepatobiliary; artificial intelligence
0 引言
近期,LLM如ChatGPT[1]、Bard、ChatGLM[2]等备受瞩目,它们展现出的对常识问题的理解能力、流畅的对话能力、上下文记忆能力、文本生成能力以及逻辑推理能力,标志着人类迈向通用人工智能的这导致了在特定领域的应用中存在着不准确性和可信度问题[3~6]。
特定领域的知识和理解对于LLM的成功应用至关重要。举例来说,对于医疗保健领域,LLM需要准确理解医学术语、诊断方法、药物治疗等内容,以便提供准确的建议或诊断。而在金融领域,LLM需要理解投资策略、市场分析、风险评估等方面的知识,以支持投资决策或提供财务咨询。因此,为了充分发挥LLM的潜力,需要针对不同领域进行定制化的知识和技能培训,从而使其能够在特定领域中表现出专业水平。
然而,从零开始训练特定领域的LLM是一项极具挑战性和成本高昂的任务。这不仅需要大量的算力支持,还需要拥有深厚领域知识的AI算法工程师进行指导和优化。这种成本和复杂性对于许多机构来说是难以承受的,尤其是对于小型企业或研究机构。因此,基于通用且可靠的大型语言模型进行微调以适应特定领域的需求成为了一种更加可行和经济的选择。
通过微调通用模型,可以将其转换为针对特定领域的大语言模型,从而获得更高的准确性和可信度。这种方法不仅可以节省大量的时间和资源,还可以确保模型具有足够的灵活性,以适应不断变化的领域需求。同时,微调过程中可以通过引入领域专家的知识和反馈来提高模型的性能,从而进一步增强其在特定领域的应用能力。
除了微调外,还可以采用其他策略来提高LLM在特定领域的应用能力。例如,结合外部数据源进行训练,引入领域专家参与模型设计和评估过程,以及建立特定领域的知识图谱来辅助模型理解和推理。这些策略可以进一步增强模型在特定领域的专业性和适用性,从而提高其实际落地的可能性。
因此,尽管LLM在通用领域取得了巨大的进步,但其在特定领域的应用仍然面临诸多挑战。为了充分发挥其潜力,则需要通过微调和其他策略来提升其专业性和适用性,从而实现在特定领域的商业化落地。这不仅需要技术上的创新和优化,还需要跨学科的合作和领域专家的参与,以确保模型能够真正服务于实际需求,并为社会带来更大的价值和影响。
1 研究现状
1.1 医学通用大语言模型
医疗健康领域已经出现一些基于通用大语言模型微调的医学大语言模型,如德克萨斯大学西南医学中心的Li等人[7]基于205 000条真实的医患交流数据和ChatGPT生成的5 000条数据对LLaMA进行微调,得到ChatDoctor这一医学通用的大语言模型。此外,上海科技大学的Xiong等人[8]利用ChatGPT和其他基于英语的医学通用大语言模型收集了医学对话数据库并翻译为中文,对清华大学开源的中文大语言模型ChatGLM-6B进行参数高效微调,得到一个医学通用的大语言模型——DoctorGLM;哈尔滨工业大学的Wang等人[9]通过医学知识图谱和GPT3.5API构建了中文医学指令数据集,在此基础上对ChatGLM-6B进行了指令微调,微调后的大语言模型命名为ChatGLM-Med。基于相同的数据Wang等人[9]还训练了医疗版本的LLaMA模型——华驼。这些医学通用大语言模型的成功表明利用医疗数据对大语言模型微调可以得到医学专业能力更强的大语言模型[10]。此外,这些通过微调得到的医学通用大语言模型都能在消费级显卡部署或训练。这对于研发或部署专用医学大语言模型的医院或机构有着巨大的诱惑。
1.2 参数高效微调方法
得益于以LoRA(low-rank adaptation,LoRA)[11]为代表的参数高效微调方法(parameter-efficient fine-tuning, PEFT),大语言模型微调的算力需求与训练时间相比全参数微调大大降低。对于某一专业领域的大语言模型的训练,一个很常见的策略是从公共的知识库获取相关领域的专业知识作为训练数据,利用这些数据对通用大语言模型进行参数高效微调。值得注意的是,如果意向训练更加专业的大语言模型,那么仅仅使用公开知识库的数据微调得到的大语言模型的专业程度并不会十分令人满意。一个主要的原因是公开的知识库对更细分领域的专业知识收录不够专业,难以得到从业者的认可[3]。因此,使用专业性的文件或数据微调大语言模型被视为一个可行的方法。由于标准化作业流程的要求,专业性文件种包含了许多专业术语及专有名词,文件的格式也有特殊的要求,往往并不适合直接用于微调。这些专业性文件需要有一定专业基础的工作人员对数据进行加工才适合用于大语言模型的微调。
1.3 本研究的贡献
本文提出一种基于医学领域专业性文件训练医学领域专科大语言模型的两阶段微调框架,并基于此框架微调出面向肝胆医学的专科大模型。本文的主要贡献有两点,即:
a)利用公开的知识图谱或对大规模的语言模型进行知识蒸馏,收集一定数量目标域的训练数据对源模型进行参数高效微调;
b)对专业性文件进行数据处理,使其符合微调的数据要求及格式,使用相对少量的更专业数据对第一阶段微调后的模型进行第二次freeze微调[12],最终训练了一个针对肝胆专科的大语言模型。
本文将这种两次微调的框架命名为“造极”。基于“造极”与临床病历数据, 本文训练了一个针对肝胆专科的医疗对话大语言模型——MedGLM.H。训练使用的临床病历数据是由东方肝胆外科医院提供的肝胆专科的不带有姓名的患者病历、诊疗记录和手术记录, 本文期望经过这些临床专业数据的训练,它能够准确回答出肝胆专科的一些问题,包括但不限于治疗方案、手术要求、检验指标解读及用药规范等。由于目前整理的病历文本数据量有限,MedGLM.H在对治疗方案与检验指标解读等回答上尚未达到专业水准。在后续的更新迭代版本会针对这一缺陷进行改进。
2 基于ChatGLM-6B的两阶段微调方法
2.1 框架
MedGLM.H的训练包括通用医学知识训练与肝胆专科的专业知识训练。这点类似于中国临床医生的培养政策:中国的医生在成为一名正式的临床医生之前必须首先在医院的所有科室进行轮转实习,以培养临床医生的综合能力。各科室轮转实习后,实习医生会留在他最终选择的科室成为该科室的实习医生,继续深入学习该科室的专业知识与临床技能。MedGLM.H的两阶段微调对应着临床医生的全科轮转实习与定岗实习。
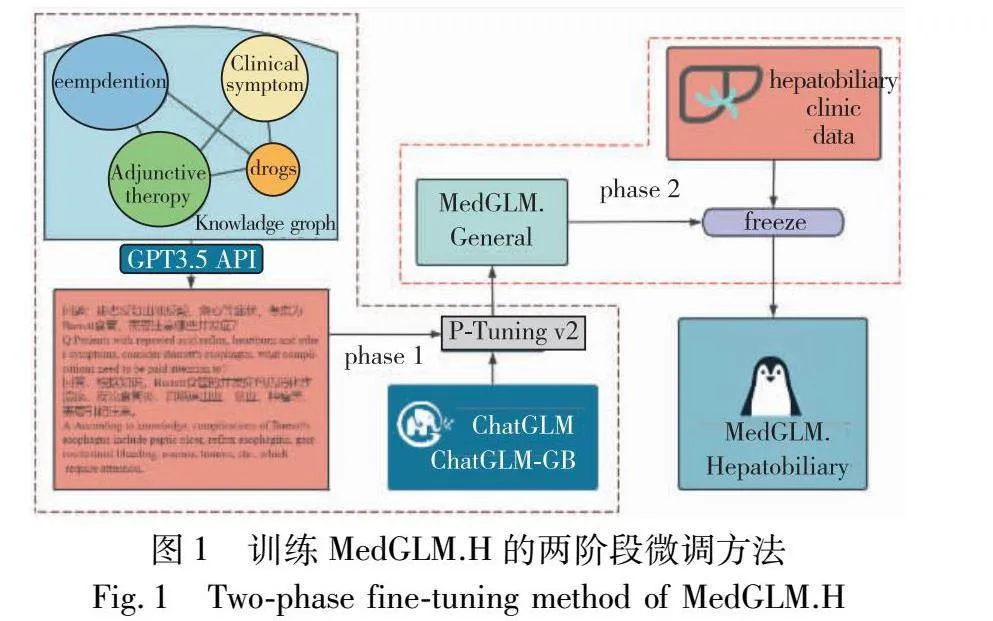
基于“造极”的两阶段微调的全过程如图1所示,其中第一阶段的微调,使用公开的医学知识图谱并借助GPT3.5的API接口生成通用的医学知识问答数据,对ChatGLM-6B进行P-Tuning v2微调。第一阶段微调后的模型命名为MedGLM.General,MedGLM.General可以回答部分通用医学方面的基础问题,但其回答问题的性能尚无法与其他通过海量通用医学数据训练后的模型相比。第二阶段的微调使用临床的病历数据进行加工,用有限的数据对MedGLM.General进行freeze微调,训练得到的MedGLM.H能够在保证通用医学问答的性能下解答针对肝胆专科的问题。
2.2 源模型
许多研究人员在选择源模型进行微调时有着相似的偏好。在基于中文的大语言模型微调中,工程师通常选择ChatGLM-6B作为源模型;而在英文方面的微调中,较为常见的源模型是LLaMA[13]。
这两个模型具有几个共同特点,首先它们都是开源的大语言模型,并且具有出色的性能表现。同时,它们的参数量都达到了十亿级别(ChatGLM-6B含有60亿个参数,LLaMA含有70亿个参数),这个级别的参数量对于大型语言模型而言只是达到门槛要求。尽管如此,由于它们的参数量相对较小且性能仍然足够,微调这些模型所需的计算资源可以被许多实验室支持。因此,十亿级别参数量的大语言模型是进行微调的一个热门选择。
MedGLM.H的训练源模型是ChatGLM-6B。该模型基于general language model(GLM)架构,参数量为62亿。结合模型量化技术,工程师可以在消费级显卡上进行本地部署(INT4量化级别最低只需要6 GB显存)。因此ChatGLM-6B被开发了许多个训练版本。目前很多中文的医学大语言模型都是基于ChatGLM-6B进行微调,例如:DoctorGLM、ChatGLM-Med。
2.3 构建数据集
首次微调的数据集主要来自公开的中文医学知识库,并参考cMeKG生成了一些数据。这些数据集的内容包括并发症、临床症状、药物治疗和辅助治疗等。医学知识库以中心词对应疾病和症状到所属科室与发病部位为一组的形式储存。再利用GPT3.5的API接口围绕医学知识库构建问答数据,训练数据为“问题—回答”的形式。共计收集20 000条全科医学的问答数据。
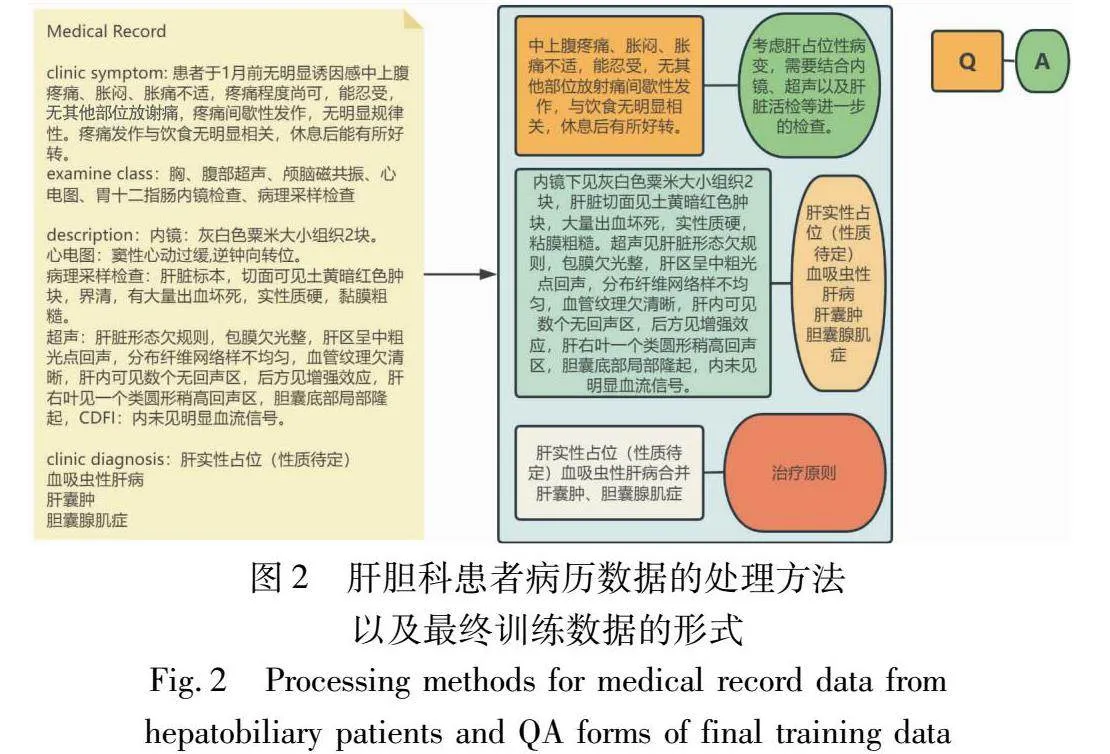
第二次微调使用了1 300条肝胆专科临床病患的病历文本及诊疗记录数据,其中的检验数据或治疗方案通常有很强的独特性(如:某药物用量、注射的量;囊肿或肿瘤的尺寸以及超声多普勒检查的血液流速等)。这些过于精确的数据对于大语言模型来说可参考性很低。因此,在处理病历数据时需要将这些数值剔除。除此之外,为了使MedGLM.H的回答更加专业且准确,病历数据还需要进行再加工,数据形式如图2所示。
医疗记录数据通过将查询部分和检查结果部分分类为“Q”,并利用相应的诊断结果、相关检查措施、手术要求、药物指南和执行后结果作为它们各自的“A”来进行处理。此外,鉴于医疗记录数据的标准化和专业性质,对部分医疗用语的改写也是数据处理的一项重要工作。为了遵循数据保密原则,数据处理任务由本文的工作人员手动完成。
由于患者医疗记录和临床数据的敏感性, 本文无法公开发布MedGLM.H的源代码和数据集。测试版本将在东方肝胆外科医院内部部署,由专业医生及部分临床患者进行测试。根据测试的结果进一步改进,以加速最终发布MedGLM.H的时间。值得一提的是,MedGLM.H的训练环境是隔离且安全的,确保对机密数据的保护并防止任何泄露。
2.4 阶段1:基于通用医学知识进行P-Tuning v2微调
由于LoRA在LLM的多轮对话中表现不佳,正如Xiong等人在DoctorGLM的后续版本中所提到的,进一步使用P-Tuning v2进行微调相比LoRA微调版本表现出了改进的测试结果。因此,本文利用P-Tuning v2进行第一次通用医学LLM的微调。
P-Tuning v2被视为Prefix-Tuning的一种版本,重点解决了prompt tuning在小模型上效果不佳的问题,并将prompt tuning拓展至更复杂的自然语言理解(NLU)任务中,如机器阅读理解(MRC)答案抽取、命名实体识别(NER)实体抽取等序列标注任务。在不同模型规模和NLU任务的微调中,它的性能可以与全参数微调方法相媲美,而只有01%~3%的微调参数。在训练中P-Tuning v2冻结模型的主要部分,对前缀进行多层提示优化。不同层中的提示作为前缀token加入到输入序列中。添加到更深层次的提示可以对输出预测产生更多的影响[14]。
P-Tuning v2的运算逻辑与结构可以通过以下几个关键部分来解释:
a)前缀编码器 (prefixencoder): 这是一个自定义的模块,用于生成可训练的前缀嵌入。它使用PyTorch的embedding层来为每个前缀ID创建一个嵌入向量。这些前缀嵌入将作为额外的输入,与原始输入一起参与模型的后续计算。
b)模型扩展: 这个类继承自预训练的源模型,并且添加了前缀编码器。在模型的前向传播过程中,前缀编码器生成的前缀嵌入会与原始输入嵌入合并。
c)前向传播过程:
(a)使用prefixencoder对前缀ID进行编码,得到前缀嵌入;
(b)获取原始输入ID的嵌入表示;
(c)将前缀嵌入与输入嵌入连接起来,形成一个扩展的嵌入序列;
(d)将这个扩展的嵌入序列输入到源模型中,进行正常的前向传播。
d)训练与更新:
(a)在训练过程中,模型的参数和前缀嵌入会根据任务目标进行更新;
(b)通过反向传播算法,计算损失函数关于模型参数的梯度,并更新模型参数和前缀嵌入。
P-Tuning v2的核心思想是通过在模型的每一层引入可训练的前缀,从而使模型能够学习到特定任务的信息。这种方法不仅提高了模型的灵活性,而且在不增加过多参数的情况下,提升了模型对特定任务的适应能力。
将模型的参数集合定义为θ,其中包含多层的模型参数(θ1,θ2,…,θn)。每一层(i)添加一组可学习的提示Pi,与模型的输入X共同参与模型的计算。
每一层的提示Pi可以表示为:[Pi=fi(Pi-1,θi)],其中fi为计算函数,θi是第i层的参数,Pi-1为前一层的提示。在训练过程中,每层提示Pi通过最小化损失函数L进行更新:
Pl:[minP1,…,PnL(Y,Y^(X,P1,…,Pn,Θ))](1)
其中:Y为真实标签,Y^是模型的预测输出。
MedGLM.H模型的任务是在肝胆领域提供专业的问答,基本上是一个涉及序列标注的具有挑战性的NLU任务。在Zhang等人进行的研究中,当面临这些困难的NLU挑战时,P-Tuning v2表现出与Fine-Tune相当的性能,同时需要更低的计算资源。因此, P-Tuning v2更适合MedGLM的第一阶段训练。
2.5 阶段2:基于私有临床数据微调
在第一阶段之后,MedGLM.General的底层已经得到很好的训练,在一般医学问答任务中表现出合理的准确性。为了保留MedGLM.General在一般医学问答任务中的性能, 本文选择在微调的第二阶段冻结基础层,仅允许更新最后5层的参数。
对于冻结的参数θi,(i≤k):[θ(t+1)i=θti]。
对于参与微调的参数θj,(j≤k):[θ(t+1)j=θtj-ηLθj],它们按照梯度下降法更新。其中t为迭代次数,η为学习率,L是损失函数。
在数学上,这可以表示为在微调过程中,对于每个冻结的参数θi, 本文设置(Lθi=0)。这意味着这些参数的梯度为零,因此在反向传播过程中不会更新。对于需要更新的参数, 本文正常计算梯度并更新参数值。
freeze微调的优点是能够利用预训练模型的强大表示能力,同时通过微调少数参数来适应特定任务,这在数据量有限或者计算资源受限的情况下尤其有用。
鉴于已处理的专业临床数据量有限,freeze微调使得可以使用少量数据进行模型细化,同时保留源模型的一些性能。经过freeze微调后,MedGLM.H能够在保持MedGLM.General在一般医学知识问答任务中强大性能的同时,解决肝胆e034b963c0f7cebd3ff043842b28dad1专业领域的特定问题。
3 实验与结果
3.1 实验设计
为了验证两阶段微调的有效性及MedGLM.H的专业性,本文设计了四个实验以评估微调方法的综合性能、MedGLM.H模型对于临床医疗问题的解答效果、模型在微调前后的性能对比以及MedGLM.H对于肝胆专科医学的专业性。
用模型微调效果的通用评价指标进行微调方法性能的评估;设置一项对于临床医疗问题的双盲评估实验,由临床医生根据通用医疗大语言模型与MedGLM.H对相同临床医疗问题的回答进行评估
;设置肝胆专科试题集,对比微调前后模型的准确率与得分率;最后,由三位临床医生进行10轮的对话以评估模型在专业医疗场景的实用性。
1)微调效果评估实验
实验验证阶段, 本文在东方肝胆外科医院的病历数据中避开训练集,随机选择了500组肝胆科患者的问诊主诉作为Q(question),使用GPT-4对问诊进行回答作为A(answer),以此作为验证集。 本文采用BLEU(bilingual evaluation understudy)值[15]和Rouge score(Rouge,recall-oriented understudy for gisting evaluation)[16]对微调后的模型进行评估,评估结果在第3.3小节。然而,应注意的是,BLEU和Rouge分数仅在评估模型生成的答案在验证集中与参考答案匹配的程度方面是可靠的。对于真实的临床应用,仍然需要进行进一步的评估[17]。
2)双盲问答对比实验
为了对比MedGLM.H对于临床医疗问题的解答效果,本文选取MedGLM.H的源模型ChatGLM-6B以及该模型通过Instruct-Tuning微调后得到的医学通用大语言模型ChatGLM-Med进行双盲评估实验。在实验中,三个模型对于同一肝胆科临床医疗问题进行解答,由专业的肝胆科临床医生对模型生成的答案质量进行综合评分。
3)微调前后对比实验
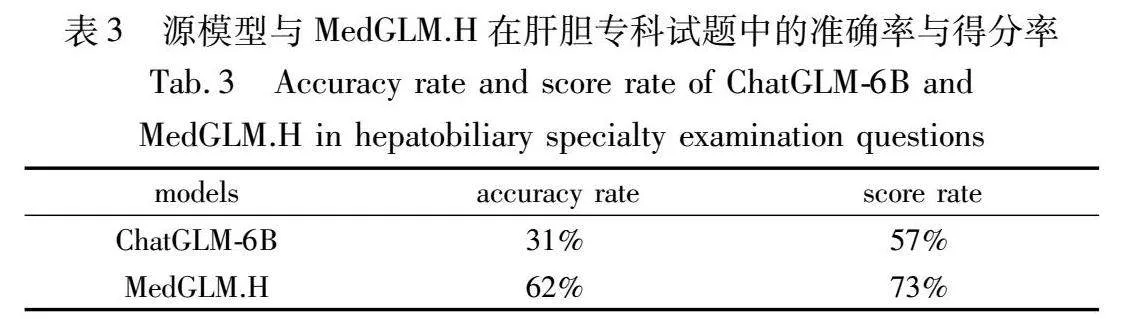
此外,在验证两阶段微调框架的有效性及MedGLM.H在肝胆专科的专业性方面,通过建立肝胆专科的真实题库作为验证集,与未经微调的ChatGLM-6B进行对比实验。验证集中的真题来自中国执业医师资格考试、临床医院中肝胆科出科考试与临床医学专业考试中关于肝胆科的真实考题。整合后的肝胆专科试题包括100道单项选择题与10道主观题。统计对比选择题的正确率与简答题的得分率。简答题的判分由东方肝胆外科医院的临床医生进行。
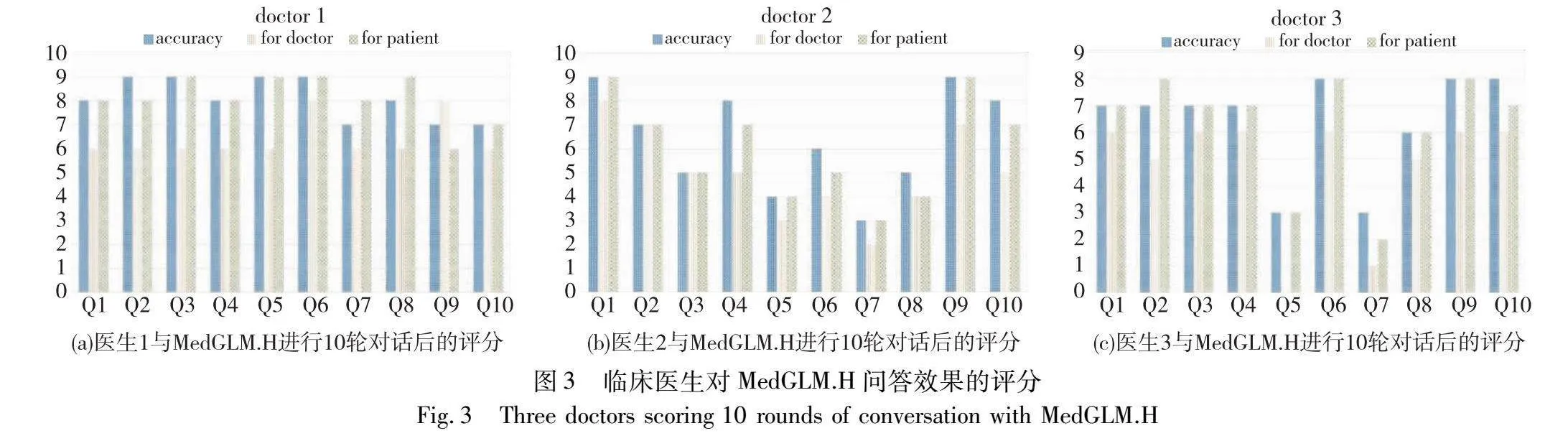
4)临床医生对话评估实验
为了验证MedGLM.H的临床适用性和专业性, 本文邀请了三位有着丰富临床经验的肝胆科医生与MedGLM.H进行10轮对话。将MedGLM.H的回答在准确性、对医生的参考价值和对病人的适用性三个维度上进行评估。旨在评估MedGLM.H的临床适用性和专业性。
3.2 评价指标
BLEU分数是用于评估AI模型机器翻译质量的一项评价指标,它会根据模型生成的结果与验证集中答案的匹配程度给出分数,这个分数在0~1,BLEU值越接近1则翻译质量越高。Rouge score是一种用于衡量自动文摘生成质量的指标,它根据生成的文摘与参考摘要之间的匹配程度给出分数,同样在0~1,1表示最匹配,0表示最不相关。
BLEU值与Rouge score的评估仅能保证MedGLM.H的回答是否与GPT-4相接近(尽管GPT-4对于医学问题的回答质量已经非常高),无法表明MedGLM.H对肝胆科患者或医生的适用性。因此设计准确性、对医生的可参考性、对病人的适用性三维度的评估是必要的。
3.3 结果与分析
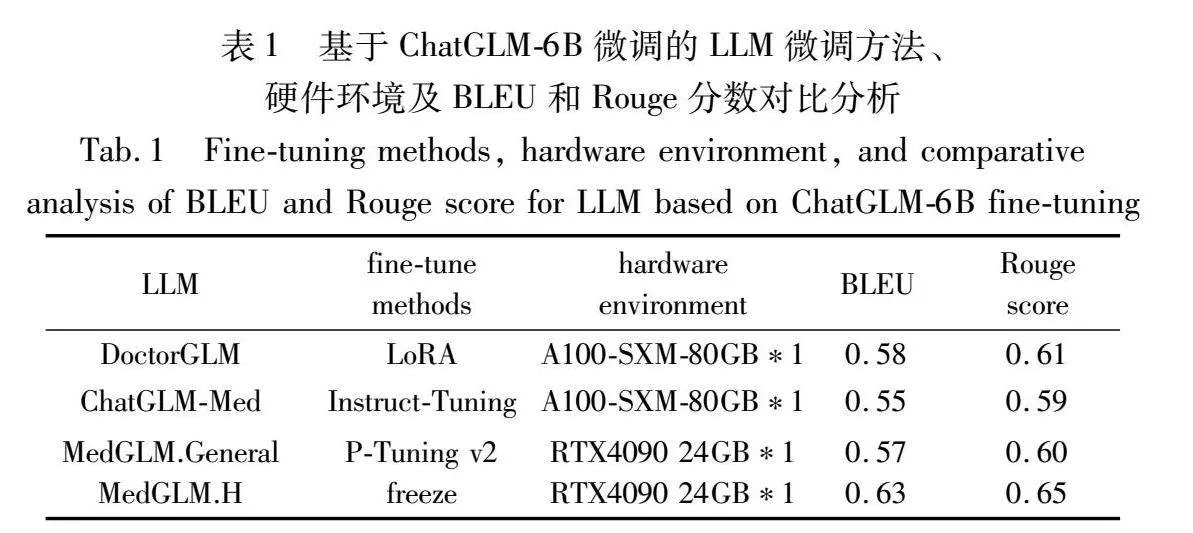
本文对比了几种基于ChatGLM-6B微调的医学大语言模型的微调方法与硬件环境,并对验证集进行BLEU与Rouge score指标评估,各大语言模型的对比验证结果记录在表1。
为了更加直观地对比几个医疗模型对于临床问题的解答效果, 本文进行了一次双盲问答对比实验,由东方肝胆外科医院的临床医生对答案的质量进行综合评分。在这个对比实验中, 本文展示了三个医学模型对于临床问题的回答。对话的内容和答案分别由三个不同的医学模型生成,但在展示给评估者时,没有显示模型的名称,以确保评估是双盲的。临床医生对这些答案的质量进行评估,并给出了综合得分。评估者只根据内容和质量来评估答案,而不知道模型的身份。这种实验证明了医学模型在回答临床问题时的性能,并提供了更直观的比较。对话的内容如表2所示。
对比实验的结果见表3,准确率表示模型对于试题中单项选择题的正确率,得分率为模型对于简答题生成的答案的得分。每道简答题的答案由肝胆专科的医生进行0~10分的打分,共计10道简答题。医生对于简答题的评判标准与临床医学专业考试及肝胆科实习医生出科考试一致,以此保证实验结果的有效性。
在基于肝胆专科试题的对比实验中,MedGLM.H展现了较高水准的肝胆专业问答水平。在得分上,与Flan-PaLM 540B在美国执业医师资格考试中取得的准确率相当[17]。其中MedGLM.H对于单项选择题的准确率达到了源模型的两倍,简答题的得分率在源模型的对比下也显示出了较大的改进。尽管目前MedGLM.H对于执业医师资格考试等专业试题的准确率与临床医生仍有一定差距。但就目前而言,本研究在轻量级大语言模型微调中进行专业领域的针对性微调表现出了一定的潜力。
本文期望MedGLM.H能够解答肝胆科常见的临床问题并且为医生提供一些治疗意见。因此,对于MedGLM.H生成的答案还需要进行三个维度的评估,分别为:生成答案的准确度、生成的答案对病人的适用度以及给医生的参考价值。 本研究邀请了三位来自东方肝胆外科医院的主治医生与MedGLM.H进行10轮的对话,最终对MedGLM.H生成的答案进行评估。图3展示了三位医生对MedGLM.H生成答案的评估。
可以证明MedGLM.H在更专业的医疗场景中执行对话任务的效果有一定的专业水准。这为训练更加专业的医疗大语言模型提供了一个思路:使用经过加工的专科病历文本数据对医疗通用大语言模型进行微调可以得到一个聚焦于某一科室的大语言模型,并且它的成本是绝大部分医院或临床医学研究团队能够负担得起的。
4 讨论与展望
尽管医学通用的大语言模型已经在早前推出,但这些大语言模型并没有广泛地部署在临床医院。一个主要的原因是这些大语言模型的对话质量对比此前一些医院部署的问答系统并没有突破性的进展。由于训练这些医学通用大语言模型的数据集很多都是来自这些基于医疗咨询数据库的问答系统,所以这些大语言模型的回答不可避免地会与早先的问答系统高度类似,并没有体现出AIGC技术的优越性[18]。MedGLM.H解决这一问题的方法是使用经过处理的病人病历及诊疗记录的文本数据对大语言模型进行微调,以提高它的对话质量。
本文的工作在低学术预算的情况下,基于通用医学知识图谱和专业的临床数据通过“造极”训练了针对肝胆专科的医疗对话大语言模型。在中国执业医生资格考试等专业医学考试中肝胆科试题的准确率与更大参数级别的大语言模型Flan-PaLM 540B在美国执业医师资格考试中取得的准确率相当。这为许多有相似情况的学术团队提供了思路,对推广训练或部署专业大语言模型也作出了一定的贡献。
尽管MedGLM.H在实验验证阶段展示了一定的专业水平,能够回答肝胆科一些专业的问题。但由于参与微调训练的数据并不十分完善且数据量有限,加之这项工作仍处于研究早期,它的回答不应该被完全信任。 本研究期待接下来的工作能够使它更加可信任,以便于部署到医疗资源匮乏的地区或社区医院。
本研究的目标是训练一个能够给医生提供专业诊疗意见、为临床病患解答专业性医学问题的专业医疗对话大语言模型。就目前的工作而言, 本研究迈出了第一步。它仍有许多问题亟待解决。如:MedGLM.H的回答需要保证相当高的准确率,给出的诊疗意见也需要大基数的实验来验证其有效性与无害性;对于医学检验结果的诊断与解答还需要进一步的训练以提高准确度。在未来, 本研究预备进行以下工作来改进Med-GLM,使它的回答能够更加准确与多元。
a)在东方肝胆外科医院不断进行测试,收集测试结果对大语言模型进行改进。
b)使用各科室的临床数据与病历文本设计医学知识图谱,以外接知识库的形式接到MedGLM.General,使MedGLM.General能够回答除肝胆科以外的专业问题。
c)接入传统机器学习或深度学习对某些疾病的预测模型,医生能够向MedGLM提问相关病症发展阶段的指标特征或干预措施对病症发展的影响。
d)通过设计prompt并使用特定数据微调使MedGLM能够做到对部分疾病的早期筛查。
参考文献:
[1]Radford A, Narasimhan K, Salimans T,et al. Improving language understanding by generative pre-training [EB/OL]. (2018) [2024-03-13].
http://www.mikecaptain.com/resources/pdf/G PT-1.pdf.
[2]Du Zhengxiao, Qian Yujie, Liu Xiao,et al. GLM: general language model pretraining with autoregressive blank infilling [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2022: 320-335.
[3]Himabindu L, Dylan S, Chen Yuxin,et al. Rethinking explainability as a dialogue: a practitioner’s perspective [EB/OL]. (2022) [2024-03-13]. http://doi.org/10.48550/arXiv.2202.01875.
[4]Esteva A, Chou K, Yeung S,et al. Deep learning-enabled medical computer vision [J]. NPJ Digital Medicine, 2021, 4(1): 5.
[5]Yim J, Chopra R, Spitz T,et al. Predicting conversion to wet age related macular [J]. Nature Medicine, 2020 (26): 892-899.
[6]Tomaev N, Harris N, Baur S,et al. Developing continuous risk mo-dels for adverse event prediction in electronic health records using deep learning [J]. Nature Protocol, 2021 (16): 2765-2787.
[7]Li Yunxiang, Li Zihan, Zhang Kai,et al. ChatDoctor: a medical chat model fine-tuned on LLaMA model using medical domain knowledge [EB/OL]. (2023) [2024-03-13]
https://doi.org/10.48550/arXiv.2303.14070.
[8]Xiong Honglin, Wang Sheng, Zhu Yitao,et al. DoctorGLM: fine-tuning your Chinese doctor is not a herculean task [EB/OL]. (2023) [2024-03-13].
https://doi.org/10.48550/arXiv.2304.01097.
[9]Wang Haochun, Liu Chi, Xi Nuwa,et al. HuaTuo: tuning LLaMA model with Chinese medical knowledge [EB/OL]. (2023) [2024-03-13].
https://doi.org/10.48550/arXiv.2304.06975.
[10]Liu Zhengliang, Yu Xiaowei, Zhang Lu,et al. DeID-GPT: zero-shot medical text de-identification by GPT-4 [EB/OL]. (2023) [20 24-03-13].
https://doi.org/10.48550/arXiv.2303.11032.
[11]Hu E, Shen Yelong, Wallis P,et al. LORA: low-rank adaptation of large language models [C]// Proc of the 10th International Confe-rence on Learning Representations. Washington, DC: IUR, 2022.
[12]Shin J, Choi S, Choi Y,et al. A pragmatic approach to on-device incremental learning system with selective weight updates [C]//Proc of 57th ACM/IEEE Design Automation Conference. Piscataway,NJ:IEEE Press, 2020: 1-6.
[13]Touvron H, Lavril T, Izacard G,et al. LLaMA: open and efficient foundation language models [EB/OL]. (2023) [2024-03-13]. https://doi.org/10.48550/arXiv.2302.13971.
[14]Liu Xiao, Ji Kaixuan, Tam W,et al. P-Tuning v2: prompt tuning can be comparable to fine-tuning universally across scales and tasks [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: ACL, 2022: 61-68.
[15]Papineni K, Roukos S, Ward T,et al. BLEU: a method for automatic evaluation of machine translation [C]// Proc of the 40th Annual Meeting of Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 311-318.
[16]Lin C Y. ROUGE: a package for automatic evaluation of summaries [C]// ACL Proc of Workshop on Text Summarization Branches Out. Stroudsburg, PA: ACL, 2004: 74-81.
[17]Singhal K, Azizi S, Tu T,et al. Large language models encode clinical knowledge [J]. Nature, 2023, 620(7972): 172-180.
[18]Cao Yihan, Li Siyu, Liu Yixin,et al. A comprehensive survey of AI-generated content (AIGC): a history of generative AI from GAN to ChatGPT [J]. Journal of the ACM, 2018, 4(37): 111-155.
