大语言模型领域意图的精准性增强方法
2024-10-14任元凯谢振平







摘 要:目前通用大语言模型(如GPT)在专业领域问答应用中存在不稳定性和不真实性。针对这一现象,提出了一种在通用大语言模型上耦合领域知识的意图识别精准性增强方法(EIRDK),其中引入了三个具体策略:a)通过领域知识库对GPT输出结果进行打分过滤;b)训练领域知识词向量模型优化提示语句规范性;c)利用GPT的反馈结果提升领域词向量模型和GPT模型的一致性。实验分析显示,相比于标准的GPT模型,新方法在私有数据集上可以提升25%的意图理解准确性,在CMID数据集上可以提升12%的意图理解准确性。实验结果证明了EIRDK方法的有效性。
关键词:大语言模型知识问答;意图精准性增强;领域知识集成;GPT反馈学习
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)10-002-2893-07
doi:10.19734/j.issn.1001-3695.2024.02.0022
Intention recognition accuracy enhancing method for large language model
Ren Yuankaia, Xie Zhenpinga, b
(a.School of Artificial Intelligence & Computer Science, b.Jiangsu Key University Laboratory of Software & Media Technology under Human-Computer Cooperation, Jiangnan University, Wuxi Jiangsu 214122, China)
Abstract:Large language models (such as GPT) exhibit instability and inauthenticity in professional domain Q&A applications. To address this issue, this paper proposed a method to enhance intent recognition by domain knowledge (EIRDK) for large language models. The method involved three specific strategies: a)scoring and filtering the GPT output using a domain knowledge base, b)training the domain knowledge word vector mode to optimize prompt, c)utilizing feedback from GPT to improve the coherence between the domain word vector model and the GPT model. Experimental analysis demonstrates that, compared to the standard GPT model, the new method achieves a 25% improvement in intent understanding accuracy on the private dataset and a 12% increase on the CMID dataset. The results validate the effectiveness of the EIRDK method.
Key words:knowledge Q&A with large language models; intent recognition accuracy enhancement; domain knowledge integration; feedback learning from GPT
0 引言
信息化时代下,问答系统已经成为人工智能领域备受瞩目的研究和应用方向,涵盖搜索引擎、虚拟助手、在线教育、医疗保健等。其核心目标在于使人与计算机之间的交互更为自然和智能,用户通过自然语言提出问题,而问答系统则以相应的反馈作出回应[1,2]。基于问答系统的工作原理和实现方式,主要可分为检索式问答系统和生成式问答系统两个类别。生成式问答系统直接根据用户提问生成相应答案,能够处理各类问题,但无法确保生成结果的真实性和可靠性。当面对复杂问题时,这类系统可能误导用户,提供不准确或不完整的信息,从而降低用户体验和信任度。相较之下,检索式问答系统在一定程度上能够规避这一问题。该系统依赖高质量的知识库,通过对用户输入的自然语言查询(query)进行检索匹配,从大规模文本或知识库中获取准确的答案或信息,确保了问答系统的可用性。然而,在理解用户输入的自然语言方面,检索式问答系统存在一些限制,难以准确理解用户的意图。
随着大语言模型(LLM)的快速发展,问答系统的研究人员逐渐尝试利用大语言模型对用户的意图进行解析。最近,OpenAI推出了ChatGPT,这是一种基于GPT-3.5架构的革命性大规模语言模型,能够胜任目前几乎所有的自然语言处理任务,包括信息抽取、文本摘要、风格续写、代码生成等[3~5]。与现有大规模语言模型不同的是,ChatGPT利用人类的反馈数据进行训练,通过强化学习的方式,使得ChatGPT能够生成类似人类的回复[6~8]。由于在各类任务上均表现出了惊人效果,ChatGPT发布仅两个月后就吸引了全球1亿活跃用户。随后在2023年的3月,OpenAI推出了GPT-4,一个更为强大和智能的语言模型,与GPT-3.5相比,GPT-4拥有更多的参数以及更大的规模,在多任务学习方面有着突破性的进展,在各个任务上均有着显著的提升。
尽管目前的大语言模型(如ChatGPT)已经能够作为生成式问答系统提供高质量的问答交互服务,但仍然无法避免生成虚假或有害信息,尤其在专业领域的问答上,面对一些未知信息,大语言模型可能会编造出一些与事实无关的回答返回给用户,这将带来灾难性的后果。因此,本文将专注于检索式问答的模式,利用ChatGPT优秀的意图对齐以及文本生成能力,对用户的query进行意图解析并从知识库中检索召回相应的答案。基于该模式,本文提出了一种基于领域知识的意图识别精准性增强框架(enhance intent recognition by domain knowledge, EIRDK),该框架通过与领域知识库的有机结合,旨在寻求一种经济有效的方法,以提升生物医药领域中检索式问答系统对自然语言问题的意图理解能力。
1 相关工作
1.1 语言模型
自然语言处理领域的语言模型通常采用预训练的方法进行初始化,随后通过特定数据微调的方式应用于下游任务[9],这一方法的应用使得语言模型在一定程度上能够理解和生成自然语言文本。预训练语言模型可分为静态和动态两类,早在2003年,Bengio等人[10]提出了NNLM模型,催生了一系列静态预训练模型,如word2vec、GloVe、FastText等[11~13],然而,这些模型在解决多义性和下游任务改进方面存在一定限制。动态预训练模型的概念首次出现于2018年3月,ELMo利用双向LSTM进行预训练,有效处理词语多义性[14]。同年12月,Google发布双向语言模型bidirectional encoder representation from Transformers(BERT),引入了双向Transformer结构,BERT的出现标志着预训练技术的新时代[15]。自那时以来,涌现了许多改进型模型,如RoBERTa、ALBERT、自回归语言模型XLNet、通用统一框架T5等[16~19]。
1.2 意图识别
意图识别是自然语言处理领域的YCU72+D5OFiR2GHOQUx6Rg==重要研究方向,旨在解决计算机对人类语言的意图理解和问题推断。这一技术的核心目标是识别并解释用户在交流过程中所表达的意图,以便更好地响应用户的需求。在实际应用中,意图识别通常与问答系统、虚拟助手和自动客服等领域相结合,以提升计算机系统对用户输入的理解程度[20~22]。
为了实现有效的意图识别,研究人员采用了多种方法,早期流行基于规则的方法,随着统计学习和深度学习的发展,意图识别的技术也随之进步[23~26]。2018年,以BERT为代表的预训练语言模型横空出世,在自然语言处理的各项任务上均取得了显著效果[15]。这些预训练语言模型通过大规模数据进行学习,能够捕捉文本中的复杂语义和上下文信息,同时拥有极强的泛化性,这使得基于预训练语言模型的意图识别方法也拥有较高的精度和泛化性[27,28]。
随着问答系统的普及,意图识别在人机交互、智能客服等场景中的应用逐渐增多。通过准确识别用户的意图,系统能够更加智能地回应用户的需求,提升用户体验。然而,面对多样化的语言表达和复杂的语境,意图识别仍然面临一系列挑战,如歧义消解、长对话建模等问题,需要不断的研究和改进。
1.3 提示工程
随着参数量超百亿的大规模语言模型(例如ChatGPT)展现出卓越的文本生成能力,提示工程(prompt engineering)逐渐成为自然语言处理领域的新兴范式[29]。提示工程的核心目标在于为预训练模型设计恰当的提示,以确保在下游任务中获得出色的效果,这催生了一种被称为“预训练、提示、预测”的新兴范式[30~33]。具体而言,提示工程创建了一个提示x′=fprompt(x),其中x∈X,为文本输入(例如“找出治疗糖尿病的所有药物”),并描述了具体的下游任务(例如文本摘要、text2sql、代码生成等)。具备提示后,大语言模型执行得到最终的答案y=fLLM(x′) 。
目前prompt主要通过四5IQ9CILxHR+hpbBU7Qx4rA==种方式生成:
a)手工构建。手工编写文本段落用于提示语言模型进行相关回答,这是一种简单而有效的提示生成方式,但性能较为不稳定,需要细致的调试。
b)大语言模型生成。利用大语言模型为每个文本输入生成对应的提示,可以弥补手工构建的不足,但较为复杂的场景下,提升的效果无法得到保证。
c)基于检索的提示。依赖于良好标注的外部资源(例如百度百科)来减轻生成不稳定性的问题。
d)提示学习。构建了一个有监督模型,根据大语言模型的生成和真实标签(ground truth)自动更新提示。
2 方法框架
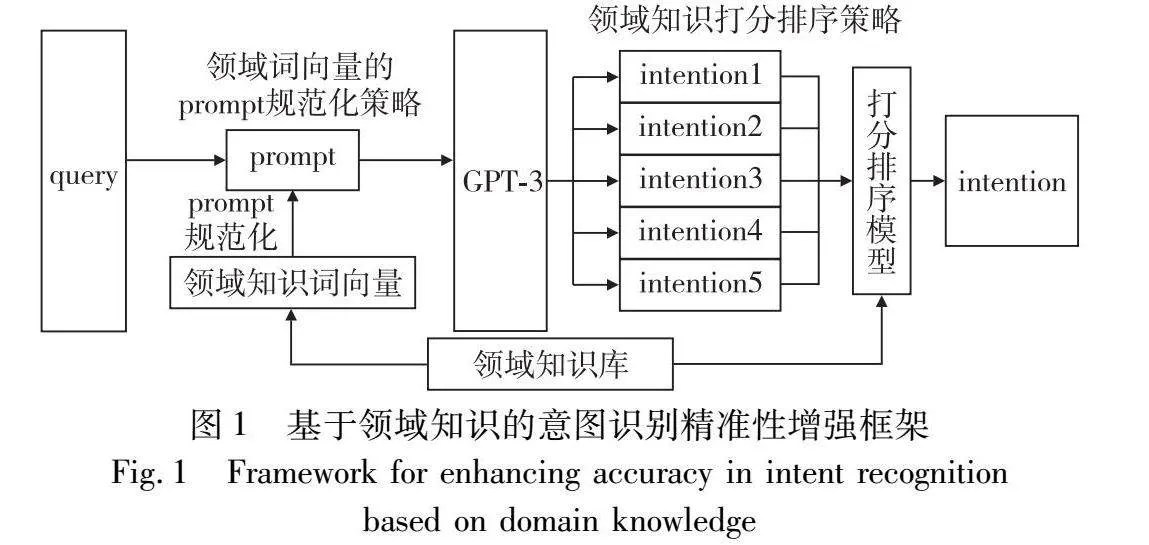
本文EIRDK方法框架如图1所示,整个框架的输入为用户的query(例如“糖尿病应该吃什么药物”),框架输出对应意图(例如“drug|disease_name:糖尿病”),整个框架可分为两个部分:
a)本文利用领域词向量和领域知识库对prompt进行规范化。根据用户输入的query,从领域知识库中提取相关信息补充到prompt中,提升ChatGPT的领域背景知识,这一步的目标是确保系统能够更精准地理解用户的意图,使得整体框架在处理意图识别问题时表现更为卓越。
b)本文借助领域知识对ChatGPT输出的意图进行打分和排序,以增强意图识别的稳定性。本文旨在提高系统的鲁棒性和适用性,确保系统在各种情境下都能可靠地识别用户的真实意图,使其在复杂的问答环境中表现更为可靠。
最后,本文探索了一种将领域词向量模型与ChatGPT对齐的方法。通过ChatGPT的反馈结果对本地领域词向量模型进行优化,并评估其对意图识别准确性的提升效果。通过这一创新性的尝试,本文期望在领域知识与先进生成技术的协同作用下,进一步优化意图识别性能,为生物医药领域的检索式问答系统提供更为强大的解决方案。
2.1 prompt规范化策略
2.1.1 通用prompt构建
考虑到本文定义的意图识别结构较为复杂,决定采用人工构建prompt的方案,以此来引导ChatGPT进行意图识别并生成一个SOLR(search on lucene replication)可识别的检索式。随后利用部分数据集进行测试和优化,确保最终得到的prompt在生物医药的常规问题上都能有一个较好的效果。由于ChatGPT的性能对prompt的设计非常敏感,本文参考Wei等人[34]提出的思维链(chain of thought,CoT)策略,按照如下形式构建prompt:
a)角色和概念定义。首先对ChatGPT进行角色定义:“你现在是一位生物医药领域的专家,请帮我根据下面的例子完成意图识别任务”。接着对生物医药领域的知识库进行抽象的表示,包括实体的语义标签(semantic type)、属性的标准名称、意图所在的索引等。同时,在给出相关定义后会提供1、2个例子作为该条定义的解释和补充。
b)少样本学习(few-shot learning)。对ChatGPT进行角色定义和相关概念描述后,根据定义的索引,提供若干条例子作为few-shot learning的例子。理想情况下给出的例子越多越好,但由于prompt长度的限制以及生物医药领域query的多样性和复杂性,无法穷举所有情况的query。因此,本文只提供一些相对通用的例子作为ChatGPT学习的模板。prompt构成示例如图2所示,其中第1行表示对ChatGPT角色的定义,第2~5行表示对实体标签的定义,第7~11行表示数据源的定义,第12行表示属性的定义,第14行开始表示给定的few-shot示例,期望ChatGPT按照示例的格式进行意图识别。最终的prompt在此基础上进行补充,由于篇幅过长,不进行详细的展示。
2.1.2 领域知识引入
领域知识在自然语言处理任务中扮演着至关重要的角色,它有助于模型更深刻地理解和生成特定领域相关的文本,提供更为准确和实用的答案。尤其是在信息检索和意图识别任务中,它可以协助模型更好地理解用户的query,识别出关键信息,生成相关性更高的回复。以生物医药领域为例,如果用户提出与医学相关的问题,模型需要具备关于医疗术语、疾病、药物、治疗方法等方面的知识,以生成准确的回答。
为了提升ChatGPT的专业性,本文在之前定义的提示中引入生物医药领域的相关知识,主要包含两个步骤。
a)query领域基本信息。利用领域知识对query中的实体(entity)信息进行解析和抽取,将解析后得到的领域基本信息添加到prompt中。
b)query领域相关信息。利用领域知识进行预训练得到BERT词向量模型,随后利用BERT模型对输入的query进行相似度匹配,从已有的领域知识库中选取与之最相似的若干条结果,将其作为query的相关领域知识和相关结构知识补充添加到prompt中。
通过以上两个步骤,本文将领域知识动态地添加到prompt中,使得ChatGPT在生成回复时能够获取到这些领域知识,产生更为精准的意图结果。本文将引入了领域知识的意图识别任务定义为
y=f(x′,d|θ)(1)
其中: f(·|θ)表示参数为θ的神经网络;x′表示预先定义的prompt;d表示额外引入的领域知识;y表示最终得到的意图。值得注意的是,本次实验发现领域知识添加的位置对意图识别的效果也会存在一定影响,在prompt结尾加入领域知识相比于其他位置更有助于ChatGPT的利用。
最终,本文利用领域知识库作为预训练数据,以双语BERT为基础模型,采用经过三个epoch进行预训练后的BERT作为领域词向量模型,通过该词向量模型对领域知识库中的文档和用户输入的query进行向量化处理并储存,以此来生成领域知识库词向量。
应用自动引入领域知识的策略时,用户输入的query首先被映射成和领域知识向量相同维度的词向量,然后通过余弦相似度算法进行计算并排序,系统根据排序后的结果返回与输入query相似度得分较高的top-k示例(k值可以作为超参数设置,实验中发现k=5的效果为最佳),作为领域知识的补充,这些示例不仅能够提供额外的信息和实例,还有助于模型更全面地理解用户的query并生成相关的回复。后续在实际的应用中时,可以考虑将用户的意图进行收集,不断地更新领域知识库并定期进行词向量模型的更新,实现整个策略的良性循环。为了更精准地提取query的相关信息,本文构建了一个领域知识词典,利用后向最大匹配算法,对query中的领域词进行抽取。prompt引入领域知识的具体算法逻辑如算法1所示。
算法1 基于领域知识的prompt自动优化算法
输入:D={d1,d2,d3,d4,d5,…,dn},D represents samples in domain knowledge base, and x represents the input query。
输出: a prompt that integrates domain knowledge。
a) embed D to edoc and embed x to eq /*对领域知识和输入的问题进行向量化*/
b) calculate similarity score sq,doc between eq and edoc /*计算相似度文档和输入问题的相似度*/
c) sort sq,doc in descending order and select top-5 docs Dsub /*获取和输入问题最相近的前5条数据*/
d) extract entities wx information from x /*利用领域知识词典进行信息提取*/
e) merge Dsub and wx into prompt /*合并第三步和第四步的知识加到prompt中*/
举例来说,用户提出一个生物医药领域的query:“治疗高血压的最新药物有哪些?”。本文根据这条query从知识库中匹配出基本信息和相关信息。基本信息包括:“disease:高血压”,“date:最新”,相关信息包括:“治疗高血压的药物=>drug|disease_name:高血压”,“降血压的药物有哪些?=>drug|disease_name:降血压”。
2.2 意图打分排序策略
生成式大语言模型一直以来以输出多样性而著称,但是在某些任务中需要限制输出的多样性以此来确保结果的稳定性。当使用ChatGPT进行意图识别任务时,可以发现它的输出结果通常会随时间而变化,这对于意图识别任务来说可能会导致严重的不稳定性问题。针对上述问题,本文通过领域知识训练打分排序模型,利用ChatGPT能够一次性生成k条结果的特性,在其输出k条意图后,用领域模型进行排序和过滤,选取最佳的结果,以此来帮助模型获取稳定的意图结果。
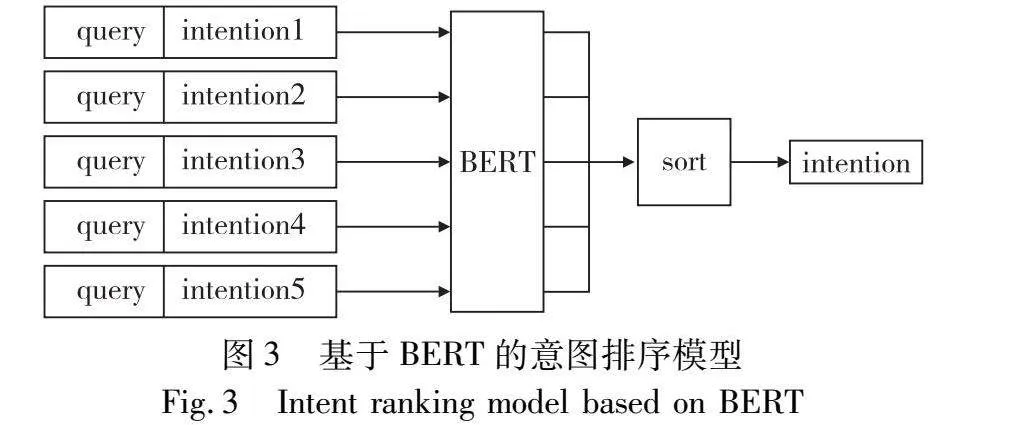
鉴于query和意图结果都需要强大的知识理解和表征能力,本文选择了BERT语言模型作为领域判别模型的基础模型,用于文本表示和语义理解。BERT通过特定领域数据的微调,可以适应该领域的语言风格和术语,对query和意图结果将有更好的知识理解和表征能力。模型结构如图3所示。
在微调阶段,本文根据BERT预训练数据的结构,构建出类似的形式,以满足BERT对query和意图结果进行联合理解的需求。模型的输入由query和意图结果构成,将它们拼接后得到一个联合的表征(representation)。这种联合表征的构建允许模型同时考虑query和意图结果的信息,帮助模型更好地捕捉它们之间的关联性及上下文信息,这一特性在解决信息检索和意图识别任务时显得尤为关键。由于query和意图结果之间的语义关系往往复杂多变,通过拼接的方案,本文为模型提供了更为丰富的输入,以此来帮助模型理解query和意图识别结果之间的内在联系。打分排序模型的目标函数如下所示。
score=fBERT(x;y|θ)(2)
其中: fBERT(·|θ)表示基于BERT的打分模型;x表示用户输入的query;y表示ChatGPT从query中解析出的意图。基于领域知识的语义判别算法如下所示。
算法2 基于BERT的语义判别模型
输入: training samples,Di={(x1,y1),(x2,y2),(x3,y3),(x4,y4),…,(xm,ym),},m represents the number of samples。
输出: semantic discrimination model after parameter updates。
a) for j=1,…,L
b) for the jth similarity score do
c) assign a null value to Dj;
d) for (x,y)∈Dj
e) build samples for each x, Dsub={(x1,y1),(x1,y2),(x1,y3),(x1,y4),(x1,y5)} /*利用对比学习生成的训练样本组成正负样本*/
f) minimize the contrast loss between positive and negative samples in Dsub//最小化正样本的损失,最大化负样本的损失
g) back propagation
h) end for;
i) end for;
j) end for
为了进一步提高BERT模型的性能,本文采用对比学习的方法来进行训练。对比学习是一种自监督学习方法,通过正样本与负样本进行比较来学习有意义的表示[35]。本次研究的场景中,正样本是query和正确意图结果的联合表示,而负样本则是来自query和错误意图结果的联合表示。
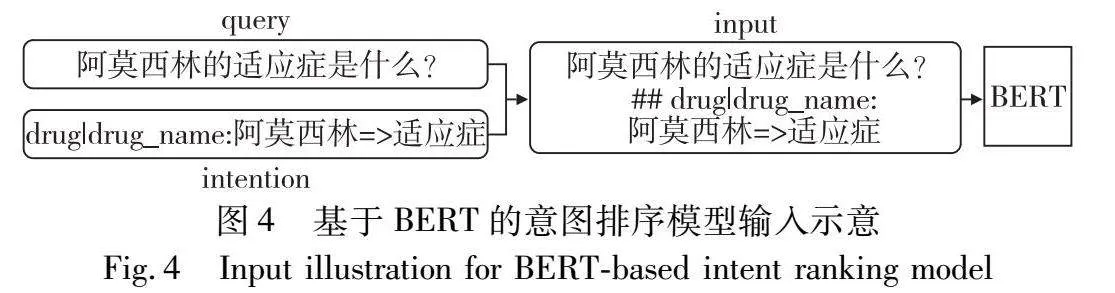
具体地,本文从训练数据中随机挑选若干对query和意图结果,拼接后得到它们的联合表示,作为正样本。随机将query和不同的意图结果拼接得到负样本。模型的目标是使正样本的表示更加相似,同时使得负样本的表示更加不同,本文通过最小化正样本与负样本之间的对比损失来实现。对于当前的意图识别任务,同一层级的实体位置可以互相转换,因此,本研究中的正样本可以通过实体之间位置的互换增强模型的鲁棒性。模型的输入如图4所示。
本文利用对比学习的训练方式,帮助模型学习更具判别性的表示,提升信息检索和意图识别的性能。通过强化相同领域的query和意图结果之间的关联性,使得整个模型框架可以更好地捕获领域特定的知识和语义信息。
2.3 词向量模型对齐策略
通常情况下本地领域词向量模型和调用的ChatGPT模型并不能完全匹配,由于它们之间缺乏一些对齐的手段,有时候经过领域词向量模型推荐筛选出来的信息并不是ChatGPT模型最期望的,导致某些query语句生成的prompt不是最优。
想要解决本地领域词向量模型与ChatGPT模型之间的不匹配问题,需要深入研究它们之间的差异,并寻找一些对齐的方法来提高它们的一致性。首先,需要认识到ChatGPT模型和本地词向量模型在训练任务、数据集和架构设计上存在显著的差异。ChatGPT-3.5是一种基于生成的语言模型,通过大规模的对话数据进行无监督学习。相比之下,本地词向量模型是在特定领域的监督任务上进行训练,使用的数据集和目标不同于ChatGPT。这种差异可能导致本地词向量模型在某些情境下难以准确捕捉到ChatGPT模型的语境和偏好。为了弥补这一差距,本文提出一种创新性的方法,利用ChatGPT生成的结果作为优化信号,辅助本地词向量模型学习到ChatGPT的偏好。
在这一新的方法中,本文将ChatGPT生成的结果作为监督信号,帮助本地词向量模型学习到ChatGPT在特定任务中的期望输出。具体而言,首先利用本地词向量选取query的若干条相关数据组成新的prompt,然后利用ChatGPT进行意图识别,最后利用本地词向量模型分别对GPT返回的结果和真实标签进行向量化并计算余弦相似度Loss,最终引导本地词向量模型朝着ChatGPT更倾向的方向调整参数。由于训练时采用真实标签进行相似度计算,而非无监督学习,并且在得到ChatGPT的结果后,会利用规则进行判别,丢弃和预定义结构或者内容偏差过大的结果,以防止ChatGPT生成的异常结果造成过大的干扰。因此,尽管ChatGPT在生成结果时存在不确定性和不真实性,但可以将这些异常结果造成的影响尽可能地降低。
这种监督信号的引入有望使本地模型学习到ChatGPT的一些偏好,进而提升本地模型召回领域相关知识的能力。然而,这仍然是一个初步的尝试,需要在实践中进行深入研究和验证。通过进一步的实验和调整,有望在两种模型之间建立更为有效的桥梁,提高它们的协同效应,为用户提供更准确、流畅的生成式语言服务。
本次实验主要涉及ChatGPT和BERT语言模型,其中ChatGPT是一个生成式模型,它负责接收用户的输入query并生成相关的回复,BERT语言模型作为一个语义理解的词向量模型,它利用ChatGPT生成的意图结果和真实标签进行训练,具体算法流程如下所示。
算法3 基于ChatGPT反馈的领域词向量对齐方法
输入: training samples,Di={(x1,y1),(x2,y2),(x3,y3),(x4,y4),…,(xm,ym),}, m represents the number of samples。
输出: semantic discrimination model after parameter updates。
a) for j=1,…,L
b) for the jth similarity score do
c) assign a null value to Dj;
d) for (x,y)∈Dj
e) dynamically generate prompt for x and get response y′from GPT API /*针对输入问题动态生成prompt并从GPT获取对应的意图结果*/
f) embed y and y′ to ey and ey′ by BERT model /*利用BERT对问题的意图结果和GPT生成的意图结果进行向量化*/
g) calculate similarity score between ey and ey′ /*计算相似度损失函数*/
h) back propagation //反向传播
i) end for
j) end for
h) end for
3 实验及结果分析
3.1 任务定义
主流意图识别任务主要用于标签分类,这个标签通常是预定义的类别,代表用户的目的或意图,比如订票、查询天气、提问等。而在生物医药问答中,无法穷举这些意图,为了结合已有的数据库进行检索式问答,本次的意图识别任务主要定义为query到SOLR检索式的生成,将一个自然语言描述的query解析成一个符合SOLR检索式格式的句子,通过这种意图转换,可以将大部分的问题进行转换,然后从数据库中进行相应的知识检索。例如query“新冠病毒的最新研究进展”,本文定义的是任务是将这个query转换成“disease|disease_name:新冠病毒 AND date:最新 AND key_words:研究进展”。其中“|”左侧表示意图的类型,右侧表示意图涉及的实体和关系。
3.2 数据集
本次实验的数据集分为和本领域强关联的私有数据集和通用数据集CMID两部分,其中私有数据集一共有1 060条query,由生物医药领域内的专家结合实际问题构造而成,具有一定的权威性。通用数据集CMID为中文医学QA意图理解数据集,该数据集用于中国医疗质量保证意图理解任务,由好大夫在线提供。下面是两份数据集的处理方式:
1)私有数据集
人工对其进行意图解析和抽象表达式的转换。按照1∶4的比例进行划分后得到,训练集848条,测试集212条。利用ChatGPT分别对每一条query进行意图解析5次,即每一条query共有6对结果(1条人工标注的标准结果,5条ChatGPT的结果),私有数据集的示例如图5所示。
2)CMID数据集
由于该原始数据集包含一些和本研究无关的query,故对此数据集进行一系列的数据清洗和筛选,选取问题长度不超过10的query,剔除其中的一些停用词、标点符号并进行去重后,得到1 474条query。同样按照4∶1的比例进行数据集划分,得到1 176条训练集数据和298条测试集数据。最后按照私有数据集的标注方法对其进行意图解析和抽象表达式的转换,CMID原始数据集如图6所示,处理后的形式和图5类似,故不进行额外的展示。
3.3 评价指标
为了比较不同方法对ChatGPT生成意图的提升效果,本文选择准确率(accuracy)作为主要评价指标,以直观地评估ChatGPT生成的意图与人工标注的意图之间的一致性。准确率是一个重要的评估指标,它通过计算生成结果中正确预测的意图数与总生成意图数的比例,为本文提供了一个量化的度量,反映了模型生成结果的准确性。
意图结果对实体顺序不敏感,为了更全面地比较结果,本文引入了一致性解析的步骤。具体而言,本文对生成的意图结果进行分块处理,以捕捉语义一致性,而不仅仅是表面匹配。这意味着即使存在实体顺序上的差异,只要语义块在生成结果和人工标注结果中相对应,仍然可以将其视为一致,这将有助于确保模型评估的一致性。
这种一致性解析的方法使得本文能够更细致地评估ChatGPT生成的结果与人工标注结果之间的相似性,从而提高了评估的灵敏度和准确性。这种对语义一致性的关注是因为在自然语言生成任务中,仅仅依靠表面匹配可能无法充分反映生成结果的质量,尤其是在语境复杂或模糊的情况下。因此,本文强调在评价中综合考虑了实体顺序不敏感性和语义一致性,以便全面地了解ChatGPT在生成意图方面的性能。
3.4 实验结果及分析
3.4.1 实验结果
本文聚焦于GPT-3.5与GPT-4,并针对提出方法进行系统的实验验证。实验数据集中既包括专属的私有数据集,也包括了广泛应用的CMID数据集,两者均用以检验意图识别准确率的变化情况。
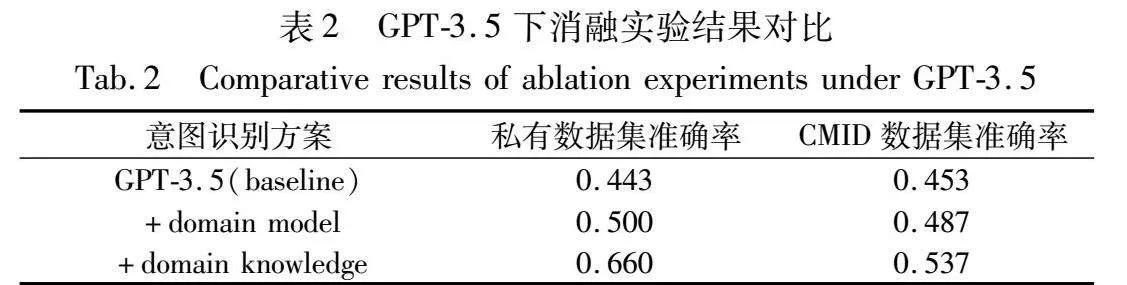
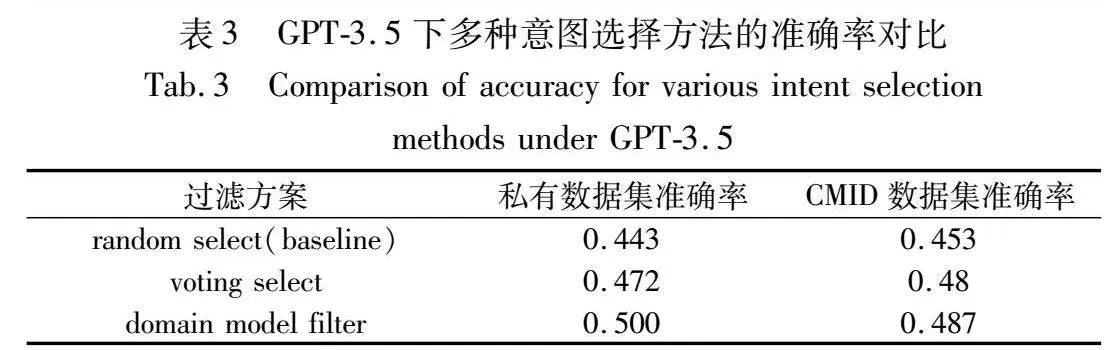
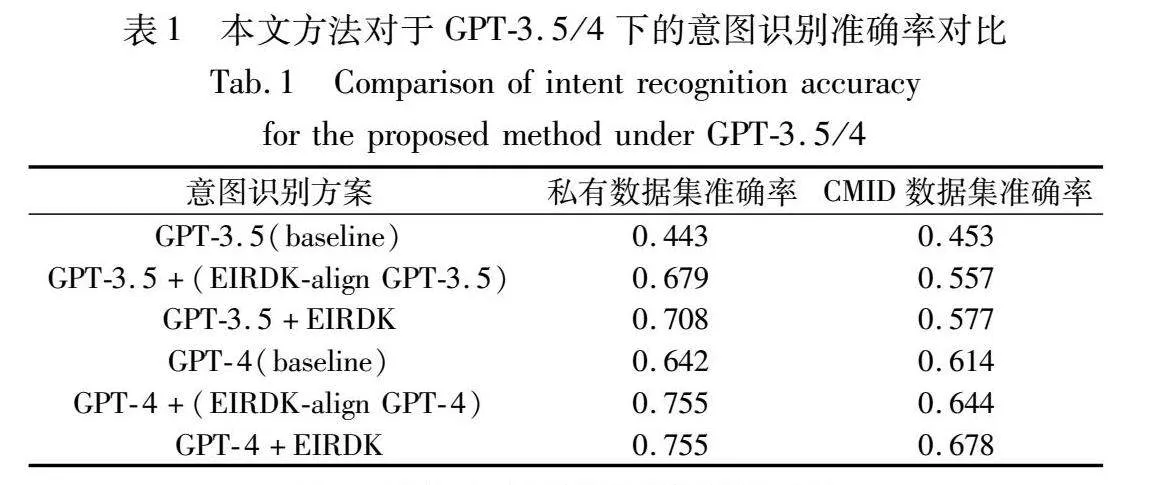
表1汇总了在不同方法应用前后,GPT-3.5和GPT-4在两个数据集上的准确率对比,结果显著揭示了提出方法的有效性;表2则提供了消融实验的准确率差异,为评估各组件的单独贡献提供了准据;表3比较了不同的领域模型过滤策略,表现了领域排序模型的筛选效力。实验结果揭示了模型性能的显著提升,特别在结合领域模型过滤和领域知识增强策略之后。
3.4.2 领域排序模型
为了评估领域模型对ChatGPT输出的稳定性提升,本文尝试了三种不同的筛选方案,以表3的形式展现。在不施加任何控制的条件下,随机选择策略的表现作为基线,反映了ChatGPT在常规场景下的表现;投票选择策略则聚焦于多次输出中的共识意图,该策略能反映出ChatGPT在不稳定性和不真实性情况下的真实表现;而领域模型排序策略旨在优选与领域相关性更高的意图,该策略能在一定程度上反映出ChatGPT输出的上限。
根据两个数据集上三种策略的性能对比,可以看出Chat-GPT的不稳定性,在多次输出的情况下会更加倾向于输出正确结果,私有数据集的投票选择性策略有0.029的提升,CMID数据集上有0.027的提升。而领域模型的排序策略则有更高的提升,两个数据集上分别达到了0.057和0.034。分析数据可以发现,只要ChatGPT能在多次输出中得到一次准确结果,本文提出的领域排序模型就有很大的概率将其筛选出来,证明了领域模型在筛选最佳意图方面展现出的卓越性和可靠性。
3.4.3 领域知识引入
从表1可以观察到,通过向GPT-3.5和GPT-4引入领域知识,使得私有数据集的准确率分别从0.443和0.642跃升至0.679和0.755,实现了显著提高。在公共数据集CMID上的实验结果虽不如私有数据集上那么突出,但也有0.1和0.03左右的提升。尽管它们的提升可以表现出领域知识嵌入对大语言模型能力的提升,但两份数据集的表现差距有点明显,尤其是在GPT-4上。针对这一现象,本文对数据集进行了观察和分析,发现CMID数据集内容十分的丰富,在引入训练集的领域知识时,很多例子并没有一些相关的数据可以被引入,这也就导致了领域知识引入的提升较小,私有数据集则没有这种情况,这也就导致了私有数据集提升明显,而CMID数据集提升不明显的情况。随后本文在CMID的训练集中添加部分和测试集拥有共性的数据进行测试验证,新的领域知识数据能够使得CMID的测试集有进一步的提升。
这些结果表明领域知识的引入对于增强大型预训练模型在特定领域中的意图识别能力至关重要,而且与传统模型微调相比,提出方法既简便又成本效益显著。
3.4.4 模型对齐
如表1所示,采用领域词向量模型对齐后,私有数据集上在GPT-3.5的模型对齐下有一定的提升,但是在GPT-4的模型对齐下并没有效果。CMID数据集上有类似的情况,仅在GPT-3.5下有提升,但GPT-4的下面没有任何效果。初步分析,由于GPT在进行意图识别时会存在一定的不稳定性和不真实性,模型在训练时受到了一部分干扰或者进行了一部分数据的丢弃,影响了词向量模型的训练。同时,由于本实验的数据集较为干净,补充上一些无关信息的prompt不会导致GPT的回答变差,不会降低其回复的效果,因此出现了结果无变化的情况,这也表明了该方法在一定程度上能使得本地词向量模型对齐GPT模型,但由于GPT模型的不稳定性,会引入一些干扰导致模型没有提升。
通过迭代训练,在一定程度上可以使得领域词向量模型更加精准地定位与特定知识领域相关的语义要点,从而在增强ChatGPT输出意图的准确性方面发挥了作用。此外,这一模型对齐策略不仅优化了ChatGPT与本地数据的适配度,也丰富了模型对领域内复杂用户需求的理解,为达成高度个性化和精准化的意图识别奠定了基础。
总体来看,无论是在私有还是公共数据集上,利用Chat-GPT的反馈结果来优化领域词向量模型的策略均得到了验证,显现了在具体领域上提升意图识别准确性的潜力,但仍然需要进一步的研究,保证本地词向量模型可以稳定地对齐GPT模型。
3.4.5 消融实验
如表2所述,进行消融实验揭示了各个组件对整体意图识别性能增益的分量。领域打分模型本身就将准确率提高至05的层次,而基于领域知识优化的prompt进一步将这一数字提升至0.66。在CMID数据集上,实验展示了本文方法在更广泛和多样化环境中的鲁棒性,领域知识的引入使准确率从0453提升至0.537,证明即便在规模更广的公共数据集上,领域知识增强同样能够提供有效的性能提升。同样地,领域打分模型也有一定的效果,将准确率从0.453提升至0.487。
对比表2两份数据的消融实验结果以及表1不同方法的准确率提升,可以发现,领域数据的引入使得打分排序模型的增益降低了。换句话说,引入领域数据增强在一定程度上提升了大语言模型的稳定性,使其能够更稳定地输出正确结果,无需借助打分排序模型进行过滤。消融实验进一步验证了领域知识引入对大语言模型的提升效果。
3.4.6 错误分析
为了更好地分析本文方法的效果提升,针对错误部分选取一些典型例子进行分析。
如query1“脊髓灰质炎口服疫苗有哪些”,真实的意图结果为“drug|disease_name:脊髓灰质炎 AND drug_type:口服疫苗”。在默认prompt情况下,GPT容易将该条的意图识别成“drug|drug_name:脊髓灰质炎口服疫苗”。这类query本身需要较多的信息补充才能帮助GPT理解药物内部的适应症和药物类型,这类query在生物医药领域中存在较多,如果全部都补充到prompt中,会导致prompt过于冗余并且可能对GPT造成一定干扰,同时浪费GPT的性能。query2 “Zanidatamab的组合物专利有哪些”,真实的意图结果为“patent|drug_name:Zanidatamab AND patent_type:组合物”。在默认的prompt情况下,GPT容易忽略“组合物”这个标签或者将其识别成药物类型。这类query如果单纯地将定义全部补充上去,反而会导致GPT识别错,而在默认定义下补充一些领域知识则能大大提升其准确率。
query1经过了本文提出的领域知识增强框架后,在输入之前,会从领域知识库中补充一些相关的例子,如:“肺炎疫苗 表示 drug|disease_name:肺炎 AND drug_type:疫苗”。而query2则会返回 “阿莫西林的组合物专利 表示 patetn|drug_name:阿莫西林 AND patent_type:组合物”。通过这些领域数据的增强后,原本GPT识别的错误问题得到了解决。
尽管如此,还有一些无法解决的例子,如:query“仲景制药的归脾丸”,这类query在原本的领域知识库中缺乏相关信息,导致本文提出的领域知识增强方案失效,无法提升ChatGPT的识别效果。此类问题后续可以通过增强领域知识库的方案解决,但目前来说这部分需要人工审核才能做到,未来希望可以找到自动化的解决方案。
3.4.7 实验总结
通过这些实验,本文得以理解引入领域模型、引入领域知和模型对齐等策略在复杂语言模型应用背景下的效能和适应性。为了能够在更多的实际应用中实现高精度的意图识别,未来也可以考虑将现有方法与其他机器学习技术相结合,如强化学习等,以引导模型自我学习和适应不断变化的用户需求和语境。
总体来看,实验结果验证了本文策略在特定领域的提升,同时也为未来语言模型在各专业领域内的深度定制和优化提供了实践依据。通过增强领域知识、细化模型对齐技术,以及设计更精妙的交互优化策略,未来的工作有望在语言理解和信息提取方面达到更高的高度。
4 结束语
本文成功地展示了如何通过整合领域排序模型和精确引入领域知识来增强ChatGPT的意图识别能力。借助领域知识,ChatGPT不仅在深入理解复杂用户意图方面实现了可观进步,而且促进模型在特定场景中性能的显著提升,在某些场景下实现超越GPT-4原有的界限,并在降低经济成本方面取得了积极的效益。此外,根据ChatGPT的反馈优化本地词向量模型,进一步提升了系统对领域知识的捕获能力。
未来研究可以在自动化采集领域知识这方面下功夫,以期从广阔的信息源中快速更新和增强模型的知识库,这将为系统的动态演进提供坚实的支持,并大幅提高其可扩展性和可持续性。此外,将用户即时的反馈整合到意图识别框架中,不但能够推动模型走向持续自我优化的轨道,而且能令模型对用户的真实需求有更深入的理解。未来方向是研究如何将这些研究成果实际运用到工业环境中,并探讨它们如何在真实世界中提升操作效能和用户满意度。
参考文献:
[1]闫悦, 郭晓然, 王铁君, 等. 问答系统研究综述[J]. 计算机系统应用, 2023, 32(8): 1-18. (Yan Yue, Guo Xiaoran, Wang Tiejun,et al. Review of research on question-answering systems[J]. Computer Systems & Applications, 2023, 32(8): 1-18.)
[2]刘娇, 李艳玲, 林民. 人机对话系统中意图识别方法综述[J]. 计算机工程与应用, 2019, 55(12): 1-7, 43. (Liu Jiao, Li Yanling, Lin Min. Review of intent detection methods in Human-Machine dialogue system[J]. Computer Engineering and Applications, 2019, 55(12): 1-7, 43.)
[3]Zhang Kai, Gutiérrez B J, Su Yu. Aligning instruction tasks unlocks large language models as zero-shot relation extractors [EB/OL]. (2023-05-18). https://arxiv.org/abs/2305.11159.
[4]Becker B A, Denny P, Finnie-Ansley J,et al. Programming is hard-or at least it used to be: educational opportunities and challenges of ai code generation[C]// Proc of the 54th ACM Technical Symposium on Computer Science Education. New York: ACM Press, 2023: 500-506.
[5]Yang K, Tian Yuandong, Peng Nanyun,et al. Re3: Generating longer stories with recursive reprompting and revision[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2022: 4393-4479.
[6]Bai Yuntao, Jones A, Ndousse K,et al. Training a helpful and harmless assistant with reinforcement learning from human feedback[EB/OL]. (2022-04-12). https://arxiv.org/abs/2204.05862.
[7]Wu Tianyu, He Shizhu, Liu Jingping,et al. A brief overview of ChatGPT: the history, status quo and potential future development[J]. IEEE/CAA Journal of Automatica Sinica, 2023, 10(5): 1122-1136.
[8]Ouyang Long, Jeff W, Jiang Xu,et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
[9]Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need[C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[10]Bengio Y, Ducharme R, Vincent P. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2000, 13: 1137-1155.
[11]Mikolov T, Chen Kai, Corrado G,et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07). https://arxiv.org/abs/1301.3781.
[12]Pennington J, Socher R, Manning C D. GloVe: global vectors for word representation[C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543.
[13]Bojanowski P, Grave E, Joulin A,et al. Enriching word vectors with subword information[J]. Transactions of the Association for Computational Linguistics, 2017, 5: 135-146.
[14]Peters M, Neumann M, Iyyer M,et al. Deep contextualized word representations[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2018: 2227-2237.
[15]Devlin J, Chang Mingwei, Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[16]Liu Yinhan, Ott M, Goyal N,et al. Roberta: a robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26). https://arxiv.org/abs/1907.11692.
[17]Lan Zhenzhong, Chen Mingda, Goodman S,et al. Albert: a lite bert for self-supervised learning of language representations [EB/OL]. (2020-02-09). https://arxiv.org/abs/1909.11942.
[18]Yang Zhilin, Dai Zihang, Yang Yiming,et al. XLNet: generalized autoregressive pretraining for language understanding[C]// Proc of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 5753-5763.
[19]Raffel C, Shazeer N, Roberts A,et al. Exploring the limits of transfer learning with a unified text-to-text Transformer[J]. The Journal of Machine Learning Research, 2020, 21(1): 5485-5551.
[20]Weld H, Huang Xiaoqi, Long Siqu,et al. A survey of joint intent detection and slot filling models in natural language understanding[J]. ACM Computing Surveys, 2022, 55(8): 1-38.
[21]曹亚如, 张丽萍, 赵乐乐. 多轮任务型对话系统研究进展[J]. 计算机应用研究, 2022, 39(2): 331-341. (Cao Yaru, Zhang Liping, Zhao Lele. Research progress on multi-turn task-oriented dialogue systems[J]. Application Research of Computers, 2022, 39(2): 331-341.)
[22]周天益, 范永全, 杜亚军, 等. 基于细粒度信息集成的意图识别和槽填充联合模型[J]. 计算机应用研究, 2023, 40(9): 2669-2673. (Zhou Tianyi, Fan Yongquan, Du Yajun,et al. Joint model for intent recognition and slot filling based on fine-grained information integration[J]. Application Research of Computers, 2023, 40(9): 2669-2673.)
[23]Zhang Xiaodong, Wang Houfeng. A joint model of intent determination and slot filling for spoken language understanding[C]// Proc of the 25th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 2993-2999.
[24]Liu Bing, Lane I R. Attention-based recurrent neural network models for joint intent detection and slot filling[C]// Proc of the 17th Annual Conference of the International Speech Communication Association. [S.l.]: ISCA, 2016: 685-689.
[25]Purohit H, Dong Guozhu, Shalin V,et al. Intent classification of short-text on social media[C]// Proc of IEEE International Confe-rence on Smart City/SocialCom/SustainCom. Piscataway, NJ: IEEE Press, 2015: 222-228.
[26]Schuurmans J, Frasincar F. Intent classification for dialogue utte-rances[J]. IEEE Intelligent Systems, 2019, 35(1): 82-88.
[27]Chen Qian, Zhuo Zhu, Wang Wen. BERT for joint intent classification and slot filling[EB/OL]. (2019-02-28). https://arxiv.org/abs/1902.10909.
[28]王堃, 林民, 李艳玲. 端到端对话系统意图语义槽联合识别研究综述[J]. 计算机工程与应用, 2020, 56(14): 14-25. (Wang Kun, Lin Min, Li Yanling. A review of joint intent and semantic slot recognition in end-to-end dialogue systems[J]. Computer Engineering and Applications, 2020, 56(14): 14-25.)
[29]Liu Pengfei, Yuan Weizhe, Fu Jinlan,et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing[J]. ACM Computing Surveys, 2023, 55(9): 1-35.
[30]Shrivastava D, Larochelle H, Tarlow D. Repository-level prompt gene-ration for large language models of code[C]// Proc of International Conference on Machine Learning. [S.l.]: PMLR, 2023: 31693-31715.
[31]White J, Hays S, Fu Quchen,et al. ChatGPT prompt patterns for improving code quality, refactoring, requirements elicitation, and software design[M]// Nguyen-Duc A, Abrahamsson P, Khomh F. Generative AI for Effective Software Development. Cham: Springer, 2024: 71-108.
[32]王培冰, 张宁, 张春. 基于prompt的两阶段澄清问题生成方法[J]. 计算机应用研究, 2024, 41(2): 421-425. (Wang Peibing, Zhang Ning, Zhang Chun. Two-stage clarification question generation method based on prompt[J]. Application Research of Compu-ters, 2024, 41(2): 421-425.)
[33]刘涛, 蒋国权, 刘姗姗, 等. 低资源场景事件抽取研究综述[J]. 计算机科学, 2024, 51(2): 217-237. (Liu Tao, Jiang Guoquan, Liu Shanshan,et al. A review of event extraction in low-resource scenarios[J]. Computer Science, 2024, 51(2): 217-237.)
[34]Wei J, Wang Xuezhi, Schuurmans D,et al. Chain-of-thought promp-ting elicits reasoning in large language models[C]// Proc of the 36th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2022, 35: 24824-24837.
[35]Zeng Zhiyuan, He Keqing, Yan Yuanmeng,et al. Modeling discriminative representations for out-of-domain detection with supervised contrastive learning[C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2012: 870-878.
