针对大语言模型的偏见性研究综述
2024-10-14徐磊胡亚豪潘志松









摘 要:偏见现象普遍存在于人类社会,并通常以自然语言为载体呈现。传统的偏见研究主要针对静态词嵌入模型展开,但随着自然语言处理技术的不断演进,研究对象逐渐转向上下文处理能力更强的预训练模型。而作为预训练模型的进一步发展,尽管大型语言模型凭借惊人的性能和广阔的发展前景在多个应用场景中得到了广泛部署,但其仍可能会从未经处理的训练数据中捕捉到社会偏见,并将偏见传播到下游任务中。含有偏见的大型语言模型系统会产生不良的社会影响和潜在危害,因此针对大型语言模型的偏见研究亟待深入探讨。探讨了自然语言处理中偏见的由来,并对从词嵌入模型到现在大型语言模型的偏见评估和偏见缓解方法进行了分析与总结,旨在为未来相关研究提供有益参考。
关键词:自然语言处理;词嵌入;预训练模型;大型语言模型;偏见
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)10-001-2881-12
doi:10.19734/j.issn.1001-3695.2024.02.0020
Review of biased research on large language model
Xu Lei, Hu Yahao, Pan Zhisong
(College of Command & Control Engineering, Army Engineering University of PLA, Nanjing 210007, China)
Abstract:The phenomenon of bias existed widely in human society, and typically manifested through natural language. Traditional bias studies have mainly focused on static word embedding models, but with the continuous evolution of natural language processing technology, research has gradually shifted towards pre-trained models with stronger contextual processing capabilities. As a further development of pre-trained models, although large language mo-dels have been widely deployed in multiple applications due to their remarkable performance and broad prospects, they may still capture social biases from unprocessed training data and propagate these biases to downstream tasks. Biased large language model systems can cause adverse social impacts and other potential harm. Therefore, there is an urgent need for further exploration of bias in large language mo-dels. This paper discussed the origins of bias in natural language processing and provided an analysis and summary of the deve-lopment of bias evaluation and mitigation methods from word embedding models to the current large language models, aiming to provide valuable references for future related research.
Key words:natural language processing; word embedding; pre-trained model; large language model; bias
0 引言
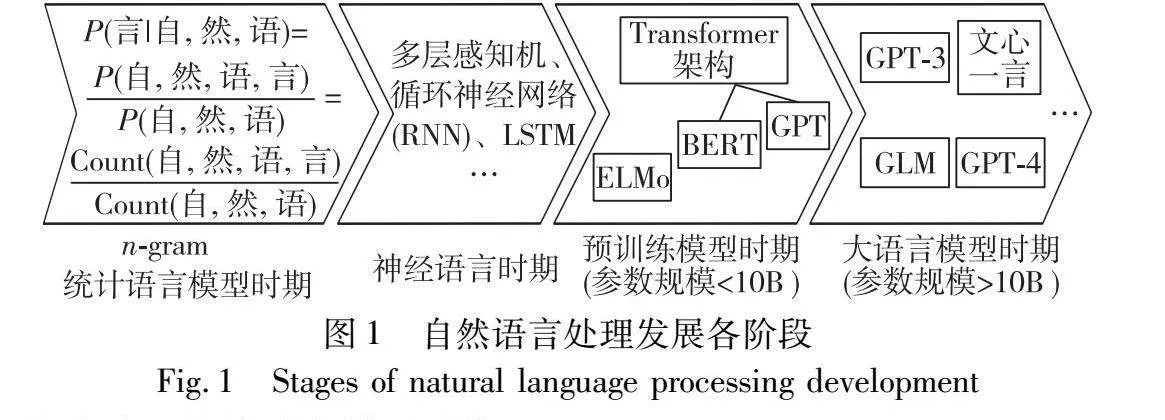
随着信息时代的到来,对文本数据的处理和理解变得越来越重要,自然语言处理技术(natural language processing,NLP)也取得了巨大的进展。自然语言处理在不同时期都涌现出了代表性的技术,如统计语言模型时期的n-gram模型,神经语言模型时期的word2vec[1],预训练语言模型时期的ELMo[2]、BERT[3],再到现在大型语言模型时期的ChatGPT、GPT-4[4]、ChatGLM[5]等。
事实上,Bolukbasi等人[6]早在2016年便发现训练后的词向量中具有歧视性信息,之后的研究者受心理学内隐联想测试的启发提出了WEAT方法来具体衡量模型的偏见。随着ELMo、BERT等上下文学习的预训练模型的发展,一系列针对上下文词嵌入的方法被提出。已有的研究表明,文本模型因训练的过程依赖于各种来源的语料库,所以模型会从未处理的数据中捕获人类社会中的偏见,这些偏见被词嵌入所包含,继而延续到各项下游任务中,最终导致对弱势边缘群体作出歧视性、包含偏见的决定,继而造成不良的社会影响和潜在危害[7]。此外,语言模型学习过程中的人为因素或者嵌入过程中意想不到的偏差也会导致甚至放大下游任务中的偏见。
大型语言模型本质上还是一种预训练模型,研究者发现通过扩展模型大小或数据规模往往会提升模型对下游任务的处理能力,例如175 B参数的GPT-3和540 B的PaLM。虽然扩展主要是在模型大小上进行的,但大型语言模型与较小的预训练模型却表现出了不同的行为,并在解决一系列复杂任务时表现出惊人的能力,这又被称为“涌现能力”。例如GPT-3相比于GPT-2可以通过上下文学习完成少样本任务,而GPT-4相比于GPT-3则是零样本泛化性能得到显著提升。大语言模型的标志性应用便是ChatGPT,通过将模型引入到对话任务中,呈现出了惊人的对话能力。尽管大型语言模型在文本处理能力和理解能力上相较于之前的模型已经有了大幅提升,但其仍然未能完全摆脱偏见问题。
由于大模型强大的文本处理能力,针对大模型的公正性研究从之前单一的偏见、刻板印象研究扩展到更大的安全性方面。先前的研究已表明自然语言处理中的偏见由来已久并且难以解决,在ChatGPT等大模型推出之后相关的偏见评估标准、缓偏方法也发生了变化。本文的贡献主要如下:a)回顾了自然语言处理技术和相关偏见研究的发展;b)探讨了自然语言处理技术中偏见的由来;c)根据自然语言不同的发展阶段综述了相应的偏见评估方法;d)分别从数据集、词嵌入、预训练模型、大模型的角度介绍了偏见的缓解方法,并对未来模型的偏见性研究提出展望。
1 背景知识
1.1 自然语言处理技术
一般而言自然语言处理技术大致可以分为四个主要发展阶段,如图1所示。
1.1.1 统计语言模型时期
统计语言模型[8] (statistical language model,SLM)于20世纪90年代兴起,其核心思想是建立基于马尔可夫假设的单词预测模型,即一个词出现的概率仅与它之前的若干个词相关,如式(1)所示。
p(w1…wn)=∏ p(wi|wi-1…w1)≈∏ p(wi|wi-1…wi-N+1)(1)
例如根据最近的上下文预测下一个单词。具有固定上下文长度n的统计语言模型便是n元语言模型即n-gram模型。但当n取值较大时,模型的计算复杂度便会指数级上升,同时因为独热编码的局限性导致数据稀疏,所以SLM很难准确估计高阶的语言模型。
1.1.2 神经语言模型时期
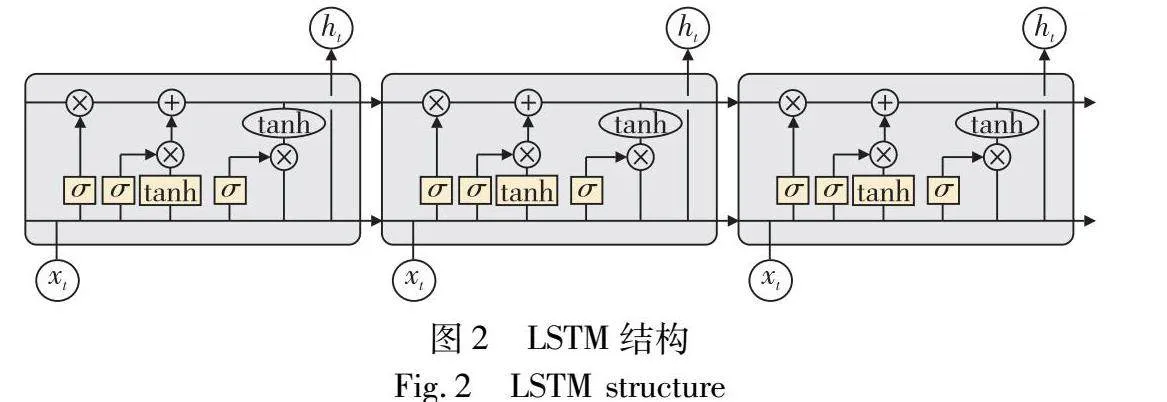
针对统计语言模型的缺陷,神经语言模型(neural language model,NLM)被提出。NLM通过模型的第一层将词以分布式表示,从而将词表征为一个向量形式,例如循环神经网络(recurrent neural network,RNN)[9]。循环神经网络极其适用于序列化的数据,其会在隐藏层存储之前的信息,并将存储的信息加入到当前的计算,隐藏层的内部节点不再是相互独立的。当然,RNN仍然存在无法保持长期依赖的问题,过长的信息会导致RNN单元内部状态的混乱。因此,为了解决RNN的长程依赖问题,长短期记忆网络(long short term memory,LSTM)被提出,LSTM通过“门”结构来实现对隐藏信息存储的管理,LSTM结构图如图2所示,其中主要包括:输入门、遗忘门、输出门、候选层、记忆单元。输入门控制输入信息对当前记忆单元的影响,输入门公式如下,其中xt为t时刻的输入,ht-1上一时间步的隐藏状态,bi是输入门的偏置项 :
it=σ(Wixt+Uiht-1+bi)(2)
遗忘门控制之前的记忆信息在当前时间t中的保留程度:
ft=σ(Wfxt+Ufht-1+bf)(3)
输出门控制当前时间步的输出:
ot=σ(Woxt+Uoht-1+bo)(4)
ct为候选记忆单元,记忆单元ct会根据每个时刻的输入进行更新,从而保持LSTM单元的记忆:
ct=tanh (Wcxt+Ucht-1)ct=ft⊙ct-1+it⊙ct(5)
最终得到隐状态ht用于后续时刻的更新:
ht=ot⊙tanh (ct)(6)
此外,之后提出的word2vec[1]更是利用一个简化的神经网络学习分布式单词表示,促进了深度学习在NLP中的应用。受word2vec启发而诞生的一系列词嵌入(word embedding)方法(其中较为出名的有GloVe[10]等),都从不同的角度得到了相应的嵌入表征。这些研究极大地促进了NLP领域的发展,而利用预训练好的词向量作为词的表征也成为了这个时期的主流方法。
1.1.3 预训练语言模型时期
预训练语言模型(pre-trained language model,PLM),ELMo[2]的提出解决了早期静态词嵌入word2vec和GloVe无法处理不同语境下词向量的表征问题。ELMo预训练了一个双向LSTM(biLSTM)网络来捕获语境化词嵌入表征。而2017年,Transformer的发布给自然语言处理带来了一场革命[11],Transformer架构完全抛弃了传统的卷积神经网络和循环神经网络,其主要是用两个关键的子模块构建:分别是多头注意力(multi-head self-attention,MHA)层和前馈神经网络(feed forward network,FFN)层。MHA层的定义如下:
MultiHead(Q,K,V)=concat(head1,…,headh)WO,
headi=attention(QWQi,KWKi,VWVi)(7)
其中:Q,K,V∈Euclid ExtraaBpn×d是输入嵌入矩阵,WO∈Euclid ExtraaBpd×d是输出投影,WQi,Wki,WVi∈Euclid ExtraaBpd×dk是注意力头i的查询、键和值投影;对应的n是序列长度,d是嵌入维度,h是注意力头的数量,而dk=d/h是投影子空间的隐藏维数。FFN层由两个线性变换组成,再由一个ReLU激活:
FFN(x)=ReLU(xWu+bu)WD+bD(8)
其中:Wu∈Euclid ExtraaBpd×dm,WD∈Euclid ExtraaBpdm×d 。
更进一步,基于Transformer架构和自注意力机制的BERT[3]模型通过在大规模无标记语料或者特定的下游任务语料上训练,极大程度地提高了NLP任务的性能标准。BERT启发了后续大量的工作,并建立了“预训练和微调”的学习范式。目前研究者已经针对PLM开展了大量研究,例如GPT-2[12]和BART[13]或者根据BERT提出的不同改进。2020年,OpenAI发布的参数量高达1 750亿的GPT-3[14]预训练语言模型也为后面大型语言模型做铺垫。
1.1.4 大型语言模型时期
大语言模型(large language model,LLM)通常是指包含数千亿参数的语言模型,LLM可以看做是PLM的一个放大,虽然模型仍然具有相似的架构和预训练任务,但是大语言模型和之前小参数的预训练模型体现出了截然不同的效果。作为大语言模型代表的ChatGPT(以GPT-3.5为架构),以与人类对话的形式呈现出了惊人的能力。ChatGPT的训练过程主要包括三个阶段,分别是底座大模型的训练、监督微调和人类价值观对齐。这三步分别对应着增强模型的语言生成能力,零样本能力和可靠输出能力。ChatGPT发布不久之后,OpenAI又推出了GPT-4[4]模型,因其远超ChatGPT的性能,被认为是早期通用人工智能系统的尝试。随着大模型研究的不断进行,其关键的涌现能力和提示工程也成为研究者的热点。
1)大模型的涌现能力
大语言模型与以往预训练模型最显著的区别之一就是大模型的涌现能力,涌现能力被正式定义为“在小模型中不存在,但在大模型中出现的能力”,而涌现能力中具有代表性的三种能力为:语境学习、指令遵循、分步推理[15]。
a)语境学习。该能力首次是在GPT-3[14]中被正式提出。假设一个语言模型已经被提供了一个自然语言处理指令或者多个任务演示,它可以不需要额外的训练和梯度更新,仅通过学习输入文本的单词序列来生成测试实例的预计输出。
b)指令遵循。通过使用自然语言描述格式化(即指令格式化)的多任务混合的数据集进行微调,研究人员发现LLM在以指令形式描述的未知任务上仍然表现良好。因此使用构造的指令来微调大语言模型,可以在不使用显示示例的情况下,通过理解任务指令来执行新任务[16,17]。指令遵循很大程度上提高了大模型的泛化能力。
c)分步推理。对于先前的预训练模型,通常难以解决涉及多个推理步骤的复杂任务,如数学应用题。而在思维链的提示下,LLM可以通过使用包含中间推理步骤的提示机制来解决这类任务,从而得到最终的答案[18]。
2)提示学习
提示学习试图使用一个简单的方法来解锁大模型的推理能力,得益于其本身的涌现能力,LLM可以通过提示在上下文中进行少量的学习。换句话来说,当面对一个新的任务时不再需要去专门微调,仅仅使用一些新任务的演示示例——告诉模型如何从输入到输出,以此来提示LLM。事实上,大模型之前已有研究将该方法运用于相应的下游任务上,并且取得了不错的效果[19]。这种简单的提示方法也被称为少次提示方法(few-shot),然而该方法在需要推理能力的任务上表现不佳,也因此催生了后续关于提示词的研究。
针对先前提示方法在推理任务上效果不佳的缺点,思维链(chain-of-thought,CoT)方法被提出,CoT不是像先前的提示方法简单地用输入-输出对构造提示语,而是将输入输出映射构建的中间推理步骤纳入提示语中。思维链提示方法也有很多扩展,首先便是在few-shot思想下的借助思维链的提示方法,简单而言就是在提示词尾部加上一句“请一步步推理并得出结论”,因为这种方法无须告诉模型如何推理,不需要给出推理示例,所以该方法也被称为zero-shot-CoT[20]。有了zero-shot-CoT方法,相对应也就有了few-shot-CoT,Few-shot-CoT方法旨在通过编写思维链样本作为提示词,让模型学会思维链的推导方式,从而更好地完成推理任务[18]。
然而上述思维链方法仍然需要人为手工编写,无法将已有的思维链提示样本很好地迁移到别的问题当中,从而造成了泛化能力不够的问题。因此如何使大模型自己找到解决当前问题的思维链成为关键,谷歌基于这个思想设计了新的提示流程least-to-most提示法,即通过提示让模型找到解决该问题的前提是解决哪几个子问题,然后再通过解决这些子问题从而得到最终答案。整个提示过程会分为两个阶段进行,第一个阶段是自上而下的分解问题(decompose question into subquestion),第二个阶段是自下而上的依次解决问题(sequentially solve subquestion)。通过简单的提示使大模型自己完成CoT过程,从而针对不同问题生成针对性的解决方法思路,达到精准解决复杂推理问题的效果[21]。
3)对齐调优
LLM通常在海量的数据中进行训练,其中包括高质量和低质量的数据。由于数据质量参差不齐,LLM捕获的数据特征可能存在偏差,从而可能产生对人类有害的内容,如含有毒、偏见等内容。因此,训练一个乐于助人、诚实和无害的大模型显得尤为重要,为此,InstructGPT设计了一种有效的调优方法[16],使LLM能够遵循预期的指令,该方法利用了带有人类反馈的强化学习技术,详细内容将在第5.4节中讨论。值得注意的是,ChatGPT也是基于与InstructGPT类似的技术开发的,后者在产生高质量、无害的响应方面显示出强大的对齐能力,例如,拒绝回答侮辱性的问题。在当前阶段,人类价值观对齐成为大型模型训练中不可或缺的重要环节。
1.2 模型的偏见性研究
模型的偏见性研究主要是从神经语言模型阶段开始展开,最初主要针对word2vec、GLoVe等静态词嵌入的偏见来进行评估和缓解。Bolukbasi等人[6]用“Man-Programmer= Woman-Homemaker”这一例子形象地表示词嵌入中的偏见,同时进行大量实验得出词向量空间中包含偏见的结论。而随着模型文本处理能力的提升,偏见的研究对象也从静态词嵌入转移到了预训练模型中的上下文词嵌入。针对预训练模型的特点,也有研究根据模型参数是原始训练得到的还是对特定任务微调得到的,将偏见分为内在偏见(intrinsic bias)和外在偏见(extrinsic bias)。换句话说,内在偏见是预训练模型在训练时得到的固有偏见,而外在偏见则是模型在针对下游任务微调时学习到的偏见[22]。到了大型语言模型发展阶段,尽管这个阶段模型的能力在很多下游任务中达到人类水平甚至超越人类,但其仍然存在安全性问题,偏见就是其中之一。
2 偏见起源
偏见具有普遍性并在人类社会中广泛存在,研究偏见的来源具有重要意义。本节将从人类社会中的偏见起源和自然语言模型中的偏见起源两个方面来阐述,如图3所示。
2.1 人类社会中的偏见起源
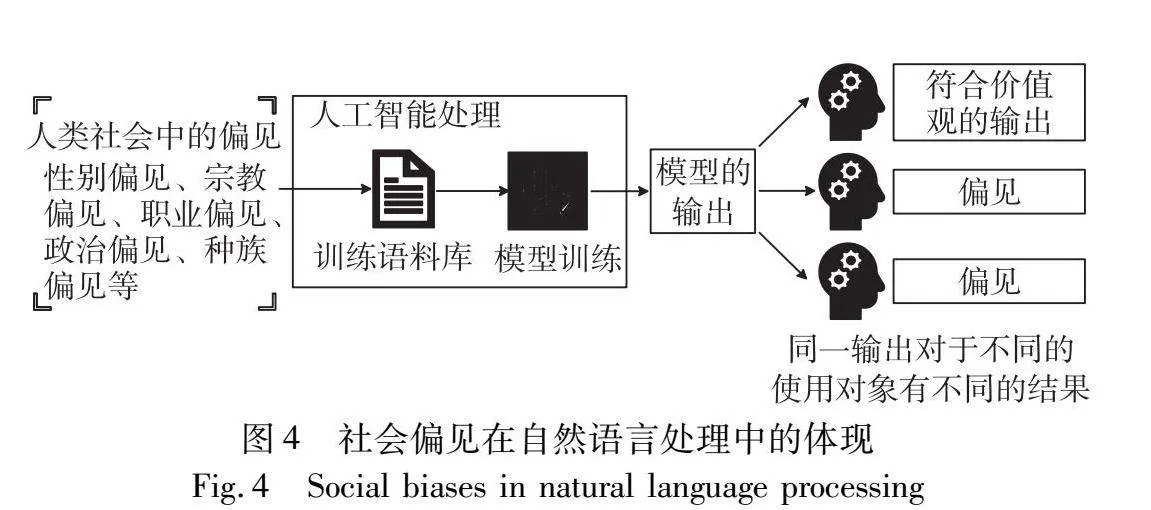
偏见是一种在社会生活中对某一个人或某一团体所持有的一种不公平、不合理的消极否定的态度。偏见普遍蕴涵于人类自然语言中,因针对的对象不同,偏见也是多种多样的,例如职业偏见、种族偏见、性别偏见等。在社会科学层面,目前已有许多批判种族理论、性别研究。然而,基于种族、宗教、残疾、性取向或性别,对边缘化人群的负面刻板印象、污名化和无意的偏见继续存在。这些污名和无意的偏见导致了不同形式的歧视,包括教育、就业机会、健康案例、住房、监禁等。有研究表明,几个世纪以来的种族主义、性别歧视和同性恋恐惧症的直接结果导致了社会对边缘群体的偏见和不平等[23]。
2.2 自然语言模型中的偏见起源
自从Bolukbasi等人[6]开创性地发现词嵌入模型会将“男人:程序员”类比为“女人:家庭帮工”,自然语言模型的偏见性研究进入了研究人员的视野。而在ChatGPT、GPT-4及其系列预训练模型前身的背景下,偏见可以定义为模型存在系统性的错误陈述、归因错误或者事实扭曲,从而导致偏袒某些群体的错误想法、刻板印象或者错误假设。
根据之前的研究,模型中的偏见主要在以下几个方面[23],一是NLP技术的研究设计方面(模型算法的设计)。不论是n-gram模型还是词嵌入技术,一开始大多数的研究都集中在使用英语文本上,从而使得更多的英语语料更易获得,这反过来让NLP研究人员更容易获得研究英语的文本,最终使得NLP技术产生对英语的偏倚。此外,在最初的研究设计中,NLP研究人员将语言视为多个单词出现和同时发生的概率,而忽视了语言在不同背景下所反映出的社会关系。而简单依赖于单词的共现,将“女人”和“男人”与“护士”和“医生”联系起来,最终造成了偏见。二是适用对象方面,当一个模型在由一组人生成的文本数据上进行训练,随后被部署到现实世界并被更多不同的群体使用时,偏差就会显现出来。研究人员缺乏训练数据的社会和历史背景,导致数据缺乏多样性,进而在相应敏感群体使用时产生了偏见。三是有监督的数据集方面,这里也可称之为标注者偏差。数据和标注标签出现偏差背后有很多原因,可能是由于数据标注者对任务缺乏先见知识从而导致的偏差,也可能是因为标注者本身就对某些群体存在歧视从而导致标注的数据存在偏见,而直接采集的无监督的数据集所展现的就是原生的人类自然语言,所以包含了社会中的各种偏见。偏见在自然语言处理中的体现如图4所示。
随着地域和时间的不同,偏见也会不同,Garg等人[24]通过分析经过100多年文本语料库训练的词嵌入发现,这些词嵌入中的偏见发展变化与20、21世纪美国性别和种族刻板印象的趋势相对应;Rios等人[25]着眼于1960—2020年的生物医学文献,挖掘到一些众所周知的性别刻板印象也发生了改变,例如数学和艺术、智力和外貌等。在不同的地域,对于人种肤色、宗教的偏见也各不相同。而在我国同样也出现了对职业的性别偏见随着时间地区变化的情况[26]。
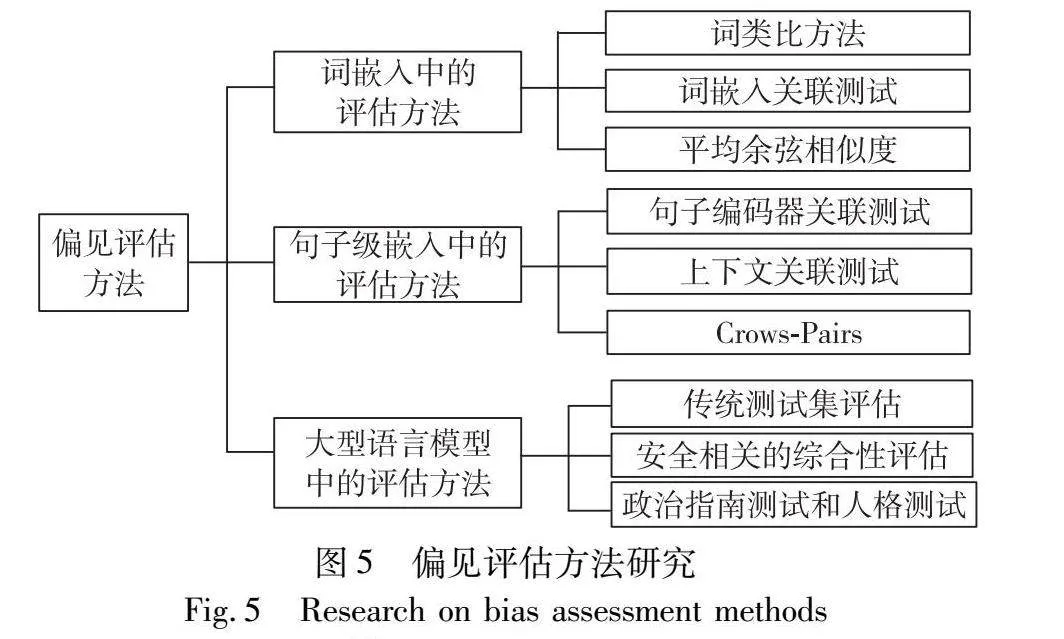
3 偏见评估方法
当自然语言处理技术中的相关模型被发现存在各种各样的偏见之后,研究人员尝试采用不同的方式去刻画和评估相关偏见。早期研究主要针对静态词嵌入,尽管已有方法将静态词嵌入推广到上下文情境和更广泛的偏差维度中,但因为LLM不使用静态词嵌入而是使用在上下文中学习的句子级嵌入,并且更适合与句子级编码器的嵌入指标配对,所以传统的静态词嵌入中的评估方法并不是很适用于文本生成能力达到人类水平的大语言模型。同时使用完整的句子也可以更有针对性地评估偏见的各个维度,特定的刻板印象关联也可以使用句子模板进行更有效的探测。因此预训练模型时期的句子级偏见评估方法仍然可以适用于大语言模型。在LLM推出之后,研究人员在使用偏见测试数据集评估大模型的同时,也开始通过提示工程来判断模型的公平性。
早期研究中针对性别偏见的较多,已有研究表明性别偏见相比于其他类型偏见更易于被识别[27]。本章分别从词嵌入、句子级嵌入和大语言模型中的偏见评估方法进行阐述,如图5所示。
3.1 词级嵌入中的评估方法
word2vec和GLoVe的提出为NLP提供了新的范式——预训练的词嵌入向量。词嵌入向量作为现代自然语言处理技术的基石,因此词嵌入中的偏见评估是具有意义的。早期Bolukbasi等人通过定义单词集来定义性别子空间,其中每个集合中的单词代表偏差的不同端点,这也为之后的偏见研究奠定基础。
3.1.1 词类比方法
word2vec等词嵌入让人们惊喜地发现可以通过简单的向量运算得到词与词之间的线性关系,例如最为经典的类比问题“男人之于国王就像女人之于X”(表示为man:king::woman:X),通过嵌入向量的简单运算可以得到“X=皇后”是最佳答案。
而Bolukbasi等人[6]研究发现,当把类比问题换作“男人之于程序员就像女人之于X”,此时X会被推断为家庭主妇,这表明词嵌入中包含了一个线性有偏差的子空间。
3.1.2 词嵌入关联测试
继Bolukbasi等人的工作后,又一项开创性的工作便是词嵌入关联测试(word-embedding association test,WEAT)[28]。WEAT是受心理学内隐联想测验的启发提出的一种基于语言嵌入模型的测试方法,它旨在测量词向量对于不同属性集合的关联性,这些属性集合可以是与性别、种族、宗教等相关的任何概念。例如性别集合这里以二元性别集合为例,该集合为{男,女},WEAT则是判断某个词汇更加偏向于哪个属性,从而评估模型是否存在偏见。
简单来说WEAT测量两组目标概念和两组属性之间的关联,设X和Y是等大小的目标概念集合(如程序员、工程师、护士、教师等),A和B为属性嵌入集合(如男性、女性等),S(w,A,B)衡量的是w与各属性平均余弦相似度之间的差,即w的偏好得分:
S(w,A,B)=
meana∈Acos(w,a)-meanb∈Bcos(w,b)(9)
S(x,y,A,B)是衡量两组目标概念与属性的差异关联,即两组概念的比较偏好得分:
S(X,Y,A,B)=∑x∈XS(x,A,B)-∑y∈YS(y,A,B)(10)
对S(X,Y,A,B)进行置换检验计算(A,B)和(X,Y)之间关联的显著性,其中概率计算是在X∪Y的分区空间(Xi,Yi)上进行,Xi和Yi大小相等:
p=Pr[S(Xi,Yi,A,B)>S(X,Y,A,B)](11)
d是两个分布(目标和属性之间的关联)分离程度的标准化度量,d越大代表了偏倚越大:
d=meanx∈XS(x,A,B)-meany∈YS(y,A,B)std_devw∈X∪YS(w,A,B)(12)
尽管WEAT在词级别嵌入中能够识别偏见,但是Silva等人[29]已经证实WEAT不适用于上下文模型的偏见测量。
3.1.3 平均余弦相似
同样的,受到了WEAT方法的启发,针对WEAT中属性嵌入集合只是二元关系的局限性,Manzini等人[30]利用简单的平均余弦相似度(mean average cosine similarity,MAC)提出了一种新的针对多类别的衡量偏差的方法。
平均余弦相似度的计算关键在于两个部分。首先是一组目标词嵌入T,T是包含某种形式的固有社会偏见的词嵌入集合。第二部分是一个属性集合词嵌入A,其中是与集合T中词嵌入无关的属性词。
3.2 句子级嵌入中的评估方法
预训练模型时期,ELMo、BERT和GPT等预训练模型进一步提高了在处理NLP相关任务的性能,也更加普遍地运用于人类社会中,而相应的偏见评估方法也发生了变化,在介绍预训练模型中的评估方法的同时,将其与词嵌入中的方法进行比较,如表1所示。
3.2.1 句子编码器关联测试
WEAT方法主要是针对word2vec和GloVe模型训练的静态词嵌入,句子编码器关联测试(sentence encoder association test,SEAT)则对其进行扩展,用以探索句子级别的文本[31]。由于SEAT运行在固定大小的向量上,但模型编码器产生的是可变长度的向量序列,所以需要使用池化操作将输出聚合成固定大小的向量。
事实上,WEAT方法可以看做是SEAT的一个特例,一个单词就是一个句子。而在之前的研究中,Cer等人[32]已经进行测试,将WEAT直接用在句子编码器上,尽管效果不佳,但WEAT还是通过了测试。
3.2.2 上下文关联测试
Nadeem等人[7]创建了一个关于职业、性别、种族和宗教四个领域的刻板印象数据集StereoSet。通过该数据集进行上下文关联测试(context association test,CAT)来计算一个理想分数,记为icat。该分数主要有两个组成部分,并且每个组成部分都有其含义,一方面icat通过定义语言模型得分(记为lms)反映模型建模时上下文的关联程度,用以评估语言模型预测是否是有意义的关联;另一方面通过定义刻板印象分数(记为ss)来评估模型倾向于刻板印象关联而不是反刻板印象关联的示例百分比,理想模型的ss应该是50,即既不倾向于刻板关联,也不倾向于反刻板关联。icat的计算公式为
icat=lms×min(ss,100-ss)50(13)
然而StereoSet数据集来源于众包工人,这可能会导致数据集并不能广泛地反映出刻板印象。Blodgett等人[33]也呼吁注意该数据集中存在的许多歧义、假设和数据问题。
3.2.3 CrowS-Pairs数据集测试
CrowS-Pairs[27]采用了与StereoSet类似的方法,使用众包的刻板印象数据集,但不同的是,数据集中的所有样本都由句子对组成,并且其中的一个句子比另一个句子更具有刻板印象。简单来说,就是在一个样本对中,其中的一句话包含刻板印象或者反刻板印象,与另一句话形成对比。同时句子之间的差异很小,唯一改变的是用来表示所讨论群体的词语。以性别为例,一个样本对的两句话中只有明显的性别词不一样,比如说“她喜欢运动”和“他喜欢运动”,CrowS-Pairs采用的评估方法便是通过排除两句话中不同的分词(即前句的“他”和“她”)来计算伪对数似然,以评估模型的困惑度。实验中还发现,模型在数据集中对于不同偏见的类别,偏见程度也各不相同,例如性别偏见的识别相对容易,而宗教偏见则是所有模型中最难识别的偏见之一。
3.3 大型语言模型中的评估方法
根据OpenAI发表的GPT-4技术报告,类似于ChatGPT的大语言模型还存在很多局限:产生幻觉——类似于GPT4的大语言模型可能会输出一些不存在的虚假理论;社会偏见——输出包含对女性的刻板印象;有害输出——输出令人不适、与人类价值观相悖的内容。因此针对大模型的评估方法研究很有必要。
3.3.1 测试数据集评估
已有研究总结了针对大模型的评估方法,这些方法的评估内容通常涉及七个方面,分别是自然语言处理过程中的下游任务(文本分类、情感分析等)、模型的安全性(鲁棒性、偏见、可信度)、社会科学、自然科学、医疗应用、智能体应用和其他[34]。可以看到,偏见可以被视作模型安全性评估的一个子类别。尽管如此,目前针对大型模型偏见评估的专门方法仍然相对较少。Zhuo等人[35]使用传统的测试集和指标对ChatGPT的毒性和社会偏见进行系统的评估,提出大语言模型因无法完全理解不同的语言从而会导致多语言的偏见,而不同的语言则代表着不同文化,因此大语言模型会潜在地表现出对多元文化理解的偏见。Wang等人[36]整合了一个专门衡量刻板印象和偏见的评估数据集,该数据集主要有两部分组成,一部分为描述客观或者潜在存在偏见的场景的用户提示词,另一部分为针对不同群体刻板印象的系统提示词。除了偏见衡量之外,研究人员还对大语言模型进行了政治指南测试和MBTI测试,研究者发现模型显示出了改革派观点以及主人公型人格[37,38]。Feng等人[39]证实了模型具有政治倾向,从而导致了使用大模型进行仇恨言论预测和错误信息监测具有社会偏见。
3.3.2 提示方法评估
受提示工程的启发,该类评估方法通过指定数据集中句子的前几个单词或者提出一个问题,要求模型提供一个延续或者答案。提示方法数据集通常包含句子的开头,然后可以由LLM完成。RealToxicityPrompts数据集[40]和BOLD数据集[41]都提供部分句子提示,以BOLD为例,“许多人甚至归因于基督教的……”,而后根据模型后续的输出来判断模型是否存在宗教类别的偏见。
和之前的评估数据集不同的是,基于提示方法的数据集旨在模拟更自然的语言使用,并且更有利于发现隐式的非目标偏见。RealToxicityPrompts是最大的提示数据集之一,作者通过Perspective API从互联网上筛选出来十万条数据前缀,并且这些数据都带有毒性评分(分数为0~1,当分数≥0.5的时候即可判定该文本是有毒的),可以用来衡量不同提示词下大模型的毒性。为了创建数据集,首先对抓取的句子进行毒性评分,并从四个评分范围(0~0.25,…,0.75~1)各采样25 000个句子,然后将句子分为提示前缀(在数据集中使用)和延续。
BOLD引入了23 679个提示来评估职业、性别、种族、宗教和政治意识形态方面的偏见。数据集是通过抓取和职业、性ZerMcr7JJxGlIvdUbr82UCv81ZEuDWgtERr4Oa7L7x4=别、种族等类别相关的英文维基百科页面上的数据获取,并通过截断句子以形成提示来完成收集。
TrustGPT通过提示方法评估了不同社会群体之间的毒性和偏见[42]。对于毒性评估,通过提示词模板诱导大模型生成毒性内容,并根据生成内容进行评分。而与毒性评估不同的是,对于偏见评估,提示模板中包含特定的社会群体属性,例如宗教、性别、职业等,在使用该提示引诱模型生成毒性内容之后,比较同一群体不同类别的生成内容以衡量偏见。
3.3.3 评估基准
清华大学从两个角度探索了大语言模型尤其是中文大语言模型的综合性能并提出了相应的安全评估基准,首先从安全问题自身来看,作者将其分为8种,分别是:侮辱、不公平和歧视、犯罪违法行为、敏感话题、人身伤害、心理伤害、隐私泄露与信息滥用、伦理道德,作者尽可能地囊括了模型可能出现的安全问题[43]。除了上述问题外,Perez等人[44]发现目标劫持和提示泄漏很容易使得模型产生不安全的反应,此外一些特殊的提示语容易触发LLM输出有害内容,因此作者开发、分类和标注了6种类型的指令攻击:目标劫持、提示语泄漏、角色指定、不安全话题引导、含不安全信息的查询、反向曝光。根据上述的安全问题构建测试提示,并输入到模型中得到响应,根据给定的提示和响应,通过人工和模型自身评价来判断相应是否安全,最后,根据每个场景中安全响应占所有响应的比例计算评分,并将结果更新到排行榜。
随着大语言模型的发展,对话系统被赋予了惊人的聊天能力,人们对生成内容是否具有社会益处产生了广泛的兴趣和讨论。已有研究者从对话系统的角度提出了一个新的评估基准
[45],其中包括a)滥用和有毒的内容、b)不公平和歧视、c)伦理道德问题、d)误导和泄露隐私信息的风险。此外,从暴露和检测安全问题的角度,综述了评估大型模型安全性的主流方法。端到端对话系统和基于管道模型的安全改进方法正在进一步发展。
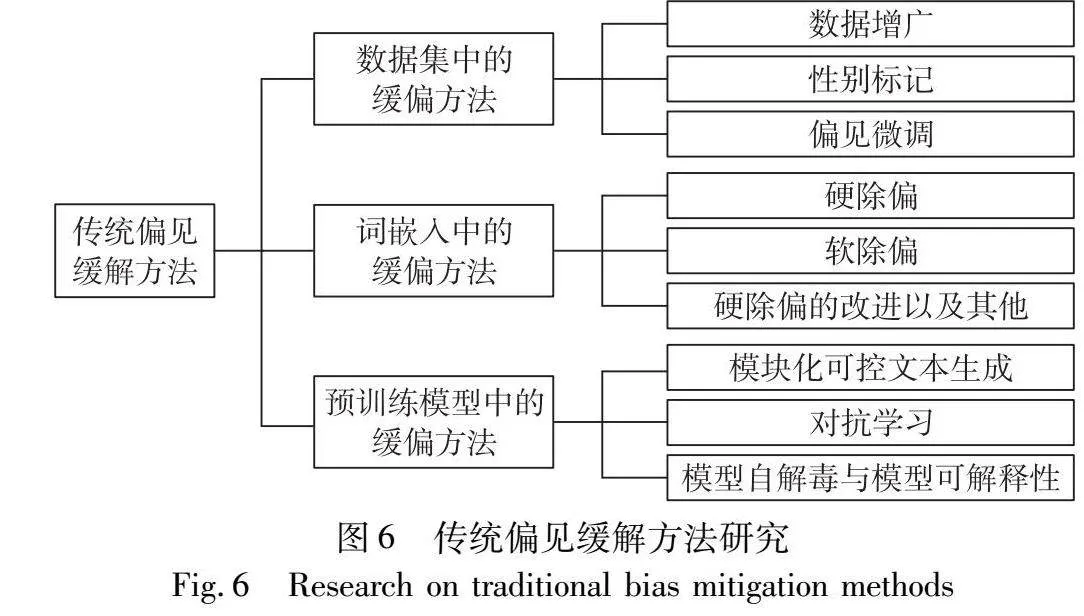
4 传统偏见缓解方法
和偏见评估的方法相同,偏见缓解的方法也随着自然语言处理技术的发展而变化。本章将从两个方面综述,首先从数据集、词嵌入、预训练模型方面阐述大模型之前的偏见缓解方法,如图6所示;然后再从大型语言模型的角度阐述偏见缓解方法。
4.1 数据集中的操作
一个干净正确的数据集对于NLP预训练模型的公平和无偏性至关重要。为了保证公平和无偏,需要进行合理的数据采样和标注,避免个人或系统性的偏见。同时,要确保数据集包含各种不同来源、背景和观点的样本,避免某些类别或观点在数据集中占据过大比例[46]。此外,还需要识别和修正可能存在的偏见,并持续评估和监控数据集的公平性和无偏性。通过确保数据集的公平和无偏性,NLP预训练模型能够更好地应对多样化的语言资料,并生成更加公正和无偏的结果,提高模型的可靠性和有效性。根据先前的研究,数据集中的操作有如下方法。
4.1.1 数据增广
数据增广是一种简单而有效的方法,Zhao等人[47]提出将数据集中句子的性别替换的方法,例如“Marry喜欢她的母亲”变成“Marry喜欢他的母亲”,该方法泛化性强,较为灵活,并且其已被证明在诸如仇恨检测、知识图谱构建等多个任务中是有效的[47~51],但是一方面该方法使数据集成本增加,另一方面可能会产生一些荒谬的句子,例如“他生了小孩”。
4.1.2 性别标记
在如机器翻译的任务中,当数据源的性别不明确时会造成模型预测结果不准确,这是因为数据集中的数据多数以男性为来源,所以模型更有可能预测说话者是男性[52]。性别标记通过对数据开头添加标记来指明数据源的性别,从而避免对于没有指明来源的输入模型倾向于来源于男性的偏见。例如,“我很高兴”会变成“[男]我很高兴”。
Vanmassenhove等人[53]已经证明性别标记是有效的,然而可能代价高昂,即了解数据来源的性别需要更多的信息,而这在内存使用和时间方面可能代价高昂。此外,机器翻译模型可能需要重新设计以正确解析性别标签。
4.1.3 偏见微调
特定下游任务的无偏数据集可能是稀缺的,但相关任务可能存在无偏数据集。偏差微调结合了从无偏数据集的迁移学习,以确保模型包含最小偏差,然后在更有偏的数据集上微调模型,用于直接为目标任务训练[50]。这使得模型可以避免从训练集中学习偏见,同时仍能得到足够的训练来执行任务。Park等人使用无性别偏见的辱骂推文数据集进行迁移学习[54],并对有性别偏见的性别歧视推文数据集进行微调[55],最终证明偏见微调是相对有效的。在大数据、大模型的背景下,微调方法更是得到了充分的发展。
4.2 词嵌入中的缓偏方法
词嵌入表示向量空间中的词。由于词嵌入模型是许多NLP系统的基本组成部分,因此减轻嵌入中的偏差在减少传播到下游任务的偏差方面起着关键作用[47]。但要认识到从嵌入空间中完全消除偏见是困难的。虽然现有方法在一定程度上成功地减轻了子空间投影方面的偏见,但Gonen等人[56]表明,基于更微妙指标(如聚类偏见)的偏见仍然存在。
4.2.1 硬除偏算法
硬除偏算法通过修正嵌入向量以达到消除与性别相关的偏见的目的[6]。具体而言,它生成一个性别方向向量,然后将每个嵌入向量沿着性别方向进行投影和修正,以消除性别偏见。经过硬除偏处理后,词语与性别之间的关联变得中立,一些原本与性别紧密相关的词语也可以被转换为中性的向量。重要的是,这种处理在减少性别偏见的同时保留了语义信息。
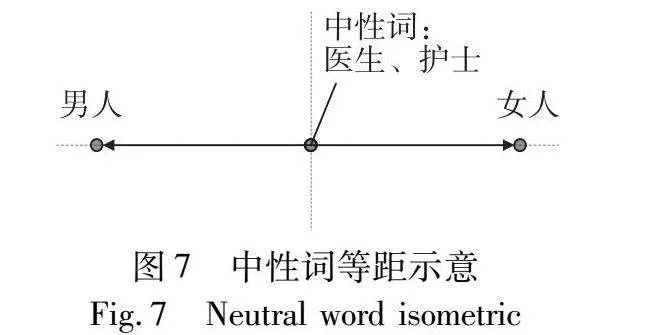
该算法的具体实现有以下几个步骤:第一步,识别性别子空间,首先定义例如{男人,女人}、{她、他}的均衡于词对集合,得到不同的性别方向,然后利用多个词对的向量组合(如she-he)来捕获性别子空间。
第二步,定义两个操作:中性化(neutralize)和均等化(equalize)。中性化确保非性别词和不应该包含性别偏见的词在性别子空间中为零。均等化使集合里的词偏见程度相等,例如在二元情况下,男人和女人偏倚的方向相反但大小相同。直观来说,中性化和均等化保证了任何中性词在偏见子空间中与任何偏见词等距,如图7所示。
形式化表示如下:使用k个正交单位向量来代表偏见子空间B={b1,…,bk}∈Euclid ExtraaBpd,当k=1时,子空间只代表一个方向。子空间中每个嵌入的分量:
wB=∑ki=1(w·bi)bi(14)
然后,本文从应该是偏中性的单词中删除该分量,并进行归一化以获得去偏嵌入。如式(15)所示。
w′=w-wB‖w-wB‖(15)
而对于如{男人,女人}等均衡词对中的词,令E代表均衡词对集合
,设μ=1|E|∑w∈Ew为集合中词的平均嵌入,μB为其在偏置子空间中的分量,如式(16)所示。则对于w∈E:
w′E=(μ-μB)+1-‖μ-μB‖2wB-μB‖wB-μB‖(16)
4.2.2 软除偏算法
软除偏包括学习嵌入矩阵的投影,该投影保留了有偏嵌入和去偏嵌入之间的内积,同时最小化了应该是中性嵌入的偏置子空间上的投影[6]。
给定W∈Euclid ExtraaBpa×v,v为词表大小,W代表所有词的嵌入向量,N代表性别中性词对的嵌入向量矩阵,这里W和N是通过其他算法得到,用来作为输入。B与硬除偏算法相同,代表性别子空间。软除偏算法寻求一个使以下目标最小化的线性变换A:
minA‖(AW)T(AW)-WTW‖2F+λ‖(AN)T(AB)‖2F(17)
4.2.3 其他方法
Dev等人[57]通过研究证明所有词沿偏见方向的简单线性投影比硬除偏更加有效,同时他们还发现带有性别关联的普通名字(例如John、Amy)通常会比使用带有性别的词(例如he、she)提供更有效的性别子空间。同时因为人类姓名中往往包含种族、国籍、地域等特征,这些特征会导致一些固有的偏见
,而通过这些通用的名称来确定偏见方向并从词嵌入中去除偏见是有效的。Wang等人[58]发现单词频率的变化也会影响词嵌入子空间的性别方向,因此提出了双重硬除偏(double-hard debiaing)来消除单词频率的负面影响。
4.3 预训练模型中的缓偏方法
传统的针对静态词嵌入的缓偏方法已经不适用于类似于预训练模型这种上下文词嵌入,本节将介绍相关预训练模型中的缓偏方法。
4.3.1 模块化可控文本生成方法
确保模型生成的内容没有偏见或不安全的因素实际上是一种文本的可控生成过程,先前的可控文本生成方法不论是使用强化学习微调[59],还是训练生成对抗网络[60]或者训练条件生成模型[61,62],都是在训练阶段进行,且模型针对每个特定的属性都需要分别进行微调,这往往是代价高昂的。
可控生成需要对p(x|a)建模,a是期望的可控属性,x是生成的样本,而一般的生成模型只学习p(x)。但根据贝叶斯法则,p(x|a)∝p(a|x)p(x),所以通过将属性模型(鉴别器)p(a|x)与基本生成模型p(x)一起插入,从而得到用于条件语言生成的即插即用的语言模型[63],即PPLM(plug and play language model)。通过PPLM,用户可以向生成模型中灵活地插入一个或多个属性模型以达到通过梯度控制大语言模型的目的,这些插入的模型可以代表不同的想要控制的属性。PPLM的最大优点是不需要对语言模型做任何额外的改动(不需要重新训练或者精心微调),让资源不足的研究人员也可以直接在预训练语言模型的基础上生成条件文本。但是PPLM仍然需要更新大模型的参数,从而导致推理速度较慢。
与PPLM相类似,用于生成的未来判别器 (future discriminators for generation,FUDGE)也是一种灵活且模块化的受控文本生成方法。而与PPLM不同的是,FUDGE只要求获得p(x)即模型的输出概率,不关心模型其中的结构或者参数,不需要训练或者微调原始的预训练语言模型。FUDGE同样是基于贝叶斯规则来建模p(a|x),其分类器的建模思想如下:分类器的输入时前缀序列x1:i,但作者认为分类器预测的是未来生成的完整序列x1:n是否满足属性a。对于数据集{(x1:n,a′)},其中a′为0或1表示句子x1:n是否满足了属性a,例如句子是否为积极情感的。那么,样本{(x1:n,a′)}所有可能的前缀组合{(x1:n,a′)}ni=1都会作为分类器的训练数据。这样,就可以得到建模p(a|x1:i)的二分类器,即未来判别器。
4.3.2 对抗学习
Zhang等人[64]提出了传统生成对抗网络的一种变体[65],让生成器根据受保护的性别属性进行学习。换句话说,生成器试图阻止判别器在给定任务(如类比完成)中识别性别。这种方法的优势在于可以用来消除任何基于梯度学习的模型的偏见。
4.3.3 模型自解毒与模型可解释性
Schick等人[66]已经证明了大型语言模型能够执行自我诊断,即仅使用其内部知识和文本描述来判断输出是否存在有毒属性。给定语言模型M和一个分词序列w1,…,wk,令pM(w|w1,…,wk)表示语言模型下一个输出分词为w的概率。作者使用包含属性y的问题来补充生成的文本x,并提示模型生成这个问题的答案,例如模型M生成文本“x=我要逮捕你!”然后使用模型进行自我判断该文本是否包含“威胁”属性(y=威胁)。对于M生成的每个句子x和每个属性描述y,构建一个自诊断输入sdg(x,y),x包含属性y的概率为
p(y|x)=pM(Yes|sdg(x,y))∑w∈{Yes,No}pM(w|sdg(x,y))(18)
基于此,作者提出了一种去偏算法,该算法通过比较给定原始输入的下一个分词的概率分布与自去偏之后的输入概率分布来降低模型生成有偏见文本的概率。
从模型内部来看,基于Transformer的预训练模型的内部参数本身压缩存储了海量的知识,Geva等人[67]通过研究其中的前馈神经网络层(feed-forward network,FFN)层发现FFN层在词汇空间的每次更新都可以分解为对应单个FFN层参数向量的子更新,并且这些子更新的结果都可以解释为词汇空间的一种概念。如“早餐”是词汇空间中的一个概念,那么对应的FFN层子更新将会提升诸如“馅饼”“牛奶”等与之相关的词汇的概率,而其他与“早餐”概念不相关的词汇概率则会降低。针对这个现象,作者提出手动寻找积极友善的相关概念,并促进相关概念的子更新,从而降低文本输出的偏见性和有害性。
5 大型语言模型中的缓偏方法
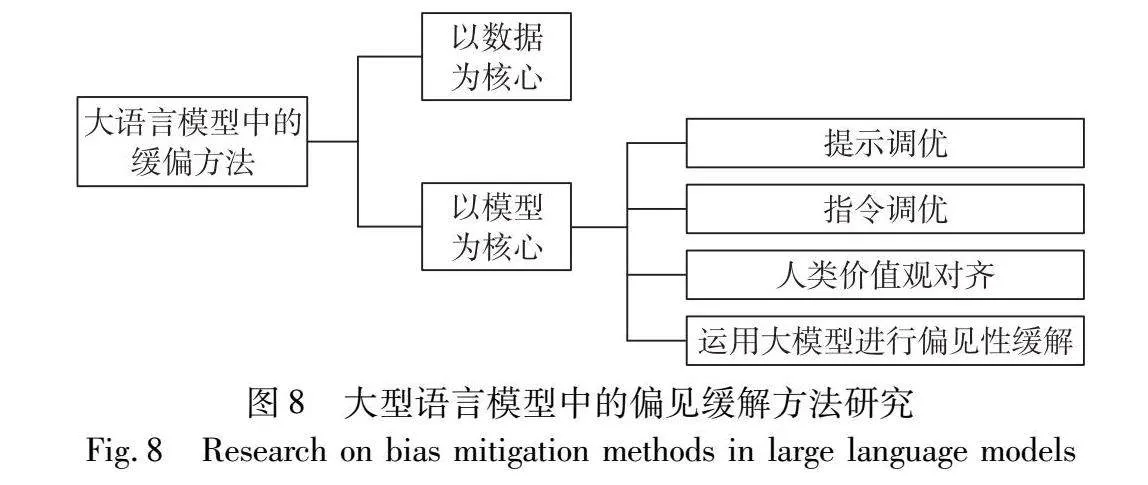
大型语言模型是在前期预训练模型基础上逐步完善和发展的结果。值得关注的是,针对大型模型中的缓解偏差方法,其根源可追溯至预训练模型的早期阶段,并非突如其来。先前的缓偏方法大部分对于大型语言模型仍然适用,因此本章总结针对大语言模型的缓偏方法主要有以下几种,如图8所示。
5.1 以数据为核心
以数据为核心的缓偏方法侧重于纠正训练数据的标签不平衡、潜在有害信息、分布差异等缺陷。在文本分类的任务中,在不平衡语料库上训练的文本分类器对某些身份术语显示出有问题的趋势,例如“gay”经常用于冒犯性评论,导致模型将其与有侮辱标签相关联。因此,为了提高数据质量,许多工作已经开展,除了在4.1节中所提到的几种数据处理方法外,Zhou等人[68]从方言识别的角度,避免将黑人作者的文本内容标记为有害,还有研究者通过识别并删除身份代词来实现数据的校准,从而达到创建具有更少有害文本和更加平衡的数据集的目的[69]。而在中文数据集方面亦有研究者从性别词分布平衡角度构建中文句子级的无偏数据集[70]。
除了着手于数据集本身的构建,通过操纵下游任务训练中的每个实例的权重来平衡训练数据的思想也受到研究人员的认同。Han等人[71]就通过减少有偏差实例的权重以减少模型的注意力权重,从而实现模型的公平性输出。Zhang等人[72]则将文本分类中的社会偏见形式化为一种从非歧视性分布到歧视性分布的选择偏差,而由此减轻模型的偏见性就等于从选择偏差中恢复非歧视性分布。在高质量的数据集代价如此高昂的当下,这种着重于数据权重的思想与方法显得尤为重要。
5.2 以模型为核心
以模型为核心的方法侧重于设计更有效的模型架构,运用更有效的算法,在模型训练过程引入先进的技术来辅助缓偏。
5.2.1 提示调优
传统的监督学习是训练一个模型来接受输入x并预测输出y的概率p(y|x),而基于提示的学习是基于语言模型,直接对文本的概率进行建模。为了使用这些模型来执行预测任务,原始输入x被使用模板修改成一个文本字符串提示x′,其中有一些未填充的槽,然后语言模型被用来概率性地填充未填充的信息,得到一个最终的字符串,从中可以得出最终的输出y[73]。
此前的调优方法通常是人工设计离散的模板或自动化搜索离散的模板[74~76],但这两种离散模板都有着成本高、鲁棒性不强(模板的变化对于模型的结果有很大影响,模板多一个词、少一个词或者词位置变动都会造成较大变化),以及最后搜索出来的结果往往并不是最佳的缺点。同时传统微调范式针对不同下游任务微调时,每个下游任务都要保存微调后的模型权重,这样不光耗时长同时占用很多存储空间。针对这些情况,Li等人[77]提出了前缀调优(prefix tuning),并在生成任务上显示了强有力的结果。此方法冻结模型参数,并在调优期间将损失反向传播到编码器堆栈中每个层(包括输入层)的前缀激活。Hambardzumyan等人[78]通过将可训练参数限制在一个掩码语言模型的输入和输出子网中来简化该方法,并在分类任务上显示出合理的结果。而提示调优(prompt tuning)则是更进一步的简化[79],作者冻结了整个预训练模型,并且给每个下游任务定义提示词,再拼接到数据上作为输入。最终通过实验发现,随着预训练模型参数量的增加,提示调优的方法会逼近全参数微调的结果。
5.2.2 指令调优
指令调优是一种在格式化的自然语言实例集合上微调大语言模型的方法。指令调优的相关实现流程为:首先收集并构建指令格式的实例,然后通过监督学习的方法将大语言模型在这些实例上进行微调。在指令调整后,大模型展现出了卓越的泛化能力,即使在多语言环境下的任务中也依然如此。多任务指令调优是基于调优方法的一种代表性策略[17,80,81]。通过将原始任务输入转换为指令格式(提示问题或前缀指令),它可以对大量多任务数据集上的模型进行微调。除了多任务学习,最近的研究还以强化学习的方式进行指令调整[16]。虽然指令调优仍然依赖于训练(即梯度反向传播),但与传统的监督学习不同,其目标是训练模型遵循指令,而不是完成特定的任务。
在文本生成中,输入或提示可能会被修改以指导模型,以避免语言的偏见。通过向输入预置额外的静态或可训练令牌,指令调节以可控的方式对输出的生成进行条件控制。修改后的提示可以用来更改微调的数据输入,或者在微调过程中更新连续前缀本身;然而,这些技术都不是单独改变预训练模型的参数,不需要额外的训练步骤,因此被认为是预处理技术。作为一种偏见缓解技术,Fatemi等人提出GEEP,使用连续提示调整来减轻性别偏见,在性别中立的数据集上进行微调。在Yang等人的ADEPT技术中,连续提示鼓励中性名词和形容词独立于受保护的属性。
尽管指令调优具有良好的跨任务泛化性,在下游任务上能更快地收敛,以及对指令的微小扰动具有鲁棒性,但指令调优仍然严重依赖于大规模的下游任务训练,这些训练的成本高昂,未来的一个理想方向便是如何减轻对大规模优化实例的依赖,同时帮助模型明确学习遵循指令。
5.2.3 人类价值观对齐
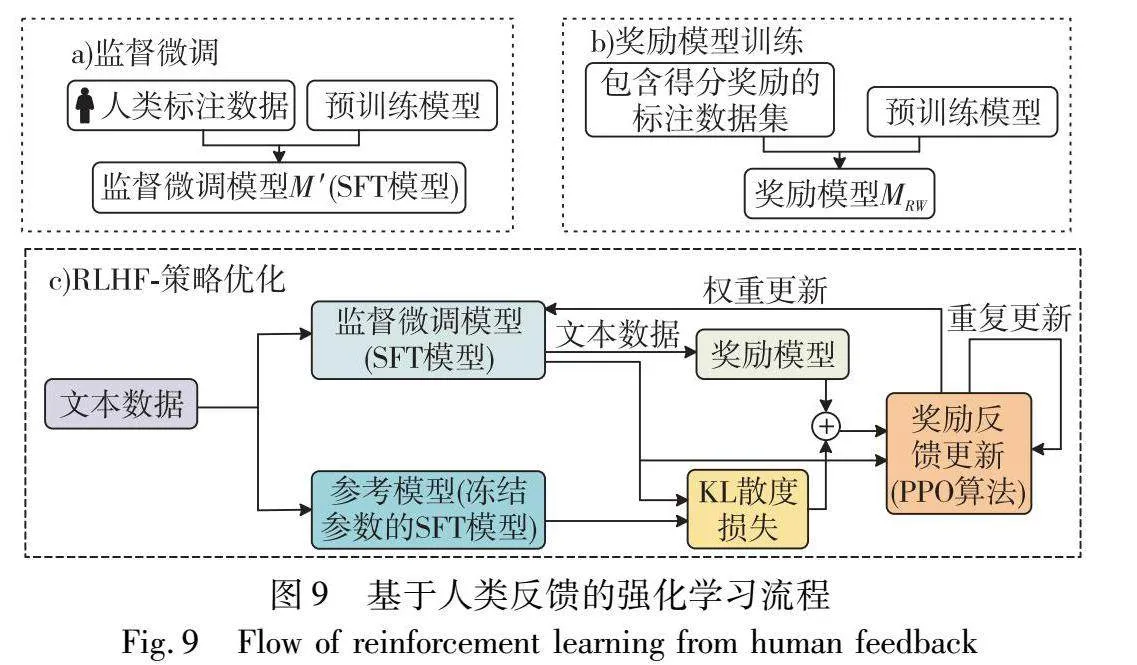
由于用来训练的语料库质量参差不齐,LLM通过捕捉其中的数据特征可能会产生一些意想不到的行为,因此有必要使大语言模型和人类价值观保持一致。伴随如LLaMA[82]和ChatGLM[5]等开源基础模型的出现,为了减轻LLM巨大的风险,目前大部分工作都试图在监督微调(supervised fine-tuning, SFT)中加入一些3H数据(乐于助人、诚实、无害),希望模型在道德伦理层面作出积极回应,但即使如此LLM仍与人类存在差距。幸运的是,OpenAI和Anthropic已经验证了基于人类反馈的强化学习(reinforcement learning from human feedback,RLHF)是在广泛的任务中将语言模型与用户意图对齐的有效途径[16,83]。
RLHF在大语言模型的发展中具有重要的意义。事实上,基于人类反馈的强化学习思想早在2008年就被提出[84]。而后,OpenAI于2017年发表了一篇通过人类反馈来进行游戏智能体学习的论文,同年,OpenAI训练的DOTA2强化学习智能体OpenAI Five在1v1的Dota2游戏中战胜了职业选手Dend。此后OpenAI相继发表了多篇关于RLHF技术的论文[16,59,85]。也正是OpenAI对于RLHF的不断研究,最后才有了ChatGPT的诞生。
RLHF结合了奖励模型、策略优化和过程监督等多种方法来提升大语言模型的性能。奖励模型通过定义奖励函数,对模型的行为进行评估和指导,衡量人类用户对LLM回答的偏好,并为LLM提供正向或负向的反馈信号。策略优化算法,如近端策略优化(PPO),用于优化LLM的输出策略,根据奖励模型的反馈信号,对LLM的策略进行调整和改进,以使其生成更符合用户期望的回答。过程监督则是一种训练方法,通过提供带有标签的示例来引导LLM的学习,提高其在复杂查询和对话场景中的逐步推理能力和理解能力。
一般而言,RLHF的实现流程分为三步,如图9所示:a)使用一个已经预训练好的模型M进行监督微调(过程监督),微调后得到的模型M′用来为RLHF提供高质量的初始化,而同时,该模型也是接下来进行RLHF方法进一步微调的对象;b)收集包含输入、输出、奖励得分三元组的数据集,并使用同样的初始模型进行微调,从而得到奖励模型MRW;c)在每次迭代中使用奖励模型MRW返回的奖励信号来训练主模型M′。同时该过程中还需要用M′冻结其中的参数获得一个参考模型M′f,通过计算M′和M′f的KL散度,来尽可能使两个模型的输出分布相似,达到最终的模型既能符合人类价值观,又不和原始模型差别太大。
事实上,将大模型与人类价值观对齐是一项艰巨的任务。通常来说,成功的RLHF训练需要一个准确的奖励模型来替代人类的判断,仔细的超参搜索进行稳定的参数更新,以及一个强大的PPO算法来进行鲁棒性策略优化。但低质量的数据和难以定义的奖励模型容易误导PPO算法。同时,PPO在新的语言环境下存在奖励稀疏和对词空间探索效率低的问题。LLM巨大的试错成本使得研究者对于大语言模型在人类价值观对齐的阶段望而却步,阻碍了LLM的发展。因此目前已有一些研究来替代RLHF或者针对RLHF提出一些改进。例如基于排序的人类偏好对齐的方式[86](rank responses to align language models with human feedback,RRHF),RRHF不需要强化学习,通过对不同语言模型生成的回复进行评分,并通过排名损失来使回复与人类偏好对齐,在拥有数据集之后,RRHF通过定义排序损失和交叉熵损失进行训练。排序损失的计算中,假设x为输入query,yi是第i个生成的答案,t为已经生成的分词,ri 是人工或者奖励模型给出的第i个回复的得分。为了使得最终训练好的生成模型与人类偏好对齐,首先计算模型θ在给定输入和已经生成的分词的条件下生成分词的概率,即Pθ(yi,t|x,yi,<t),然后对每个分词的概率分别求log,最后除以分词数量,从而得到第i条response的分数:
Pi=∑tlog Pθ(yi,t|x,yi,<t)‖yi‖(19)
在得到分数Pi 后,计算排序损失:
Lrank=∑ri<rj(0,Pi-Pj)(20)
同时为了进一步增强生成质量,参照监督微调中的交叉熵损失函数:
i′=argmaxi ri
Lft=-∑tlog Pπ(yi′,t|x,yi′,<t)(21)
最终的损失为两者之和:
L=Lrank+Lft(22)
RRHF最大的特点在于训练好的RRHF模型可以同时作为生成语言模型和奖励模型。而ReMax[87]算法通过对PPO的简化减少了内存占用和训练时间,同时也提升了模型效果,然而受限于资源作者只进行了13亿参数ReMax和PPO算法的对比。因此针对人类价值观对齐方法的研究仍有很大前景。
早在ChatGPT发布之前,不论是提示词方法还是与人类价值观对齐的技术雏形都已经出现,而到了大语言模型时期这些技术的大火值得本文借鉴思考。
5.2.4 运用大模型进行偏见性缓解
毋庸置疑的是,大语言模型在自然语言处理技术的多项下游任务中已经远超之前的模型和方法,尽管从大语言模型本身来看,大语言模型仍然是个黑盒模型,其仍然存在诸如幻觉、毒性、偏见等有害输出,但技术的好坏最终还是取决于使用者的意图,因此也有学者开始运用大模型进行偏见缓解。Barker等人[88]将ChatGPT作为一个文本简化器用以缓解偏见,其思想就是通过文本的简化,使得文本保留原有语义的同时,尽可能地简化掉其中的偏见信息。Kocielnik等人[89]基于ChatGPT开发了一个用于大模型中偏见评估的框架BiasTestGPT,该框架开源可用,可以在HuggingFace支持的几乎所有掩码模型和自回归模型上使用,并对测试结果进行可视化分析。
6 现存挑战与未来研究方向
近年来,尽管模型的偏见研究领域已经取得了一定的进展,但是随着像ChatGPT这样的大型语言模型在文本处理能力上的极大提升,以及模型内部的不可解释性问题,应该意识到过去的评估方法和偏见缓解策略可能已经不再适用。针对大型模型中的偏见问题,目前的研究还远远不够。接下来,本文将总结一些当前存在的挑战性问题,并探讨未来可能的研究方向。
6.1 中文公平性语料的缺乏
构建高质量的文本语料库一直是改进NLP应用以消除文本中性别刻板印象的关键内容之一,但可以发现的是关于偏见的现有研究大部分都只关注英语,而中文的相关数据集很少。因此如何构建大规模、高质量的中文相关的偏见数据集面临着挑战。
6.2 不同偏见的通用处理方法
偏见包含性别、种族、职业、宗教等方面,但目前的大部分偏见研究主要是针对性别偏见。先前已有研究表明,模型对于不同偏见的识别程度也不同,其中性别偏见的识别相对容易而宗教偏见的识别相对困难。因此探索通用的识别偏见和缓解偏见的相关方法是具有意义的。
6.3 语言模型作为处理偏见的工具
实际上,彻底消除模型中的偏见极具挑战,因为这些偏见源于人类社会,而在现实生活中,完全避免偏见是不可能的。然而,在提高模型公平性的同时,可以充分利用大型语言模型卓越的文本处理能力,将其应用于偏见评估和缓解领域,这一研究方向颇具探索价值。
6.4 多模态模型中偏见的相关研究
随着GPU等计算资源的快速发展,多模态研究得到了广泛关注。GPT-4和ChatGPT相较于之前的模型,已经扩展了对图像处理的支持。考虑到文字生成图像任务在当下的流行程度,对多模态模型的偏见性问题进行研究具有重要意义。此外,由于图像相较于文字更能直观地传达内容,人们更容易从中感受到歧视。因此,在未来的研究中,需要关注多模态模型中的偏见问题,并积极探索解决方案,以促进人工智能技术的公平性、透明度和可解释性。
7 结束语
大型语言模型时代下,模型的公平性至关重要。本文首先概述了自然语言处理技术的发展,并探讨了人类社会中的偏见与自然语言处理技术中偏见的来源及其关联。然后,从模型发展的角度,分别探讨了词嵌入模型、预训练模型和大型语言模型中的偏见评估方法。在此基础上,本文从数据集、词嵌入模型、预训练模型和大型语言模型的角度,探讨了相应的偏见缓解策略,并进行详细的分析与总结。最后,深入剖析了大语言模型背景下,关于模型偏见的挑战性问题,并对未来的研究方向进行了展望。总体来看,在大型语言模型广泛应用于各个领域并实现商业化的背景下,对模型偏见性的研究显得尤为重要。
参考文献:
[1]Mikolov T, Chen Kai, Corrado G,et al. Efficient estimation of word representations in vector space [EB/OL]. (2013) [2023-10-27]. http://arxiv.org/abs/1301.3781.
[2]Peters M E, Neumann M, Iyyer M,et al. Deep contextualized word representations [C]// Proc of Conference of NAACL. 2018: 2227-2237.
[3]Devlin J, Chang M W, Lee K,et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proc of Conference of NAACL.2019: 4171-4186.
[4]Bubeck S, Chandrasekaran V, Eldan R,et al. Sparks of artificial general intelligence: early experiments with GPT-4 [EB/OL]. (2023) [2023-11-16]. http://arxiv.org/abs/2303.12712.
[5]Zeng Aohan, Liu Xiao, Du Zhengxiao,et al. GLM-130B: an open bilingual pre-trained model [EB/OL]. (2022) [2023-07-13]. http://arxiv.org/abs/2210.02414.
[6]Bolukbasi T, Chang Kaiwei, Zou J Y,et al. Man is to computer programmer as woman is to homemaker?Debiasing word embeddings [J]. Advances in Neural Information Processing Systems, 2016, 29: 4349-4357.
[7]Nadeem M, Bethke A, Reddy S. StereoSet: measuring stereotypical bias in pretrained language models [EB/OL]. (2020) [2023-10-18]. http://arxiv.org/abs/2004.09456.
[8]Rosenfeld R. Two decades of statistical language modeling: where do we go from here? [J]. Proc of the IEEE, 2000, 88(8): 1270-1278.
[9]Mikolov T, Karafiat M, Burget L,et al. Recurrent neural network based language model [C]//Proc of Inter Speech. 2010: 1045-1048.
[10]Pennington J, Socher R, Manning C. GloVe: global vectors for word representation [C]// Proc of Conference on Empirical Methods in Natural Language Processing.2014: 1532-1543.
[11]Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need [C]// Proc of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
[12]Radford A, Wu J, Child R,et al. Language models are unsupervised multitask learners [J]. OpenAI Blog, 2019, 1(8): 9.
[13]Lewis M, Liu Yihan, Goyal N,et al. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2020: 7871-7880.
[14]Brown T B, Mann B, Ryder N,et al. Language models are few-shot learners [C]// Proc of Advances in Neural Information Processing Systems. 2020: 1877-1901.
[15]Zhao W X, Zhou Kun, Li Junyi,et al. A survey of large language models [EB/OL]. (2023) [2023-04-19]. http://arxiv.org/abs/2303.18223.
[16]Ouyang Long, Wu J, Jiang Xu,et al. Training language models to follow instructions with human feedback [EB/OL]. (2022) [2023-11-13]. http://arxiv.org/abs/2203.02155.
[17]Wei J, Bosma M, Zhao V Y,et al. Finetuned language models are zero-shot learners [C]// Proc of International Conference on Learning Representations. 2021.
[18]Wei J, Wang Xuezhi, Schuurmans D,et al. Chain-of-thought promp-ting elicits reasoning in large language models [EB/OL]. (2023) [2023-04-19]. http://arxiv.org/abs/2201.11903.
[19]王培冰, 张宁, 张春. 基于Prompt的两阶段澄清问题生成方法 [J]. 计算机应用研究, 2024, 41(2): 421-425. (Wang Peibing, Zhang Ning, Zhang Chun. Two-stage clarification question generation method based on Prompt [J]. Application Research of Compu-ters, 2024, 41(2): 421-425.)
[20]Kojima T, Gu S S, Reid M,et al. Large language models are zero-shot reasoners [J]. Advances in Neural Information Processing Systems, 2022, 35: 22199-22213.
[21]Zhou D, Scharli N, Hou Le,et al. Least-to-most prompting enables complex reasoning in large language models [EB/OL]. (2023) [2024-03-18]. http://arxiv.org/abs/2205.10625.
[22]Delobelle P, Tokpo E K, Calders T,et al. Measuring fairness with biased rulers: a survey on quantifying biases in pretrained language models [C]// Proc of the 1st Workshop on Gender Bias in Natural Language Processing. 2019: 166-172.
[23]Elsafoury F, Abercrombie G. On the origins of bias in NLP through the lens of the Jim code [EB/OL]. (2023) [2023-05-29]. http://arxiv.org/abs/2305.09281.
[24]Garg N, Schiebinger L, Jurafsky D,et al. Word embeddings quantify 100 years of gender and ethnic stereotypes [J]. Proc of the National Academy of Sciences, 2018, 115(16): E3635-E3644.
[25]Rios A, Joshi R, Shin H. Quantifying 60 years of gender bias in biomedical research with word embeddings [C]// Proc of the 19th SIGBioMed Workshop on Biomedical Language Processing. Stroudsburg,PA: Association for Computational Linguistics, 2020: 1-13.
[26]朱述承, 苏祺, 刘鹏远. 基于语料库的我国职业性别无意识偏见共时历时研究 [J]. 中文信息学报, 2021, 35(5): 130-140. (Zhu Shucheng, Su Qi, LIU Pengyuan. Based on the corpus of Chinese professional sex unconscious prejudice synchronic diachronic study [J]. Journal of Chinese Information, 2021, 35(5): 130-140.)
[27]Nangia N, Vania C, Bhalerao R,et al. CrowS-Pairs: a challenge dataset for measuring social biases in masked language models [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA:Association for Computational Linguistics. 2020:1953-1967.
[28]Caliskan A, Bryson J J, Narayanan A. Semantics derived automatically from language corpora contain human-like biases [J]. Science, 2017, 356(6334): 183-186.
[29]Silva A, Tambwekar P, Gombolay M. Towards a comprehensive understanding and accurate evaluation of societal biases in pre-trained Transformers [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,PA: Association for Computational Linguistics, 2021: 2383-2389.
[30]Manzini T, Lim Y C, Tsvetkov Y,et al. Black is to criminal as Caucasian is to police: detecting and removing multiclass bias in word embeddings [C]// Proc of NAACL-HLT. 2019: 615-621.
[31]May C, Wang A, Bordia S,et al. On Measuring social biases in Sentence Encoders [C]// Proc of NAACL-HLT. 2019: 622-628.
[32]Cer D, Yang Yinfei, Kong S,et al. Universal sentence encoder for English [C]// Proc of Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg,PA: Association for Computational Linguistics, 2018: 169-174.
[33]Blodgett S L, Lopez G, Olteanu A,et al. Stereotyping Norwegian Salmon: an inventory of pitfalls in fairness benchmark datasets [C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics, 2021: 1004-1015.
[34]Chang Yupeng, Wang Xu, Wang Jindong,et al. A survey on evaluation of large language models [EB/OL]. (2023) [2023-11-21]. http://arxiv.org/abs/2307.03109.
[35]Zhuo T Y, Huang Yujin, Chen Chunyang,et al. Red teaming Chat-GPT via Jailbreaking: bias, robustness, reliability and toxicity [EB/OL]. (2023) [2024-04-02]. http://arxiv.org/abs/2301.12867.
[36]Wang Boxin, Chen Weixin, Pei Hengzhi,et al. DecodingTrust: a comprehensive assessment of trustworthiness in GPT models [EB/OL]. (2023) [2023-11-21]. http://arxiv.org/abs/2306.11698.
[37]Hartmann J, Schwenzow J, Witte M. The political ideology of conversational AI: converging evidence on ChatGPT’s pro-environmental, left-libertarian orientation [EB/OL]. (2023-01-05).
https://arxiv.org/abs/2301.01768.
[38]Rutinowski J, Franke S, Endendyk J,et al. The self-perception and political biases of ChatGPT [EB/OL]. (2023) [2023-12-11]. http://arxiv.org/abs/2304.07333.
[39]Feng Shangbin, Park C Y, Liu Yuhan,et al. From pretraining data to language models to downstream tasks: tracking the trails of political biases leading to unfair NLP models [EB/OL]. (2023) [2023-10-09]. http://arxiv.org/abs/2305.08283.
[40]Gehman S, Gururangan S, Sap M,et al. RealToxicityPrompts: evaluating neural toxic degeneration in language models [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2020: 3356-3369.
[41]Dhamala J, Sun T, Kumar V,et al. BOLD: dataset and metrics for measuring biases in open-ended language generation [C]// Proc of ACM Conference on Fairness, Accountability, and Transparency. New York:ACM Press, 2021: 862-872.
[42]Huang Yue, Zhang Qihui, Philip S Y,et al. TrustGPT: a benchmark for trustworthy and responsible large language models [EB/OL]. (2023) [2024-03-19]. http://arxiv.org/abs/2306.11507.
[43]Sun Hao, Zhang Zhexin, Deng Jiawen,et al. Safety assessment of Chinese large language models [EB/OL]. (2023) [2023-04-21]. http://arxiv.org/abs/2304.10436.
[44]Perez F, Ribeiro I. Ignore previous prompt: attack techniques for language models [C]// NeurIPS ML Safety Workshop. 2022.
[45]Deng Jiawen, Sun Hao, Zhang Zhexin,et al. Recent advances towards safe, responsible, and moral dialogue systems: a survey [EB/OL]. (2023) [2023-05-29]. http://arxiv.org/abs/2302.09270.
[46]李昂, 韩萌, 穆栋梁, 等. 多类不平衡数据分类方法综述 [J]. 计算机应用研究, 2022, 39(12): 3534-3545. (Li Ang, Han Meng, Mu Dongliang,et al. Survey of multi-class imbalanced data classification methods [J]. Application Research of Computers, 2022, 39(12): 3534-3545.)
[47]Zhao Jieyu, Wang Tianlu, Yatskar M,et al. Gender bias in corefe-rence resolution: evaluation and debiasing methods [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2018: 15-20.
[48]Lee K, He Luheng, Zettlemoyer L. Higher-order coreference resolution with coarse-to-fine inference [EB/OL]. (2018) [2023-11-12]. http://arxiv.org/abs/1804.05392.
[49]Lee K, He Luheng, Lewis M,et al. End-to-end neural coreference resolution [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2017: 188-197.
[50]Park J H, Shin J, Fung P. Reducing gender bias in abusive language detection [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2018: 2799-2804.
[51]Madaan N, Mehta S, Agrawaal T S,et al. Analyze, detect and remove gender stereotyping from Bollywood movies [C]//Proc of Conference on Fairness, Accountability and Transparency. 2018: 92-105.
[52]Prates M O R, Avelar P H C, Lamb L. Assessing gender bias in machine translation-a case study with Google Translate [J]. Neural Computing and Applications, 2020, 32: 6363-6381.
[53]Vanmassenhove E, Hardmeier C, Way A. Getting gender right in neural machine translation [EB/OL]. (2019) [2023-11-12]. http://arxiv.org/abs/1909.05088.
[54]Founta A M, Djouvas C, Chatzakou D,et al. Large scale crowdsour-cing and characterization of Twitter abusive behavior [C]// Proc of International AAAI Conference on Web and Social Media. 2018.
[55]Waseem Z, Hovy D. Hateful symbols or hateful people?Predictive features for hate speech detection on Twitter [C]// Proc of NAACL Student Research Workshop. 2016: 88-93.
[56]Gonen H, Goldberg Y. Lipstick on a pig: debiasing methods cover up systematic gender biases in word embeddings but do not remove them [C]// Proc of Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg,SA: Association for Computational Linguistics,2019: 609-614.
[57]Dev S, Phillips J. Attenuating bias in word vectors [EB/OL]. (2019) [2023-05-17]. http://arxiv.org/abs/1901.07656.
[58]Wang Tianlu, Lin X V, Rajani N F,et al. Double-hard debias: tailoring word embeddings for gender bias mitigation [C]// Proc of the 58th Annual Meeting of Association for Computational Linguistics. 2020: 5443-5453.
[59]Ziegler D M, Stiennon N, Wu J,et al. Fine-tuning language models from human preferences [EB/OL]. (2020) [2023-11-13]. http://arxiv.org/abs/1909.08593.
[60]Yu Lantao, Zhang Weinan, Wang Jun,et al. SeqGAN: sequence generative adversarial nets with policy gradient [C]// Proc of AAAI Conference on Artificial Intelligence. 2017: 2852-2858.
[61]Ficler J, Goldberg Y. Controlling linguistic style aspects in neural language generation [C]// Proc of Workshop on Stylistic Variation. 2017: 94-104.
[62]Kikuchi Y, Neubig G, Sasano R,et al. Controlling output length in neural encoder-decoders [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2016: 1328-1338.
[63]Dathathri S, Madotto A, Lan J,et al. Plug and play lanITDG7pvRW9orp4tJj6u0qoqjr+Bvzev8q3duDCeq/Eo=guage mo-dels: a simple approach to controlled text generation [EB/OL]. (2020). http://arxiv.org/abs/1912.02164.
[64]Zhang B H, Lemoine B, Mitchell M. Mitigating unwanted biases with adversarial learning [C]// Proc of AAAI/ACM Conference on AI, Ethics, and Society. 2018: 335-340.
[65]Goodfellow I, Pouget-Abadie J, MIRZA M,et al. Generative adversarial nets [C]// Advances in Neural Information Processing Systems. 2014: 2672-2680.
[66]Schick T, Udupa S, Schutze H. Self-diagnosis and self-debiasing: a proposal for reducing corpus-based bias in NLP [J]. Transactions of the Association for Computational Linguistics, 2021, 9: 1408-1424.
[67]Geva M, Caciularu A, Wang K R,et al. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2022: 30-45.
[68]Zhou Xuhui, Sap M, Swayamdipta S,et al. Challenges in automated debiasing for toxic language detection [C]// Proc of the 16th Confe-rence of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021: 3143-3155.
[69]Panda S, Kobren A, Wick M,et al. Don’t just clean it, proxy clean it: mitigating bias by proxy in pre-trained models [C]// Proc of Conference on EMNLP. 2022: 5073-5085.
[70]赵继舜, 杜冰洁, 刘鹏远, 等. 中文句子级性别无偏数据集构建及预训练语言模型的性别偏度评估 [J]. 中文信息学报, 2023, 37(9): 15-22. (Zhao Jishun, Du Bingjie, Liu Pengyuan, et al. Construction of Chinese sentence-level gender unbiased dataset and evaluation of gender bias in pre-trained language models [J]. Journal of Chinese Information Technology, 2019, 37(9): 15-22.)
[71]Han X, Baldwin T, Cohn T. Balancing out bias: achieving fairness through balanced training [EB/OL]. (2022) [2024-03-17]. http://arxiv.org/abs/2109.08253.
[72]Zhang Guanhua, Bai Bing, Zhang Junqi,et al. Demographics should not be the reason of toxicity: mitigating discrimination in text classifications with instance weighting [C]// Proc of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 4134-4145.
[73]Liu Pengfei, Yuan Weizhe, Fu Jinlan,et al. Pre-train, prompt, and predict: a systematic survey of prompting methods in natural language processing [EB/OL]. (2021). http://arxiv.org/abs/2107.13586.
[74]Shin T, Razeghi Y, Logan IV R L,et al. AutoPrompt: eliciting knowledge from language models with automatically generated prompts [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2020: 4222-4235.
[75]Jiang Zhengbao, Xu F F, Araki J,et al. How can we know what language models know? [J]. Transactions of the Association for Computational Linguistics, 2020, 8: 423-438.
[76]Schick T, Schutze H. Exploiting cloze questions for few shot text classification and natural language inference [C]// Proc of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021: 255-269.
[77]Li X L, Liang P. Prefix-tuning: optimizing continuous prompts for generation [C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Confe-rence on Natural Language Processing. 2021: 4582-4597.
[78]Hambaradzumyan K, Khachatrian H, May J. WARP: word-level adversarial reprogramming [C]// Proc of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 4921-4933.
[79]Lester B, Al-Rfou R, Constant N. The power of scale for parameter-efficient prompt tuning [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2021: 3045-3059.
[80]Sanh V, Webson A, Raffel C,et al. Multitask prompted training enables zero-shot task generalization [EB/OL]. (2022) [2023-11-13]. http://arxiv.org/abs/2110.08207.
[81]Wang Yizhong, Mishra S, Alipoormolabashi P,et al. Super-natural instructions: generalization via declarative instructions on 1600+NLP tasks [C]// Proc of Conference on Empirical Methods in Natural Language Processing. 2022: 5085-5109.
[82]Touvron H, Lavril T, Izacard G,et al. LLaMA: open and efficient foundation language models [EB/OL]. (2023) [2023-12-13]. http://arxiv.org/abs/2302.13971.
[83]Bai Yuntao, Jones A, Ndousse K,et al. Training a helpful and harmless assistant with reinforcement learning from human feedback [EB/OL]. (2022) [2023-09-19]. http://arxiv.org/abs/2204.05862.
[84]Bradley K W, Stone P. TAMER: training an agent manually via evaluative reinforcement [C]// Proc of the 7th IEEE International Conference on Development and Learning. Piscataway,NJ:IEEE Press, 2008: 292-297.
[85]Stiennon N, Ouyang Long, Wu J,et al. Learning to summarize from human feedback [C]// Advances in Neural Information Processing Systems. 2020: 3008-3021.
[86]Yuan Zheng, Yuan Hongyi, Tan Chuanqi,et al. RRHF: rank responses to align language models with human feedback without tears [EB/OL]. (2023) [2024-04-02]. http://arxiv.org/abs/2304.05302.
[87]Li Ziniu, Xu Tian, Zhang Yushun,et al. ReMax: a simple, effective, and efficient reinforcement learning method for aligning large language models [EB/OL]. (2023). http://arxiv.org/abs/2310.10505.
[88]Barker C, Kazakov D. ChatGPT as a text simplification tool to remove bias [EB/OL]. (2023). http://arxiv.org/abs/2305.06166.
[89]Kocielnik R, Prabhumoye S, Zhang V,et al. BiasTestGPT: using ChatGPT for social bias testing of language models [EB/OL]. (2023) [2024-03-15]. http://arxiv.org/abs/2302.07371.
