教育大语言模型的内涵、构建和挑战
2024-10-11刘明吴忠明杨箫郭烁廖剑

摘要:大语言模型作为新一代人工智能的核心技术,为教育领域带来前所未有的机遇。但由于以ChatGPT为代表的通用大语言模型仅能提供通用型反馈,难以与复杂的教育场景、育人方式相匹配,因而亟需构建专用的教育大语言模型。教育大语言模型具有教育知识库的全面性、教学内容生成的安全性、反馈信息的教育价值性、问题解决的个性化、人机交互的多模态性、用户使用的易用性等特点和优势。其构建流程主要包括6个步骤:一是制定教育目标,预设模型构建标准与技术范式;二是选择或设计大语言模型基座,对齐教育任务属性;三是构建教育语料库,实现无序数据的教育价值转向;四是开展模型训练或提示,获得教育任务通用和细粒度知识;五是链接外部教育知识库,灵活扩展模型知识和学生模型;六是评价教育大语言模型,让模型“懂人理”。当前教育大语言模型的应用主要聚焦编程、课后阅读和计算机教育三类教学场景,有助于学生计算思维、提问能力和编程技能等高阶能力和学科基本能力的提升。未来教育大语言模型应由多方合力共建语料库与知识库以统一标准,尝试应用新技术以破解多模态理解缺陷和计算困境,深入探索人机协同教学机制以实现其与高阶教育目标的匹配。
关键词:教育大语言模型;生成式人工智能;人工智能教育应用;知识增强
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2024)05-0050-11 doi10.3969/j.issn.1009-5195.2024.05.006
基金项目:2024年度国家自然科学基金面上项目“知识增强大语言模型的科学课教学问题智能生成方法研究”(62477039);2024年度重庆市教育委员会科学技术研究计划重点项目“个性化科学教育大语言模型的关键技术与应用示范研究”(KJZD-K202400208)。
作者简介:刘明,博士,教授,博士生导师,西南大学教育学部(重庆 400715);吴忠明,博士研究生,西南大学教育学部(重庆 400715);杨箫,硕士研究生,西南大学教育学部(重庆 400715);郭烁,博士研究生,西南大学教育学部(重庆 400715);廖剑,博士,副教授,硕士生导师,西南大学教育学部(重庆 400715)。
党的二十大报告提出,要“构建新一代信息技术、人工智能、生物技术、新能源、新材料、高端装备、绿色环保等一批新的增长引擎”,“推进教育数字化”(新华社,2022)。教育数字化转型既是构建教育新生态、支撑教育高质量发展的必由之路(祝智庭等,2022),也是推进教育公平发展的有效途径。教育部怀进鹏部长在谈及教育、科技、人才、创新等领域的改革时亦指出,要“大力推进智慧校园建设,打造中国版人工智能教育大模型”(中华人民共和国教育部,2024)。面对新一轮科技革命和产业变革的深入发展,以生成式人工智能为代表的新一代人工智能技术成为引领教育数字化转型的重要驱动力,将推动教育领域迎来人机协同、跨界融合、共创共享的新时代(戴岭等,2023)。大语言模型作为新一代人工智能的核心技术,主要有两大发展方向:一是以ChatGPT为代表的通用大语言模型,二是针对特定领域或任务进行优化设计的专用大语言模型。由于教育内容的复杂性、教育场景的多样性和教育形式的灵活性,传统通用大语言模型难以充分理解教育场景和信息的内在关系,其普适化、通用化的生成内容无法与现实教育内容及教育主体高度匹配,也难以实现与教育场景的深度耦合,因此教育领域亟需设计、开发和构建专用的教育大语言模型。本研究通过分析当前国内外主流的教育领域大语言模型的类型、技术特征和优缺点,提出了教育大语言模型的主要内涵与特征,描述了教育大语言模型的主要构建方法与流程,并探讨了当前教育大语言模型开发与建设面临的挑战与应对策略,以期为新一代人工智能赋能教育数字化转型提供参考。
一、大语言模型教育应用综述
随着2022年ChatGPT将大语言模型引入大众视野,大语言模型行业发展如火如荼,诸如LLaMA、OPT、Baichuan等开源大语言模型如雨后春笋般发布,为垂直领域的教育大语言模型奠定了良好的技术基座。通过对近三年教育领域大语言模型相关的学术论文、行业咨询报告、Github开源项目以及开源数据竞赛等进行检索,本研究共梳理出29个可应用于教育领域的大语言模型。进一步分析发现,当前对教育领域大语言模型的探索处于起步阶段,研究主体主要是商业公司和高校研究团队;研究平台主要有两类:一是企业、高校或研究院设立的研究平台,二是以开源数据竞赛、国际教育会议工作坊等为支撑的开放平台。
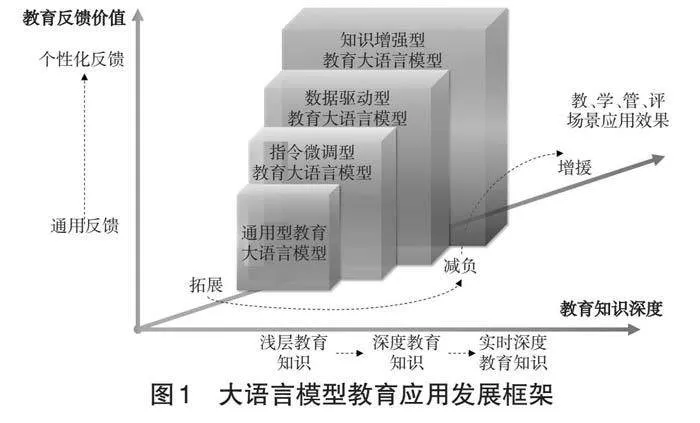
从教育应用视角出发,本研究将教育领域大语言模型划分为通用型教育大语言模型、指令微调型教育大语言模型、数据驱动型教育大语言模型和知识增强型教育大语言模型四种技术范式。表1对15个主流教育领域的大语言模型的应用场景、特点与不足等进行了梳理和比较。
1.通用型教育大语言模型
通用型教育大语言模型是指在特定教育任务或教学活动的指导下,教育用户直接利用ChatGPT、星火认知大模型等对话式聊天机器人和开源大语言模型的通用知识,通过主动对话的形式解决教育问题、辅助教学活动的大语言模型。较为常见的工具有ChatGPT、星火认知大模型、文心一言等。该范式是大语言模型教育应用的初等形态,研究者已在启发式对话教学(李海峰等,2024)、学习行为分析(Snyder et al.,2024)和作业评价(王丽等,2023)等场景下开展了教育应用,具有适用场域广泛、教育实效明显、师生使用部署便捷等优势,但也存在因模型闭源和领域深度知识缺失而带来的教育提示语编写困难、反馈的教育价值不高、复杂教育任务场景下准确度不足、数据隐私与安全隐患等问题。
2.指令微调型教育大语言模型
指令微调型教育大语言模型是指在特定教育任务引导下,通过构建基于教育学或心理学理论指导的结构化文本,来表达规范的教育微调数据集、微调指令数据集或教育提示语,以此对通用大语言模型开展提示输出或指令调优训练的垂直领域大语言模型。此类范式下,最具代表性的模型有国际中文教育大语言模型“桃李”、九章大模型(MathGPT)、中文儿童陪伴大语言模型“巧板”,以及用于教育文本评估、课堂活动指导和教学问答的大语言模型“Merlyn Edu”(Jagmohan et al.,2023)。有学者使用DistilBERT-66M模型和自整理数据集,经微调形成了支持“困惑、情感和紧迫”三个维度的在线课堂分析大语言模型(Clavié et al.,2019)。此类教育大语言模型在保留原有基座模型泛化能力的基础上,简化了师生撰写复杂教育提示语的过程,提升了模型反馈的教育价值,也提高了目标教育任务的准确度。但由于其有效微调指令数据量不足和不均衡等因素,使得此类范式下的教育大语言模型缺乏对学科知识的认知,进而导致其在复杂任务场景下的反馈效果不佳、模型过拟合,甚至生成有害信息等。
3.数据驱动型教育大语言模型
数据驱动型教育大语言模型是指在指令微调型教育大语言模型构建过程中,在开展指令微调前,使用与任务相关的公共数据集或通用教育数据集构建预训练数据集(如教学数据、百科知识等),对大语言模型基座进行预训练,进而实现“预训练+微调”双阶段训练的教育大语言模型。此类范式下,代表性的研究有:其一,Bulathwela等(2023)基于T5基座模型,使用开源S2ORC数据集进行预训练,并使用SQuAD、SciQ开源问答数据集进行两阶段微调,构建了教育问题生成大语言模型“EduQG+”。其二,MetaAI自研了基于自回归架构的大语言模型,从预印本服务器、Semantic Scholar、教材、PubChem、Common Crawl等资源中过滤并构建了880亿Token论文数据库、70亿Token引文数据库、科学知识库、学术与科学语料库、科学领域代码数据库,由此构建了用于科学知识推理、检索与组合的教育大语言模型“Galactica”(Taylor et al.,2022)。其三,Zhao等(2024)基于LLaMA-13B基座模型,使用化学论文和课本数据库进行预训练,并使用科学相关文本提示语进行指令调优,最终构建了可实现化学知识问答、分子式设计与反应分析的化学教育大语言模型“ChemDFM”。相较于指令微调型教育大语言模型,此类教育大语言模型一定程度上解决了准确性、过拟合和有害信息等问题;但因训练数据质量参差不齐、知识时效性难以保障、多模态表示缺失等因素,致使该模型面对新知识时可能仍无法满足教育任务的需要,同时生成内容的深度也存在不足。
4.知识增强型教育大语言模型
知识增强型教育大语言模型是指在上述教育大语言模型进行推理、生成响应之前,充分引入检索增强生成(Retrieval-Augmented Generation,RAG)技术,通过检索模型输入与预设外部教育知识库(如教材、学科知识图谱等)的相关内容或引用网络搜索引擎检索结果,以实现对教育大语言模型的输出优化。例如,华东师范大学的社会认知计算团队基于LLaMA-7B/13B基座,在教育学与心理学理论指导下,以自建中文教材与经过过滤的开源指令调优对话数据集进行预训练,并以自建问答、情感支持、启发式对话和论文评估等数据集进行微调,同时整合了基于搜索引擎的检索增强技术,由此构建了可用于知识问答、情感咨询、产婆术对话教学与文本评估等众多教育场景的教育对话大语言模型“EduChat”(Dan et al.,2023)。浙江大学的研究团队基于Qwen-7B基座模型,首先利用通用中文语料库对其进行微调;其次利用教材类的教育权威知识库构建本地知识库,并以此对模型进行第二轮无监督微调;随后基于布鲁姆分类法在多种教育任务场景中构建指标模板,以此收集教育指令数据集并进行第三轮指令微调;最后引入基于本地知识库和搜索引擎两类检索方法进行输出结果优化,由此构建了检索增强的教育大语言模型“智海—三乐”(WisdomBot)。方略研究院(2024)利用GPT结构大语言模型,运用自建的互联网内容数据、高校管理与研究的智库数据、人类反馈数据,以及持续更新的高等教育业务场景和主题知识库,构建了面向高校管理和智库咨询的教育大语言模型“一答”。此类技术范式能够通过引入外部知识库的方式,实现教育大语言模型的知识可持续更新,并进一步提升反馈的准确性和实用性。然而,由于现有研究中普遍缺乏其与学生画像或学生模型的有效整合,进而导致其普遍存在个性化学习支持不足的问题。
基于上述分析,本研究从大语言模型教育应用的技术范式、场景应用、教育反馈价值和教育知识深度四个方面构建了如图1所示的大语言模型教育应用发展框架。当前大语言模型的教育应用已基本涵盖智慧教学、智慧学习、智慧管理与智慧评价四大场景,但多以智慧学习和评价场景为主。随着技术手段的不断精进,以指令微调、教育大数据预训练、知识增强等技术对大语言模型进行二次或多次开发的教育WTXdSHSFlmW5dPlzHWlDrg==大语言模型将会不断涌现,其不仅能降低教育用户的使用门槛,逐步摆脱通用大语言模型在开放域知识上的无序性和在教育反馈上的低阶性,而且随着模型的教育知识深度不断强化,教育知识实时更新的能力将不断得到拓展,教育反馈价值也将由通用性走向具有认知和元认知干预效果的个性化,进而促进教、学、管、评四大场景下的协同应用效果从简单的拓展发展为减负或“增援”(乐惠骁等,2022)。另外,数据的隐私保护和复杂教育场景下的泛化能力也将得到有效提升,进而为教育数字化转型的基础设施建设提供坚实的技术基座。当然其也面临生成内容安全隐患、开发经济技术成本高、多模态理解能力欠缺等问题。
二、教育大语言模型的内涵与特征
基于上文对主流教育大语言模型的分析和比较,本研究将教育大语言模型界定如下:教育大语言模型是指在教育理论或规范指导下,在特定教学场景中,使用教育大数据进行提示或指令微调、预训练甚至引入外部知识进行检索增强而生成的深度神经网络语言模型,是自然语言处理、知识库和教育大数据技术等的集合体,其以人机对话或者智能分析服务的形式,为教师、学生、管理者和家长等教育主体,提供高效化教学资源创建、智能化人机协同教与学、个性化教育反馈与评价和精准化教育管理与决策服务等功能,旨在实现人类智慧与机器智能的协同共生。
该定义中,教育大数据是指教育活动中产生的,并在教育理论或规范下进行修正和标准化的大规模数据,包括教学反思日志、心理辅导文本、报考咨询记录、MOOC论坛评论等。深度神经网络模型是指基于Transformer架构的神经网络模型,包括主流的轻量级BERT到重量级T5以及超重量级的LLaMA模型等。与通用型大语言模型相比,教育大语言模型具有以下典型特征:
一是教育知识库的全面性。教育大语言模型依托教育大数据预训练和外部知识检索增强技术,保障教育大语言模型在教育情境下具有相对广泛和及时更新的知识结构,包括教育情境下的教育知识、科学研究和社会实践中涉及的各学科领域、不同层次水平的知识等,体现了教育大语言模型的包容性,并能够准确地理解与生成内容。
二是教学内容生成的安全性。通用大语言模型仍存在生成内容版权争议、虚假信息、违法用途和价值导向不安全等伦理问题(焦建利,2023)。而教育大语言模型作为支持落实立德树人任务的数字基座,能够主动保障在各类教育情境下快速生成健康、安全、高质量的教育内容,实现主动追溯非原创内容源头,并根据用户偏好实现推理过程的透明阐述,同时能避免有害或与价值导向偏离的信息输送,继而提升教育大语言模型的可信度。
三是反馈信息的教育价值性。当前通用大语言模型教育反馈能力仅停留在浅层次的纠错型反馈(徐晓艺等,2024),而教育大语言模型融合了教育学、心理学和学习科学相关理论,能够生成具有启发性和可实施性的教育反馈,如支架引导、纠错反馈等认知型反馈,以及学习策略指导、自我调节等元认知反馈,有助于促进学习者学科核心素养和高阶思维能力的发展。
四是问题解决的个性化。面对教育情境的复杂性与教育活动中任务的复杂性(翟雪松等,2023),教育大语言模型能精准把握教育目标和学生画像,理解多样教育场景下多元化的用户需求,充当诸如助教、学伴、助管等不同角色,适应自主学习、小组学习、情景化学习等多种学习情境,实现个性化学习、差异化教学、精准化评价、数据驱动化管理。
五是人机交互的多模态性。教育数据是外在表现数据与情感、认知、技能等内在机理数据的统合(牟智佳,2020),教育大语言模型应当具备图片、音频、视频等多模态教育数据的识别和融合能力,推动人形教育机器人、数字孪生等前沿教育技术辅助教学,揭示深层次教育规律,促进教育公平。
六是用户使用的易用性。通用大语言模型通常需要利用较为精准的提示语来输出高质量的内容。教育大语言模型能对不同层级用户的认知水平、信息素养等进行充分考量,并从训练数据和模型架构两个层面,降低提示语、上下文等外部因素对输出内容的影响。
上述特征是教育大语言模型的理想特征,受限于教育大数据建设、计算能力和技术发展瓶颈等因素,现有的教育大语言模型可能还无法囊括上述全部特征,但其依旧是教育大语言模型未来应当遵循与发展的目标。未来应当在教育大语言模型构建流程的基础上,不断开展教育场景的适应性拓展。
三、教育大语言模型构建流程
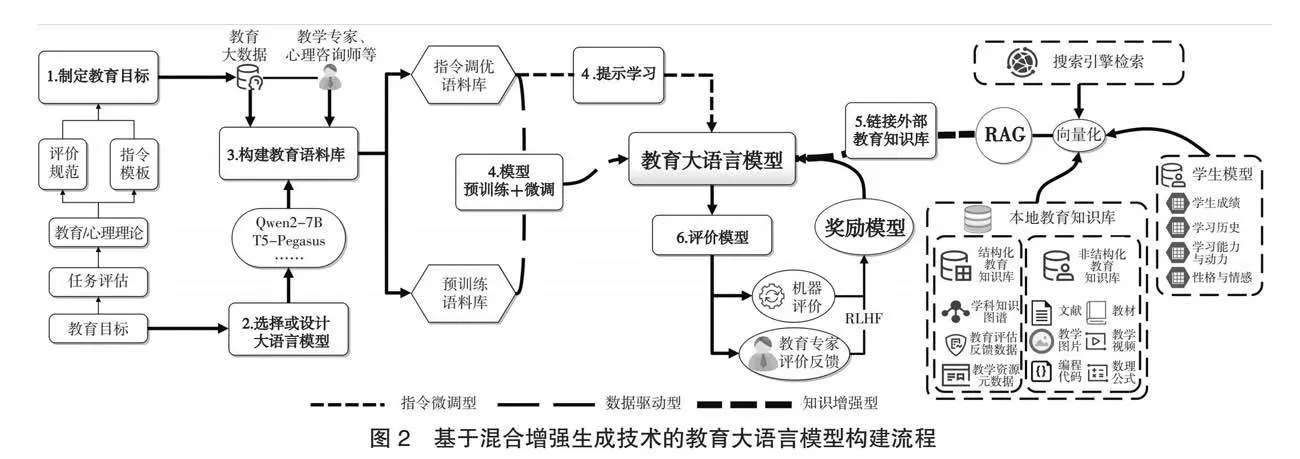
基于教育大语言模型的内涵与特征,本研究提出基于混合增强生成技术的教育大语言模型构建流程。其中,混合增强生成技术是指在“人在回路”设计理念指引下,与一线教师协同增强大语言模型生成内容的安全性以及反馈信息的教育价值性,并利用检索增强生成技术解决大语言模型中教育领域知识不足,进而提升知识结构全面性的方法。教育大语言模型开发的每个阶段都需开发者、一线教师、专家、学生和家长的协同参与,以增强用户对模型的信任度。模型构建流程包括制定教育目标、选择或设计大语言模型、构建教育语料库、开展模型训练或提示、链接外部教育知识库、评价模型等6个步骤。其逻辑关系与主要内容如图2所示。
1.制定教育目标,预设模型构建标准与技术范式
该环节是开发教育大语言模型的预备工作,也是区别于通用大语言模型构建的核心流程,主要包含教育目标预设、教育/心理理论挖掘、评价规范与指令模板构建等流程。在教育目标预设层面,需要进行用户需求的教育痛点分析、潜在使用场景分析、“合规性”与“可行性”分析以及构建深度确定。首先,开发团队要基于对用户的研究或数据分析,挖掘具体的教育痛点、对应需求与潜在使用场景,进而确定具体的教育目标。其次,确认模型构建的合规性,如是否有政策或法规的限定或支持,应用对象是否涉及相关法律法规或学术伦理的限制。再次,评估模型构建的可行性,如现有教育大数据是否完备、开发人员现有技术水平能否保障、硬件与资金投入是否充足、教育领域专家能否支持开发全程的咨询与价值观对齐工作等。最后,依据上述决策内容,确定构建的大模型类型,是指令微调型、数据驱动型还是知识增强型的教育大语言模型。教育/心理理论挖掘是指根据教育目标,选择合适的教育学或心理学理论,来指导教育大语言模型生成内容逻辑与价值理性的过程,如选用苏格拉底产婆术理论来指导启发式对话任务。评价规范是指开发团队在教育/心理理论指导下,构建教育大数据评估指标体系、语言合规性过滤标准和教育大语言模型生成内容人工评价标准等,进而保障生成内容的安全性和教育场景的适应性。指令模板是指在开发团队根据目标任务的实际需求,遵循理论规范,构建教育语料库标准化表达的模板,如基于布鲁姆认知分类法则构建的面向高阶认知对话活动的微调指令语料库模板。
2.选择或设计大语言模型基座,对齐教育任务属性
基座大语言模型的选择或设计是构建教育大语言模型的基础。当前主流的教育大语言模型均通过选择通用大语言模型开展指令微调或“预训练+微调”,少部分教育科技企业在自主设计大语言模型的基础上进一步构建了教育大语言模型。在设计大语言模型层面,需充分考虑教育目标任务的特征,开展基础架构选择与结构拓展。基础架构的选择应与大语言模型的四大技术路线相照应。例如,诸如MOOC情感分类等轻量级理解型教育任务宜选择BERT类自编码型大语言模型架构,人机对话、科学推理等有条件生成型教育任务宜选择LLaMA、Qwen等GPT类自回归型大语言模型架构,文本摘要、机器翻译等多语言无条件生成型任务宜选择mT5、BART等序列转序列型大语言模型架构,而融合上述多种教育任务的则可以选择ChatGLM、ERNIE等GLM类自回归空白填充型大语言模型架构。结构拓展需根据教育任务需求在基础架构上进行拓展,如有多模态输入任务的应当考虑在编码阶段增加多模态融合、一致性对齐和多层次学习表示等的结构设计。在选择大语言模型层面,应当从教育目标的任务类型与大语言模型技术路线和细粒度特征对齐两个视角进行选择,如可以选择ChatGLM3、mT5、FireFly-Qwen、Alpaca-LoRA等。
3.构建教育语料库,实现无序数据的教育价值转向
要训练出高性能的教育大语言模型,需要从数据的采集来源和预处理方法两个方面着手。在采集来源方面,要重点关注无监督的通用型数据集和有监督的特定任务型数据集。通用型数据集主要是指大规模、易获取和多样性强的开放教育语料库,主要包括中小学和高等教育教材和相关学科书籍、教育政务网站、期刊文献数据库、MOOC论坛对话、代码库、古诗词等。例如,大规模中文对话数据集BELLE包含了约80万条多轮对话的开源数据,School Math包含了约25万条中文数学题及解题过程的数据(Ji et al.,2023)。特定教学任务型数据集主要是指为了提升教育大语言模型在特定教学场景(如教学反馈、心理辅导等)下的垂直能力而自主构建或开源的领域语料库、对话数据集和人类指令集等。例如,EduChat为增强其情感支持、对话式教学、写作评价功能,构建了中文情感支持数据集ESConv-zh、对话教学语料库和写作评价语料库(Köpf et al.,2023)。在预处理方法层面,首先要基于第一个环节中指定的评价规范,结合教育专家的建议,对教育大数据开展质量过滤、去重、隐私去除、分词等流程(Zhao et al.,2023);其次要依据预设的指令模板对教育数据集进行整理与统一表达,如将传统问答语料库转换为苏格拉底式对话语料库,实现由传统数据集向安全、具有特定教育价值的语料库转换。
4.开展模型训练或提示,获得教育任务通用和细粒度知识
预训练与指令微调或提示学习是教育大语言模型获得任务能力的核心步骤。在指令微调型教育大语言模型构建流程中,可以开展提示学习。提示学习克服了微调的高成本劣势,使得大语言模型在不显著改变其结构和参数的条件下,通过输入“提示”文本,即可增强模型的泛化能力。在概念上,提示是一种输入形式,用于指示教育大语言模型在执行特定教育任务时应该采取什么行动或生成什么输出。在实现方式上,当前的提示学习主要有情境学习提示和思维链提示两类技术路径,前者主要通过问题描述、问答样本和问题来提示大语言模型,后者在问答样本中涉及推理步骤。在实际效果上,提示学习可以方便地提供最新的知识,降低训练计算成本,同时少量样本的提示学习效果也更优于传统微调(Adigwe et al.,2023)。因此,在应用策略上,针对BERT、T5等轻量级和重量级的大语言模型可以采用微调,而针对如GPT-3.5-Turbo、GPT-2等超重量级大语言模型则可以考虑采用提示学习策略(刘明等,2023)。
在数据驱动型和知识增强型教育大语言模型构建流程中,需要开展基于“预训练+微调”的双阶段训练过程。在预训练层面,需要引入无监督的、中文教育场景的大规模通用数据集进行预训练,让大语言模型获得解决教育领域任务的通用能力。在微调层面,需要根据教育目标,细分任务需求,再引入指令微调流程,让教育大语言模型再获得特定的下游任务能力。通过微调后的大语言模型可以更好地适配到具体的教育目标中。当前,大语言模型领域主要有指令微调和对齐微调两类微调方法。其中,指令微调需要先构建具有“描述—(解释—输入)—输出”格式的实例集,然后以有监督方式进行微调,实例的格式设计和合理的数量增量可以提升大语言模型在教育目标中的泛化能力。对齐微调主要是为了降低教育大语言模型的虚假信息、认知冲突等有害信息而进行的微调。教育大语言模型中的对齐微调主要体现为,融合“人在回路”理念的强化学习,构建奖励模型,实现模型输出内容与人类价值观的对齐。
5.链接外部教育知识库,灵活扩展模型知识和学生模型
知识检索增强环节是知识增强型教育大语言模型构建的必要环节,是保障教育大语言模型缓解外部教育知识局限性、降低反馈幻觉、及时更新知识和实现个性化学习的外包服务,主要包括构建本地教育知识库、学生模型和搜索引擎检索三类方法。三类方法均包含知识检索和提示语注入两个步骤,其中构建本地教育知识库和学生模型两类方法中还包含教育知识准备、学生模型构建、知识入库三个前置步骤。具体而言,教育知识准备是指收集外部教育知识数据并进行向量化的过程,其可被划分为结构化和非结构化教育知识两类。结构化教育知识是指学科知识图谱、教育评估反馈数据、教学资源元数据等具有标准化格式、有清晰数据属性定义、可供人和计算机高效访问的教育数据。非结构化教育知识是指教师上传的课程文档、文献、教材、教学多媒体资源、编码代码和数理公式等未设定数据模型或进行预定义排序的教育数据。学生模型是提升教育大语言模型个性化能力的基础设置,本质上它是一个存储学习成绩、学习历史、学习能力、性格与情感等数据的教育知识库,其通过一定的数据过滤、关键信息提取、分块、格式化规范,可形成结构化和非结构化两类离线教育知识集,随后可根据文本特征选择嵌入模型(如ERNIE-Embedding、BGE等),并将知识集中的文本数据转化为向量矩阵。知识入库是指将离线教育知识集进行向量化后,建立索引,写入并构建离线教育知识库的过程。知识检索主要是指根据教育用户的提问和历史对话数据,在离线教育知识库或搜索引擎中挖掘与提问或历史对话最相关知识的过程。提示语注入是指将知识检索环节挖掘到的最相关知识作为指令加入提示语的过程,并通过将组合后的指令输入教育大语言模型,实现输出效果的优化。
6.评价教育大语言模型,让模型“懂人理”
完成教育大语言模型的构建后,则需要评估、比较大语言模型的性能并更新奖励模型。教育大语言模型主要有两种评估方式:机器评价与人工评价。在机器评价方面,主要考察BERTScore和DialogRPT两个评价指标(Dan et al.,2023)。其中,BERTScore是指通过比较评价数据集(如C-Eval、GAOKAO等)中的目标文本与教育大语言模型生成的文本之间的余弦相似度,并对生成的精准度、召回率和F1 Score等数据进行类比。DialogRPT主要用来评估模型生成文本的流畅度,相关参数包括updown、human_vs_rand、human_vs_machine和final(average & best)。在人工评价方面,需要依据在制定教育目标环节构建的评价体系进行,其包括课程知识回答正确率计算、满意度和安全性评估方法、教育专家或教育大语言模型受众问卷调查模板或访谈提纲、机器与专家反馈模板的相似度计算、机器对用户提问的理解程度评价方法和机器生成内容的教育价值评价体系等。其次,基于机器评价和人工评价结果,对教育大语言模型开展置信度评估,对置信度较低的环节进行二次训练与开发,例如根据用户反馈对教育语料库进行重新设计,对基座大模型的选择、设计方法甚至预训练和微调方法进行策略调整。最后,需要收集高质量的教育专家评价反馈数据,采用排序、问题约束、基于规则等方法对数据进行清理,调用基于人类反馈的强化学习算法(如近端策略优化算法PPO、自然语言策略优化算法NLPO)构建奖励模型,对模型输出结果进行优化和过滤,使得教育大语言模型的输出结果更好地与人类价值观对齐(Zhao et al.,2023)。
四、教育大语言模型应用案例
基于教育大语言模型的技术范式,已有研究者在不同范式下将教育大语言模型应用到教育领域,并取得了一定的效果。笔者将从编程、课后阅读和计算机教育三类教学场景呈现教育大语言模型赋能学生计算思维、提问能力和编程技能等高阶能力和学科基本能力提升的应用案例。
1.编程教学场景下指令调优型教育大语言模型培养学生计算思维能力
计算思维是智慧教育时代学生需要具备的最为重要的核心素养之一,如何在科学、编程等教学中系统地开展计算思维教学,成为学校应对未来挑战和培养未来人才的关键路径(陈鹏等,2023)。有学者首先基于计算思维理论框架与支架式教学理论,构建了基于ChatGPT提示微调的智能编程支架学习大语言模型,其包含解决方案评估、代码评估与自主对话三大功能模块以及对应的多轮对话提示语模板,并基于GPT-3.5 API进行调优。其次基于理论框架与教育大语言模型,构建了智能编程支架学习系统,并在S大学教育技术学专业课程中开展了为期一个学期的教学实验,44名大二学生被随机分配到实验组(使用该系统开展编程学习)和对照组(在传统的教师指导模式下开展教学)。通过学期始末的计算思维能力测验对照与期末的编程学习系统接受度问卷调查,结果表明实验组学生在编程能力测验中的平均得分高于对照组学生,大部分学生对该编程系统持积极态度,且相较于传统教学模式,该智能编程支架学习系统能有效提升学生的计算思维能力;但研究还发现该系统以及调优后的模型在理解学生复杂需求的准确性上仍存在不足(廖剑等,2024;Liao et al.,2024)。
2.课后阅读场景下数据驱动型教育大语言模型培养学生提问意识与阅读能力
提问意识与能力是批判性思维、问题解决能力等核心素养的重要构成要素,其与阅读理解能力有着显著的相关性。针对传统阅读理解教学中普遍存在的提问少、水平低、层次浅等问题,有学者构建了面向阅读理解教学场景下学生自主提问的教育大语言模型Co-Asker。该模型基于T5-Pegasus 275M基座,使用开源中文维基百科数据集进行预训练,并利用中文阅读理解数据集和中医药问答语料库进行微调。研究还构建了人机协同问题共创系统,并在某大学智慧教育通识课程中开展教育实验。结果表明,Co-Asker可以产生高质量的类人化问题,激发学生的提问兴趣和投入度,加深学生对浅层次阅读内容的理解。但研究也发现,该系统难以产生能启发学生深层次思考的深度问题,且可能会引起部分学生在学习任务中对问题生成功能的过度依赖,同时也存在模型的大规模参数与数据的量级导致智能提问模型的训练时间与经济成本消耗过高等问题(Liu & Zhang et al.,2024)。
3.计算机教育场景下知识增强型教育大语言模型提升学生编程技能
如何开展融合通识与专业的计算机教育课程是提升学生计算思维和数字化能力的关键。有学者在哈佛大学计算机科学导论课程项目平台CS50中,为了实现对学生在线课程学习的“一对一”指导,增设了智能化编程教学指导工具。该工具以GPT-4作为基座模型,引入检索增强技术,将课程讲授内容以30秒为时间窗口进行分割,并逐一使用OpenAI的文本嵌入模型进行向量化并存储于ChromaDB向量数据库中。之后该模型会根据学生的输入,在向量数据库中查询讲座片段,最后将最相关的内容整合在提示语中,由此实现解释代码片段、修改代码风格、课程查询等功能,并降低GPT-4模型的幻觉现象。将该工具应用于参与CS50课程项目的70名学生中,通过学生反馈和专家验证回应的准确性发现,该工具在指导学生开展具有挑战性的问题上是有效且可靠的,同时其回应的课程知识的正确率达到88%(Liu & Zenke et al.,2024)。然而,由于微调语料库的缺失,此模型也存在反馈质量不稳定的问题,且忽略了人机协同教学设计的作用。
五、教育大语言模型的实施挑战与应对策略
1.语料库与知识库的构建缺乏统一的标准,需多方合力共建
教育大语言模型具有的知识全面性和反馈信息的教育价值性,其本质是由预训练或微调语料库的完备性及其教育性决定的;而教育需求和问题响应个性化的实现则取决于检索增强生成的外部教育知识库中学生模型知识库的构建。从数据要素视角来看,当前制约教育大语言模型发展的主要因素有两个:一是非结构化、多模态问答语料库的缺乏(邢蓓蓓等,2016),二是具有特定教育价值的指令调优语料库和学生模型数据库建设标准的缺失。
针对上述问题,可以从数据建设生态和统一标准构建两个角度进行应对。针对数据建设生态问题,可从宏观、中观和微观三个视角构建应对策略。在宏观治理层面,政府与教育部门应推动教育大语言模型基础设施和公共训练数据资源平台建设,重视非结构化教育过程数据的挖掘与治理。同时,可依托政府背书、科技企业联动、学校或研究院带动与智慧教育专家指导的模式,以教育数据开源倡议、开放数据竞赛等形式(如BEA竞赛),带动学生与从业者共同参与教育领域数据的构建、挖掘与治理,从而形成高质量教育数据建设的新生态。在中观学校层面,应构建更加完备的非结构化数据服务与管理基础设施,标准化数据接口,形成全域协同的数据共创机制,实现不同部门与业务流程的知识库的流通与融合,由此既可为构建“校园百事通”奠定数据基础,也可为服务区域和国家教育数字化转型奠定良好条件。在微观开发团队层面,可以通过反向翻译法,将公开的英文教育数据集(如OpenAssistant问答数据集、ESConv英文心理咨询数据集)进行翻译,扩充中文教育数据集范围。在教育大语言模型指令调优和学生模型标准建设方面,应联同教育学、学习科学、心理学和自然语言处理领域的专家,从学科教学、启发式问答等方面开展语料库构建的标准化格式与规范制定,并从基本信息、内容偏好、学习风格、平时表现等方面开展学生模型知识库的结构与数据标准设计。
2.模型结构的多模态理解缺陷和计算困境凸显,亟须尝试应用新的技术
当前,高等学校科研团队独立开展教育大语言模型研究,主要面临两大核心挑战:一是已有教育大语言模型在选用基座模型的输入嵌入、注意力机制等方面时对多模态的理解能力不足;二是大语言模型庞大的参数规模对算力的需求很大,导致教育大语言模型的训练和推理时间与硬件成本居高不下。在保持现有计算技术条件下,亟须尝试应用新的技术。
针对模型结构的多模态理解缺陷问题,可以考虑引入视觉语言模型,或在输入嵌入层面引入图片、文本、知识图谱等多模态数据一致性对齐嵌入模型,并在注意力机制部分引入交叉注意力机制、局部注意力机制等,进而提升大语言模型的多模态理解能力。针对算力需求困境问题,可以从训练策略调整和降低模型复杂度两方面着手。在训练策略调整方面,可以尝试使用分布式云计算策略,通过腾讯云HCC、百度智能云千帆大模型平台构建高性能计算集群,进而降低教育大语言模型构建的门槛与时间成本。在降低模型复杂度方面,可以基于知识蒸馏技术,构建诸如EduDistilBERT一类的“教育小模型”(Clavié et al.,2019),在最大程度保留教育大语言模型性能的同时,压缩模型的复杂度,进而降低教育大语言模型的推理成本。
3.教育大语言模型与高阶教育目标匹配难,亟待深入探索人机协同教学机制
教育大语言模型中指令调优类模型在复杂教育情境下存在理解能力不足的问题,数据驱动型与知识增强型模型虽在特定教育任务下的回应具有适应性且准确率较高,但在已有的学习活动设计中,教育大语言模型多以“喂养型”人机会话形式向学生传授知识,尽管这在一定程度上能提升学习效率,降低教师压力,但也可能让学生产生惰性依赖,难以在学习效果提升、高阶思维能力培养等方面实现可持续发展。
解决上述问题需要深度探索融合教育大语言模型的人机协同教学机制。一方面,在机器智能层面,教育大语言模型应当在苏格拉底对话理论、协作知识建构理论等高阶学习理论与支架指导下形成高质量语料库,并开展预训练与微调,同时结合外部知识,让教育大语言模型在学习活动中充分发挥作为协作、启发、反思等高阶思维活动的引导者和师生外部知识拓展的认知大脑。此外,教育大语言模型应当与教育机器人、虚拟代理和数字孪生等技术进行深度融合,实现物理与虚拟空间中认知中枢的构建与信息的具身贯通。另一方面,在人类智慧方面,教师需充分发挥其教学智慧,探索教育大语言模型赋能高阶认知学习活动的实践路径,将教育大语言模型的技术、人机交互特征与教学活动要素进行关联映射,进而动态把握教学过程,实现差异化角色设计,并在正确的人机协同学习观引导下规范学生学习动机与行为,继而通过对教学实践的反思与反馈进一步反哺教育大语言模型。
在大语言模型等智能技术赋能教育数字化转型的热潮下,本研究从教育大语言模型的内涵与特征入手,梳理并总结了教育大语言模型的主要构建流程,并对实际开发中可能存在的问题与挑战提出了应对之策,以期为大语言模型赋能教育发展提供参考。当下教育大语言模型主要聚焦教育目标任务指导下的数据、模型等教育基础设施建设方面的研究,未来将会涌现更多以育人为核心要义的教育大语言模型。此类大语言模型在基础能力上更关注对多模态知识的理解,其不仅具有强大的教育目标任务生成能力,更能够以“教育智能体”的形态融入教育机器人双师教学、虚拟现实学习环境下的虚拟教育代理,并以更加高阶的人机协同角色适应更多教育场景,从而赋能教师专业发展和学生成长。
参考文献:
[1]陈鹏,王晓,杨姝等(2023).可视化编程能有效促进K12学生的发展吗——基于SSCI期刊39项实验和准实验的元分析[J].现代远程教育研究,35(4):102-112.
[2]戴岭,胡姣,祝智庭(2023).ChatGPT赋能教育数字化转型的新方略[J].开放教育研究,29(4):41-48.
[3]方略研究院(2024).高教管理与研究平台[EB/OL]. [2024-04-08].https://www.squarestrategics.com/publicize.
[4]焦建利(2023).ChatGPT:学校教育的朋友还是敌人?[J].现代教育技术,33(4):5-15.
[5]乐惠骁,汪琼(2022).人机协作教学:冲突、动机与改进[J].开放教育研究,28(6):20-26.
[6]李海峰,王炜,李广鑫等(2024).智能助产术教学法——以“智能苏格拉底会话机器人”教学实践为例[J].开放教育研究,30(2):89-99.
[7]廖剑,许邯郸,刘明等(2024).数智分身:人工智能时代教师本位人机共教模式[J].现代远程教育研究,36(4):85-93.
[8]刘明,吴忠明,廖剑等(2023).大语言模型的教育应用:原理、现状与挑战——从轻量级BERT到对话式ChatGPT[J].现代教育技术,33(8):19-28.
[9]牟智佳(2020).多模态学习分析:学习分析研究新生长点[J].电化教育研究,41(5):27-32,51.
[10]王丽,李艳,陈新亚等(2023).ChatGPT支持的学生论证内容评价与反馈——基于两种提问设计的实证比较[J].现代远程教育研究,35(4):83-91.
[11]新华社(2022).高举中国特色社会主义伟大旗帜 为全面建设社会主义现代化国家而团结奋斗——在中国共产党第二十次全国代表大会上的报告[EB/OL].[2023-09-12].https://www.gov.cn/xinwen/2022-10/25/content_5721685.htm.
[12]邢蓓蓓,杨现民,李勤生(2016).教育大数据的来源与采集技术[J].现代教育技术,26(8):14-21.
[13]徐晓艺,陆祎(2024).生成式人工智能助力初中英语写作教学的实践探究[J].中小学英语教学与研究,(4):49-53.
[14]翟雪松,许家奇,童兆平等(2023).人工智能赋能高校韧性教学生态的路径研究[J].中国远程教育,43(1):49-58.
[15]中华人民共和国教育部(2024).统筹推进教育科技人才体制机制一体改革[EB/OL].[2024-08-05].http://www.moe.gov.cn/jyb_xwfb/gzdt_gzdt/moe_1485/202407/t20240722_1142
212.html.
[16]祝智庭,胡姣(2022).教育数字化转型的实践逻辑与发展机遇[J].电化教育研究,43(1):5-15.
[17]Adigwe, A., & Yuan, Z. (2023). The ADAIO System at the BEA-2023 Shared Task: Shared Task Generating AI Teacher Responses in Educational Dialogues[C]// Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023). Toronto, Canada: Association for Computational Linguistics:796-804.
[18]Bulathwela, S., Muse, H., & Yilmaz, E. (2023). Scalable Educational Question Generation with Pre-Trained Language Models[C]// Wang, N., Rebolledo-Mendez, G., & Matsuda, N. et al. Artificial Intelligence in Education. Cham: Springer Nature Switzerland:327-339.
[19]Clavié, B., & Gal, K. (2019). EduBERT: Pretrained Deep Language Models for Learning Analytics[EB/OL]. [2023-09-12]. http://arxiv.org/abs/1912.00690.
[20]Dan, Y., Lei, Z., & Gu, Y. et al. (2023). EduChat: A Large-Scale Language Model-Based Chatbot System for Intelligent Education[EB/OL]. [2023-09-14]. http://arxiv.org/abs/2308.02773.
[21]Jagmohan, A., & Vempaty, A. (2023). Merlyn Mind’s Education-Specific Language Models[EB/OL]. [2023-09-12]. https://www.merlyn.org/blog/merlyn-minds-education-specific-
language-models.
[22]Ji, Y., Deng, Y., & Gong, Y. et al. (2023). Exploring the Impact of Instruction Data Scaling on Large Language Models: An Empirical Study on Real-World Use Cases[EB/OL]. [2023-09-12]. http://arxiv.org/abs/2303.14742.
[23]Köpf, A., Kilcher, Y., & von Rütte, D. et al. (2023). OpenAssistant Conversations - Democratizing Large Language Model Alignment[EB/OL]. [2023-09-14]. http://arxiv.org/abs/2304.07327.
[24]Liao, J., Zhong, L., & Zhe, L. et al. (2024). Scaffolding Computational Thinking with ChatGPT[J]. IEEE Transactions on Learning Technologies, 17:1-15.
[25]Liu, M., Zhang, J., & Nyagoga, L. M. et al. (2024). Student-AI Question Cocreation for Enhancing Reading Comprehension[J]. IEEE Transactions on Learning Technologies, 17:815-826.
[26]Liu, R., Zenke, C., & Liu, C. et al. (2024). Teaching CS50 with AI: Leveraging Generative Artificial Intelligence in Computer Science Education[C]// Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1. New York, NY, USA: Association for Computing Machinery:750-756.
[27]Snyder, C., Hutchins, N. M., & Cohn, C. et al. (2024). Analyzing Students Collaborative Problem-Solving Behaviors in Synergistic STEM+C Learning[C]// Proceedings of the 14th Learning Analytics and Knowledge Conference. New York, NY, USA: Association for Computing Machinery:540-550.
[28]Taylor, R., Kardas, M., & Cucurull, G. et al. (2022). Galactica: A Large Language Model for Science[EB/OL]. [2024-04-01]. http://arxiv.org/abs/2211.09085.
[29]Zhao, W. X., Zhou, K., & Li, J. et al. (2023). A Survey of Large Language Models[EB/OL]. [2023-09-12]. http://arxiv.org/abs/2303.18223.
[30]Zhao, Z., Ma, D., & Chen, L. et al. (2024). ChemDFM: Dialogue Foundation Model for Chemistry[EB/OL]. [2024-04-10]. http://arxiv.org/abs/2401.14818.
收稿日期 2023-11-13 责任编辑 刘选
The Essence, Development and Challenges of Educational Large Language Models
LIU Ming, WU Zhongming, YANG Xiao, GUO Shuo, LIAO Jian
Abstract: Since the generalized Large Language Models(LLMs) can only provide generalized feedback, which is difficult to match with complex educational scenarios, there is an urgent need to build Educational Large Language Models(ELLMs). ELLMs are characterized by the comprehensiveness of the educational knowledge bases(EKB), the security of the teaching content generation, the educational nature of the feedback value, the personalization of the problem solving, the multimodal nature of the human-computer interaction, and the ease of use for the users. There are six steps to construct ELLMs: formulating educational goals, selecting or designing a LLM base, constructing educational corpuses, model training or prompt learning, linking to external EKB, evaluating ELLMs. As far as the application of ELLMs is concerned, existing studies have been applied to programming, after-school reading and computer education, and have explored the enhancement of higher-order competencies and the basic disciplinary competencies that ELLMs empower students. For the future ELLMs, it is necessary to make multi-party efforts to build corpuses and EKB to unify the standards, consider the technological shift, and explore the mechanism of human-computer collaborative pedagogy.
Keywords: ELLMs; Generative Artificial Intelligence; Artificial Intelligence in Education; Knowledge Augmentation
