基于多智能体深度强化学习的车联网资源分配方法
2024-09-19孟水仙刘艳超王树彬
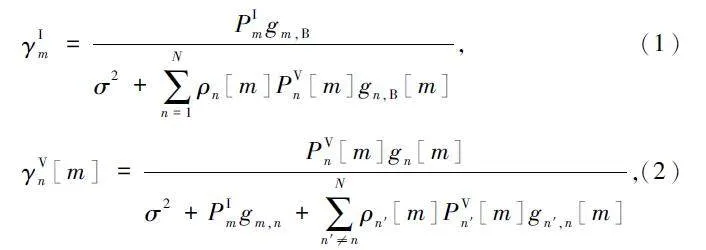


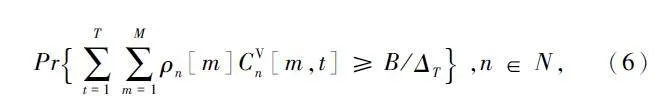



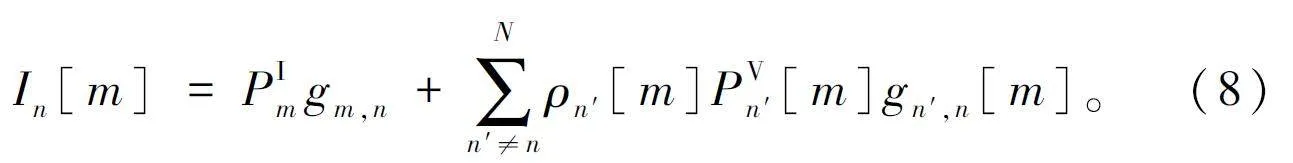

摘 要:在车联网中,合理分配频谱资源对满足不同车辆链路业务的服务质量(Quality of Service,QoS) 需求具有重要意义。为解决车辆高速移动性和全局状态信息获取困难等问题,提出了一种基于完全分布式多智能体深度强化学习(Multi-Agent Deep Reinforcement Learning,MADRL) 的资源分配算法。该算法在考虑车辆通信延迟和可靠性的情况下,通过优化频谱选择和功率分配策略来实现最大化网络吞吐量。引入共享经验池机制来解决多智能体并发学习导致的非平稳性问题。该算法基于深度Q 网络(Deep Q Network,DQN),利用长短期记忆(Long Short Term Memory,LSTM) 网络来捕捉和利用动态环境信息,以解决智能体的部分可观测性问题。将卷积神经网络(Convolutional Neural Network,CNN) 和残差网络(Residual Network,ResNet) 结合增强算法训练的准确性和预测能力。实验结果表明,所提出的算法能够满足车对基础设施(Vehicle-to-Infrastructure,V2I) 链路的高吞吐量以及车对车(Vehicle-to-Vehicle,V2V) 链路的低延迟要求,并且对环境变化表现出良好的适应性。
关键词:车联网;资源分配;多智能体深度强化学习;深度Q 网络
中图分类号:TN929. 5 文献标志码:A 开放科学(资源服务)标识码(OSID):
文章编号:1003-3016(2024)06-1388-10
0 引言
随着通信技术的飞速发展,车联网作为物联网中车辆通信网络的新范式,对提升交通服务的安全性和舒适性起着日益重要的作用[1]。其中,蜂窝车联网(Cellular Vehicle-to-Everything,C-V2X)通信技术实现了车辆与车辆、车辆与基础设施、车辆与行人以及车辆与互联网之间通信的无缝连接,为车联网提供了全方位的通信技术支持[2]。C-V2X 通信技术主要通过支持车对基础设施(Vehicle-to-Infra-structure,V2I)和车对车(Vehicle-to-Vehicle,V2V)2 种通信模式为不同服务质量(Quality of Service,QoS)需求提供不同的应用服务[3]。其中,V2I 通信主要应用于提供高数据传输速率的非安全相关的应用服务,而V2V 通信则专注于实现低延迟和高可靠性的实时信息传输[4-5]。然而,面对网络资源的稀缺性以及车联网中服务类别的多元化,如何实现V2I 和V2V 链路之间的协同资源共享以保证CV2X 网络资源的有效利用是车联网资源分配时面临的巨大挑战。
目前,车联网中的资源分配问题已得到广泛研究,文献[6-8]采用传统优化算法来解决这一问题。然而,随着无线网络多样性和复杂性的增加,这些传统算法面临着严峻的挑战,例如,车联网环境的动态不确定性使得实时获取信道状态信息变得困难。同时,由于车联网用户具有不同的服务需求,构建的优化问题和约束条件通常是非凸的,这使得优化算法在求解时容易陷入局部最优解[9]。因此,如何设计一个更智能、更灵活的资源分配算法成为车联网中的一个重要问题。
随着人工智能技术的不断进步,深度强化学习(Deep Reinforcement Learning,DRL)在无线通信领域得到了广泛应用。与传统的优化算法相比,DRL展现出更强大的解决复杂问题的能力。通过与未知环境的交互,DRL 能够学习如何做出最优决策,以最大化长期累积回报。此外,针对一些难以通过传统算法优化的目标,DRL 可以通过设计相应的训练奖励来解决。因此,DRL 为解决车联网中资源分配问题带来了全新思路。文献[10]研究了设备到设备(Device-to-Device,D2D)网络的联合信道选择和功率控制问题,以最大化D2D 网络的加权和速率为目标,提出了一种基于分布式DRL 的算法,并通过仿真结果证明了即使没有全局瞬时信道状态信息,该算法也能有良好的性能表现。文献[3]在包含V2V 链路和V2I 链路的认知车辆网络中应用了一种改进的深度Q 网络(Deep Q Network,DQN)算法来提高频谱利用率。上述算法在静态环境模型上表现良好,但并不适用于动态变化的车联网环境。文献[11]针对V2X 通信资源分配问题,提出了一种使用DQN 进行子频带选择和使用深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)进行发射功率分配的DRL 算法,在此基础上,加入元强化学习来提高算法对动态环境的适应性。但在该算法中,同时训练2 种不同的DRL 算法会增加模型训练的难度,使算法变得更复杂。文献[12]针对不同的QoS 需求,提出了一种基于链路优先级集中式的强化学习频谱资源分配算法,该算法实现了在对一般链路无干扰的情况下,为高优先级链路提供了高质量的通信支持,并且在实际场景中展现了出色的抗噪声性能。但该算法采用的是集中式控制方案,每条链路都需要与基站进行信息交互,增加了通信开销和传输时延。文献[13 -15]都采用基于DQN的多智能体深度强化学习(Multi-Agent Deep Rein-forcement Learning,MADRL)算法来解决车联网环境中的资源分配问题,然而,这些算法均未考虑多个智能体同时探索学习所引发的非平稳性问题,而这一问题将直接影响算法的收敛速度,从而降低算法的性能。
为解决上述问题,本文提出了一种完全独立的分布式MADRL 的资源分配算法,以进一步提升动态车联网环境下资源共享效率。在该算法中,经过训练和学习的V2V 用户仅依赖局部环境观测值就可以学到最佳资源分配策略,即最优的子信道选择和功率分配策略。为解决多智能体并发学习带来的非平稳性问题,本文引入共享经验池机制,以促进智能体之间更好地合作和学习。为解决每个智能体对环境的部分可观测问题,采用长短期记忆(LongShort Term Memory,LSTM)和卷积神经网络(Convo-lutional Neural Network,CNN)结合的残差网络(Re-sidual Network,ResNet)跳跃连接结构,这种结构使得智能体能够捕捉和利用环境状态信息的时间序列关系,从而提高了算法处理序列数据的能力,同时也增强了算法的泛化能力。最后,通过仿真实验验证了该算法的有效性,确保了在满足V2V 链路延迟约束条件的同时减少了V2V 链路对V2I 链路的干扰。
1 系统模型
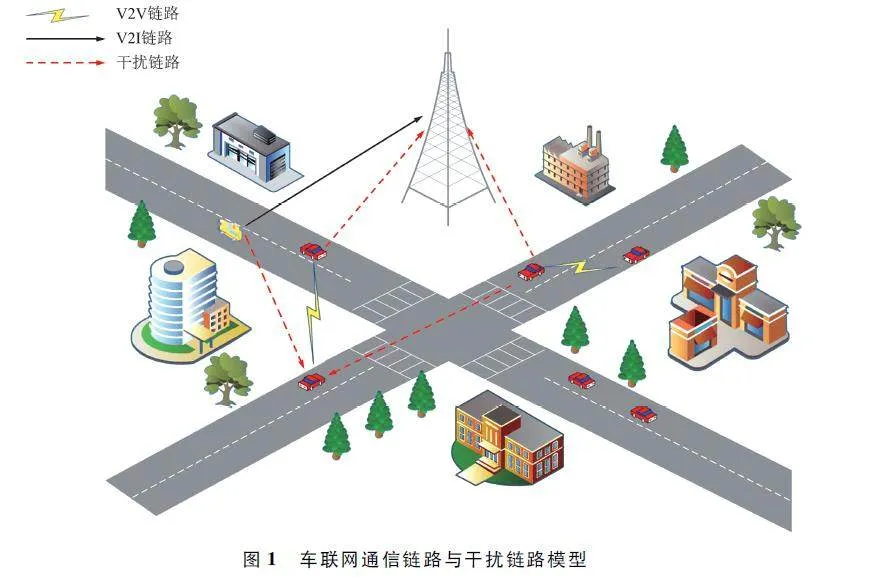
本文考虑拥有一个基站和多辆车构成的城市道路交通的C-V2X 通信场景。在该场景中,具有M 辆车的V2I 链路完成高吞吐量的数据传输任务,而具有N 辆车的V2V 链路实现低延迟、高可靠的实时信息传输任务。本文只考虑V2I 通信的上行链路,并假设所有车辆用户的收发机都采用单天线,此外,假设M 条V2I 链路被预先分配了M 个具有固定发射功率的正交子信道,即第m 条V2I 链路占用第m 个子信道并且这些子信道之间无干扰。为提高频谱利用率,这些子信道可以被V2V 链路重用。考虑到实际情况,V2V 链路的数量往往远大于V2I 链路的数量,为更有效地利用有限的频谱资源,将V2V 链路重用V2I 链路的频谱资源是必要且合理的。因此,本文主要目标是为这些V2V 链路设计一种有效的频谱共享方案,以使这2 种类型的车辆链路以最小的信令开销到达各自的目标。图1 显示了V2V 共享V2I 链路时的通信链路和干扰链路的复杂关系。
当第n 条V2V 链路共享第m 条V2I 链路的子信道时,这条V2V 链路的接收端可能受到来自其他V2V 链路以及V2I 链路的发射端的干扰,而第m 条V2I 链路的接收端会受到来自V2V 链路的干扰,则第m 条V2I 链路与第n 条V2V 链路的信干噪比(Signalto Interference plus Noise Ratio,SINR)分别表示为:
式中:PIm 、PVn[m]和PVn′[m]分别表示第m 条V2I 链路、第n 条V2V 链路和除n 以外的其他V2V 链路(如n′)的发射功率,σ2 表示噪声功率,ρn [m]、ρn′[m]表示第n 和n′条V2V 链路是否重用第m 条V2I 链路,如果重用,其值为1,否则值为0;gm,B 表示第m 条V2I 链路的信道功率增益,gn,B [m]表示V2V 链路n 对V2I 链路m 的干扰信道增益,gn [m]表示第n 条V2V 链路的信道增益,gm,n 表示V2I 链路m 对V2V 链路n 的干扰信道增益,gn′,n [m]表示其他V2V 链路n′对V2V 链路n 的干扰信道增益。发射功率计算公式为:
g = αh, (3)
式中:α 表示与频率无关的大尺度衰落,即阴影衰落和路径损耗;h 表示与频率相关的小尺度衰落信道增益。对于信道衰落,本文同时考虑大尺度和小尺度衰落,并假设信道衰落在一个子信道内大致相同并且在不同子信道之间相互独立。由此,第m 条V2I 链路和第n 条V2V 链路的信道总吞吐量分别为:
CIm = W lb(1 + γIm ), (4)
CVn[m] = W Ib(1 + γVn[m]), (5)
式中:W 为信道带宽。
如上所述,本文的目标是在提高V2I 链路的总吞吐量的同时,满足V2V 链路低延迟、高可靠的实时数据传输的要求。为此本文定义在一定时间限度内,成功传输有效载荷的概率为:
式中:B 表示在每个周期T 内生成的V2V 链路传输载荷的大小,单位为bit;ΔT 表示信道相干时间。
综上所述,本文研究的车联网中资源分配问题可以描述为:在V2V 链路中,如何智能地重用V2I 的子信道,并选择适当的发射功率进行数据传输,以减少V2V 链路的传输时延,同时减少其对V2I 链路的干扰,即在追求最大化V2I 链路总吞吐量的同时提高V2V 链路的单位时间内载荷成功传输率。
2 算法方案设计
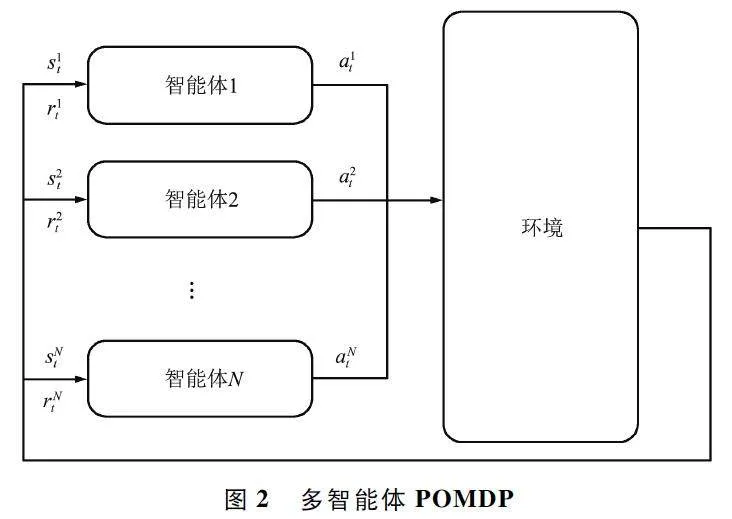
MADRL 是应对车联网中动态不确定性以及全局信道状态信息获取困难的有效方法。在MADRL模型中,多个智能体采取试错的方式不断与环境交互,以获得最大化累积奖励来优化信道选择与功率控制策略。由于V2V 链路中每个用户作为独立智能体无法完全获取信道状态的完整信息,因此采用部分可观察马尔科夫决策过程(Partially ObservableMarkov Decision Process,POMDP)对动态频谱分配和功率选择过程进行建模,该过程由动作、状态和奖励描述。如图2 所示,在t 时刻,获得环境状态snt的V2V 链路n,根据策略做出动作ant,所有V2V 链路的动作同时被执行后,环境状态依据状态转移概率转移到下一时刻的状态snt+1 ,并且每条V2V 链路得到执行各自动作后的奖励rnt。
2. 1 状态空间
V2V 链路用户不能在t 时刻观测到全局环境状态St,而只能获得和自己相关的环境状态snt,并且其他V2V 链路的动作也是未知的。V2V 链路n 占用第m 条V2I 链路传输数据时,该V2V 链路可获得的状态包括V2V 链路n 的信道增益gn[m]、受到其他V2V 链路的干扰gn′,n[m]、对V2I 链路的干扰gn,B [m]以及受到V2I 链路m 的干扰gm,n。则V2V 链路n占用V2I 链路m 传输数据时的关联信道增益表示为:
Gn [m] = {gn [m],gn′,n [m],gn,B [m],gm,n }。(7)
将V2V 链路n 在第m 条V2I 链路传输数据时受到的所有干扰表示为:
此外,为了保证每条V2V 链路在一定的时间限度内完成数据传输任务,将剩余的传输载荷数Bn 和剩余的可传输载荷时间Tn 也考虑进可获得的环境状态内。因此,V2V 链路n 的状态空间表示为:
snt= {Bn ,Tn ,{In [m]}m∈M ,{Gn [m]}m∈M }。(9)
2. 2 动作空间
车联网的资源分配问题可归结为V2V 链路的子信道选择和传输功率控制问题。每条V2I 链路占据被自然分成的M 条不相交的子信道中的一条,N 条V2V 链路可以从这M 个频谱子信道中选择一条链路进行重用并控制发射功率以便进行数据传输。考虑实际电路的限制,本文将功率控制分为4 个级别的离散值,即[23,10,5,-100]dBm。因此,每条V2V 链路的动作空间维度为4×M。
2. 3 奖励函数
在强化学习中,奖励函数起到驱动智能体学习策略的关键作用,通过对智能体采取的策略进行评估,提供相应的奖励或惩罚,帮助智能体在复杂的环境中学会有效决策。本文研究目标是使V2I 链路的总吞吐量最大化和提高V2V 链路的载荷成功传输概率。本质上,这是一个多目标优化问题,本文通过权重系数法将其转化成单目标优化问题。分别将2 个目标函数设置成2 个奖励函数,即在t 时刻,V2I链路吞吐量的奖励函数即为该链路获得的总吞吐量;将t 时刻未完成传输的V2V 用户奖励函数设置为载荷传输速率,对于已完成传输的V2V 用户奖励函数设置为比载荷传输速率更大的常数β,以鼓励V2V 用户提高传输速率。因此对第二个目标的奖励函数设置为:
式中:λ 为权重系数。
强化学习的目标是找到最佳策略π* ,任何状态St 下的智能体都能根据π 做出最优决策,从而最大化期望奖励,即:
式中:γ 是折扣因子,表示未来奖励对当前状态的重要程度。
2. 4 MADRL 法
虽然将MADRL 引入车联网环境来解决资源分配问题的方案优于传统算法,但是仍然面临以下挑战:① 动态变化的车联网环境和环境状态信息部分可观测;② 分布式的多智能体训练方案会影响环境的平稳性从而影响训练过程并削弱算法的性能。为此,本文提出基于MADRL 的完全分布式的多智能体深度循环残差Q 网络(Multi-Agent Deep RecurrentResidual Q Network,MADRRQN)算法,该算法整体框架如图3 所示。
每条V2V 链路作为智能体拥有自己的DQN 并独立训练。智能体从与环境交互到学习过程主要分为动作选择、经验存储和学习3 个阶段。首先,将当前环境状态snt输入到DQN 中的估计网络中,智能体n 根据εgreedy 策略选择动作,即以概率ε 随机采取动作,或以概率1-ε 从估计网络中选择使输出Q 值最大的动作。智能体n 做出动作ant后得到奖励rnt,环境状态变为snt+1 。此时,智能体获得了一条经验(snt,ant,rnt,snt+1 )并将该经验放入经验池中。为解决多智能体分布式训练带来的非平稳性的问题,本文所有智能体共享经验池中的经验。经验池根据容量采用先进先出的存储方式。最后,在学习阶段,从经验池中抽取小批量经验分别输入到估计网络和目标网络中,然后从这2 个网络中输出Q1e(s1t,a1t;θ)和maxa′1tQit(s1t+1 ,a′1t;θ′)并计算损失值:
loss = [rnt+ γ maxa′1tQit(snt+1 ,a′nt;θ′)- Qne(snt,ant;θ)] 2 。(13)
利用反向传播计算的损失值更新估计网络的参数θ,每隔一定时间将估计网络的参数拷贝给目标网络,更新其参数θ′。该过程重复进行并不断优化智能体的行为策略,从而实现最优的动作选择。具体如算法1 所示。
为了避免与环境交互时积累的经验不足导致智能体做出的动作策略陷入局部最优解,有必要权衡利用(使用已知的动作)和探索(学习新的、可能更好的动作)的关系。因此,本文采用自适应的ε-greedy 探索算法,即在算法实现的初始阶段,面对大的状态和动作空间,智能体主要进行新动作和新状态的探索。然后,随着迭代次数的增加,逐渐增加利用概率让智能体根据以往经验做出最佳决策。
ε = εmin + (εmax - εmin )e-ζt, (14)
式中:εmax 和εmin 分别为ε 的最大值和最小值,ζ 为衰减因子。
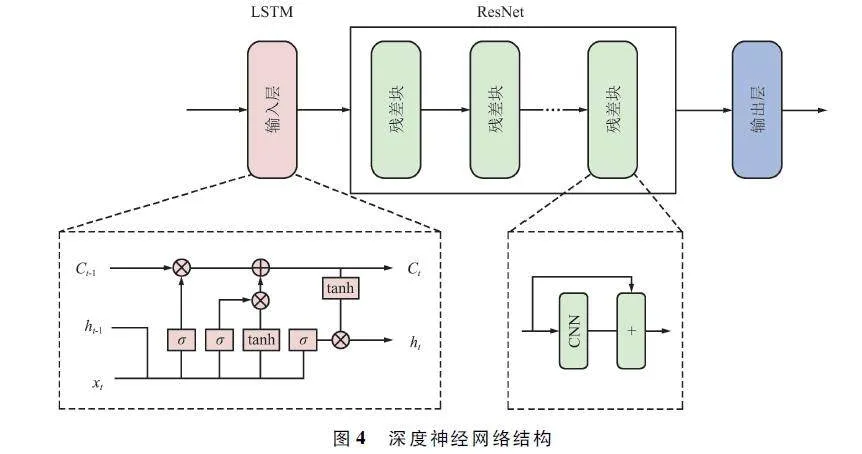
在强化学习中引入深度神经网络的目的是为了有效处理高维度复杂的状态和动作空间。通过深度神经网络的强大学习能力,智能体能够更准确地表示和近似复杂的状态-动作映射关系,从而提高对大量和多样化状态信息的处理能力,进而增强训练和决策的性能。本文提出的深度神经网络结构如图4 所示。
采用LSTM 网络作为深度神经网络的输入层来解决MADRL 的部分可观测问题、提高对序列数据的处理能力以及捕捉长期依赖关系,从而提高模型对动态环境的自适应能力。为了提高模型特征提取能力和预测能力,采用了CNN 的跳跃连接的ResNet结构。
3 仿真结果分析
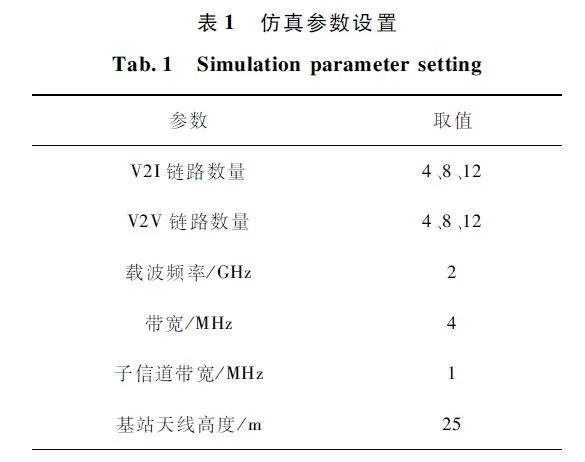
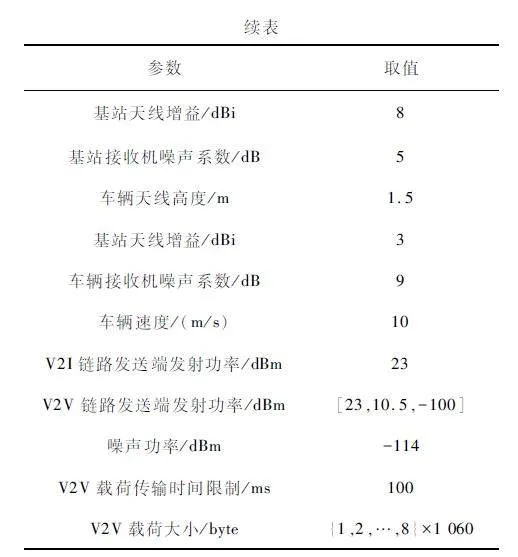
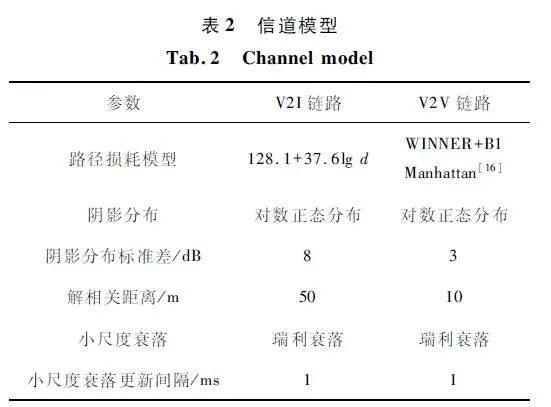
本文车联网仿真场景遵循3GPP TR36. 885[16]中的城市交通道路场景,并遵循设置车联网环境的仿真参数[17-18]。为了便于仿真,将交通场景面积等比例缩小一半。表1 给出了主要仿真参数,表2 给出了V2V 链路和V2I 链路的信道模型。
每个智能体的深度神经网络由一层LSTM 作为输入层和2 个ResNet 连接的3 层CNN 构成,各层神经元都是120 个。使用修正线性单元(RectifiedLinear Unit,ReLU)作为激活函数,并使用RMSProp优化器更新网络参数,学习率为0. 001。采用的自适应εgreedy 算法中,ε 最大值为1,最小值为0. 02,衰减因子为0. 005,经验池大小为20 000,每次训练抽取的小批次样本数为2 000,折扣因子为0. 99,总共进行1 000 个训练回合,训练过程的每个训练集的时间都是100 ms。测试阶段共进行100 个回合。在训练阶段,载荷大小固定为2×1 060 byte,车速固定为10 ~ 15 m / s,在测试阶段,分别改变其大小以验证所提算法的鲁棒性。
为了验证所提MADRRQN 算法的有效性,本文在Python 平台上使用PyTorch 框架对提出的算法进行仿真,并在算法V2I 链路吞吐量、V2I 链路信道利用率以及V2V 链路有效传输等方面与其他算法的性能进行比较。其他算法包括:① 随机算法,子信道和功率随机选择;② 多智能体深度Q 网络(Multi-Agent Deep Q Network,MADQN)算法,由每层包含120 个神经元的4 层全连接结构的DQN 构成,训练智能体时,每个智能体分配相同的奖励值;③ 单智能体深度Q 网络(Single-Agent Deep Q Network,SADQN)算法,所有智能体共享一个DQN,在每个时隙,只有一个智能体根据训练的DQN 更新其动作选择的策略,而其他智能体动作的选择策略保持不变。
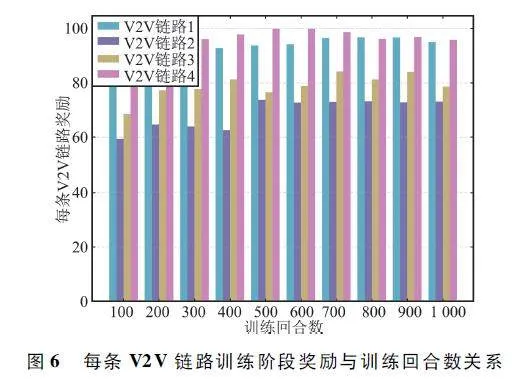
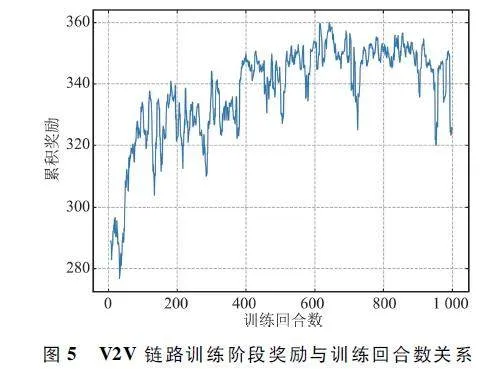
图5 和图6 分别显示了车辆数为4 时,训练阶段所有智能体的总和累积奖励和每个智能体奖励与训练回合数的关系。从图中可以看出,奖励值随着训练回合数的增加而增加,最后趋于收敛。从图6可以看到,每条V2V 链路的奖励值随着训练回合数的增加也趋于平稳。由此证明了所提MADRRQN算法的有效性。收敛的奖励值存在波动的原因在于车辆的快速移动,导致车联网的拓扑结构不断变化,同时也受到信道衰落的影响。
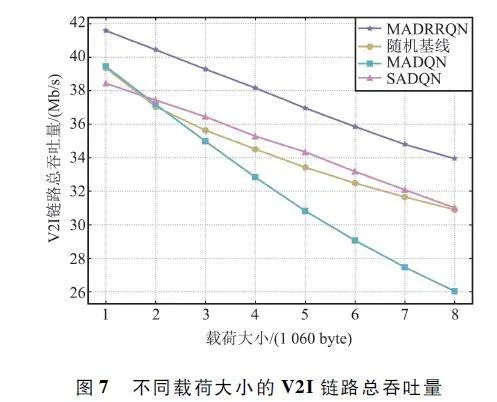
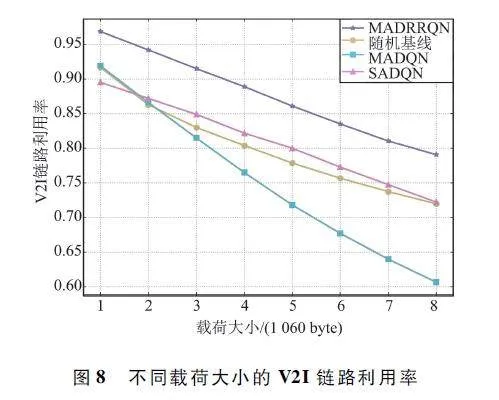
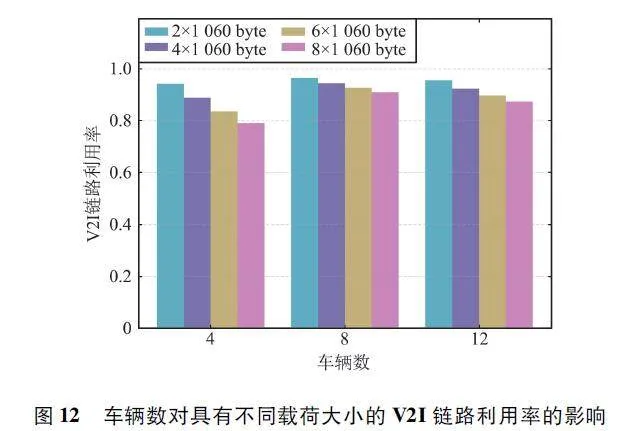
本文通过V2I 链路总吞吐量和V2I 链路利用率(实际获得的V2I 链路总吞吐量与禁用所有V2V 链路获得的V2I 链路总吞吐量的比值)来评估该算法在V2I 链路上的性能。图7 和图8 分别展示了不同载荷大小对不同算法在V2I 链路总吞吐量和利用率方面的性能影响。从图中可以看出,随着V2V 载荷大小的增加,所有算法的性能都有所下降。这是因为成功传输更多的载荷需要更长的传输时间和更高的V2V 链路发射功率,加剧了对V2I 链路的干扰,从而减小了V2I 链路的总吞吐量。但是,相同载荷大小的条件下,MADRRQN 算法具有更大的V2I 链路总吞吐量和更高的V2I 链路利用率。
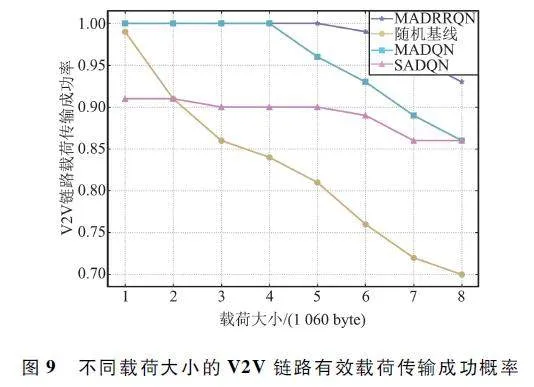
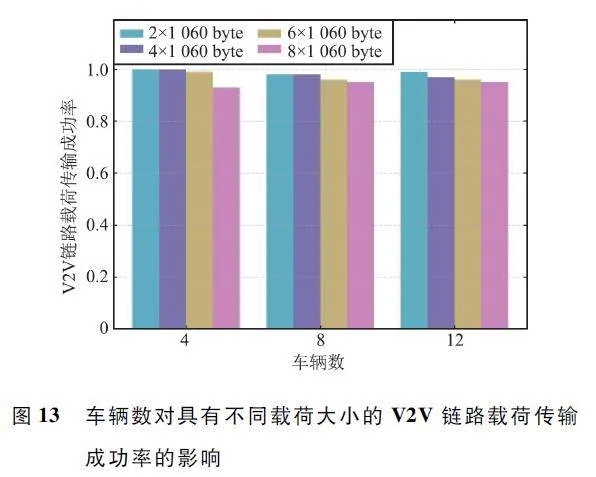
图9 显示了不同载荷大小,不同算法在V2V 链路载荷传输成功率方面的性能表现。所有算法的载荷传输成功率都随着载荷大小的增加而降低了,但其他算法的性能表现都比MADRRQN 算法差,虽然MADQN 算法在载荷小于等于4 ×1 060 byte 时传输成功率达到了100% ,但是随着载荷的增加,成功率显著下降,而MADRRQN 算法的载荷传输成功率下降缓慢,即使载荷达到8×1 060 byte,其载荷传输成功率仍然在90% 以上。
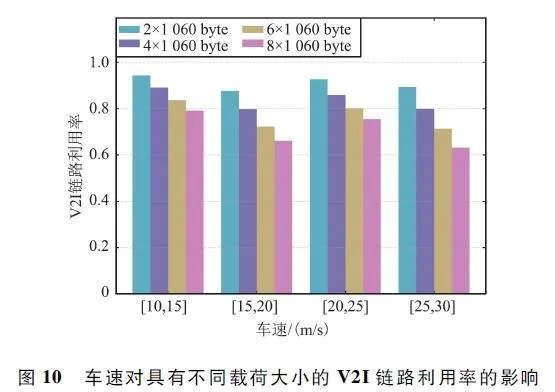
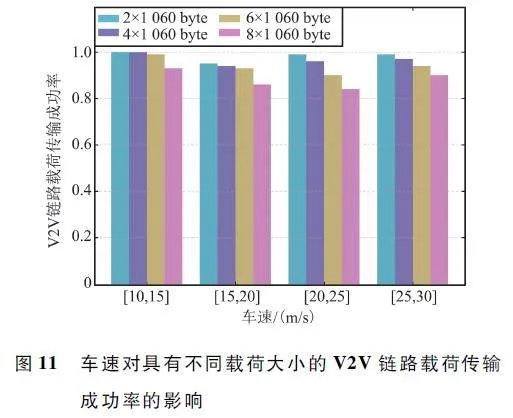
为了验证MADRRQN 算法对环境变化的适应性,本文从车速和车辆数量两方面验证其对算法性能的影响。图10 显示了车辆数固定为4 时的车速对具有不同载荷大小的V2I 链路利用率的影响。仅使用链路利用率来评估V2I 链路总吞吐量的变化的原因在于,车速的改变同样会影响没有V2V 链路传输时的V2I 链路吞吐量。因此,采用V2I 链路利用率这一相对比值更能客观地反映吞吐量的变化情况。从图中可以看出,车速对于2×1 060 byte 和4×1 060 byte 载荷的V2I 链路利用率影响较小,其链路利用率都高于80% 。对于大载荷,高车速对其影响较大,这是因为随着车速的增加,车联网拓扑结构变化更快,而需要传输的载荷数量更多,这对V2V 链路的子信道选择和功率分配提出了更高的要求。图11 显示了车辆数固定为4 时的车速与V2V 链路载荷传输成功率的关系图。对于相同的载荷大小,所提出的MADRRQN 算法的性能随着车速的增加而改变。这是因为车联网环境随着车速的增加变化地更加显著,增加了环境的不确定性和获取信道状态信息的难度。然而,所提出的算法仍然可以保持高V2I 链路总吞吐量和V2V 链路成功传输的概率,这说明车速变化对所提MADRRQN 算法的性能影响较小,因此该算法能够适应车联网环境中的车速变动。
当增加车辆,即子信道的数量增加时,意味着智能体的动作空间维度也增加了,对算法性能提出了更高要求。图12 和图13 分别展示了车辆数对具有不同载荷大小的V2I 链路利用率和V2V 链路载荷传输成功率的影响。从图中可以看出,车辆数对于所提算法的性能影响较小,甚至随着车辆数的增加,在大载荷的情况下,V2I 链路利用率反而提高了。由此说明算法能够适应不同数量车辆的环境,具备扩展到更多车辆情况的能力,并且对于传输载荷大小的变化具有鲁棒性。
4 结束语
针对车联网中的资源分配问题,本文采用了V2V 链路共享V2I 链路频谱资源的策略,并基于MADRL 算法提出了MADRRQN 算法。在该算法中,每条V2V 链路都被视为一个独立的智能体,每个智能体进行独立的训练和决策,显著降低了决策过程中的信息传输开销,增强了算法的可扩展性。通过充分的仿真实验,本文验证了所提算法的有效性,展示了其在最大化V2I 链路总吞吐量、提高V2I链路频谱利用率以及提升V2V 链路载荷成功传输概率等性能方面的优越性。此外,该算法还表现出在不断变化的车联网环境中的鲁棒性和适应性。未来研究将继续优化该算法,以适应更为复杂的实际应用场景。
参考文献
[1] YADAV S,PANDEY A,DO D T,et al. Secure CognitiveRadioenabled Vehicular Communications Under SpectrumSharing Constraints[J]. Sensors,2021,21(21):7160.
[2] QI W J,SONG Q Y,GUO L,et al. Energyefficient Resource Allocation for UAVassisted Vehicular Networkswith Spectrum Sharing [J ]. IEEE Transactions onVehicular Technology,2022,71(7):7691-7702.
[3] CHEN L L,ZHAO Q J,FU K,et al. Multiuser Reinforcement Learning Based Multireward for Spectrum Access inCognitive Vehicular Networks [J ]. TelecommunicationSystems,2023,83(1):51-65.
[4] 方维维,王云鹏,张昊,等. 基于多智能体深度强化学习的车联网通信资源分配优化[J]. 北京交通大学学报,2022,46(2):64-72.
[5] XIANG P,SHAN H G,WANG M,et al. Multiagent RLEnables Decentralized Spectrum Access in Vehicular Networks[J]. IEEE Transactions on Vehicular Technology,2021,70(10):10750-10762.
[6] ZHANG M L,DOU Y,CHONG P H J,et al. Fuzzy Logicbased Resource Allocation Algorithm for V2X Communicationsin 5G Cellular Networks[J]. IEEE Journal on Selected Areasin Communications,2021,39(8):2501-2513.
[7] XIE Y C,YU K,TANG Z X,et al. An Effective CapacityEmpowered Resource Allocation Approach in LowlatencyCV2X[C]∥2022 14th International Conference on Wireless Communications and Signal Processing (WCSP ).Nanjing:IEEE,2022:794-799.
[8] 赵莎莎. 基于PSO 的D2D 蜂窝网络联合信道分配和功率控制[J]. 无线电工程,2023,53(7):1660-1669.
[9] LIANG L,YE H,YU G D,et al. DeeplearningbasedWireless Resource Allocation with Application toVehicular Networks[J]. Proceedings of the IEEE,2020,108(2):341-356.
[10] TAN J J,LIANG Y C,ZHANG L,et al. DeepReinforcement Learning for Joint Channel Selection andPower Control in D2D Networks [J]. IEEE Transactionson Wireless Communications,2020,20(2):1363-1378.
[11] YUAN Y,ZHENG G,WONG K K,et al. Metareinforcement Learning Based Resource Allocation for Dynamic V2X Communications [J]. IEEE Transactions onVehicular Technology,2021,70(9):8964-8977.
[12] GUAN Z,WANG Y Y,HE M. Deep Reinforcement Learningbased Spectrum Allocation Algorithm in Internet ofVehicles Discriminating Services [J]. Applied Sciences,2022,12(3):1764.
[13] HAN D,SO J. Energyefficient Resource Allocation Basedon Deep Qnetwork in V2V Communications[J]. Sensors,2023,23(3):1295.
[14] TIAN J,SHI Y,TONG X L,et al. Deep ReinforcementLearning Based Resource Allocation with HeterogeneousQoS for Cellular V2X[C]∥2023 IEEE Wireless Communications and Networking Conference (WCNC). Glasgow:IEEE,2023:1-6.
[15] VU H V,FARZANULLAH M,LIU Z Y,et al. MultiagentReinforcement Learning for Channel Assignment andPower Allocation in Platoonbased CV2X Systems[C]∥2022 IEEE 95th Vehicular Technology Conference(VTC2022Spring). Helsinki:IEEE,2022:1-5.
[16]3GPP. Study LTEbased V2X Services (Release 14 )[R]. Valbonne:3GPP Support Office,2016.
[17] KY?STI P,MEINIL? J,HENTILA L,et al. WINNER IIChannel Models[M]. Hoboken:John Wiley & Sons,2008.
[18] LIANG L,YE H,LI G Y. Spectrum Sharing in VehicularNetworks Based on Multiagent Reinforcement Learning[J]. IEEE Journal on Selected Areas in Communications,2019,37(10):2282-2292.
作者简介
孟水仙 女,(1984—),硕士,高级工程师。主要研究方向:无线电监测、电磁兼容。
刘艳超 女,(1996—),硕士研究生。主要研究方向:认知无线传感器网络、强化学习。
(*通信作者)王树彬 男,(1971—),博士,教授。主要研究方向:认知无线传感器网络、机器视觉。
基金项目:国家自然科学基金(62361048)
