数字化转型环境下图书采购推荐服务
2024-09-16胡海莹周博张四新










摘 要 图书采购是丰富馆藏资源的一种重要活动,但是哪些图书该采购,成为了图书采购管理工作中的难题。针对该问题,论文提出一种基于COA-CNN-GRU神经网络的图书推荐方法。首先,利用灰色关联分析提取图书借阅数据中影响采购的关键因素。接着,通过COA算法优化CNN-GRU模型,构建了针对图书采购的推荐模型。以湖北文理学院图书馆为例,对约11,000种图书的借阅记录进行7:3划分,形成训练集(7,700种)与测试集(3,300种)。实验证明,该模型训练精度高达90.06%,展现出卓越的预测性能与泛化能力,为图书采购管理提供了科学、高效的决策工具。
关键词 图书采购;推荐模型;COA-CNN-GRU;神经网络
分类号 G258.6
DOI 10.16810/j.cnki.1672-514X.2024.08.008
Recommended Services for Book Procurement in a Digital Transformation Environment
Hu Haiying, Zhou Bo, Zhang Sixin
Abstract Acquiring books is a vital endeavor for enhancing library collections, yet determining the most suitable titles for procurement poses a significant challenge in book acquisition management. To tackle this challenge, this paper proposes a novel book recommendation system grounded in a hybrid COA-CNN-GRU neural network architecture. Firstly, the key factors affecting the procurement of books in the book borrowing data are extracted by using gray correlation analysis. Then, the recommendation model for book purchasing is constructed by optimizing the CNN-GRU model through the COA algorithm. Taking the library of Hubei College of Arts and Sciences as an example, the borrowing records of about 11,000 kinds of books were divided 7:3 to form a training set (7,700 kinds) and a test set (3,300 kinds). The experiment proves that the training accuracy of the model is as high as 90.06%, showing excellent prediction performance and generalization ability, which provides a scientific and efficient decision-making tool for book procurement management.
Keywords Book purchase. Recommendation model. COA-CNN-GRU. Neural network.
0 引言
高校图书馆具有重要的职能和使命,需要为学生、教师、科研人员及社会大众开放并提供服务。图书采购作为图书馆管理的一个重要环节,对于丰富馆藏资源、保障学生学习生活、为教师教学科研提供信息支撑、满足社会大众的图书阅读需求等均具有十分重要的意义。
随着信息技术日新月异的进步与发展,人工智能技术的应用边界日益拓宽,时至今日,图书馆服务领域也已广泛应用了人工智能技术,比如智能选书[1]、自助借书[2]、读者画像[3]、精准推送[4]等,许多研究者也开发了各类智能化图书系统。其中,图书信息的分析挖掘和预测模型的建立,对图书馆人员设备、空间设计和资源采购的便利性具有很好的指导意义,有助于实现图书馆的智能化管理。张一翠、魏青山[5]等构建了以EBL五步骤为指导的EBL-PDA嵌套模型,并在EBL指导下的PDA实践助力图书馆有效补充了馆藏,更精准地把握读者需求。宋丽[6]提出了一种依托于数据挖掘技术的智慧图书馆个性化推荐服务体系,并对此体系中涉及的图书馆数据挖掘手段、个性化推荐服务方案策划与实施效果进行了细致对比与深入剖析;范云欢[7]系统回顾了图书馆学习支持服务的研究现状及其在智慧环境下的特征,从学习者行为、知识内在关联性及学习情境三个维度构建了一套学习支持服务的大数据挖掘模型,并对其数据来源和挖掘路径进行了深入探讨与解析。
在图书采购推荐模型的研究范畴内,运用线性回归分析模型和灰色系统理论模型来推测图书馆图书借阅趋势,是一种常见的研究途径。然而,图书采购的过程实际上是一个受多重复杂因素交织影响的非线性动态过程[8]。面对这一特性,不同学者针对具体问题展开了针对性研究。例如,孙宝[9]为减弱主观因素影响,强化图书采购决策的科学严谨性,构建了基于层次分析法(AHP)的图书购置策略。刘驰[10]借助灰色神经网络理论,构建了一种基于图书拒借率和流通率的复本采购预测模型。
鉴于神经网络模型所展现出的卓越非线性拟合能力,它能够有效地捕捉并再现序列内部复杂的非线性变换特征[11]。张俊三等人[12]设计了一种创新路径,他们首先构建了一个反映用户与物品之间互动关联的用户—物品图谱,进而应用图神经网络(GNN)技术学习这些实体的内在特征表达,并在此基础上提出了一个结合邻域采样机制的多目标图推荐算法。蔡丹丹[13]则以上海图书馆公开的一般外借图书借阅数据为基础,运用遗传算法对神经网络进行了深度优化,开发出一套基于遗传神经网络架构的图书采购推荐模型,旨在评估图书能否成为满足大众阅读需求的“热门书籍”,进而指导生成精准的图书采购建议清单。另外,黄小华[14]在遗传算法的基础上注入了改良元素,改进后的算法用于优化神经网络的权重分配、阈值设定及网络结构本身。借此优化手段,他深入探究了图书各种属性与其被图书馆纳入采购范围之间的潜在联系,并最终实现了对图书是否会被采购这一行为的精确预测分类。
近几年CNN-GRU模型已被用于水质预测[15]、人脸识别[16]、风电功率预测[17]和电力负荷预测[18]等。本研究以湖北文理学院2022—2023年图书借阅大数据为基础,利用COA优化算法结合CNN-GRU模型,挖掘图书馆采购书籍与图书信息间的潜在关系,建立一种基于COA-CNN-GRU 神经网络的图书采购推荐模型,为图书采购提供决策依据。
1 关键影响因素的提取
灰色关联分析技术[19]作为一种源自灰色系统理论的核心工具,其核心功能在于定量揭示和评估灰色系统内部各项变量间的相互关联强度。在本次研究中,我们将运用灰色关联分析方法,依据各个影响因素随时间演变趋势的相似性程度,以确定图书信息特征与图书馆采购决策间存在的关联紧密程度。其中,关联度数值越高,则意味着该图书信息特征对于图书采购活动的影响力越显著。
依据图书馆内记录的图书详细数据集,我们重点关注如下十项关键属性:“书名标识”“主题关键词”“图书分类编号”“作者信息”“定价情况”“出版社归属”“出版年份”“馆藏复本量”“语言种类”及“历史借阅频次”。通过对这些要素实施灰色关联分析,可以深入探讨它们与图书馆图书采购策略的相关性和影响力。
为了解决这一问题,本文以“借阅次数”作为决策依据,采用灰色关联分析方法来分析影响要素与借阅次数之间的关系,并提取出影响读者“借阅次数”具有较大关联的关键因素。首先通过图书管理系统收集影响图书采购因素分析数据作为比较序列,X'i(i=1,2,…,n),假设有n组数据形成如下矩阵:
(1)
式(1)中m表示影响因素的个数。
无量纲化处理是必要的,因为影响因素和结果的量纲不一样。采用均值化法、初值化法和标准化法计算影响因素和结果,以避免无量纲化误差。假设n组样本的影响结果为参考序列,用Y'=(y'(1),y'(2)…,y'(m))表示,经过无量纲化处理后的矩阵为:
(2)
在本研究中可计算每一个比较序列与参照序列中对应元素的相关系数,表示为:
(3)
式(3)中i=1,2, … ,n,是比较序列的索引,ρ为分辨系数,其中通常设置ρ=0.5,h=1,2,…,m。
通过利用上述相关系数,本研究可以进一步求得各影响因素与参照序列间的关联度,其计算公式如下:
(4)
将计算出来的关联序从大到小依次排列,值越大说明该因素对结果的影响越大,由此提取出影响图书馆采购的关键因素,计算结果如表1所示。
根据关联度计算结果,选取关联度大的要素作为本论文的关键要素,即“主题词”“分类号”“著者”“出版社”“出版年”“复本”等6类要素作为关键要素。
2 基于COA-CNN-GRU的图书采购推荐模型
为了建立图书采购推荐模型,以上述6类关键要素作为输入变量,以“借阅次数”作为决策类别,将借阅次数分类如下:以借阅次数超过10次的书籍为“热门书籍”,5~9次的书籍为“较热门书籍”,1~4次的书籍为“一般书籍”,借阅次数为0的书籍为“冷门书籍”,分别用数字1表示“冷门书籍”,数字2表示“一般书籍”,数字3表示“较热门书籍”,数字4表示“热门书籍”。
2.1 原理分析
在CNN与GRU结合的架构中,CNN模块用于捕获输入序列的局部特征表达,而门控循环单元(GRU)[20]作为一种源于LSTM的时序建模变种神经网络结构,用于揭示序列数据的时间关联性。具体来说,CNN首先将序列数据转化为二维特征映射,并通过卷积及池化的运算提取出空间层面的特征信息。这些被提取出的特征会被传输至GRU模型中,以发掘序列内部的时序依赖关系。最后,整个模型运用时间反向传播算法(BPTT)进行优化训练,在此过程中,损失函数的梯度按照时间顺序自后向前穿越GRU层直至CNN层执行反向传播,并依循损失函数所得出的梯度来逐步调整模型的参数,从而提升模型对训练数据的拟合程度。关于GRU内部的状态演化机制,可由以下等式详述:
(5)
式(5)用于描述重置门(Reset gate)机制,它在GRU中负责决定丢弃历史信息的程度,其中变量Rt表征重置门输出向量,其取值越大,则遗忘的历史信息越多。
(6)
式(6)用于描述更新门(Update gate)机制,该门控作用于决定前一时步状态信息与当前时步信息的融合比例。此处,Zt表示更新门的sigmoid输出向量,当其数值增大时,意味着更多来自前一时刻的状态信息得以保留在当前状态中。
(7)
式(7)用于生成候选激活值,其中表示一种候选状态,表示为一种激活函数,其输出范围在[-1,1],这使得GRU网络能够有效处理梯度消失和梯度爆炸问题,同时保持了信息的潜力。
(8)
式(8)明确了最终输出值的计算方式,其中Zt表示Update gate的激活状态,同样以门控的形式对信息流进行调节作用;(1-Zt)*Ht-1表示存储前一时步遗留至最终记忆的状态信息;则是当前时步记忆内容经筛选后存续至最终记忆的部分。
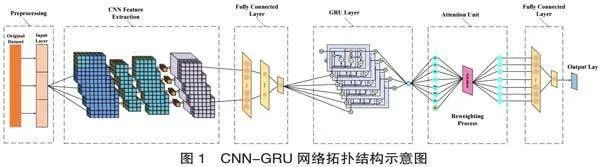
在上述表达式中,Ht-1表示前一时间步t-1的信息,为第t个时间步的输入向量,+表示逐元素相加运算,WR,WZ,Wh代表权重矩阵,bR,bZ,bH代表偏移量,б代表sigmoid函数,而符号*代表Hadamard乘积,CNN-GRU网络的拓扑结构如图1所示。
2.2 模型优化算法
COA是一种元启发式优化算法,具备卓越的进化性能、高效的搜索速率及出色的寻优特性[21]。鉴于这些优势,将其应用于优化CNN-GRU模型的超参数配置,有望显著增强模型训练效果。该算法模仿浣熊捕猎行为,通过一系列模拟步骤包括种群初始化、模拟鬣蜥遭遇浣熊的觅食与对抗过程(全局探索阶段)及应对捕食者威胁时的躲避行为(局部开发阶段),进而优选出最优解决方案。
对于探索阶段,式(9~13)展现了浣熊如何在搜索空间中动态迁移并进行广泛探索的过程。尤其是在成功捕猎鬣蜥之后,浣熊会在空间中寻找新的潜在区域。
(9)
式(9)描述了种群在搜索空间内的随机初始化过程,其中Xi,j表示种群个体,bUj表示寻优上边界,bDj表示寻优下边界,V为[0,1]之间的随机数。
(10)
式(10)表述了浣熊在多维树状结构中位置的变化规则,其中Xp1i,j代表第i只浣熊在第j维度上的新位置坐标,V为[0,1]之间的随机数,Gj表示在该维度上最佳个体(类比为鬣蜥)的位置,I是从集合{1,2}中随机抽取的数,N代表浣熊群体的规模,[N/2]指不超过N除以2的最大整数,m则表示决策变量的数目。
(11)
(12)
(13)
式(11~13)进一步说明了鬣蜥跌落后,系统将其置于搜索空间的随机位置,而地面的浣熊则据此调整自己的追踪策略。其中,Ggj表示在第j维度上鬣蜥跌落的具体位置,FGg,i和Fi,j分别表示第j个维度下鬣蜥落地后的目标函数值与第i个浣熊的目标函数值,而Fip1和Fi分别表示第i个浣熊在新位置的目标函数值与在之前位置的目标函数值。
至于开发阶段,式(14~16)体现了浣熊在面对捕食者威胁并采取逃离行动时,如何借助自然行为机制实现局部搜索能力的提升,这表明了该算法在搜索过程中的开发能力。
(14)
式(14)中,blocj,D与blocj,U分别定义了第j个决策变量的局部上下界约束,t与T分别表示了当前迭代次数与最大允许的迭代次数。
(15)
(16)
式(15~16)描述了浣熊如何根据更新后的位置评估目标函数,并以此判断是否替换原有位置。在该过程中,Xp2i,j代表了第i只浣熊在第j维度的新位置,而Fip2和Fi分别表示该浣熊在新旧位置处的目标函数值。
2.3 模型构建
建立图书推荐模型的流程包括数据预处理、构建模型框架、优化超参数及模型测试评估,具体如图2所示。数据预处理阶段需要收集大量图书信息数据,并对其进行排列组合和归一化处理。
本研究采用了一种融合了CNN和GRU的混合模型,其输入层容纳了共计1.1万个图书信息样本,而输出层则致力于预测各类图书的受欢迎程度分类。模型内嵌了一系列隐藏层组件,依次包括折叠序列层、卷积层、池化层、Relu激活层、Sigmoid激活层、全连接神经网络层(FNN)、乘法层、展开序列层、扁平化层、Softmax输出层及GRU循环层。这些隐藏层以交错的方式相互连接,并共同汇聚至最终的FNN层。值得注意的是,GRU层在模型中扮演着从传递的数据中捕捉关键特征及维护内部状态的角色。
在正式进行模型训练之前,CNN-GRU模型的表现会受到众多超参数配置的影响,例如隐藏层层数和学习率等。为了寻找到最优的超参数配置组合,本研究采用了一种高效且具备全局最优搜索能力的COA算法进行模型优化。同时,为确保该模型在训练过程中具有稳定的梯度,参数初始化阶段采用了均匀分布初始化(Uniform Initialization)方法,并在激活函数选择上采用了tanh函数和sigmoid函数。此外,模型参数优化采用了Adam算法(自适应矩估计优化算法),旨在最小化损失函数,从而提升模型表现。
在模型性能评估阶段,本研究采纳了混淆矩阵作为评价分类预测准确性的核心指标。通过深入分析混淆矩阵的各项指标,如准确率、召回率、精确率和F1得分,可以全面了解模型在不同类别上的分类精确度表现。
3 结果分析
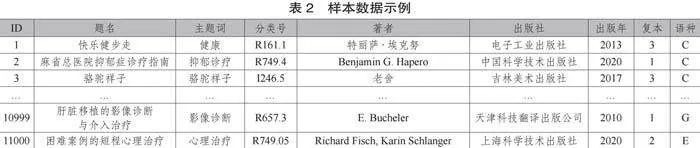
在本研究中,我们运用了MATLAB软件(版本R2023a)进行相关函数集的编程与执行操作。为了有效处理“主题词”“分类号”“著者”“出版社”“出版年”“复本”等图书信息特征及四种决策类别的组合问题,本文通过了排列组合方法与控制变量策略简化了繁杂的组合形态。本研究所构建的数据集涵盖了总计11 000组实验样本数据。其中,70%的数据被分配为训练集,剩余的30%作为测试集,具体样本数据如表2所示。
在训练模型之前,本研究先行对全部实验数据执行了Z-Score标准化预处理步骤,以消除原始数据尺度差异的影响。接着,依据图书信息的特性特征,对数据集进行了合理的输入与输出设置。之后,本研究利用了COA(Coyote Optimization Algorithm )优化算法的优势,对所构建的CNN-GRU模型中的超参数进行了细致调优,以确定最优的迭代次数、学习速率、正则化参数值及隐藏层神经元数量。
随后,本研究将训练集和测试集应用于三种图书采购推荐模型:CNN、CNN-GRU和COA-CNN-GRU,以验证它们的准确性,详见图3。根据混淆矩阵可知,三种模型中COA-CNN-GRU的整体预测性能最好,能以较高的准确率来预测多种决策类别。
通过对三种模型进行性能评估分析,可得出结论:COA-CNN-GRU模型在分类预测方面优于其他五种模型,表现出更高的精度,详见表3。
根据各模型的实验结果,本研究综合评估了性能,并进行了综合评价指标F1值的对比,具体结果如图4-a所示。模型对类别1的预测表现均优于其他三种情况,这是因为类别1只需确定不同图书信息的特征即可较好地进行预测分类。与此同时,CNN模型的预测性能明显低于其他模型。尽管CNN模型相对于SVM和Linear Classification模型具有更好的分类性能,但其仅能提取局部特征信息。
图4-b比较了各模型的召回率。显然,本研究中的COA-CNN-GRU模型的召回率高于其他模型,即该模型能够获取更多特征信息。同时,该模型的分类预测效果也明显优于其他两种模型。这是由于混合神经网络的预测效果与超参数密切相关,而COA优化算法具有更好的优化性能。
4 结语
论文结合理论探究和实证检验,创新性地运用改良神经网络技术的图书采购优化策略。通过对图书馆借阅记录的深度挖掘,建立了与图书采购推荐高度相关的六大核心信息指标,即“主题关键词”“分类编号”“作者”“出版社名称”“出版年份”及“复本数量”。研究成果突显了COA算法架构的优越性,并运用COA算法有效优化了CNN-GRU模型内部的超参数设定,最终融合COA算法与CNN-GRU神经网络形成的整合模型展现出了卓越的预测准确率,高达90.06%。鉴于此,该模型具有广泛的适用性和可移植性,不仅适用于当前研究环境下的图书采购推荐,还可推广至其他各类高校图书馆场景,从而为高校图书馆图书采购决策提供更为科学且精确的数据支撑。
参考文献:
蔡迎春.图书馆精准采购实现策略[J].数字图书馆论坛,2021(6):50-55.
蔡屏.自助借书系统具体实施细节研究[J].图书馆建设,2011(2):71-74.
刘卫红.元宇宙环境下图书馆读者画像研究[J].图书馆界,2023(3):1-5,28.
王娜.AI赋能的图书馆用户兴趣画像构建与精准推送服务研究[J].图书情报导刊,2022, 7(1):16-21.
张一翠,魏青山.循证图书馆学在读者决策采购模型建立和实践中的应用研究:以西安交通大学为例[J].图书馆学研究,2021(5):53-59.
宋丽.基于数据挖掘技术的智慧图书馆个性化推荐服务分析[J].图书馆学刊,2023,45(2):69-73.
范云欢.智慧环境下基于大数据挖掘的图书馆学习支持服务[J].情报探索,2020(5):40-45.
柯羽.高校毕业生就业质量评价指标体系的构建[J].中国高教研究,2007(7):82-84,93.
孙宝.基于回归控制的高校图书馆采购量建模研究[J].情报理论与实践,2013,36(6):93-97,106.
刘驰.灰色神经网络模型在图书采购复本量预测的应用[J].科技创新导报,2013(19):200-201.
耿立艳,张占福,李达.基于ARIMA-SVM的城际高铁客流量短期预测[J].交通与运输, 2020,36(6):42-45.
张俊三,肖森,高慧,等.基于邻域采样的多任务图推荐算法[J].计算机工程与应用,2024, 60(9):172-180.
蔡丹丹.基于遗传神经网络的图书采购推荐模型研究[J].图书馆研究与工作,2022(5):38-42.
黄小华,苗松,施化吉,等.基于改进遗传神经网络的图书采购模型研究[J].现代情报,2009,29(9):162-165.
MEI P , LI M , ZHANG Q ,et al. Prediction model of drinking water source quality with potential industrial-agricultural pollution based on CNN-GRU-Attention[J].Journal of Hydrology, 2022,610(127934):1-13.
PANKA J, BHARTI P K , KUMAR B. A new design of occlusion-invariant face recognition using optimal pattern extraction and CNN with GRU-Based architecture[J].International Journal of Image and Graphics, 2022(16):789-813.
薛阳,王琳,王舒,等.一种结合CNN和GRU网络的超短期风电预测模型[J].可再生能源,2019,37(3):456-462.
赵兵,王增平,纪维佳,等.基于注意力机制的CNN-GRU短期电力负荷预测方法[J].电网技术,2019,43(12):4370-4376.
CHENG Y C, YEH H C, LEE C K. Multi-objectiveoptimization of the honeycomb core in a honeycombstructure using uniform design and grey relationalanalysis[J].Engineering Optimization, 2021(54):286-304.
CHO K, VAN MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN Encoder-Decoder for statistical machine translation[J].Computer Science, 2014(9):1724-1734.
DEHGHANI M, TROJOVSKA E, TROJOVSKY P,et al. Coati optimization algorithm: a new bio-inspired metaheuristic algorithm for solving optimization problems[J]. Knowledge-based systems, 2023(259):1-43.
胡海莹 湖北文理学院图书馆馆员。 湖北襄阳,441053。
周 博 湖北文理学院机械工程学院硕士研究生。 湖北襄阳,441053。
张四新 湖北文理学院图书馆馆长。 湖北襄阳,441053。
*本文系湖北省中青年科技创新团队计划项目“汉江流域资源环境与区域发展”(项目编号:T202314)、2020年湖北省高校图工委科研基金项目“后疫情时代的高校图书馆阅读疗法服务研究”(项目编号:2020-YB-08)研究成果之一。
