基于虚拟化的大数据分布式实验平台的研究与实践
2024-09-14江接宝石良玉


摘要:针对高职院校大数据技术专业多门核心课程的实验环境复杂与学生实验困难问题,提出基于虚拟化的分布式大数据实验平台辅助课程实验教学。本文从职业院校大数据技术专业全国申报情况、大数据专业实验系统现状、实验平台方案、实验平台技术路线中的关键技术与工具介绍、总结效果等方面,详细介绍了虚拟化的分布式大数据实验平台的技术原理及客户端与服务器端软件版本信息。该平台融入大数据行业企业的实际岗位技能需求、全国职业院校技能大赛大数据赛项规范、大数据技术专业核心课程要求与“1+X”大数据平台运维职业技能等级证书标准等要求。通过实践教学分析,该方法方便学生学习大数据专业相关核心课程的实践操作,提高了学习效果。
关键词:虚拟化;大数据;分布式实验平台;Hadoop;VirtualBox
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)23-0085-04
开放科学(资源服务)标识码(OSID)
0 引言
2021年,工业和信息化部发布《“十四五”大数据产业发展规划》。数据已成为重要的生产要素,大数据产业作为以数据生成、采集、存储、加工、分析、服务为主的战略性新兴产业,是激活数据要素潜能的关键支撑,是加快经济社会发展质量变革、效率变革、动力变革的重要引擎。面对新一轮科技革命和产业变革深入发展的机遇期,世界各国纷纷出台大数据战略,开启大数据产业创新发展新赛道,聚力数据要素多重价值挖掘。
2022年,江西省发布《关于深入推进数字经济做优做强“一号发展工程”的意见》文件,提到服务“数字技术创新工程”“上云用数赋智工程”等,培养数字工程师,推动数字化转型,助力数字经济高质量跨越式发展。
近五年,全国各大高职院校陆续申报开设大数据技术专业。截至2021年,全国892所高职院校成功备案大数据技术专业,其中江西省有33所高职院校备案大数据技术专业,大数据技术专业迎来大发展。一方面,进入大数据时代,大数据技术被应用到社会的方方面面,包括电商商务、医疗卫生、智慧交通、银行金融、智慧教育、商业分析、国家安全、食品安全等,从而导致大数据技术人才需求量猛增,人才缺口较大。另一方面,各大高职院校积极响应社会和市场的需求,陆续开设大数据技术专业。由于大数据专业是前沿学科、实战导向的新型复合型专业,在学好理论课的同时,对于学生的动手能力和实战经验要求较高[1]。因此,如何培养实战技能以达到该专业岗位的要求,是各职业院校大数据技术专业课程教师们关注的热门议题。同时,在2019年,江西省职业院校技能大赛大数据赛项正式开设,将大数据专业相关技术列入了大数据技术赛项,吸引了大量师生一起钻研大数据技术,通过竞赛提高实操能力。
为深入培养大数据技术人才,各高职院校开始不满足于短时间的集中培训,尝试将竞赛内容推广到全专业的课程教学中。但现阶段实验资源不足,各大竞赛设备限制了学习人数。将竞赛设备推广到全专业教学,受到设备资源不足的制约。本课题组教师具有多年大数据技术企业工作经验,又有大数据技术竞赛实践指导经验,决定借鉴竞赛备赛设备,开发基于虚拟化的大数据分布式实验平台,为完善大数据技术专业课程实验做出有价值的研究。
1 目前职业院校大数据专业实验系统现状
高职院校的大数据实验教学平台一般以开源Apache Hadoop为基础。经过课题组成员调研了解到,实验平台建设主要有以下几类方案:
1) 普通单物理机方案。不采用虚拟化计算。在一台单物理PC机上直接安装Linux操作系统(CentOS) ,然后在CentOS中直接安装JDK,进而安装部署Hadoop平台。该方案的不足:实验环境只有一个机器,只能配置成单机模式或伪分布模式集群,不利于学生练习搭建多节点的集群学习[2]。在传统学校机房,一般PC机器都安装Windows系统,多门课程共同使用,直接安装Linux操作系统与实际情况不太符合,利用率不高。
2) 基于企业开发的大数据实验平台。企业开发的大数据实验平台采用云计算和虚拟化技术,将底层计算、存储与网络资源集中进行了虚拟化云端管理,实验平台按需分配和管理硬件资源。在进行实验时,学生可以在Web页面上进行实验,根据实际的需求,动态地进行资源分配。学校需要购买大容量高性能专业的服务器与实验平台,花费较高。该方案的不足:实验环境在机房集群,学生一般只有上专业课才能使用,使用受时间与空间的约束。
3) 基于物理机+虚拟化技术。为避免上述不足之处,采用在单台物理机Windows系统上安装VirtualBox软件[3],虚拟出若干台可同时运行的虚拟机,在虚拟机上搭建大数据集群环境。在新建的虚拟机上,安装Linux操作系统、配置局域网、安装JDK软件等,进一步在多个虚拟机上安装部署Hadoop集群。学生在普通机房(PC机器内存大于等于16 G性能会更佳),可以搭建完全分布式Hadoop集群进行实验操作,并且可以将实验过程的虚拟机系统导出为镜像文件,存储在移动U盘或硬盘;在VirtualBox软件上导入镜像文件,可以继续课程实验部分内容,不受时空限制,有利于学生专业学习与实操技能提升。该方案的优点:在VirtualBox软件上搭建基于虚拟化的大数据分布式实验平台,为大数据专业核心课程提供学生实验环境,解决实验环境复杂,学生实操技能不足的难题。
2 大数据实验平台建设
2.1 实验方案
基于虚拟化的大数据分布式实验平台分解成六层:物理集群层、数据来源层、数据传输层、数据存储层、资源管理层与数据计算层,符合软件平台设计的高内聚低耦合原则,从技术的角度可以实现。
1) 物理集群层。通过虚拟化工具VirtualBox在一台安装Windows系统的PC机上创建3个虚拟机,并且安装Linux系统(CentOS 7) 。三台虚拟机配置局域网IP地址(Master机器:192.168.56.101;Slave1机器:192.168.56.102;Slave2机器:192.168.56.103) ,三台机器之间可以互相连通,形成三台机器集群,并且每台机器都要关闭防火墙。
2) 数据来源层。数据可以来源于传统的关系型数据库(MySQL、Oracle) 、系统的日志文件、互联网Web网页数据与图片视频数据等;数据可以分为结构化、半结构化和非结构化数据[4]。
3) 数据传输层。通过数据传输工具Sqoop和日志收集工具Flume,将数据来源层的异构数据传输到数据存储层。
4) 数据存储层。在Linux系统之上安装Hadoop系统,具备HDFS分布式文件系统,三台Linux系统形成了逻辑上的文件系统集群,可以存储相关数据;非关系型数据库HBase把数据存储在HDFS分布式文件系统,可以实现海量数据的存储与查询;关系型数据库MySQL存储相关分析与计算的结果数据。
5) 资源管理层。Hadoop平台包括YARN资源管理器。YARN的引入有利于Hadoop平台集群的资源统一管理、数据共享和利用率,提升平台的健壮性[5]。
6) 数据计算层。数据计算层在资源管理层之上,可以通过MapReduce框架处理大数据的离线计算任务;通过Spark框架在内存技术(比MapReduce框架的计算效率更高);通过Flink框架进行数据的实时计算,适用于实时性要求较高的计算任务。
系统的服务器端利用基于虚拟化工具VirtualBox开发,支持镜像文件导出,学生可以自由通过PC机导入镜像文件进入实验环境,不受地理位置限制。利用现有大数据实训室的硬件条件,能够实现平台的测试与试运行。此外,师生也能通过个人PC机导入镜像文件进入实验环境,实现课堂教学到课外应用的全覆盖。
具体实现方案,如图1所示。
2.2 技术路线
VirtualBox是一款开源虚拟机软件,可创建的虚拟系统包括Linux、Windows、Mac OS等操作系统。本实验通过VirtualBox软件创建多台虚拟机,配置虚拟机网络环境,实现虚拟机之间互相连通,模拟多台物理机。
SSH客户端用于远程连接Linux系统服务器,可以执行服务器操作命令,上传文件到服务器,对服务器进行管理。
Chrome是Google开发的一款设计简单、高效的Web浏览工具,流行于软件开发者群体,特别适用于Hadoop平台的Web访问。
Hadoop是由Apache基金会开发的免费开源的分布式系统平台,包括三大核心组件:HDFS分布式文件存储系统、MapReduce离线计算框架和YARN资源管理。
ZooKeeper是Google的Chubby的一个开源实现,是Hadoop和HBase的重要组件,在平台中负责分布式应用程序协调。
Hive是一个数据仓库工具,可以提取、转化与加载数据。Hive可以通过HQL语言(类似SQL结构化查询语言)进行查询、分析和存储在Hadoop中的大规模数据。
Flume是一款开源高可用的分布式海量日志采集、传输和聚合的软件,在数据收集的过程中,可以支持在日志系统中定制各类数据发送方[6]。
Sqoop是一款开源工具,主要用于在Hadoop (Hive) 与传统的关系数据库(MySQL) 间进行数据的双向传递。它可以将HDFS的数据导入到关系型数据库中,也可以将关系型数据库MySQL中的数据导入到Hadoop的HDFS。
Kafka是一种高吞吐量的分布式发布订阅消息系统,可以与Hadoop平台协调处理线上和离线的消息,为平台集群提供实时的消息流。
Spark是开源的通用并行计算框架,为大规模数据处理而设计的快速通用计算引擎。与Hadoop MapReduce计算框架类似,因中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此,Spark能更好地适用于数据挖掘与机器学习等需要迭代的算法场景。
Flink是开源实时流数据处理框架,由Apache软件基金会开发,其核心是通过Java和Scala编写的分布式流数据处理引擎。
HBase是Apache Hadoop项目的子项目,基于列存储数据,不同于关系数据库基于行存储,适合于非结构化数据存储的数据库。
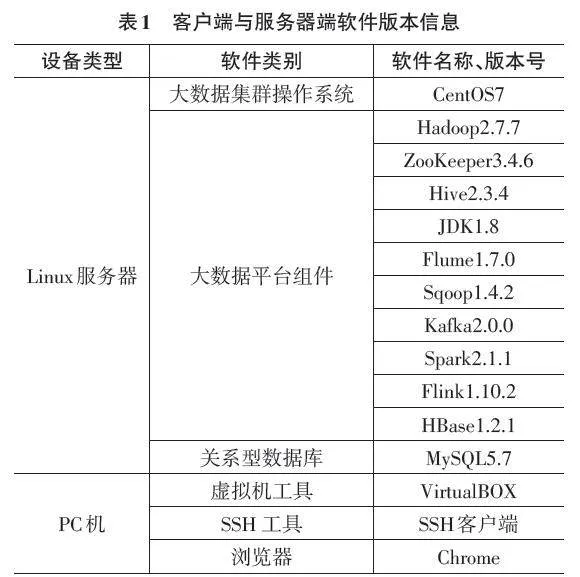
具体客户端与服务器端软件版本信息,如表1所示。
2.3 效果展示
在开源软件VirtualBox上创建3台虚拟机,通过CRT工具连接虚拟机,如图2所示。
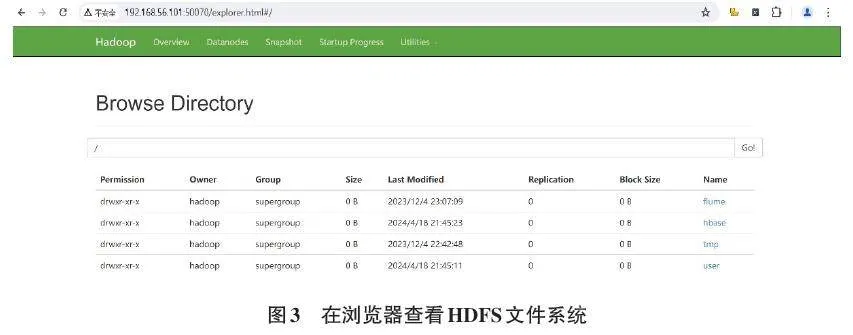
在连接上Master机器的CRT上运行命令start-all.sh,启动Hadoop集群。在Chrome浏览器查看Hadoop集群的HDFS分布式文件系统,如图3所示。
高职院校大数据技术专业的核心专业课程包括:Hadoop技术基础、Spark技术、大数据应用开发等课程。上述课程都需要Hadoop实验平台的支撑,本实验平台可以用于上述课程Hadoop平台相关的实验。
3 总结
1) 开发基于虚拟化的大数据分布式实验平台。通过虚拟化技术,在一台PC上,模拟出多台机器,并将多台机器配置成分布式大数据实验集群,在集群上搭建大数据平台;解决高职院校在大数据技术专业课程中通常只能使用单台机器实验,不能进行分布式多台机器实验教学的难题。
2)方便学生进行大数据技术课程实验。通过镜像文件使用实验平台,学生可以在个人计算机上进行核心课程实验,方便学生随时随地进行专业课程实验,解决大数据技术多门专业核心课程实验环境复杂,以及竞赛设备不能覆盖全专业的实验资源不足的难题。
3)提高学生大数据技术的实操技能。在平台开发设计中,将大数据技术行业企业岗位技能工具(Hadoop、ZooKeeper、Hive、HBase、Flume、Sqoop、Kafka、Spark、Flink等)运用到课堂教学实验中,丰富课堂教学内容,提高学生大数据技术工具使用与实操技能。
综上所述,基于虚拟化的大数据分布式实验平台适合高职院校的大数据技术专业核心课程的教学实验。参考大数据行业企业的岗位需求及所需职业能力的分析,依据全国职业院校技能大赛大数据赛项规范、大数据技术专业核心课程标准、“1+X”大数据平台运维职业技能等级证书标准等要求,在VirtualBox软件上搭建基于虚拟化的大数据分布式实验平台,为大数据专业多门核心课程提供学生实验环境,解决实验环境复杂与学生实操技能不足的难题。
参考文献:
[1] 林子雨.大数据技术原理与应用课程建设经验分享[J].大数据,2018,4(6):29-37.
[2] 吴小东,林国新.大数据课程实践教学平台的建设[J].福建电脑,2022,38(8):119-121.
[3] 江接宝,王朝晖.《大数据技术》课程实践改革研究[J].电脑知识与技术,2020,16(35):107-108.
[4] 张倩,李国庆.企业知识图谱在通信行业的应用探索[J].邮电设计技术,2023(7):75-80.
[5] 郑灵逸,李擎.一种基于HiveSQL的增加任务并行度与建立中间表组合的优化查询方法[J].现代计算机,2021,27(36):55-59.
[6] 张亮,杨春丽,马媛媛.大数据应用部署研究[J].电信网技术,2016(5):30-36.
【通联编辑:唐一东】
