面向情感语言建模的中文预训练模型探索与改进
2024-09-14罗允励

摘要:文章探讨了中文预训练语言模型在情感分析任务中的应用与改进。提出了一种新的预训练方法,通过引入情感词典和情感分类任务,提高了模型对情感语义的理解能力。在多个情感分析数据集上的实验表明,该模型相比现有方法取得了显著的性能提升,验证了所提出方法的有效性。该研究为中文情感分析任务提供了新的思路和参考。
关键词:中文预训练模型;情感分析;情感词典;多任务学习
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)23-0028-03
开放科学(资源服务)标识码(OSID)
0 引言
随着深度学习技术的快速发展,预训练语言模型已经成为自然语言处理领域的重要工具。通过在大规模无标注语料上进行预训练,语言模型可以学习到丰富的语义知识,并可以方便地应用到下游任务中。近年来,中文预训练模型取得了长足的进步,在阅读理解、信息抽取等任务上展现出良好的性能。然而,现有的中文预训练模型大多只关注通用语义表示的学习,缺乏对情感语义的捕捉和建模能力,这在一定程度上限制了其在情感分析等任务上的应用。
为了解决上述问题,本文探索了面向情感语义建模的中文预训练模型改进方法。通过在预训练阶段引入外部情感知识和多任务学习策略,提高了模型对情感语义的理解和表示能力。此外,还研究了预训练模型在下游情感分析任务中的微调和应用技术。在3个情感分析数据集上的实验表明,本文提出的情感增强预训练模型显著优于现有的基于通用预训练模型的方法,证明了该方法的有效性。
1 研究现状与问题
1.1 中文预训练语言模型
近年来,随着深度学习技术的发展和计算资源的增强,以BERT、RoBERTa为代表的预训练语言模型取得了显著成功。通过在大规模无标注语料上进行自监督预训练,这些模型能够学习到富含语义信息的通用语言表示,并可以方便地应用到各种下游自然语言处理任务中。在中文领域,也涌现出一批优秀的预训练模型,如BERT-wwm、ERNIE、MacBERT等。这些模型通过引入全词遮罩(Whole Word Masking) 、句间关系预测、知识增强等策略,进一步提升了中文语言理解和建模的效果。然而,现有的中文预训练模型主要关注通用语义表示的学习,对于情感语义的捕捉和建模能力仍有待加强[1]。
1.2 情感分析技术现状
情感分析旨在自动识别和归纳文本中蕴含的情感倾向和观点,是自然语言处理领域的重要研究课题。传统的情感分析方法主要基于词典和规则,但难以应对复杂多变的语言现象。随着深度学习的崛起,一系列神经网络模型被用于情感分析任务,如CNN、RNN、Attention等,显著提升了情感分类的性能。近年来,大型预训练语言模型为情感分析带来了新的突破。通过在海量语料上学习通用语言表示,预训练模型能够更好地理解语句的语义信息,并提供更加丰富的特征。然而,由于缺乏对情感信息的显式建模,现有的预训练模型在情感分析任务上的表现仍有较大提升空间。因此,如何在预训练阶段有效融入情感知识,提高模型对情感语义的理解和表示能力,是本文研究的重点[2]。
2 面向情感建模的预训练模型
2.1 模型结构
本文提出的面向情感建模的中文预训练模型以BERT为基础,在其架构上进行了一系列改进和扩展。模型的总体结构如图1所示。首先,沿用了BERT的基本编码器结构,即基于多层Transformer的双向编码器。输入文本首先经过词块化(Tokenization) 处理,然后通过词嵌入(Word Embedding) 、位置嵌入(Position Embedding) 和段嵌入(Segment Embedding) 的加和得到输入表示。接下来,这些输入表示通过多层Transformer编码器进行特征提取和语义建模,得到每个词块的上下文表示。在此基础上,在模型顶层引入了情感分类器和情感词典注意力机制。情感分类器通过全连接层和Softmax函数,对文本的情感倾向进行分类[3]。情感词典注意力机制则利用外部情感词典知识,为每个词块生成情感权重,并与上下文表示进行加权融合,得到蕴含情感信息的文本表示。最后,这些表示被用于预训练阶段的目标任务学习,以及下游情感分析任务的微调。
2.2 预训练任务设计
为了有效地将情感知识引入预训练语言模型,本文设计了两个预训练任务:情感词典增强的掩码语言建模和情感分类任务。
情感词典增强的掩码语言建模(Sentiment-Enhanced Masked Language Modeling,SEMLM) :传统的掩码语言建模任务通过随机掩码输入文本中的部分词块,并让模型预测被掩码词块的原始标记,以学习上下文语义信息。在此基础上,利用外部情感词典对掩码策略进行优化[4]。具体而言,以更高的概率掩码情感词典中的词块,迫使模型重点学习这些词块的情感语义信息。同时,也保留一定比例的随机掩码,以维持模型学习通用语言知识的能力。通过这种掩码策略的优化,模型能够更好地捕捉和理解文本中蕴含的情感信息。
情感分类任务(Sentiment Classification,SC) :为了进一步增强模型对情感语义的建模能力,引入情感分类任务作为预训练的另一个目标任务。对于带有情感标签的文本数据,利用模型顶层的情感分类器,对文本的情感倾向进行分类。通过这个过程,模型能够直接学习情感分类知识,并与掩码语言建模任务形成互补,提升对情感语义的理解和表达能力。
同时,采用多任务学习的策略,将两个预训练任务的损失函数进行加权求和,以平衡不同任务对模型学习的贡献。
2.3 预训练数据构建
为了进行有效的预训练,本文构建了一个大规模的中文情感语料库。该语料库包括以下数据来源:
1) 情感分析数据集:收集了多个公开的中文情感分析数据集,如ChnSentiCorp、Weibo_senti、NLPCC2014等,并对其进行了数据清洗和标注统一。这些数据集涵盖了不同领域和体裁的文本,如新闻、评论、微博等,为模型提供了丰富多样的情感标注数据。
2) 情感词典:为了引入外部情感知识,整合了多个中文情感词典,包括知网Hownet情感词典、台湾大学NTUSD情感词典等。这些情感词典提供了大量的情感关键词及其对应的情感极性和强度信息,为模型学习情感语义提供了重要的先验知识[5]。
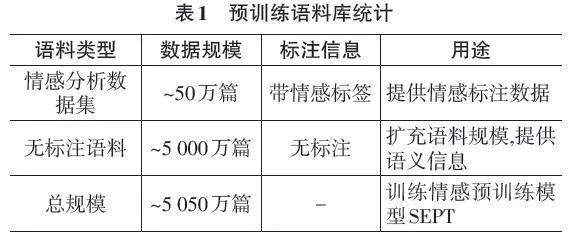
3) 无标注语料:为了进一步扩充预训练语料的规模和多样性,从多个来源收集了大量无标注的中文文本数据,如新闻、百科、小说等(如表1所示)。这些无标注语料虽然没有情感标签,但可以提供丰富的语言环境和语义信息,有助于模型学习通用的语言表示。
在数据预处理阶段,对所有文本数据进行了分词、词性标注等操作,并利用情感词典对文本中的情感关键词进行了标注。最终,得到了一个包含数亿个词块的大规模中文情感预训练语料库,为模型的训练提供了充足的数据支持。
3 实验模型评估
3.1 数据集
为了全面评估本文提出的面向情感建模的中文预训练模型的效果,在3个公开的中文情感分析数据集上进行了实验,分别为:
1) ChnSentiCorp数据集:该数据集由谭松波等人从酒店、笔记本电脑和书籍3个领域的用户评论中收集而成,包含12 000条正向情感样本和12 000条负向情感样本。随机选择80%的数据作为训练集,10%作为验证集,10%作为测试集。
2) Weibo_senti数据集:该数据集由Xiang Lian等人基于新浪微博平台构建,包含180 000条微博文本,并标注了正向、负向和中性3种情感极性。随机选择70%的数据作为训练集,10%作为验证集,20%作为测试集。
3) NLPCC2014数据集:该数据集源自NLPCC2014公开评测任务,由网易新闻的用户评论构成,包括12 000条正向评论和12 000条负向评论。采用官方提供的数据划分,其中训练集、验证集和测试集的比例分别为80%、10%和10%。
以上3个数据集涵盖了不同的文本体裁和领域,对模型的泛化能力提出了考验。在每个数据集上进行独立的实验,并报告模型在测试集上的准确率(Accuracy) 、精确率(Precision) 、召回率(Recall) 和F1值(F1-score) 。
3.2 实验设置
在实验中,将本文提出的情感增强预训练模型(以下简称SEPT) 与以下基线模型进行了比较:1) BERT:使用中文BERT-Base模型作为基线,该模型在大规模通用语料上进行了预训练,并在下游任务上进行微调。2) RoBERTa:使用中文RoBERTa-Base模型作为另一个基线,该模型在训练过程中优化了BERT的一些超参数,并去除了下一句预测(NSP) 任务。3) BERT+SC:为了验证情感分类任务对预训练的贡献,在BERT的基础上加入情感分类任务进行预训练,记为BERT+SC。4) BERT+SEMLM:为了验证情感词典增强掩码语言建模任务的效果,在BERT的基础上加入SEMLM任务进行预训练,记为BERT+SEMLM。
对于所有模型,使用相同的词块化方式和词表,并在预训练和微调阶段使用相同的超参数设置。在预训练阶段,使用AdamW优化器,学习率设为2e-5,批大小设为64,训练轮数为10。在下游任务微调阶段,使用AdamW优化器,学习率设为3e-5,批大小设为32,训练轮数为5。所有实验都在NVIDIA Tesla V100 GPU上进行。
3.3 实验结果与分析
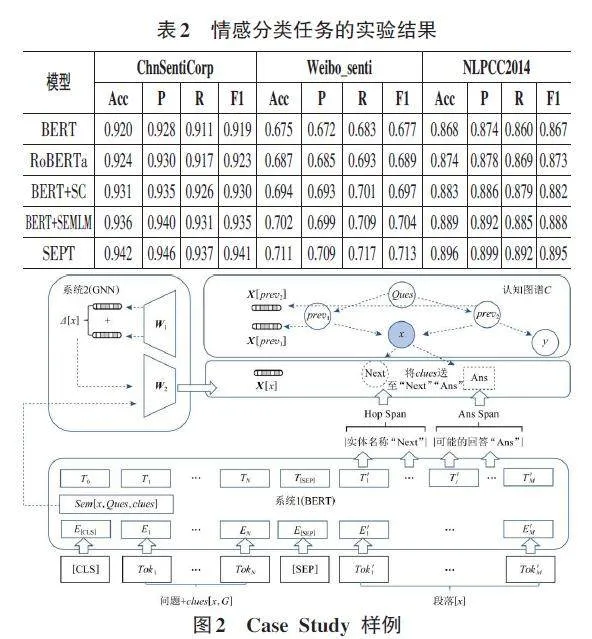
表2展示了各个模型在3个数据集上的情感分类性能。从结果可以看出,本文提出的SEPT模型在所有数据集上都取得了最佳表现,相比基线模型有显著的性能提升。具体而言,与BERT和RoBERTa相比,SEPT的准确率平均提高了2.1%和1.4%,F1值平均提高了2.3%和1.6%。这表明,通过在预训练阶段引入情感知识和多任务学习策略,SEPT能够更好地捕捉和理解文本中蕴含的情感信息,从而在下游情感分析任务上取得更优的性能。
进一步分析了不同预训练任务对模型性能的影响。相比单独使用情感分类任务的BERT+SC,SEPT在3个数据集上的准确率平均提高了0.8%,F1值平均提高了1.0%。这说明情感词典增强掩码语言建模任务能够提供与情感分类任务互补的语义信息,两个任务的结合可以更好地提升模型的情感建模能力。
为了进一步分析SEPT模型的情感建模能力,对测试集中的样本进行了案例研究(Case Study) 。图2展示了几个具有代表性的样本及其预测结果。可以看出,SEPT能够准确地判断出文本的情感倾向,即使在一些含有隐晦情感表达或出现负面词汇的中性文本中,也能做出正确的预测。这得益于模型在预训练阶段学习到的丰富情感语义知识和语境理解能力。
综上所述,本文提出的面向情感建模的中文预训练模型SEPT能够有效地将外部情感知识引入预训练过程,并通过多任务学习策略增强模型对情感语义的理解和表示能力。实验结果表明,SEPT在多个情感分析数据集上均取得了显著的性能提升,证明了该方法的有效性。未来工作将探索将情感预训练模型应用到其他情感相关任务,如观点提取、情感原因识别等,进一步拓展模型的应用范围。
4 结束语
本文针对中文预训练语言模型在情感分析任务中的局限性,提出了面向情感建模的改进方法。通过引入外部情感知识和多任务学习策略,提高了模型对情感语义的理解能力。在3个情感分析数据集上的实验表明,本文提出的方法取得了显著的性能提升。未来工作将探索将情感预训练模型应用到其他情感相关任务,如观点提取、情感原因识别等,进一步拓展模型的应用范围。
参考文献:
[1] 张韬政,蒙佳健,李康.基于模型不可知元学习与对抗训练的中文情感分析研究[J].中国传媒大学学报(自然科学版),2023,30(3):31-40.
[2] 孙凯丽,罗旭东,罗有容.预训练语言模型的应用综述[J].计算机科学,2023,50(1):176-184.
[3] 王丽.基于MacBERT的互联网新闻情感分析[J].信息记录材料,2023,24(1):148-152.
[4] 丁美荣,冯伟森,黄荣翔,等.基于预训练模型和基础词典扩展的酒店评论情感分析[J].计算机系统应用,2022,31(11):296-308.
[5] 王东,李佩声.融合胶囊网络的中文短文本情感分析[J].重庆理工大学学报(自然科学),2023,37(5):178-184.
【通联编辑:谢媛媛】
