基于数据增强和CNN的小样本图像分类研究
2024-09-14黄志伟



摘要:为解决卷积神经网络在研究图像分类问题时,由于训练样本过少而导致模型过拟合、测试准确率低的问题,本文整合了一套轻量级的数据增强方案,可以快速扩充图像样本。本文以Fashion-MNIST和CIFAR-10数据集为例,在只选取少量初始样本的前提下进行数据扩充,采用TensorFlow深度学习框架和Keras搭建VGGNet-13和ResNet-18模型进行训练和测试。结果表明,模型在测试集上表现出较好的准确率,有效应对小样本学习带来的过拟合问题,验证了该数据增强方案的有效性。
关键词: 数据增强; 卷积神经网络; 小样本学习; 图像分类; 随机填充
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)23-0021-04
开放科学(资源服务)标识码(OSID)
0 引言
Yann LeCun等人[1]在1998年提出了卷积神经网络(Convolutional Neural Networks,CNN) ,该技术在识别手写数字方面取得了显著的成绩。经过二十多年的发展,卷积神经网络在许多领域都起着至关重要的作用,例如图像分类[2]、语音识别[3]、目标检测[4]、人脸识别[5]等。图像分类是利用算法对已有的图像进行特征学习,找出其所属的类别。虽然卷积神经网络在图像分类问题上有着显著的效果,但前提是需要收集大量的图像样本用于训练,否则神经网络将很难学到足够的特征信息。然而,获取充足且具有较好区分度、特征清晰的样本通常比较困难。在只有少量样本的情况下,如果直接使用卷积神经网络对小样本进行训练,很容易出现过拟合现象,且模型不具备泛化能力。
小样本学习[6]是在只有少量初始样本的前提下,训练出一个能解决实际问题的模型。针对小样本困境,数据增强[7]是一种实用且非常有效的方法,它可以大量增加样本的数量和特征。数据增强的具体实现策略较多,包括图像的几何变换、色彩变换、图像拼接和模型生成等。而且,不同的策略有着不同的实现要求,任意的数据增强方法也不一定兼容。因此,本文以轻量化、低成本和兼容性为出发点,选择不基于模型、只对单图像进行变换的数据增强方法,即随机裁剪[8]、随机翻转、随机擦除[9]和随机填充[10]4种方法对小样本数据进行扩充。
本文分别从Fashion-MNIST和CIFAR-10数据集的训练集中随机抽取少量样本,以构造小样本困境,两个数据集中的测试集用于验证模型测试的准确率。接着将4种数据增强方法进行整合,按比例对小样本进行数据扩充。最后选择VGGNet-13[11]和ResNet-18[12]模型做图像分类的训练和测试,通过研究小样本在有数据增强和无数据增强的两种不同情况下,计算出卷积神经网络在测试集上的准确率,验证该方案的有效性。
1 实验环境与数据集
1.1 实验环境
本文在Windows 11系统下进行训练和测试。实验基于Anaconda 2022平台,采用深度学习框架TensorFlow 2.10和Keras 2.10搭建神经网络模型,运用Numpy库和Matplotlib库对数据进行数据预处理和数据可视化。
1.2 数据集
本文采用的数据集为Fashion-MNIST和CIFAR-10,这两个数据集均可从Keras中下载。
1) Fashion-MNIST数据集。Fashion-MNIST数据集包含有10个类别、70 000张像素为28×28的灰度图像。其中训练数据集中每个类别含有6 000个样本,测试数据集中每个类别含有1 000个样本。数据集的类别分别是:T-shirt(T恤)、Trouser(牛仔裤)、Pullover(套衫)、Dress(裙子)、Coat(外套)、Sandal(凉鞋)、Shirt(衬衫)、Sneaker(运动鞋)、Bag(包)以及Ankle Boot(短靴)。训练样本实例如图1所示。
2) CIFAR-10数据集。CIFAR-10数据集由60 000张分辨率为32×32的彩色图像组成,包含50 000个训练图像和10 000个测试图像。该数据集共有10个类别,分别为:Airplane(飞机)、Automobile(汽车)、Bird(鸟)、Cat(猫)、Deer(鹿)、Dog(狗)、Frog(青蛙)、Horse(马)、Ship(船)以及Truck(卡车),每个类别包含6 000张图像。训练样本实例如图1所示。
1.3 小样本数据
由于小样本所指代的具体样本数量没有明确的定义,因此,本文分别对Fashion-MNIST和CIFAR-10数据集构造出3种不同的小样本初始状态。具体地,初始样本数量分别设置为1 500、3 000和4 500个,其中,每一类样本分别占150、300和450个样本。这些样本均是随机从训练集中抽取。这样做的好处是在于,可以研究不同样本数量的初始状态与数据增强方案之间的联系。
2 数据增强方法
2.1 随机填充
随机填充(Random Padding,RP) 的概念由Nan Yang等提出。他们认为,CNN通过学习图像中不同位置的同一物体,可以提高模型的识别精度。这是因为特征空间信息会阻碍模型对特征关系的学习,而随机填充的数据增强方法可以减弱模型对特征位置信息的学习。
RP是一种用于训练CNN的新填充方法,它通过在图像的一半边界上随机添加零填充来实现。这种操作随机地改变特征位置的信息,可以有效削弱模型对位置信息的学习能力。该方法结构简单,不需要参数学习,并且与其他CNN识别图像的模型兼容。RP的实现过程非常简单,它通过随机地对特征图相邻的两个边界(左上、右上、左下和右下)进行零填充,填充一次则图像的尺寸增加1。常见的填充厚度为n = 1、2、3,选择填充厚度后RP会执行2n次填充操作。
令输入图像为I,其中T、B、L、R分别为图像的上、下、左、右四个边界,S表示图像的四种相邻边界的组合,从中选择一种记为Sn,输出为随机填充的图像I´。RP的实现步骤如下:
INPUT: I
PROCESS:
T = B = L = R = 0
S = [[1,0,1,0],[1,0,0,1],[0,1,1,0],[0,1,0,1]]
FOR i = 1,2,..,2n DO
Sn = RANDOM_CHOICE(S,1)
T += Sn [0]
B += Sn [1]
L += Sn [2]
R += Sn [3]
END FOR
I´ = I([T , B , L , R])
OUTPUT: I´
2.1.1 图像的RP
采用RP数据增强方法,对Fashion-MNIST和CIFAR-10数据集的初始样本进行数据增广,每个样本进行4次RP操作,即每张原图被扩充为4张。因此,初始样本数变为N1 = 6 000、12 000、18 000。本文的随机填充厚度统一设置为n = 3,而随机填充操作会改变图像的原有尺寸。因此,原图像经过RP操作后,两个数据集的样本尺寸分别从28×28和32×32增加到34×34和38×38。原始样本经过RP操作的实例如图2所示。
2.2 随机裁剪
随机裁剪(Random Cropping,RC) 是一种简易的单图像数据增强方法。RC需要预先定义图像的裁剪面积大小和裁剪次数,以及目标区域的裁剪概率。RC通过对原图像进行多次操作得到许多不同的图像,从而达到数据扩充的目的。经过裁剪后的图像,其尺寸有可能不相同,这种情况可以根据任务需求,将图像重新调整为与裁剪之前相同的尺寸。RC可以快速增加图像的数量和多样性,进而降低模型过拟合的风险。
2.2.1 图像的RC+RP
本文运用RC对每张初始图像进行2次裁剪,设定裁剪面积为原图像的80%,并且将裁剪图像重新调整为原图的尺寸。最后,采用RP对2张裁剪图像分别进行2次零填充。因此,经过RC+RP操作后,1张初始图像扩充为4张,而初始样本被增广为N2 = 6 000、12 000、18 000。原图经过RC+RP操作后的实例如图3所示。
2.3 随机翻转
图像翻转包括:镜像翻转(左右翻转)、垂直翻转(上下翻转)、镜像加垂直翻转(左右和上下同时翻转),共3种翻转方式。而随机翻转(Random Flipping,RF) 是从3种翻转方法中随机选择,以增加图像样本数量,并提高图像特征的多样性。
2.3.1 图像的RF+RP
本文从3种RF方式中随机选择2种对初始图像进行操作,得到2张翻转图像,然后对每张翻转图像进行2次RP操作。因此,1张原图增广为4张。最终,初始样本被增广为N3 = 6 000、12 000、18 000。原图经过RF+RP操作后的实例如图4所示。
2.4 随机擦除
随机擦除(Random Erasing,RE) 是在图像中随机选择一个矩形区域进行擦除,用0像素值代替擦除区域的像素值。这种技术可以对同一张图像进行多次擦除操作,产生许多具有不同遮挡程度的图像,从而达到数据扩充的目的。RE的优点在于其实现难度低,属于轻量级的技术,并且不需要模型参数学习。此外,增加RE处理的图像可以降低模型过拟合的风险,提高模型对遮挡图像的鲁棒性。
RE的实现过程并不复杂。首先,根据输入图像的宽度W和高度H,计算出图像的面积A = W×H;然后,需要定义最小擦除面积比例sl和最大擦除面积比例sh,以避免出现无效擦除和过度擦除的情况。随机从[sl,sh]之间取值,可得到初始化擦除面积Se。最后,定义擦除面积的最小长宽比re,则擦除面积的高为He = (Se×re)1/2,宽为We = (Se / re)1/2。根据这些参数设置,可以实现随机选择图像的擦除面积和擦除位置。
2.4.1 图像的RE+RP
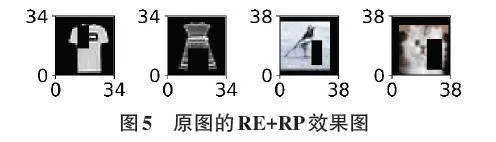
本文对初始样本进行2次RE操作,然后使用RP对每张被擦除的图像进行2次RP操作,使1张原图扩充为4张。因此,初始样本被增广为N4 = 6 000、12 000、18 000。原始图像经过RE+RP操作后的实例如图5所示。
2.5 训练集与测试集
Fashion-MNIST和CIFAR-10数据集的小样本经过RP、RC+RP、RF+RP、RE+RP的操作之后,初始样本数量从开始的1 500、3 000、4 500个,分别扩充为N1 + N2 + N3 + N4 = 24 000、48 000、72 000,即每张原始图像按照1:16的比例进行了数据扩充。由于随机填充改变了图像的原始尺寸,两个数据集的扩充样本尺寸分别为34×34和38×38。这些经过一整套低成本数据增强方案得到的增强样本,会根据不同的初始样本情况,分别用于模型的训练。
另外,为了证明数据增强方案的有效性,本文还研究了在没有采用数据增强方案的情况下,直接将1 500、3 000、4 500个初始样本用于模型训练的情况。然而,Fashion-MNIST数据集的初始样本尺寸只有28×28,这个图像尺寸会导致VGGNet-13网络无法完成卷积和池化过程。因此,在研究这一问题时,本文对Fashion-MNIST的1 500、3 000、4 500个初始样本采用传统的0填充方式,将图像尺寸从28×28增大至34×34。
为了更好地验证模型的泛化性能,本文将Fashion-MNIST和CIFAR-10数据集中的10 000个测试样本用于模型测试,计算模型的准确率。由于两个测试集的样本尺寸分别为28×28和32×32,无法直接用于测试,这是因为训练样本的尺寸已经被改变。因此,本文将Fashion-MNIST和CIFAR-10数据集中的测试样本全部进行传统0填充,将图像尺寸分别增大至34×34和38×38。
3 模型结构与实验
3.1 卷积神经网络
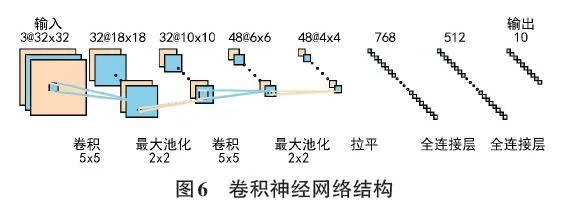
卷积神经网络的结构包括输入层、卷积层、池化层、全连接层和输出层,如图6所示。输入是单通道的灰度图像或三通道的彩色图像。卷积是一种特殊的线性运算,根据设置的卷积核数量和大小对输入图像进行卷积操作,得到特征图,再经过非线性激活函数运算,即为卷积层的输出。卷积操作之后一般进行池化操作。池化层通过指定池化大小对卷积结果做进一步处理,这个步骤可以降低特征图的维度,减少网络参数。卷积和池化操作结束之后,需要将特征图拉平成一维,成为全连接层的输入。全连接层对特征向量进行计算,最终实现分类的目的。
VGG和ResNet模型是较为流行的卷积神经网络,由于其结构的创新设计,在图像分类方面取得了较好的成绩。本文选择了VGGNet-13和ResNet-18这两个在各自系列中相对不太复杂的模型,它们的参数量相对较少。而且,通过对比两种不同网络结构的模型,可以检验本文整合的数据增强方案对不同模型的适应性。
3.2 模型超参数设置
本文对VGGNet-13和ResNet-18模型的原始超参数和网络结构进行了调整。VGGNet-13模型的两个全连接层部分,神经元数量由原始的4 096分别调整为512和128。ResNet-18模型的第一个卷积层,其卷积核大小由原来的7×7调整为3×3,步长(stride) 由原来的2调整为1,并删除了3×3的最大池化(maxpool) 。
为了提高模型的泛化能力和收敛速度,VGGNet-13和ResNet-18模型都加入了Batch Normalization操作。批次大小设定为128,训练轮数(epochs) 设定为15,并且加入了dropout以降低过拟合风险。模型的损失函数选择SparseCategoricalCrossentropy,度量方式采用准确率。优化算法方面,VGGNet-13采用的是Adam,学习率为0.01;ResNet-18采用的是SGD,学习率为0.1。
3.3 实验结果和分析
本文首先研究了Fashion-MNIST数据集。针对1 500、3 000、4 500个样本的初始状态,均采用同一套数据增强方案对小样本进行数据扩充。将无数据增强的初始样本和数据增强样本分别用于VGGNet-13和ResNet-18模型的训练。经过15次迭代后,在10 000个样本的测试集上验证模型的泛化性能。实验结果如表1所示。
结果表明,直接使用1 500个初始样本进行训练,模型测试的准确率只有0.10。然而,采用经过数据增强方案得到的24 000个样本进行训练,模型测试的准确率最高可以达到0.87,两者相差了0.77,远高于没有采用数据增强方案的模型。此外,使用3 000和4 500个初始样本进行训练,模型的测试准确率依旧偏低。使用48 000和72 000个数据增强样本进行模型训练,发现在测试集上的准确率最高可达0.90。
表1的结果证明,在Fashion-MNIST数据集的小样本困境下,本文整合的数据增强方案不仅可以快速地增加样本数量,而且还增加了样本特征的多样性。这些样本可以有效地提高模型的泛化性能,降低过拟合风险,提高模型的鲁棒性。表1还展示了VGGNet-13和ResNet-18两个不同模型的研究结果,发现2个模型都具有较高的准确率。
为了进一步验证本文的数据增强方案在其他数据集的小样本问题上是否依然具有提升模型准确率的能力,本文还研究了CIFAR-10数据集。VGGNet-13和ResNet-18模型经过15次迭代,在测试集上的准确率如表2所示。
结果发现,直接使用1 500个初始样本进行训练,模型测试的准确率最高只有0.18。而采用经过数据增强方案得到的24 000个样本进行训练,模型测试的准确率最高可以达到0.52,两者相差了0.34,同样高于没有采用数据增强方案的模型。使用72 000个数据增强样本进行训练,学得模型在测试集上的准确率最高为0.69。虽然0.69的准确率并不算高,但本文旨在研究数据增强方案的有效性。
表2的结果说明了CIFAR-10数据集的小样本,经过本文整合的数据增强方案,依旧可以提升模型在测试集上的准确率。而随着初始样本数量的增加,模型的准确率显著上升。要想进一步提升模型在测试集上的准确率,需要增加初始样本数量,以及增加兼容的数据增强方法。
4 结论
本文将随机填充、随机裁剪、随机翻转、随机擦除这4种数据增强方法融合为一套数据增强方案,并对其有效性进行了系列验证。通过分析表1和表2的计算结果,发现该方案可以提高模型测试的准确率,即使变换数据集和神经网络结构,模型的测试精度依然有较好的提升,证明了该方案的有效性。本文的研究可以为其他图像分类的小样本问题提供参考方案。
该方案尚有不足之处,如模型测试的准确率还有提升空间、可以增加其他兼容且互补的数据增强方法等。在未来的工作中,将对这些不足之处进行进一步研究。
参考文献:
[1] LECUN Y,BOTTOU L,BENGIO Y,et al.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278-2324.
[2] 张珂,冯晓晗,郭玉荣,等.图像分类的深度卷积神经网络模型综述[J].中国图象图形学报,2021,26(10):2305-2325.
[3] ABDEL-HAMID O,MOHAMED A R,JIANG H,et al.Convolutional neural networks for speech recognition[J].IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014,22(10):1533-1545.
[4] 卢宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016,31(1):1-17.
[5] 梁路宏,艾海舟,徐光祐,等.人脸检测研究综述[J].计算机学报,2002,25(5):449-458.
[6] 赵凯琳,靳小龙,王元卓.小样本学习研究综述[J].软件学报,2021,32(2):349-369.
[7] 孙书魁,范菁,孙中强,等.基于深度学习的图像数据增强研究综述[J].计算机科学,2024,51(1):150-167.
[8] TAKAHASHI R,MATSUBARA T,UEHARA K.Data augmentation using random image cropping and patching for deep CNNs[J].IEEE Transactions on Circuits and Systems for Video Technology,2020,30(9):2917-2931.
[9] ZHONG Z,ZHENG L,KANG G L,et al.Random erasing data augmentation[J].Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):13001-13008.
[10] YANG N,ZHONG L C,HUANG F,et al.Random padding data augmentation[M]//Communications in Computer and Information Science.Singapore:Springer Nature Singapore,2023:3-18.
[11] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[EB/OL].2014:1409. 1556.https://arxiv.org/abs/1409.1556v6
[12] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:770-778.
【通联编辑:唐一东】
