基于主题偏好的数字图书馆个性化检索算法研究
2024-09-14樊伟红郑聪
摘要:由于当前数字图书馆所采用的个性化检索算法缺乏对用户喜好的有效聚类分析能力,致使用户难以准确、迅速地获取其所需信息。因此,文章设计了基于主题偏好的数字图书馆个性化检索算法。该算法利用向量空间模型对用户的主题偏好进行深入挖掘并赋值。随后,采用TF-IDF算法作为图书指标权重的计算方法,对赋值后的聚类结果进行处理,以此作为图书的类别标签。运用Multi-Agent模型构建了相应的图书个性化检索模型,旨在提升数字图书馆系统的检索效率。为了验证所提方法的有效性,设计了对比实验环节。通过将所提方法与传统方法进行对比,结果显示:所提方法的检索结果误差率更低,结果弹出率更高,且结果输出时间更短。这些优势表明,所提方法的使用效果相较于传统方法具有显著提升,进一步证明了该方法在实际应用中的更高价值。
关键词:数字图书馆;主题偏好;个性化检索;Multi-Agent模型;向量空间模型
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2024)23-0017-04
开放科学(资源服务)标识码(OSID)
0 引言
至今,数字图书馆的定义还没有得到一个准确的、具有共同认知的定义[1-2]。从宏观进行分析,数字图书馆是图书馆内由计算机处理的数字信息仓库,可使用数字技术进行信息资源组织与管理,为用户提供便利的图书馆功能与服务[3-4]。在数字图书馆服务中,个性化检索是其主要功能之一。所谓的个性化检索是根据用户的兴趣特点,向用户推荐其感兴趣信息的信息搜索方式,其原理是根据用户喜好内容为其推荐匹配信息。随着用户数量的逐渐增多,需要对用户的需求信息展开研究。因此,相关学者提出了大量方法以解决信息检索问题。
文献[5]设计了一个基于大数据分析技术的数字图书馆信息检索模型,采集数字图书馆信息检索历史数据,引入大数据分析技术构建信息检索模型,通过实例验证所设计模型的优越性。结果表明,该方法能够针对性地对需求信息进行检索,但是在面向海量数据信息时,存在结果输出时间较短的问题。文献[6]提出一种基于递归神经网络与注意力机制的动态个性化搜索算法,采用递归神经网络建立用户个性化偏好模型,根据用户兴趣的动态性建立模型,通过注意力机制对历史用户行为进行加权处理。运用用户模型得到信息查询与文档之间的相关度得分,获取个性化排序结果。实验结果表明,该算法能够取得较好的个性化搜索结果,但是存在检索结果误差率较低的问题,并且用户喜好划分能力不强。除此之外,文献[7]提出了基于数据挖掘技术的图书馆个性化快速推荐算法,通过改进的Apriori算法分析图书借阅历史数据,分析数据之间的关联性,从而实现个性化推荐。实验结果表明,该算法具有较快的结果输出速度,但是在结果弹出率方面还有待加强。
根据上述分析可知,传统方法的使用效果并不能为用户提供满意的服务。为此,在此次研究中将根据用户对于书籍内容的主题偏好对个性化检索服务展开优化,设计基于主题偏好的数字图书馆个性化检索算法。在此次研究结束后进行对比实验,验证此次研究中设计方法在实际使用中的可行性与科学性。
1 数字图书馆个性化检索算法设计
在本次研究前,对目前使用的数字图书馆个性化检索算法进行了系统且全面的分析,通过分析结果可以发现,当前使用的数字图书馆个性化检索算法具有计算速度缓慢、用户喜好划分能力较低的问题。针对上述问题,在此次研究中将设定用户主题偏好挖掘模块,并从整体化方向提升数字图书馆个性化检索算法的使用效果。
1.1 用户主题偏好挖掘
通过文献研究可知,在用户使用搜索引擎时,关键词输入是用户的显性需求,由于词汇输入的准确性、用户描述的规范性等问题,使用此种方式得到的搜索结果往往达不到用户的搜索要求。因此,在本次研究中主要对用户的搜索主题偏好进行挖掘分析。使用向量空间模型[8]对用户主题偏好进行表示,在数字图书馆系统中建立[N]维的主题向量空间:[[(s1,r1),(s2,r2),...,(sn,rn)]]。其中,[sn]表示第[n]个搜索关键词,[rn]表示用户在[sn]上的偏好程度,[i∈1,2,...,n]。使用此设定可得到的用户主题向量的偏好内容可表示为:
[R=(r1,r2,...,rn)] (1)
使用式(1) 对用户操作日志进行分析,得到该用户在此阶段的主体偏好[rd]。由于在用户的操作过程中含有大量的浏览、下载、收藏等操作,其中包含了用户的很多喜好信息,为了得到更加精确的用户喜好信息,构建相应的日志分析模块,获取用户操作内容集合,则有:
[Rd=(rd1,rd2,...,rdn)] (2)
使用式(2) 统计用户的访问与搜索频率,对不同的操作内容进行权重计算,并进行对应的加权处理得到此关键词的访问频率,即可得到用户在此主题上的访问情况,将此作为用户的主体偏好程度,并将其体现到向量空间中,从而得到用户的主题偏好向量,具体表示如下。
[Rd=(r1,r2,...,rn)] (3)
仅使用上述公式完成分析过程是具有一定局限性的,因为在用户的搜索过程中会出现输入不规范、输入内容不当等问题,同时在上述公式的使用过程中会出现噪声影响或者遗漏等问题。因而,根据上述公式设定结果,使用Canopy算法[9-10]这种低成本的聚类算法对用户的主体偏好进行计算处理,则用户最终主题偏好可体现为:
[A=α×Gd+β×Ggroup] (4)
式(4) 中,[Ggroup]表示用户群主体偏好,[Gd]在此公式中与[Rd]等价。使用此公式可得到各阶段的用户偏好向量,对其进行赋值,可得到准确度更高的偏好向量聚类结果。使用上述公式对数字图书馆中的数据进行处理,并将处理结果作为后续操作对象。
1.2 设定图书信息标签
对使用上文处理后的数据进行标签聚类处理,在此环节中,使用TF-IDF算法[11-13]作为图书指标权重算法。设定[TF]表示图书标签与图书之间的相关程度,如果图书中出现的某一种标签较多,则图书与这一标签的相关度越高。则图书[p]中标签[bi]的[tfi]可表示为:
[tfi=ni,ji=1nbi×ni,j] (5)
式(5) 中,[ni,j]表示图书[bi]被标签[p]标注的次数,分母则是图书[bi]被所有标签标注的次数总和。通过文献研究可知,IDF表示一个标签对图书集合的普遍性权重[14-15],如果此标签在图书中使用的次数越多,则此标签可能描述了图书的多种特征,不具备代表性,权重计算结果可信度较低。则标签[fi]的[idfi]计算过程可表示为:
[idfi=lgYj:fi∈ni,j] (6)
式(6) 中,[Y]表示图书馆系统中的图书种类总数,分母表示被标注过的图书数目。如果使用的标签是不存在的,则可将分母视作0,针对此特殊情况,分数可适度额外增加1。最后,将式(5) 与式(6) 结合,得到最终的指标权重,具体公式如下所示。
[hij=idfi×tfi] (7)
使用上述公式,得到图书信息标签权重信息,并选择合适的标签聚类算法对其进行处理,在此研究中选用C均值聚类算法对其进行处理,为了提升使用效果,设定标签向量[j]与标签向量[k]之间的函数距离计算公式如下所示:
[dist(j,k)=1-k∈ynlj×lkk∈ynlj2k∈ynlk2] (8)
式(8) ,[dist(j,k)]表示上述两标签向量之间的函数距离,使用此公式对图书信息标签进行处理。在此次研究中,为了更好地完成聚类处理过程,将设定固定的迭代处理次数,并选择每个迭代过程中的最小值作为距离标准。
1.3 实现图书个性化检索
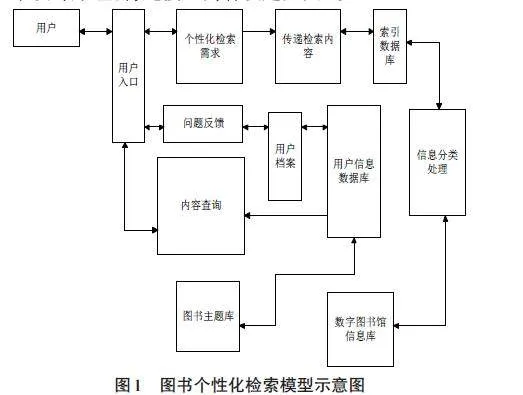
在上述设计中,完成了文中设计方法的基础设计部分,在此部分中将对上述设定部分进行综合处理,实现图书个性化检索。根据数字图书馆系统中检索信息的分布性特点,可知其内部空间信息具有空间上与功能上的分布性。为了提升检索速度,此次研究中使用Multi-Agent模型[16-17],构建对应的图书个性化检索模型。为了保证此模型的使用效果,根据软件工程学设计原理,将此模型内容设定如图1。
根据图1,构建相应的检索模型并将其应用到数字图书馆系统中,并将系统中的二元变量分为两类,将此两类数据在系统中的数据库记录设定为[q]与[w],通过计算相异度的形式,得到图书馆系统可提供的主题个数。图书馆系统中的图书主题具有多种,用户只能搜索到其中的一小部分,用户与图书馆系统中的图书种类呈现出不对称变量的形式,以此可以使用Jaccard系数来衡量用户可检索内容。由于图书馆系统中多使用互联网技术作为依托,为了使此次研究结果的使用效果更佳,除上文中设计的主体偏好挖掘技术之外,还应将用户画像技术应用至此次研究设计方法中,实现数字图书馆的个性化服务。
将文中设计内容有序融入传统方法中,通过局部优化的方式,对传统方法进行整体化性能提升,以此保证文中设计方法的使用效果。至此,基于主题偏好的数字图书馆个性化检索算法设计完成。
2 实验分析
2.1 实验环境设计
在此次研究中完成了基于主题偏好的数字图书馆个性化检索算法的设计部分,在此环节中将对文中设计方法的计算效果进行分析。在此次研究中主要使用算例对比的方式,使用文中设计方法与文献[5]基于大数据分析技术的数字图书馆信息检索模型(传统方法1) 和文献[6]基于递归神经网络与注意力机制的动态个性化搜索算法(传统方法2) 进行对比。
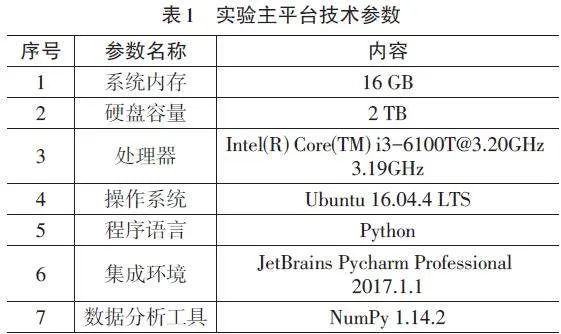
通过文献研究可知,在数字图书馆中含有大量的图书数据,且外界因素会对检索结果造成一定的影响,因此,将实验平台设定如表1。
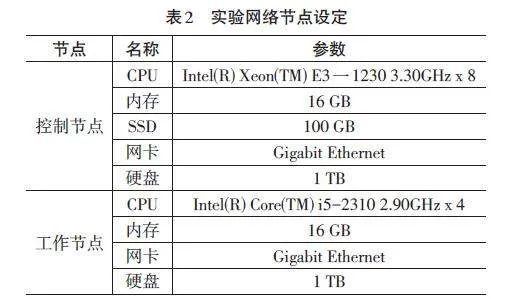
通过上述参数组建此次实验平台,并将其应用到文中设计方法与传统方法的对比过程中。由于数字图书馆的运行过程中涉及大量的网络控制部分,因此,将实验平台搭建为Hadoop分布式平台的形式,以此提升实验对比过程中的运算效果。在此实验网络共计4个节点,节点设备参数设定如表2。
将实验平台安装至此实验网络中,为实验过程提供硬件与技术支持。
2.2 实验方案设计
在此次实验过程中,将对数字图书馆中的300名用户在为期1年内的操作日记进行分析,并使用文中设计方法与传统方法对其主题喜好进行挖掘,并将此部分数据使用到个性化检索中。为了对文中设计方法与传统方法的使用效果进行全面细致的对比,将实验对比指标划分为3部分,首先为DCG指标,此指标主要表示文中设计方法与传统方法在个性化检索过程中的质量,通过检索结果的误差率表示。其次为个性化检索有效性,通过检索结果的弹出率表示。最后一组指标设定为检索结果输出时间,通过此指标验证文中设计方法与传统方法在使用中的计算速度。此次实验中,对上述指标共进行周期为50次的对比实验,具体实验结果将通过数据与图像的形式输出。
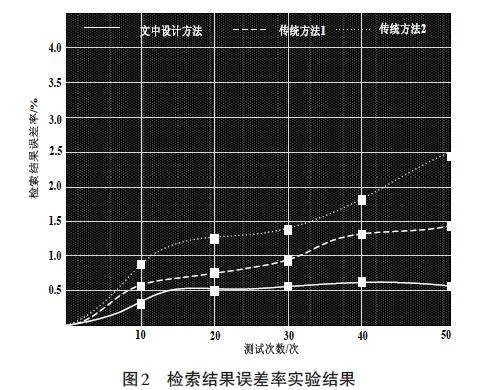
2.3 检索结果误差率实验结果分析
通过上述实验结果可知,在使用文中设计方法后得到的检索结果误差率较低,可达到用户的检索精度要求。传统方法在使用后得到的检测结果误差率较高,无法达到用户的检索精度要求。同时,通过对上述实验结果进行系统分析可以看出,文中设计方法的检索精准度较高,是由于在检索过程中,文中设计方法将用户的主题偏好作为搜索的主要约束条件,以此保证检索结果符合用户的搜索精度要求。传统方法在使用过程中,仅根据用户输入内容进行检索,所得到检索结果与用户的预计检索结果具有一定差异,由此造成了使用传统方法进行检索后,结果误差率较高的问题。因此,在日后的研究中,应将用户主题偏好以及用户喜好聚类作为研究的重点,以提升检索方法的使用效果。
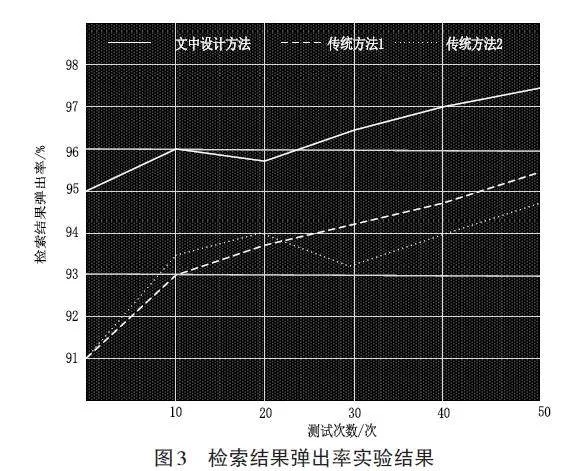
2.4 检索结果弹出率实验结果分析
由图3可以看出,使用文中方法后检索结果的弹出率较高。对其数据进行分析可知,文中设计方法的检索成功率较高,且检索结果较为有效。使用传统方法后,检索结果的弹出率明显低于使用文中设计方法。对实验结果进行系统分析后初步了解到,由于传统方法对于用户的喜好分析能力较差,导致检索结果中多呈现异常,直接影响了检索结果的弹出率,无法为用户提供满意的检索结果;文中设计方法在检索的过程中,对于用户的喜好进行了精准的分析,由此提高了检索方法的使用效果。针对上述实验结果可以断定,文中设计方法的使用效果优于传统方法。
2.5 检索结果输出时间实验结果分析
通过图4可知,文中设计方法的检索结果输出时间较短,传统方法的解锁结果输出时间较长。此结果表明,文中设计方法的检索速度明显高于传统方法,在相同时间内使用文中设计方法,可得到更多的检索结果。由此可见,文中设计方法在使用主题偏好聚类技术后,其使用性能得到了明显提升,而传统方法使用的计算部分较为落后,直接影响了传统方法的使用效果。综合上述实验结果分析内容,可以确定,文中设计方法在使用后,用户满意度会明显高于传统方法。
对上述3部分实验结果进行综合分析后可知,文中设计的检索算法使用效果优于传统检索算法在日后的研究中可使用此算法作为图书馆个性化推荐服务中的主要运行程序。同时,在日后的检索算法研究中,应将用户的个人信息作为数据的来源与分析的主要内容。
3 结束语
目前,数字图书馆的信息资源管理建设已经取得较好的成果,但其个性化服务还需要进行进一步完善。此次研究将主题偏好挖掘分析技术应用到用户的个性化搜索中,提升了数字图书馆个性化服务的智能化发展。但由于此次研究时间较短,导致其在某些方面还存在相应不足,在日后的研究中还应对其不足之处加以优化升级,为图书馆用户提供更加便利的服务,推动数字图书馆个性化服务的可持续化发展。
参考文献:
[1] 吴谈,周栋,包恒泽.基于用户类别兴趣偏好的个性化排序方法[J].湖南科技大学学报(自然科学版),2020,35(1):104-112.
[2] 黄进,周栋.一种融合社会化标注系统中主题域相似的个性化排序方法[J].计算机工程与科学,2018,40(5):880-887.
[3] 张妤,孟兰,孙成东,等.浅析农业科研单位图书馆个性化信息服务:以吉林省农业科学院图书馆为例[J].东北农业科学,2020,45(5):112-114,131.
[4] 王军,王蕴洁,丁立宁,等.新媒体环境下高等院校图书馆个性化 信息服务对策研究[J].黑龙江工程学院学报,2019,33(1):63-66,80.
[5] 王均玲.大数据分析技术的数字图书馆信息检索模型设计[J].现代电子技术,2020,43(17):155-157,161.
[6] 周雨佳,窦志成,葛松玮,等.基于递归神经网络与注意力机制的动态个性化搜索算法[J].计算机学报,2020,43(5):812-826.
[7] 王庆桦.基于数据挖掘技术的图书馆个性化快速推荐算法研究[J].现代电子技术,2019,42(5):149-151,156.
[8] 张强,王国军.个性化搜索中一种基于位置服务的隐私保护方法[J].电子与信息学报,2018,40(8):1998-2005.
[9] 李莉.基于多Agent技术的数字图书馆个性化信息服务检索模型研究[J].情报科学,2018,36(5):90-93,98.
[10] 严锐,李石君.基于查询意图识别与主题建模的文档检索算法[J].计算机工程,2018,44(3):189-194.
[11] 毛文山,赵红莉,孙凤娇,等.基于Item2Vec负采样优化的专题地图产品个性化推荐方法研究[J].地球信息科学学报,2020,22(11):2128-2139.
[12] 郑蕊,杜荣花.数字人文时代高校图书馆蒙古学学科服务升级研究:以内蒙古高校图书馆为例[J].呼伦贝尔学院学报,2020,28(1):102-106.
[13] 范宇.基于大数据的高校图书馆个性化服务路径[J].吉林化工学院学报,2019,36(12):67-70.
[14] 孙琪.基于智能过滤技术的数字图书馆个性化信息推荐服务研究[J].中国中医药图书情报杂志,2020,44(6):22-24.
[15] 邵丝媞.基于空间信息支持的图书馆个性化资源集成系统设计[J].现代电子技术,2019,42(18):112-115,119.
[16] 李云畅.大数据时代高校图书馆检索服务系统经验借鉴[J].内蒙古财经大学学报,2019,17(4):138-140.
[17] 李春刚.探索大学图书馆文献资源检索利用技巧[J].大学图书馆学报,2019,37(4):127.
【通联编辑:代影】
