基于Transfomer的会话推荐方法
2024-09-14王波邓新荣黄万来



摘要:基于会话的推荐旨在从当前会话和以往的匿名会话中预测用户的下一个行为。在基于会话的推荐系统中,捕获项目之间的长期依赖关系是一个至关重要的挑战。本文提出了一种基于Transformer架构的会话推荐方法。具体来说,通过Transformer的编码器部分捕获会话中所有项目之间的全局依赖关系,而不考虑它们之间的距离。本文的模型将嵌入层中得到的嵌入向量传输至注意力机制进行聚合,最终通过预测头预测当前会话的下一推荐项目。笔者在开放的基准数据集上进行了实验,实验结果表明,本文提出的方法展现了良好的效果。
关键词:会话推荐;注意力机制;推荐系统
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2024)23-0001-04
开放科学(资源服务)标识码(OSID)
0 引言
面对人们生活中的海量信息,如何从海量数据中获取有效信息成为一个迫切需要解决的问题。推荐系统可以为不同的用户提供个性化的推荐,使得每个用户都可以从推荐系统筛选的有限的、多样的信息中获得他们想要的信息。
传统的推荐系统通常利用丰富的用户信息来模拟用户偏好并推荐用户可能感兴趣的项目。换句话说,每个用户必须有足够的交互记录,并且用户身份必须在每个交互事件中可见。然而,在许多在线系统中,例如电子商务网站和大多数新闻媒体网站,推荐系统只能依靠当前会话信息来提供准确的推荐,因为新用户的身份以及未登录的用户是未知的,这使得历史信息在这些场景中不可用。为此,基于会话的推荐系统对如何为新用户提供准确的推荐做了大量的研究。
早期基于会话的推荐工作主要集中在发现项目间的关系,如转移关系和共现关系。典型方法如ItemKNN[1]和马尔可夫链[2]依靠会话中的最后一个元素来产生建议。然而,仅仅依赖会话的最后一个元素并不能在整个会话中反映用户的兴趣。由于深度学习在各个研究领域取得巨大进展,越来越多的深度学习模型用在了会话推荐中,它们习惯将会话中的一系列点击建模为一个序列,并利用神经网络来建模整个动作序列。例如,GRU4Rec[3]将递归神经网络应用于基于会话的推荐,并将该问题视为时间序列预测。又如SR-GNN[4]将会话建模为图形,以捕捉复杂的项目交互。然而,众所周知,由于梯度消失和爆炸问题,RNN呈现出很难训练的缺点[5]。像LSTM和GRU这样的各种变体缓解了上述问题,但仍然难以捕捉长期依赖性。
随着Transformer[6]在近几年的爆火,其在推荐任务中实现了较为可观的性能和效率。与基于RNN的方法不同,Transformer允许模型访问历史的任何部分,而不管距离远近,这使得它可能更适合于捕捉具有长期依赖性的会话模式。本文选择了Transformer模型的编码器部分作为模型的框架,实现了一种较为高效的自注意力网络会话推荐方式。本文的主要贡献如下:
1) 实现了一种基于Transformer架构的会话推荐方法,该模型能够捕获并保留所有项目之间的完全依赖关系,而不管它们的距离如何。
2) 在生成基于会话的推荐过程中,上述方法能够较好地提取出项与项之间的共现关系,对后续研究有引导作用。
3) 本文这种相对简单的方法在公开数据集上取得了不错的效果,具有一定的实际应用意义。
1 相关研究
会话推荐作为一种重要的个性化推荐技术,旨在根据用户在会话中的隐式反馈为用户进行相应的推荐预测,以增强用户体验和满足其个性化需求。以往的推荐系统主要关注单个项目或商品的推荐,而会话推荐则更关注推荐一系列相关项目或话题,从而可以更好地满足用户在会话过程中的连续性需求。
传统的基于会话推荐方法,使用较为广泛的有矩阵分解方法[7] (Matrix Factorization)和马尔可夫链的方法[8] (Markov Chains)。这两种方法的核心思想是利用用户的历史行为数据来预测可能引起其兴趣的交互项目。因此,为了实现这一目标,首先需要获取用户的历史行为数据,并以此为基础进行分析和预测。这在一定程度上,使得预测较为依赖用户-物品矩阵中的用户评分,若缺失对应评分或者无法有效建模序列中的上下文信息等问题,都将不能有效完成推荐任务,因此在实际会话推荐中的效果欠佳。
最近,神经网络和基于注意力的模型在基于会话的推荐系统中很受欢迎。GRU4Rec[3]首创并利用了会话并行训练的小批量技术,这是GRU首次被用于处理基于会话的推荐系统。此外,文献[9]的研究通过融合带注意力机制的编码器来对用户的历史行为顺序进行分析,并抓住用户在当前会话中的关键意图。STAMP[10]通过应用网络和关注网络捕捉用户的一般和当前兴趣。SR-GNN[4]将会话建模为图形结构,以捕捉复杂的项目交互,同时通过注意力机制将用户的全局偏好和当前兴趣结合起来,这些方法都为会话推荐带来了新的启示。自从Transformer[6]在自然语言处理领域表现出优异的性能以来,自注意机制被广泛用于对序列数据建模,并在推荐系统中取得了显著的效果,文献[11-13]等工作实现了基于Transformer架构的会话推荐方法,但大多过于复杂,显得较为臃肿。我们在参考上述结构的基础上,通过一种简单的方式实现了会话推荐。
2 模型
2.1 问题描述
基于会话的推荐系统基于当前用户会话数据进行预测,因此仅需考虑当前会话中的项目。定义一个项目集合[V],其包含所有会话中出现的不同项目,记作[V={v1,v2,...,vv}]。匿名会话系列则可以表示为一个列表[S],记作[S=s1,s2,...,sn],这里的[si]属于集合V,代表用户在会话[S]中点击的项目。针对基于会话的推荐系统,其目标是预测出序列S的下一点击项[sn+1]。笔者设计并训练了一个模型,这个模型以分类器的形式出现,它的任务是为集合[V]中的每个可能选项打分。输出分数向量用[Y]表示,记作[Y={y1,y2,...,yn}],这里的第[i]项即为与项目[vi]相对应的得分。模型将会根据这些预测分数,挑选得分最高的k个项目作为推荐候选。
2.2 模型总览
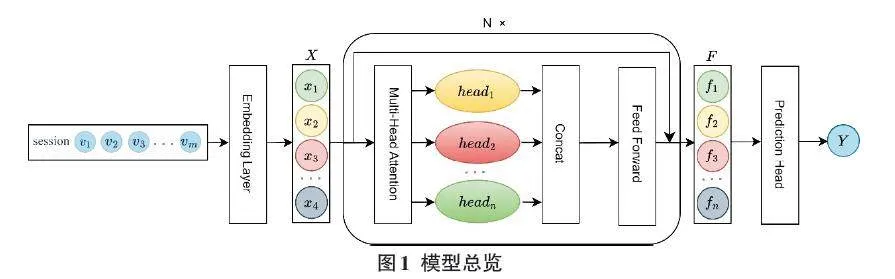
对于会话推荐任务,充分挖掘项目之间的依赖关系是进行推荐的关键所在。本文提出基于Transformer的会话推荐模型,该模型架构分为三个部分:(1)数据输入和嵌入层;(2)Transformer架构,包括注意力块、多头注意力、前馈网络等部分;(3)偏好概率输出。模型架构如图1所示。
模型流程可概述为:将交互集[S={v1,v2,…,vm}]映射到嵌入向量空间为[X={x1,x2,…,xm}],通过Transfomer层后输出为当前会话对于所有物品的偏好概率分布[Y={y1,y2,…,yv}],其中得分最高的Top-K个物品即被选择为推荐项目。以下为各个部分的处理细节。
嵌入层:在数据处理过程中,通过对原始会话进行拆分的方式,增加相似会话提升对共现特征的学习效率。在嵌入层的过程中,设置了一个项目矩阵[M∈RI×d],通过嵌入层将交互集中的交互项转化为指定维度[d]的向量,即[vi∈Rd]。
[EmbS=MT×S] (1)
自注意力块:模型通过自注意力块来计算项目之间的关联程度。注意力机制可以定义为一种映射方式,它将一个查询向量与一系列键值对关联,产生一个输出向量。该输出是值向量的加权组合,权重则是根据查询与各个键之间的兼容性函数计算得出的。在模型中,[X]为项目嵌入集,输出的Attention可以反映出会话的共现依赖和意图。
注意力计算如下:
[Attention=softmaxXWQXWKTdXWV] (2)
式中:投影矩阵[wQ,wK,wv∈Rd×d],[d]为潜在维度,[d]为比例因子,在潜在维度[d]过高情况下,可以避免内积值过大。
多头自注意力:此机制使模型能同时捕获不同位置以及不同子空间表征的信息。这种方法的有效性已由先前研究所验证。在模型中,笔者并行使用了[h]个具有不同参数的独立注意力模型,允许不同的注意力头关注不同位置的信息,并将所有注意力模型的输出连接起来以生成最终值,这有助于捕捉到不同层次的共现信息。
[O=Concathead1,head2,…,headh] (3)
[headi(Attention)=sofimaxXWQiXWKiTdXWVi] (4)
式中:投影矩阵[WQi,WKi,WVi∈Rd×d],[headi]为单次注意力机制的输出结果。
前馈网络和残差连接:上述多头注意力的实现主要基于不同空间的线性投影。为了在模型中引入非线性能力和维度相互作用,自注意力机制的输出会被输入到前馈网络中。该网络采用点状前馈架构,并选择ReLU作为激活函数,进而实现非线性并允许不同隐藏维度之间的交互。同时,本文还使用了残差连接来充分利用低层信息,这在以往的工作中被证实是有效的[14]。
[F=ReLUOW1+b1W2+b2+O] (5)
式中[:W1],[W2∈Rd×d]是参数矩阵,[b1],[b2∈Rd]是偏置向量。
预测头(Prediction Head) :预测头本质是一个线性层,该映射操作由一个权重矩阵和一个可选的偏置项组成。在获得会话[S]中交互项目经过上述多头自注意力机制的最终输出[F]后,预测头将该高维度的特征表示映射到与项目集[V]种类相同的维度,并最终经过[softmax]函数输出概率。预测头用于生成每个项目的概率分布,将模型的表示与项目类别之间建立联系,从而实现对输出序列的建模和生成。
[Y=softmax(WpF+bp)] (6)
式中:[Wp,bp]为预测头的参数矩阵和偏置向量。此外,笔者在嵌入层和预测头共享权值来减轻过度拟合并减小模型大小。
3 实验
3.1 数据集及基线
为了验证模型的有效性,本文在公开的数据集Yoochoose和Diginetica上进行实验。Yoochoose数据集来自数据挖掘竞赛RecSys2015,由电子商务用户会话中的点击和购买事件组成。由于Yoochoose数据集较为庞大,笔者使用了Yoochoose1/64作为训练序列。此外,笔者还使用了来自2016年CIKM杯竞赛的Diginetica交易数据集。两个数据集的统计数据如表1所示。
为了验证本文提出的基于Transformer的会话推荐模型的性能,在实验中使用以下基线模型进行对比,并在上述两个数据集上评估本文模型与基线模型的效果:
1) POP。最基本的会话推荐方法,依据训练数据集中出现频率最高的条目来进行推荐。
2) S-POP。该会话推荐算法会选出当前会话中最频繁出现的互动项目作为推荐项。
3) Item-KNN。基于之前会话中用户点击的商品的相似度推荐产品,这里的相似度是通过计算商品间会话向量的余弦相似度得出的。
4) FPMC。这种方法采用序列预测技术基于马尔可夫链原理,通过结合矩阵分解与马尔可夫链理论,构建一个推荐系统模型,专门推荐接下来可能感兴趣的物品。
5) GRU4REC[3]。在会话推荐中采用RNN对用户序列建模,利用并行小批处理训练过程将会话拼接,使用基于排序的损失函数学习模型。
6) STAMP[10]。该模型整合了用户的长远兴趣和即时兴趣,形成了对会话的全面表征。
7) SR-GNN[4]。为了获得会话的特征表征,该模型应用图神经网络(GNN) 对会话内的项目序列构建成会话图结构,并利用注意力机制来提炼会话信息。
3.2 评价指标和损失函数
笔者采用准确率(Precision) 和平均倒置排名(Mean Reciprocal Rank, MRR) 作为评价指标,以便准确地比较基准模型的性能。
P@K:精准度指标在会话推荐系统中被广泛采用,用于衡量系统的预测正确性。精准度表示在排名前k的位置中有正确推荐项的测试案例所占的比例。在本文的实验中,笔者主要使用P@20的指标,具体定义如下:
[P@K=nhitN] (7)
式中:N为会话推荐任务中参与测试的项目总数,[nhit]表示在推荐的前[k]个排名项目中有会话需要项目的数量。
MRR@K:平均倒置排名用于衡量推荐系统在预测中的整体性能,特别关注正确推荐项目在序列中的位置。MRR指的是所有测试会话中,第一个被正确推荐项的倒数排名的平均值。当排名超过[k]时,倒数排名会被设置为0。在本文的部分实验中,笔者采用了MRR@20,具体定义如下:
[MRR@K=1Nv∈V1Rankvtarget] (8)
式中:[Rankv]为交互项目[vtarget]在总项目集[V]中的排名。
在训练过程中,笔者使用的损失函数为Top1loss。该损失函数在预测结果中仅选择置信度最高的检测结果作为正样本,而将其他检测结果视为负样本。已有的研究工作和笔者的实验均证明了这一损失函数的有效性。Top1loss定义如下:
[Ltop1=1Nsj=1Nsσrs,j-rs,i+σr2s,j] (9)
其中,[Ns]表示样本集中的样本数量,[rs,j-rs,i]表示预测得分之间的差值,[σ(·)]表示sigmoid函数。
3.3 实验结果
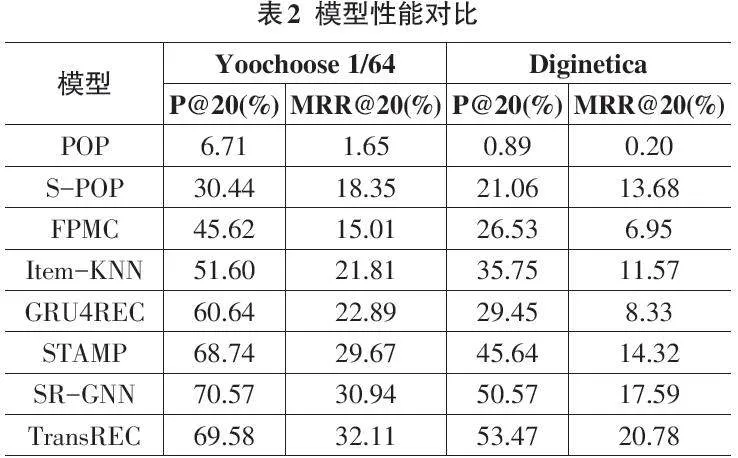
为进一步展示本文所提出基于Transfomer的推荐算法的性能,笔者最终确定了以下超参数:交互项目维度[d:256]、训练批处理大小[batchsize:64]、模型层数[n:2]、多头注意力头数[head:4]。在训练过程中,笔者使用小批量Adam优化器对这些参数进行优化。此外,由于数据集较为庞大迭代次数较多,笔者将训练的初始学习率[lr]设置为[10-4],并在经过若干轮迭代后,将学习率降至[5-4]和[10-5]。笔者对模型进行了与其他推荐算法或模型的性能比较,如表2所示。
从表1可以看出,本文提出的基于Transformer的会话推荐模型TransREC除了P@20指标外,其他指标均处于领先地位。这为本文所提出的推荐算法的有效性提供了有力的验证,初步证明了基于Transformer架构的推荐方法在会话推荐中的可行性。笔者进一步分析了随着轮次迭代,模型损失的变化情况,如图2所示。
笔者使用了30轮的训练数据作为分析对象。从图2中可以清晰地看出,随着训练轮数的增加,损失逐渐减小,验证损失也呈现出相似的趋势。在训练轮数达到15轮左右时,损失的下降空间逐渐变小,达到了一个亚饱和状态。笔者预计,随着后续训练轮数的逐步增加,损失的下降空间将进一步减少,最终可能会呈现出训练损失不断下降而验证损失逐渐上升的过拟合状态。
同时,笔者也分析了训练轮数对评价指标P和MRR的影响。从图3可以看出,对于两个不同的数据集而言,P和MRR两个指标同样在15轮左右达到最高值。对于Yoochoose64数据集而言,其指标在15轮以后保持了一个相对稳定的状态;而Diginetica数据集在达到最大值后,则呈现出性能逐步缓慢下降的情况。整体而言,笔者的模型在不同数据集上均取得了良好的训练效果且变化趋势相近。
4 结论
在本文中,笔者提出了一种基于Transformer架构的会话推荐方法。该模型通过注意力机制,在相对简单的架构下实现了项目与项目之间共现关系的捕获,完成了对会话中项目特征的学习和聚合,从而实现会话的下一项推荐。
在实验过程中,笔者将上述架构的模型与其他基线模型在Yoochoose64和Diginetica两个数据集上进行了性能对比,证明了其在会话推荐领域的可行性及性能的优异性。此外,笔者还通过分析训练轮数对模型损失函数及评价指标变化的影响,验证了本文方法的准确性。后续的研究可以进一步挖掘该方法在推荐任务上的潜力。
参考文献:
[1] LINDEN G,SMITH B,YORK J.Amazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[2] GARCIN F,DIMITRAKAKIS C,FALTINGS B.Personalized news recommendation with context trees[C]//Proceedings of the 7th ACM conference on Recommender systems.China.ACM,2013:105-112.
[3] HIDASI B,KARATZOGLOU A,BALTRUNAS L,et al.Session-based recommendations with recurrent neural networks[EB/OL].2015:1511.06939.https://arxiv.org/abs/1511.06939v4
[4] WU S,TANG Y Y,ZHU Y Q,et al.Session-based recommendation with graph neural networks[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33(1):346-353.
[5] PASCANU R, MIKOLOV T, BENGIO Y. On the difficulty of training recurrent neural networks[C]//International conference on machine learning.PMLR, 2013: 1310-1318..
[6]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017(30): 5998-6008.
[7] KOREN Y,BELL R,VOLINSKY C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[8] GU W R,DONG S B,ZENG Z Z.Increasing recommended effectiveness with Markov chains and purchase intervals[J].Neural Computing and Applications,2014,25(5):1153-1162.
(下转第13页)
(上接第4页)
[9] LI J,REN P J,CHEN Z M,et al.Neural attentive session-based recommendation[C]//Proceedings of the 2017 ACM on Conference on Information and Knowledge Management.Singapore Singapore.ACM,2017:1419-1428.
[10] LIU Q,ZENG Y F,MOKHOSI R,et al.STAMP:short-term attention/memory priority model for session-based recommendation[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.London United Kingdom.ACM,2018:1831-1839.
[11] LUO A, ZHAO P, LIU Y, et al..Collaborative co-attention network for session-based recommendation[C].//Proceedings of the 29th International Joint Conference on Artificial Intelligence (IJCAI), 2020: 2591-2597.
[12] SUN S M,TANG Y H,DAI Z M,et al.Self-attention network for session-based recommendation with streaming data input[J].IEEE Access,2019,7:110499-110509.
[13] FANG J.Session-based recommendation with self-attention networks[EB/OL].2021:2102.01922.https://arxiv.org/abs/2102.01922v1
[14] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:770-778.
【通联编辑:唐一东】
