基于Scrapy 的新能源汽车评论数据采集与情感分析
2024-09-03于波冯文雯于晓雨周维燕

摘要:本研究基于Scrapy爬虫框架从懂车帝网站上爬取新能源汽车评论数据,并进行了数据分析和情感分类。研究发现,用户对新能源汽车主要关注性能、续航能力、外观设计、购车体验和售后服务等方面。情感分析显示用户普遍持积极态度,但亦存在对价格和购车过程中的问题的不满。本研究为新能源汽车行业发展和市场需求提供了数据支持,为互联网时代大数据分析提供了一个实践案例。
关键词:新能源汽车;短评论;网络爬虫;数据分析;情感分类;可视化
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)19-0033-03
0 引言
在互联网时代,网络数据量呈现爆炸性增长的趋势。截至2023年12月,我国网民规模达10.92亿人,较2022年12月新增网民2 480万人,互联网普及率达77.5%[1]。在这个背景下,伴随着国内汽车行业的蓬勃发展,新能源汽车作为其中的主力军之一,吸引了大量消费者的关注。懂车帝网站作为汽车领域的重要信息交流平台,汇集了众多用户对不同新能源汽车的评论与观点。
然而,面对互联网上海量的文本数据,仅依靠人工筛选数据已不再现实。高效地从海量数据中提取有价值信息成了研究人员和企业关注的焦点。自动化网络爬虫技术因其在不同领域的广泛应用而备受瞩目。本文基于Python编写程序,采用Scrapy作为爬虫框架,从懂车帝网站上爬取当下新能源汽车的评论数据。通过对爬取的数据进行清洗与整理,提取其中的有价值信息,并运用可视化技术进行展示。同时,还对评论进行了情感分析,以探索用户对新能源汽车的态度与情感倾向。
本文旨在利用网络爬虫技术,探索并挖掘新能源汽车领域的用户评论数据,为汽车行业的发展和市场需求提供数据支持,同时为互联网时代大数据分析提供一个实践案例。
1 主要技术
1.1 爬虫原理
网络爬虫是一种基于获取不同URL的核心支撑,用于搜索和抓取该URL下的各种文章、链接和图片等内容的技术。在给定的URL中,网络爬虫会持续从中提取URL,并对当前URL的内容进行筛选和获取。当一个URL的内容被完全检索后,网络爬虫会自动转到下一个URL,重复这一过程,直到所有URL都被检索一次。在技术层面上,网络爬虫通过程序模拟浏览器请求站点的行为,将站点返回的数据(如HTML代码、JSON 数据或二进制数据)存储在本地,以供后续使用。根据不同的需求,网络爬虫可以针对性地进行爬取,并增加目标定义和过滤机制。
本文采用Scrapy爬虫框架进行数据采集。Scrapy 是一个基于Python开发的高层次、快速的网页抓取框架,用于抓取网站信息并从页面中提取结构化数据[2]。在数据挖掘、监测和自动化测试等不同场景下,Scrapy 具有广泛应用。
1.2 数据分析流程
数据分析是应用统计、计算机科学、机器学习和领域专业知识等技术和方法,对大量数据进行收集、清洗、处理和分析,以发现有意义的信息、趋势和模式,并从中获得见解,从而支持决策制定、问题解决和创新的过程。
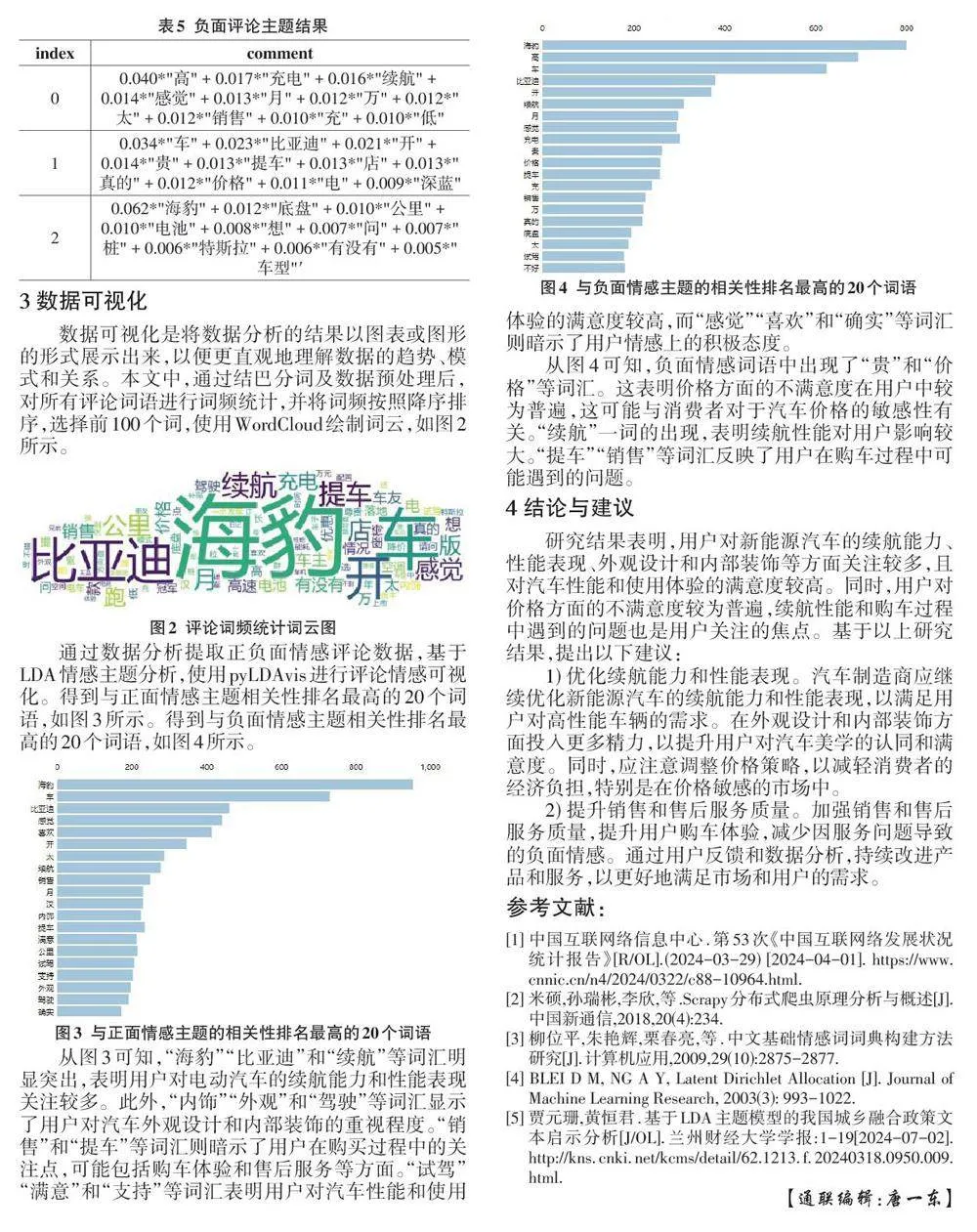
本文使用numpy、pandas、jieba分词、gensim、pyL⁃ DAvis、matplotlib 和wordcloud 等技术工具,对懂车帝比亚迪海豹新能源车的评论信息进行数据分析、情感分类及可视化。具体流程如图1所示。
2 功能实现
2.1 爬虫模块
我们根据懂车帝网站评论页面的URL结构,定义了URL规则。在URL中发现,每一个车型的汽车在 `/ community` 评论页URL之后的数字对应了每一个车型的汽车,每个车型汽车数字后面则为评论页页码。评论首页URL如下所示。
https://www.dongchedi.com/community/5579/1
通过构造相应的URL,循环生成并遍历每个URL来模拟浏览器翻页过程。本文设定爬取的目标页数为前400页,具体代码如下所示:
