基于ARIMA-LSTM 组合模型的工业生产车间粉尘浓度预测
2024-09-03彭涛赵生慧秦吉胜赵亮

摘要:在工业生产环境中,精确预测车间内的粉尘浓度对于确保工作场所的安全和产品质量至关重要,而该环境下单一的预测模型往往难以捕捉所有关键的数据特征。为了提高预测精度,该研究通过ARIMA模型提取数据的线性特征,使用LSTM模型拟合预测残差中的非线性特征,构建基于ARIMA-LSTM的组合预测模型。该模型采用均方误差(MSE) 、平均绝对误差(MAE) 和平均绝对百分比误差(MAPE) 作为评估指标。基于某厂生产车间的粉尘浓度时间序列数据进行实验评估,结果表明该模型的MSE、MAE和MAPE分别为0.74、0.66和3.29%,预测精度均优于单一的ARIMA模型,验证了模型的有效性和可靠性。
关键词:工业车间;粉尘浓度预测;ARIMA;LSTM;组合模型;时间序列
中图分类号:TP399 文献标识码:A
文章编号:1009-3044(2024)19-0009-05
0 引言
随着我国工业化的深入发展及转型升级,工业生产车间中的粉尘问题日益显著。在材料加工、机械操作、切割和磨削等过程中,一旦所产生的粉尘达到一定浓度,不仅可能威胁到车间作业工人的身体健康,引发尘肺病、呼吸系统疾病,而且可燃性粉尘还可能引起爆炸,造成重大安全事故[1]。此外,对于高精度产品制造车间而言,粉尘积聚还会污染生产设备的敏感部件,影响设备的稳定性和生产效率,从而降低生产线的整体产量和质量。目前,多数生产车间仍依赖传统的定点、定时手动采样分析方法,这种方法耗时且效率低,难以满足快速响应和预防措施的需求。因此,构建一个有效的粉尘浓度预测模型,用于了解车间环境下的粉尘浓度变化趋势,提前做出防治措施,对于解决工业车间生产过程中导致的粉尘问题具有重大的实际意义。
针对工厂生产车间环境下的粉尘浓度预测,目前的研究相对较少,但在露天矿和室外大气环境等领域已经积累了大量研究。传统的统计学习模型因其简易性和对时间序列数据特性的灵活分析能力而被广泛应用。例如,陈日辉[2]采用粉尘浓度数据建立的GM(1,1) 模型在矿井粉尘浓度预测中展现出较低的预测误差。王月红等[3]基于某矿的粉尘浓度时间序列,使用ARIMA(1,2,1) 模型进行预测,相对误差控制在10% 以内。王志建等[4]利用AR(1) 模型分析并成功预测了蚌埠市2018至2019年的PM2.5日浓度,误差同样低于10%,验证了模型的有效性。然而,现实中的粉尘序列通常具有非线性特征,尤其是在复杂的工厂生产车间环境中,传统的统计学习模型通常是线性模型,处理具有非线性特征的粉尘序列具有一定的局限性。因此,随着人工智能的发展,具有强大非线性拟合能力的机器学习模型开始被广泛用于粉尘浓度预测。例如,颜杰等[5]采用Elman神经网络模型有效预测了露天矿PM2.5的浓度,模型不仅精度高而且误差小。张易容[6]构建的LSTM模型在某矿粉尘浓度预测中准确率达到92.97%,有效预测了粉尘浓度。白盛楠等[7]提出的基于LSTM循环神经网络的预测模型,在北京市的粉尘浓度历史数据上进行测试,有效预测了PM2.5的日变化趋势,展示了模型的优异预测性能。然而,单一的非线性模型在处理同时具有线性和非线性特征的时间序列时,往往不能达到最优预测效果。
本文提出一种ARIMA-LSTM组合模型,用于工厂生产车间环境的粉尘浓度预测。该模型结合ARIMA 模型优秀的线性处理能力和LSTM模型的非线性数据建模优势,同时考虑粉尘浓度序列数据可能包含的线性和非线性特征,从而实现更高精度的预测。
1 方法模型
1.1 ARIMA-LSTM 组合模型整体架构设计
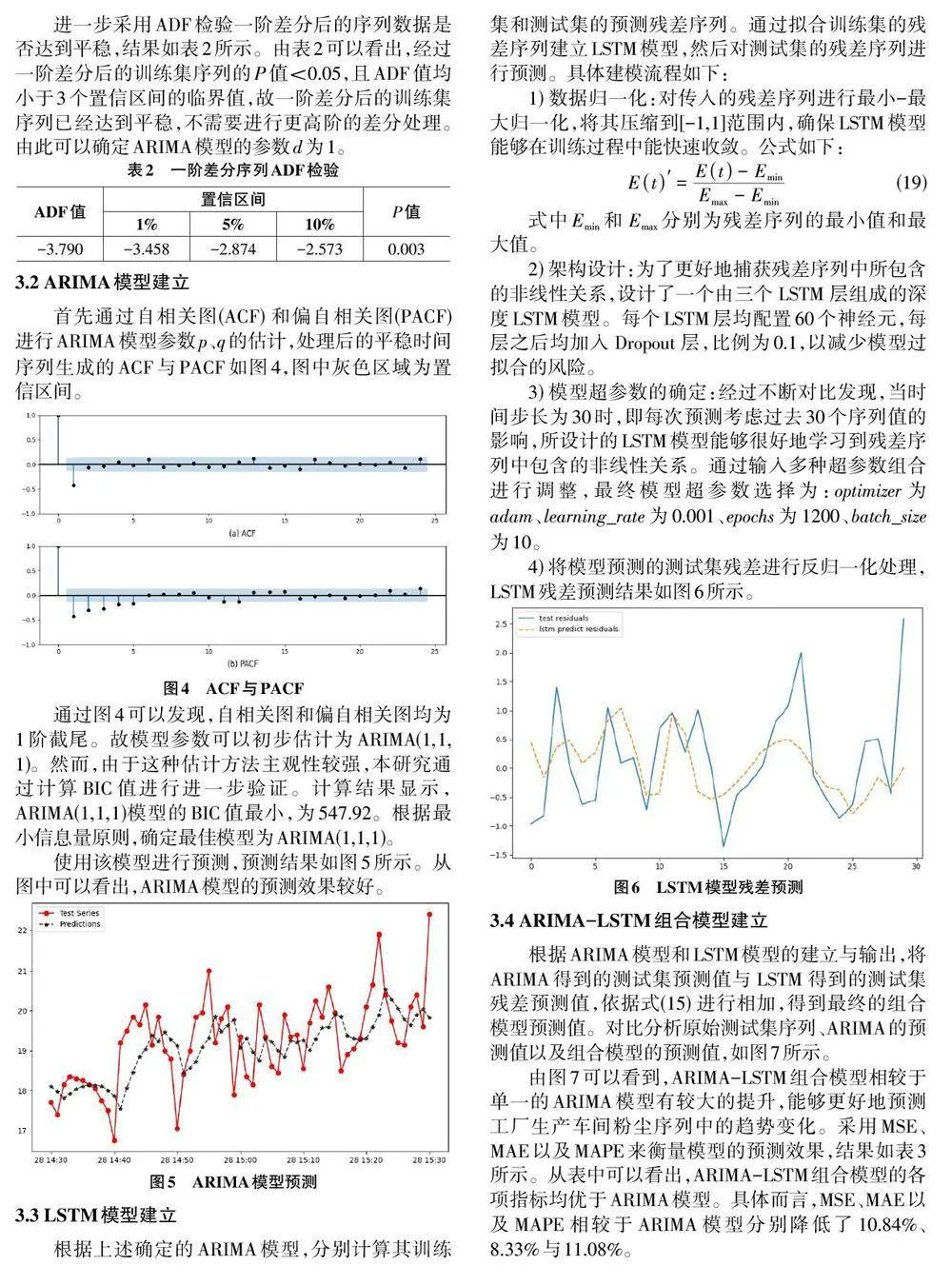
工厂生产车间的粉尘浓度序列数据,由于环境的复杂性,其时间维度上的分布同时包含线性和非线性特征。因此,本研究结合ARIMA模型在线性分析方面的精确性以及LSTM在捕捉非线性关系上的能力优势,构建适用于车间环境下粉尘浓度预测的ARIMALSTM组合模型。该模型首先利用ARIMA模型进行线性趋势分析,并通过残差计算揭示潜在的非线性特征。接着,以这些残差数据为基础,应用LSTM模型对非线性动态进行建模和预测,以修正和完善ARIMA 模型的初始预测,从而降低整体预测的误差率。下面将详细介绍这两个模型的工作流程,并解释它们如何在组合模型中相互补充。组合模型框架如图1所示。
