基于对抗学习的查新检索式自动生成
2024-08-13曾立英王亭亭刘耀王晓燕

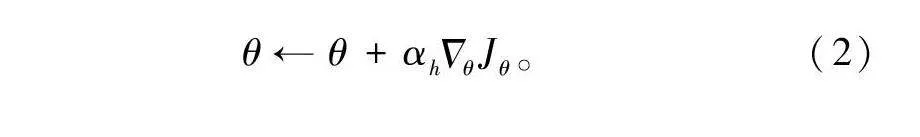





摘要: 科技查新是科研人员获取前沿信息的重要途径,但伴随着信息量的剧增,传统查新检索式的构建方法存在效率低、关键词提取不全面、一词多义等问题,因此提出了融合基于Transformer的双向编码器表达与SequenceGAN的查新检索式自动构建模型BSGAN。通过BiLSTM-CRF构建领域词表及概念同义词词表,解决了查新检索式构建过程中关键词不够全面的问题;采用基于Transformer的双向编码器表达模型中多头注意力机制,解决了检索式中一词多义问题;使用BSGAN检索式自动构建模型,实现了查新检索式的自动生成与逻辑构建,解决了传统方法中专家手工构建检索式效率低的问题。最后,通过万方中文数据库中的检索结果来评价检索式,实验结果表明,自动构建模型BSGAN生成的查新检索式在医药、化工、计算机等领域均达到了较高的查准率与查全率。
关键词: 查新检索式; 对抗学习; BiLSTM-CRF; Transformer
中图分类号: G252.7
文献标志码: A
文章编号: 1671-6841(2024)06-0070-07
DOI: 10.13705/j.issn.1671-6841.2023134
Novelty Retrieval Expression Automatic Generation Based on
Adversarial Learning
ZENG Liying1, WANG Tingting1, LIU Yao2, WANG Xiaoyan3
(1.College of International Education, Minzu University of China, Beijing 100081, China;
2.Institute of Scientific and Technology Information of China, Beijing 100038, China;
3.Library, Minzu University of China, Beijing 100081, China)
Abstract: Scientific and technological novelty retrieval was an important way for researchers to obtain frontline information. But with the blooming of information, the traditional construction method of novelty retrieval expression had some problems, including low efficiency, incomplete keywords extraction, polysemy, etc. Regarding the issues above, a new model called BSGAN was proposed that could combine BERT and SeqGAN for automatic construction of novelty retrieval expression. The method solved the issue that keywords were not comprehensive enough in the construction process of novelty retrieval expression by building domain vocabulary and concept synonym vocabulary through BiLSTM-CRF. At the same time, the issue of polysemy in retrieval expression was solved by using the Multi-headed Self-attention mechanism in Bert. In addition, BSGAN was used to implement the automatic generation and logical construction of novelty retrieval expression, which could solve the low efficiency of experts′ traditional manual construction methods. Finally, the retrieval expression was evaluated by the retrieval results in Wanfang Chinese database. The experiment outcome showed that the novelty retrieval expression automatically generated by BSGAN achieved high precision and recall in the fields of medicine, chemical engineering, computer, etc.
Key words: novelty search; adversarial learning; BiLSTM-CRF; Transformer
0 引言
随着数据科学、人工智能等技术在全球的飞速发展,人类步入了知识经济“信息爆炸”时代。网络环境下信息的需求量剧增,传统的查新手段已远远不能满足科技查新的发展需求,尤其是每年出现的科技查新阶段性业务高峰期,给查新机构人员储备与服务效率都带来巨大的挑战。
科技查新工作的核心任务是分析查新委托内容,拟定检索策略,对检索结果进行评价,反复优化检索策略,因而检索策略的优劣直接影响查新报告的质量。狭义上,检索策略是指检索提问表达式,也称检索式,是由关键词、关键词之间的逻辑关系组成的逻辑表达式。然而,现有的科技文献检索技术存在不完善之处。一方面,检索本身存在模糊性,面对海量的数据,查新人员很难得到自己需要的信息;另一方面,现有的科技查新检索式大多是由专家撰写的,需要花费巨大的人力和时间。因此如何实现查新检索式的自动构建成为一个重要且有意义的问题。检索策略的制定需要经过反复优化才能得到良好的效果,而人工所做的反复优化的过程与对抗学习框架中生成器与判别器相互迭代更新参数的过程类似,故生成对抗网络(generative adversial network, GAN)可适用于检索式生成。生成对抗网络启发自博弈论中的二人零和博弈,由Goodfellow等[1]开创性地提出,包含一个生成模型(G)和一个判别模型(D)。对抗学习基本思想是生成模型捕捉样本数据的分布。判别模型是一个二分类器,用于判别输入数据是否真实,这个模型的优化过程属于二元极小极大博弈问题,训练时固定一方,更新另一方的参数,交替迭代,使对方的错误最大化。最终,生成器能估测出样本数据的分布。此外,通过对GAN的生成器、判别器做结构上的改进或对目标函数等进行优化,能产生更多种基于GAN的变种以适配不同的任务场景,生成对抗网络目前广泛应用于计算机视觉[2]、自然语言处理[3]、半监督学习[4]等领域。
时霁等[5]以较新的查新技术规范为依据,介绍了传统手动制定查新检索式的步骤及注意事项。孙可佳等[6]利用双判别器结构生成诗歌,并通过诗歌的主题与优美诗意作为策略梯度反馈给生成器。庞栓栓[7]利用LeakGAN作为长文本来生成模型。沈杰等[8]利用SGAN(SequenceGAN,SGAN),也称SeqGAN来解决开放领域中闲聊的问答生成。Yu等[9]提出的SeqGAN中使用的生成器是基于深层神经网络编码机制的Seq2seq(sequence to sequence),虽然查新检索式的生成与问答生成相似,但仍有较大区别。在Seq2seq中,编码机制将一个可变长度的信号序列变为固定长度的向量表达,这并不适用于查新点的编码,因此提出了查新检索式自动生成模型,用基于Transformer的双向编码器表达(bidirectional encoder representation from Transformers, BERT)替换SeqGAN的编码机制,并辅以领域词表及概念同义词词表来生成查新检索式,可以帮助查新人员高效和精准地提供信息知识咨询服务。
1 模型设计
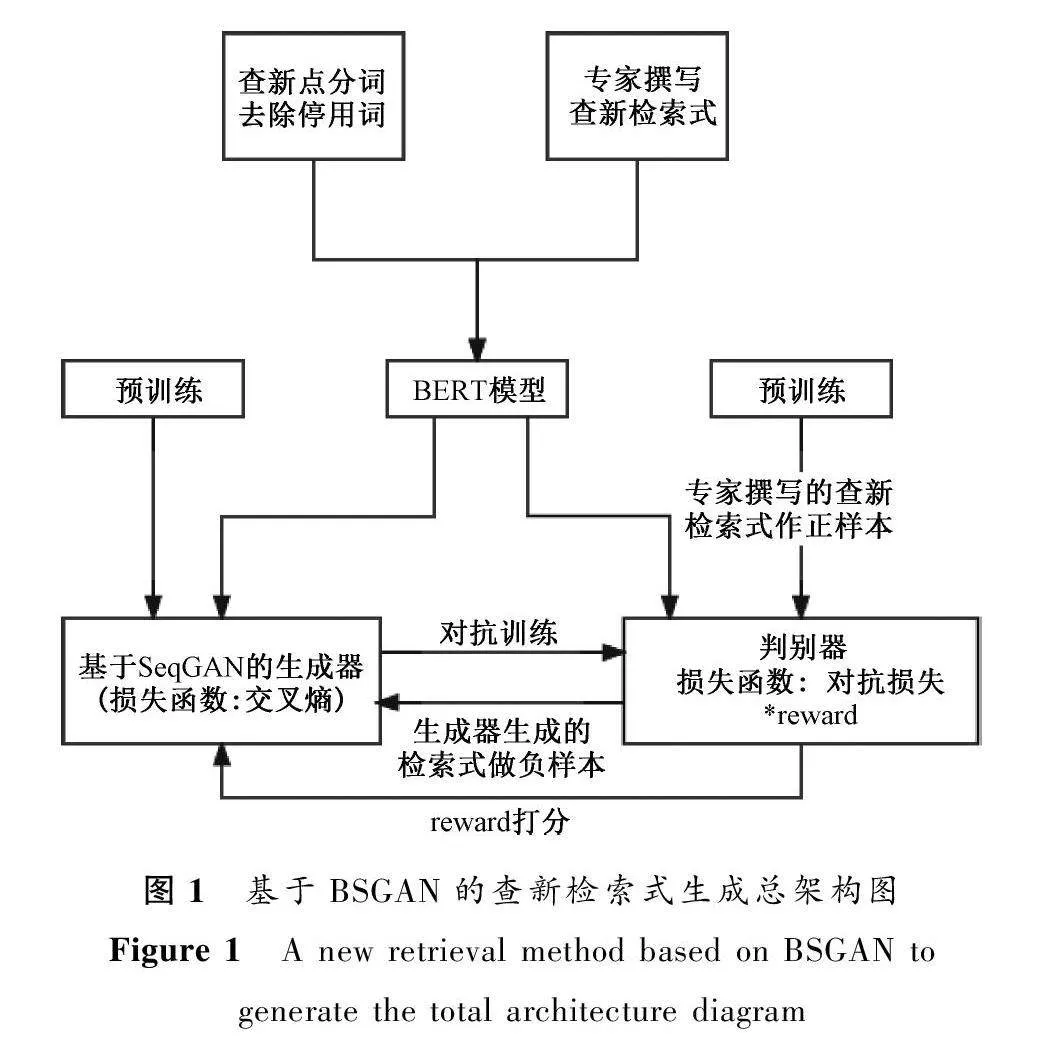
传统检索式的构建方式存在效率低下,关键词不够全面、一词多义等问题。为有效解决这些问题,本文提出了融合BERT与SeqGAN的BSGAN模型,依据查新委托单中的查新点自动构建检索策略,查新员可以对自动生成的查新检索式进行优化和修改以保证检索结果的准确性。基于BSGAN生成查新检索式的总架构图如图1所示。
图1中的BSGAN模型融合了SeqGAN模型与BERT模型。SeqGAN利用强化学习(reinforce learning,RL)来解决GAN的缺陷,其输入和生成的数据都是连续的,是可微分函数与深度神经网络结合成深度生成式模型的必要条件。在SeqGAN中,判别器为二分类器,生成器为Seq2seq,虽然Seq2seq生成的查新检索式是连续的,但其自带的向量表示模型不能解决检索式中一词多义问题,因此选取基于Transformer的BERT模型为词嵌入模型。
图1总框架中检索式生成部分,将查新点与查新检索式分别存储在txt文本中,且按段落形式一一对应,作为Bert模型的输入,首先将查新点及查新检索式分词、去除停用词等预处理,预处理后以键值对结构存储于词汇表中。然后,通过Bert模型的多头注意力机制——依据词汇表将文本中的每个字或词转换为一维初始向量,在查新点中提取每个字或词的文本向量和位置向量,并将这三个向量进行线性变化,添加注意力权重后作为模型的输入。其次引入mask任务并使用双向语言模型做预训练,最后通过微调模式解决下游任务。BERT模型输出的是融合全文语义信息的向量表示,可作为BSGAN算法的输入。BSGAN算法流程如下。
输入: G、D分别是生成器和判别器,Gθ、Dφ为生成器训练出来的矩阵,检索式的向量为生成器的输入,生成器的输出yt为判别器的输入。
输出: G与D是否达到纳什均衡。
1) 随机初始化Gθ网络和Dφ网络参数。
2) 通过最大似然估计预训练G网络,目的是提高G网络的搜索效率。
3) 判别器与生成器共享参数。
4) 使用预训练的Gθ生成一些数据即负样本,通过最小化交叉熵来预训练Dφ。
5) 开始GAN的过程,不断循环迭代。
6) 开始生成检索式,并使用奖励函数方程计算reward(这个reward来自G生成的检索式与D产生的Q值),Y1∶T=(y1,y2,…,yT)~Gθ。
7) for 1∶T里面的各个时刻do
8) 使用公式(1)更新G的参数。
9) 计算奖励Q值。
10) 通过梯度更新生成器的参数。
11) end for
12) for 判别器的每一个时间步do
13) 通过生成器的序列生成伪检索式,伪检索式与真检索式联合起来。
14) 更优的G生成更好的检索式,和真实数据一起通过公式(2)训练D。
以上7)至14)循环训练直到收敛。
其中:QGθDφ为Q值;αh代表学习率。
(a=yt,s=Y1∶T-1)=
1N∑Nn=1D(Yn1∶t),Yn1∶t∈MCGθ((Y1∶t,N)),t<T,
Dφ(Y1∶t),t=T,(1)
θ←θ+αhΔθJθ。(2)
2 实验与结果
2.1 文献预处理及数据集构建
为使BSGAN模型能够生成查新检索式,选取科技文献中的摘要作为查新需求对BSGAN模型进行预训练。本文利用万方接口以“主题:药学领域and时间:2015年1月1日—2020年12月31日”为检索式进行检索,并按照篇章结构的层级关系对论文进行解析与存储。经观察发现,在获取的420篇药学领域期刊论文中,有303篇论文摘要结构符合“目的,方法,结果与结论”三段式。再选取情报学领域、计算机领域、化学化工领域以及药剂学领域中的科技文献作为实验对象,检索策略同时包含“目的”“方法”“结果与结论”这三个限定词,时间设定为2015年至2020年,检索结果数量分别为1 267、3 675、3 132、4 979篇,共13 053篇。
对获取的科技文献进行预处理,从主要论文摘要中解析提取查新需求并观察提取效果。查新需求提取后以键值对的形式存放于json文件中,一个字段表示一个查新需求。一篇摘要分为三个查新需求。以下为《新型冠状病毒肺炎治疗中人免疫球蛋白的合理使用与药学监护》中文摘要查新点的提取结果。
1) "论文":"新型冠状病毒肺炎治疗中人免疫球蛋白的合理使用与药学监护.pdf"
2) "目的":"探讨人免疫球蛋白在新型冠状病毒肺炎治疗中的合理使用与药学监护要点。"(“目的”对应查新需求1)
3) "方法":"查阅文献,整理静脉用人免疫球蛋白的作用机制、适应证、感染性疾病应用概况、剂量、药代动力学特点,以及对实验室指标的影响和不良反应等特点,提出合理用药建议。"(“方法”对应查新需求2)
4) "结果":"人免疫球蛋白在新型冠状病毒肺炎的治疗中缺乏直接使用证据,不建议常规应用。免疫缺陷或疾病进展迅速的患者可考虑使用,但应把握剂量,注意输注速率。使用过程中应动态监测患者血浆球蛋白水平,加强药学监护。"(“结果”对应查新需求3)
对查新需求进行数据收集及预处理,合并重复项、删除缺失项,提取“标题”和“摘要”字段,形成待分析和处理的语料集,后续对语料进行分词、停用词过滤等操作,形成最终实验数据集。
2.2 领域词表与同义词表的构建
本节以药学领域的科技查新项目为例,对科学技术要点从写作内容和写作特征的角度进行分析,挖掘查新点中的关键概念,初步构建领域词表。初步构建的领域词表因数据量少,不足以支撑整个科技查新项目,需不断更新,因而利用双向长短时记忆网络-条件随机场(bi-directional long short term memory-conditional randomfield, BiLSTM-CRF)对查新文本(包含查新需求和查新点)进行概念及关系标引,构建领域概念及同义词表。以下为摘自药学领域委托单中的两例查新点。
查新点1:“以蛹虫草、玛卡、黄精、枸杞为主要原料,辅以菊粉调制成具有增强体质、耐受疲劳的一款饮料。(来源《王府一号肾精液口服液》)”
将查新点1中的关键概念通过初步构建的词表可视化展示如图2所示,可观察到,与查新点1相关的概念中,“枸杞”的直接上位类是“药食同源材料”,“抗疲劳饮料”的间接上位类是“免疫饮料”。领域词表中“枸杞”还缺乏其别名,如《神农本草经》记载的枸杞的别名有“枸棘子”“杞子”“枸杞果”等,故将这些含有同义词的概念词提取并保存在概念同义词表中,并在概念词字段后添加其同义词。
查新点2:“利培酮口服溶液的处方为:利培酮200g,酒石酸1.0Kg,氢氧化钠100g,苯甲酸200g,纯化水加至200L。(来源《利培酮口服溶液》)”
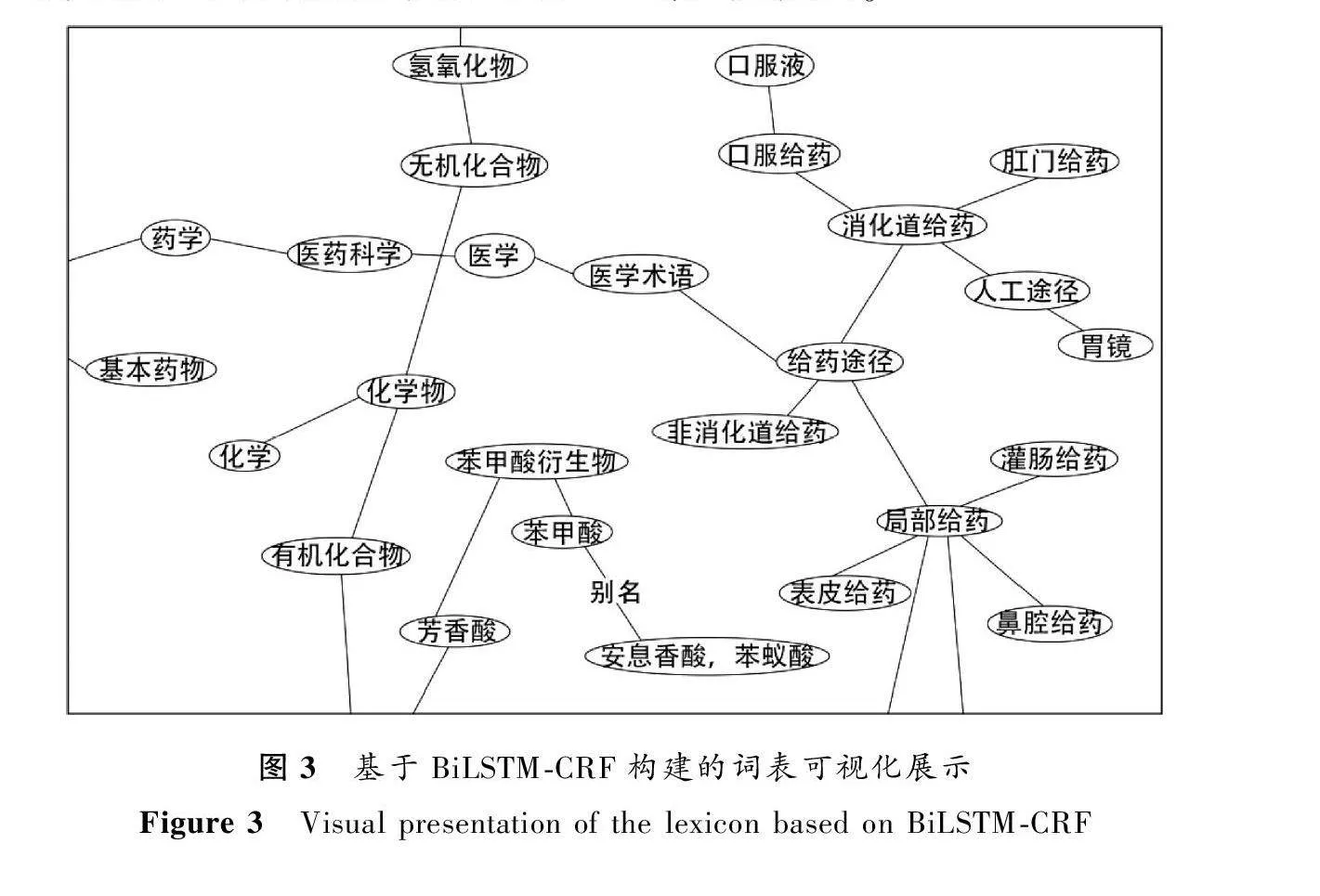
查新点2提出了“利培酮口服液”的处方,通过BiLSTM-CRF模型构建的领域词表及同义词表中与“利培酮口服溶液”相关的词可视化展示如图3所示。可看出“苯甲酸”的别名有“安息香酸”“苯蚁酸”,说明领域词表与概念同义词表的构建与扩充有助于查新检索式的生成。如“利培酮”的同义词有“利哌利酮”“瑞司哌酮”“瑞斯哌东”“利司环酮”等,依据领域词表来构建概念同义词表可使查新检索式更完整。
BiLSTM-CRF模型构建领域词表及同义词表的流程如下:将查新点与查新需求作为训练语料,统称为查新文本。首先对查新文本按领域分类,将不同领域的概念按属性分类。然后采用概念词典、规则提取并辅以人工标注的方法对文本中的概念进行初步标引。最后,当词汇积累到一定程度,得出以下科技查新概念词的分类体系。如果某一概念属于多个分类,则选择频次最高的分类。可分为五个类别。1) 成分:“菊粉”“蛹虫草”等;2) 功能:“抗疲劳”“增强体质”“滋阴补阳”“缓解衰老”等;3) 适应证:“焦虑”“抑郁”“负罪感”“怀疑”“幻觉”“妄想”等;4) 剂型:“中药合剂”“口服液”“注射剂”“凝胶剂”“微球”“膜状制剂”等;5) 技术:“核磁共振”“脑肿瘤切除”“萃取”“提纯”等。
根据相应特点制定分类规则,最后辅以人工标注的方式共标注2 000条查新点。本研究构建并扩充了图书馆、情报与文献学领域、数学领域、军事学领域、管理学领域等共26个领域的概念词表及16个概念同义词词表。其中药学领域词表中存储5 453个词,词表主要包含从属关系,药学领域同义词表中包含25个概念词,概念同义词以并列关系存储。
2.3 检索式生成
查新检索式自动生成的具体流程如图4所示。生成式对抗网络的训练是生成网络与判别网络之间博弈的过程。为了以最快的方式达到纳什均衡,训练开始前,用最大似然估计方法将真实查新检索式数据集置于文本生成网络中进行预训练。然后,使用生成网络生成的数据和真实数据作为判别器的输入,以最大交叉熵为目标函数预训练判别网络。最后生成网络和判别网络交替训练,生成网络通过一定步骤的更新训练得到进步,判别网络通过定期训练得到进步。
图4中,在训练查新检索式生成网络时,对抗学习的方法可以解决训练样本不足的问题。实验分别以数据集个数为50、100、150、300依次进行。结果发现语料数量为100条时,便可以生成与真实数据相同的查新检索式。输入数据为100个查新点时,生成器训练600次,判别器训练300次,生成器与判别器达到纳什均衡,效果最优,可以输出与标准集相同的查新检索式,而将训练次数提高时,模型生成的查新检索式与专家撰写的查新检索式相同的个数不再增加。通过纳什均衡状态下的生成模型检验查新检索式的生成效果,输入查新需求如下。
“目的探讨不同范围肝切除术治疗肝内胆管结石的临床疗效。
方法对86例肝内胆管结石患者采用手术治疗,比较不同范围肝切除治疗的临床效果。
结果左外叶切除术后结石残余率明显高于左半肝切除……
结论肝切除是治疗肝内胆管结石最有效的方法,对于非局限在左外叶的肝内结石,左、右半肝切除和肝段切除术优于左外叶切除术。肝切除范围与术后结石残留和手术治疗效果密切相关。”
基于BSGAN模型生成的查新检索式为“肝切除and肝内胆管结石and肝内胆管结石and(左外叶切除or左半肝切除or肝段切除术)and残余率and(肝切除范围or术后结石残留or肝段切除术)”,由抽检的检索式观察到,BSGAN模型生成的查新检索式符合万方数据库检索式的撰写要求。除此方法外,利用Textrank方法提取查新点中的关键词,通过组配逻辑算符来构成查新检索式,这也是查新平台推荐检索式的方法之一。
本文将BSGAN模型与Textrank构建的检索式在万方中文数据库中的检索结果作对比,表1展示了两个查新点的检索式生成,并与Textrank和专家手工撰写的检索式对比。以查新点1为例,BSGAN模型生成的检索式经检索得到1 771条结果,综合来看检索结果查准率高,查全率的评判需进一步与专家筛选的目标文献进行计算。而Textrank生成的检索式经检索得到了11 774 534条结果,该方法是关键词的单纯组合,并没有对关键词的上位类或下位类进行逻辑组配导致结果冗余,查准率低导致查全率低。
3 实验结果评价
由于检索式的特殊性,无法直接对检索式进行评价,所以选择《面向自动处理的科技查新案例解析与实现》[10]中的查新点与专家撰写的查新检索式来检验模型效果。利用专家撰写的检索式与模型生成的检索式在万方数据库中进行检索,检索结果都按照相关性排序。查新报告中专家撰写的检索式得到的检索结果作标准集,采用查全率与查准率作为评价标准来评估方法的有效性。对查准率和查全率这两个评价指标进行定义,具体计算方法为
查准率=检索出的正确的论文数量检索出的论文总数量,(3)
查全率=检索出的正确论文数量查新报告中的检索结果数量。(4)
当查准率小于50%时,需使用检索词匹配领域词表中该词的上位类或下位类进行再次检索,若依旧小于50%,则输出模型生成的检索式。经过多次实验发现,利用BSGAN方法自动生成检索式的速度快在ms级别,最长时间即再次检索时间为0.89 s。测试集中平均查全率为75%,平均查准率为82%。其查全率与查准率部分结果如表2所示。
以表2中的查新项目2为例,考察其在科技查新报告(编号为20161100100049)中的查全率,选取专家标注的四篇国内文献作为目标文献。将Textrank与BSGAN模型的检索结果按相关度排序,分别取前50篇相关文献。BSGAN完全命中专家选取的目标文献,而Textrank模型生成的检索式涵盖范围广,查准率低,检索到目标文献的概率更低。综上,本文提出的BSGAN模型检索结果更接近查新报告中的目标文献,与专家检索结果差异小。但BSGAN模型生成的部分查新检索式也存在如括号缺失或冗余、部分专业词汇如“苯并异噁唑”未被准确识别而导致关键词不够全面和逻辑关系缺失等问题。为确保检索式能正常使用,实验采取部分措施加以弥补,包括:1) 将检索式中丢失或冗余的括号利用正则补充完整;2) 通过领域词表及概念同义词表解决专业词汇未能准确识别的问题,进而解决关键词不全面的问题;3) 检索式中缺失的逻辑关系,检索词若为从属关系则添加“and”关系,若为概念同义词关系则添加“or”关系。
4 结论
为了解决传统构建查新检索式方法效率低下的问题,本文针对科技查新类文本的特点,提出了基于对抗学习的查新检索式自动生成模型BSGAN。研究并实现了查新检索式自动生成关键技术。首先从论文中提取摘要并将其解析为查新点,然后基于领域专家的先验知识通过BiLSTM-CRF构建了领域词表及概念同义词词表,最终实现查新点中的概念和概念关系自动匹配,并通过领域词表和概念同义词表解决了查新检索式生成过程中关键词不全面的问题,通过BERT模型的多头注意力机制,解决了检索式中一词多义问题,通过使用对抗学习模型解决了查新检索式的自动生成问题。
参考文献:
[1] GOODFELLOW I J, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[C]∥Proceedings of International Conference on Neural Information Processing Systems. Cambridge: MIT Press,2014:2672-2680.
[2] 张敏情, 李宗翰, 刘佳, 等. 基于边界平衡生成对抗网络的生成式隐写[J]. 郑州大学学报(理学版), 2020, 52(3): 34-41.
ZHANG M Q, LI Z H, LIU J, et al. Generative steganography based on boundary equilibrium generative adversarial network[J]. Journal of Zhengzhou university (natural science edition), 2020, 52(3): 34-41.
[3] 张得祥, 王海荣, 钟维幸, 等. 融合软奖励和退出机制的WGAN知识图谱补全方法[J]. 郑州大学学报(理学版), 2022, 54(2): 67-73.
ZHANG D X, WANG H R, ZHONG W X, et al. WGAN knowledge map completion method integrating soft reward and exit mechanism[J]. Journal of Zhengzhou university (natural science edition), 2022, 54(2): 67-73.
[4] 胡彬. 半监督对抗鲁棒模型无关元学习方法的研究与实现[D]. 南京: 南京邮电大学, 2022.
HU B. Research and implementation of semi-supervised adversarially robust model-agnostic meta-learning[D]. Nanjing: Nanjing University of Posts and Telecommunications, 2022.
[5] 时霁, 邵如洁. 科技查新检索策略制定分析[J]. 电子技术与软件工程, 2023(2): 198-201.
SHI J, SHAO R J. Analysis on the formulation of retrieval strategy for sci-tech novelty retrieval[J]. Electronic technology & software engineering, 2023(2): 198-201.
[6] 孙可佳, 李启南. 基于改进生成对抗网络的诗歌生成[J]. 兰州交通大学学报, 2020, 39(2): 64-70.
SUN K J, LI Q N. Poetry generation based on improved generative adversarial nets[J]. Journal of Lanzhou Jiaotong university, 2020, 39(2): 64-70.
[7] 庞栓栓. 基于LeakGAN的诱饵文档生成研究与实现[D]. 北京: 北京交通大学, 2019.
PANG S S. Research and implementation of bait document generation based on LeakGAN[D]. Beijing: Beijing Jiaotong University, 2019.
[8] 沈杰, 瞿遂春, 任福继, 等. 基于SGAN的中文问答生成研究[J]. 计算机应用与软件, 2019, 36(2): 194-199.
SHEN J, QU S C, REN F J, et al. Chinese question answer generation based on sgan[J]. Computer applications and software, 2019, 36(2): 194-199.
[9] YU L T, ZHANG W N, WANG J, et al. SeqGAN: sequence generative adversarial nets with policy gradient[C]∥Proceedings of the AAAI Conference on Artificial Intelligence. Menlo Park:AAAI Press,2017:2852-2858.
[10]刘耀, 曹燕. 面向自动处理的科技查新案例解析与实现[M]. 北京: 科学技术文献出版社, 2019.
LIU Y, CAO Y. Analysis and implementation of sci-tech novelty retrieval case oriented to automatic processing[M]. Beijing: Scientific and Technical Documentation Press, 2019.
