预测个人收益数据计算模型研究
2024-07-17赖丹何军


摘要:个人的收益情况与未来的发展以及社会的建设都有紧密的联系。个人收益也是社会各界所关注的热门话题之一。本文根据数据计算模型对个人收益情况进行预测研究应用,将收集的数据进行数据处理、数据建模和各数据结果分析对比。所运用到数据挖掘的模型主要有KNN模型、决策树模型、随机森林模型。在三个模型的对比下,随机森林模型的预测准确率最好,最终选取随机森林模型预测个人收益是否超过50k。
关键词:个人收益;KNN模型;决策树模型;随机森林模型
DataMiningResearchonPersonIncomePrediction
LaiDan1HeJun2
1.ChengduJinchengCollegeSichuanChengdu610097;
2.ChengduGaoxinChengwaiSeniorHighSchoolSichuanChengdu610095
Abstract:Theincomestatusofindividualsiscloselyrelatedtotheleveloffutureeconomicdevelopmentandsocialconstruction.Atpresent,thestudyofpersonalincomehasalwaysbeenoneofthehotspotsthatpeoplepayattentionto.Thispapermainlystudiestheapplicationofmachinelearninginpersonalincomeprediction,andconductsdataprocessing,datamodeling,andanalysisandcomparisonofvariousdataresultsonthecollecteddata.ThemodelsusedindataminingmainlyincludeKNNmodel,decisiontreemodelandrandomforestmodel.Inthecomparisonofthethreemodels,therandomforestmodelhasthebestpredictionaccuracy.Finally,therandomforestmodelisselectedtopredictwhetherpersonalincomeexceeds50k.
Keywords:personalincome;KNNmodel;decisiontreemodel;randomforestmodel
1研究背景
随着社会经济的发展进步,社会关注的热点逐步转移到了个人收益水平上来,个人的收益水平直接决定着一个家庭的稳固和社会的进步。个人的收益状况在目前的技术支持之下也可预测,通过预测我们可以发现并解决目前的个人收益出现逆差的问题,就可以做到在问题出现之前解决问题。笔者先收集个人的基本信息,通过数据挖掘依据计算机不同的计算方法对个人收益情况进行预测。机器学习解决生活中的问题已经不胜枚举[1]。利用计算机的数据挖掘算法解决社会中的各个领域的数据问题,如经济、生活和医学等,处理各个行业的工作推进的难点都可以提供有效的办法[2]。笔者通过爱数科数据收集网站收集了个人的一些基本数据集,收集了个人的个体受教育程度、年龄、性别、职业、婚姻状态以及个人收益等。笔者选取了这些数据的一部分进行数据挖掘实验,具体采用了KNN计算模型、决策树计算模型、随机森林计算模型。通过分类别计算预测、比对不同的计算方法以及特征因素对个人收益预测准确性的影响;通过调整其中的重要参数比对,达到各个模型预测准确性的最优值再对比;通过比对结果得到最优的预测模型。
2KNN模型、决策树模型、随机森林模型介绍
2.1KNN模型概述
KNN模型的全称是K近邻模型,这是一种简单的预测模型,便于操作,同时也便于移植,但要得到实验的高精度就要满足多种限制条件。首先在计算数据时,会要求数据的范围不能太大,数据范围稍小一些,通过模型计算结果就会很精确;反之,范围过大会导致预测结果偏差较大。其次是在进行数据计算时,KNN模型的计算核心是计算度量之间的距离,计算距离的前提就是要选取目标点,也就是要选取距离目标最近的K值,然后再根据分类决策的原则,决定目标点的类比。最后一点,也是最关键的一点,通过K值的确定来决定最后的预测准确度,而K值的选取是完全主观的,也是决定性的。当K值的选择过大时,预测的误差会增大,模型就会变得过于泛化,无法预测训练和测试集中的数据点;反之,当K值的选择过小时,近似误差就会偏大,模型会变得过于具体,不能很好地泛化。
2.2决策树模型概述
决策树模型是一种简单的非参数分类器。它不仅不需要对数据有任何的先验假设,而且在计算数据速度方面较快,其结果容易解释。在复杂的决策情况中,往往需要多层次或者多阶段的决策。当一个阶段的决策完成后,又会有新的不同的自然情况发生,每种自然状态下,都又有新的策略需要选择,选择后产生的不同的结果又会有更新的自然状态,这些被称为序列决策或者多级决策。这样就可以由一个决策图和可能的结果组成。它参照了树的形态来建立可视化图形结构,是一种类似于流程图的结构。其中,每一个内部节点都代表着一个特征变量的测试,而每一个分支代表着测试的结果,每一个叶节点代表着一个类的标签。其结点的类型有三种:决策节点、机会节点和结束节点。在决策树模型中有三种算法分别为ID3算法、C4.5算法、CART算法。ID3算法是计算训练集所有样本的信息熵和每一个特征分类后的信息增益来选择信息增益最大的特征进行分类。C4.5算法则是在ID3算法的基础上采用信息增益率作为特征选择,解决了ID3算法无法处理连续变量的问题。CART算法不再通过信息熵的方式来选择特征,而是采用了基尼系数,通过衡量信息量对特征进行选择。由于基尼系数没有对数计算,可以大幅度地减少开销,相对于ID3算法和C4.5算法,最大的优势是可以处理回归问题。在决策树模型中max_depth(决策树最大参数)是使模型达到最优的参数之一,当模型的样本量过多、特征特多的情况下,使用max_depth可以解决过拟合的问题。
2.3随机森林概述
随机森林算法的本质也是决策树模型,与决策树算法的本质相同,但计算方式却又有很大的区别。随机森林算法包含了多个决策树,同时通过随机森林算法所输出的类比由众数来确定。随机森林算法结合了随机种子的空间算法和集成学习算法,得到了一个在不同的数据环境下优于决策树模型的算法。通过新的计算方法,解决了决策树模型中的过拟合问题,同时数据中的噪声以及异常值对于本算法的准确预测都不会产生影响,而且在计算的最后也不需要进行最后的分类验算,大大提高了计算的效率。随机森林算法是建立在决策树算法的基础上,通过分类建立了更多的决策树。首先,在数据进行训练时使用Bagging算法训练得到多个决策树模型;然后对特征变量进行分类时,采用多个决策树分别进行类别预测;再通过投票法对数据的类别进行判断,哪一种类别所获得的投票数最多,就把该数据归于哪一类。在实践中我们可以发现,随机森林模型的计算结果也在前面的计算中得到了很大的提升,不仅不会出现过拟合的问题,也大大展示了它强大的泛化能力,从而计算的预测误差也相对减小。由于随机森林包含很多的决策树,因此此算法可以处理分类问题,也可以处理回归问题,同时也可以处理降维问题。同时,由于随机森林在计算当中对于异常值和噪音由很强的包容性,在各个领域的应用中都凸显了自己强大的优点,计算的结果也具有更强的预测性和分类性。因此,在医学计算领域,以及经济建模领域等都有随机森林的优秀表现。
3实验分析
3.1实验数据案例分析
3.1.1实验数据来源与实验工具
爱数科数据网站有关于个人收益预测的数据集,笔者先从网站上下载这些数据,这些数据集有个人的一些基本的数据,包含性别、年龄、职业、婚姻状态以及受教育程度等。每一条个人收益有类别标签,其标签有两种取值1或0,1表示个人收益超过5万美元,0表示个人收益低于5万美元。笔者将下载好的数据集进行特征变量和目标变量选择,选取年龄、性别、受教育时长、种族、每周工作小时数作为测试集,将收益作为目标变量;接下来对数据集进行训练集和测试集划分,数据集有10000+条数据,笔者的实验配置相对较低,同时也考虑到数据模拟计算的难度,提高数据运算的可行性,本文从数据集中随机抽取4000+条数据来进行实验。
本文使用jupyterNotebook软件进行机器学习的实验,这个软件的本质是Web应用程序可以很便捷地创建和共享程序文档,并且支持实时代码,便于操纵数学方程,也能可视化调整,也可以随时markdown,常用于数据清理和转化,进行数据模拟,统计建模等等实验性的应用。
3.1.2数据预处理
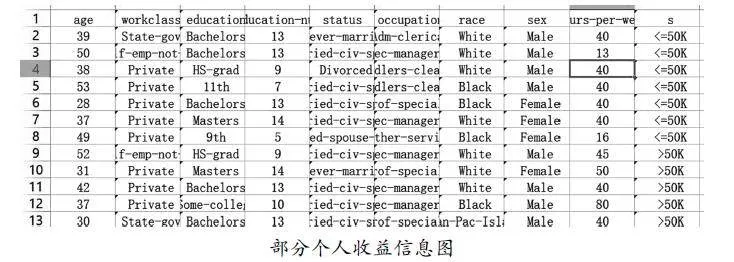
笔者对下载的数据保存为Excel的形式,如下图,由于数据中存在字符型和数据数值相差幅度较大,因此,笔者在进行实验之前对数据进行处理。具体的处理步骤为;字典特征提取、无量纲化处理、数据归一化[3]。
部分个人收益信息图
3.2实验结果
3.2.1KNN模型的实验结果
在对数据进行特征工程处理后,先使用KNN模型进行实验。在上文解释了K值的重要性,所以首先要调整KNN模型中K值的大小以便于实验。为了K值的最优取值,运用网格搜索对K值进行最优范围的筛选,通过筛选的结果,最终将K值的取值范围选取为3、5、7、9、11,实验的结果如表1所示。
由表1可以看出,当K值从[3、5、8、10、12]逐渐变大时,模拟实验的准确率开始不断的上升,K值上升到10的时候准确率又开始下降;K值取10时,KNN模型的准确率最高。由此,本文的KNN模型中的参数K值的最优值是10。
3.2.2决策树的实验结果
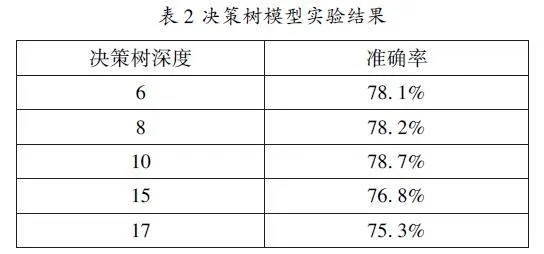
本文使用决策树模型进行实验,上文解释了max_depth参数的重要性,为了使模型能达到最好的效果,将对max_depth进行最优参数筛选。我们采用网格搜索对max_depth值进行最优范围的筛选,通过最终的筛选结果,本文将决策树最大深度的最佳范围取值为6、8、10、15、17,实验的结果如表2所示。
表2是对决策树max_depth参数最佳范围筛选的结果。从表2可以看出,随着决策树深度的加深,决策树模型预测准确率在逐步增加,当max_depth取15时准确率达到最高。由此可以判断出,本文的决策树模型中max_depth的最佳参数为15。
3.2.3随机森林的实验结果
通过随机森林模型再进行实验,通过调整n_estimators值来筛选范围,可以快速找到随机森林包含决策树的最佳个数,将结果进行筛选,可以将决策树的个数依次设置为5、10、20、30、40,实验结果如表3所示。
由表3可知,当决策树的数目增大的时候,通过随机森林模型模拟的结果的准确率会不断变高,并且决策树数目达到30的时候,准确率达到最高。因此,可以得出结论,利用随机森林模型模拟个人的收益情况中,决策树的数目为30的时候模拟的情况最好。
3.2.4三种模型的比较
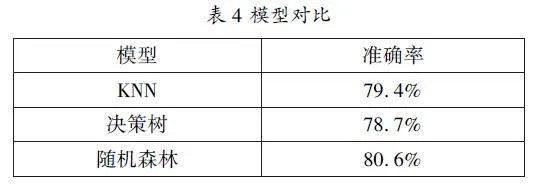
现将三类模型的模拟情况进行对比,KNN模型的K值为7,决策树模型的max_depth为15,随机森林模型含有30个决策树,通过对比可以得到三个模型模拟的准确率都很高,其中随机森林模型的预测准确率最高。因此,本文选择随机森林模型来判断年收益是否超过50k这一问题的解决方案。
结语
本文通过计算机模型对个人收益进行预测,使用了三种模型进行预测,并对比预测结果:KNN模型的预测准确率最高为79.4%、决策树模型预测准确率最高为78.7%、随机森林模型预测准确率最高为80.6%。通过比对实验结果,可以看到预测效果最好的是随机森林模型。
参考文献:
[1]李运.机器学习算法在数据挖掘中的应用[D].北京邮电大学,2015.
[2]杨志辉.基于机器学习算法在数据分类中的应用研究[D].中北大学,2017.
[3]方洪鹰.数据挖掘中数据预处理的方法研究[D].西南大学,2009.
作者简介:赖丹(1988—),女,汉族,四川双流人,研究生,中学一级,研究方向:计算数学;何军(1986—),男,汉族,四川绵竹人,本科,中学一级,研究方向:中学数学教育。
