基于检验大数据的心肌梗死预测模型研究
2024-07-09王莹
王莹
关键词:机器学习;逻辑回归;支持向量机;大数据;心梗
心血管疾病是人类死亡的主要原因,全世界每年约有2,000万人死于急性心血管疾病。心肌梗死(myocardialinfarction,MI)是由心肌缺血引发的心肌损伤,其高发病率给家庭和社会带来沉重的经济负担,并严重影响MI患者的生活质量[1]。研究表明,MI患者的高发病率与早期缺乏有效的预防和干预措施有关。干预滞后的原因包括首次就医治疗的延迟、缺乏显著提示意义的预测标志物,以及传统评价标准无法提供准确预测[2]。对于MI患者,早发现、早诊断、早治疗能够有效提高预后效果和生存率。
目前,MI的诊断方法包括心电图、超声心动图、冠状动脉造影和循环生物标志物检测等。其中,循环生物标志物对MI患者的诊断、预后和治疗效果监测非常重要。循环生物标志物包括心脏肌钙蛋白(cardiactroponin,cTn)、肌红蛋白(myoglobin)、乳酸脱氢酶(lactatedehydrogenase,LDH)、谷草转氨酶(aspartateaminotransferase,AST)、肌酸激酶(creatinekinase,CK)和葡萄糖(glucose)等。
目前,循环生物标志物检测存在两方面的局限性。首先,单独的循环生物标志物在推断病情及病程方面存在不足。尽管cTn是医学实验室诊断MI的金标准,但其在骨骼肌损伤、肾脏疾病、恶性肿瘤或败血症等情况下也会增加。AST在各种组织中无处不在,显著影响其对心肌损伤的特异性诊断,限制了其作为心脏生物标志物的使用。LDH也在多种组织中存在,使得LDH成为心脏损伤特异性较差的标志物。CK存在于多种其他组织中,严重影响其作为心肌损伤生物标志物的特异性[3]。其次,多项循环生物标志物的组合缺乏直观的规律性,人工筛查无法及时早期发现。
机器学习(machinelearning,ML)具备处理海量多维数据的能力,能够在现有数据的基础上发掘数据之间的潜在关联关系并生成预测模型。兰欣等[4]认为,患者诊断过程中产生的大量检验数据依靠人力采用常规方法诊断费时费力,同时缺乏质量保证,可以结合ML进行辅助诊断。
目前,对MI预测模型的研究主要集中在特异性明显、数据缺失率低的检验项目。例如,王觅也等[5]使用多种ML算法基于57项检验项目构建预测模型,对MI患者进行风险分析,预测结果相对稳定。吕永楠等[6]采用随机森林算法基于19项血液检验项目建立男性MI诊断模型,能够有效区分MI与心绞痛。王颖晶等[7]采用6种机器学习算法基于123项检验项目建立了MI识别模型,通过特征挖掘找出CK、血糖等MI关键和致病因素。这些研究均采用了人为筛选检验项目,与真实世界的数据存在较大差异,不利于发现新的诊断标志物。
源源不断的检验数据汇集形成海量数据,其中蕴藏大量已知与未知的临床发展规律。重新解读海量数据并将其再利用,有助于新型标志物的发现[8]。本研究拟通过两种ML算法基于MI患者的全量检验数据建立MI预测模型及验证评估,并发掘在MI中作为关键因素的检验项目。
1材料与方法
1.1数据来源
本研究的数据来源于深圳市某综合性三甲医院2016年10月1日至2021年9月30日的全量检验数据和相应诊断结果。这些数据涵盖了临床血液及体液学、临床生物化学、临床免疫学、临床微生物学和临床细胞分子遗传学五大类,共计1338项检验项目(包括少量来自不同仪器设备的同一检验项目)。数据包括患者的ID、年龄、性别、就诊部门、检验日期、检验项目编码、检验结果和诊断结果八个字段,共计140616701条记录。
1.2数据预处理
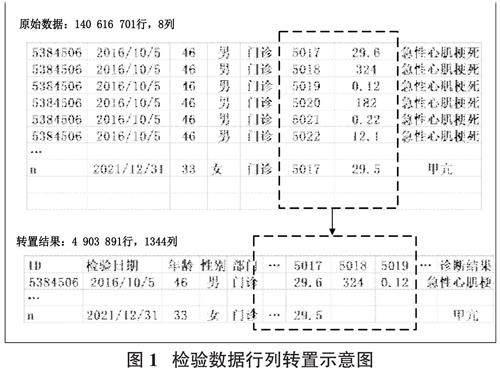
数据预处理包括将全量检验数据和相应诊断结果导入大数据平台、实施数据结构的行列转置、数据清洗和必要的数据类型转换。在大数据平台上对数据实施行列转置,如图1所示。转置后,同一患者在相同检验日期的所有检验项目位于一行,所有患者的相同检验项目位于一列,形成了大数据宽表。
检验数据结构复杂、类型众多,主要存在以下三方面的问题:1)结构化数据中存在非法标识符(例如>、<、.、*、NULL等)。2)非结构化文本数据需要数字化。3)人工录入和系统转化等导致的错误数据。通过数据清洗、文本数据数字化、错误数据纠正和缺失数据填充等方式实现数据的准确性、一致性和完整性。
为了便于ML算法处理数据,数值型数据统一转为双精度浮点类型,并对这些数据采用归一化方法,将其压缩到[0,1]之间。确定特征列(检验项目)与目标列(诊断结果),形成ML数据源。
1.3ML方法
常规的ML分类算法主要包括随机森林(Ran?domForests,RF)、K近邻(K-NearestNeighbor,KNN)、支持向量机(SupportVectorMachine,SVM)和逻辑回归(LogisticRegression,LR)等。其中,LR分类不仅可以提供分类类别,还可以提供预测概率(特征的权重),有利于结合实际业务进行分析判断和解释。LR二分类算法不仅适用于处理医疗数据,对大数据量或小数据量均具有优异的性能和计算结果,对噪声干扰及冗余属性也有较好的鲁棒性。
LR二分类算法的条件概率分布为:
其中,x是输入数据,Y是输出结果,w为权重向量,w.x是w与x的内积,b是偏置,e是自然常数。对于给定的输入实例x,通过式(1)和式(2)求得P(Y=1|x)和P(Y=0|x),LR比较两个条件概率值的大小,将实例X分到概率值较大的类[9]。
SVM通过探求风险最小来提高学习机的泛化能力,实现置信度范围和经验风险的最小化[10]。SVM分为线性和非线性,本研究采用线性SVM,通过产生一个超平面,对样本进行分类,直到训练样本中属于不同类别的样本点恰好位于该超平面两侧,从而实现对线性可分样本的最佳分类。
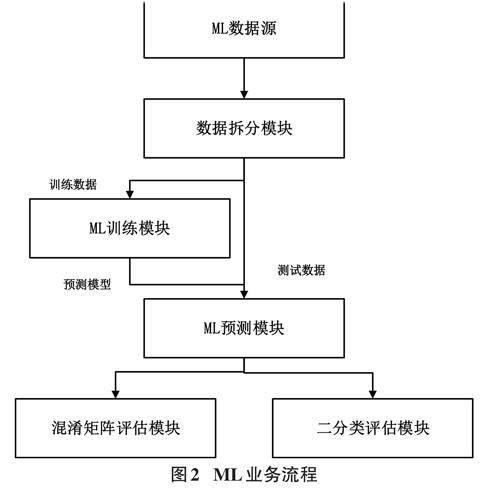
ML业务流程如图2所示,按照预设比例在数据拆分模块中将ML数据源随机拆分为训练和测试两部分数据。训练数据进入ML训练模块,结合ML分类算法生成预测模型。在ML预测模块中,测试数据和预测模型生成预测结果。预测结果分别输入到混淆矩阵评估模块和二分类评估模块进行预测水平评估。
1.4预测模型评估方法
预测模型的预测水平评估采用混淆矩阵和二分类评估两种方式。混淆矩阵的每一列表示一种类别的预测值,每一行表示一种类别的真实值,如图3所示。
其中,正确预测的正样本标记为真阳性(trueposi?tive,TP),负样本被预测为正样本标记为假阳性(falsepositive,FP),负样本被预测为负样本标记为真阴性(truenegative,TN),正样本被预测为负样本标记为假阴性(falsenegative,FN)。混淆矩阵采用准确率、精确率、召回率和F1-Score四项指标,评估指标的计算公式如下:
二分类评估采用AUC和F1-Score两项指标。AUC(areaundercurve)为受试者工作特征曲线(re?ceiveroperatingcharacteristiccurve,ROC)下面积,AUC值介于0到1之间,AUC值越趋近于1则区分能力越强。
1.5平台工具
平台工具采用公开商业软件,其中包括大数据平台提供的数据存储、计算和管理功能,大数据治理开发平台的数据治理和数据开发功能,以及机器学习平台的模块化组件,用于机器学习预测模型的开发、验证和评估。
2结果
2.1LR二分类模型
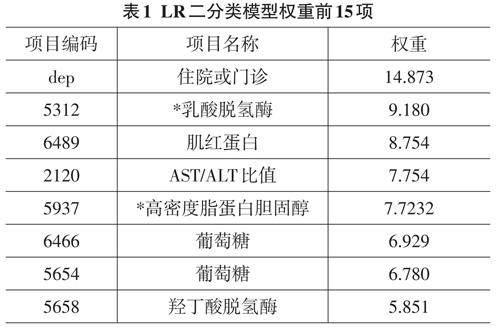
LR二分类模型包括1338项特征(检验项目)的权重,其中前15项权重如表1所示。
其中,项目编码为检验项目的唯一标识,权重为相应检验项目在模型中的系数。权重越大,该检验项目与对应诊断结果的相关性越强。由于历史原因,项目编码缺乏统一规划,存在项目编码6466和5654表示来自不同检验设备的相同检验项目的情况。
2.2LR二分类模型预测水平评估
2.2.1混淆矩阵评估结果
预测结果评估如表2所示,其中准确率、精确率、召回率和F1-Score四项指标均大于0.900,表明预测水平较高。
2.2.2二分类评估结果
预测结果评估中,AUC为0.994,F1-Score为0.960,均高于0.950,表明预测水平较高。
2.3SVM模型预测水平评估
2.3.1混淆矩阵评估结果
预测结果评估如表3所示,其中准确率、精确率、召回率和F1-Score四项指标均大于0.900,表明预测水平较高。
2.3.2二分类评估结果
预测结果评估AUC为0.991和F1-Score为0.953,均高于0.950,表明预测水平较高。
3讨论
本研究采用LR和SVM两种ML算法对同一数据源进行训练和预测,生成的预测模型均具有较高的预测水平,表明预测模型具有稳定性和可靠性。以直观输出参数、可解释性强的LR二分类预测模型为例,LR二分类预测模型展示的检验项目与诊断结果的关系可以分为两种情况:一种是已经获得相关临床研究验证,另一种是尚未被充分挖掘。获得临床验证的检验项目如LDH、葡萄糖、年龄和超敏肌钙蛋白(high-sen?sitivitycardiactroponinI,hs-cTnI)和高密度脂蛋白胆固醇(highdensitylipteincholesterol,HDL-C)等,有研究通过ML发现AST、LDH为MI患者需要关注的危险因素,MI患者的年龄、性别、超敏肌钙蛋白(hs-cTnI)检验结果为训练数据,预测效果非常理想[11]。研究表明HDL-C的低平均值和高变异性与心肌梗死、卒中和死亡风险增加有关[12]。研究发现在ST段抬高型MI患者中,葡萄糖是1年全因死亡率的独立预测因子,具有可接受的阴性和阳性预测值。在非ST段抬高型MI患者中,葡萄糖与1年全因死亡率独立相关,也是最佳预测因子[13]。本研究的项目编码分别为6466和5654,分别是来自不同检测设备对葡萄糖的检测结果,两个项目编码对应的权重接近,证明了葡萄糖与诊断结果强相关的可靠性,与王颖晶等[7]采用6种机器学习方法研究发现血糖、总胆固醇、肌酶同工酶为MI关键致病因素相符。
尚未被充分挖掘的项目,如dep、胱抑素C(Cys?tatinC,CysC)等,权重最高的dep中,来自住院和门诊的MI患者分别为4526例、860例以及其他来源2例。MI患者大部分来自住院患者(占比84%),特征明显,与高发病率以及早期缺乏有效的干预和预防措施有关。多项研究表明CysC水平对于MI的发生发展及预后,有一定的预测作用,可作为临床预测MI的指标,但其与MI的发病机制之间的关系尚未完全明确,需要进一步研究[14-15]。本研究采用LR基于全量检验数据构建的预测模型的AUC和F1-Score两项指标均高于0.950,王觅等[5]使用LR基于57项检验项目生成预测模型的AUC为0.900和F1-Score为0.810,王颖晶等[7]采用LR基于123项检验项目生成预测模型的AUC为0.785和F1-Score为0.660,一定程度表明本研究基于全量检验项目生成的预测模型预测水平高于上述研究者基于部分检验项目生成的预测模型。
综合以上分析,LR二分类预测模型按照权重降序排列的MI患者的前15项特征大部分与上述国内外临床诊断研究结果吻合,表明了预测模型的辅助诊断可用性。LR二分类预测模型中每个特征不是独立的决定性因素,需要1338项特征共同构成的完整LR二分类预测模型发挥作用。SVM预测模型缺乏可视性,适合计算机处理,但其作为LR二分类预测模型的对照具有重要的价值。
本研究通过ML基于检验大数据生成MI预测模型,一方面结果与国内外研究成果相符,另一方面也挖掘出待进一步研究的内容。SVM和LR二分类预测模型基于真实世界的全量检验数据均具有较高的预测水平,具有实际应用的可行性。其中LR二分类预测模型量化输出了检验项目与诊断结果的权重,相比以往研究的定性分析关联关系模式,有助于进一步深入研究。在研究中也发现了尚未完全明晰价值的检验项目具有较高的相关性,需要进一步结合临床诊断信息进行研究。本研究使用的近5年的检验数据也存在样本量小、只有两种ML算法以及缺乏多中心验证的问题,后续可以在此基础上进一步扩展检验数据量和数据挖掘方法,以在临床验证预测模型的可行性。
