医疗数据挖掘场景下的数据加工处理方法研究
2024-07-09叶章辉
叶章辉
关键词:医疗数据挖掘;数据加工;缺失值;异常值;非量化数值
1医疗数据挖掘的意义和价值
随着信息技术的高速发展,医学领域信息化越来越受到重视。如何利用信息技术更好地为医学实践和医学研究服务,受到越来越广泛的关注。医学信息以数据的形式存储,如基因序列、电子病历、临床用药、医学影像以及临床检查检验等每天都产生海量的数据信息[1-2]。有人将大数据比作“原油”,而数据挖掘则是大数据应用的核心。安全合理地利用医学大数据资源,可以为临床提供辅助诊断,拓展科研思路,提高科研效率和强化医院数据治理能力,甚至能够提高人类的健康水平[3-4]。然而,医疗数据的来源多样,从而导致对数据进行加工和处理的需求存在差异。如何基于业务需求,拆解问题,发现问题本质,选择合适的数据加工处理方法,需要不断积累经验。将医学问题转化为数学问题,利用数据模型来解决医疗数据挖掘的需求,是一项重要的工作[5]。
2医疗数据类型的定义和常见数据质量问题
本文采用中国真实世界数据与研究联盟(China?REAL)[6]制定的既有健康医疗数据的定义,对医疗数据进行了划分。既有健康医疗数据是指基于医疗管理决策和医院各科室正常运行而收集的医疗数据,与针对特定研究目标而收集的医疗数据不同。这类数据包括医院的实验室信息系统数据、电子病例数据、体检中心数据和医保理赔数据等,通常由医疗机构在日常运营过程中积累而来。而基于特定研究目的而设计的实验数据,则遵循预先设定的方案,这些数据与既有健康医疗数据有所不同,因为这些数据的收集过程通常受到研究目标所指导,被划分为非既有健康医疗数据。
从既有健康医疗数据的定义可以看出,该类数据在收集过程中缺乏明确的数据收集规则,因此其数据质量和可用性难以得到保证。在使用过程中会面临诸多问题和挑战。
1)异构性和多样性:不同医疗机构积累的数据可能具有不同的格式、结构和标准,这使得数据的整合和分析变得复杂。医疗数据的异构性和多样性需要采用适当的数据标准化和清洗方法进行处理。
2)非结构化的数据:一些重要的医疗数据,如医疗影像数据通常以非结构化形式保存,这增加了数据加工处理和分析的复杂性。例如,心电图、CT扫描图像和核磁共振图像等需要图像处理技术。
3)数据的缺失:原始数据在收集和存储过程中未设定明确的收集规则,因此在既有健康数据集中容易出现数据缺失情况。例如,患者未提供个人信息、技术故障导致信息丢失、样本的损失导致数据缺失。
4)噪声异常数据:在数据采集和记录过程中可能受到干扰或误差,导致生成噪声异常数据。例如,仪器故障导致误差、环境干扰或人为失误产生的异常数据。
对既有健康医疗数据进行挖掘分析存在诸多挑战。为了有效地研究这些数据,通常需要建立专业的研究团队,明确定研究目标,并最终以符合临床研究需求的方式进行医学数据挖掘[7]。数据工程师负责数据的收集和处理,合理高效的数据加工处理方法将对研究结果的可靠性和准确性产生重大影响。本文接下来主要介绍医疗数据挖掘场景下的数据加工处理方法。
3数据加工处理方法
基于既有健康医疗数据进行研究时,数据质量难以得到保证,可能存在数据缺失和错误等情况。因此,在进行数据分析之前,需要对原始数据进行加工处理。本文主要介绍了3种主要数据加工处理方法,包括缺失值处理、异常值识别和非量化数值处理。
3.1缺失值处理
从数据库中提取原始数据时,由于数据为既有医疗数据,数据记录时并没有确切的规划,记录过程中可能存在数据信息缺失的情况。例如在对糖耐量异常人群进行血糖分析时,可能存在部分患者的餐后血糖数据缺失。样本数据的缺失可能导致数据统计分析结果存在偏差,所以在对数据进行分析时,需要对缺失的数据进行处理。以下介绍常规的缺失数据加工处理方法:
1)直接剔除。在研究项目中,如果样本所缺失的数据为该研究中极为关键的研究变量数据,则应该直接对该样本进行剔除处理。例如研究糖尿病患者出现动脉粥样硬化性心血管疾病的演变过程,若一个样本缺少患者的降压药使用情况,且患者的用药情况直接影响研究的决定性变量分析,则该样本不能满足研究基本要求,需要从数据集中剔除。
2)用统计学指标填补缺失值。在收集的样本集中,每个指标可能存在一定缺失率,但临床研究经验表明,存在适度缺失是允许的,并且有可以容忍的缺失率阈值。如果指标数据的缺失比例在设定阈值以内,可以结合临床研究经验,采用统计学上的均值、中位数、极大值、极小值或者众数中的一种取值来填补缺失值,该方案是一种被普遍采用的方法,常见于医学研究。
3)用算法填补缺失值。通过算法实现缺失值的填充是一种相对复杂的方法,以协同过滤算法为例进行介绍。协同过滤算法[8]是一种常用于推荐领域的算法,该算法将个体的特征信息用向量形式表示,通过计算不同个体间的距离来评估相似度。定义越相似的个体,他们的指标值也越相近。在进行缺失值填充时,可以通过计算识别出与存在缺失值的个体最相似的样本集(该样本集的指标信息是完整的),然后通过取均值或最相似个体的相应指标值来替换缺失值。
4)直接不做处理。在临床研究中,缺失值处理通常是必不可少的步骤,以便达到较好的分析效果。但在某些特殊情况下,即便不对缺失数据进行处理,对建模的效果也不会产生影响。例如在构建随机森林算法的疾病预测模型时,由于随机森林算法的原理特性,其对特征数据的缺失值并不敏感,所以在建模过程中可以不进行缺失值处理。这种情况较为特殊,仅在特定条件下可作为可选的处理方案。
3.2异常值识别
异常值是指样本中个别数值明显偏离其所属样本的其余观测值,也称为异常数据或离群值。在统计分析和机器学习应用中,异常值的检测是非常重要的步骤。异常值如果不做处理,会导致该属性的分布特性发生偏斜。同时异常值会严重影响数据集的均值和标准差,从而可能导致统计分析结果存在偏差或影响估计。本文主要介绍5种常用的异常值检测方法:
1)领域经验。基于专业人员对样本特征数据属性的了解来判断数据是否为异常值。例如分析正常人群的餐后血糖变化趋势信息时,正常人的餐后两小时血糖在3.9~7.8mmol/L范围内,如果出现餐后两小时血糖为22mmol/L,则可以通过经验判断该患者属于糖尿病患者的血糖数据,不属于正常人群,可认定该数据为异常数据。
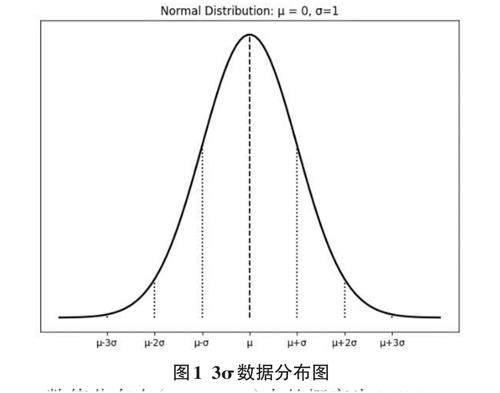
2)3σ(三西格玛)准则。3σ准则又称拉伊达准则,在统计学中,标准差是衡量一组值变化量或离散度的度量,低标准差表示数据趋向于接近集合的平均值。在分析过程中,假设实验数据总体服从正态分布,设μ表示该数据集的平均值,σ表示该数据集的标准差。
数值分布在(μ-σ,μ+σ)中的概率为0.6827;
数值分布在(μ-2σ,μ+2σ)中的概率为0.9545;
数值分布在(μ-3σ,μ+3σ)中的概率为0.9973。
在实际数据中出现大于μ+3σ或小于μ-3σ的数据概率是很小的,所以3σ准则将超出该范围的数据定义为异常值。
3)Z-Score(标准化数值法)。Z-Score是通过实测值与平均值的差再除以标准差的计算方式,如式(1)。
其中x为实测值,μ为平均值,σ为标准差。
Z值代表实测值与总体平均值之间的距离。该方法可以将两组或多组数据转化为无量纲的Z-score分值,提高数据的可比性,避免量纲差异对数据可比性的影响。例如在分析人群血糖数据时,既有空腹血糖数据,也有餐后两小时血糖数据,要判断某患者的空腹血糖和餐后两小时血糖是否异常,由于两个指标的参考范围不一致,无法直接对比,可通过计算两个指标对应的Z-score数据来判断这两个样本的异常程度。
4)三分之一极值判别法。文献[9]中提到,异常值判断基于样本点之间的距离。参考公式(2),其中X(n)为数据集中最大值,X(n-1)为第二大值,X(1)为最小值。X(n)-X(1)表示数据集的最大间隔,如果最大值与其最近节点的间隔大于最大间隔的三分之一,则认为这个最大值为异常值。
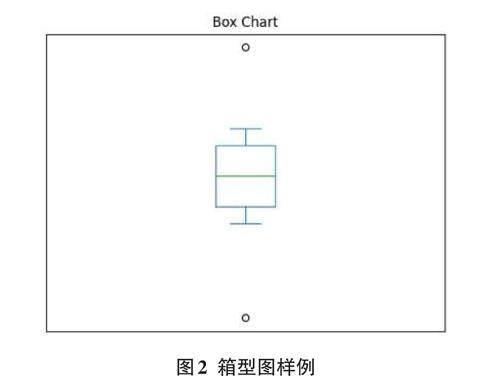
5)箱型图异常值。箱型图可展示样本数据分布情况,包含数据集的四分位数,基于四分位数可计算出异常取值的阈值信息。
计算方法:获取数据集的四分位数,得到Q1(25%分位数),Median(中位数),Q3(75%)分位数。跨度取值为QD=Q3-Q1。
lower则表示阈值下限,upper表示阈值上限。在异常值识别中,数据集中大于upper的和小于lower的数据被判定为异常值,如图2所示。图中最上方和最下方两个节点为异常值节点,正T和倒T的横线取值对应阈值上限和下限,中间方框上中下三条横线取值分别为Q3、Median和Q1。
3.3非量化数值处理
在基于既有健康医疗数据进行数据分析时,除了文本类型和图像类型的数据外,大部分数据都是数值型的,例如年龄、身高、体重等。这些量化数值可以方便直接进行统计分析和建模。而对于性别、尿蛋白、尿潜血、尿液颜色等指标,则采用非数值型的格式进行存储。针对这类非数值型数据,在进行处理时可以将其划分为有量级区别和无量级区别两种情况:
1)无量级区别的非量化数据。例如性别、尿液颜色、粪便颜色等,不同取值间只有类别的区别,没有量级属性。对于此类非量化数据,可以采用独热码(One-HotEncoding)的方式进行数值化处理。如在性别收集的数据中只有一个维度,可能在数据集中用1表示男性,2表示女性。如果不做处理直接进行均值计算,所得到的均值并无实际统计意义。所以在统计分析和建模时应避免因赋值而对模型系数产生影响,通过独热码处理,可以将性别数据转化为两个维度,如图3所示。这样可以避免特征标签数值对分析和建模产生影响。
2)有量级区别的非量化数据。以尿液检查报告中的尿蛋白为例,在报告中以符号形式进行表征[-、±、+、++、+++],无法直接进行数值型分析和建模。此时可以依据临床经验,对不同标志进行相应的数值转化。尿蛋白的不同表征符号存在量级区别,[-]表示正常,未检查到尿蛋白,后面依次表示所检查的尿蛋白含量逐级增加。因此,可以通过设定合适的数值来替换对应的符号信息。
4结束语
随着数据挖掘技术在医疗研究领域中的应用越来越普及,医疗数据加工处理在医疗研究中扮演着愈发重要的角色。通过数据加工处理和分析,可以帮助研究人员合理利用既往患者的大量医疗数据,建立疾病预测模型,从而为临床医生提供更准确的诊断支持。此外,结合患者检查检验结果数据,还可为临床治疗决策提供依据,为医生制定更适合患者的治疗方案提供帮助,并为促进医学科研创新提供支持。
最重要的是,在医疗资源管理层面,充分利用医疗数据加工处理技术,可为医院管理者提供更加细致、全面和有价值的信息,有助于合理分配医疗资源,提高医疗效率和质量。总之,医疗数据加工处理在提高医疗质量、推动医学研究,以及优化医疗资源管理等方面发挥着重要作用。
