基于人工智能的高校反电信网络诈骗模型研究
2024-07-09胡娟蒋雷
胡娟 蒋雷
关键词:网页指纹识别;TextRank;Single-pass;BERT;TextCNN;FastText
0引言
随着电信互联网的迅猛发展,电信网络诈骗案件高发,手段多样,对社会安全构成严重威胁。特别是在校大学生,由于安全意识薄弱,成为诈骗的高发群体,导致重大的人身及财产损失,给学校安全管理带来挑战。针对校园诈骗问题,虽然高校和相关部门努力应对,但是缺乏有效的预防和应对措施,安全教育不足,实时风险预警和疏导支撑体系亟须加强。
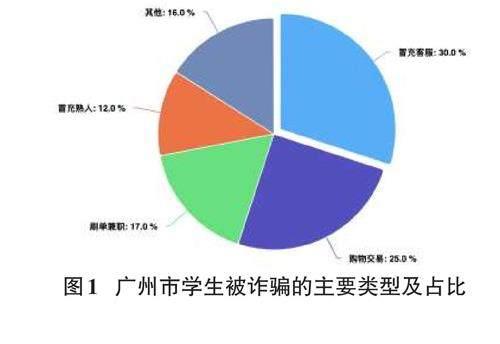
2021年10月,广州市反诈中心公布一则警情通报:本市学生被骗警情以4类诈骗手法为主[1](占比84%):冒充客服(占比接近30%)、购物交易(约25%)、刷单兼职(约17%)、冒充熟人(约12%),如图1所示。学生被骗单案金额万元以上的警情占25%,被骗金额千元以上的警情占55%,其中单案最大被骗金额为60余万元。学生被骗警情中未成年人约占14%,19~23岁年龄段占比66%,新生占比约20%。2021年12月,广州公安发布一则警情通报:近期,全市电信网络诈骗警情有所下降,但在校学生群体的警情占比略有提升[2]。为了满足学校和公安部门的反诈需求,保护在校师生的财产安全,本着预防胜于治疗的理念,高校反电信网络诈骗模型研究项目应运而生。
2电信网络诈骗网站的特征
2.1冒充客服类诈骗网站特征
上文图1显示约30%的学生遭受了假冒平台客服的诈骗影响。诈骗者技巧多变,常常模仿正规身份。诈骗团伙灵活运用当前社会热点,不断刷新欺诈策略,加大了识别难度。假冒平台客服诈骗主要具有3种典型特征:1)通过假冒官方客服发送虚假网址,诱使受害者泄漏个人信息以盗取资金。2)构建假的充值平台,通过冒充客服的形式误导受害者输入敏感信息,从而盗窃资金。3)发送带有假网站链接的钓鱼邮件,冒充客服指导受害者登录,以窃取财产。这类仿冒网站设计高度还原官网,通过混入真实元素来混淆视听,提高了识别的难度,并且这些网站可迅速更换图片,以适应新的时事,使得追踪和识别变得异常复杂。
2.2虚假购物交易类诈骗网站特征
上文图1数据显示约25%的学生遭受了虚假购物交易诈骗的侵害。随着线上购物成为日常生活的一部分,这一便捷的购物方式不仅受到广大消费者的欢迎,也为不法分子提供了可乘之机。这类诈骗网站通常具有2种特征:1)诈骗者通过发送包含虚假链接的信息,诱导消费者进行充值或购买不存在的商品。这种方式直接诱骗用户付款,而商品或服务实际上是虚构的。2)他们先引导消费者浏览看似正规的在线商城,然后巧妙地诱使消费者转至正规平台之外的交易环境,以更高的折扣或特别优惠为诱饵进行交易,最终实现诈骗的目的。这种诈骗不仅损害了学生的财产安全,也严重影响了网络购物环境的健康发展。因此,提高警惕、识别并防范这些诈骗手段对于保护学生的权益至关重要。
2.3刷单兼职返利类诈骗网站特征
上文图1中显示学生通过参与虚假刷单兼职任务而遭遇欺诈的情况占比约17%。诈骗团伙利用招聘信息作为诱饵,通过社交媒体平台和群组散播大量广告,宣称完成简单任务即可获得回报,以此吸引学生加入。他们常常通过创建假冒的在线商城,假装提供兼职刷单、组团购买或抢单等任务来获取利益,诱使受害者投资。当资金累积到一定数额后,这些不法分子会关闭网站并消失,导致受害者资金损失。这类诈骗网站通常具有2种特征:1)以非常吸引人的高额返利或者奖励承诺来诱惑受害者参与刷单活动。这些承诺往往不切实际,比如承诺极短时间内获得高额收益,或者以小搏大的投资回报率。这种策略的目的是利用人们对快速赚钱的渴望,诱使他们加入并投入资金;2)是直接发布虚假刷单任务的网站,这些网站往往只有少量的商品页面,并在页面中插入虚假的用户收益信息,以吸引受害者参与。
3反欺诈检测模型
3.1网站结构检测模型
诈骗网站精心运用HTML、CSS和JavaScript这三大网页构建技术,创建出具有欺骗性的网站界面。HTML定义了网页的基本结构,CSS负责美化页面布局和样式,而JavaScript则添加了动态交互功能。这些元素共同构建出文档对象模型(DOM),形成了网页的动态视图,使得网站能够响应用户的操作。
在此基础上,诈骗网站利用DOM的灵活性,通过JavaScript脚本修改网页内容,来假冒正规网站的外观和行为,进而诱导用户泄露个人信息。网页指纹算法在识别诈骗网站方面起到了至关重要的作用。通过分析网页的DOM结构和其他特征,生成网页的唯一标识(即指纹)。这种技术可以帮助识别和区分诈骗网站,为网络安全提供一种有效的防护手段,减少学生受到的欺诈风险。
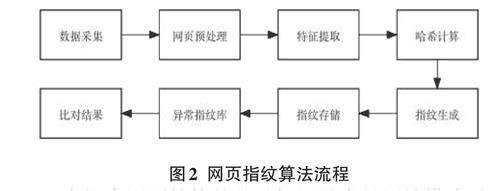
网页指纹的生成和应用流程如图2所示。
在探索网页结构的基础知识及常见网站模式后,可以利用网页结构信息识别潜在的诈骗类网站。
1)首先需要收集大量的网站数据,积累诈骗网站样本。随后,通过提取这些网站的模板指纹集合,并在大规模的网站数据中执行相似度计算,以识别出诈骗网站。
2)构建网页结构指纹需要对网页进行预处理,合理提取转换为指纹的标签节点,然后构建指纹生成算法,使用合适的方法将提取的标签节点转换为字符串。
3)有多种方法用于提取网页结构,选择最佳的方法需要根据业务需求和数据属性进行。在提取过程中,关键在于移除生成指纹冗余的信息,以避免对相似性评估造成干扰。同时,文本的长度对指纹的相似度计算具有显著影响,过长的文本不仅增大了异常指纹库的存储和计算负担,而过短的文本可能无法捕获必要的信息,从而增加错误判断的风险。为了精确提取关键特征,应当基于问题的具体关注焦点,对文本的不同分割粒度赋予适当的权重。
4)将预处理后的数据转换为一个标准格式的字符串,以便于进行哈希计算。使用哈希函数(如MD5、SHA-1、SHA-256等)对序列化后的字符串进行计算,生成一个固定长度的哈希值。
5)将这个哈希值作为网页的“指纹”。最终生成的哈希值(即网页指纹)可以用来表示网页的特征。在实际应用中,网页指纹会考虑更多的元素和细节,比如标签的属性、样式信息、脚本内容等,会生成更为复杂和独特的指纹。
6)网页指纹生成之后,其存储方式取决于使用场景、存储效率和访问速度。
7)为了维护和更新异常指纹库,需要定期进行指纹的添加和移除。添加新的异常指纹主要依赖于人工检查和自动检测机制。考虑到人工检查成本较高,时间较长,自动检测机制显得尤为关键。该机制的开发包括数据的准备、网页指纹特性的定义以及模型的训练。一旦模型训练完成,就可以将新采集到的指纹与库中的异常指纹进行比对来识别潜在的诈骗网站。同时,定期清理长时间未被匹配的失效指纹,也是异常指纹库管理的一个重要方面。通过实施最近最少使用(LRU)策略,可以有效减少所需的存储空间和计算力,从而提升系统的整体识别效率。
8)通过将待检测指纹与异常指纹库进行匹配及相似度分析,能够识别出潜在的诈骗网站。这一识别流程还嵌入了基本的过滤机制,例如采用白名单策略,以确保合法的正规网站不会被错误地标记为诈骗网站,有助于提高诈骗网站识别结果的准确性。
此模型结合了网页内容预处理、指纹生成算法和异常指纹库的维护,创建了一套系统化的诈骗网站识别机制。
3.2网站文本检测模型
在当今数字化时代,文本作为网络中出现频率较高的信息载体,发挥着至关重要的作用。网站的大部分内容都是由文本构成,比如产品描述、评论和论坛帖子等。然而,这种信息的普遍性和易获取性也使其成为电信网络诈骗活动的温床。诈骗集团利用文本传播虚假信息、实施欺诈等非法行为。文本形式和语义的多样性增加了识别诈骗网站的复杂度。
为了检测出诈骗网站,首先要获取网页文本数据,主要有以下几种方式:从HTML文本文件中提取。从HTML页面中提取各个标签的文本内容,包括文章、标题、评论等直接显示的信息。从网页图片中提取文本内容。一些关键的信息,如广告、产品等,可能以图像的形式呈现。光学字符识别(OCR)技术可以用来识别图像中的文本内容,从而提取图像信息。网址文本数据,电信网络诈骗活动时常涉及使用高度相似的网站域名和网址参数。通过分析这些网址的文本数据,如域名、站点路径和URL参数等,可以获得用于识别和过滤可疑网站的信息。
获取了网页文本数据之后,探索有效的技术手段来识别和阻止电信网络诈骗活动显得尤为重要。在这一背景下,敏感词规则模型、文本聚类模型和文本分类模型成为网络安全领域的重要工具。这些模型各自具有独特的优势,在识别不同类型的网络诈骗活动中发挥着关键作用。通过深入分析和应用这些模型,可以更有效地保护学生免受网络诈骗的侵害。
1)敏感词规则模型[3]。敏感词规则模型通过设置敏感词和短语列表,这种基于规则的方法可以识别潜在的欺诈内容。虽然此方法依赖于不断更新的敏感词库,但它为快速筛选提供了一个有效的起点。在处理特定类型的网络诈骗,如刷单兼职返利类诈骗网站时,敏感词规则模型展现出了特别的价值。这类诈骗网站通常会使用一系列特定的词汇和短语来吸引用户参与,比如“高回报”“零风险”“兼职赚钱”等,这些都可以作为敏感词纳入监测列表中。
TextRank算法作为一种自动提取文本关键词和短语的方法,可以分析诈骗文本的内容结构。在刷单兼职返利类诈骗网站的场景下,TextRank算法能够从大量的宣传和招募文本中,自动识别出关键信息,揭示出诈骗者常用的语言模式和策略。这不仅加强了敏感词规则模型的有效性,还提供了一种动态学习和适应新出现的诈骗手段的能力。通过结合这两种技术,可以构建出一个更加强大、灵活且具有自适应性的网络诈骗检测系统,能够有效地识别和防范刷单兼职返利类诈骗网站,保护学生的财产安全。
2)文本聚类模型[4]。文本聚类模型利用聚类技术,通过将文本分为基于相似性的不同组或类别,有效地帮助识别大量未标记文本数据中的模式和趋势。这种技术特别适合于揭示异常或不寻常的内容集群,这些内容集群往往是欺诈活动的指示器。在应对虚假购物交易类诈骗网站的场景中,文本聚类模型的价值尤为突出。这类诈骗网站常常发布大量看似合法但实际为虚假的商品交易信息,诱骗消费者进行购买。
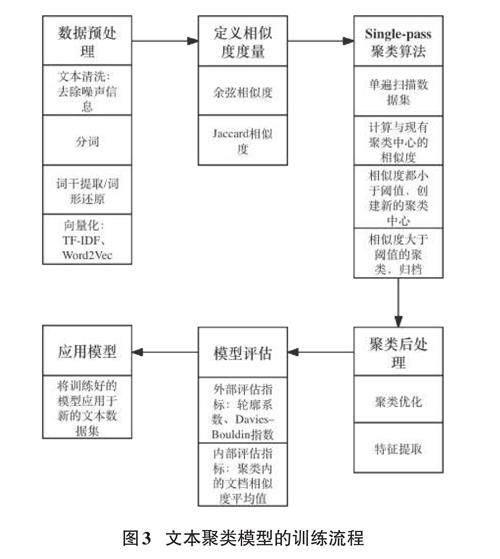
Single-pass算法是一种快速的文本聚类方法,它通过单遍扫描数据集,即时地将文本分配到已有的或新创建的聚类中。这种算法特别适合处理大规模数据集,能够迅速识别出包含虚假购物交易信息的文本聚类。在虚假购物交易类诈骗网站的检测中,Single-pass算法可以快速处理和分析大量网站文本数据,识别出具有相似欺诈特征的文本群体,从而有效揭示和预防诈骗行为。文本聚类模型的训练流程如图3所示。
结合文本聚类模型和Single-pass算法,能够高效地监测和识别虚假购物交易类诈骗网站,及时发现新的诈骗模式和趋势。这种方法不仅提高了检测的速度和精确度,也为学生提供了更为安全的购物环境。通过不断优化这些技术,可以进一步强化网络安全防护,有效遏制虚假购物交易类诈骗活动的蔓延。
3)文本分类模型[5]。文本分类模型通过学习已标记的数据集,能够识别文本的具体类别,如区分正常文本、广告、欺诈信息等。深度学习技术,特别是卷积神经网络(CNN)和循环神经网络(RNN),已经在提高文本分类的准确性方面取得了显著成果。随着BERT算法(BidirectionalEncoderRepresentationsfromTrans?formers)、TextCNN算法和FastText算法的引入,文本分类模型在处理复杂文本数据,尤其是识别仿冒平台类诈骗网站方面的能力得到了极大的增强。识别诈骗类网站的文本检测流程如图4所示。
在处理待检测的可疑网站文本以识别仿冒平台类诈骗网站的过程中,首先需要收集和准备待检测的网站文本数据。这是检测流程的起点,涉及从可疑网站提取文本内容,包括网站描述、商品信息、用户评论等,作为后续分析的基础数据。
接下来,使用基于规则的模型对收集到的文本数据进行初步筛选。这一步的目的是快速过滤掉明显属于正规网站的文本,减少后续处理的数据量。规则模型依赖于预定义的敏感词和短语列表,通过匹配这些敏感词来识别潜在的欺诈内容。
经过规则模型过滤后,使用TextCNN算法对剩余的文本数据进行深度分析。TextCNN是一种利用卷积神经网络对文本进行分类的算法,它通过提取文本中的局部特征来识别网站是否为仿冒或诈骗性质。
之后可以应用FastText算法进一步地检测。Fast?Text在处理文本分类时特别高效,因为它考虑了词汇的n-gram特征,能够快速识别文本模式,对于识别具有特定词汇和表达模式的仿冒网站非常有效。
最后,利用BERT算法进行深层次的文本分析。BERT通过理解文本的双向上下文关系,能够捕捉到更加复杂和细微的语义信息,进一步提高识别仿冒平台类诈骗网站的准确性。
在输出检测结果后,整个检测流程完成,汇总各阶段的检测结果,输出最终的分析报告,明确指出哪些网站被识别为仿冒或诈骗网站。通过这样的先后顺序,可以有效地结合不同技术的优势,从而提高检测仿冒平台类诈骗网站的准确率和效率。
结合这些深度学习技术,文本分类模型在识别仿冒平台类诈骗网站方面的性能大幅提升。这些算法不仅提高了模型对文本的理解深度,还增强了其在处理大量和复杂数据时的效率和准确性。
4结论
本研究针对广州市高校学生群体面临的电信网络诈骗问题,通过深入分析诈骗类网站及其特点,开发了一套高效的反电信网络诈骗检测模型。该模型主要包括网站结构检测模型和网站文本检测模型,目的是为了有效识别和防范冒充客服、虚假购物交易以及刷单兼职返利等主要诈骗手段。通过利用网页指纹算法分析网站的DOM结构来识别具有欺骗性的网站,结合敏感词规则模型(TextRank算法)、文本聚类模型(Single-pass算法)以及文本分类模型(BERT算法、TextCNN算法和FastText算法)对网站文本进行深度分析,构建出一套系统化的诈骗网站识别机制。这些技术的综合应用,不仅提高了识别准确率,还为保护高校师生的财产安全提供了有力支撑,体现了“预防胜于治疗”的理念。
