基于深度学习的个性化学习资源推荐算法研究
2024-07-09邵文倩
邵文倩
关键词:学习资源;深度学习;推荐算法;卷积神经网络;个性化推荐
0引言
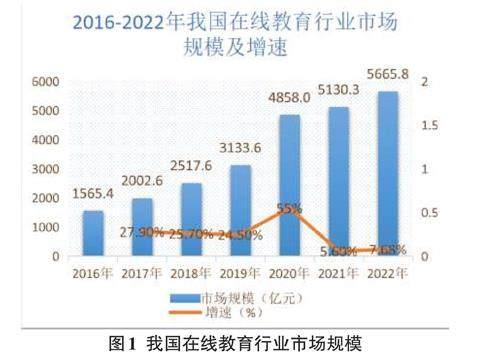
随着互联网技术在教育领域的深入应用,学习者可足不出户通过学习在线平台获得感兴趣的学习资源。图1显示了我国在线教育行业市场规模及增速,可见在线学习教育发展迅速。然而,在线学习资源的不断增加既给个性化学习带来了机遇,也带来了挑战。面对丰富的学习资源,学习者很容易陷入选择困难,难以迅速找到最符合自身特质的学习资料。这种情况使得为学习者从众多数据中筛选有意义的信息成为在线学习领域亟须解决的难题。因此,为学习者提供个性化的学习资源推荐服务,也成为各大在线学习平台竞相追求的创新与挑战。
传统的学习资源个性化推荐方法主要包括基于内容的推荐方法和协同过滤推荐方法等。梁婷婷等人针对文本处理中普遍存在的多义词与同义词问题,提出了一种基于内容过滤和改进的PageRank算法进行学习资源的推荐[1]。此外,丁永刚等学者针对学习资源推荐的问题,创新性地提出了一种基于学习者社交网络信息的协同过滤推荐方法。该方法深入挖掘了学习者与其好友之间的信任关系,从而预测新学习者对特定学习资源的评分[2]。朱明提出了一种教学资源协同过滤推荐方法,通过聚类算法对用户进行聚类以提高可扩展性[3]。
随着人工智能技术的迅猛发展和广泛应用,深度学习技术已经渗透到个性化推荐领域,并为其带来了颠覆性的变革。在线学习平台作为数字教育的重要组成部分,积累了海量的可用数据,为构建基于深度学习的个性化在线学习资源推荐算法提供了数据基础。在此背景下,Batouche等人创新性地提出了一种基于无监督机器学习的教学资源推荐方法,并通过改进的人工神经网络取得了令人满意的推荐效果[4]。
程美娟采用深度学习方法进行个性化推荐,推荐过程中结合了区块链技术来提高推荐系统中数据的安全性,有效提升推荐系统的性能[5]。赵蔚提出了一个融合知识推荐技术与本体技术的个性化资源推荐策略,使得学习资源推荐更为高效[6]。文孟飞提出了一种将支持向量机与深度学习相结合的方法,显著提高了教学视频资源的利用率和获取率,从而优化了在线学习体验[7]。此外,Tarus设计了混合知识推荐系统,将知识本体与序列模式挖掘相结合,为在线学习者提供个性化的资源推荐[8]。
现有部分研究将深度学习技术应用至学习资源领域,提供重要参考价值,但仍有可提升之处,例如更为细化地推荐学习资源,考虑学习者的各种学习兴趣,不局限于某一兴趣点。
1基于深度学习的个性化学习资源推荐算法
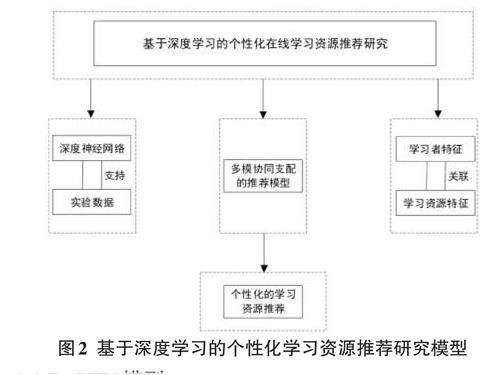
个性化学习资源推荐算法以在线学习平台为背景,依托卷积神经网络模型框架,提出了S-CNN模型,旨在降低学习者在线学习时寻找自身感兴趣学习资源的难度。如图2所示,该推荐方法包含训练过程与推荐过程。训练过程包括数据集清洗、学习者特征处理、学习资源特征处理等流程;推荐过程主要通过评分指标与特征标签将用户对不同学习资源的评分划分等级,综合显性评分和隐性评分为学习者实现个性化推荐。
1.1S-CNN模型
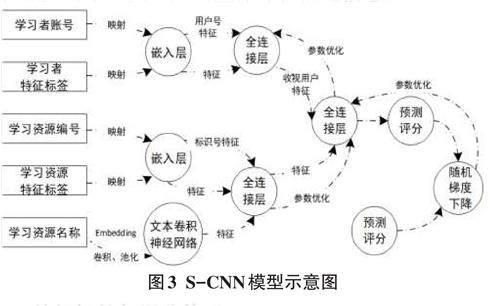
在处理具有特定结构的数据时,卷积神经网络发挥了核心作用。它主要依赖于卷积和池化这两种操作,尤其在图像等二维网格数据以及自然语言这种一维词序列的处理中表现出色。卷积神经网络应用在学习资源个性化推荐中,不仅擅长提取学习者与学习资源的局部特征,还能将这些特征进行抽象组合,从而生成更高级别的特征表示。由于数据集中存在大量不同类别的学习者账号和学习资源编号,使得无法使用传统的一位有效编码方式,该简单编码方式在控制神经网络输入维度方面显得捉襟见肘。鉴于此,在构建网络时,于首层引入了嵌入层技术,通过嵌入矩阵,将学习者账号和学习资源编号这类离散数据转化为连续的低维向量,而这些向量正是以学习者账号和资源编号为索引从嵌入矩阵中获取的。
首先,在生成学习者特征时,嵌入层的输入信息为每个学习者账号及其对应的特征标签。具体来说,这些信息被映射为一个向量表示,能够充分捕捉学习者的喜好与特征。然后,这些向量被传递至全连接层,进行更深层次的特征提取。为了生成学习资源特征,同样采取了这样的策略,每个学习资源编号及其关联的特征标签被输入到嵌入层中。鉴于学习资源可能具有多个标签,因此采用求和的方式来处理这些标签在嵌入矩阵中的表示。这样,能够将这些多元标签信息有效地融合为一个向量。
S-CNN模型如图3所示,其中,在处理学习资源名称时,采用文本卷积神经网络(TextCNN)技术。该技术通过词嵌入层将名称中的每个字符映射为嵌入向量,这些向量组合成嵌入矩阵。随后,卷积层对嵌入矩阵执行卷积运算,以捕获文本的局部特征。池化层进一步提炼这些特征,降低数据维度,得到学习资源名称的最终特征。值得注意的是,本文所指的学习资源意为以课程为中心,相关的课程视频、试题库、讨论组等,因此在对学习资源进行标签提取时,同一课程相关的学习资源共用整体课程概述信息。
1.2特征标签与评分体系
本文使用隐性评分与显性评分相结合构成评分体系。其中,显性评分指用户在学习平台上对学习资源进行的打分,而隐性评分是通过数据筛选和计算得出的实际评分,呈现为学习资源评分矩阵,提供了对学习资源质量更全面的评估。
在对数据集进行深入分析后,发现了影响学习者对课程评分的两个关键因素。首要的是学习资源观看时间,这一因素显著反映了用户的偏好程度[9]。为确保公正性和准确性,观看时间进行了归一化处理,最终将其表示为特定学习资源观看时间与总学习时间的比值。此外,观看频率也被证实是一个不可忽视的影响因素,它在一定程度上揭示了学习者对特定学习资源的兴趣水平。
该推荐算法利用学习资源的观看频率和学习者观看学习资源时间作为评分的主要衡量标准。其中,Sij指的是学习者i对学习资源j的实际观看时间,而观看频率ω则反映了学习者重复访问同一资源的频次。隐性评分公式详见式(1),根据学习者i平均观看时长Sh与学习资源j时长Tj的比例aij,将学习用户对不同学习资源的评分划分为十个等级。bj为在线学习平台中学习资源j获得的评分,f(i,j)为学习者i对学习资源j的评分,其中综合评分是显性评分与隐性评分的平均值,综合评分公式详见式(2)。
1.3模型训练
卷积操作在获取文本向量特征中扮演着关键角色,这一操作的性能与多个因素有关,包括卷积窗口大小h、卷积窗口个数T、学习速率α、卷积步长λ[10]。详细的文本卷积如式(3)-式(5)所示:
深入挖掘了用户学习信息中的有效信息后,数据中共包含1317个学习资源,需要构建1317个学习资源编号的匹配索引,来确保embedding函数能够与嵌入矩阵的索引精确对应。在此基础上,嵌入层矩阵R进一步与学习资源名称矩阵相结合,该矩阵的维度被设定为1317×32。在这个扩展的矩阵中,每个元素都表示了某个学习资源名称中特定字符的特征向量。其中,Yij表示第i个学习资源名称中第j个字符的特征向量,连续应用卷积窗口i到i+j,得到新的特征向量。矩阵E为卷积核函数矩阵,其维度依赖于学习资源数k和卷积窗口w。矩阵X是矩阵R与矩阵E进行卷积计算后的结果,这样的处理方式有助于捕捉学习资源名称中的局部特征和全局特征,从而为后续的学习任务提供更丰富的特征表示,其中,Hij代表第i个学习资源通过j次卷积得到的向量。
2实验结果及分析
2.1实验数据采集
为了验证基于卷积神经网络的学习资源推荐算法的有效性,笔者使用了爬虫程序爬取某在线学习网站中的免费课程及用户相关数据。经过清洗后,数据集包括728门课程,1317条课程相关学习资源简介,以及2139名有学习记录的用户。具体信息如表1所示。这里的“学习资源简介”指的是以课程为中心的内容,包括课程视频简介、试题库简介、讨论组简介等。而某一学习资源简介不仅包含自身的简介信息,还包括该资源所属课程的概述简介。
2.2数据预处理与实验设计
为了确保学习者观看历史数据质量的优越性,需要对课程资源的观看历史数据进行详尽的预处理。经过分析后发现,大约有21%的观看时长不足两分钟,而观看时长在2到20分钟之间的数据则占据了最大比例。短暂的观看可能是由于学习者误触或者对该学习资源不感兴趣,因此我们保留超过2分钟的学习历史记录。
在实验模型的验证阶段,采用了留一法交叉验证(Leave-One-OutCross-Validation)的策略。具体而言,假设数据集中有N个样本数据,我们逐一将这些样本挑选出来作为测试集,而其余的N-1个样本则作为训练集。这样能够确保每个样本都有被单独测试和评估的机会,从而为模型提供更准确、更可靠的性能评估结果。
2.3实验结果及分析
本次实验模型的训练建立在TensorFlow开源框架之上,通过神经网络对学习者信息和课程信息进行深入特征提取,获得了两组关键特征[11],并传输至全连接层中。为了提高模型的预测精度,采用均方根误差作为损失函数来计算预测值与实际评分之间的差距。同时,利用随机梯度下降法对网络中的参数进行迭代更新,逐步优化模型的性能。
文章中模型损失函数采用随机梯度下降法进行迭代优化。为了比较不同推荐算法的性能,当推荐数N分别为5、10、15和20时,计算SVD(SingularValueDecomposition)、协同过滤、LSTM(LongShort-TermMemory)和S-CNN四种方法的查准率、召回率和F1值进行对比。其中,SGD学习速率设置为0.001、0.005、0.01之间随机选择,以寻找最佳的学习速度[11]。
如图4所示,在推荐学习资源数目N较少时,协同过滤方法、LSTM方法和S-CNN方法都具有较高的查准率,随着N的增加,SVD方法也能取得较好的效果。在召回率指标上,LSTM方法和S-CNN方法表现突出。从F1值的分析来看,在N=15和N=20时,本文提出的S-CNN方法可以获得比较好的效果。
3结束语
当前的研究大多偏向于推荐在线学习平台中的课程,而较少探究课程资源相关的学习内容。本文提出的推荐方法不仅成功地解决了稀疏数据造成的信息不足问题,而且还深入探索并充分利用了高维数据中的潜在特征。该方法能够精准地获取学习者的特征标签和课程资源的标签,并在卷积神经网络模型中进行有效训练。通过巧妙地结合隐性评分和显性评分,可以获取学习者的潜在兴趣和偏好信息。因此,基于这种方法,在线学习平台和教育者可以更精确地规划和设计个性化的学习资源推荐策略,从而更好地满足每位学习者的独特需求。
