大规模多任务中文理解能力测试
2024-07-09曾辉
曾辉
关键词:中文大模型;多任务评测;zero-shot;few-shot;垂直领域任务
0引言
随着ChatGPT[1]等大模型的惊艳亮相,ChatGLM[2]、MOSS[3]、文心一言、通义千问、商量等具备中文能力的大模型也相继发布。虽然针对英文大语言模型已有较为完善的评测方式(如MMLU[4]),但目前仍缺乏针对中文大语言模型的评测方法。因此,推出一种科学的中文大模型评测方法并提供高质量的中文评测数据集已迫在眉睫。
以Transformer[5]为架构的中文预训练大模型采用大量文本语料(包括中文百科数据、海量中文电子书籍和众多中文网站)进行预训练。然而,这种训练方式的模型在理解和解决诸多领域问题的能力尚未经过科学、全面的评测。
由于近期发布的大语言模型大多经过了指令微调训练,本测试提供了zero-shot和few-shot两种测试方式。在few-shot模式中,模型会得到5个示例。测试题目为单项选择和多项选择题,每道选择题可能有一个或多个正确答案,更类似于人类考试,难度也更大。
本次测试涵盖医疗、法律、心理学和教育四个大类。其中,医疗类题目来自大学医学专业考试,法律类题目来自国家统一法律职业资格考试,心理学题目源于心理咨询师资格考试和心理学专业研究生入学综合基础考试,教育领域的题目取自全国普通高等学校统一招生考试。测试题目覆盖范围广,专业知识点难度高,非常适合评估大模型的综合能力。
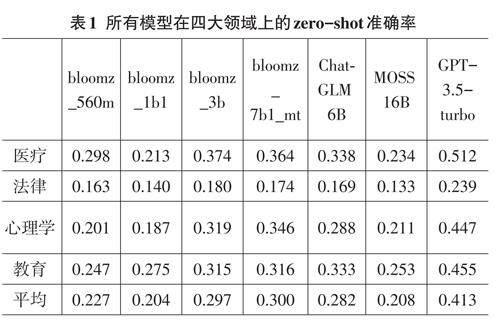
值得一提的是,高达160亿参数的MOSS模型在四大领域的zero-shot准确率均低于26%,是评测中表现倒数第二的模型。而参数量至少1750亿的GPT-3.5-turbo模型取得了41.3%的平均zero-shot准确率(见表1)。
评测结果显示,虽然大模型最近进展迅速,但最先进的模型仍未达到某个领域的专家水平。所有模型在法律领域任务上的准确率都接近随机准确率。相关测试代码见github.com/Felixgithub2017/MMCU。
1多任务测试
本研究开发了一个涉及多个任务的广泛测试,包括各个领域知识的单选和多选题,涵盖医学、法学、心理学和教育学等领域。其中,医疗分为15个子任务,教育分为8个子任务。数据集中的问题由专业人员从在线免费资源中手动收集,涵盖医学院考试、全国法律资格考试、心理咨询师资格考试、心理学研究生入学基础综合考试和全国普通高校招生考试等内容。本研究共收集了11900个问题,设计为few-shot调试集和测验集。few-shot调试集每个主题有5个问题,共55个问题;测验集共有11845个问题。
1.1医疗
医学领域涵盖以下学科:基础医学、药学、护理、病理、临床诊断、感染病、手术、人体结构、放射学、寄生虫病、免疫、小儿科、皮肤病与性病、胚胎学、药物学。医疗领域共有2819个问题。
以下是一个医疗问题示例:
针对初次出现的急性腰椎间盘膨出,首选的治疗方式为:
A.严格的床上休息,三周之后佩戴腰带进行下床活动。
B.保持卧床,但可进行站立和坐起动作。
C.在硬膜外进行皮质类固醇注射。
D.对髓核进行化学溶解处理。
1.2法律
法律类问题包括以下领域:中国特色社会主义法律体系、法学基础、宪法原理、中国法制史、国际法概论、法律职业伦理与司法体系、刑法基础、刑事司法程序、行政法及其诉讼程序、民事法律、知识产权保护、商业法规、经济法理论、环境与资源法、劳动法与社会保障法规、跨国私法、国际商法、民事诉讼法律、法律职业道德与司法结构。法律领域共有3,695个问题。
以下是一个法律问题示例:
依据法律规定,哪种情形应受民法调整?
A.小明要求税务部门退还多缴的所得税。
B.小红丢了手机,贴出寻物启事:“归还者将获得现金奖励。”
C.小李向女朋友保证:“若我在北京找到工作,便带你去美国旅游。”
D.小王作为志愿者,定期在孤儿院提供帮助。
1.3心理学
心理学问题覆盖以下领域:心理学基础、个性及群体心理学、成长心理学、心理健康与异常、心理咨询基础、咨询理念、评估心理学、咨询技巧、咨询实践方法。心理学领域共有2,001个问题。
以下是一个心理学问题示例:
将与己无关的事物视为相关,这种临床症状最可能见于:
A.被害型幻想
B.痴迷型幻觉
C.连接型错觉
D.夸张型妄想
1.4教育
这部分包括语文、数学、物理、化学、政治、历史、地理和生物,题目来自中国普通高等学校招生全国统一考试(中国高考)。教育领域共有3331个问题。
以下是一个数学问题示例:
如果一个圆锥的侧面积是底面积的三倍,那么这个圆锥的侧面展开成扇形时,扇形的中心角大小为()。
A.六十度
B.九十度
C.一百二十度
D.一百八十度
2实验
2.1实验方法
为了衡量多任务测试的性能,本研究计算了所有模型在所有任务上的zero-shot和few-shot准确率。评测了Bloom系列中的bloomz_560m、bloomz_1b1、bloomz_3b和bloomz_7b1_mt;同样评测了清华大学知识工程与数据挖掘研究组开发的ChatGLM6B[2]、复旦大学创建的MOSS16B[3]以及OpenAI的GPT-3.5-tur?bo[1]。
在zero-shot模式下,将题目直接输入到模型以获取答案并计算准确率。以下是一个zero-shot提问示例:
请阅读以下选择题并给出正确选项,不要解释原因。
在笛卡尔坐标系中,点P(m-3,4-2m)不可能位于()
A.一象限
B.二象限
C.三象限
D.四象限
正确答案的序号是:
其中,粗体部分为问题的前缀和后缀,前缀告诉模型应该怎样给出答案,后缀引导模型输出答案序号。而在few-shot模式下,先给模型提供5个问题和答案的例子,再附上问题让模型给出答案。
2.2评测结果
1)模型的大小与其准确性。表1对不同模型的zero-shot准确率进行了比较。本研究发现GPT-3.5-turbo在四个领域都遥遥领先。还发现,MOSS16B模型虽然有160亿参数,却具有接近随机的准确率(大约25%)。相比之下,参数量更低的Bloom家族的bloomz_560m、bloomz_1b1、bloomz_3b、bloomz_7b1_mt以及ChatGLM6B的zero-shot准确率都要更高。
尽管bloomz_560m模型的参数量最小,它的表现却超越了参数量更大的bloomz_1b1模型和MOSS16B模型。这些结果表明,虽然模型参数量是实现强大性能的关键因素,但训练的方式和数据也非常重要。
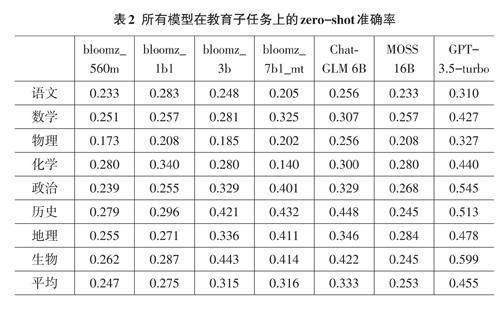
turbo在大多数子任务上都取得了相对最高准确率,紧随其后的是ChatGLM6B,但这两个模型的性能都不均衡。表3显示了所有模型在教育子任务上的准确性。它表明这两个模型在所有任务上的表现都低于60%,GPT-3.5-turbo的准确率从生物的59.9%到语文的31.0%不等,而ChatGLM6B的准确率从历史的44.8%到物理的25.6%不等。
总的来说,所有模型在物理任务上的表现均不佳。表2显示,计算量大的数学、物理科目的准确率往往较低。对于GPT-3.5-turbo而言,准确率最低的任务依次是语文、物理、数学科目。部分原因可能是GPT-3.5-turbo的中文训练数据不足,导致中文语文科目表现不佳,并且与解决程序性问题相比,模型更容易解答陈述性问题。
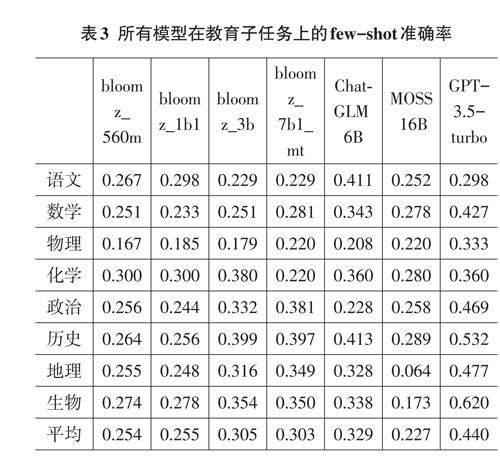
测试还表明,所有模型在few-shot模式下都有不同程度的性能下降(见表3)。例如,与zero-shot准确率相比,GPT-3.5-turbo在语文、化学、政治和地理子任务上的few-shot准确率都有下降。而这种趋势在ChatGLM6B模型上体现得更加明显,ChatGLM6B在所有教育子任务上的few-shot准确率都低于zero-shot准确率。我们认为这可能是由于GPT-3.5-turbo和Chat?GLM6B已经经过了较为充分的指令微调和与人类偏好的对齐,因此few-shot模式下的5个示例反而给模型造成了困扰。
3讨论
3.1评测结果分析
与针对英文语言的MMLU相同,本研究的测试方式不需要大型训练集。本研究假设模型已经通过阅读互联网上大量不同的文本获取了必要的知识,这个过程通常称为预训练。
人类主要通过阅读书籍、听老师讲课和做练习题来学习新知识。因此,本研究提供了few-shot测试模式,并为每个任务提供调试集和测验集。调试集用于few-shot提示,测验集用于计算最终准确率。
以表4展示的医疗领域为例,所有模型在诸多医疗子任务上的准确率都低于60%,表现仅次于GPT-3.5-turbo的ChatGLM6B在诸多医疗子任务上的zeroshot准确率甚至没有超过50%。因此,未来的研究应该特别致力于提高模型在医疗、法律等垂直领域任务的准确性。此外,所有模型在全部任务上的表现都未达到优秀水平(90%)。
目前尚不清楚简单地增大参数量是否能在这些任务上取得提升,因为数据也可能是一个重要的瓶颈。这些大模型训练通常采用海量互联网公开数据,数据的高效筛选以及垂直领域高质量数据的标注也非常重要。
通过观察表1-表4中的数据,可以发现一些有趣的趋势。首先,在四个主要领域中,GPT-3.5-turbo的zero-shot准确率普遍高于其他模型,这表明更大的模型参数量可能有助于提高模型在这些任务上的性能。
然而,即使是性能最佳的GPT-3.5-turbo,其在法律领域的准确率也只有0.239,远低于理想水平,这突出了法律领域对模型理解能力的挑战。
此外,在教育子任务中,所有模型在物理和数学科目上的表现普遍较差,这可能反映出这些科目的问题对模型的推理能力提出了更高的要求。相比之下,模型在历史和政治科目上的表现相对较好,可能因为这些科目更依赖于语言理解能力。
从医疗子任务的表现来看,大多数模型在临床医学和皮肤性病学上的表现相对较好,而在组织胚胎学和药物分析学上表现较差。这可能反映了不同医学领域对模型知识和推理能力的不同要求。
总的来说,虽然大规模预训练模型在多任务测试中取得了一定的成绩,但它们在特定领域和子任务上的表现仍然存在很大的差异。这强调了未来研究的重点应该是提高模型在垂直领域任务上的性能。
3.2模型改进建议
1)领域特定的预训练。针对在法律和医疗等特定领域表现不佳的问题,可以采用领域特定的预训练方法。通过使用与目标领域相关的文本进行预训练,可以增强模型在该领域的理解能力。
2)多任务学习。考虑到模型在不同任务上的表现存在差异,可以采用多任务学习方法,同时训练模型在多个任务上进行优化。这种方法可以帮助模型学习到跨任务的通用特征,提高其在多个领域的表现。
3)任务特定的微调。在zero-shot测试中,模型可能没有充分利用任务的特定信息。可以在微调阶段引入任务特定的信息,例如使用与任务相关的提示或示例,以帮助模型更好地理解任务要求。
4)知识融合。考虑到模型在某些科目上的表现较差,可以尝试将外部知识融合到模型中。例如,对于数学和物理等科目,可以将数学公式和物理定律作为先验知识融入模型中,以提高模型在这些科目上的推理能力。
5)模型架构的改进。针对模型在特定任务上的局限性,可以探索新的模型架构。例如,对于需要强推理能力的任务,可以设计能够进行逻辑推理和关系推断的模型架构。
6)数据增强。为了提高模型在特定任务上的表现,可以采用数据增强技术,生成更多样化的训练样本。这有助于模型学习到更丰富的特征表示,提高其泛化能力。
7)细粒度评估。在评估模型性能时,可以采用更细粒度的评估方法,针对不同的任务和子任务进行单独评估。这有助于更准确地识别模型在哪些方面存在不足,从而有针对性地进行改进。
通过采用这些改进方法,可以有效提高模型在多任务测试中的表现,特别是在那些模型表现不佳的领域和任务上。
5总结
本研究提出了一种新的中文语言测试,覆盖医学、法律、心理学和教育四个主要领域及其多个子任务,旨在评估预训练的中文大型语言模型在解决跨领域问题的能力。通过对不同规模模型的测试发现,模型的参数量增加并不总是能带来性能的提升,模型的训练策略和所使用的数据集的质量对其性能有着决定性的影响。即便是在性能最佳的模型中,其在特定任务上的表现也未能达到理想的优秀水平,这表明当前的模型仍然存在明显的局限性。
为了进一步提升模型的性能,研究者们应该关注如何设计更有效的模型架构,以便更准确地捕捉和学习文本数据中的知识。此外,开发和标注高质量的数据集也至关重要,这不仅能够提供更丰富的训练材料,还能够帮助模型更好地理解和处理复杂的问题。总之,未来的工作应该着重于探索更先进的建模技术和优化数据处理方法,以推动中文大型语言模型在多领域任务中的应用和发展。
