基于关系缩放模型的电商知识图谱链接预测问题研究
2024-07-05潘亚男王军
潘亚男 王军

摘要:针对电商知识图谱链接预测模型精度较低且存在重复推荐同类型商品的问题,提出改进的关系缩放(Relation Scale,RS)模型。基于TransE和TuckER模型,判断三元组头尾实体关系强弱,引入关系缩放因子,确定所有关系路径权重,以提高模型收敛速度。实验结果表明,基于OpenBG500数据集,改进模型的MRR、Hits@1、Hits@3和Hits@10均有提高;相较于传统TransE模型,RSTransE的MRR和Hits@10分别提高了47.4%和71.1%;相较于传统TuckER模型,RSTuckER的MRR和Hits@10分别提高了35.8%和28.4%。RS模型能更准确预测用户需求,实现更加个性化且精准的推荐结果。
关键词:推荐系统;关系缩放;知识图谱;链接预测
中图分类号:
TP391.1
文献标志码:A
基于知识图谱的商品推荐能够有效地过滤信息[1],减少用户获取信息的时间,提高用户处理信息的效率。尽管电商类推荐模型为用户选择商品时带来极大的便利,但仍存在诸多问题如不能很好地理解用户需求造成重复或者过度推荐等。此外,商品间关系更为复杂,其关系路径也有众多选择,如何根据不同情况迅速选取更优关系路径亦广受关注。电商知识图谱(Electronic Commerce Knowledge Graph,ECKG)是推荐系统的分支,由多个三元组构成的知识表示框架,通过优化ECKG改进推荐系统提高电商平台的营销效果已成为研究热点之一[2]。然而,现有知识图谱嵌入的方法忽略了如实体类型和关系路径等能够进一步提高嵌入精度的额外信息,存在一定局限性[3]。近年来,ECKG链接预测问题研究逐渐深入,陆续提出了TransE[4]、TransH[5]、TransD[6]和TuckER[7]等模型,用于预测ECKG中的缺失或未来的链路;通过引入注意力机制[8-10]、向量共享交叉训练机制[11]、多任务学习框架[12]和网络节点创新要素[13]等技术手段,不断完善和扩展知识图谱的内容[14],以构建规模化、高质量的ECKG[15]。将知识图谱链接预测应用于旅游路线推荐[16]、短文本实体消歧[17]、供应链重构[18]、企业关系可视化[19]和电子商务[1]等领域,能够为路线推荐、商品推荐和企业决策提供优化途径。其中常用的有经典的翻译嵌入模型TransE和最新的塔克张量分解模型TuckER。TransE模型的参数较少,能防止欠拟合,梯度下降优化方法中的梯度均为可调整参数,训练耗时更短。传统的TransE模型常用于链接预测领域,处理一对一关系时表现较好,能够处理知识图谱并描述三元组,但在描述头尾实体的关系强弱方面存在不足。TuckER模型采用低秩张量分解的思想,减少了参数的数量,能够在多维度上建模实体和关系之间的复杂关系,有助于降低模型的复杂性和提高泛化能力,从而更好地捕捉知识图谱中的信息,张量分解使其对一对多和多对多关系具有更好的建模能力,但是仍然没有体现关系的重要程度。目前可通过层缩放技术[20]描述关系重要程度。为使推荐模型更好理解用户行为,本文以TransE模型和TuckER模型为基础,提出关系缩放(Relation Scale,RS)模型,通过引入关系缩放因子(Relation Scale Factor,RSF),将原模型改进为RSTransE和RSTuckER。
1 RS模型构建
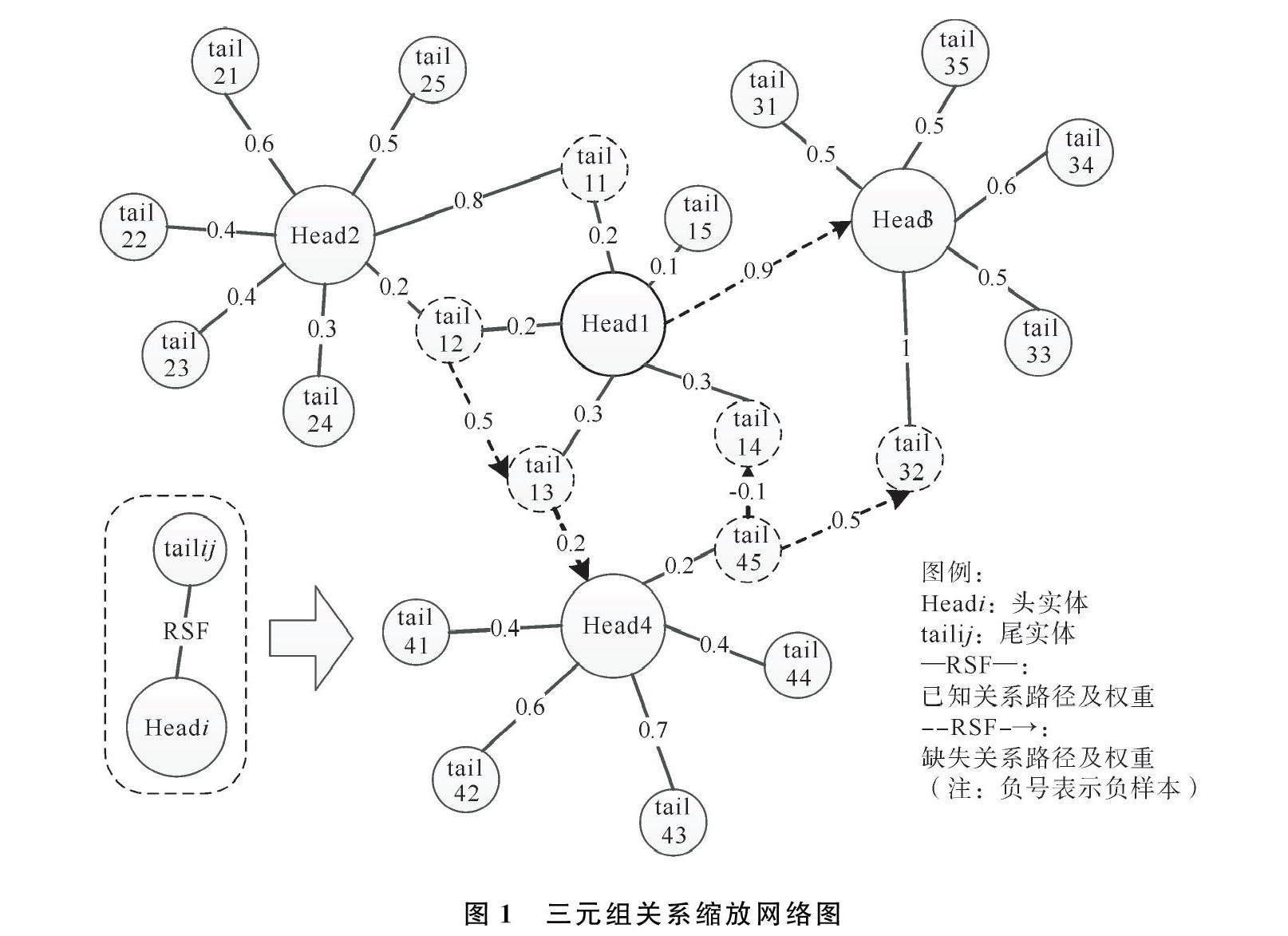
知识图谱的核心是三元组(h,r,t),h∈Eh代表头实体,t∈Et代表尾实体,r∈Rn代表头尾实体两者之间的关系,h,r,t均为向量形式,Eh,Rn,Et分别代表与之对应的集合。链路预测挖掘三元组中实体之间关系路径,以经典的TransE或TuckER模型为例,在链路预测任务中引入RSF提升关系描述能力。RSF可以为关系路径嵌入同长度的向量,每个关系嵌入向量上有唯一与其对应的RSF,其基本结构如图1所示。
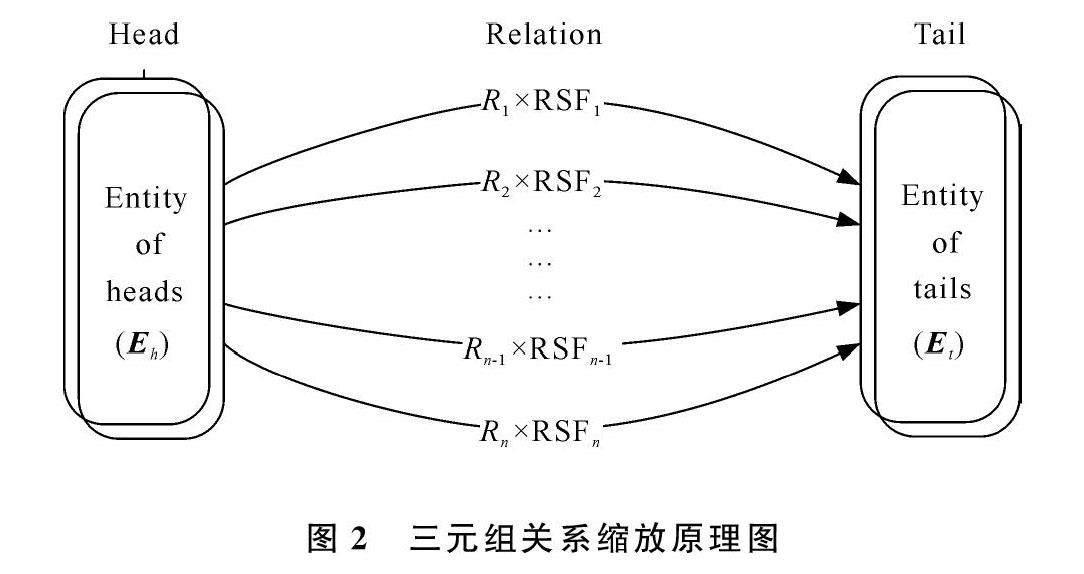
选择Adam优化器控制关系集合Ri中嵌入元素的重要程度,依据关系强弱获得相应的权重,通过控制关系的缩放比例,训练可通过RSF控制关系强弱,关系缩放原理如图2所示,其中Eh表示头实体集合,Ri(i=1,…,n)表示尾头尾实体之间的关系集合,Et表示尾实体集合,RSFj(j=1,…,n)表示关系缩放因子。
模型中实体和关系的所有嵌入方式按照随机过程[21]初始化;每次迭代时,嵌入向量归一化处理,从验证集中采样少量三元组作为小批量数据训练的初始三元组集合,上述三元组采样获取单个缺失三元组。采取具有恒定学习速率的梯度下降方法更新参数,根据模型在验证集上的性能适时停止迭代。正负样本都是均匀划分到训练集和测试集上的,处理方式可以参照公开学术数据集OpenBG500[21]。
1.1 RSTransE模型
处理知识图谱时,传统的TransE模型无法准确地捕捉到三元组中关系的强度差异,即在使用TransE模型时,不能有效地表示并推断知识图谱中不同实体之间关系的重要性,导致在知识图谱的表示中丧失重要的语义信息,从而影响相关任务的准确性。为描述知识图谱中头尾实体的关联性强弱,将关系缩放因子用于TransE模型缩放三元组间关系,以表示它们间的相互作用和影响程度。
RSTransE模型的距离函数采用L3范数的平方,表示为
d(h+(RSF×r)2,t)=‖h‖23+‖(RSF×r)2‖23+‖t‖23-2(hTt+((RSF×r)2)T(t-h))(1)
RSTransE模型的缺失三元组集合为
Q'(h',r,t')=(h',r,t)|h'∈Eh∪(h,r,t')|t'∈Et(2)
其中,上标T表示向量转置;‖·‖3表示L3范数;RSF为关系缩放因子,范围取0~1,其维度和关系r的第1维度相同。各个h,r,t的张量是 (n, D),其中n是每次训练选取的样本个数,D是嵌入维度。
RSTransE模型的损失函数表示为
L=∑(h,r,t)∑(h',r,t')[γ+d(h+r,t)-(h'+r,t')]+(3)
其中,Q'(h',r,t')表示头或尾实体存在缺失的三元组集合,超参数γ是正实数,是调节训练的标准尺度;[x]+为合页损失函数,把负样本正则化,取x的非负部分,若x≤0,则[x]+=0。
约束条件:对于已存在的三元组Q(h,r,t)有h+r≈t;对于不存在的三元组Q(h,r,t),要求h+r与t间隔甚远;实体嵌入的L3范数正则化为L1范数,而关系嵌入的范数没有任何正则化或范数的约束,但也可以正则化。
通过最小化损失函数L完成模型训练,采用随机梯度下降法,使已存在三元组中关系的距离d(h,r,t)尽可能小,使缺失三元组关系的距离d(h'+r,t')尽可能大。所有实体和关系随机获得,做归一化处理。每次选取一批三元组训练,同时对应三元组选取存在缺失的实体,根据验证集上达到的效果选择是否停止。
1.2 RSTuckER模型
引入RSF到TuckER模型,得到RSTuckER模型,用以重新分解TuckER模型,其中头实体嵌入矩阵Eh与头实体h等价,同理尾实体嵌入矩阵Et和t等价,即Ε∈Rne×dei且关系嵌入矩阵R∈Rnr×dri,其中ne和nr分别表示实体和关系的个数,de和dr分别表示实体和关系嵌入向量的维数,得分函数为
φ(es,r,eo)=W×1es×2wRSFr×3eo(4)
wRSFr=RSFj×Ri(5)
其中,es,eo∈Rdei是E中表示头尾实体嵌入向量的行;wr∈Rdri是R中表示关系嵌入向量的行;W∈Rde×dr×dei是核心张量。基于logistic sigmoid函数得到每个三元组得分φ(es,r,eo)为预测概率p,损失函数为
L(p,y)=-1ne∑nei=1(y(i)log(p(i))+(1-y(i))log(1-p(i)))(6)
由于W的参数个数只取决于实体和关系的嵌入维度,而不取决于实体或关系的个数,因此,其参数个数随实体和关系嵌入维数de和dr的增加而线性增加。与DistMult、ComplEx和SimplE等简单模型将所有知识编码到嵌入关系中有所不同,TuckER使用核心张量W进行多任务学习,将其中一部分学到的知识存储在该张量中并与所有实体和关系共享。TuckER的核心张量可视为一个共享的“原型”关系矩阵池,根据嵌入的每个关系中的参数进行线性组合。
2 实验设置
2.1 数据集
本文基于OpenBG500数据集评估RS模型有效性。OpenBG500由OpenBG中提取,OpenBG是涵盖产品和消费需求的大规模多模态数据集[1, 21]。OpenBG500是开放的中国电子商务和商业知识图谱数据集,包含249 743个实体,500个关系,验证集5 000个实体,测试集5 000个实体,改进研究均基于验证集完成(图3)。
2.2 模型测评指标
实验采用MRR、Hits@1、Hits@3和Hits@10作为测评指标[1, 9, 13, 22]。对于任意三元组(h,r,t),通过更换头实体或尾实体得到存在缺失的三元组,头实体缺失的三元组用(?,r,t)表示,尾实体缺失的三元组用(h,r,?)表示,其中?表示缺失部分。例如,头部和尾部的集合是固定个数(若待替换项有n-1项),针对生成的三元组集合(n-1个)计算距离,按照距离由小到大排序。
MRR是链接预测正确实体排名倒数的平均值,对于(h,r,?),若第1个正确答案排在第n位,则该次测评得分为1/n,由于只计算前10个实体,所以此处n最大为10,如果前10个实体中不包含正确答案,则测评得分为0,最终对多次测评得分求平均值,计算公式为
MRR=1Q∑Qi=11ranki(7)
1ranki=1i0(8)
其中,Q为三元组的集合,Q表示测试的三元组的个数。MRR反应的是被找到的实体在所有实体按推荐顺序排列后的位置,表示模型的推荐能力。
Hits@n是指在链接预测中排名小于n的三元组的平均占比,表示模型能够正确表示三元组关系的能力,计算公式为
Hits@n=1Q∑Qi=1Euclid Math TwoIA@(ranki≤n)(9)
其中,Euclid Math TwoIA@(·)是indicator函数(若条件真则值为1,否则为0),一般取n等于1、3或10,且该指标越大越好。
2.3 参数设置
实验使用一台64位操作系统的计算机,CPU为Intel酷睿i5-1155G7,GPU为NVIDIA GeForce MX450,PyThorch深度学习开发框架,Python作为开发语言。为保证训练效率和模型性能,将Adam作为训练优化器。RSTransE模型中的参数配置:批量大小batch_size设置为100 000,迭代次数epoch为40,margin调整为1,距离范数distance_norm调整为3。RSTuckER模型中的参数配置:批量大小batch_size设置为128,迭代次数epoch为40,margin调整为1,距离范数distance_norm调整为3,学习率learning_rate调整为0.05,衰减率decay_rate调整为1,实体嵌入维度筛选为200,输入层损失为0.3,第1隐藏层的损失为0.4,第2隐藏层的损失为0.4,标签平滑量为0.1。
3 结果与讨论
3.1 关系嵌入维度实验
对于较小规模的知识图谱,嵌入维度在50~200之间,由于RSTransE和RSTuckER模型选取嵌入维度的方式相同,因此,只讨论RSTransE模型的关系嵌入维度的实验,实验选取4个常用指标,RSF为0.4时,其它参数保持不变,不同嵌入维度下各项指标的值如表1所示。
嵌入维度D为50时,单次训练所需时间最短,但各项指标最低;嵌入维度D为200时,Hits@3和Hits@10均最大,但耗时最长且超过100 ms,嵌入维度D为100时,各项指标较高,单次训练所需时间也较短;因此,嵌入维度调整为100。同理,RSTuckER模型选取嵌入维度为200较为合适。
3.2 RSTransE模型结果
RSF取值范围调整为0~1,取值间隔为0.1。经过RSTransE模型多次训练后,实验结果见表2。RSF取0.4时,MRRmax=0.560 3,Hits@1max= 0.451 4,Hits@10 max= 0.790 2;RSF取0.3时,Hits@3 max=0.641 4。综上,RSF取0.4时,总体改进效果最优。
3.3 RSTuckER模型结果
RSTuckER模型改进过程中,RSF取值范围同RSTransE模型,实验结果见表3。RSF取0.2时,MRR max= 0.717 1,Hits@1 max= 0.608 0;RSF取0.5时,Hits@3 max= 0.798 4;RSF取0.9时,Hits@10 max= 0.910 6。因此,考虑全部指标或者仅考虑Hits@10时,RSF应取0.9;仅考虑Hits@3时,RSF应取0.5;考虑Hits@1和MRR,RSF应取0.2。
3.4 其他方法对比分析
经过对TransE、DisMult、ComplEx和TuckER等模型的实验与对比分析可知,上述方法中,TransE和TuckER的链接预测结果较好。基于原模型,引入RSF调控三元组关系强弱。通过RSTransE、RSTuckER和其他方法的对比实验,验证了RSF对原模型的改进具有有效性与优越性(表4)。通过关系缩放模型能够更深入地研究知识图谱的语义联系,增强知识表达能力,提升各类任务中模型的性能。
4 结论
RS模型能实现根据客户需求变化改变实体之间关系的重要程度,从而更准确地预测实体之间的关系路径,有助于改进被推荐商品和用户之间的关联性、重要性。为了更好的验证RS模型的适用性,改进经典模型TransE和TuckER,得到新的链路预测模型RSTransE和RSTuckER。实验结果表明,在OpenBG500数据集上应用RS模型,证实了关系缩放模型可以更准确地预测缺失的关系,提高知识图谱应用的性能和效果,这使得商品推荐的准确性得到了显著提高,更加符合用户的偏好。
参考文献
[1]ZHANG W,WONG C M, YE G Q, et al. Billion-scale pre-trained e-commerce product knowledge graph model[C]// 2021 IEEE 37th International Conference on Data Engineering (ICDE). Chania, 2021: 2476-2487.
[2]杨东华, 何涛, 王宏志, 等. 面向知识图谱的图嵌入学习研究进展[J]. 软件学报, 2022, 33(9): 3370-3390.
[3]PENG C Y, XIA F, NASERIPARSA M, et al. Knowledge graphs: Opportunities and challenges[J]. Artificial Intelligence Review, 2023, 56: 13071-13102.
[4]BORDES A, USUNIER N, GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data[C]// 26th International Conference on Neural Information Processing Systems. Cambridge, 2013: 2787-2795.
[5]WANG Z,ZHANG J W, FENG J L, et al. Knowledge graph embedding by translating on hyperplanes[C]// 28th AAAI Conference on Artificial Intelligence. Québec, 2014:1112-1119.
[6]FUSAR-POLI P. TRANSD recommendations: Improving transdiagnostic research in psychiatry[J]. World Psychiatry, 2019, 18(3): 361-362.
[7]BALAEVIC' I, ALLEN C, HOSPEDALES T M. Tucker: Tensor factorization for knowledge graph completion[C]// 9th International Joint Conference on Natural Language Processing. Hong Kong, 2019: 5185-5194.
[8]WANG X, HE X N, CAO Y X, et al. KGAT: Knowledge graph attention network for recommendation[C]// 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Anchorage, 2019: 950-958.
[9]吴铮, 陈鸿昶, 张建朋. 基于双曲图注意力网络的知识图谱链接预测方法[J]. 电子与信息学报, 2022, 44(6): 2184-2194.
[10] ZHANG W,DENG S M, CHEN M Y, et al. Knowledge graph embedding in e-commerce applications: Attentive reasoning, explanations, and transferable rules[C]// 10th International Joint Conference on Knowledge Graphs. Bangkok, 2021: 71-79.
[11] 陈文杰, 文奕, 张鑫, 等. 一种改进的基于TransE知识图谱表示方法[J]. 计算机工程, 2020, 46(5): 63-69+77.
[12] 卞嘉楠, 冒泽慧, 姜斌, 等. 基于知识图谱和多任务学习的工业生产关键设备故障诊断方法[J]. 中国科学, 2023, 53(4): 699-714.
[13] 何建佳, 廖耀文, 周洋. 基于产业互联网络节点创新要素的链接预测方法[J]. 计算机应用研究, 2023, 40(10): 1-5.
[14] 张天成, 田雪, 孙相会, 等. 知识图谱嵌入技术研究综述[J]. 软件学报, 2023, 34(1): 277-311.
[15] GOMEZ-PEREZ J M, PAN J Z, VETERE G, et al. Enterprise knowledge graph: An introduction[M]. Switzerland: Springer International Publishing, 2017.
[16] 王翊臻, 云红艳, 李正民. 旅游顺承事理图谱的构建及应用研究[J]. 青岛大学学报(自然科学版), 2022, 35(1): 34-39+47.
[17] 王荣坤, 宾晟, 孙更新. 融合多特征和由粗到精排序模型的短文本实体消歧方法[J]. 青岛大学学报(自然科学版), 2022, 35(3): 16-21.
[18] ROLF B, MEBARKI N, LANG S, et al. Using knowledge graphs and human-centric artificial intelligence for reconfigurable supply chains: A research framework[J]. IFAC-PapersOnLine, 2022, 55(10): 1693-1698.
[19] 林莉, 云红艳, 贺英,等. 基于企业知识图谱构建的可视化研究[J]. 青岛大学学报(自然科学版), 2019, 32(1): 55-60.
[20] TOUVRON H, CORD M, SABLAYROLLES A, et al. Going deeper with image transformers[C]// IEEE/CVF International Conference on Computer Vision. Montreal, 2021: 32-42.
[21] XIE X, ZHANG N Y, LI Z B, et al. From discrimination to generation: knowledge graph completion with generative transformer[C]// Companion Proceedings of the Web Conference. Lyon, 2022: 162-165
[22] EBISU T, ICHISE R. TORUSE: Knowledge graph embedding on a lie group[C]// 32th AAAI Conference on Artificial Intelligence. Lousiana, 2018: 1819-1826.
Research on the E-commerce Knowledge Graph Link Prediction Problem
Based on the Relation Scale Model
PAN Ya-nan, WANG Jun
(Business College, Qingdao University, Qingdao 266061, China)
Abstract:
To address the issues of low accuracy in link prediction models for e-commerce knowledge graphs and the repeated recommendation of the same type of products, an improved Relation Scale (RS) model was proposed. The strength of relationships between the head and tail entities of triples was assessed using the TransE and TuckER model. The weights of all relationship paths were determined by introducing a scaling factor, thus enhancing the models convergence speed. Experimental results show that the MRR, Hits@1, Hits@3 and Hits@10 of the improved models are all enhanced based on the OpenBG500 dataset. The MRR and Hits@10 for the RSTransE model increase by 47.4% and 71.1% respectively, compared with the traditional TransE model. The MRR and Hits@10 for the RSTuckER model increase by 35.8% and 28.4% respectively, compared with the traditional TuckER model. These findings indicate that the RS model can more accurately predict user needs and achieve more personalized and precise recommendation results.
Keywords:
referral system; relational scale; knowledge graph; link prediction
