基于分层特征交叉注意力的小样本马铃薯病害叶片识别
2024-07-03李坤刘婧齐赫
李坤 刘婧 齐赫


doi:10.15889/j.issn.1002-1302.2024.10.029
摘要:为了及时、准确地识别马铃薯叶片病害,有效预防马铃薯早期病变并提高马铃薯的产量和质量,针对传统马铃薯病害叶片识别方法过度依赖标注样本和特征利用不充分的问题,提出一种基于分层特征交叉注意力的小样本马铃薯病害叶片识别方法。首先,利用VGG-16网络的不同编码块,将支持分支和查询分支的马铃薯叶片映射到深度特征空间,并按照不同块的输出构造分层特征集;其次,设计一种交叉注意力网络,实现双分支网络分层特征之间的信息交互,强化特征的表达;最后,利用掩码平均池化获得交互特征的全局信息,并借助无参数的度量学习指导未知马铃薯病害叶片类型的识别。通过在AI Challenger 2018开源数据集、自建小样本马铃薯数据集上进行测试,所提出模型分别可以实现0.973、0.951的识别精度,优于当前主流的马铃薯病害叶片识别模型,具有较好的实际应用价值。
关键词:马铃薯病害叶片识别;小样本学习;分层特征;交叉注意力网络
中图分类号:TP391.41 文献标志码:A
文章编号:1002-1302(2024)10-0210-07
收稿日期:2023-07-22
基金项目:海南省自然科学基金(编号:619QN246);浙江省博士后科研项目(编号:ZJ2021028)。
作者简介:李 坤(1983—),女,辽宁北票人,博士,讲师,研究方向为智能农业大数据、植物病害检测。E-mail:likun5311@sina.com。
随着农业科技的不断发展,农作物病害的早期检测和识别对于提高农作物产量和质量、保障粮食安全具有重要意义。马铃薯是全球重要的粮食作物之一,常受到各种病害的威胁,如马铃薯晚疫病、马铃薯早疫病等[1]。这些病害迅速扩散和侵害,严重影响马铃薯的产量和质量,给农民带来巨大的经济损失。
传统的马铃薯病害识别方法主要依赖于人工检查和经验判断,该类方法存在主观性强、效率低、误判率高等问题[2-3]。近年来,深度学习技术的兴起为马铃薯病害识别带来了新的机遇[4-5]。深度学习模型可以通过学习大量的马铃薯病害图像数据,从中自动提取特征,并准确识别不同的病害类型。代国威等提出一种基于机器学习算法的马铃薯早、晚疫病检测模型,该方法借助Fast K-means算法实现不同天气、不同时间段下马铃薯叶片病害的检测[6]。陈从平等针对现有模型在复杂场景下识别率低的问题,提出一种基于深度学习算法的马铃薯叶片病害识别方法,通过从整张图片中分割出马铃薯叶片,并提取叶片在空间中的颜色、纹理等细粒度特征,依据提取的特征识别出病害叶片[7]。王林柏等针对病害区域定位精度不高的问题,提出一种基于卷积神经网络的马铃薯叶片病害检测方法,通过捕获待识别对象的中心点坐标来提升模型的定位性能,同时借助中心点坐标回归获得目标区域[8]。类似地,惠巧娟等基于深度学习算法提出一种叶片病害检测方法,通过建立病害叶片在空间特征中不同层级特征的交互,强化特征表达的可靠性;并通过在开源的Plant数据集上进行测试,验证了设计的合理性[9]。李康顺等针对人工诊断成本高的问题,提出一种改进YOLO的农作物叶片病害检测方法,借助空间和通道注意力机制,强化特征表达的鲁棒性;还设计了一种焦点损失函数,提升了分类的性能[10]。熊梦园等借助迁移学习提出一种玉米叶片病害检测方法,通过在传统RseNet-50网络中嵌入通道和空间注意力机制,促使模型聚焦病害区域[11]。赵越等将Faster R-CNN网络应用到马铃薯叶片病害的检测任务中,通过采用数据增强的方式缓解模型识别性能过度依赖训练数据集的问题;利用预训练模型作为特征提取的基线模型,有效提升了模型的泛化性能[12]。
上述马铃薯叶片病害检测模型在自建或开源数据集上均可以实现较为理想的检测结果。然而,大多数模型的识别性能仍然依赖大量的训练数据;该类数据集的标注成本高,不利于实际应用。最新的方法通过涂鸦、框线、关键点标注的弱监督方式可以缓解上述数据标注成本高的问题,但该类模型对于未知新类的泛化性能不佳;此外,模型的微调仍然需要一些带标签的监督信息。针对上述问题,提出一种基于分层特征交叉注意力的小样本马铃薯叶片病害识别方法,主要缓解现有模型特征利用不充分和模型过度依赖训练样本的问题。其主要创新点如下:
(1)提出一种支持分支和查询分支的双分支特征交互模块,通过建立支持分支、查询分支每层特征间的信息交互,充分挖掘跨分支特征间的关联性。
(2)利用小样本学习网络的支持分支,指导查询分支中的目标识别,旨在提高模型对于未知新类病害的泛化性能。
(3)利用无参数的度量学习,实现特征间的关联性计算,这有助于减少模型参数、降低计算资源。
1 小样本学习任务定义
小样本学习网络旨在利用有限的支持图片和对应的真实标签,指导与之同类的查询图片中的目标识别。例如,马铃薯病害叶片数据集按照类的定义划分为Base集和Novel集,Base集用于模型的训练,Novel集用于模型鲁棒性和泛化性的测试;此外,Base集和Novel集中的类没有交集,即Cbase∩Cnovel=。与传统深度学习方式不同的是,小样本学习采用多示例学习模式,即Base类Cbase包含多个支持集S和查询集Q[13]。每个S集包含1组支持图片和对应的标签,即Si=[(Ik,Lk)]Kk=1,其中Ik表示支持图片,Lk表示对应的真实标注。类似地,查询集可表示为Qj=[(Iq,Lq)],并且Lq仅用于训练阶段。
2 马铃薯叶片病害识别方法
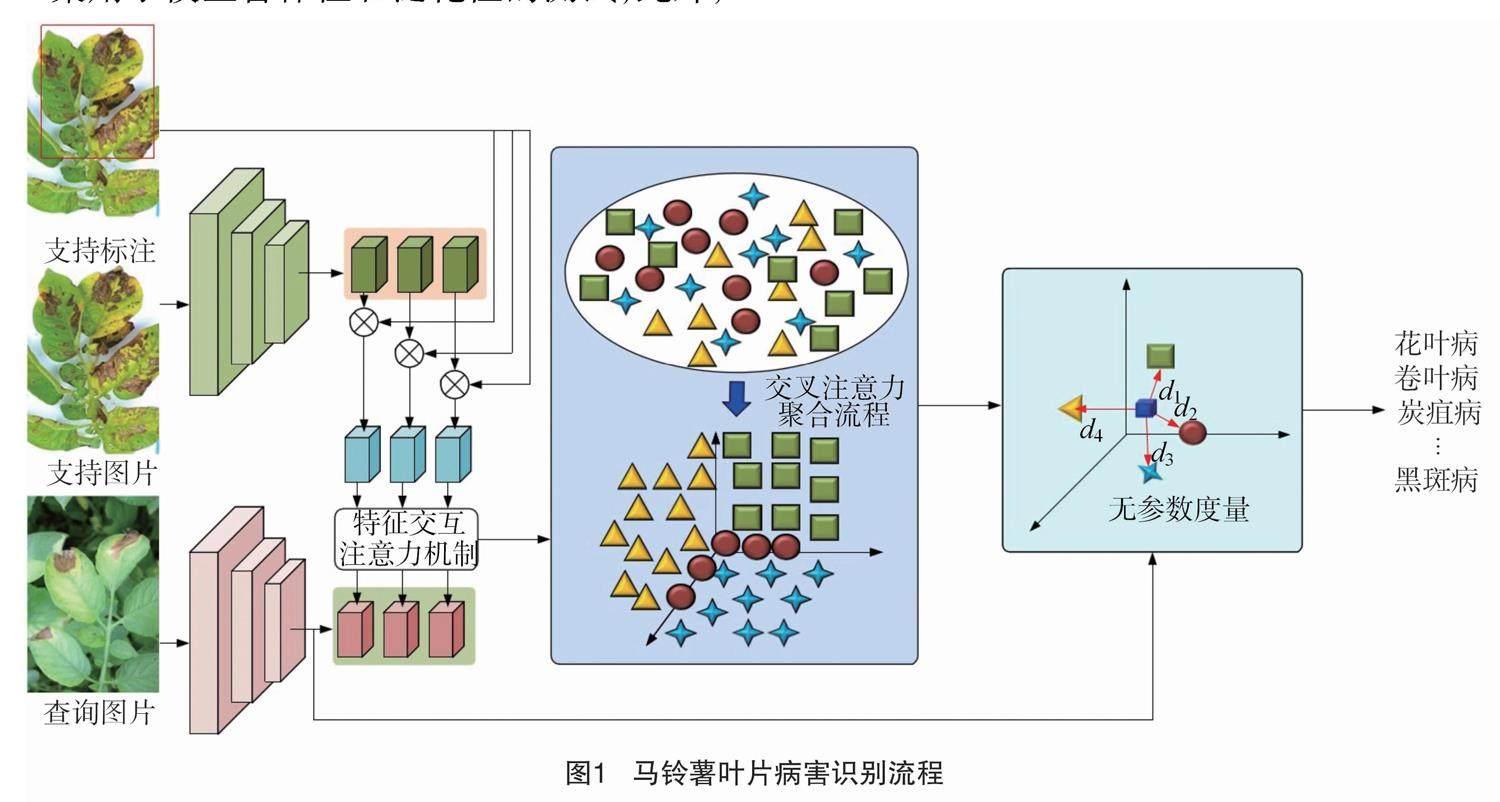
所提出模型包括特征提取、双分支特征交互、无参数度量3个模块,模型结构如图1所示。首先,在特征提取阶段采用ImageNet数据集上预训练的VGG-16作为主干网络,将双分支网络输入的马铃薯病害叶片图像映射到深度特征空间,构造支持分支特征集和查询分支特征集。然后,利用支持图片的真实标注,将支持特征集划分为前景特征集、背景特征集,并建立前景特征集、查询特征集中每层特征间的信息交互,强化特征间和特征内的信息表达能力。最后,采用无参数的度量学习,计算交互特征集和查询特征间的相似度,依据相似度分数指导查询图片中的目标识别。
2.1 特征提取
VGG-16网络在图像分类、目标检测、语义分割任务中得到了广泛应用。此处以VGG-16为主干网路为例,阐述马铃薯叶片病害图片分层特征提取与交互的详细流程[14]。VGG-16网络的结构如图2所示。
VGG-16是一种经典的卷积神经网络,由13层是卷积层、5层池化层和3层全连接层组成,并将池化层的输出作为视觉编码特征。在特征提取方面,VGG-16网络可以分为低层特征、中间层特征、高层特征。低层特征可以捕获图像的底层结构和纹理特征,如边缘、角点等;中间层特征在空间上相对较大,包含更丰富的语义信息,能够表示图像中的部分目标或局部结构;高层特征虽然可以捕获物体的形状、部件的组合等抽象和语义丰富的特征,但由于下采样操作,极易造成信息的丢失[15-16]。为此,本研究利用一组共享权重的VGG-16作为主干网络,提取支持图片和查询图片在低层、中间层、高层空间中的特征表达。每层特征表示如公式(1)所示。
Fl=avg_pool[conv1→x(I)]
Fm=avg_pool[conv1→y(I)],x Fh=avg_pool[conv1→z(I)]。(1) 式中:Fl表示低层特征图,Fm表示中间层特征图,Fh表示高层特征图;avg_pool(·)表示平均池化操作,conv(·)表示卷积操作,x、y、z分别表示低层、中间层、高层特征图输出层对应的层数。 此外,为了直观展示不同层特征对病害区域的聚焦程度,分别将低层、中间层、高层特征聚焦区域可视化,可视化效果如图3所示。可以看出,低层特征更聚焦纹理信息,中间层更关注局部结构,高层更关注目标区域。 2.2 双分支特征交互 支持分支和查询分支虽然共享相同的语义类,但由于相同类地处位置不同,以及不同视角和背景因素的影响,导致相同类之间存在很大差异。为此,本研究在支持分支、查询分支映射特征图中建立不同层之间的特征交互,促进不同层特征间的信息传递和融合,旨在提高模型对双分支图片共有语义信息的捕获能力;其次,双分支不同层间的深度融合也有助于缓解跨域数据集中空间语义信息分布离散的问题。本研究设计的分层特征交互模块流程如图4所示。 图4中,低层Fl、中间层Fm、高层特征Fh分别表示融合支持分支和查询分支后的特征,此处采用交叉注意力机制实现跨分支间不同层的特征融合,跨分支间的特征融合计算如公式(2)所示。 Fl=softmaxFqlFsTldFql Fm=softmaxFqmFsTmdFqm Fh=softmaxFqhFsThdFqh。(2) 式中:Fql、Fqm 、 Fqh和 Fsl、 Fsm、 Fsh分别表示查询特征和支持特征的低层、中间层、高层特征,d表示特征维度,T表示转置。 在跨分支分层特征融合后,得到低层融合特征Fl′、中间层融合特征Fm′、高层融合特征Fh′,并采用分支间交叉注意力融合策略对低层和中间层进行融合,得到2个通道的融合特征Flm;然后,将融合特征与高层特征进行融合,得到最终3个通道的融合特征图Fus。具体计算如公式(3)所示。 Flm=softmaxFl′F′TmdFl′ Fus=softmaxFlm′F′ThdFlm′。(3) 此处,Fus集成了马铃薯叶片低层、中间层、高层的上下文语义信息,并以此作为指导查询图片中目标识别的指导信息。 2.3 无参数度量 当前主流的小样本学习框架中,采用卷积运算作为融合指导信息和查询图片特征的度量方法[17-18]。然而,该类有参数学习的方法参数量大,难以满足实际场景中对于实时识别的高要求。为此,本研究采用无参数的度量方法计算指导信息和查询图片中每一位置特征间的相似度。具体计算如公式(4)所示。 Cs=Fq·Fus|Fq||Fus|。(4) 式中:Cs表示查询特征和指导信息间的余弦相似度值;Fq表示查询特征;|·|表示向量的模。 马铃薯叶片病害区域较小,并且病害区域并非单一连续区域。为此,本研究通过逐像素对查询特征图和指导信息做相似度计算,并根据每一位置处的最大相似度值,指导查询图片中每一位置处的像素进行分类。具体计算如公式(5)所示。 ms=argmax[Cs(x,y)s→q]。(5) 式中:ms表示最大相似度值;argmax(·)表示最大相似度函数,用于计算每一位置处的查询特征与指导信息特征集间的最大相似度值[19];Cs(x,y)s→q表示当前位置(x,y)处查询特征与指导信息间的相似度。 最后,为了实现模型和指导信息集的优化,采用交叉熵损失函数[20],具体计算如公式(6)所示。 ls=-∑Lilg(pi)。(6) 式中:ls表示交叉熵损失函数;Li表示真实标签;pi表示预测结果;特别地,pi是所有位置处的像素分类结果的拼接。 3 试验 3.1 试验环境与评价指标 试验环境采用Windows 10操作系统,搭载cuDNN V8.2深度学习加速库、NVIDIA CUDA 11.1,支持GPU加速的PyTorch深度学习框架,GPU为NVIDIA GeForce RTX 3090 24 GB,编程语言采用Python,编辑器采用Pycharm。初始学习率为0.001,优化器采用Adam,迭代次数为90。模型训练与测试阶段的精准率和损失曲线如图5所示。 为验证本研究方法的性能,选择当前目标识别领域主流的评价指标:精准率(Precision)、召回率(Recall)、F1分数。计算如公式(7)至公式(9)所示。 Precision=TPTP+FP×100%;(7) Recall=TPTP+FN×100%;(8) F1分数=2×Precision×RecallPrecision+Recall×100%。(9) 式中:TP表示被模型正确预测的病害叶片数;FP表示被模型错误预测的病害叶片数;FN表示没有检测出的病害叶片数。 3.2 试验数据集 模型训练数据集包括AI Challenger 2018开源马铃薯病害叶片数据集、自建马铃薯病害叶片数据集。AI Challenger 2018开源马铃薯病害叶片数据集包括健康、一般程度的早疫病、严重程度的早疫病、一般程度的晚疫病、严重程度的晚疫病马铃薯叶片等5种类型数据,总共包括2 100幅图片,并按照 7 ∶3 的比例划分为训练集和测试集。自建数据集中的图片主要来源于甘肃张掖某马铃薯种植基地,主要选择马铃薯黑痣病、马铃薯轮纹病、马铃薯黄萎病、健康叶片4种类型,总共包括500幅图片,同样按照7 ∶3的比例划分为训练集和测试集。2种数据集中不同类型的马铃薯病害叶片数据样本分布如图6所示。 3.3 试验结果与分析 为了验证所设计模型的有效性,分别在开源AI Challenger 2018马铃薯病害叶片数据集、自建马铃薯病害叶片数据集上进行测试。 3.3.1 AI Challenger 2018马铃薯病害叶片数据集 为验证所设计模型的有效性,选择当前主流的马铃薯病害叶片检测模型进行对比试验,对比模型包括MobileNet V3[18]、SPP[8]、YOLO v3[8]、YOLO v4[8]、GLCM[6]、DLNet[7]、Faster R-CNN[12]。不同模型在AI Challenger 2018开源马铃薯病害叶片数据集上的识别结果见表1。 通过分析表1中不同模型的识别结果,可以发现:(1)本研究方法综合性能提升效果明显,所设计模型获得的精准率、召回率、F1分数分别为0.973、0.951、0.964。(2)相比于对比模型中表现最好的MobileNet v3,本研究方法的精准率提升了0.83%;相比于所有对比模型中表现最好的DLNet,本研究方法的召回率提升了1.82%;相比于所有对比模型中表现最好的Faster R-CNN,本研究方法的F1分数提升了1.37%。(3)所设计模型的时间开销为51.68 ms,相比于所有对比模型中测试开销最低的YOLO v3,降低了12.59 ms。究其原因,所设计模型在度量阶段采用无参数的度量计算方式,有效降低了系统检测时间开销,具有更好的实时性。(4)虽然本研究模型在单一指标上提升效果不显著,但综合精准率、召回率、F1分数3个指标,综合性能优势明显,主要原因是本研究模型将支持分支和查询分支输入图片的低层、中间层、高层特征进行了融合,利用融合特征指导未知新类病害图片的分割,这极大地提升了特征表达的鲁棒性和可靠性。此外,本研究设计的跨分支间的特征融合方式可以缓解支持图片、查询图片跨域间数据分布离散的问题,这为实际场景下识别马铃薯病害叶片提供了一种新的思路。 3.3.2 自建的马铃薯病害叶片数据集 为了进一步验证所设计模型在实际场景中对于马铃薯病害叶片的识别性能,采集某农区马铃薯种植基地的病害叶片,并选择常见的目标识别模型进行对比试验,对比模型包括YOLO v3、Faster R-CNN、MobileNet v3、GoogleNet、Inception v4。不同模型在自建的马铃薯病害叶片数据集上的测试结果见表2。 从表2可以看出,相比开源数据集上的识别结果,真实场景下模型的识别性能均有所下降。然而,相比当前主流的目标识别模型,本研究方法仍存在一定的优势。本研究方法的精准率为0.951,相比Faster R-CNN模型,提升了2.70%;本研究方法的召回率为0.938,相比GoogleNet模型提升了2.74%;本研究方法的F1分数为0.946,相比MobileNet v3模型提升了1.39%。在时间开销方面,所设计模型相比YOLO v3降低了15.36 ms,具有更低的时间开销。上述测试结果进一步验证了所设计模型不仅在开源数据集上取得了可竞争性的结果,在自建数据集上同样具有竞争性。究其原因,小样本学习网络建立的指导规则更有利于未知类的识别,并且已有成果也验证了小样本学习网络中建立的支持-查询规则更有益于模型的泛化性能,这为马铃薯未知新类病害叶片的识别提供了可能。 图7给出了本研究模型在2个数据集上的混淆矩阵。可以看出,所提出模型在2个数据集上均可以实现较为理想的测试结果,并且不同类之间的误报概率较小,这也验证了所设计模型可以有效捕获到类间和类内特征。为了进一步直观展示不同类特征表示的分布情况,将双分支特征交互后的融合特征进行可视化,特征分布如图8所示。可以看出,在2个数据集上,经过特征交互后,类间距离增大、类内距离减小。 3.4 消融试验 为验证所设计模型的主要组件:多尺度特征提取和双分支特征交互模块对提升马铃薯病害叶片识别性能的作用,设计表3所示的消融试验。此处,以VGG-16网络的高层输出特征构造指导信息,指导查询图片中的马铃薯病害叶片识别为基线模型。可以看出,相比单一使用高层特征构造的指导信息指导查询图片中马铃薯病害叶片的识别性能,融合多尺度特征可以显著提高识别的性能。然而,最好的识别结果是融合支持分支和查询分支中每一层的特征。上述结果也验证了本研究设计的初衷,通过挖掘支持分支、查询分支间特征的上下文语义关联,来强化特征表达的鲁棒性和泛化性。 4 结论 提高马铃薯病害叶片的识别精度,降低识别时间开销,是当前马铃薯病害叶片识别领域的难点和热点。本研究提出了一种基于分层特征交叉注意力的小样本马铃薯叶片病害识别方法。通过提取支持分支和查询分支的高层、中间层、低层特征,并建立双分支特征间的信息交互,强化特征表达的鲁棒性和泛化性能;其次,利用无参数的度量实现指导信息与查询特征之间的相似度计算,有效缓解模型识别开销大的问题。主要结论包括: (1)提取单一分支特征的高层、中间层、低层特征,有助于强化马铃薯病害叶片特征的表达能力; (2)建立支持分支和查询分支每一层特征间的信息交互,有助于捕获跨域数据集中的不变特征,提升模型对于未知病害区域的泛化性能; (3)所提出模型可以在开源AI Challenger 2018马铃薯病害叶片数据集上实现0.973的识别精准率,在自建数据集上实现0.951的识别精准率;在保持识别精度的同时,有效降低了模型测试的时间开销。 参考文献: [1]Rashid J,Khan I,Ali G,et al. Multi-level deep learning model for potato leaf disease recognition[J]. Electronics,2021,10(17):2064. [2]Chen W R,Chen J D,Zeb A,et al. Mobile convolution neural network for the recognition of potato leaf disease images[J]. Multimedia Tools and Applications,2022,81(15):20797-20816. [3]Hou C J,Zhuang J J,Tang Y,et al. Recognition of early blight and late blight diseases on potato leaves based on graph cut segmentation[J]. Journal of Agriculture and Food Research,2021,5:100154. [4]Ngugi L C,Abelwahab M,Abo-Zahhad M. Recent advances in image processing techniques for automated leaf pest and disease recognition:a review[J]. Information Processing in Agriculture,2021,8(1):27-51. [5]Kashyap C K,Rashmi M,Chandan C,et al. Automated recognition of optical image based potato leaf blight diseases using deep learning[J]. Physiological and Molecular Plant Pathology,2022,117:101781. [6]代国威,胡 林,樊景超,等. 基于GLCM特征提取和投票分类模型的马铃薯早、晚疫病检测[J]. 江苏农业科学,2023,51(8):185-192. [7]陈从平,钮嘉炜,丁 坤,等. 基于深度学习的马铃薯病害智能识别[J]. 计算机仿真,2023,40(2):214-217,222. [8]王林柏,张 博,姚竟发,等. 基于卷积神经网络马铃薯叶片病害识别和病斑检测[J]. 中国农机化学报,2021,42(11):122-129. [9]惠巧娟,孙 婕. 基于多尺度特征度量元学习的玉米叶片病害识别模型研究[J]. 江苏农业科学,2023,51(9):199-206. [10]李康顺,杨振盛,江梓锋,等. 基于改进YOLOX-Nano的农作物叶片病害检测与识别方法[J]. 华南农业大学学报,2023,44(4):593-603. [11]熊梦园,詹 炜,桂连友,等. 基于ResNet模型的玉米叶片病害检测与识别[J]. 江苏农业科学,2023,51(8):164-170. [12]赵 越,赵 辉,姜永成,等. 基于深度学习的马铃薯叶片病害检测方法[J]. 中国农机化学报,2022,43(10):183-189. [13]Jiang W,Huang K,Geng J,et al. Multi-scale metric learning for few-shot learning[J]. IEEE Transactions on Circuits and Systems for Video Technology,2021,31(3):1091-1102. [14]汪 泉,宋文龙,张怡卓,等. 基于改进VGG16网络的机载高光谱针叶树种分类研究[J]. 森林工程,2021,37(3):79-87. [15]Elaraby N,Barakat S,Rezk A. A conditional GAN-based approach for enhancing transfer learning performance in few-shot HCR tasks[J]. Scientific Reports,2022,12:16271. [16]Pambala A K,Dutta T,Biswas S. SML:semantic meta-learning for few-shot semantic segmentation[J]. Pattern Recognition Letters,2021,147(12):93-99. [17]Wang C J,Xin C,Xu Z L. A novel deep metric learning model for imbalanced fault diagnosis and toward open-set classification[J]. Knowledge-Based Systems,2021,220:106925. [18]徐振南,王建坤,胡益嘉,等. 基于MobileNet V3的马铃薯病害识别[J]. 江苏农业科学,2022,50(10):176-182. [19]孙小琳,季伟东,王 旭. 基于余弦相似度反向策略的自然计算方法[J]. 信息与控制,2022,51(6):708-718. [20]李叔敖,解 庆,马艳春,等. 基于路径聚合扩张卷积的图像语义分割方法[J]. 计算机工程与科学,2021,43(4):712-720.
