基于深度学习的物流跟踪管理
2024-06-21胡瑶胡经蒙杨欣怡孙世诚刘庆华
胡瑶 胡经蒙 杨欣怡 孙世诚 刘庆华

摘 要:利用先进的人工智能和计算机视觉技术,物流管理取得了重大进展。如何建立一套能够有效解决物体遮挡、运动模糊、目标相似等实际问题的检测技术,是一个重要的挑战。文章提出了一种基于YOLOv8和Deep-SORT的方法来跟踪货物位置。该系统可以有效地识别、定位、跟踪和计数镜头前的货物。称之为“warehouse management”,该算法基于示例跟踪范式,并将跟踪应用于检测对象的边界框。在此基础上,自动识别感兴趣区域(ROI),有效消除不需要物体。我们的F1的分数是0.816 7。
关键词:Deep-SORT;YOLOv8;warehouse management;目标检测;图像识别
中图分类号:F253;U169.7 文献标志码:A DOI:10.13714/j.cnki.1002-3100.2024.10.007
Abstract: Utilizing advanced artificial intelligence and computer vision technology, logistics management has made significant progress. How to establish a set of detection technology that can effectively solve the practical problems such as object occlusion, motion ambiguity and target similarity is an important challenge. This paper presents a method based on YOLOv8 and Deep-SORT to track cargo location. The system can effectively identify, locate, track and count goods in front of the lens. It is called“warehouse management” and the algorithm is based on the example trace paradigm and applies the trace to the bounding box of the detected object. Based on this, the Region of Interest (ROI) is automatically identified, effectively eliminating unwanted objects. Our F1 score is 0.816 7.
Key words: Deep-SORT; YOLOv8; warehouse management; target detection; image recognition
0 引 言
近几年来,由于人们的消费能力提高,商品的需求量与日俱增,因此,如何对商品进行有效的库存管理已成为一个亟待解决的问题。大部分的仓库管理者都是以手工方式清点存货。但这种方法成本较高,由于要经常监视进货和出货,因此需要大量的劳动力,迫切需要能降低劳力、大大节约成本的仓储管理系。为了解决仓库管理问题,现有的各种管理解决方案都使用物联网设备为工作人员提供实时库存细节。虽然采用了感应器和硬件,保证了精确性,但却要求持续的维修,这使得其并不适合于市场,仍需要进行低成本的存货检查。
在零售行业中,将人工智能与计算机视觉相结合(尤其是在库存自动化方面),已成为一个新兴的研究热点。自助服务的潮流已经影响到我们生活的方方面面。但实际情况下,如目标遮挡、目标运动、目标相似度高、新季节性商品的引入等,对目标识别造成了很大的阻碍。我们获得了一个训练数据集,包含真实图像和合成图像总计116 500个项目扫描以及相关的分割掩码。该测试资料包含了大量的录像剪辑,每一剪辑都包含了一至几个用户用一种很自然的方式所做的扫描操作。由于涉及到多个管理员,且每一个管理员的扫描方式都稍有差异,试验变得更加复杂。在测试方案中,会有一个用于存放被扫描项目的托盘,同时摄像头会被放在结算台的正上方。本项目提出一种全新的warehouse management管理方法,该方法融合了检测、追踪和筛选等多个功能,能够精确地计算出不同物体的个数。近年来,利用相机进行库存行为检测的研究取得了很大进展。目前,很多的研究都是利用高斯混合模型对汽车进行分割,以获取汽车的相关信息。Akhawaji等[1]使用卡尔曼滤波器,进一步消除了假阳性,从而改善了跟踪的效率。但是,当作业区光照条件改变时,该方法的效果就会降低。在图像处理之外,我们也会使用深度学习的方法来探测目标。
在此基础上,给出了一个基于YOLOv8的实时库存管理方法。一种最新的物件检测算法,YOLOv8已经被用来检测存货中的物件数目。然后,对每一类目标进行识别、深度排序。并对该方法进行优化,使其在各种光照、气象条件及短时遮挡等情况下更具优越性。由于这种方法无需对目标区域有先验知识,所以其适用范围广泛。
1 相关工作
人们对深度学习研究得越深入,对其认识就越来越多。例如分类、物体探测、物体追踪、以及健康护理。由于其取消了传统的收银台,并显著地减少了收银员的工作时间,因而引起了自助收银员的浓厚兴趣。这种方法最大程度上节约了人力资源,因为它采用了机器视觉和感应器融合技术,以识别被选择的商品,并在结束时,通过手机应用软件将其结算给收银员。松下公司已经开发出一套基于无线电波识别(RFID)标签的自助检验系统,该技术已经被广泛地应用于安防领域。这一系统具有很高的性价比,这使得它非常适合在仓储中使用。目前,国内外学者已对视觉物体的识别与分类进行了大量的研究,尤其是在仓库中,以货架上的商品探测为主要研究内容。即便如此,也有多视角立体视觉(MVS)利用圆锥直方图(CHoG)作为特征描述子,从检索图像中抽取出隐藏的特征,然后发送给数据服务器以供识别。除阅读标签外,还可将检测自动功能延伸至对物品进行视觉特性及总体外观的分析。Aquilina等[2]开创了一种利用 SCARA机器人简化仓库结算流程的方法, SCARA机器人带有机器视觉的四轴机器人系统。当管理员把东西放到传送带上时,这个系统会确认东西,把它们包装好,并且会自动产生一个总账。相比之下, Redmon等[3]提出使用传统多类检测器,依赖于卷积神经网络从单个RGB图像中检测并识别项目。
1.1 对象检测
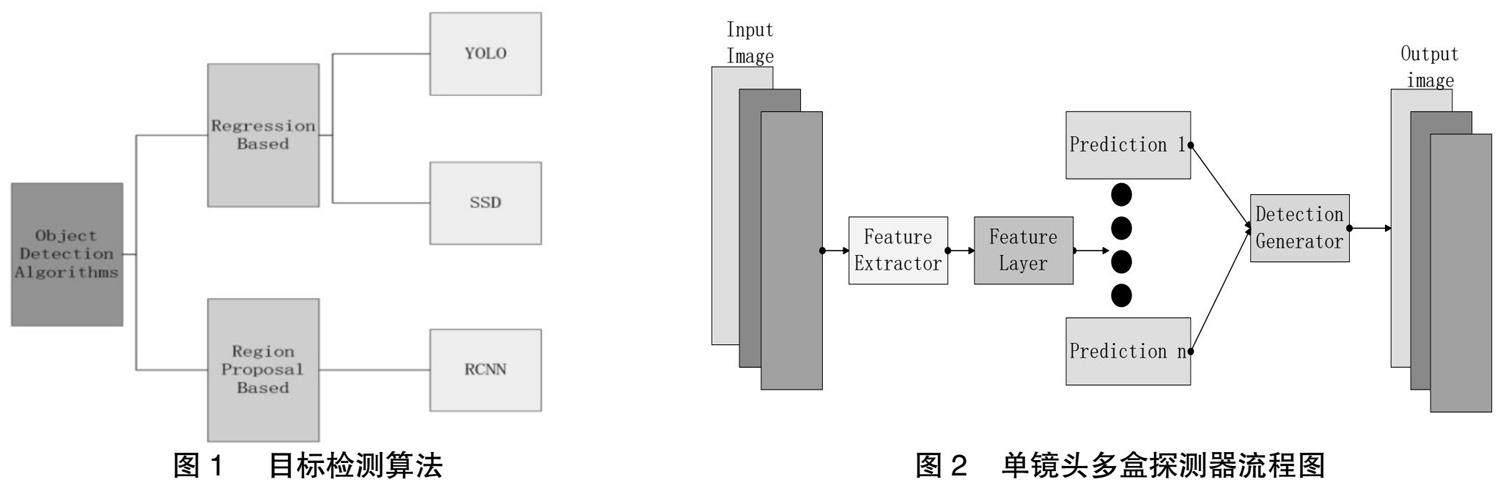
在此基础上,提出了一种基于机器学习方法的物体检测方法。在 Liu等[4]的目标检测模型中,主要包含了3个阶段:感兴趣区域的选择、特征的提取和目标的分类。一种常用的感兴趣区域提取方法是利用一个滑动窗口来对一张图片进行不同比例的变换。如图1所示。
深度学习算法主要可以分为两类,其中将检测任务视为回归问题的是 You Only Look Once (YOLO)和 Single Shot Multi-Box Detector (SSD)。另一方面,以区域为基础的 CNN (Region-based CNN,R-CNN)等算法对目标区域先进行定位再进行分类。该方法是一种新的图像分类方法。根据提取出的特征,采用 SVM方法对待识别区域中有无目标进行分类。RCNN的训练耗时较长,而且在探测速度上有一定的局限性。
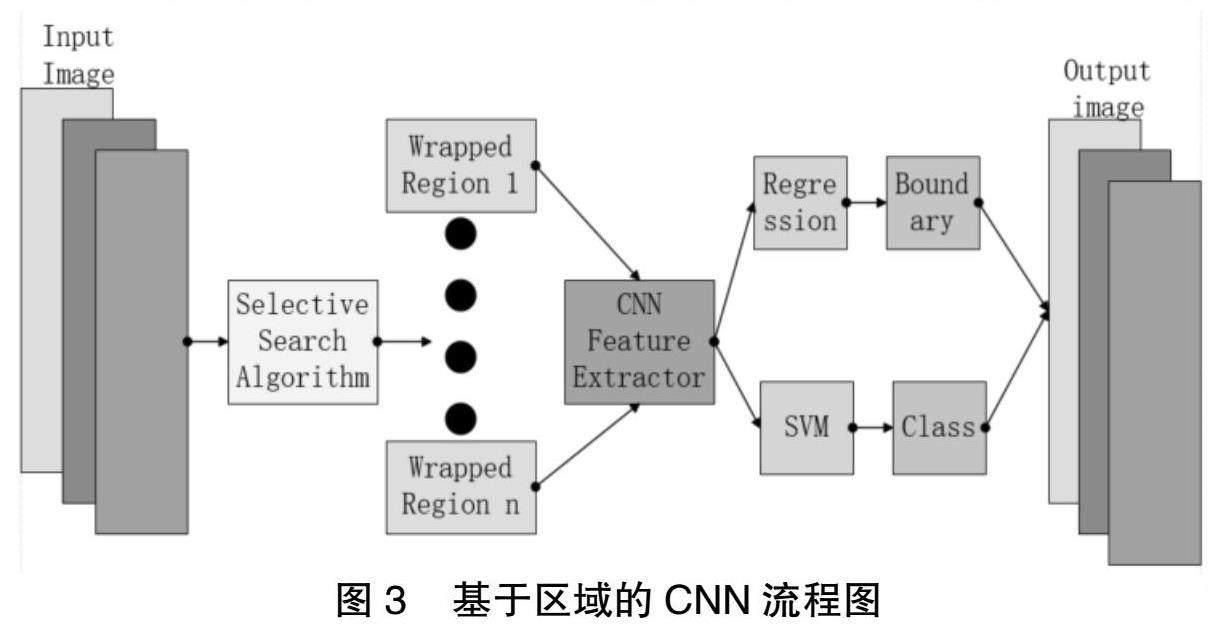
本文基于 SSD、YOLO等一阶检测器来实现对物体的探测。图2展示了SSD模型的体系结构。在SSD算法中,采用了基于CNN的特征抽取方法。在此基础上,利用卷积图对图像进行多尺度分类。因为SSD算法没有采用基于面积的推荐算法,所以 SSD算法比R-CNN算法更快。如图3所示。
对于移动对象的检测,通常采用基于 SIFT或者 HOG的特征提取技术。但是,受目标表观、尺度、噪声、光照等因素影响,现有方法存在较大误差。卷积神经网络(Correlation Network,CNN)具有较好的学习效果。近年来,随着物体探测技术的发展,人们提出了一类、二级探测器和无锚点探测技术。这两种模型都是以数据为基础的,使得机器可以自主地学会图像中的特征表示,因此不需要抽取图像中的特征。两阶段检测架构将检测过程分为区域提议阶段和分类阶段,目前比较流行的模型包括R-CNN、FastR-CNN和Faster R-CNN等。而单级检测器则采用单一的前向全卷积网路,可直接提供目标的边界盒及目标类别。在这类产品中,最常用的模型是SSD和YOLO。
最近几年,无锚检测模型在目标检测领域的应用越来越突出。另外,Redmon等[5]提出的Task-aligned一阶段对象检测(Task-aligned One-Stage Object Detection,TOOD)方法也是一个很好的例子。该方法在对齐测度中引入了目标的定位与分类,从而实现了任务间的互动与目标间的协调。他们还建议采用任务对齐的方式,使锚定位最优,从而使其表现优于之前的一阶侦察机。另外,YOLOX是 YOLO系列检测器模型的非锚定演化。他们使用了诸如去耦合头等高级探测技术,并使用了领先的标签分发战略模拟OTA。YOLOX比其他同类产品具有更高的性能。基于NVIDIAV100 GPU,YOLOv7的推理速度可达30fps以上,比现有的任何一种实时目标检测器都要快。另外,最新的YOLOv8看起来也比之前 YOLO的任何一个版本都要好。由于包含了海量目标类型,可以很好地进行特征学习,在训练过程中往往会采用MS-COCO检测问题,ImageNet问题,以及 PASCAL VOC问题。通过训练,该模型可以很好地适应某一特定的任务。但是,目前大部分的物体检测算法都存在精度与性能的矛盾,如何兼顾这两个问题是一个亟待解决的问题。
1.2 对象跟踪
目标跟踪是指在不同的帧间,根据不同的时间和空间特征,对不同的目标进行检测。在最简单的情况下,获取第一个检测集,给出它们的ID,然后在框架内对它们进行追踪,这就是物体追踪的精髓。单个目标和多个目标可以进一步划分为两种类型。多目标追踪算法的主要任务是对图像中的多个目标进行辨识,并对其进行指派和维护,以及对输入图像中的目标进行追踪。
物体追踪是指在一系列的影像中对物体进行定位与追踪。这一工作在很多实际应用中都很重要。目标跟踪过程中存在目标表观、目标遮挡、摄像机运动、光照、尺度等问题。针对上述问题,国内外学者提出了多种基于特征的、深度学习的、基于概率的目标跟踪方法。随着机器学习、计算机视觉等技术的发展,目标跟踪技术得到了长足的发展。
Bewley等[6]提出了一种简单的在线实时跟踪(Simple Online Real-Time Tracker,SORT)的多目标跟踪的实用方法,并将其重点放在了高效实时的对象关联上。此项研究突出了侦测品质对追踪效能的影响,而采用不同的侦测方式可将追踪效能提升18.9%。另外,由于该算法的简单性,它可以达到260赫兹的高更新速率,是其他高级追踪器的20倍。Deep-SORT是一种SORT追踪方法,该方法根据影像的特性,将深度关联量值融入其中。
Zhang等[7]提出了一种高级的目标跟踪算法,该算法利用类似于Deep-SORT的深度神经网络以获得最新的跟踪精度。针对实际目标跟踪中存在的诸如遮挡、尺度偏差、运动模糊等问题,提出了一种新的目标跟踪算法。ByteTrack已经在许多标准测试中取得了很好的成绩,并且在精确度和速度上超过了其他受欢迎的物体追踪工具。ByteTrack将充分发挥深度学习的优势,极大地促进目标跟踪技术的发展。
1.3 视频修复
视频补绘是利用可靠信息对视频序列中的缺损进行修复的一种方法。该技术在影视等领域具有广泛的应用前景。由于视频绘制涉及到时空两个方面的信息,因此,图像绘制是一个极具挑战的研究课题。针对该问题,人们提出了多种基于卷积神经网络的时空上下文学习方法。虽然近年来视频渲染技术已经有了一定的发展,但其研究还处于起步阶段,还面临着诸多问题,如场景的复杂性、时序的连续性、以及图像中存在的大量空白区域等。Zhang等[7]提出了一种流修复网络,它是通过利用本地时间窗口内的相关流特征,来完成一个被破坏的流。在此基础上,针对时空变换的特点,提出了一种窗口划分策略。另外,为了准确地控制电流对每个空间transformer的影响,在此基础上,提出了一种新的业务权重计算模型,并将其与双视图空间多头自动注意(MHSA)技术相结合,实现了全局性和视窗型注意力的融合。
2 实 验
图4是对我们架构的说明。该方案是一种多步的方案,下面将对其进行更多的讨论。该方法以测试集合A的数据作为输入。在第一个步骤中,帧会经过剪切和覆盖帧的预处理。第二个步骤是把经过处理的图像送到一个探测网络,由探测网络产生一个定位框。在此基础上,将含有运动轨迹位置的图像输入深度集,并将其与运动轨迹进行分类,从而得到运动轨迹的类别得分。最后一个步骤是利用一个合并的算法来调整目标轨道,并且为每一个轨道选择一个轨道的输出框架。
2.1 生成数据和训练模型
本研究的物件检测模式,利用三维扫描物件模式与其对应之分割蒙板所产生之复合影像来发展。考虑到对外源数据的利用,本文采用了一种与实验视频中目标颜色相似的背景,并且在背景中添加了一种高斯噪声。为了充实训练资料组(如图5所示),本文还探讨了如何将背景图像中的目标进行放大,增强其分辨能力的方法。鉴于原始图片的低品质。本项目前期研究发现,采用基于产生式对抗网络(SRGAN)的超分辨方法,可实现对单个图片的超分辨,并取得较好的训练图片质量。我们一共产生了13万个训练图片和20 000个验证图片。我们在YOLOv8中调整了预先训练好的权重(如图6所示)。
2.2 异常对象去除
我们所使用的数据集合,是一组嵌入在正常图片中的单一商品的综合图片。在训练过程中,所有的作品都被单独放在一个框架内,并且放在一个不允许其他物品接近的“自由空间”里。但是,在进行逻辑推理时,即使现场没有任何商品,该模型也可能对员工的双手或躯体进行错误的检测。针对这一问题,本项目拟采用计算机视觉技术,从一幅图像中提取出人体部分,尤其是手部,并对其进行遮挡。其中,主要是利用关键点侦测和事例分割两种方式,来估算出每个手部的语义关键点的位置,或是把手部当作物件来辨识。随后,我们应用Flow-Guided Video Inpainting (FGVI),利用flow completion,feature propagation,content hallucination 这3个可训练模块共同优化Inpainting过程。
2.3 感兴趣区域检测
本研究以手部对象的识别为研究对象,拟通过对手部对象的动态识别,来实现对手部对象的检测与跟踪,从而提高整个加工管线的检测精度和总体工作效率。首先利用高斯混合模型对每一段视频进行背景提取,然后对其进行检测。在此基础上,采用背景相减的方法,将前一帧图像进行合成,并将各帧的前景图像进行分割。由于相机在场景中不会发生运动,因此我们仅在关键帧中获取感兴趣区域的坐标。但是,为防止出现异常感兴趣区域,对每一帧,我们都会计算出当前一帧、前后两帧的感兴趣区域,并从中选取一个带中间值边框的感兴趣区域。同时,本文还提出了一种基于填充的差分图像处理方法,以确定具有类似于种子值的像素。在这个范例中,将种子放置在影像的中央,但是你可以随意设定它。通过这种方式,所有附着在边界上的象素都会被识别出来,并且这些像素被称为“托盘”。但是,这个方法得到的整体效果较差。
当每一个物体经过 ROI的磁道被决定后,我们决定一个框架ID,这个框架是磁道中最中央的物体边框。在此基础上,我们先求出每一个被探测到的边界盒的中心点,再求出它们到相应的边界盒中心的欧氏距离,从而得到该边界盒。最后,给出了在各感兴趣区域中心最短帧内的目标探测结果。
2.4 应用分析
与R-CNN、 DPM等方法相比, YOLO方法表现出了很好的效果,但是对于小型目标的准确定位还不够理想。因为,在这个问题范围内,并没有包含很小的图片,所以,YOLO可以很容易地被用于这项研究。YOLO把输入的图片分成一个方格,例如 M*M。YOLO将可信度用Pr(物体)*IOU来表示,这里的Pr(物体)代表物体出现的可能性;IOU是指推理结果与地表真实结果有交叠的区域。各网格单位产生5种预测(x,y,w,h和置信得分)。另外,每个格子生成用 Pr(类别|对象)表示的条件类别概率。如公式(1)所示,说明了在测试阶段怎样才能得到特定的类的置信度得分。
(1)
最后一层是用来预测与其关联的类别机率和边界框的坐标。然后,将包围盒标准化到0至1。所有其他的层都采用了ReLu激活函数,以提高非线性度,如公式(2)所示。
(2)
在该框架下,Yolov8采用了基于CSP(C2f)的C2f模块,而Yolov5采用了C3模块。CSP结构可以提高CNN的学习性能,降低模型的运算量。C2f模块包括两个Conv模块以及多个瓶颈,它们之间用分叉和 Concat相连接。其他的主要和YOLOv5一样。在主干网络的最底层,采用了SPPF组件。然后,我们用YOLOv8检测器来检测物体,见图5。这个最新技术的侦测器可以增加投资回报,它可以将影像的尺寸调整到640×640。为保证最大程度的精确性和最快的推理速度,本文采用了深度追踪算法。通过对产生目标的样本集的训练,我们得到了116种不同类型的样本,其中在训练过程中,样本集的准确率达到了98.3%。此外,本算法在对目标进行定位的同时,还使用了探测置信度与类别置信度。我们的个别产品追踪解决方案包括两个在线追踪算法:SORT与Deep-Sort。这两种方法都具有很好的目标追踪效果,而且都是基于边界矩形来追踪所关注的物体。这两种方法都是利用卡尔曼滤波器对每一个目标的将来位置进行预测。最后,将预测结果与对应的轨迹相结合,保证了目标在视频中的精确追踪。综合上述两个方面的研究成果,使得该方法在实际应用中具有较高的精度和较高的计算效率。SORT和Deep-Sort尤其适用于目标非常接近或者有遮挡的情形,这两种算法都是为解决高速追踪问题而设计的。同时,本文提出的方法可以有效地应对物体的尺寸、方位、外观等因素的改变,使得图像在光照、背景等因素的影响下,具有较强的鲁棒性。
在此基础上,本项目的研究成果可应用于多种场景下,对单一商品进行高精度的追踪。总之,本项目提出的算法具有较高的计算精度和较高的计算效率,对实际应用具有重要意义。因此,该方法是一种切实可行的方法,适用于各种场合。我们所选的追踪者为算法提供一系列track-let,每一个track-let都有一个不同的ID。在每一个track-let中,我们都保留了被测物体的边界框坐标,它的类别指派,以及它的可信度。然后,我们给每一个track-let指定了一个类别标签,这个类别是在 track-let的所有类别中平均置信程度最高的。接着,我们对某些轨迹进行了分析,认为有些轨迹是单一轨迹的延续,并且对其进行了合并。对任何两个track-let,我们都会按照一定的顺序进行比较,如果在一个track-let中,最后一个frame中,x和 y的坐标都在 K个像素之内,那么就会将这两个frame进行合并。采用一种基于深度分类的算法,对每一个物体在整个框架内都进行跟踪。Deep-SORT利用表观描述符,将标识的转变减到最少,为了改进追踪效果,在处理有时序信息和时序信息的情况下,一般采用卡尔曼滤波方法。具体见表1。
2.5 实验装置
这一部分将介绍用于win11系统的试验平台。所有的试验都是在英特尔3.6 GHz处理器,8 GB内存,以及 NVIDIA Quadro P4000图形卡上完成的。 如图7所示。
本系统的硬件架构,使本系统具有较强的运算力,可于较短时间内完成相关实验。尽管我们的算法同时利用了 CPU和 GPU两种资源,但是在试验过程中,我们仅用了一个GPU。在 CPU上使用多线程进行处理,保证了对现有计算资源的高效利用。但是,该算法以 GPU为核心,实现了大规模运算。我们的试验是可扩充的,也就是说,这些试验可以适用于各种不同的硬件配置。与其他YOLO算法相比,YOLOv8的计算结果准确率为53.9。所以,YOLOv8被选为车辆探测的对象。由于这些类别是在 MSCOCO的资料集中被训练过的,因此使用了预训练模型。该视频输入具有1 080p (1 920×1 080)的分辨率和15 fps的帧速率。由于该数据集合中的每一个分类都包含在内,因此将其视为均衡的。对于YOLOv8来说, image尺寸参数被设定为640。这个模式把最长的尺寸调节到了640,也就是在保留了纵横比的情况下,把1 920的尺寸变成了640。这样,208个可变尺寸的图片接近640×360。平置信度阈值设置为0.5。这个类别出现在一个有边框的盒子里的可能性是通过一个可信度得分来评价的。
在推理方面,我们主要关注于感兴趣区域中的目标的检测与追踪。为了达到这个目的,我们只从感兴趣区域中抽取像素,并将其设置为640×640。在每一秒都会开始对感兴趣区域进行检测。因为视频是60帧/秒,所以我们把 n设为10,这样就可以省去65%的 ROI运算。实验结果表明, SRGAN网络对训练样本中任意组合的目标图像的增强效果最好。我们前期对已有的80个数据集进行了精细调整,取得了96.8%的准确率。最后,我们采用中介体YOLOv8对75次样本进行精细调整后,得到的 MAP值为98.3%。在目标跟踪方面,本文采用了 SORT和 Deep-Sort这两种方法。在这两个例子中,我们把能够突破的追踪次数提高到30个,从而使追踪的鲁棒性和可靠性得到进一步提高。我们试过各种画面长度,发现30个画面是最佳的。最后,我们设置K,即我们的合并算法中前一个轨道的最后一帧中心与下一个轨道的第一帧中心之间的最大像素数为100。
2.6 实验结果
我们考察了该框架在不同阶段的效率,以达到预期的成果。结果显示,YOLOv8检测器模式与深度追踪算法的配合最佳,其F1值可达0.816 7。因此,必须谨慎地选择探测器模型和追踪方法,以达到最佳的效能。在此基础上,对多种 ROI检测技术进行了研究。研究结果表明,相对于单一的感兴趣区域,利用每一帧感兴趣区域可以有效地改善图像的流水处理性能。因此,在现有的视频监视任务中,使用感兴趣区域探测方法是非常重要的。
为此,本项目以 YOLOX、YOLOv8等多种 YOLO模型为研究对象,通过对各种 YOLO模型的测试,进一步提高目标探测的性能。结果表明,YOLOv8具有较好的识别效果。我们通过对比不同尺寸图片对搜索效果的影响,发现不同尺寸图片的搜索效果基本一致,提示图片尺寸并不是影响搜索效果的重要因素。
在YOLO模型的基础上,本文对 SORT算法和Deep-Sort算法进行了性能评估。这两个跟踪器的表现都非常优秀,但是我们发现,F1得分为0.816 7,它有着更好的稳定性。由于我们所用的图片仅为640×640,因此,在追踪时,我们可以采用更高的分辨率。
3 结 语
本文提出了一种全面的架构,可以在所关注的区域内对商品进行精确检测与统计。本文采用视频图像处理方法以提高检测效果,并将假阳性率降至最低。该算法可以实现对目标区域的自动检测和分割,并将目标区域从背景中删除。本文利用YOLOv8即时检测网络,以及只有一个有边框的追踪器来取得这个成果。在此方法中,F1得分0.816 7。在此基础上,本课题还将对其在更为复杂的场景下的适用性和基于深度学习的物体检测方法进行深入的研究,进一步改进系统的准确性。
参考文献:
[1] AKHAWAJI R,SEDKY M,SOLIMAN,A H.Illegal parking detection using gaussian mixture 287 model and kalman filter[C]// In Proceedings of the 2017 IEEE/ACS 14th International Conference 288 on Computer Systems and Applications (AICCSA), Hammamet,Tunisia,October 30–November 3,2017,IEEE,2017,46(1):840-847.
[2] AQUILINA Y,SALIBA M A.An automated supermarket checkout system utilizing a scara robot: Preliminary prototype development[J]. Procedia Manufacturing,2019,38:1558-1565.
[3] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: Unified,real-time 322 object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR),Las Vegas,Nevada,June 27-30, 2016, IEEE, 2016,50(1):55-60.
[4] LIU Wei ANGUELOV D,ERHAN D,et al.SSD: Single shot 324 multi-box detector[J].Computer Vision-ECCV,2016,45(2) :21-37.
[5] REDMON J,FARHADI A.Yolo9000: Better,faster,stronger[C]//In 2017 IEEE Conference on Computer Vision and Pattern Recognition(CVPR),Honolulu,Hawaii,July21-26, 2017, IEEE, 2017,55(1),6517-6525.
[6] BEWLEY A,GE Zongyuan,OTT L,et al.Simple online and real-time tracking[C]// IEEE International Conference on Image Processing (ICIP),Phoenix,Arizona,September 25-28, 2016, IEEE, 2016,46(2):1249-1254.
[7] ZHANG Kaidong,FU Jingjing,LIU Dong.Flow-guided transformer for video inpainting [J].Springer International Publishing,2022,24(3):840-847.
