基于改进YOLOv3无人机图像目标检测
2024-06-17王涛,吴观茂





摘要:无人机航拍图像中的物体通常很小,边界模糊,加上复杂的背景和不断变化的照明条件,所以YOLOv3算法的检测精度相对较低.因此,构造四级BiFPN,既可以对融合的输出特征作出平等的贡献,又可以使得Neck部分变为FPN+PAnet结构,同时充分利用底层与高层特征融合信息,以提高特征提取和目标检测性能.添加更小的检测层,可以使得模型拥有四个先验框,有更高的概率出现对于目标物体有良好匹配度的先验框,使得模型更容易学习.实验结果表明,提出的无人机图像目标检测模型(YOLOv3_Drone)在VisDrone-2019的mAP比YOLOv3算法提高了3.83%,证明了该方法的有效性.
关键词:无人机;目标检测;YOLOv3;BiFPN
中图分类号:TP391文献标志码:A
Target Detection Based on Improved YOLOv3 UAV Image
WANG Tao, WU Guanmao
(School of Computer Science and Engineering, Anhui University of"Science and Technology, Huainan 232001, China)
Abstract: Objects in UAV aerial images are usually very small, with blurry boundaries, complex backgrounds and changing lighting conditions, so the detection accuracy of YOLOv3 algorithm is relatively low. Therefore, constructing a four level BiFPN can not only make equal contributions to the fused output features, but also make the Neck part become an FPN+PAnet structure; and meanwhile, it makes full use of the fusion information of low-level and high-level features to improve the performance of feature extraction and target detection. By adding a smaller detection layer, the model can achieve four priori boxes, and further, there is a higher probability that a priori box with good matching degree for the target object will appear, which will make the model more easier to learn. The experimental results show that the proposed UAV image target detection model (YOLOv3_Drone) in VisDrone-2019’s mAP is 3.83% higher than that of YOLOv3 algorithm, which proves the effectiveness of this method.
Key words: UAV; target detection; YOLOv3; BiFPN
近年来,使用无人机(UAV)进行低空摄影已经成为一项成熟的技术,并在不同领域取得示范性效果.基于低空无人机的航空摄影具有平台小、成本低、成像分辨率高、操作方便、机动灵活、应用范围广等优点,它是对卫星遥感的有力补充.无人机是低空航空摄影的理想平台,可以用高清晰度传感器捕捉地面目标,其图像分辨率远高于基于飞机的高空航空摄影.在低空飞行高度,航空图像不受云的影响,使用高清晰度相机获得的图像分辨率可以达到厘米级[1].
无人机已广泛应用于民用和军用领域,如侦察和监视、搜索和救援、运动分析等,每天都会获取大量数据.但无人机图像中的物体通常很小,并且由于边界模糊和复杂的背景,导致难以准确识别目标.
目标检测的任务是指在图像中找到感兴趣的目标,并精准地确定目标类别和位置信息[2] .无人机图像的大数据量和目标的小尺寸给无人机图像中快速、准确的自动目标检测带来了新的挑战[3].因此,仅仅依靠人力资源去检索、获取和处理无人机图像是不切实际的.
无人机实时采集的海量数据可以使用大数据技术和深度学习进行处理,将传统的目标检测方法从低效的手动模式转变为智能实时高效模式[4].因此,将深度学习应用于无人机航空视频中的目标检测具有重要的研究价值和意义.
目前,YOLOv3是一阶段算法中常用的基于深度学习的目标检测方法之一,相比于二阶段算法,其速度快,能够以端对端的方式直接进行目标分类和边框回归.然而,YOLOv3实验通常在MS COCO数据集上进行,并不完全适用于无人机图像.
针对无人机图像的特点,本文提出了一种以YOLOv3为基础的新改进算法,并命名为YOLOv3_Drone.四级BiFPN和新检测层用于改进YOLOv3目标检测方法,使其适用于无人机航空图片.这解决了无人机环境中的目标遮挡和小目标检测问题,提高了小目标检测的精度.
1相关工作
无人机图像中的目标检测旨在从图像或视频帧中的已知类别中找到目标实例[5].该任务通常
会给出对象的位置和尺度,以边框的形式,并附带其类别的概率.根据边界框及其类上的概率生成对象的位置和比例.无人机图像检测被应用在许多领域,包括巡查交通秩序、采集农业信息、检测电力线和巡查森林以及军事侦察.现在对无人机的研究非常流行,如于润等人使用深度学习算法和基于无人机的多光谱影像来及早发现松枯病[6].
基于深度学习的目标检测的算法可以分两类.一类是以R-CNN[7]、SPPNet[8]、Fast R-CNN[9]、Faster R-CNN[10]等为主的两阶段算法,主要原理是:先在原始图片上选择感兴趣的区域,即候选区域,然后在候选区域进行目标分类和边界框回归.虽然二阶段算法检测精度比较高,但由于计算成本大,导致速度比较慢.另一类是以SSD[11]、YOLO[12]、YOLOv2[13]、YOLOv3[14]为主的一阶段算法,不同于两阶段算法,其采用端对端的方式直接进行分类和回归,检测速度可以达到实时检测,但检测精度比较低.
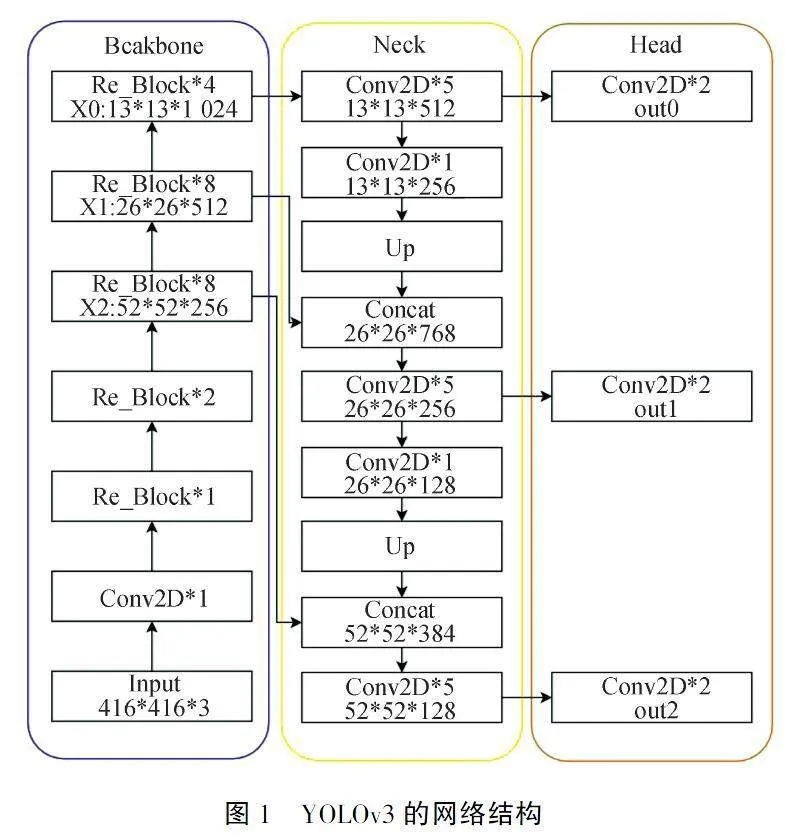
由于YOLOv3网络结构简单、在小目标数据集上检测精度较低,因此在一阶段算法中具有较大改进空间,我们对其进行改进,使得模型更加适应无人机航拍图像.YOLOv3是在YOLOv1和YOLOv2基础上做了进一步改进,其网络结构如图1所示.Joseph Redmon等[14]将特征提取主干网(Backbone)上Darknet19替换为Darknet53,后者与前者相比,具有三个重要特点:一是使用了残差网络Residual,二是使用特有的DarknetConv2D结构,三是删除了原始网络中的完全连接和池操作.YOLOv3参考Lin Tsung-Yi 等人所研究的特征金字塔(FPN),在颈部(Neck)上引入多尺度特征融合层进行传达强语义特征.在头部(Head),利用网络结构中不同部位、不同尺寸的特征图对小、中、大三种目标进行分类与回归.
如图1所示:图中的每个Conv2D卷积运算由nn.Conv2d(普通卷积)+nn.BatchNorm2d(批量归一化)+nn.LeakyReLU(relu激活函数)组成,可以有效解决卷积过程中梯度消失、过拟合等问题.
假定输入的图片大小为416×416,YOLOv3首先利用Backbone的Darknet53进行特征提取,当提取的特征图大小为13×13时,就转到Neck进行上采样操作,将其的长宽扩大2倍,然后与主干网中尺度为26×26的特征图进行融合,重复此操作,就可以得到三级FPN,最后用Head中52×52、26×26、13×13三个尺寸预测层进行小、中、大目标检测.
但由于无人机图像具有复杂背景、小目标和目标相互遮挡的特点,因此,简单粗暴的特征融合、不够小的检测层,会导致YOLOv3算法的目标检测不准确,会出现遗漏和委托错误.因此,在本研究中,我们对无人机图像的YOLOv3目标检测模型进行了改进,并提出了YOLOv3_Drone模型.
2方法
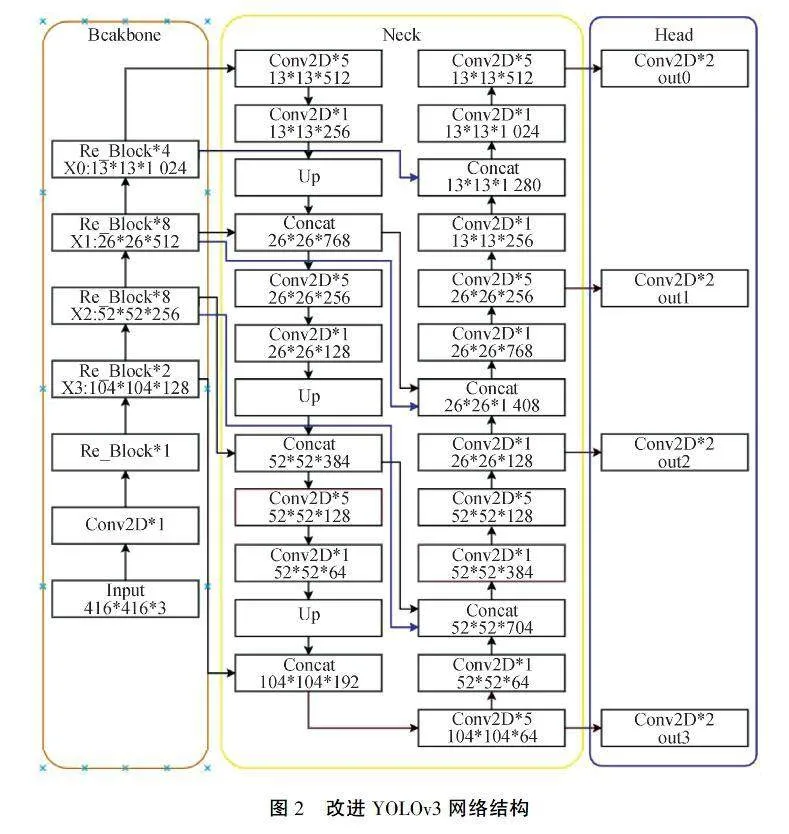
YOLOv3算法在大、中型目标对象的数据集都取得不错的检测效果,但在小型目标对象的数据集上检测精度就会下降很多,尤其在以小目标为主的无人机航拍VisDrone数据集上检测下降更为明显.这是由于无人机图像目标小、背景复杂、遮挡量大,给无人机图像目标检测带来困难,而且随着卷积神经网络越深,会丢失局部特征和细节特征.因此在我们的模型中,对YOLOv3进行两处改进,提出了无人机图像目标检测模型(YOLOv3_Drone),改进后的网络结构如图2所示.
2.1四级BiFPN
自FPN引入以来,FPN已被广泛应用于多尺度特征融合.然而,由于这些不同的输入特征具有不同的分辨率,它们通常对融合的输出特征作出不平等的贡献.因此,Tan Mingxing等人提出了一个简单而高效的加权双向特征金字塔网络(BiFPN),它引入可学习的权重来学习不同输入特征的重要性,同时反复应用自顶向下FPN和自底向上PAnet的多尺度特征融合[15],其网络结构如图3所示.
具体来说,以上图(3)所示的BiFPN在level 6的两个融合特征为例,其计算过程如公式(1)所示:
ptd6=Conv(w1gPin6+w2gResize(Pin7)w1+w2+ε)pout6=Conv(w′1gPin6+w′2gPtd6+w′3gResize(Pout5)w′1+w′2+w′3+ε)(1)
其中,ptd6是自上而下路径中第6层的中间特性,pout6是自下而上路径中第6层的输出特性.
由于BiFPN被Tan Mingxing等人证明优于FPN[16]、PANet[17]、NAS-FPN[18],因此,我们将YOLOv3的Neck部分中FPN替换为BiFPN精度将会有所提升,
因为BiFPN相对于FPN在特征融合、跨尺度信息集成、计算效率和模型训练稳定性等方面都具有明显的优势.
与此同时,卷积神经网络越深,特征图的感受域越大,这意味着每个神经元包含更多的全局和高层语义特征,但会丢失局部特征和细节特征.相反,当卷积神经网络较浅时,特征图神经元中包含的特征往往更局部和详细[19].最后,为了提高无人机图像中小目标的检测精度,我们通过构造四级BiFPN来进一步利用底层与高层的融合.
2.2新的检测层
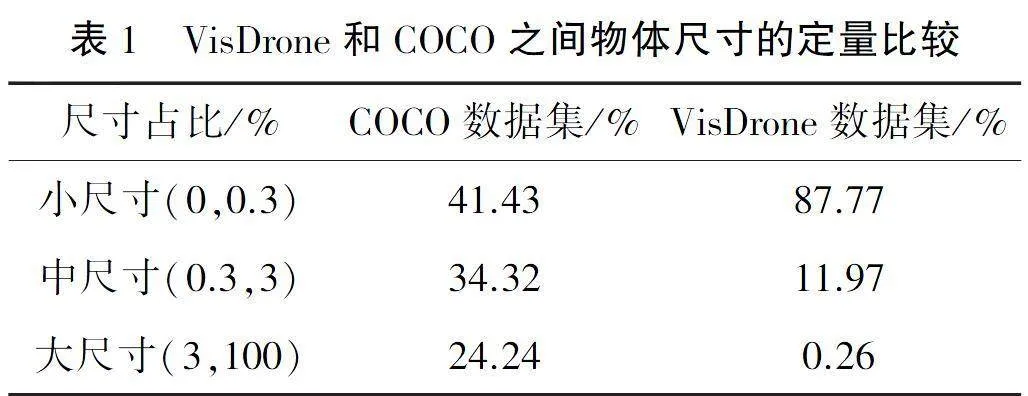
YOLOv3采用的初始锚大小是根据COCO数据集中的对象框大小进行聚类的.表1显示了VisDrone数据集和COCO数据集之间的对象大小差异,小对象在VisDrone数据集中占大多数.
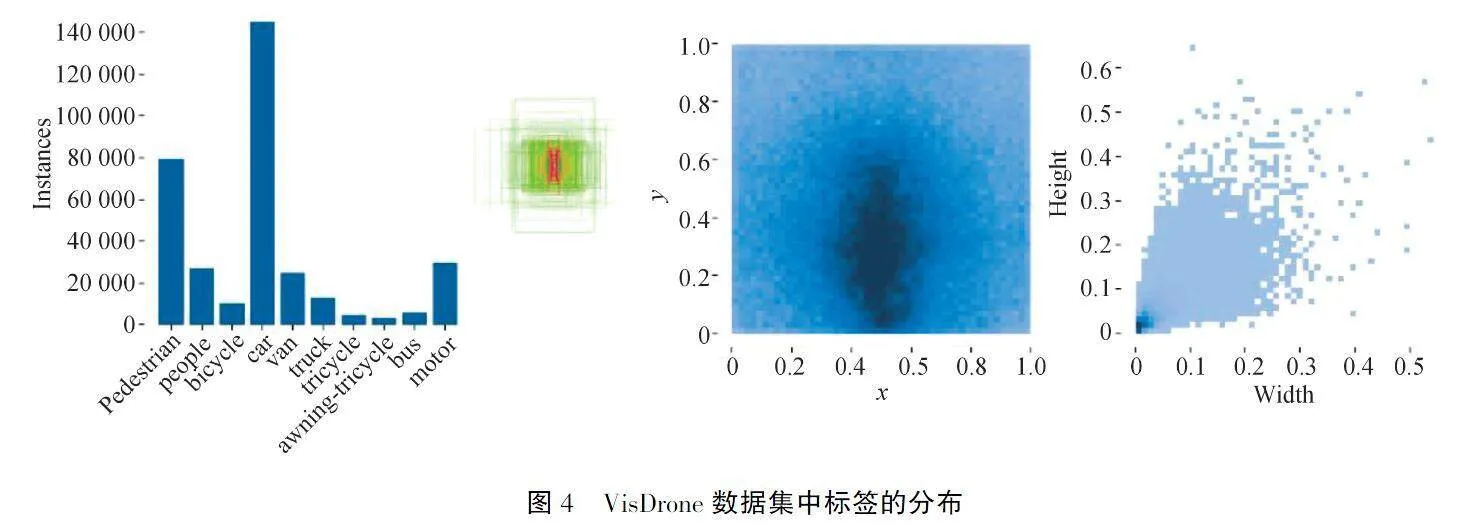
从图4可以看出,VisDrone数据集中有许多小对象.对于具有许多小对象的数据集,一种方法是通过较大的图像输入模型进行训练和测试.因此,原始三个先验锚框尺寸不太适用VisDrone数据集.
深度特征图尺寸大,感受野小,有利于小尺度目标的检测.YOLOv3算法使用52×52深度特征图来检测小目标.由于VisDrone2019以小目标为主,52×52特征图可能不是最佳的更小目标检测特征图,因此,本文采用104×104特征图代替52×52特征图来提高对更小目标的检测能力.如图2所示,最浅层信息连接主干网中的X3,X3输出特征图尺寸为104×104×192,重复此操作,X2输出特征图尺寸为52×52×704,X1输出特征图尺寸为26×26×1 408,X0输出特征图尺寸为13×13×1 280.
改进后的YOLOv3算法使用104×104、52×52、26×26、13×13特征图分别负责更小、小、中、大目标的检测.
3实验与分析
3.1目标检测数据集
传统的数据集以大对象为主,小对象很少或分布不均匀,大量小对象集中在图像的一小部分.这种不平衡的样本分布结构导致训练的模型更倾向于大型对象.为了解决这个问题,我们使用以小物体为主的专业无人机航空摄影数据集VisDrone-2019作为实验数据集.
VisDrone数据集共有8 899幅图像,包括6 471幅图像和343 205个标签,Valset中的548幅图像和38 800个标签,以及测试集中的1 610个图像.在标记对象中总共有11个类:0:行人、1:人、2:自行车、3:汽车、4:货车、5:卡车、6:三轮车、7:遮阳篷三轮车、8:公共汽车、9:摩托车和10:其他.与COCO和ImageNet相比,VisDrone中的对象框面积更小,密度更大,如图5所示.
3.2配置环境与评估指标
改进的YOLOv3模型运行环境:阿里AutoDL算力市场的GPU为RTX 3090,配置环境为1.10版PyTorch、3.8版Python、11.3版Cuda.本文采用改进的YOLOv3网络结构进行训练,模型最大学习率为0.01,最小学习率为0.0001,批量大小为8,学习次数设置为300,每10次epochs保存一次权值.
改进后的模型通过四个指标进行评估:(1)F1(查准率和查全率的调和平均值);(2)Precision(查准率);(3)Recall(查全率);(4)mAP(平均精度值).其中mAP的计算过程如公式2所示:
mAP=∑ni=1AP(i)n(2)
其中i是当前类别,AP(i)是当前类别的平均精度,n是类别总数.
3.3实验结果
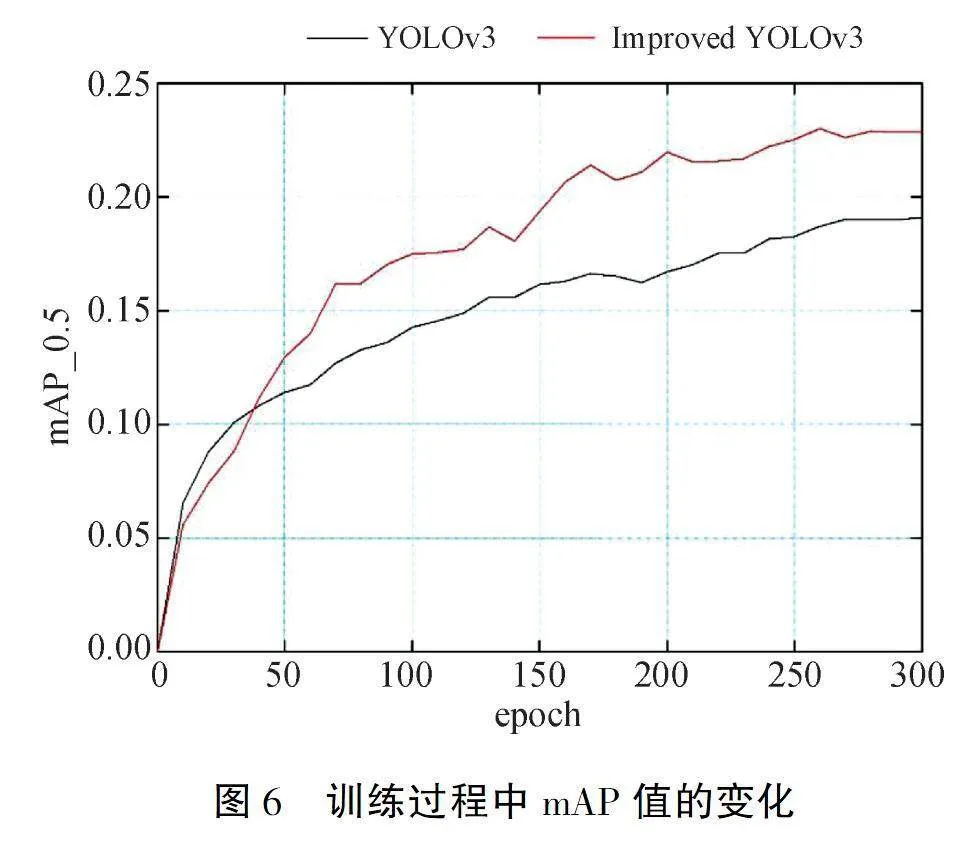
为了公平比较,我们使用YOLOv3的默认参数来训练YOLOv3模型和改进的YOLOv3模型,并分别进行300 epochs以获得最佳模型.训练的mAP值变化如图6所示.可以看出改进YOLOv3相比于初始YOLOv3有明显提升.
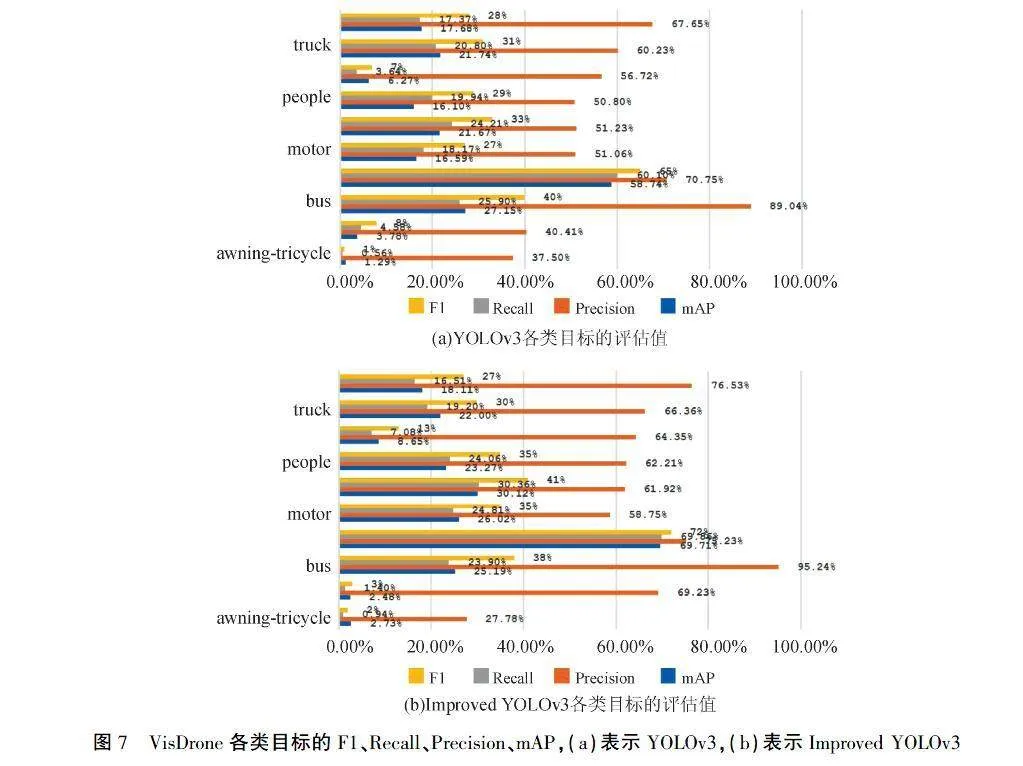
在图7中,可以观察到People类中,原始YOLOv3在F1、Recall、Precision、mAP模型评估值分别为29%、19.94%、50.80%、16.10%;而改进后YOLOv3这四个模型评估值分别为35%、24.06%、62.21%、23.27%,分别提高了6%、4.12%、11.41%、7.17%,这说明该算法在小目标检测方面有很大的改进.
从表2可以看出,改进的YOLOv3在F1、Recall、Precision、mAP四个模型检测评估指标的平均值全都超过初始YOLOv3,并分别提升了2.7%、2.285%、7.461%、3.83%,这说明构造四级BiFPN和添加更小检测层有助于提高模型在无人机航拍图像的检测精度.构造四级BiFPN过程中,一方面Neck部分采用FPN+PAnet网络结构,既可以传达强语义特征,又可以传达强定位特征,同时在多尺度融合时,对融合的输出特征作出平等的贡献;另外一方面进一步将主干网(Backbone)的底层特征图与颈部(Neck)的高层特征图进行融合,最后使得输出的特征图更加丰富.添加更小检测层(即104×104),可以使得模型拥有四个先验框,通过设置多个不同的尺度的先验框,就有更高的概率出现对于目标物体有良好匹配度的先验框,并且当52×52检测层不适用更小的目标时,可以防止漏检或检测不准,最后使得模型更容易学习.
为了验证300 epochs中最好模型的检测效果,我们选取同一张VisDrone航拍图片,检测效果如图8所示.
在图8中,可以观察到,Improved YOLOv3的检测效果明显优于YOLOv3.例如Improved YOLOv3中pedestrian类标签数量超过YOLOv3.实验结果表明,我们改进模型的检测精度有所提升,能防止小目标被漏检或误检.
4总结
无人机的飞行高度、视角和快速飞行速度导致无人机图像中的物体通常很小,边界模糊,加上复杂的背景,给低空航拍目标检测带来挑战.为了解决上述问题,本文针对无人机图像目标检测模型(YOLOv3_Drone)提出了一种改进的YOLOv3算法.将YOLOv3的Neck中的FPN替换为BiFPN,可以使得多尺度融合层能对融合的输出特征作出平等的贡献.此外Neck部分不再是单一的FPN结构,只能传达强语义特征,在构建四级BiFPN网络结构时,引用PAnet网络结构,也能传达强定位特征,两者强强联合,能提高对小目标的检测精度.同时进一步利用Backbone的底层与Neck的高层的融合,构造四级BiFPN,使得多尺度融合信息更加丰富.将YOLOv3的三个检测层改为四个检测层,在保持原有的三个先验框不变的基础上,构造104×104的检测层.当52×52的检测层不适用更小的航拍目标时,可以防止漏检或者误检,而且四个检测层更有利于有更高的概率出现对于目标物体有良好匹配度的先验框,有利于模型学习.
最终的实验数据表明,我们基于这两种指导思想设计的YOLOv3模型与原始的YOLOv3模型相比,F1、Recall、Precision、mAP四个模型检测评估指标的平均值全都超过初始YOLOv3,分别提升了2.7%、2.285%、7.461%、3.83%.然而,虽然该模型的精度有所提高,但速度略有下降,在未来的研究中,有必要提高YOLOv3_Drone模型的速度和实时性能.
[参考文献]
[1]TAN L,LV X,LIAN X,et al.YOLOv4_Drone:UAV image target detection based on an improved YOLOv4 algorithm[J].Computers amp; Electrical Engineering,2021,93:107261.
[2]黄健,张钢.深度卷积神经网络的目标检测算法综述[J].计算机工程与应用,2020,56(17):12-23.
[3]ZHANG J,LIANG X,WANG M,et al.Coarse-to-fine object detection in unmanned aerial vehicle imagery using lightweight convolutional neural network and deep motion saliency[J].Neurocomputing,2020,398:555-565.
[4]HAN R,ZHANG C.Big Data Analysis on Economical Urban Traffic in Beijing:Organize overlapping transportation though the underground diameter line of Beijing railway hub[C]//2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA).IEEE,2019:269-273.
[5]KYRKOU C,PLASTIRAS G,THEOCHARIDES T,et al.DroNet:Efficient convolutional neural network detector for real-time UAV applications[C]//2018 Design,Automation amp; Test in Europe Conference amp; Exhibition (DATE).IEEE,2018:967-972.
[6]YU R,LUO Y,ZHOU Q,et al.Early detection of pine wilt disease using deep learning algorithms and UAV-based multispectral imagery[J].Forest Ecology and Management,2021,497:119493.
[7]GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:580-587.
[8]HE K,ZHANG X,REN S,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[9]GIRSHICK R.Fast R-Cnn[C]//Proceedings of the IEEE international conference on computer vision,2015:1440-1448.
[10]REN S,HE K,GIRSHICK R,et al.Faster r-cnn:Towards real-time object detection with region proposal networks[J].Advances In Neural Information Processing Systems,2015,39(6):1137-1149.
[11]LIU W,ANGUELOV D,ERHAN D,et al.Ssd:Single shot multibox detector[C]//European Conference on Computer Vision,Cham:Springer,2016:21-37.
[12]REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:Unified,real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[13]REDMON J,FARHADI A.YOLO9000:better,faster,stronger[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:7263-7271.
[14]REDMON J,FARHADI A.Yolov3:An incremental improvement[J].ArXiv E-Prints:1804.02767,2018.
[15]TAN M,PANG R,LE Q V.Efficientdet:Scalable and efficient object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2020:10781-10790.
[16]LIN T Y,DOLLR P,GIRSHICK R,et al.Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:2117-2125.
[17]LIU S,QI L,QIN H,et al.Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2018:8759-8768.
[18]GHIASI G,LIN T Y,LE Q V.Nas-fpn:Learning scalable feature pyramid architecture for object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2019:7036-7045.
[19]LIU Y,SUN P,WERGELES N,et al.A survey and performance evaluation of deep learning methods for small object detection[J].Expert Systems with Applications,2021,172:114602.
[责任编辑马云彤]
