基于语义网的数字图书馆信息检索系统框架模型
2024-06-06杨鸿


作者简介:杨鸿(1987-),女,讲师。研究方向为图书馆学-医学文献检索与利用。
DOI:10.19981/j.CN23-1581/G3.2024.16.028
摘 要:面对互联网技术的成熟化、普及化發展,数字图书馆成为了为人们提供信息资源的重要机构。然而面对数据异构化、分散化发展的大环境,数字图书馆的传统信息检索系统与用户日益提高的信息检索需求不再适应,难以正确判断出用户的检索意图,存在检索效率低、检测结果不够准确的问题。基于此,该文结合语义网技术,对数字图书馆信息检索系统框架模型进行模块、流程、系统结构设计,并在此基础上给出领域本体集成与构建、语义相似度算法优化的方法,旨在为数字图书馆信息检索系统科学建设提供参考,从而最大化展现出数字图书馆的信息资源利用价值。
关键词:语义网;数字图书馆;信息检索系统;信息资源利用价值;系统框架模型
中图分类号:G258.2 文献标志码:A 文章编号:2095-2945(2024)16-0120-04
Abstract: In the face of the mature and popular development of Internet technology, digital library has become an important institution to provide people with information resources. However, in the face of the development environment of data isomerization and decentralization, the traditional information retrieval system of digital library can no longer adapt to the increasing information retrieval needs of users, and it is difficult to correctly judge the retrieval intention of users. there are some problems, such as low retrieval efficiency and inaccurate detection results. Based on this, combined with semantic web technology, this paper designs the module, process and system structure of the framework model of digital library information retrieval system. On this basis, it gives the methods of domain ontology integration and construction and semantic similarity algorithm optimization, in order to provide reference for the scientific construction of digital library information retrieval system, and thus maximize the utilization value of digital library information resources.
Keywords: semantic web; digital library; information retrieval system; utilization value of information resources; system framework model
传统信息检索查询模式智能化不足,信息资源共享未能实现,无法准确、快速检索出用户需求的信息资源。而语义网技术是基于机器理解人类语言的技术方法,可在Web基础上,利用标准化、共同性机器可理解元数据等先进技术,调整传统字词匹配检索模式,从语义层面理解用户检索意图,以便为用户提供更为优质的检索服务。因此,有必要探寻基于语义网的数字图书馆信息检索系统框架模型设计与构建方法,并解决集成构建领域本体、改进语义相似度算法等技术难题,从而为数字图书馆信息检索发展中语义网技术的科学应用奠定基础。
1 基于语义网的数字图书馆信息检索框架模型设计
1.1 系统框架模型设计
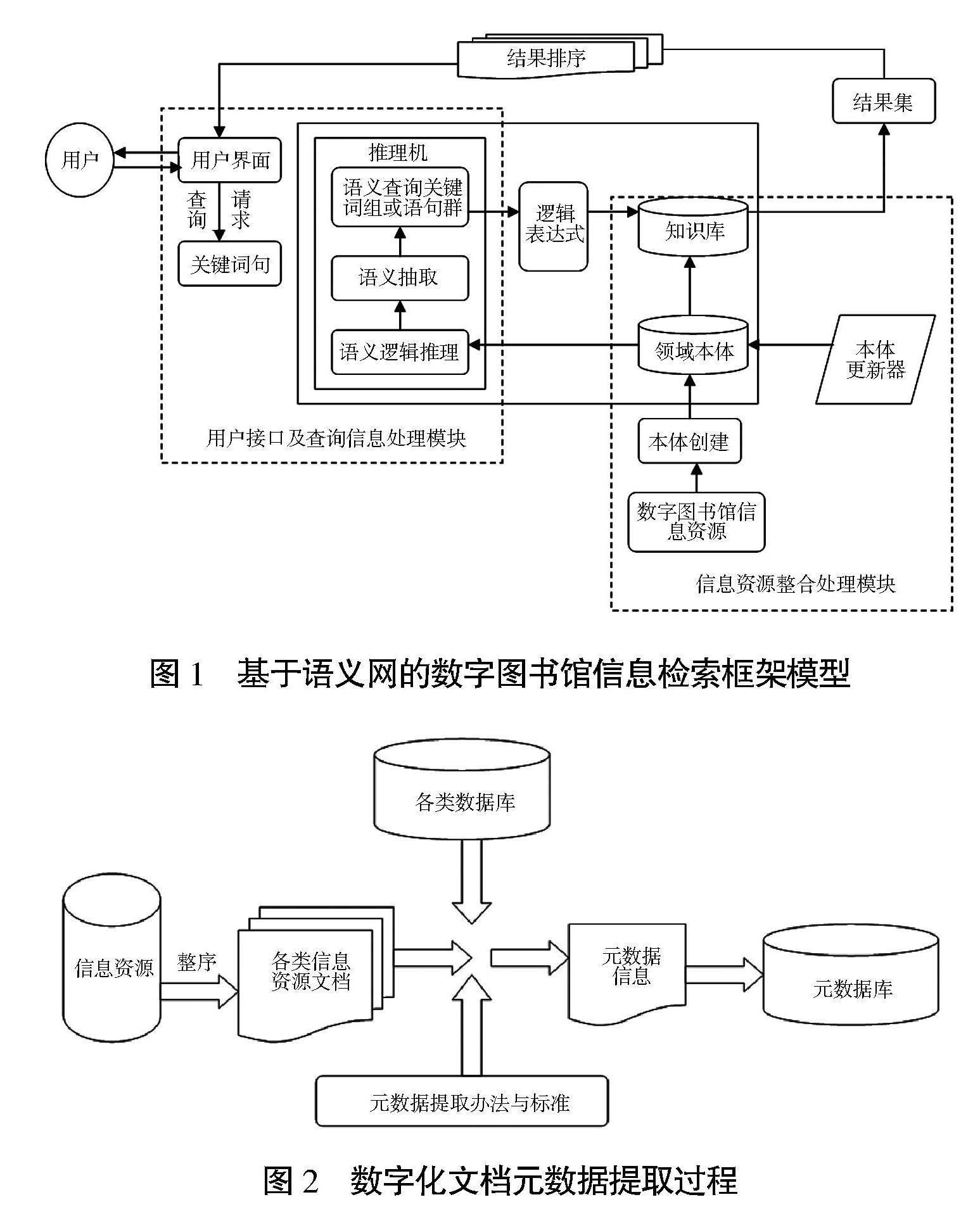
数字时代背景下,打造数字图书馆,采用智能化、现代化方式为用户提供信息资源,是图书馆稳定持续发展的必然出路,在此背景下,语义网技术应运而成。此技术可将信息检索范围延展至知识层面,并能对语义表达进行规范,通过人机交互为用户提供知识共享、思想交流服务[1]。在语义网技术支持下,构建数字图书馆的信息检索框架模型时,需要以可扩展标记语言(XML)、资源描述框架(RDF)、本体技术为基础,并应用到知识管理等多个理论,本文设计的系统框架模型如图1所示。
1.2 功能模块设计
1.2.1 信息资源整合处理模块
利用语义网技术创建信息检索框架模型时,首先要合理构建本体模型,并运用先进技术完成领域本体创建过程,在此过程中,需要利用信息资源整合处理模块处理各类信息资源。应引入专家支持,利用专家的知识经验,获取并理解各个相关领域的知识内容,并从中筛选认可度较高的词语,然后对各个词语间的逻辑关系进行分析[2]。此过程可纳入用户对领域知识的认知,使用领域本体标记文档,再将其中的特征词汇提取出来加以分析,并与概念集形成关联,从而完成语义标引过程。此模块采用元数据整合信息资源,面对规模化的数字资源,元数据标准无法有效统一,网络中还存在一些半结构化数据,为提高信息提取的准确性,此模块还引入了可扩展标记语言,在排除外界因素干扰的情况下,按照元数据处理规范,针对性获取符合用户需求的元数据,而后再将采集的数据汇总到一起,并存储于元数据库中。信息资源整合处理包含初步整序、粗粒度提取、细粒度提取、元数据获取、元数据存储5个步骤(图2)。由于XML无法描述语义,需利用RDF定义概念模型,对资源间的关系进行描述,此技术采用XML这一语法基础,利用命名空间思想完成描述过程,流程更简洁,元数据处理更为快捷。
图1 基于语义网的数字图书馆信息检索框架模型
图2 数字化文档元数据提取过程
1.2.2 用户接口及查询信息处理模块
在语义网支持下,可创建具有人机交互功能的用户接口,语义是用户对现实世界计算机表示的解释,在基于语义网的数字图书馆信息检索系统中,用户可在用户界面中输入自己的信息查询关键词,推理机收到查询信号后,会先将用户输入的关键词句转化成为适合的本体查询词句,再利用信息资源领域本体,运用领域中的知识、自然语言分析关键词句,计算语义相似度并推理语义,然后将语义相似度与用户所查询关键词句的领域本体提取出来,进而分析出用户的检索意图。此步骤完成后,若检索意图不明确,查询请求处理子模块会跳转至用户界面,让用户重新输入关键词句并向处理子模块提交查询任务;若检索意图已明确,则在返回用户界面后,直接向系统检索结构提交分析出的检索请求。分析时,系统的领域本体会向推理机传送与检索请求相关的知识内容,再推理分析检索请求词句之间的关联性,然后自动查找符合要求的信息。与此同时,还会结合推理情况,创建契合检索要求的词群或句群,然后根据检索结果,构建一个逻辑清晰的检索结果呈现模式,向客户可视化展示检索得到的信息资源。利用此种模式,用户输入关键词句后,便可快速完成信息检索,可降低检索误差、提高检索效率。
1.2.3 检索匹配与输出模块
检索匹配及输出模块是以上一环节分析得到的与检索请求相符的词群或句群为依据,结合已构建完成的领域本体,从知识库中查询用户需要查询的信息资源。接收到用户接口及查询信息处理模块提交的检索关键词句群后,此模块根据推理规则推理分析存储于知识库,由RDF、RDFS等技术描述的实例,准确输出结果集,将搜寻到的与检索请求相符的信息资源或文献资料归类到一起,再经过分析处理之后,与用户输入的检索请求展开一致性、相关性对比,以对比结果为依据,判断检索结果与用户需求是否相符,然后根据领域本体知识,利用语义相似度算法,对二者的相关度数值进行计算,并按相关度程序排列信息次序,然后再按照相似度由高到低的顺序,经由用户界面,将查询到的信息资源结果反馈给用户,如此便可完成用户在整个数字图书馆的信息检索过程。
1.3 信息检索流程设计
基于语义网技术的数字图书馆传统信息检索系统,需要立足语义层次、知识层次检索信息资源,因而其检索流程共划分为4个步骤,一是根据元数据采集、处理标准,利用语义网技术统一数字图书馆各类信息的格式,并构建元数据库,用于存储处理后的信息。二是运用检索工具,结合专家知识及经验,以数据库中的信息作为数据源,构建与存储领域本体。三是以领域本体为基础,根据用户输入的信息检索关键词展开推理分析,经过转换格式后,再计算语义相似度,然后将符合要求的语义提取出来。四是根据提前设定的检索表达方式,抽取领域本体知识中符合用户需求的信息资源,然后根据各个资源与检索关键词间的语义相关度计算结果,排列各个信息资源的展示顺序,按照相似度程度向用户提供检索结果[3]。
1.4 信息检索系统的结构
基于语义网的数字图书馆的信息检索系统由4部分组成,一是数据提供者,主要是指数据库机构及部门,负责设定数据库的利用权限,定义数据库语义映射,确保用户能够访问信息资源,并为数字图书馆信息资源有效共享提供支持。二是领域专家,其将与程序员一起,利用程序员给出的元数据及其他信息,共同创建领域本体并为本体提供数据存储、查询及浏览服务。三是程序员,其是元数据的提供者,以元数据作为主要数据源,利用领域本体知识内容,设计与构建数字图书馆的信息检索系统,应赋予系统语义查询功能,还要合理设置系统的服务检索功能,除此之外,还要对不同等级用户的访问、查询等各个权限进行合理设定。四是用户,其会通过用户界面将自己的信息资源查询请求提交给数字图书馆的语义查询及搜索系统,得到系统执行检索任务反馈后,从用户界面查看反馈回来的信息资源。在此结构体系下,可帮助用户精准、快速获取所要查询的信息资源。
2 基于语义网的数字图书馆信息检索模型构建关键环节
2.1 领域本体集成与构建
2.1.1 领域本体集成
领域本体有顶层本体、领域本体、任务本体、应用本体4种类型,而领域本体间具有3种不同的映射关键,一是单本体,二是多本体,三是混合本体。由于互联网发展背景下,数字图书馆的信息资源会持续变化,并具备共享信息资源的需求,因而数字图书馆存在结构不同的信息,因此基于语义网的数字图书馆信息检索模型不可应用单本体或多本体,而是应选用混合本体,以便提高数字图书馆信息内容的更新效率。集成领域本体时,除了要借助领域专家丰富的知识、充足的经验之外,还需要运用语义网技术,并参照用户关于领域知识的认知度、了解情况等内容,从而生成认可度较高的词汇,确保用户检索请求可以得到准确、快捷的处理,同时也有助于提升用户信息查找时需求表达的准确性,从而提高信息资源检索查询效率,实现信息资源有效共享。
2.1.2 领域本体构建
本文结合运用骨架法、IDEF5法构建领域本体,引入螺旋模型思想,采用周期性方式、按螺线进行多次迭代,从而创建一个适应需求持续变化趋势的领域本体。第一,要分析需求。面向客户展开问卷调查,从而确定系统的应用目的、应用范围、应用对象。根据调查反馈,考虑到目前数字图书馆掌握的信息类别及知识总量,合理确定領域本体的体积,选择最为适合的表述语句,同时还需要明确创建领域本体的时间,并给出领域本体的更新间隔,将这些内容清晰列在领域本体构建计划方案之中。第二,分析本体,根据需求分析及工作计划书创建本体,以领域专家为核心,在程序员、用户辅助下,运用访谈、调研、网络查询等多种方式获取领域知识,并确定领域本体的核心概念及内在关联,创建标准化语言,构建本体核心概念集[4]。第三,创建本体,根据本体分析结果、运用编码工具及相关标准、采用形式化编码形式编写本体,以便简化程序、奠定本体共享重用基础。第四,验证评价本体,利用骨架法的本体评价标准测试本体,分析术语是否存在歧义、术语逻辑关系是否一致。第五,本体进化,利用迭代技术持续优化已创建的本体,使之符合实用需求。
2.2 语义相似度算法优化
2.2.1 基于语义距离的算法优化
根据语义距离计算语义相似度,需要考虑到概念继承性,还将二元关系链的长度大小纳入考量。需要根据网络的各个有向边的重要权值完成语义相似度计算。计算公式为
sim(w1,w2)=■,(1)
式中:l代表网络结构最大深度,Dis(w1,w2)代表w1与w2 2个概念节点间最短路径的有向边数目。但此计算过程较为粗糙,仅以节点间路径作为依据,未能考虑到语义距离角度对计算结构所产生的影响。而节点所在层次表示的是语义深度,也是语义相似度的重要影响因素,若按照此算法计算语义相似度,计算结果可能会与实际形成偏差。为此,计算基于语义距离的语义相似度算法时,应将语义深度纳入其中,语义深度的计算公式为
?琢=1-■,(2)
式中:Dep(w1)、Dep(w2)表示本体网络结构中w1与w2节点的所在层数。设网络根节点深度为1时,每个层次的节点深度均为1。
此外,网络层次中节点地位也会影响计算结果,父节点与子节点是包含与被包含的关系,然而子节点的特征对于父节点而言并非完全适用,可能会出现高层级节点及低层级节点的相似度比低层级节点与高层级节点间相似度更低的情况。因此,计算语义相似度时,需考虑到网络层级中节点所处地位,计算公式为
?茁=■。(3)
综合考虑这些因素,可以将基于语义距离的语义相似度计算公式调整为
sim1(w1,w2)=■。(4)
利用此算法计算语义相似度,得出结果更加全面与精准。
2.2.2 基于概念特征的算法优化
此算法是对概念的特定属性值进行对比分析,从而判断概念间的相似性。相同属性量越多,得出的相似度结果越高。基于概念特征的语义相似计算公式为
sim1(w1,w2)=?兹f(w1∩w2)-?琢f(w1-w2)-?茁f(w2-w1),(5)
式中:w1∩w2代表w1与w2的共有属性集,而w1-w2、w2-w1分别代表w1、w2 2个概念独有的属性集。然而领域本体中,除了术语间关系描述外,还会定义各个本体的属性特征,若本体中不同概念具备相同属性数目,则说明二者具有较高的相似度[5]。为简化算法,应仅考虑本体属性这一影响因素,因此,需要对基于概念特征的语义相似计算公式进行优化。由于领域本体中,不同本体的属性数量并不一致,2个本体相同属性及不同属性数量的差值可能为负,此时,需要利用其他参数进行调节,但会导致计算过程相对复杂,且计算结果无法量化。因而,优化算法时,只考虑2个本体的共有属性及概念集的总属性量,不将二者不同属性计入其中,则可将基于概念特征的语义相似度算法优化为
sim1(w1,w2)=■,(6)
式中:Attr(w1)与Attr(w2)分别代表概念w1与w2的属性特征集合,Attr(w1+w2)则代表这2个概念的共有属性特征集合,其中f(x)表示x的属性数目。利用此算法可减少重复性计算,并提升计算结果的量化性。
2.2.3 基于信息量的语义相似度算法优化
此算法是通过不同概念的共有信息量判断二者相似度,计算公式为
sim(w1,w2)=■[-log p(w)],(7)
式中:sim(w1,w2)表示涵盖w1与w2 2种概念的全部集合。但数字图书馆涵盖多种类型、不向来源的信息资源,具有相对较大的领域本体构建体量,因而需要在信息量语义相似度算法的基础上,结合运用基于语义距离的算法以及基于概念特征的算法。在这3种算法思想融合的基础上,从语义距离、概念特征、信息量3个维度展开语义相似度计算[6]。因此应将基于信息量的语义相似度算法调整为
simw1,w2=■,
(8)
式中:?兹1、?兹2、?兹3表示不同类型的领域本体在各分析视角中的重要权值。此算法各部分相似度值域取值范围均介于0与1之间,且值域范围也为0到1,此算法可以根据实际情况调节各类领域本体的重要权值,在参数修正的基础上可适用于多种不同情况。改进后的语义相似度算法综合了3种算法的优势,可提高语义相似度计算精准度,并能得出更加客观、合理的计算结论。
3 结束语
互联网时代,数字图书馆建设实现了信息资源共享,为发挥数字图书馆的信息资源利用价值,需要同步更新与优化信息检索系统。出于这一目的,本文运用语义网,设计契合数字图书馆用户需求的信息检索系统,给出了该系统的框架模型。模型创建时,采用可扩展语言,以资源描述框架为支持,模拟专家的知识及经验,进而有效集成领域本体知识并科学建设本体结构。本文所设计的信息检索系统,可在深度解析语义的基础上实现信息快速检索,能够高效、精准查询与利用数字图书馆的信息资源。
参考文献:
[1] 佘俊,罗勇,余少锋,等.基于语义理解和AI的电力设备信息检索方法[J].电子设计工程,2022,30(22):89-92,98.
[2] 龍彦.基于语义的公共图书馆信息资源检索平台优化研究[D].湘潭:湘潭大学,2021.
[3] 张婷.旅游领域本体构建及语义检索研究[D].太原:太原理工大学,2020.
[4] 简芳洪.融合主题语义的信息检索模型研究[D].武汉:华中师范大学,2020.
[5] 徐凯斌.基于潜在语义分析的多语种信息检索系统的研究与实现[D].延吉:延边大学,2019.
[6] 王浩林.基于张量分解和语义网的医学信息检索和推荐系统[D].北京:中国科学院大学(中国科学院重庆绿色智能技术研究院),2018.
