FFDNet:复杂环境中的细粒度面部表情识别
2024-06-01何昱均韩永国张红英
何昱均 韩永国 张红英


摘 要:针对面部表情识别在复杂环境中遮挡和姿态变化问题,提出一种稳健的识别模型FFDNet(feature fusion and feature decomposition net)。该算法针对人脸区域尺度的差异,采用多尺度结构进行特征融合,通过细粒度模块分解和细化特征差异,同时使用编码器捕捉具有辨别力和微小差异的特征。此外还提出一种多样性特征损失函数,驱动模型挖掘更丰富的细粒度特征。实验结果显示,FFDNet在RAF-DB和FERPlus数据集上分别获得了88.50%和88.75%的精度,同时在遮挡和姿态变化数据集上的性能都优于一些先进模型。实验结果验证了该算法的有效性。
关键词:表情识别; 头部姿态; 特征解耦; 损失函数
中图分类号:TP391.41 文献标志码:A 文章编号:1001-3695(2024)05-042-1578-07
doi:10.19734/j.issn.1001-3695.2023.08.0394
FFDNet:fine-grained facial expression recognition in challenging environments
Abstract:This paper proposed a robust recognition model FFDNet for facial expression recognition in complex environments with occlusion and pose variation of the face. The algorithm used a multi-scale structure for feature fusion to address the diffe-rences in face region scales. It decomposed feature differences and fine-grained by fine-grained modules, and used encoders to capture features with discriminative power and small differences. Furthermore it proposed a diversity feature loss function to drive the model to mine richer fine-grained features. Experimental results show that FFDNet obtains 88.50% and 88.75% accuracy on the RAF-DB and FERPlus datasets, respectively, while outperforming some state-of-the-art models on both occlusion and pose variation datasets. The experimental results demonstrate the effectiveness of the algorithm.
Key words:expression recognition; head position; feature decoupling; loss function
0 引言
面部表情是人类交流时传递信息的重要方法。心理学家Mehrabian[1]的研究表明, 人类的感情传递55%来自于面部表情。面部表情识别旨在通过算法自动识别人脸情绪,在虚拟现实、心理辅导和健康检测等方面有重要应用,吸引了学术界和工业界的大量关注[2]。
早期针对人脸表情识别的研究在受控的实验室场景中进行,因为环境良好,所以如梯度方向直方图[3]、局部二值模式[4] 和主成分分析法[4]等人工设计特征提取器的方法能够获得良好的性能。近年来,无约束野外场景下的人脸表情识别备受关注。然而,在这一背景下,人脸遮挡和姿态变化问题成为了人脸表情识别所面临的新挑战。人脸遮挡会极大地改变人脸的视觉外观,严重影响人脸表情识别的准确度。由于遮挡导致人脸特征定位不准确、人脸对齐不精确或配准错误,进而增加了从被遮挡的面部提取可鉴别特征的难度[5]。人脸姿态变化则会造成特定的面部特征(如眼睛、嘴巴等)在图像中的位置和形状发生变化,相同的表情在不同的头部姿态下会呈现出不同的视觉特征,给表情识别带来挑战。为了解决这些问题,一些研究工作进行了探索。何俊等人[6]为解决人脸识别多角度问题,首先提取回归模型的增量修正特征,然后用PCA进行特征选择,最后采用判别共享高斯过程隐变量模型识别多角度人脸表情。Wang等人[7]使用随机裁剪和基于关键点的裁剪,生成不同的面部区块图像,以缓解遮挡和姿态对表情识别的影响。Ye等人[8]注重利用表情识别中人脸的关键部分信息,结合两层注意力机制的CNN-LSTM,有效地挖掘重要区域的信息。王素琴等人[9]基于GAN先对遮挡人脸图像填补修复,再进行表情识别。郑剑等人[10]关注到人脸局部细节信息的重要性,使用双分支结构分别提取全局特征和局部特征,使用两阶段注意力权重学习策略,按重要性权重融合全局和局部特征,同时采用区域偏向损失函数鼓励重要区域,获得较高的注意力权重。
上述方法侧重于提取具有较强判别能力的特征,如眼睛、嘴巴、额头等在不同表情中变化显著的强特征。然而,这些强特征往往只占据了人脸区域的一部分。在人脸遮挡或头部姿态变化情况下,人脸显著特征缺失,会带来严重的精度損失。与之相对应的,一些在表情变化中变化微弱、但由于其分布广泛而对于识别过程同样重要的弱特征,如鼻翼、颧骨肌肉、眉毛等区域,却没有针对性的研究。在实际场景中,由于人脸遮挡和头部姿态的变化,面部区域的信息会受到不同程度的损失。这也就意味着,除了关注强特征外,亦需关注弱特征,以提高模型的鲁棒性。弱特征因为区域尺度较小,在特征提取过程中,会逐渐消失在模型不同的特征层中,所以本文的多尺度特征融合方法显得尤为重要。多尺度方法能够从全局和局部两个方面出发,综合提取人脸中与表情相关的强特征和弱特征,从而扩大特征信息的覆盖范围,有效地缓解姿态变化和人脸遮挡问题。
通过多尺度特征融合方法能够获取更为丰富和多样化的特征信息。然而,在人脸遮挡和头部姿态变化的情境下,对残存人脸的融合特征进行细腻的识别,能够提升人脸表情识别的效果。通过将多尺度的融合特征分解为多组细粒度特征,可以将原本融合的整体特征细分为更小、更具体的特征。这样做的好处在于,细粒度特征更加具有针对性,可以专注于捕获细微的、特定于面部表情的特征差异。例如,在“开心”和“愤怒”两种表情中只采用整体的特征,可能会注意到一些共性,比如嘴巴的张开程度。然而,通过细粒度特征分解可以更加具体地关注在“开心”时嘴角的上扬程度,以及在“愤怒”时嘴角的下垂程度等细微差别,从而更准确地辨识这两种表情。因此,本文使用细粒度模块将融合特征分解为多组细粒度特征以感知面部动作,有效提升面部表情识别对细微特征差别的识别能力,这在复杂环境下非常具有优势。在特征分解过程中,为了得到差异性高冗余性低的多细粒度特征,设计了一种多样性损失驱动模型分解多样性特征,提高模型表征能力。同时,充分利用编码器encoder的优势,挖掘细粒度特征之间的潜在关系,有助于在捕获微小差异特征的同时,更为专注那些具有更高价值的特征。综上所述,本文的主要贡献总结如下:
a)基于特征融合和特征分解的思想,提出了针对头部姿态和遮挡问题的表情识别网络FFDNet。FFDNet利用卷积神经网络获得全局和局部特征,并且通过encoder模块挖掘潜在的特征关系,从而精准捕获面部表情间的差异。
b)利用融合单元构建多尺度模块,获取不同感受野和处于不同深度的特征。融合单元具有不同的功能,通过GSConv卷积对特征进行压缩、扩展、交互和下采样。多尺度模块在面部表情识别中能够提取不同尺度区域的特征,有助于获得更丰富的面部表情信息。
c)提出细粒度模块,将包含高级语义信息的结构特征分解为多组细粒度特征。每个特征都会学习一个特征关系权重,并使用encoder来捕获潜在特征之间的内在关系,从而获得具有区分性特征的表示。
d)为了提取更加丰富的细粒度特征,设计了多样性特征损失(diversity feature loss,DF loss)。通过降低细粒度特征之间的相似性促进特征的多样性和丰富性。
最后,FFDNet在野外数据集中进行了广泛实验。实验结果表明,FFDNet优于几种先进的人脸表情识别方法。同时在姿态变化和遮挡数据集上的精度更是显著优于几种先进算法。这表明基于特征融合和特征分解的方法能够进一步提高面部表情识别,尤其是复杂情况下的识别性能。
1 相关工作
自文献[11]第一次提出对表情进行研究后,人脸表情识别的研究一直在继续。目前对于人脸表情识别任务,常见的方法是提取面部表情的特征,然后根据特征进行分类。早期的人脸识别通常使用人工设计提取特征,然后使用支持向量机[12]和AdaBoost[13]等分类器进行分类。
得益于计算机视觉的发展,基于深度学习的表情识别获得了巨大进步。数据集是深度学习算法的重要部分。从数据集难易程度大致可以分为实验室受控数据集和野外数据集。野外数据集因为样本分布更接近真实使用场景而受到广泛关注。但是数据集中完整且姿势标准的人脸样本占据大多数,而遮挡和姿态变化等的复杂样本较少,给模型的泛化性带来了困扰。人为收集并标注大量复杂情况的样本几乎是不可能的。基于对抗生成网络GAN的图像合成方法带来了新的解决方案。Huang等人[14]提出了TP-GAN,该模型使用单张图像可以合成正面照,在大姿态情况下也能够保持身份特征和较好的真实感。Tran等人[15]提出了DR-GAN,学习和其他脸部信息如头部姿态解耦的特征,可以通过单张或多张同身份的图片有效转正侧脸。Xie等人[16]认为从图像中提取的特征通常和其他面部属性比如姿势等纠缠在一起,这对于FER不利。所以提出一种双分支解缠生成对抗网络模块,引入两个鉴别器进行身份和表达分类,分离表情和其他属性。
目前许多工作注重提取人脸表情特征,以实现更好的分类效果。比如Gera等人[17]使用迁移学习得到一个特征提取器结构,通过高效通道注意力鼓励有效特征并抑制无效特征。Fard等人[18]针对面部图像的类内差异和类间相似性问题,提出Ad-Corre损失。该损失函数指导网络生成类内样本相关性高、类间样本相关性较低的嵌入式特征向量。Xue等人[19]使用multi-attention dropping随机丢弃注意力图增强局部区域在表情识别中的作用,利用Transformer探索不同局部区域之间的丰富联系。Ruan等人[20]提出基于特征分解和重构的特征学习方法。通过特征分解模拟表情相似性,然后捕获特征类间和类内的关系,并以此重建表情特征。Wang等人[21]在人脸表情识别数据集上建立自我关注机制,利用排名正则化对训练中的每个样本进行加权,并建立重新标记机制,以修改排名最低组中样本的标签。
但是这些工作没有很好地解决遮挡、姿态变化的问题。目前的研究工作证明了从全局和多尺度解决人脸表情识别中的复杂情况是非常有效果的。Xia等人[22]针对遮挡和姿态变化,提出了多尺度特征融合网络。该模型将分成不同粒度的局部区域形成新图像,从细粒度到粗粒度输入图像,逐步挖掘局部细粒度信息、粗粒度信息和全局信息。同时使用多尺度特征融合策略捕获细微类间的变化特征。Zhao等人[23]使用多尺度模块融合具有不同感受野的特征,降低了更深层次卷积对遮挡和变化姿态的易感性。同时使用局部注意力模块引导网络关注局部的显著特征。Gera等人[17]在模型的不同深度上将特征图进行分割,得到多个区域,获取到全局上下文信息和局部上下文信息。Liao等人[24]从三重注意力的卷积神经网络分支中获取全局特征向量,从关键点引导的注意分支中获取局部特征向量,最后使用拓扑图和图匹配模块增强信息表达和区分不同表情的能力。Cho等人[25]提出了一种局部注意力网络,它根据姿势变化,自适应地捕捉重要的面部区域。Ma等人[26]提出了同时接收RGB图和LBP特征图的模型,使用注意选择性融合进行特征融合,然后使用Transformer在可视词和全局子注意力之间构建相关性。自Vision of Transformer[27]工作獲得成功后,Transformer被广泛用于计算机视觉。ViT将Transformer成功应用在图像分类领域,其模型简单、效果好,且可扩展性强。ViT通过将图像分解为大小相同的区域并嵌入为向量,在大规模数据集上进行训练,实现了与CNN有竞争力的效果。目前基于Transformer的表情识别分为基于完全的Transformer和基于CNN和Transformer组合模式两种。比如Akeh等人[28]使用完全ViT架构进行表情识别,将图像划分为区域后,输入ViT模块中进行识别。另一种如Xue等人[19]使用CNN提取特征图,将特征图划分为patch输入ViT中进行分类。
受这些工作的启发,本文设计了一个基于特征融合和特征分解的多细粒度关系感知网络。通过采用特征融合技术,能够提取丰富的多尺度特征,同时关注到关键的微小人脸区域。接着采用特征分解和encoder来从全局层面探索多尺度潜在特征之间的关系,从而帮助模型集中关注具有辨别力的面部区域和微小特征。
2 本文方法
本章将介绍模型的整体结构以及各部分的实现细节。如图1所示,FFDNet由用于特征融合的多尺度模块、分解融合特征的细粒度模块和特征关系提取模块encoder三个部分组成。在特征提取模块,FFDNet使用ResNet34[29]作为骨干网络,因为它具有很好的泛化性能。特征关系提取模块则使用Transformer的encoder完成。
2.1 特征提取和多尺度模块
针对输入图像,首先需要进行特征提取。ResNet是一种深度卷积神经网络,其允许网络学习残差映射,从而增加网络的深度。FFDNet的特征提取使用ResNet34。该网络有四个stage,每个stage输出特征的分辨率分别为40×40,20×20,10×10和5×5。
正如上文所述,人脸中贡献给表情识别的区域尺度是不同的。在特征提取时,不同尺度区域的特征信息会分布在模型的不同深度中,导致模型更加关注拥有显著和较大尺度的人脸区域。然而当人脸受到遮挡或者姿态变化,显著区域可能会出现缺失,这将严重影响模型的识别性能。
特征融合可以很好地解决该问题。首先,特征融合能够整合来自不同层次的特征图,这些特征图具有不同的分辨率和语义信息,从而实现了多尺度特征表达。其次,该方法可以将低层特征的细节信息与高层特征的语义信息融合在一起,为模型提供更丰富的特征信息。当然,特征融合还有助于增加网络的深度和宽度,从而提高网络的鲁棒性,使其能够更好地应对图像中的变形、遮挡、噪声等问题。
多尺度的特征融合通常采用自顶向下的方式,能够有效传输定位信息。然而,在分类任务中并不需要定位信息。所以FFDNet的特征融合方式在建立不同特征级别间的信息流时,更偏重深度特征。图1中feature fusion部分展示该特征融合算法的结构。该结构共进行了三次特征融合。前两次分别融合了ResNet模块stage1~3的高分辨率低语义特征和stage2~4的低分辨率高语义特征。最后融合了前两次融合的输出以及最具有语义信息的stage4输出。最终得到一个长度为512的特征向量,用于进一步的任务处理。
在特征融合过程中,过于复杂的模型不利于收敛,所以FFDNet采用了GSConv[30]。如图2所示,GSConv通过将原始卷积、深度可分离卷积和通道混洗混合在一起得到。这种方法解决了深度可分离卷积在通道信息上也是深度可分离的问题,同时在特征提取能力和速度之间取得了较好的平衡。除了计算量的优势外,GSConv还可以通过控制卷积的stride实现不同倍的下采样,并通过点卷积实现通道交互并调节通道数。这些操作在多尺度特征融合时被广泛使用,使得FFDNet在特征融合过程中能够更加高效地处理任务。
单个融合单元(fusion unit,FU)结构如图3所示。每个GSConv块使用两个GSConv堆叠。每个FU使用四个GSConv块,分别完成通道调节、通道交互和下采样功能。FU中所有卷积都是用1×1的感受野。这没有改变特征的感受野,只是将特征信息进行融合和传递。浅层的粗级特征会通过FU模块向深层流动,并且和细级特征进行融合。最终在模型的各层中建立直接的信息流,增强了特征的表示。
2.2 细粒度模块
由于人脸具有相似的全局结构,所以人脸表情识别可以视为一种细粒度分类任务。要实现高性能的细粒度分类,需要捕捉能够有效区分不同类别、细微差异的细粒度特征。在前面的FFDNet中,通过特征融合提取了在网络不同深度的特征,这在一定程度上促进了细粒度特征的提取,但是多层感知机对于从融合特征中分解细粒度特征并不敏感。
细粒度模块将融合的特征向量分解为多组细粒度特征,然后encoder探索这些细粒度特征之间的关系,捕获对不同表情类别敏感的特征。在图4中,细粒度模块首先使用FC和ReLU对融合特征进行特征映射,从融合特征中获取差异化信息。不同分支从融合特征中分离出不同特征,将一个融合特征分解为多组不同的潜在特征。潜在特征的不同维度代表不同的元信息,而特征内部元信息的关注度应当是不同的,因此需要為特征分配一个特征内关系权重。
首先通过FC产生一个和潜在向量等长的权重向量,然后通过sigmoid映射到合理数值得到内特征权重,从而得到一个自感知的特征。在整个过程中,长度为512的融合特征向量通过细粒度模块被分解为多组细粒度特征,作为特征序列送入encoder中进行特征挖掘和分类。
2.3 多样性损失
融合特征被分解为多个细粒度特征的过程中,特征冗余是无法避免的。为此设计一种降低冗余,提高特征多样性的损失函数DF loss(diversity feature loss)。FFDNet希望不同的细粒度特征在特征空间是不同的矢量,它们具有不同的方向。DF loss对于特征向量在空间中的大小并不关心,因为同方向不同大小的特征是共线向量。共线向量可以通过放大或者缩小一个向量得到。所以使用余弦相似度(cos similarity,CS)衡量两个特征在方向上的相似度,公式如下:
其中:u和v分别代表两个细粒度特征向量;L为向量的长度。当u和v在方向上等同时,相似度为1,反之则为-1。
假设细粒度模块中的特征分解为N个细粒度特征。计算每个细粒度特征之间的相似性,会产生N×N个相似度结果,定义为相似性矩阵CORMN×N。因为CS(u,v)等于CS(v,u),且CS(u,u)=1,所以CORMN×N是一个对角线值为1的对称矩阵。其中CORM[i,j]代表第i和j个向量间的相似性。相似性越低,两个特征之间就具有更强的差异性。具体来讲,CORMN×N和细粒度特征的关系用式(2)表示。
其中:Fn表示第n个细粒度特征。该矩阵清晰展示了多组细粒度特征两两之间的相似性程度。对于批次大小为B的样本,会得到批相似性矩阵BCORMB×N×N。但是训练时,会存在有分类错误的样本,该类样本的特征及其特征相似度不具有参考价值。所以需要过滤错误分类样本的相似性矩阵。
对于批次大小为B的样本,有target labels TL={TL1,TL2,…,TLB},有预测类别predict labels PL={PL1,PL2,…,PLB},分类是否正确的判别函数为
然后,定義分类结果:
在训练过程中,DF loss结合了交叉熵损失函数,总的损失函数如下:
Losstotal=CELoss+λDFLoss(6)
DF loss只是在模型训练过程中提供辅助,所以λ被用来调节CE loss和DF loss的比例,通常设置λ值小于1。
3 实验结果与分析
本文在两个野外数据集RAF-DB[31]和FERPlus[32]以及姿态变化和遮挡数据集上进行了实验,验证FFDNet在表情识别尤其是复杂任务下的优越性。
3.1 数据集
图5中展示了RAF-DB和FERPlus数据集中的部分样本。
a)RAF-DB。该数据集是一个拥有30 000张面部图像的野外表情数据库。数据集分为单标签子集和多标签子集。本文只使用了单标签表情图像,包括七种基本情绪(惊讶、害怕、厌恶、开心、伤心、愤怒和中性)。其中12 271幅图像作为训练集,3 068幅图像作为测试集。
b)FERPlus。该数据集是FER2013数据集的扩展版本,提供了更准确和丰富的标签,以及一些增强的图像质量。FERPlus数据集中包含来自各种真实场景和环境的人脸图像,这些图像包含八种基本的表情类别,相比于RAF-DB数据集多了contempt类别。
c)occlusion datasets。为了验证模型在遮挡条件下的性能,Wang等人[7]从RAF-DB和FERPlus的测试集中收集了面部遮挡图像作为遮挡数据集。两个数据集的遮挡图像分别有735张和605张。
d)pose variation datasets。同时为了验证模块在不同头部姿态下的性能,Wang等人[7]从RAF-DB和FERPlus的测试集中收集了头部姿态变化的图像。在姿态RAF-DB和姿态FERPlus数据集中,有1 248张和1 171张图像的俯仰角和偏航角大于30°,558和634张图像大于45°。
3.2 实验细节
本文使用对齐的人脸表情样本作为模型的输入,分辨率设置为40×40。在训练中采用了数据增强方法(比如随机水平翻转、随机裁剪、随机擦除等)缓解过拟合问题。
模型框架使用PyTorch搭建,在Intel i5-13600k和NVIDIA 3080 Ti硬件设备上进行训练。对于所有数据集均设置批次大小为64,模型训练200个epoch。优化器使用Adam,初始学习率使用0.001,并使用reduce学习率衰减策略。这样的策略有助于模型更好地收敛。
3.3 消融实验
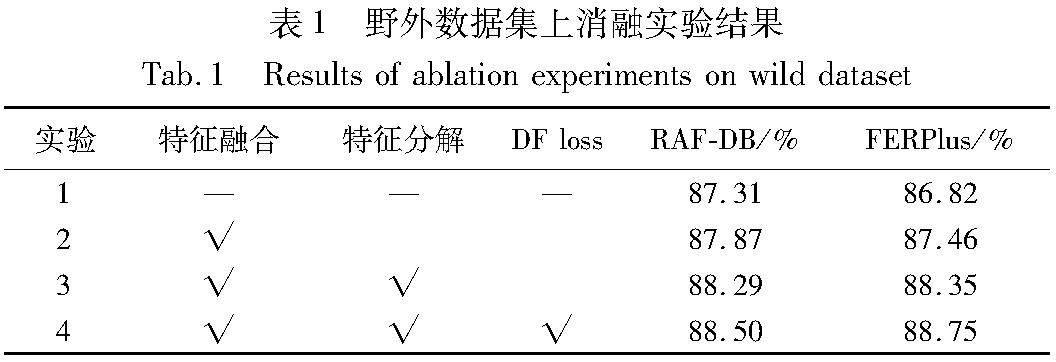
为了显示FFDNet各模块的有效性,本文在野外数据集RAF-DB和FERPlus上进行了消融实验,评估不同模块对性能的影响。实验结果如表1所示。
基线网络(实验1)将ResNet34提取的特征直接简单嵌入后送入encoder中,不使用其他策略。但是由于嵌入过程中,特征没有平滑过渡,其性能没有优势。实验2在基线上新增了特征融合,即在卷积特征提取阶段使用了本文的特征融合模块,然后将融合特征输入encoder中。
与基线相比,实验2的性能有了显著提升(0.64%,0.56%)。这证明了特征融合在人脸表情识别中的有效性。有效性的原因在于特征融合从不同层次不同尺度的特征图融合信息,同时捕获低级别的细节信息和高级别的语义信息。特征融合也为模型创建了类似残差的更短更多的路径,在一定程度上也缓解了梯度消失的问题。
实验3在baseline上使用了特征融合和特征分解策略,在两个数据集上分别提升了0.89%和0.42%。特征融合能够提升特征的丰富性,但是没有重点关注区分性特征。在融合的特征上进行特征分解得到细粒度特征,能够驱动模型在丰富的特征中挖掘有区分性的特征。
实验4进一步使用了DF loss,该损失函数降低了细粒度特征中的冗余信息,推动模型挖掘更多差异性的细粒度特征。该实验在两个数据集上获得了0.4%和0.21%的提升,证明了该损失函数的有效性。
a)细粒度特征分解数量对模型的影响。在特征分解中,融合特征被分解为多个细粒度特征。细粒度特征的数量和特征的维度都是可调的参数,所以该实验将在RAF-DB数据集上探讨这两种参数对模型影响。
图6(a)展示特征分解时不同特征个数在RAF-DB数据集上的测试精度。可以看到当分解个数为33时能够获得最佳性能。一方面,当使用小数量的细粒度特征时,特征的表达能力有限,模型难以充分挖掘数据中的复杂特征,导致性能下降。另一方面,当特征数更多时会增加网络的深度,从而可能导致梯度消失或梯度爆炸问题。同时计算复杂度增加,可能会过度拟合训练数据中的噪声和细节。
图6(b)展示了细粒度特征向量不同维度对模型的性能影响。可以看到,当向量维度为216时获得了最佳的分类精度。但是相比于192维度只有极小的提升,所以在FFDNet中使用了计算量更少的192维度。
同样地,当用更低的维度表征细粒度特征时,表达能力有限。当使用更高的维度时,会增加计算复杂度,使得模型难以训练。
b)t-SNE可视化。为了进一步展示特征融合和特征分解方法的有效性,该实验使用t-SNE在二维空间上进行可视化。如图7所示,不同颜色代表不同的类别。点代表RAF-DB测试集的样本。在baseline(图7(a))上有一定的聚类效果,但是类别间隔不明显。使用特征融合后的算法(图7(b))能够捕获更多人脸区域特征,所以有更好的分类间隔。特征分解能够关注融合特征上更具有辨别力的特征(图7(c)),特别是对于存在遮挡、姿态偏移和相似的类间样本,有着更好的判别力。所以在t-SNE中类间间隔有了扩大,提升了模型的性能。
3.4 与先进算法对比
1)在RAF-DB上的对比情况
表2显示了FFDNet与几种先进的人脸表情识别方法在RAF-DB数据集上的比较结果。
从表2可以看出,FFDNet方法的分类准确率最高,达到了88.50%。与VTFF和PACVT相比,提高了0.36%和0.29%。MA-Net、CERN、PACVT和本文方法一样,通过探索多尺度全局特征对人脸表情识别的有效性。RAN使用多区域的输入实现对遮挡和姿态的鲁棒性。Ad-corre通過设计复杂的损失函数促进特征的多样性。但是相比于这些方法,FFDNet获得了更高的精度。这是因为除了关注大视野的特征外,FFDNet还注重丰富特征中各细粒度特征间的关系。
图8为FFDNet在RAF-DB数据集上的混淆矩阵。可以看到,FFDNet在惊讶、开心、伤心、愤怒和中性上分别获得了88%、96%、87%、83%和88%的可观精度。但是在害怕和厌恶类别上的精度较差,原因是多方面的。一方面,从图5可以看出,这两种表情与开心愤怒等表情相比,没有较为强烈的特征变化,并且非常相似。另一方面,这两类表情的数据样本数量偏低,也使得网络在两种表情上的泛化性弱。
2)在FERPlus上的对比情况
表3显示了先进方法在FERPlus数据集上的结果。从表3可以看到,FFDNet获得了最高的性能,达到了88.75%。SCN针对数据集标签进行优化。RAN将图片裁剪为多个区块作为输入,提高模型对遮挡人脸的鲁棒性。LAN使用局部注意力网络,根据姿态变化自适应捕捉重要面部区域的注意力。文献[34]使用双分支结构将表情识别中的不利因素解耦过滤,实现了较好的分类性能。与这些方法相比,FFDNet注重特征的尺度性,并挖掘特征的潜在关系,实现了更优的性能。
图9为FFDNet在FERPlus数据集上的混淆矩阵。可以看到在中性、开心、惊讶和愤怒类别上获得了非常好的性能。与RAF-DB数据集一样,在害怕和厌恶类别上的精度较低。轻蔑类别是FERPlus数据集在FER2013上新增的类别。从图5可以看到,轻蔑和中性类别的人脸具有很高的相似性,从混淆矩阵可以看到,轻蔑类别经常被错分为中性类别。这也是FERPlus数据集上的一个难点。
3.5 在遮挡和姿态数据集上的实验
为了验证FFDNet在复杂场景下能够实现非常好的性能,本文在遮挡和姿态数据集上进行实验。
表4是FFDNet和先进算法在姿态变化的人脸表情数据集上的结果,最佳精度使用加粗字体表示。可以看到FFDNet在姿态变化数据集上相比于其他先进算法有更好的表现。特别是在Pose-RAF-DB数据集上比其他算法有很大的优势,在两种姿态数据集上分别比其他最先进算法提升了0.58%和0.49%。
表5是FFDNet和先进算法在遮挡人脸表情数据集上的结果,最佳精度使用加粗字体表示。可以看到FFDNet总是获得最优分类性能,在两个遮挡数据集上分别获得了84.13%和85.12%的精度。特别地,在Occlusion-RAF-DB上的性能与其他算法相比有较大的优势。
在姿态变化和遮挡数据集的实验结果表明,FFDNet使用特征融合和细粒度特征分解能够有效提取和捕获具有分辨力的特征,实现在复杂情况下更具有判别力的人脸表情识别算法。
3.6 可视化分析
为了更好地解释FFDNet的有效性,本实验使用Grad-CAM[37]方法对基线模型、基线模型+特征融合和FFDNet三种模型进行可视化分析。为了更清楚地表达模型在复杂情况下的有效性,本文从RAF-DB中收集了包含光照、姿态变化、遮挡等情况的图像样本进行可视化。从图10可以看到,特征融合的感受尺度(图10(c))总体上是比基线网络(图10(b))更大,这也说明特征融合能够提取感受野更大、语义信息更丰富的特征,但是更丰富的特征并没有重点关注有辨别力的区域。FFDNet中通过细粒度特征分解和encoder进行特征关系提取,能够从丰富特征中定位更具有判别力的特征。从图10可以看到,使用了特征分解的FFDNet(图10(d))是从(特征融合得到的)尺度泛滥的特征上收敛到更重要的区域上,总是能稳健地定位到正确的人脸区域。特征融合扩大特征尺度,特征分解后通过encoder能够挖掘和关注更重要的特征,所以FFDNet在复杂情况数据集上总是能获得更加优异的性能。
3.7 算法实时性
为了评估该模型在实际应用中的执行性能,本文进行了实时性测试。实验环境采用了3.2节中所描述的配置,并对1 000张图片进行了多次测试。结果显示,每帧图像的平均推理耗时约为10 ms,相当于每秒处理100帧。在仅使用CPU的环境下,每帧图像的平均推理耗时约为20 ms,相当于每秒处理50帧。两组实验结果表明,本文算法能够满足实现实时性任务的要求。
4 结束语
本文提出了一种基于特征融合和特征分解的表情识别模型FFDNet,用于野外的表情识别。具体来说,首先通过骨干网络提取特征,通过GSConv构建的多尺度模块进行多级特征的融合;然后多尺度特征被多分支的细粒度模块分解为多组特征。使用encoder提取细粒度特征间的丰富关系,捕获具有辨别力的细粒度特征。为了解决特征冗余问题,使用DF loss降低细粒度特征之间的相关性,提升特征的多样性。在数据集上的实验结果表明,FFDNet在野外数据集中,特别是在姿态变化和遮挡数据集上有卓越的识别性能。
参考文献:
[1]Mehrabian A. Communication without words[J]. Communication Theory, 2008,6: 193-200.
[2]Jeong M, Ko B C. Drivers facial expression recognition in real-time for safe driving[J]. Sensors, 2018,18(12): 4270.
[3]童莹. 基于空间多尺度HOG特征的人脸表情识别方法[J]. 计算机工程与设计, 2014,35(11): 3918-3922,3979. (Tong Ying. Facial expression recognition algorithm based on spatial multi-scaled HOG feature[J]. Computer Engineering and Design, 2014,35(11): 3918-3922,3979.)
[4]李俊华, 彭力. 基于特征块主成分分析的人脸表情识别[J]. 计算机工程与设计, 2008,29(12): 3151-3153. (Li Junhua, Peng Li. Facial expression recognition based on feature block principal component analysis[J]. Computer Engineering and Design, 2008,29(12): 3151-3153.)
[5]南亚会, 华庆一. 遮挡人脸表情识别深度学习方法研究进展[J]. 计算机应用研究, 2022,39(2): 321-330. (Nan Yahui, Hua Qingyi. Research progress of deep learning methods for occlusion facial expression recognition[J]. Application Research of Compu-ters, 2022,39(2): 321-330.)
[6]何俊, 何忠文, 蔡建峰, 等. 一种新的多角度人脸表情识别方法[J]. 计算机应用研究, 2018,35(1): 282-286. (He Jun, He Zhongwen, Cai Jianfeng, et al. New method of multi-view facial expression recognition[J]. Application Research of Computers, 2018,35(1): 282-286.)
[7]Wang Kai, Peng Xiaojiang, Yang Jianfei, et al. Region attention networks for pose and occlusion robust facial expression recognition[J]. IEEE Trans on Image Processing, 2020,29: 4057-4069.
[8]Ye Ming, Hu Qian, Liu Guangyuan. CNN-LSTM facial expression recognition method fused with two-layer attention mechanism[J]. Computational Intelligence and Neuroscience, 2022, 2022: article ID 7450637.
[9]王素琴, 高宇豆, 張加其. 基于生成对抗网络的遮挡表情识别[J]. 计算机应用研究, 2019,36(10): 3112-3115,3120. (Wang Suqin, Gao Yudou, Zhang Jiaqi. Occluded facial expression recognition based on generative adversarial networks[J]. Application Research of Computers, 2019,36(10): 3112-3115,3120.)
[10]郑剑, 郑炽, 刘豪, 等. 融合局部特征与两阶段注意力权重学习的面部表情识别[J]. 计算机应用研究, 2022,39(3): 889-894,918. (Zheng Jian, Zheng Chi, Liu Hao, et al. Deep convolutional neural fusing local feature and two-stage attention weight learning for facial expression recognition[J]. Application Research of Computers, 2022,39(3): 889-894,918.)
[11]Darwin C, Prodger P. The expression of the emotions in man and animals[M]. USA: Oxford University Press, 1998.
[12]Shan Caifeng, Gong Shaogang, McOwan P W. Facial expression re-cognition based on local binary patterns: a comprehensive study[J]. Image and Vision Computing, 2009,27(6): 803-816.
[13]Wang Yubo, Ai Haizhou, Wu Bo, et al. Real time facial expression recognition with AdaBoost[C]//Proc of the 17th International Confe-rence on Pattern Recognition. Piscataway, NJ: IEEE Press, 2004: 926-929.
[14]Huang Rui, Zhang Shu, Li Tianyu, et al. Beyond face rotation: global and local perception GAN for photorealistic and identity preserving frontal view synthesis[C]//Proc of IEEE International Confe-rence on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 2439-2448.
[15]Tran L, Yin Xi, Liu Xiaoming. Disentangled representation learning GAN for pose-invariant face recognition[C]//Proc of IEEE Confe-rence on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2017: 1415-1424.
[16]Xie Siyue, Hu Haifeng, Chen Yizhen. Facial expression recognition with two-branch disentangled generative adversarial network[J]. IEEE Trans on Circuits and Systems for Video Technology, 2020,31(6): 2359-2371.
[17]Gera D, Balasubramanian S, Jami A. CERN: compact facial expression recognition net[J]. Pattern Recognition Letters, 2022,155: 9-18.
[18]Fard A P, Mahoor M H. Ad-corre: adaptive correlation-based loss for facial expression recognition in the wild[J]. IEEE Access, 2022,10: 26756-26768.
[19]Xue Fanglei, Wang Qiangchang, Guo Guodong. Transfer: learning relation-aware facial expression representations with transformers[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 3601-3610.
[20]Ruan D, Yan Yan, Lai Shenqi, et al. Feature decomposition and reconstruction learning for effective facial expression recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2021: 7660-7669.
[21]Wang Kai, Peng Xiaojiang, Yang Jianfei, et al. Suppressing uncertainties for large-scale facial expression recognition[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 6897-6906.
[22]Xia Haiying, Lu Lidian, Song Shuxiang. Feature fusion of multi-granularity and multi-scale for facial expression recognition[J/OL]. The Visual Computer. (2023-06-10). https://doi.org/10.1007/s00371-023-02900-3.
[23]Zhao Zengqun, Liu Qingshan, Wang Shanmin. Learning deep global multi-scale and local attention features for facial expression recognition in the wild[J]. IEEE Trans on Image Processing, 2021,30: 6544-6556.
[24]Liao Lei, Zhu Yu, Zheng Bingbing, et al. FERGCN: facial expression recognition based on graph convolution network[J]. Machine Vision and Applications, 2022, 33(3): 40.
[25]Cho S, Lee J. Learning local attention with guidance map for pose robust facial expression recognition[J]. IEEE Access, 2022,10: 85929-85940.
[26]Ma Fuyan, Sun Bin, Li Shutao. Facial expression recognition with visual transformers and attentional selective fusion[J]. IEEE Trans on Affective Computing, 2021,14(2): 1236-1248.
[27]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: transformers for image recognition at scale[EB/OL]. (2021-06-03). https://arxiv.org/abs/2010.11929.
[28]Akeh L J, Chandra R K, Loo W, et al. Modelling emotions recognition from facial expression using vision transformer with IMED dataset[C]//Proc of the 3rd International Conference on Artificial Intelligence and Data Sciences. Piscataway, NJ: IEEE Press, 2022: 254-257.
[29]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778.
[30]Li Hulin, Li Jun, Wei Hanbing, et al. Slim-neck by GSConv: a better design paradigm of detector architectures for autonomous vehicles[EB/OL]. (2022-08-17). https://arxiv.org/abs/2206.02424.
[31]Li Shan, Deng Weihong, Du Junping. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2017: 2852-2861.
[32]Barsoum E, Zhang Cha, Ferrer C C, et al. Training deep networks for facial expression recognition with crowd-sourced label distribution[C]//Proc of the 18th ACM International Conference on Multimodal Interaction. Piscataway, NJ: IEEE Press, 2016: 279-283.
[33]Liu Chang, Hirota K, Dai Yaping. Patch attention convolutional vision transformer for facial expression recognition with occlusion[J]. Information Sciences, 2023, 619: 781-794.
[34]Xie Yunlan, Tian Wenhong, Zhang Hengxin, et al. Facial expression recognition through multi-level features extraction and fusion[J]. Soft Computing, 2023, 27(16): 11243-11258.
[35]Ma Xin, Ma Yingdong. Relation-aware network for facial expression recognition[C]//Proc of the 17th International Conference on Automatic Face and Gesture Recognition. Piscataway, NJ: IEEE Press, 2023: 1-7.
[36]Liu Hanwei, Cai Huiling, Lin Qingcheng, et al. Adaptive multilayer perceptual attention network for facial expression recognition[J]. IEEE Trans on Circuits and Systems for Video Technology, 2022, 32(9): 6253-6266.
[37]Selvaraju R R, Cogswell M, Das A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 618-626.
