期刊论文结构化数据加工存储标准的研究与探索
2024-05-29彭劲松李璐
彭劲松 李璐

专题主持人
赵婧,女,中图科信数智技术(北京)有限公司期刊业务总监。研究方向:数字出版技术平台建设、数字出版与标准研究。
主持人语
标准化是经济社会发展强有力的技术支持,标准达到统一,才能获得最佳秩序和社会效益。科技期刊数字化发展同样离不开标准的引导与规范,只有保证标准化工作的顺利开展,才能促进数字出版活动获得共同秩序和共同效益,促进参与各环节的各相关主体互联互通。特别是在全球开放科学大背景下,我国科技期刊高质量发展、参与国际竞争,培育世界一流科技期刊亟须标准化引领。
本专题共四篇文章,第一篇聚焦国内外科技论文结构化标准应用的历程,提出既能完整保留论文原始信息,又便于提取各类结构化信息的数据处理方案,实现一次加工多渠道投放和传播;第二篇参考科研与学术出版社区中多种持久标识符体系(PIDs)的发展现状,提出基于PIDs构建技术解决方案;第三篇以科技期刊发布系统迁移作为切入点,按照论文数据、扩展数据及由此衍生的用户数据进行层次划分,提出数据迁移的思路、方法和注意事项;第四篇从个案切入,以中华医学会系列杂志为例阐释DOI在科技期刊传播和评价中的重要价值,并提出防止DOI著录错误的有效建议。四篇文章将视角集中于科技期刊平台的软设施建设,即:标准规范作为科技期刊数字化的基础设施,能够促进科技期刊数字出版的标准化、規范化,促进跨平台、跨模态、跨机构数据交换、数据集成和多平台传播,就需要在资源整理、平台建设、业务制度等层面,通过形成方案指南和实践案例,使之被更多科技期刊共识和践行,更积极地参与全球开放科学,服务我国科技强国建设,为我国科技创新提供支撑力量。本专题的初衷即在此。
摘 要:期刊论文结构化加工在期刊界已经逐步形成共识,国内期刊平台多采用新版期刊文章标签集(Journal Article Tag Suite,JATS)标准进行加工,但JATS标准仅对数据属性提出建议值,自行拓展空间较大,导致实际的数据加工结果千差万别,数据交换困难重重。本文分析了国内外数字化加工和标准进化的历程及我国在XML结构化数据加工中存在的问题,进一步分析了存档及交换标签集、出版标签集等不同子集的特点,提出既能完整保留论文原始信息,又便于提取各类结构化信息的数据加工及存储解决方案,可以根据需要通过减法转换生成符合各平台标准的数据加工存储格式,从而真正实现一次加工、多渠道投放和传播。
关键词:期刊论文结构化;JATS;存档及交换标签集;出版标签集;数据加工存储标准;XML
DOI: 10.3969/j.issn.2097-1869.2024.02.007文献标识码:A
著录格式:彭劲松,李璐.期刊论文结构化数据加工存储标准的研究与探索[J].数字出版研究,2024,3(2):57-64.
1 背景及既有研究
1.1 国际期刊数字化加工及标准进化的基本历程
国际期刊论文全文内容的数字化加工及标准进化经历了较长的发展过程,总体可分为萌芽期、发展期和成熟期三个阶段。
1.1.1 萌芽期
国际出版业数字化加工及文档格式标准起源于20世纪60年代,IBM研究人员发现,要提高数据的可移植性,必须采用一种通用的文档格式来分离内容和数据样式。在该原则下,IBM创建了通用标记语言(Generalized Markup Language,GML),并开始用该语言标记文档内容、版式及相互关系。
1.1.2 发展期
1986年,国际标准化组织(International Organization for Standardization,ISO)在GML的基础上发布了一个信息管理方面的国际标准通用标记语言(Standard Generalized Markup Language,SGML),是ISO、美国国家标准学会(American National Standards Institute,ANSI)、欧洲计算机制造商协会(European Computer Manufacturers Association,ECMA)的共同标准,主要用来注释文本文档,提供文档片段类型信息的规范。在此阶段,一些国际出版公司如Commerce Clearing House(CCH)等开始搭建基于SGML文档存储和展示的平台,把大量的纸质胶片等文档进行电子化处理,转变为SGML文档。部分科技期刊和数据库开始搭建基于SGML规范底层的电子期刊及数据库产品,还有一些国际出版公司(如EBSCO)更是采用了文本标记的方式对期刊的元数据信息进行分类标记。1996年,学术资源平台SpringerLink在线出版项目建立了全球第一个电子期刊全文数据库;同年,美国物理联合会(American Institute of Physics,AIP)开发了在线期刊出版服务(Online Journal Publishing Service,OJPS);1997年,巴西创建了SciELO科技期刊出版平台。这一阶段的主要方向是通过平台形成各自的网络电子出版模式。
1.1.3 成熟期
20世纪90年代中期,万维网联盟(World Wide Web Consortium,W3C)又在SGML标准的基础上衍生出可扩展标记语言(Extensible Markup Language,XML),形成了用以描述网络上的数据内容和结构的数字化标准。XML继承了SGML的大部分功能,去除了使用率较低的功能,降低了使用的复杂度,使科技期刊在出版网络化的同时,能够发挥数据集成的优势,共享数据。国际科技期刊数字化出版自XML的出现开始走向成熟,通过底层数据标准的转换对接,从单一出版社、出版平台走向了集群化并购的道路。例如,爱思唯尔(Elsevier)搭建了ScienceDirect全文数据库,包含近3 000种期刊的全文数据;施普林格(Springer)成为了世界最大的开放获取出版集团之一;2004年,AIP将原OJPS升级为Scitation平台,并为10多家出版商提供服务。国际上,期刊集群化开放获取已经成为主流,为了更好地实现集群化和数据共享,美国国家信息标准组织(National Information Standards Organization,NISO)采用了美国国家生物技术信息中心(National Center for Biotechnology Information,NCBI)的期刊文章标签集(Journal Article Tag Suite,JATS)作为NISO定义的标准规范,并在此后逐步推出一系列国际出版物标准,形成了标准体系。自2010年以来,全球出版行业开始加速数字化转型。当前,国际数字化业务已经“颠覆”了传统出版的概念。据市场调研机构Technavio评估,全球数字出版市场的总体规模会在2021—2025年以每年平均12.6%的增长率加速扩张[1]。以美国为例,其出版的核心业务逐渐从单一的平面化纸质内容生产向跨媒体、多元化的新型数字内容生产转变,美国科技期刊业已基本完成数字化转型,传统的纸质出版已经成为一项小众业务。
1.2 国内期刊数字化加工及标准进化的基本历程
国内科技期刊的数字化加工及标准化进程整体与国际同行相比尚有较大发展空间。国内的数字化标准基本采用借鉴方式,主要是学习认知国际标准,国内科技期刊数字化发展过程同样也可近似地分为萌芽期、快速发展期和初步成熟期三个阶段。
1.2.1 萌芽期
中国的数字化出版起始时间并不晚,其开始于“748工程”。1974年,原国家计划委员会发文批复,同意将汉字信息处理系统工程列入国家科学技术发展计划,成立汉字信息处理系统工程(简称“748工程”)[2]。但国内科技期刊的数字化进度比较缓慢,直至20世纪90年代,随着计算机的普及,数字化才真正开始。起初,国内科技期刊数字化的主要方向是图片化,而数字化的主体主要是图书馆。
这一阶段的标准体系主要是基于扫描图片及以扫描图片为基础的PDF文件。PDF采用“扫描+光学字符识别(Optical Character Recognition,OCR)”的方式进行数据加工,这种方式的优势在于,只要有纸质期刊,就可以进行加工,没有其他任何前提要求。但这种方式也存在一些弊端,如数据加工后,阅读时只能查看扫描形式的论文,不仅不美观,而且文件体积大,不便于网络传输,OCR识别出来的文字内容也经常出现错误。
1.2.2 快速发展期
20世纪末至2010年,国内众多出版公司认识到扫描版PDF的问题而开始采用数字化的排版方式,直接进行转换加工形成PDF文件。这种加工方式的优势在于内容视觉效果美观,便于阅读,不会出现扫描文件常见的锯齿现象,加工出来的文件体积小,便于使用。但这种方式对排版文件的收集提出了严格的要求,不仅要求完整收集排版文件及其附属文件(如补字、补图等),而且还要保证收集到的文件是最后印刷使用的文件版本,而非某个中间版本。虽然这种方式操作较为繁琐,但通过适当增加特定性标签并经过长时间的磨合和发展,这也成为了PDF加工的主流方式。这一时期,国内出现了以知网、万方、维普为代表的一批期刊数据库厂商,他们所采用的主要加工方式是“元数据+PDF展示”。此时,国内的各科技期刊编辑部也开始向纸刊与编辑部网站两种产品并存的方向发展,2010年后,大部分科技期刊都已建立自己的网站。
1.2.3 初步成熟期
自2015年开始,国内科技期刊数字化的主体除图书馆和数据库厂商外,也涌现出一批科技期刊出版机构。这一时期,国内科技期刊数字化转型开始走向成熟,在国家政策的扶持下出现了一批以内容方为主体的期刊集群平台,如Mednexus、Researching、SciEngine、SciOpen等。这些平台借鉴了前沿国际技术信息,建立了可以进行全文XML结构化数据展示的期刊集群平台,同时采用XML结构化数据进行全文内容加工,少量头部期刊开始基于JATS编制适合自己的XML数据标准,如中华医学会的CMA JATS、科学出版社和清华大学出版社各自的XML数据标准等,并分别根据标准开展XML结构化数据加工。2019年,中国科技期刊卓越行动计划的开展大幅加快了国内科技期刊数字化的进程。2023年,“DOAJ China Day 2023”开放获取研讨会在海南召开,开放获取方式已得到众多科技期刊的认可。
1.3 我国期刊论文XML结构化数据加工中的问题
目前国际上进行期刊论文数字化加工的首要目的是數据存储,用标注语言把内容和样式进行分离,底层是用标注语言进行标注的文本文件,主要侧重数据标准,并在数据标准的基础上根据不同的产品需求提炼出对应的产品标准,由此在加工和制作数据时就可以不被产品标准所限制。笔者所在的机构已有近40年的数据加工经验,一般国际客户都会要求先按其自定义的数据规范加工和制作后,再转换、输出为目标平台的格式。
而我国开始探索期刊XML数据加工的理念主要是按产品标准制定数据标准,从而导致数据加工和制作受产品需求所限,大多国内客户都会要求直接制作成目标平台的数据格式,这可能会产生如下问题。
1.3.1 无法完整保留期刊论文所有的原始信息
国内主流的数据加工方式是根据特定产品的需求进行加工,因此在加工具体的XML数据项时,需要根据产品的标准要求舍弃不需要的原始信息,这样做的好处是在展示时可以通过渲染实现数据的统一展示;但也由于丢失了部分原始信息,导致加工出来的数据无法作为原始数据进行存档,而强行存档或将造成数据不完整等不可预期的后果。
1.3.2 无法基于已加工数据生成不同需求产品的数据
对于上述XML结构化数据加工方式,由于数据不能完全体现论文的原始状况,若仅根据经验将数据加工成目标产品需要的数据格式,那么当需要把数据按其他数据库收录要求进行转换时,可能导致无法生成相应数据,只能根据加工后的不完全数据进行转换或重新加工,造成资源浪费。
2 期刊论文结构化数据存储标准的设计与实践
2.1 国际数据标准设计思路
为解决上述问题,可参考国际数据标准的设计思路。JATS是由NISO发布的期刊论文XML编码的标准[3],鉴于该标准的完整性及各类内容提取的方便性,其成为全球科技期刊的一种通用数据交换文档格式,支持出版商和数据库进行期刊内容的存储和交换[4],现在已经逐渐被全世界大部分期刊平台认可并作为其底层数据的通用标准。
该标准体系分为三个标准子集:期刊存档及交换标签集(Journal Archiving and Interchange Tag Set)、期刊出版标签集(Journal Publishing Tag Set)和文章创作标签集(Article Authoring Tag Set),见表1。
期刊存档及交换标签集[5]是一套数据标准集,提供标准化格式以存储期刊文章的知识内容。该标准集在系列标准中包容性最强,其中大部分属性值都是字符数据值,可以容纳任何源值,最大程度保留原始数据内容(包含元素之间的标点和空格等)而无需求助于样式表生成文本元素。由于该标准集具有完整性特征,其还支持针对各种出版标准的用户数据交换,而避免出现数据丢失的情况。
期刊出版标签集[6]是为期刊出版用户提供的一种出版发布规范标准化格式,是一种产品标准,侧重于期刊发布,其包含的标签比期刊存档及交换标签集少。根据该期刊发布标准,部分原文内容(如作者基金信息的分类标题等)会由发布平台通过样式表处理,从而丢弃原始的实际数据信息。
文章创作标签集[7]是为论文作者提供的一种论文写作标准化格式,很多编辑软件针对该标准开发相应工具,方便作者写作并对接期刊编辑。与前两个标准集不同,文章创作标签集是整体标签套件,规定比较严格,很多元素内容必须以指定的顺序出现并限制其格式设置选项,不允许在该标签集上出现具有期刊编辑个体风格的内容,比如列表或参考文献的标号等。
2.2 期刊论文数据加工实践问题分析及解决思路
2.2.1 问题分析
对于国内期刊的XML结构化数据加工,除第一章提出的问题外,笔者在多年数据加工服务实践中还遇到了如下问题:
(1)各期刊集群或出版社的规范不一致;
(2)在同一种规范下,平台的样式不同导致对数据的要求不同;
(3)期刊集群或出版社标准持续更新。
上述问题和第一章中提出问题的实质都在于,虽然期刊或期刊集群的标准规范都是产品类型的规范,但即使是同一期刊或同一集群,这一规范也会根据产品的适用场景不同而发生变化。
2.2.2 关键问题解决思路
为解决上述问题,本文提出如下解决思路。
(1)在构建数据加工存储标准时,以期刊存档及交换标签集而非期刊出版标签集为基础来进行构建,可以加强相关标签集的包容性,需要时再转换为期刊出版标签集或其他期刊自行定义标准。这种方法的核心是数据标准与产品标准的分离。
因此,在设计数据存储标准时,要尽可能兼容其他平台的颗粒度。同时,由于XML语言具有可扩展性,标签名称是否相同并非问题的关键,标签内容的唯一性和准确性才是关键。具体来说,一是要针对各种期刊原文进行分析,对期刊中的各种元素进行总结;二是要制定囊括期刊所有内容的标准集(参考期刊存档及交换标签集的存储方式),将期刊中的所有内容都以元素存储的方式进行标识,且在加工过程中保证标签内容的唯一性和准确性。
(2)采用多种手段保证论文原文信息完整,可通过如下方式处理:第一,将期刊出版标签集或产品类型标签集中需要舍弃的内容适当增加特定性标签,放入专项内容进行存储,同时采用适合其内容的标签进行标注;第二,对于原文元素中出现的标点或空格等用于分割信息的内容,也应基于保留原则,采用特定标识进行标记,这样既能保留原文内容(如原始的标点或间距等),实现原文重现,又能在根据产品标准统一渲染时去除相关标识的内容,使内容按照统一的规格得以呈现。
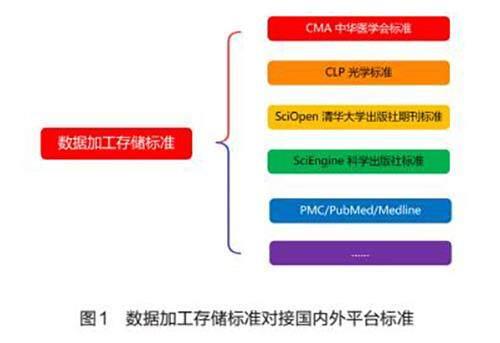
(3)数据加工存储标准的应用针对不同的平台标准转换,也就是将数据加工后存储的标签和结构按照所需的平台标准进行转换,由于设计的标准集内容涵盖期刊的所有内容,客户需要的平台标准和产品标准一般为该标准集的子集(见图1)。因此实际操作时可以针对客户的个性化需求删减不需要的标签内容,进行减法对接,并将标签对应到客户所需标准上,实现一次加工多次分发的目标。
笔者采用上述方式进行数据加工、存储和转换相关工具的调整和优化,并在实际的数据服务过程中进行了验证,现已成功将加工后的数据与多个平台进行对接,包括DOAJ、PubMed及PubMed Central(PMC)、Elsevier Digital Commons、Index Copernicus(ICI)、西太平洋地区医学索引(WPRIM)、国家科技图书文献中心(NSTL)、中国科学引文数据库(CSCD)、中国知网(CNKI)、万方医学、中国人文社会科学引文数据库(CHSSCD)、中文社会科学引文索引数据库(CSSCI)、中国科学院科技论文预发布平台(ChinaXiv)、EDP Sciences、OVID Technologies、SciOpen、SciEngine、中国激光杂志社(CLP)、中华医学会杂志社(CMA)、方正等平台,全部采用同一个数据加工存储标准并通过减法直接输出,已实现一次加工多渠道投放的效果。
2.3 应用案例及成效
笔者根据对中华医学会杂志社的多年数据加工经验和对标准的理解,在上述数据加工存储标准基础上建立了规范、高效的“中华医学会期刊文档标签集”(以下简称为“CMA-JATS标准”),现已完成中华医学会杂志社全部回溯数据的标准化加工工作,并持续进行现刊的数据加工。
中华医学会杂志社从2006年开始研究国际数字化成功案例,以内容建设为核心,参考国际标准并结合中国医学期刊的特色制定了CMA-JATS标准[8]。杂志社于2015年开始搭建中华医学期刊网,目前已收录期刊206种,论文130余万篇。2019年,为了更好地服务集群化期刊出版平台,提升学术数据资源的价值,杂志社搭建了数据中台和业务中台,将通用能力进行抽象化和原子化处理,实现了数据、业务、用户的集约化管理。其中,数据中台在数据标准方面不断迭代,将高精度、高价值的数据进行清洗、标引、分发、统计等,为数据资产的保值和增值打下基础。目前,中华医学会杂志社已经基于数字中台架构开展了多种数字运营形式,除中华医学期刊网外还建立了中华医学期刊全文数据库、中国临床案例成果数据库、中华医学期刊App等多形态、多模式的前端应用,使其成为国内名列前茅的已实现数字出版可持续运营的科技期刊出版单位。
3 面向科技期刊的数据加工及标准建议
目前,大量科技期刊和出版单位正在尝试构建自己的数据标准并开展数据加工,对此,本文提出如下建议。
3.1 从存储标准中提取产品标准,以适应跨平台传播需要
对科技期刊、出版社等内容方而言,不建议以某单一平台的产品标准作为数据存储标准。建立数据存储标准时应脱离产品需求,可使用JATS期刊存档及交换标签集为基础来搭建存储标准之上的数据中台,以本刊或本单位能用到的最大集的方式保留期刊的原始内容。同时,建议以期刊出版标签集为基础来搭建期刊网站平台,充分利用样式表及平台渲染实现网站平台的效果。目前,国内大部分技术厂商的标准都基于JATS期刊出版标签集搭建,因此这种方式也能够适应技术厂商的发布平台。由于期刊出版标签集和文章创作标签集都是期刊存档及交换标签集的子集,完全可以从数据平台提取对应产品平台的各项内容,使内容方真正掌握对数据的主动权,也只有全内容的存储标准才能使内容方在对接第三方平台时,仅在数据标准里做“减法”或“翻譯”即可生成第三方数据。存储标准和样式表是脱离的,所有内容均为文本化信息,而产品标准大多与样式表相结合,若脱离了样式表则可能导致部分数据内容缺失。目前国内很多科技期刊出版单位仍将产品标准置于首位,以产品标准来定义自己的数据标准,并且多以平台展示作为数字化的发展方向,这就导致内容方的数据被产品标准所“绑架”,在跨平台传播时,数据的重用性会受到较大影响,甚至需要重复性加工。XML存储和排版文件等数据都应是内容方的资产,不同的产品标准应该是从存储标准中被针对性提炼出来的,这样内容方才能自主选择平台产品,实现期刊平台商的更迭与优化。
3.2 将数据底层进行结构化处理,避免伪数字化
期刊数字化主要是存储方式的数字化,而网页展示与检索、PDF阅读与下载等只是数字化的表面现象,是对期刊内容的数字化展示手段,后者仍属于传统出版的逻辑。真正的数字化应将数据底层进行结构化处理,而非仅为展示目的的伪数字化。
当前,一些科技期刊内容方存在一种认知误区,即只要采用了国际JATS标准,能在数据库Schema①中检测通过,就可以和国际对接。但实际并非如此,Schema通过仅表明文件逻辑正确,可以导入对方平台,但内容标识的正确性无法通过Schema验证法进行检测。一些加工商将内容生硬地关联至标准元素(Element)中,可能会导致后续产品扩展出现问题,这就是对标准目的性理解不到位的结果。(①指数据库的组织和结构。)
XML是一种可扩展的标注语言,其元素及属性(Attribute)均可自定义,并非只有严格按照国际通用定义才能与国际对接,JATS等通用标准都是由国际组织提供的一些指导性标准,主要是基于颗粒度的指导,国外的主流出版单位很少完全套用国际通用的标准,而是往往会根据自身的需求进行改动,或完全自定义一种自己的标准。国际对接的核心并不在于是否采用了国际标准元素,而在于颗粒度。如果数据加工的颗粒度足够高,那么在与其他平台对接时,只需进行每个元素的转换或翻译即可。这就如同语言翻译,虽然中文和英文字集不同,但每个单词对应的指示性内容是一致的,只需对应翻译就可以让对方理解。因此,对接标准的实质是内容的对接,而非标签的对接,本质上也可以理解为存储标准和产品标准的对接。
目前部分国内期刊平台为了展示效果的视觉统一或美观进行了很多样式渲染,如一些原文的分类小标题等是通过平台样式表根据标签渲染出来的,在底层数据上并没有相应保留,有些期刊平台甚至完全抛弃了原有数据的结构,对于科技期刊而言,若此后再想在其他平台传播就会面临较大的麻烦。因此,数据标准和产品标准的分离是内容商实现数据多平台传播的基础,应充分吸取成功经验,避免造成“为了展示而展示”的伪数字化。
3.3 对数据进行高质量、高颗粒度的加工和存储,基于标准开发平台
目前国内大部分科技期刊内容方均采用现成的平台,造成其数字化受限于平台,形成“被数字化”的局面,其加工的数据在后续使用中都受到限制,甚至使出版资源数字化变成一个“鸡肋”项目。而在国际上,数字化出版不仅实现了盈利,且大有替代传统出版的架势,主要区别就在于国外科技期刊出版单位的数据加工往往有的放矢,可以持续应用于后续产品中。
要缓解目前国内科技期刊内容数字化过程中存在的问题,首先要确认需求,明确数字化的目的及后期产品的种类,根据需求制定能够满足后续产品颗粒度需求的标准;然后在此基础上对内容进行高质量、高颗粒度的数据加工和数据存储,而这也是期刊论文结构化数据存储标准的核心要求。平台应基于标准来开发,而不是反过来由平台决定标准。
数字化内容加工的精确度是关键,国外科技期刊出版单位往往都对基础XML数据精度有明确要求,一般为99.95%或99.995%。当前国内出版物的质量有三审三校等过程体系进行保证,但期刊数字化内容的质量问题还没有引起足够的重视。
3.4 重视知识标注的专业化
在进行数据加工和知识标注的过程中,需要对二者的数据进行分别处理。其主要的不同在于,数据加工是根据加工的技术要求和质量要求,将期刊、论文的数据进行结构化处理,放置于不同的标签中,除加工的知识外,不需要论文内容相关的领域知识;而知识标注则不同,需要标注人员具有与论文内容相关的学科背景,对其中的术语、知识有基本的了解,才能做好知识标注,如对论文的分类或研究方法进行标注等。数据加工可以由普通的熟悉相关操作的人员进行,而后者则建议由具有专业背景的人员进行操作。
3.5 增强版权意识,区分元数据和全文数据对接
在与第三方渠道进行对接时,科技期刊内容方应充分了解对接的各数据库或渠道所需要的数据类型,区分元数据对接和全文数据对接,增强版权意识。一些编辑部对文章的版权认知尚不清晰,在元数据收录时直接将全部数据信息提供给收录方,这有可能导致内容方与收录方在后期产生版权纠纷。
4 结语
本文基于对国内外科技期刊数字化加工及标准进化基本历程的梳理,提出通过期刊论文结构化数据加工存储标准的建立和实施,有效、完整保存期刊内容,并在此基础上提出可以通过从存储结构中提取相关标签的信息并进行转换的方式,生成任何类型平台所需的包括JATS在内的多种出版标准数据,以及支持与各类数据库减法对接的数据,从而实现一次加工多渠道投放的效果。本文还基于笔者所在机构在数字加工领域的长期经验,对科技期刊提出区分存储标准和产品标准、吸取结构化加工成功经验并避免伪数字化、对内容进行高质量和高颗粒度的加工和存储、分别处理数据加工与知识标注,以及增强版权意识,区分元数据和全文数据对接等建议。
作者简介
彭劲松,男,北京欣博友数据科技有限公司技术总监。研究方向:数字化国际标准及传播。
李璐,女,北京欣博友数据科技有限公司期刊XML结构化制作项目经理。研究方向:期刊国内外标准对接。
参考文献
[1]付娆,李晖.结构改变与模式创新:美国数字出版业发展的现状、转向及启示[J].出版与印刷,2022(5):25-31.
[2]周程.转载《知识分子》:王選当年是如何攻克核心技术战胜外企的?[EB/OL].(2018-04-29)[2024-01-03].https://www.icst.pku.edu.cn/fqlm/icst_35th/zxbd/1223569.htm.
[3]MARK H N.NISO Z39.96-201x, JATS: Journal Article Tag Suite[J].Serials Review,2012,38(3):213-214.
[4]包靖玲,李敬文,沈錫宾,等.美国NLM DTD 3.0期刊存储和交换标签集中文章正文部分标记解读[J].中国科技期刊研究,2014,25(4):515-519.
[5]NCBI.Journal Archiving and Interchange Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/archiving.
[6]NCBI.Journal Publishing Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/publishing.
[7]NCBI.Article Authoring Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/articleauthoring.
[8]沈锡宾,李鹏,刘冰,等.CMA JATS在中华医学会杂志社数字出版中的三年实践总结[J].中国科技期刊研究,2018,29(3):248-252.
Research and Exploration on Structured Data Processing and Storage Standards for Academic Journals
PENG Jinsong, LI Lu
Formax BPO Beijing Inc., 100085, Beijing, China
Abstract: Structured data processing of papers has gradually formed a consensus in academic journal field. Domestic journals and platforms mostly adopt the Journal Article Tag Suite (JATS) standard for processing, but the JATS standard only puts forward suggested values for data attributes, which has a large space for self-expansion, resulting in different actual data processing results and difficulties in data exchange. This study analyzed the process of digital processing and standard evolution at home and abroad and the problems existing in XML structured data processing in China, and further analyzed the characteristics of different subsets such as Journal Archiving and Interchange Tag Set and Journal Publishing Tag Set. A data processing and storage solution were proposed, which can not only completely retain the original information of the paper, but also facilitate the extraction of various structured information. It can be used to generate data compliant with each platforms standard through subtraction and conversion as needed, thus truly realizing one-time processing and multi-channel delivery and communication.
Keywords: Structured data of academic journals; JATS; Journal Archiving and Interchange Tag Set; Journal Publishing Tag Set; Data processing and storage standard; XML