基于视觉与激光融合的井下灾后救援无人机自主位姿估计
2024-05-27何怡静杨维
何怡静 杨维
文章編号:1671?251X(2024)04?0094?09 DOI:10.13272/j.issn.1671-251x.2023080124
摘要:无人机在灾后矿井的自主导航能力是其胜任抢险救灾任务的前提,而在未知三维空间的自主位姿估计技术是无人机自主导航的关键技术之一。目前基于视觉的位姿估计算法由于单目相机无法直接获取三维空间的深度信息且易受井下昏暗光线影响,导致位姿估计尺度模糊和定位性能较差,而基于激光的位姿估计算法由于激光雷达存在视角小、扫描图案不均匀及受限于矿井场景结构特征,导致位姿估计出现错误。针对上述问题,提出了一种基于视觉与激光融合的井下灾后救援无人机自主位姿估计算法。首先,通过井下无人机搭载的单目相机和激光雷达分别获取井下的图像数据和激光点云数据,对每帧矿井图像数据均匀提取 ORB特征点,使用激光点云的深度信息对 ORB特征点进行深度恢复,通过特征点的帧间匹配实现基于视觉的无人机位姿估计。其次,对每帧井下激光点云数据分别提取特征角点和特征平面点,通过特征点的帧间匹配实现基于激光的无人机位姿估计。然后,将视觉匹配误差函数和激光匹配误差函数置于同一位姿优化函数下,基于视觉与激光融合来估计井下无人机位姿。最后,通过视觉滑动窗口和激光局部地图引入历史帧数据,构建历史帧数据和最新估计位姿之间的误差函数,通过对误差函数的非线性优化完成在局部约束下的无人机位姿的优化和修正,避免估计位姿的误差累计导致无人机轨迹偏移。模拟矿井灾后复杂环境进行仿真实验,结果表明:基于视觉与激光融合的位姿估计算法的平均相对平移误差和相对旋转误差分别为0.0011 m和0.0008°, 1帧数据的平均处理时间低于100 ms,且算法在井下长时间运行时不会出现轨迹漂移问题;相较于仅基于视觉或激光的位姿估计算法,该融合算法的准确性、稳定性均得到了提高,且实时性满足要求。
关键词:井下无人机;位姿估计;单目相机;激光雷达;视觉与激光融合;ORB 特征点中图分类号:TD67 文献标志码:A
Autonomous pose estimation of underground disaster rescue drones based on visual and laser fusion
HE Yijing, YANG Wei
(School of Electronic and Information Engineering, Beijing Jiaotong University, Beijing 100044, China)
Abstract: The autonomous navigation capability of drones in post disaster mines is a prerequisite for their capability to perform rescue and disaster relief tasks. The autonomous pose estimation technology in unknown three-dimensional space is one of the key technologies for autonomous navigation of drones. At present, vision based pose estimation algorithms are prone to blurred scale and poor positioning performance due to the inability of monocular cameras to directly obtain depth information in three-dimensional space and the susceptibility to underground dim light. However, laser based pose estimation algorithms are prone to errors due to the small viewing angle, uneven scanning patterns, and constraints on the structural characteristics of mining scenes causedby LiDAR. In order to solve the above problems, an autonomous pose estimation algorithm of underground disaster rescue drones based on visual and laser fusion is proposed. Firstly, themonocular camera and LiDAR carried by the underground drone are used to obtain the image data and laser point cloud data of the mine. The ORB feature points are uniformly extracted from each frame of the mine image data. The depth information of the laser point cloud is used to recover the ORB feature points. The visual based drone pose estimation is achieved through inter frame matching of the feature points. Secondly, feature corner points and feature plane points are extracted from each frame of underground laser point cloud data, and laser based drone pose estimation is achieved through inter frame matching of feature points. Thirdly, the visual matching error function and the laser matching error function are placed under the same pose optimization function, and the pose of the underground drone is estimated based on vision and laser fusion. Finally, historical frame data is introduced through visual sliding windows and laser local maps to construct an error function between the historical frame data and the latest estimated pose. The optimization and correction of the drone pose under local constraints are completed through nonlinear optimization of the error function, avoiding the accumulation of estimated pose errors that may lead to trajectory deviation of the drone. The simulation experiments that simulating the complex environment after a mine disaster are conducted. The results show that the average relative translation error and relative rotation error of the pose estimation algorithm based on visual and laser fusion are 0.0011 m and 0.0008°, respectively. The average processing time of one frame of data is less than 100 ms. The algorithm does not experience trajectory drift during long-term operation underground. Compared to pose estimation algorithms based solely on vision or laser, the accuracy and stability of this fusion algorithm have been improved, and the real-time performance meets the requirements.
Key words: underground drones; pose estimation; monocular camera; Lidar; visual and laser fusion; ORB feature points
0引言
由于矿井生产条件复杂,加之有些企业内部安全生产监管缺失,易导致井下发生瓦斯爆炸、水害等事故[1],给人民群众的生命和财产造成极大损失。灾后矿井具有场景未知、光线昏暗、环境危险的特点,为灾后救援工作带来极大困难。无人机具有体积小、灵敏度高、适于狭小危险环境中飞行的优点[2],可利用无人机承担灾后矿井救援的侦测、搜救和运送小型救援物资等任务[3]。无人机在井下灾后环境下的自主导航能力是其完成抢险救灾任务的前提[4],而在未知三维空间中的自主位姿估计技术是无人机自主导航的关键技术之一[5]。
目前,在灾后矿井无人机位姿估计研究方面,包括基于单目相机的视觉位姿估计方法和基于激光雷达的激光位姿估计方法。井下无人机搭载的单目相机连续拍摄灾后矿井图像,通过对图像提取并匹配 ORB(Oriented FAST and Rotated BRIEF)特征点,构建视觉匹配误差,将视觉匹配误差最小化以完成基于视觉的井下无人机位姿估计[6-7]。但由于单目相机无法直接获取三维空间的深度信息,仅基于视觉估计出的井下无人机位姿和真实位姿之间相差一个尺度因子。井下无人机通过搭载的三维激光雷达扫描井下环境得到激光点,1个扫描周期内获取的所有激光点的集合记为1帧激光点云。通过对井下激光点云进行激光特征点的提取和匹配,构建激光匹配误差,通过对激光匹配误差最小化完成基于激光的井下无人机位姿估计。但激光雷达存在视角小、扫描图案不均匀的问题,容易出现激光特征点匹配退化现象,为解决该问题,Lin Jiarong 等[8]提出了 LOAM livox 算法来优化激光点云筛选和激光特征点提取。为提升位姿估计在剧烈运动场景下的稳定性,P. Dellenbach 等[9]基于数据间的连续性提出了 CT? ICP 算法,增加了弹性闭环检测,可适应激光雷达快速剧烈运动的场景。另外,K. Chen 等[10]提出了一种基于稠密点云块的激光位姿估计算法,利用字典形式存储激光点云,进一步降低了位姿估计和闭环检测的计算量。但由于灾后矿井巷道中横向激光特征点的数量远高于纵向激光特征点,上述算法在井下巷道中运行时容易出现激光特征点匹配失误的问题,导致位姿估计出现错误,定位和建图性能迅速劣化。
为解决基于视觉的井下无人机位姿估计的尺度模糊问题,可通过融合激光雷达数据来弥补,因为激光雷达可直接获取目标的精确深度信息,可对ORB 特征点进行深度恢复[11]。此外,由于灾后矿井巷道光线昏暗[12],单目相机容易出现拍摄不足或过曝的问题,导致在狭窄巷道中的定位性能较差,而激光雷达受光照等环境因素的影响较小,所以可通过融合激光雷达数据对基于视觉估计得到的井下无人机位姿进行补偿[13-19]。为弥补仅基于视觉或激光在灾后矿井中进行位姿估计的局限性,本文提出了一种基于视觉与激光融合的井下灾后救援无人机自主位姿估计算法。通过对井下图像和井下激光点云分别提取 ORB特征点和激光特征点,并分别进行帧间匹配,得到视觉匹配误差和激光匹配误差,然后将2个匹配误差置于同一位姿优化函数下求解井下无人机位姿。同时,利用视觉滑动窗口和激光局部地图引入历史帧数据,对最新估计的无人机位姿进行修正和约束,避免直接拼接井下无人机位姿造成的轨迹漂移问题。
1井下无人机自主位姿估计流程
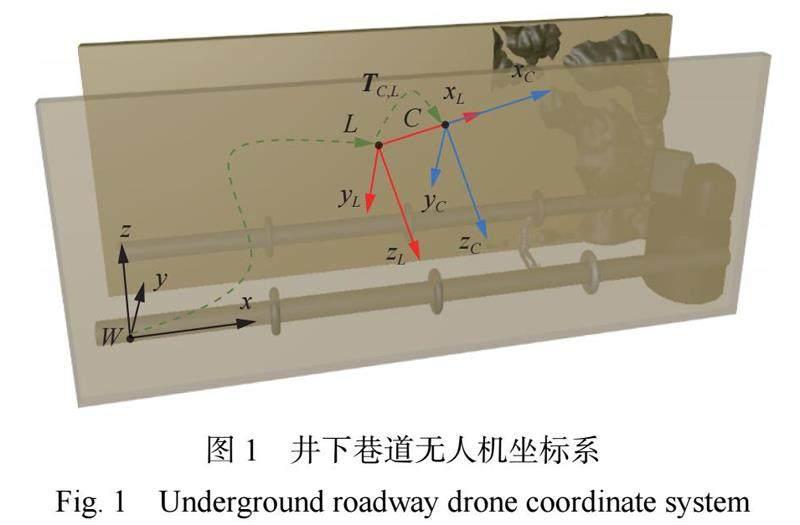
建立井下巷道无人机坐标系,如图1所示。假设巷道为封闭空间,两侧墙壁为竖直,表面有结构化纹理或因受灾而凹凸不平。以无人机在井下巷道中的初始位置为原点 W,建立三维世界坐标系W? xyz, x轴指向无人机前进方向并平行于巷道纵向,y轴平行于巷道横向,z轴竖直向上,且 x轴、y轴、z轴遵循右手定则。无人机搭载单目相机和激光雷达在巷道中飞行,分别以单目相机光心C和激光雷达中心L为原点,建立动态的视觉坐标系C? xCyCzC 和激光坐标系 L? xLyLzL,2个坐标系的 xC 和 xL 轴、yC 和 yL 轴、 zC 和zL 轴分别代表无人机的正前方、正左方和正上方,遵循右手定则。由于相机和激光雷达在飞行过程中相对位置不变,利用相机和激光雷达之间的外参标定可获取2个坐标系之间的转换矩阵TC;L 。
无人机自主位姿估计流程如图2所示。井下无人机通过搭载的单目相机和激光雷达分别获取井下图像和井下激光点云。对于井下图像提取 ORB 特征点并进行深度恢复,通过 ORB 特征点的帧间匹配构建视觉匹配误差,通过对视觉匹配误差最小化实现基于视觉的无人机位姿估计;对于井下激光点云提取激光特征点,通过激光特征点的帧间匹配构建激光匹配误差,通过对激光匹配误差最小化实现基于激光的无人机位姿估计。将视觉匹配误差和激光匹配误差置于同一位姿优化函数下,基于视觉与激光融合估计井下无人机位姿。利用视觉滑动窗口和激光局部地图引入历史帧数据,构建历史帧数据和最新估计位姿之间的重投影误差函数,并通过非线性优化完成在局部约束下的无人机位姿优化和修正,实时输出井下无人机6DOF 位姿和轨迹图。
2基于视觉和激光的灾后矿井环境特征点提取
2.1 ORB 特征点深度恢复
井下无人机首先对单目相机采集的矿井图像进行 ORB特征点提取,由于提取的 ORB特征点不具备深度信息,通过匹配该特征点得到的井下无人机位姿与真实位姿之间将相差一个尺度因子,所以在完成 ORB特征点提取后,需利用激光点云对提取的 ORB 特征点进行深度恢复。
利用空间比例投影法恢复 ORB特征点的深度,如图3所示。相机像素平面 P上第 k 帧数据的ORB 特征点 i 的坐标记作Xk;(P)i,將该特征点和视觉坐标系 xC 轴正向的激光点按比例投影到 xC 轴正向dK 处的平面 K上,得到视觉特征投影点和激光点云投影点,视觉特征投影点的坐标记为Xk;(P)i′。对于平面K上的每个视觉特征投影点,通过 KD 树(K-dimensional Tree)搜索算法搜寻与其距离最近的3个激光点云投影点,坐标记为Xk;(L)1(′),Xk;(L)2(′),Xk;(L)3(′)。这3个激光点云投影点对应的原始激光点的坐标为 Xk;(L)1,Xk;(L)2,Xk;(L)3,将这3个原始激光点拟合成一个平面 F,并将 ORB 特征点按相机透视原理投影到平面 F上,得到 ORB 特征点的三维估计点,该点坐标记为 X(?)k;(C)i 。ORB 特征点的三维估计点与无人机当前所在位置的水平距离 d(?)k;i 即该 ORB特征点的深度信息。
2.2激光雷达特征点提取
与 ORB特征点不同的是,井下激光点云中的激光特征点分为两类:一类是处在尖锐边缘上的激光点,一般位于灾后塌落的杂物、石块等,此类激光点与邻域点差异较大,记作特征角点;另一类是位于光滑平面上的激光点,例如巷道壁或管道等,此类激光点与邻域点的差异较小,记作特征平面点。因此,通过计算每个激光点与其邻域点之间的差异,即可提取井下激光点云中的激光特征点,这种差异用曲率表示:
c = j2∈*j1"Xk;(L)j2? Xk;(L)j1"(1)
式中:c为激光点 j1的曲率;S为激光点 j1在其所在激光线上的邻域点集合;Xk;(L)j1和 Xk;(L)j2分别为激光点 j1和j2的坐标。
根据井下环境设定曲率的角点阈值和平面点阈值。当激光点的曲率高于角点阈值时,说明该点与周围环境差异较大,将其加入特征角点集合ε;当激光点的曲率低于平面点阈值,说明该点位于差异不大的平面上,将其加入特征平面点集合H。若激光点的曲率处于平面点阈值和角点阈值之间,则该点特征性较弱,对后续帧间匹配属于冗余信息,不加入特征点集,避免计算资源浪费。
3基于视觉与激光融合的井下无人机位姿估计
3.1视觉帧间匹配与位姿估计
对于视觉坐标系下的井下无人机位姿,利用第 k 帧数据中的 ORB特征点 i的归一化坐标X(?)k;(C)i =(?(x)k;i ; y(?)k;i ; k;i ),可得
其中,Rk(C)+1;k =[R(0) R(1) R(2)]T 和 tk(C)+1;k =[t(0) t(1) t(2)]T 分别为无人机从第k帧到第k+1帧数据的视觉坐标系下1;k 的旋转矩阵和平移矩阵,即
将式(2)和式(3)作为匹配误差进行非线性优化[20],即可估计出视觉坐标系下无人机从第k帧到1;k 。
3.2激光帧间匹配与位姿估计
对于激光坐标系下的井下无人机位姿,利用激光点云中的匹配特征角点和匹配特征平面点之间的距离作为激光匹配误差eε和eH,将其放在同一位姿优化函数下,使得2帧激光点云之间所有匹配误差的二范数平方和达到最低,从而求解出基于激光的井下无人机位姿Tk(L)+1;k 。
3.3视觉与激光融合位姿估计
井下无人机从第k帧到第k+1帧数据的位姿可记作 Tk+1;k = exp (ξk+1;k ),其中ξk+1;k 为 Tk+1;k 的李代数表示,是一个六维向量,代表井下无人机的6DOF 位姿。构造位姿优化函数,寻找最优ξk+1;k,使得视觉和激光特征点在前后帧的匹配总误差最小,即第k帧数据和第k+1帧数据之间的匹配误差ek 的二范数平方总和最小。
式中:ek(C)和ek(L)分别为第k帧数据中的 ORB特征点和激光特征点的匹配误差;Xk(C)和 Xk(L)分别为第k帧数据中的 ORB特征点和激光特征点的坐标;X 11分别为第k+1帧数据中的 ORB特征点和激光特征点的坐标。
对式(6)进行非线性优化,在相机和激光雷达观测数据的共同约束下,迭代求解无人机在井下的初始融合位姿。但式(6)对误匹配的特征点非常敏感,因为误匹配会使得对应误差项偏大,而二范数平方的增长速率极快,将会耗费大量时间用于调整一个错误的值,因此将二范数度量替换为一个增长速率较缓的鲁棒核函数 Huber 函数。替换后的匹配误差可表示为
式中δ为阈值。
加入鲁棒核函数后,当匹配特征点的误差较小时,保持原有的度量,当误差大于阈值δ后,函数增长由二次形式变成一次形式,保证了在对多个误差平方进行联合优化时减少无效的观测残差,降低了误匹配特征点等异常项在代价函数中的影响,从而提高位姿优化函数的稳定性。
4井下无人机位姿的局部约束优化
将算法估计得到的每一帧的无人机位姿进行拼接,即可得到无人机在井下的运动轨迹。但由于无人机每一帧的位姿误差不断累计,最终将造成无人机轨迹出现无法修复的偏移,使得无人机在井下的位姿估计精度迅速下降。因此,提出引入视觉和激光的历史帧数据来对最新估计的位姿进行约束,保证无人机位姿的局部连贯性,避免轨迹漂移。
4.1视觉关键帧选取策略
当无人机在井下运行时,利用视觉滑动窗口可保留过去一段时间内的历史图像数据,计算窗口内的历史帧数据与最新估计的位姿之间的误差函数,通过对其进行最小化,即可实现对最新估计位姿的修正和约束。在构建滑动窗口时需要适时添加和删除关键帧,在选取关键帧时,既要保证加入的关键帧数据能有效修正轨迹偏差,也要避免过高的计算成本[21]。因此,提出基于场景的关键帧选择策略,如图4所示。无人机在井下巷道中拍摄的所有图像可分为动态帧、静态帧和普通帧3类。动态帧是指无人机在井下出现大幅运动或在巷道转角处的场景,此时 ORB 特征点匹配难度增加,应提高关键帧密度。静态帧是无人机静止或运动较为缓慢时,视野内出现了其他运动的干扰物体的场景,此时将会出现动态的 ORB特征点来干扰位姿估计,因而当视野内动态特征点的数量超过阈值后,应舍弃该帧。普通帧是指剩余的普通情况下的帧。关键帧的选取应遵循以下原则:①初始时刻的图像帧标记为关键帧。②动态特征点数量超过阈值的静态帧不应标记为关键帧。③求解相邻关键帧的位姿差距ΔT = T 1 Tn( Tn 为最新估计位姿,Tn?1为与当前帧数据距离最近的滑动窗口内的关键帧的位姿),若丢弃帧超过10帧或ΔT 超过设定阈值时,则认为2帧数据之间视差较大,应将最新一帧标记为关键帧,加入滑动窗口。遵循上述原則添加关键帧,可保证在无人机运动快、ORB 特征点匹配量少时,关键帧提取密集,从而实现位姿精度和计算实时性之间的平衡。
4.2局部约束优化
利用关键帧选取策略将一帧图像数据标记为关键帧后,需引入其对应的激光历史帧数据,即利用坐标变换将激光数据投影到世界坐标系下[22]。同视觉滑动窗口一样,激光历史帧数据同样可以对最新加入的估计位姿进行约束和优化,由于激光雷达的特征点分为2类,需要用2类激光特征点分别约束。具体做法:对于每一个新加入的特征角点和平面点,分别在角点映射和平面点映射中进行最近邻搜索,得到特征点邻近的特征点云簇,计算点云簇的协方差矩阵。根据协方差矩阵中特征值大小和特征向量的对应关系可知,特征角点对应的点云簇呈线状,特征角点和对应点云簇之间的距离为
式中:n?(x);ε为点云簇坐标均值点到特征角点的向量;nε为点云簇的方向向量,即其协方差矩阵的最大特征值对应的特征向量。
特征平面点对应的点云簇呈面状,特征平面点到对应点云簇的距离为
式中:n?(x);H 为点云簇坐标均值点到特征平面点的向量;nH 为点云簇的平面法向量。
将视觉滑动窗口中的数据转换到世界坐标系下,对视觉和激光的历史帧数据进行融合,实现在二者共同局部约束下的无人机位姿优化。构建井下无人机的整体状态向量,其中包括滑动窗口内无人机在世界坐标系下的位姿、ORB 特征点集和激光特征点集。利用滑动窗口内的历史帧数据对无人机的整体状态向量构建局部约束,即可完成对无人机位姿的优化。对整体状态向量构建约束的数学表示为
式中:ewin 为关键帧的共视特征点的重投影误差; eprior 为滑动窗口边缘化带来的先验信息误差。
利用非线性优化求解式(10),即可得到在视觉和激光共同局部约束下优化的井下无人机位姿。由于单目相机和激光雷达提取到的特征点相互独立,增量方程中对应的特征矩阵为零或呈现较强稀疏性,极大降低了优化的计算成本,保证了实时性。
5 仿真与分析
为检验基于视觉与激光融合的井下灾后救援无人机自主位姿估计算法的有效性,在 Ubuntu16.04中模擬灾后矿井巷道并在仿真平台上进行实验,同时与仅基于视觉或激光的位姿估计算法进行比较。模拟的灾后矿井巷道宽度为4 m、高度约为3 m。考虑到灾后矿井巷道光线昏暗且存在烟尘,对仿真所有获得的井下图像进行亮度降低与模糊处理。为保证仿真环境复杂度,设置大量走动或静止的行人、木箱、石块等障碍物,并对侧壁进行凹凸处理。将环境栅格化、二进制化处理,障碍物点为1、其余为0,得到环境矩阵C(矩阵大小为h × w)。计算环境矩阵的汉明距离D(C),则环境复杂度可表示为
真实矿井正常工作的平均复杂度为0.227,而仿真环境平均复杂度达0.518,可以模拟灾后环境的复杂程度。
5.1算法准确性
不同算法的估计轨迹与真实轨迹比较如图5所示(t 为时间)。可看出相比于仅基于视觉或激光的位姿估计算法,基于视觉与激光融合的位姿估计算法在各个平面上的轨迹都明显接近于真实轨迹,且更加平滑。这是由于基于视觉与激光融合的位姿估计算法添加了历史帧约束,保证了局部轨迹的一致性,在井下巷道狭窄环境中能够避免较大的轨迹漂移,实现较为精确的位姿估计。
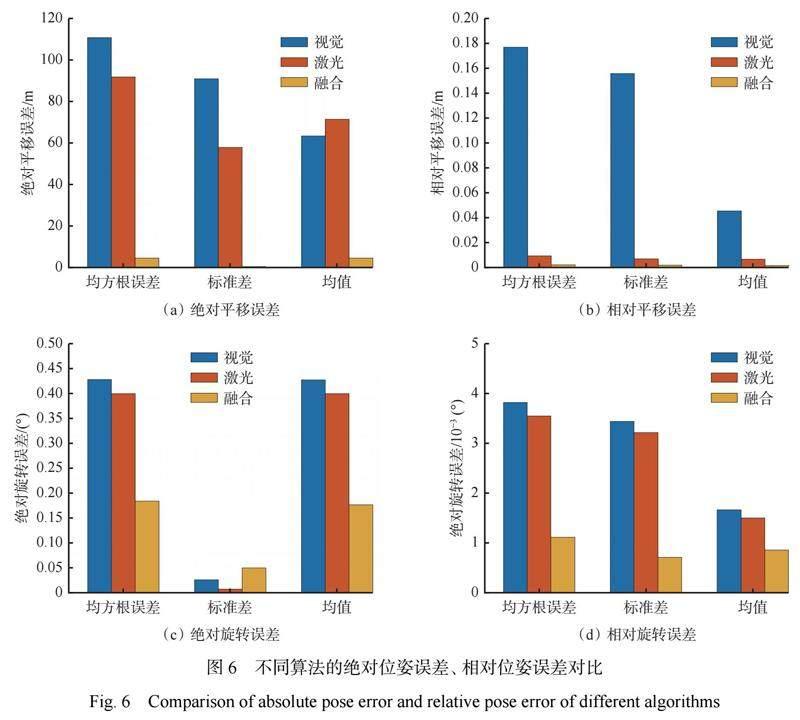
除轨迹图的定性评估外,采用绝对位姿误差和相对位姿误差[23]对算法的精确性进行定量评估。在仿真平台上分别运行基于视觉的位姿估计算法、基于激光的位姿估计算法和基于视觉与激光融合的位姿估计算法,计算估计轨迹与真实轨迹的绝对位姿误差和相对位姿误差,分别以均方根误差、标准差和均值等误差评价指标呈现,如图6所示。可看出基于视觉的位姿估计算法在各误差评价指标中表现最差,而基于视觉与激光融合的位姿估计算法则表现最优;基于视觉与激光融合的位姿估计算法的绝对平移误差、相对平移误差和相对旋转误差均远低于基于视觉的位姿估计算法和基于激光的位姿估计算法,各项误差均值分别降低到4.52 m、0.0011 m、和0.0008°。因此,与基于视觉的位姿估计算法和基于激光的位姿估计算法相比,基于视觉与激光融合的位姿估计算法的精确度较高,能够更精准地实现无人机位姿估计。
5.2算法稳定性
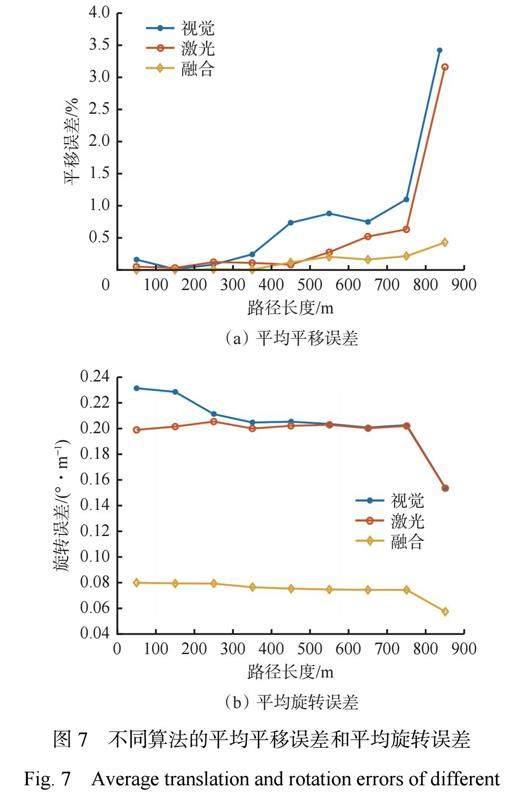
算法稳定性测试通过计算算法估计轨迹和真实轨迹每隔100 m 的平均平移误差和平均旋转误差来实现,结果如图7所示。从图7(a)可看出,仅基于视觉或激光的位姿估计算法的平移误差随运行路径长度的增加而迅速增加,这是因为帧间误差随时间累计,长时间运行将会导致较大的定位漂移;而基于视觉与激光融合的位姿估计算法加入了历史帧约束,实时对最新估计位姿进行优化,因此平移误差相对较低且变化平稳。从图7(b)可看出,基于视觉与激光融合的位姿估计算法的平均旋转误差远低于仅基于视觉或激光的位姿估计算法,且随运行路径长度增加而平稳下降。因此,相较于仅基于视觉或激光的位姿估计算法,基于视觉与激光融合的位姿估计算法的平均误差均较低,具有较高的稳定性,能够满足井下位姿估计的稳定性要求。
5.3算法实时性
通过分析算法运行时间和资源占用率来验证算法的实时性。算法各模块的平均运行时间见表1。可看出位姿估计中特征点提取所占时间最长,这是为了保证在灾后矿井的任何未知场景下都能有足够丰富的特征点用于后续的位姿估计;而在位姿融合估计前去除了大量冗余特征点,因此视觉与激光融合估计位姿的时间相对较短。由于在位姿优化中引入大量历史帧数据进行约束,所以相较于位姿估计时间,位姿优化的迭代收敛时间更长。但由于位姿估计和优化是由2个独立的线程分别实现,高精度优化不会影响初次位姿估计的计算,所以1帧数据的平均处理时间低于100 ms,可以满足无人机在井下环境中位姿估计的实时性要求。
对基于视觉的位姿估计算法、基于激光的位姿估计算法和基于视觉与激光融合的位姿估计算法在运行过程中计算机的 CPU(i5?11300H,3.11 GHz ×4)和内存(16 GiB)的平均占用率进行对比,结果见表2。
从表2可看出,基于视觉与激光融合的位姿估计算法的 CPU 占用率和内存占用率仅略高于其他2种算法。基于视觉与激光融合的位姿估计算法结合了视觉和激光算法的原理,并进行了冗余信息的删除和关键帧的优化,以较低的计算资源代价换取了更高精度的位姿估计,保证了无人机算力资源的高效利用,能够在井下实现较长时间的运行和实时位姿估计。
6结论
1)提出了一种基于视觉与激光融合的井下灾后救援无人机自主位姿估计算法。将井下无人机获取的视觉和激光数据进行融合,利用滑动窗口和局部地图引入历史帧数据进行局部约束,减少累计误差带来的井下无人机轨迹漂移,提升了自主位姿估计的精确性和稳定性。
2)利用井下激光点云数据对单目相机的 ORB 特征点恢复深度信息,按空间比例投影法有效、精准地拟合 ORB特征点所在的平面,精确恢复 ORB 特征点三维信息。
3)利用视觉滑动窗口和激光局部地图引入历史帧数据,实现对最新估计的无人机位姿进行修正和约束,避免直接拼接井下无人机的位姿造成的轨迹偏移。
4)仿真实验结果表明:基于视觉与激光融合的位姿估计算法的平均相对平移误差和相对旋转误差分别为0.0011 m 和0.0008°, 远低于仅基于视觉或激光的位姿估计算法,能够实现更为精确的井下无人机6DOF 位姿估计;该算法在面对不同矿井场景下的位姿估计误差均趋于稳定,有较好的稳定性;算法采用双线程工作,可满足实时性要求,且 CPU 和内存占用率仅略高于基于单一传感器的位姿估计算法,以较低的计算资源换取了较高精度的位姿估计。
参考文献(References):
[1]王恩元,张国锐,张超林,等.我国煤与瓦斯突出防治理论技术研究进展与展望[J].煤炭学报,2022,47(1):297-322.
WANG Enyuan,ZHANG Guorui,ZHANG Chaolin,et al. Research progress and prospect on theory and technology for coal and gas outburst control and protection in China[J]. Journal of China Coal Society,2022,47(1):297-322.
[2]畢林,王黎明,段长铭.矿井环境高精定位技术研究现状与发展[J].黄金科学技术,2021,29(1):3-13.
BI Lin,WANG Liming,DUAN Changming. Research situation and development of high-precision positioning technology for underground mine environment[J]. Gold Science and Technology,2021,29(1):3-13.
[3]江传龙,黄宇昊,韩超,等.井下巡检无人机系统设计及定位与避障技术[J].机械设计与研究,2021,37(4):38-42,48.
JIANG Chuanlong,HUANG Yuhao,HAN Chao,et al. Design of underground inspection UAV system and study of positioning and obstacle avoidance[J]. Machine Design & Research,2021,37(4):38-42,48.
[4]范红斌.矿井智能救援机器人的研究与应用[J].矿业装备,2023(1):148-150.
FAN Hongbin. Research and application of mineintelligent rescue robot[J]. Mining Equipment,2023(1):148-150.
[5]马宏伟,王岩,杨林.煤矿井下移动机器人深度视觉自主导航研究[J].煤炭学报,2020,45(6):2193-2206.
MA Hongwei,WANG Yan,YANG Lin. Research on depth vision based mobile robot autonomous navigation in underground coal mine[J]. Journal of China Coal Society,2020,45(6):2193-2206.
[6] MUR-ARTAL R,MONTIEL J,TARDOS J D. ORB- SLAM:a versatile and accurate monocular SLAM system[J]. IEEE Transactions on Robotics,2015,31(5):1147-1163.
[7] CAMPOS C,ELVIRA R,RODRIGUEZ J J G,et al. ORB-SLAM3: an accurate open-source library for visual,visual-inertial,and multimap SLAM[J]. IEEE Transactions on Robotics,2021,37(6):1874-1890.
[8] LIN Jiarong,ZHANG Fu. Loam livox:a fast,robust, high-precision LiDAR odometry and mapping package for LiDARs of small FoV[C]. IEEE International Conference on Robotics and Automation,Paris,2020:3126-3131.
[9] DELLENBACH P,DESCHAUD J E,JACQUET B,et al. CT-ICP:real-time elastic LiDAR odometry with loop closure[C]. International Conference on Robotics and Automation,Philadelphia,2022:5580-5586.
[10] CHEN K,LOPEZ B T,AGHA-MOHAMMADI A,et al. Direct LiDAR odometry:fast localization with dense point clouds[J]. IEEE Robotics and Automation Letters,2022,7(2):2000-2007.
[11]余祖俊,张晨光,郭保青.基于激光与视觉融合的车辆自主定位与建图算法[J].交通运输系统工程与信息,2021,21(4):72-81.
YU Zujun,ZHANG Chenguang,GUO Baoqing. Vehicle simultaneous localization and mapping algorithm with lidar-camera fusion[J]. Journal of Transportation Systems Engineering and Information Technology,2021,21(4):72-81.
[12]洪炎,朱丹萍,龔平顺.基于 TopHat加权引导滤波的 Retinex 矿井图像增强算法[J].工矿自动化,2022,48(8):43-49.
HONG Yan,ZHU Danping,GONG Pingshun. Retinex mine image enhancement algorithm based on TopHat weighted guided filtering[J]. Journal of Mine Automation,2022,48(8):43-49.
[13]李艳,唐达明,戴庆瑜.基于多传感器信息融合的未知环境下移动机器人的地图创建[J].陕西科技大学学报,2021,39(3):151-159.
LI Yan,TANG Daming,DAI Qingyu. Map-building of mobile robot in unknown environment based on multi sensor information fusion[J]. Journal of ShaanxiUniversity of Science & Technology,2021,39(3):151-159.
[14]毛军,付浩,褚超群,等.惯性/视觉/激光雷达 SLAM 技术综述[J].导航定位与授时,2022,9(4):17-30.
MAO Jun,FU Hao,CHU Chaoqun,et al. A review of simultaneous localization and mapping based on inertial- visual-lidar fusion[J]. Navigation Positioning and Timing,2022,9(4):17-30.
[15] SHAN T,ENGLOT B,MEYERS D,et al. LIO-SAM: tightly-coupled lidar inertial odometry via smoothing and mapping[C]. IEEE/RSJ International Conference on Intelligent Robots and Systems,Las Vegas,2020:5135-5142.
[16] QIN Chao,YE Haoyang,PRANATA C E,et,al. R- LINS:a robocentric lidar-inertial state estimator for robust and efficient navigation[J].2019. DOI:10.48550/arXiv.1907.02233.
[17] XU Wei,ZHANG Fu. Fast-LIO:a fast,robust LiDAR- inertial odometry package by tightly-coupled iterated Kalman filter[J]. IEEE Robotics and Automation Letters,2021,6(2):3317-3324.
[18] XU Wei,CAI Yixi,HE Dongjiao,et al. Fast-LIO2:fast direct LiDAR-inertial odometry[J]. IEEE Transactions on Robotics,2022,38(4):2053-2073.
[19] ZUO Xingxing,GENEVA P,LEE W,et al. LIC-fusion: LiDAR-inertial-camera odometry[C]. IEEE/RSJ International Conference on Intelligent Robots and Systems,Macau,2019:5848-5854.
[20] ZHAO Shibo,ZHANG Hengrui,WANG Peng,et al. Super odometry: IMU-centric LiDAR-visual-inertial estimator for challenging environments[C]. IEEE/RSJ International Conference on Intelligent Robots and Systems,Prague,2021:8729-8736.
[21] KIM B,JUNG C,SHIM D H,et al. Adaptive keyframe generation based LiDAR inertial odometry for complex underground environments[C]. IEEE International Conference on Robotics and Automation, London,2023:3332-3338.
[22] LIN Jiarong, ZHENG Chunran, XU Wei, et al. R2LIVE: a robust, real-time, LiDAR-inertial-visual tightly-coupled state estimator and mapping[J]. IEEE Robotics and Automation Letters,2021,6(4):7469-7476.
[23] STURM J,ENGELHARD N,ENDRES F,et al. A benchmark for the evaluation of RGB-D SLAM systems[C]. IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve,2012. DOI:10.1109/IROS.2012.6385773.
