基于OpenCV-Python的彝文文档图像识别的 预处理算法
2024-05-25李成恩邓拉美喻宁兴
李成恩,邓拉美,喻宁兴
1.六盘水市六枝特区第一中学,贵州六盘水,553400
2.六盘水市六枝特区教育局,贵州六盘水,553400
3.六盘水市第二人民医院,贵州六盘水,553400
0 引言
彝族文章是我国彝族历史文化的重要载体,是研究分布在我国西南地区的彝族的重要资料,更是中华民族的文化瑰宝。但是随着时间的推移,彝族文档保护情况不容乐观,而且由于年代久远和纸张质量问题,很多彝族文档已经无法翻看和查阅,对彝族文档进行数字化处理,是保存文档的迫切需要,保存彝族的文章文档、通过分析研究彝族文章了解彝族的历史、文化和风俗习惯,也是铸牢中华民族共同体意识的迫切需要。
民族语言信息化是让民族语言“活”起来,因此,研究民族语言意义重大。研究如何识别彝族文本文档,首先,我们要掌握一定的彝文知识。彝文指的是彝族的文字,其特点包括:彝文是一种古老的音节文字,一个字形代表一个意义,其文字总数达万余字。彝文的独特体字多,合体字少。彝文的字形结构有点、横、竖、横析,大致有象形、会意、指事、假借四类。彝文涉及宗教、历史、哲学、文学、语言文字、医药、天文、地理和农技等各个方面。彝文文献的书写方式因地区而异,四川凉山一带彝文一般由右向左横行书写;云南、贵州、广西一带则由左向右竖行书写。彝文的声调一般分为3~5个,调型简单。彝文的词序和虚词是表达语法意义的主要手段,基本语序是主语—宾语—谓语。名词、动词、人称代词作定语时,在中心词前;形容词、数量词作修饰语时,在中心词后。有些副词修饰双音节中心词时,在中心词的两个音节之间。彝文中的量词非常丰富,有些方言的量词能直接修饰中心词,起后置冠词的作用。1980年,国务院正式推行了《彝文规范方案》,很大程度上推动了彝族文化的传播。2014年,贵州民族大学的吴勰对古彝文进行了规范化,整理出5000多个古彝文字符,其中常用字3000余个,其余为文献整理所需的异体字[1]。到目前为止,该套字符集已经能够满足古彝文信息化的基本需求。目前对彝族文章文档的图像识别的研究比较少[2]。结合彝文的特征用合适的算法进行预处理,对彝文文档的识别和分析具有重要意义。预处理的好坏直接关系到文本图像的识别和分析的质量。
1 方法和程序
一般来说,古籍文档图像分析和识别需要几个阶段:预处理(二值化)、文本行切分、字符切分和文字识别[3]。本论文是利用OpenCVPython为实验平台,将通过高清摄像机拍摄的彝文图片进行预处理。为后期的图像处理和识别奠定基础。本论文选取的彝文图片为2010年6月中华书局出版的《国家图书馆藏彝文典籍目录》。
图片二值化是图片预处理的关键环节。在二值化之前要进行灰度化处理。二值化的好坏直接影响后期图片的识别和处理。在OpenCVPython中二值化的效果见图1。

图1 彝文文本原始图像与二值化图像对比
在OpenCV-Python实验平台上彝文文本图像二值化的算法如图2所示。
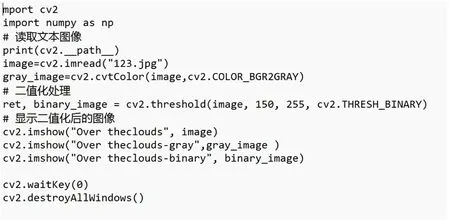
图2 彝文文本图像二值化算法截图
文本图像中的噪声一般是图像采集、传输等过程中由外界因素干扰所引起的,为了减少文本图像中的噪声,提高文本图像的质量和文本图像识别的准确率,文本图像识别的预处理过程中一般还包括了对图像进行降噪处理。本文在OpenCV中利用算法对文本图片进行了降噪处理。降噪处理后可以极大提高图片质量。降噪前后对比如图3所示。

图3 彝文文本图像降噪前后对比
降噪的算法截图如图4所示。

图4 彝文文本图像降噪算法截图
经过对文本图像的二值化和降噪处理后,接下来开始对文本图像进行连通域分析。通过对文本图像的连通域分析,可以将图像中的不同物体分割开来,实现高准确率的图像识别。本文尝试对《国家图书馆藏彝文典籍目录》中的第466页的彝文进行连通域分析。通过分析,得到连通域169个。连通域分析结果如图5所示。

图5 彝文文本图像的连通域分析结果
2 发现的问题和展望
2.1 发现的问题
对图像进行预处理是为文本图像的识别做准备工作,对预处理的结果进行分析,是我们发现问题、寻找研究方向和方法的必由之路。通过对连通域结果的图片分析,我们发现以下三个问题,这也是以后研究的方向。
①我们可以看到在贵州、云南等地彝文有竖向书写的写作习惯,并且在列与列之间会出现一个个独立的笔画(点)。列和列之间的笔画如图6所示。

图6 列和列之间的笔画
②连通域数量过多的问题,如图6所示,一张彝文图像有169个连通域,连通域数量多会对后期字符识别造成干扰。
③有些彝文文章存在彝文和汉文的混排的情况。需要研究如何把彝文和汉文切分出来,实现彝文文本图像版面的分割和描述。
2.2 研究展望
(1)经查阅资料,对于列和列之间的点有两种观点,一种观点是姓氏之间的分割点,另一种观点认为列和列之间的点是分割不同的音节点,以避免混淆和误解。两种观点的对错,有待去考证。需要再深入地研究,找到真正的原因。列和列之间的点的归属问题,是列切分必须解决的问题。通过观察彝文图像可以看出,彝文列和列之间的距离不均等,甚至来说列间距差别还有点大,再加上彝文有些字体书写习惯和字体本身结构的原因,给列切分带来了一定的难度,不能简单地按照宽度均分的方法,笔者打算采用基于轮廓的分割方法来尝试对彝文文本图片的文字进行列切分,一般情况下,采用该方法对图片的质量、清晰度要求比较高,如果图片质量不高或者存在噪声,会极大地影响轮廓识别的准确性,极大可能造成切分出错,彝文尤其是古彝文由于年代久远、保存环境等原因,图片质量普遍不高,使用基于轮廓切分的方法比较困难。彝文是竖向书写的文体,如何精准地把彝文列切分出来,是彝文图像识别中非常重要的步骤,更是以字符切分、字符识别的基础,列切分效果的好坏,直接影响到后面的图像识别的最终结果。彝文列切分中可能产生部分字体切分出错的情况,比如列和列之间的笔画的归属问题,切分出错的字体部分回归本体的问题。如何在OpenCVPython中用合适的算法来处理上述的问题,是今后研究的方向之一。
(2)如何有效地减少、合并连通域也是今后研究的课题。连通域数量多可能由很多原因造成。比如图片质量、噪声干扰、算法的阈值等。针对预处理后连通域数量过多的情况,笔者打算在以后的研究过程中通过优化算法程序的方法进行实验。摸索出一种更适合彝文文本图像连通域分析的算法,也是今后的努力方向和目标。
(3)今后研究的方向还包括对彝文和汉文混排的文本图像版面分割和描述的问题的研究,在彝文文本预处理的过程中,选取的彝文图片比较单纯,都只是字符,没有插图、页码,以及其他不同于字符的内容出现,但是在现实中彝文文本图像中包括很多有异于字符的内容,如何把版面不同的内容进行准确分割和描述,如何在OpenCV-Python的实验平台上找到合适的算法对彝文、彝文和汉文混排的文本图像的版面进行分割和描述,也是以后研究的重点问题。
3 结语
在OpenCV-Python中利用算法对彝文文档图像进行有效处理,包括但不限于列切分、字符切分、后处理等,并且通过一定数量的实验测试,保证算法处理结果有较高的准确率。总结并提炼出基于OpenCV-Python的有效处理彝文文本图像的算法。在基于OpenCV-Python平台上扩大试验样本的数量,优化算法,以期能达到更好的彝文文本图像识别效果。
