基于YOLOv5和U-NET的多目标药盒抓取系统设计
2024-05-18袁斌郎宇健陈凌鹏李晨
袁斌,郎宇健,陈凌鹏,李晨
基于YOLOv5和U-NET的多目标药盒抓取系统设计
袁斌,郎宇健,陈凌鹏,李晨
(浙江科技学院 机械与能源工程学院,杭州 310023)
解决传统机器视觉机器人抓取系统对多目标及复杂目标背景分割不精确导致的目标定位精度差而影响机器人抓取效率的问题,提出一种新的深度学习抓取识别定位系统。搭建由Delta机械臂、PC上位机、双目相机等组成的硬件系统,对工业部署常用的YOLO系列算法进行对比研究。将YOLO与U-NET相结合,用于目标的检测和分割。在精确分割出属于目标和背景目标的像素区域的同时,计算边缘和中心位置信息,运用立体视觉技术得到三维位置,并转换为世界坐标系,由PC机引导机械臂去完成抓取任务。深度学习目标检测和图像分割相结合的系统在较复杂背景、多目标的场景下比未添加图像分割的算法拥有更好的目标定位精确度。YOLOv5和U-NET相结合的目标定位抓取方法具有较高的鲁棒性,达到了并联机械臂的抓取要求。该方法能够运用于其他多自由度机械臂上,具有良好的应用价值。
Delta机械臂;双目视觉;抓取方法;YOLOv5;深度学习;U-NET
随着科技的不断进步,逐渐进入全新的智能制造时代。在这个时代,制造业将更加智能化、自动化、数字化和网络化,以满足不断增长的市场需求,其重要组成部分——机器人技术,也将不断发展和创新,成为制造业自动化的重要推动力量。全球机器人不断高速发展,被广泛应用于工厂自动化[1]、医疗服务[2]、农业[3]等领域。为了增强机器人的自动化水平,采用视觉技术与工业机器人抓取技术相融合的方法已经成为工业技术领域的热点。机器人的难点之一是它们不能正确抓取物体[4]。虽然人类能够很自然地做到这一点,但对于机器人,该操作较复杂,它想要精确了解物体的形状和位置,需要基于优秀的视觉系统。视觉系统为机器人提供了直观、准确、丰富的环境信息,通过对视觉传感器捕捉到的图像信息进行处理,机器人可以很容易地实现目标的识别、跟踪和定位[5],从而引导其操作。目前,机器人已经知道如何执行复杂的任务,但仍缺乏敏捷性和适应移动物体或环境的能力。由此可见,通过构建系统来帮助机器人提高感知技能并识别捕捉物体是主要研究课题。为了与真实物体进行交互,机器人必须能够准确、快速地定位到目标物体的位置,目标定位是机器人抓取任务中的关键环节之一,直接影响着抓取效果和机器人的工作效率。目前的主流方法是利用激光距离传感器、立体视觉和3D相机[6]来解决。
Markovic等[7]通过计算机视觉传感器获取周围环境物体的形状、位置、深度图像等信息,实现了实时更新参数后自动执行。日本电子技术大学的Hasegawa等[8]设计了一种可以解决机器人非常接近物体时其视觉传感器因遮挡而失效的问题的系统,提高了机器人抓取的准确性和稳定性。Sepulveda等[9]提出了一种识别茄子质心三维位置的抓取决策方法,通过质心三维位置来抓取茄子。Yu等[10]提出了一种用于检测机器人抓取矩形框架的深度学习算法,并将检测到的矩形框架内的三维点云映射到抓取参数中。
深度学习具有数据处理高效的优点,近年来越来越受到关注。目前,深度学习技术已经成功应用于多个领域,如图像分类、自动驾驶汽车、语音识别、行人检测、人脸识别、癌症检测等。在这些领域,深度学习在检测和分割不同类别对象方面具有较高的效率。由此可见,在机械臂抓取中加入深度学习目标检测和图像分割,可以提高图像目标定位精度[11-13]。
研究中的检测任务采用YOLOv5算法,YOLO系列算法相较于R-CNN[14]、Faster R-CNN[15]等网络模型,它在识别精度达标的情况下拥有更快的检测速度[16],更易实现机械臂的抓取。图像分割算法采用U-NET方法,它在分割医学图像方面具有出色的效果和性能[17]。文中依次串联YOLO算法和U-NET算法,组成目标定位框架,实现自动检测、定位。图像分割能够消除目标预测框内无关背景的噪音干扰,有效提高目标的定位准确度,通过立体视觉技术得到目标的世界坐标,并引导机械臂抓取。
1 系统概述
Delta机器人抓取系统需要完成对目标的快速识别、定位,并引导机械臂去完成抓取任务,其系统结构如图1所示。此系统主要由2个部分组成:视觉系统,由双目相机配合上位机完成识别、定位目标物;执行系统,由上位机引导机械臂实现抓取目标的任务。视觉系统上位机采用笔记本电脑,并通过Snap7协议与PLC通信,执行系统采用西门子1200型号PLC控制,主要控制delta机械手上的伺服电机,通过Modbus协议读取绝对编码器参数。系统整体框架如图2所示。
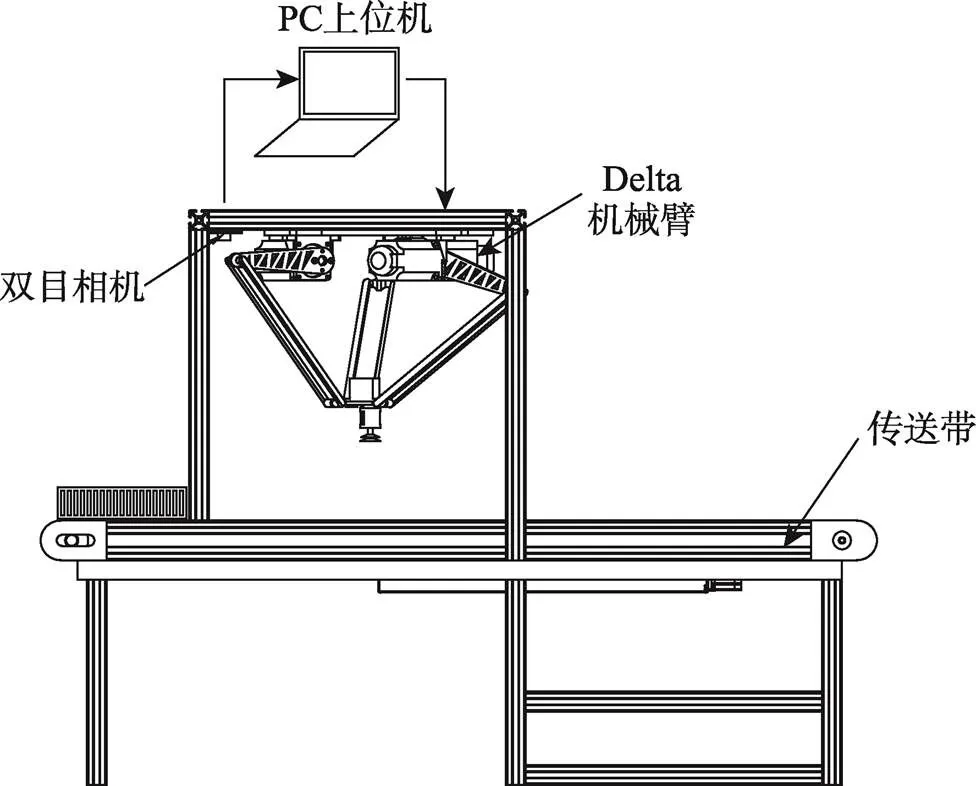
图1 系统结构
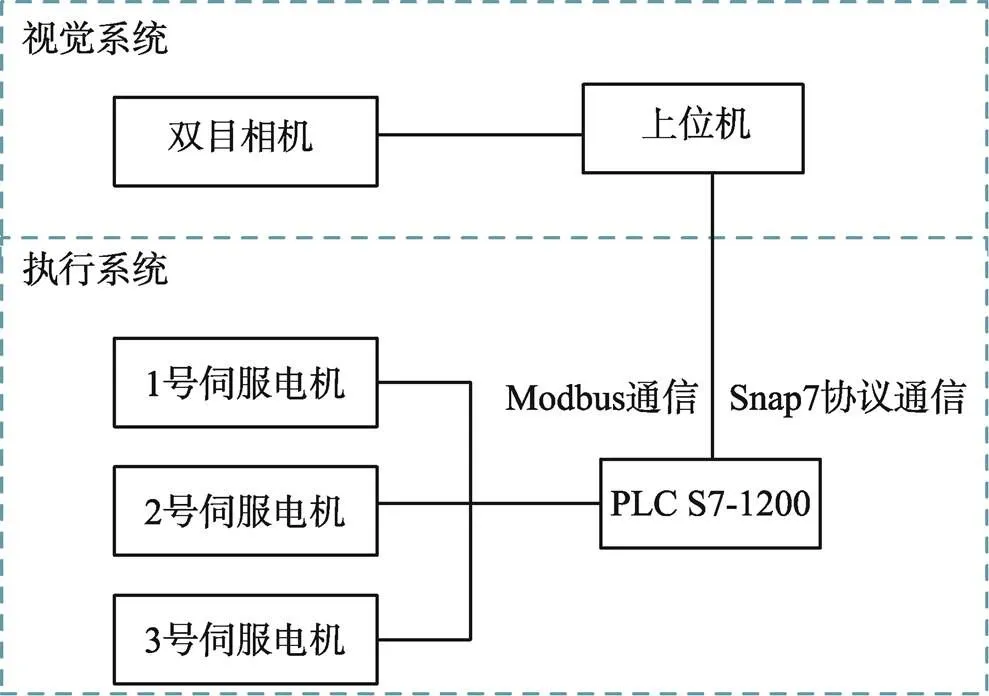
图2 系统框架
2 识别和定位研究
为了准确得到目标物体的位姿信息,首先通过YOLOv5算法对目标区域进行检测,得到ROI区域,然后将ROI区域输入串联的U-Net算法,分割出目标物体及无关背景。结合边缘检测算法识别目标的外轮廓,并对目标物体外轮廓进行最小矩形拟合,计算出目标的中心和旋转角度,最后利用SGBM立体匹配算法计算空间坐标。
2.1 识别定位算法
在目标物体识别定位过程中,采用多种算法融合的方式进行求解。识别定位算法流程如图3所示。

图3 识别定位算法流程
2.1.1 设备和样品
此次试验的深度学习训练设备采用服务器(CPU: Intel 8350C, 2.6 GHz; GPU: RTX3090; RAM: 56G; Pytorch:1.9.0; CUDA: 11.1)。测试图像处理的上位机为HP笔记本电脑(CPU: i5-7300HQ; GPU: RTX1050ti; RAM: 16 G, 2 400 MHz)。相机采用双目摄像头,型号为Pay Cam c4008。目标样品为普通药盒。
2.1.2 数据集制作
为了考察不同光线对抓取目标的影响,用于训练的数据集由CMOS相机在不同光线下模拟实际抓取场景拍摄摆放姿态不同的200张单目标药盒照片,以及200张多目标随机摆放照片组成。部分照片如图4所示,将照片的尺寸修改为480像素×480像素,通过软件Labelimg进行人工标注。神经网络模型需要大量的数据集来参与训练,才能得到理想的模型参数,但实际试验中采集的样本照片的数量和多样性不足,通常需要采用数据增强方法来扩充训练集的数据量。通过增强数据后,获得了一个1 500张图片的数据集,用于训练模型,以提高检测的准确性。

图4 子数据集
2.1.3 算法对比
YOLO(You only look once)系列算法是目前工业上运用非常广泛的算法,文中采用YOLOv5-6.0版本。最近,还在继续更新YOLOv5,衍生了YOLOv5-6.0/7.0版本,它具有更高的检测精度和更好的鲁棒性。将YOLOv5、YOLOv7、YOLOv8的小模型算法均按默认配置,使用上述数据集在服务器上训练100轮,并进行预测,检测结果见表1。在表1中,Param、Weight size、、分别表示参数量、权重、准确率、召回率;mAP50表示IoU阈值为0.5时的平均准确率,mAP50-95表示不同IoU阈值(0.5~0.95,通常以0.05为步长)下的平均精确率的平均值;Train time、Speed分别表示训练时间、检测时间;加粗数值表示各项参数的最优值。
表1 检测算法对比
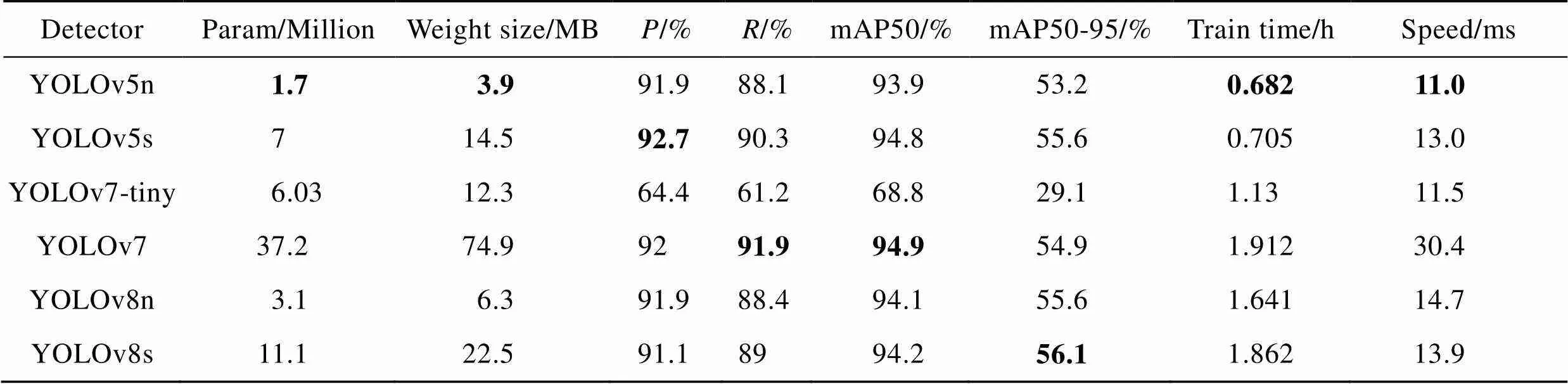
Tab.1 Comparison of detection algorithms
从表1可以看出,在达到标准检测精度的前提下,YOLOv5具有比YOLOv7、YOLOv8更少的参数和更快的检测度。从同一模型来看,随着模型参数的增加,其准确率和召回率的提高幅度非常微小。这主要是因其数据集相较于COCO数据集小得多,模型存在大量的冗余参数,导致模型的各项指标下降。由此可见,对于较小的数据集,选用参数量较少的模型,不仅可以提高准确率、降低训练时间,还在预测速度上具有较大优势。由此,选用YOLOv5检测算法,其训练和推理速度比YOLOv7、v8快得多,且内存占用率更低。YOLOv5在移动设备或资源受限的系统中具有更好的实时性,为了后续能够在嵌入式移动端设备中部署,所以选择它来实现机械臂的抓取。
2.1.4 YOLOv5算法
YOLOv5深度学习目标检测框架能够在图像或视频中快速、准确地检测和定位多个物体,YOLOv5主要由CSPDarknet53、SPP组成。如图5所示,将输入图片缩放,并进行归一化等操作,通过卷积神经网络对图像进行特征提取,在提取特征后,对不同层次的特征进行融合,以更好地描述目标特征,最后使用卷积神经网络对目标进行检测,并输出检测结果。
2.1.5 图像分割
语义分割是一种深度学习算法,它能够将标签或类别与图像中的每个像素相关联,用于分割不同类别的像素集合。语义分割能够在无人操作的情况下自动区分目标和背景,提高了定位的准确度。
这里对4种语义分割算法(U-NET、Fast-SCNN、HRNet、DeepLab-v3+)进行了研究。U-NET算法具有结构简单,易于理解和实现,能够有效捕捉多尺度特征等优点,但它对于大规模场景和高分辨率图像的分割性能有限,无法捕捉完整信息。Fast-SCNN是一种用于实时语义分割的轻量级网络,其网络结构轻量,计算量和参数量较小,适合实时应用。HRNet算法是一种高分辨率网络,在各种分割任务中具有较强的表现能力,其复杂的网络结构需要大量的计算量和参数量,与其他轻型算法相比,在检测速度方面无竞争力。DeepLab-v3+是一种先进的语义分割网络,采用空洞卷积和编码器−解码器结构,并引入空间金字塔池化模块来捕捉多尺度信息,具有非常强大的分割性能,在边缘细节和复杂场景下表现非常突出。同时,它也需要大量的计算量和参数量的支持,推理需要较高的计算资源,无法做到实时检测。由于抓取任务需要实时检测,对推理检测速度也有较高要求,因此排除了HRNet、DeepLab-v3+算法,这里选择兼顾准确性和检测速度的U-NET算法。
采用定位方法,首先对左右相机得到的图像进行矫正,然后传入YOLOv5中进行目标检测,得到目标检测预测框,如图6所示。然后,提取ROI区域,为后续图像分割做准备,如图7所示。将得到的ROI图片输入U-NET网络,进行图像分割,成功消除了无关背景信息,清晰地分割出感兴趣目标,如图8所示。
在图像分割后,去除了原始图像背景的干扰噪点,能够清晰地分割出目标物体。为了避免图像分割后部分像素点丢失对目标中心采集产生影响,首先需要采用Canny边缘检测算法,计算获取目标的清晰轮廓信息,再通过OpenCV中的函数对检测区域进行轮廓检测。通过对目标轮廓边界进行最小外界矩形的拟合,得到最小外接矩形,输出清晰完整的外接矩形框和矩形框的顶点坐标,并将4个点的坐标(0,0)、(1,1)、(2,2)、(3,3)代入式(1),求得旋转边角矩形的中心点(c,c),如图9所示。将计算得到的中心点坐标转换到初始输入图像中,即可显示其中心点位置,如图10所示。
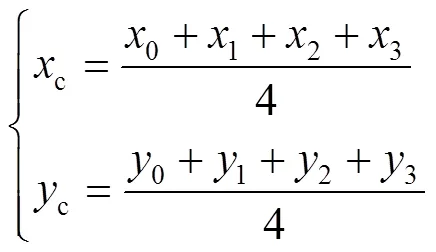
图5 文中采用的YOLOv5算法结构
Fig.5 Structure of YOLOv5 algorithm used

图6 检测结果
图7 ROI区域
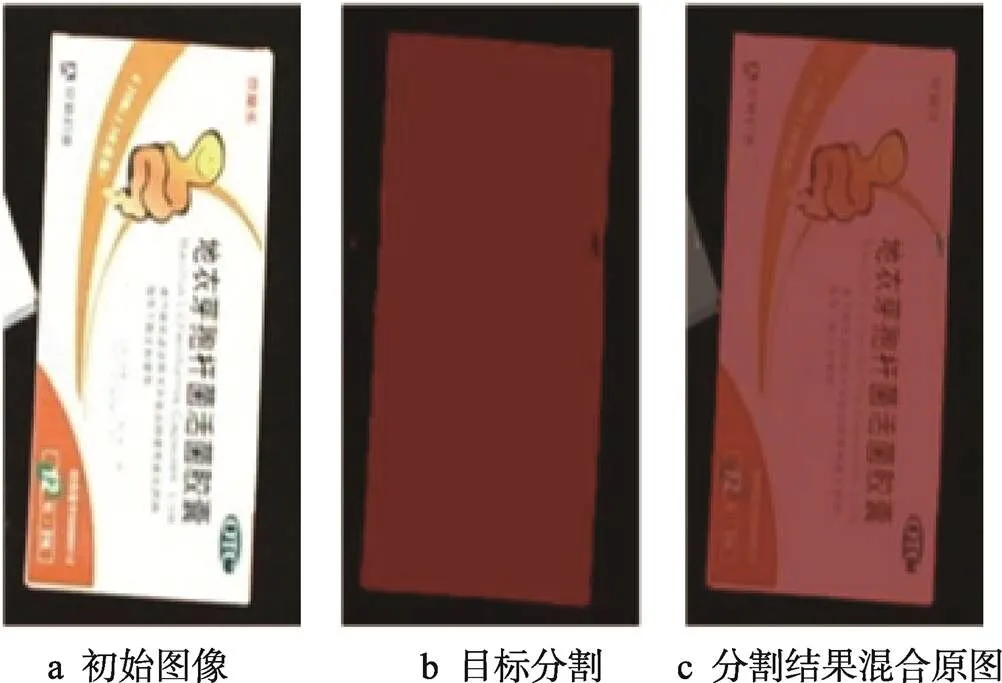
图8 图像分割结果

图9 矩形边缘及中心点效果

图10 目标中心效果
2.2 机械臂的手眼标定
为了实现从目标平面坐标到世界坐标系的转换,需要了解相机的成像过程,还需要完成相机标定和手眼标定。实现机械臂抓取过程是将像素坐标系转换到世界坐标系的过程,是摄像机成像的逆过程。根据相机成像原理,建立单相机像素坐标(,)与世界坐标(w,w,w)的转换模型,见式(2)。
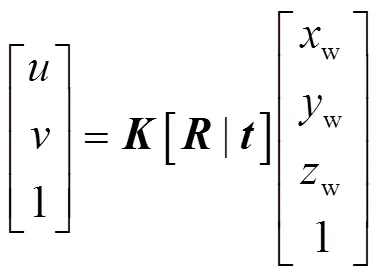
式中:为相机内参矩阵;为旋转矩阵;为平移矩阵。
2.2.1 手眼标定
机械臂手眼标定是将相机与机械臂末端执行器进行标定,通过相机来确定机械臂末端执行器的位姿。手眼系统可分为Eye-in-Hand(眼在手上)系统和Eye-to-Hand(眼在手外)系统。因为这里的检测区域是固定的,所以采用Eye-to-Hand系统,标定如图11所示。


可知,相机坐标系和机械臂基座坐标系保持不变,即保持不变。同理,机械臂末端坐标系和标定板坐标系保持不变,即保持不变。故可将式(3)变换为式(4)。
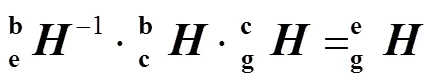

推导式(5),可得式(6),通过变形可得式(7)。
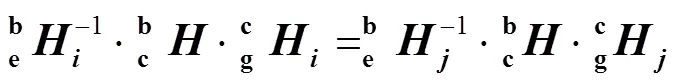
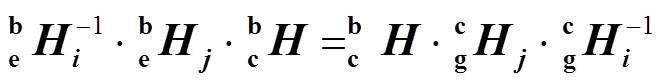
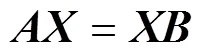
2.2.2 相机标定
对双目相机进行标定,获得相机对应的内外参数。采用张定友棋盘格标定法标定相机,棋盘格型号为GP200-5。得到相机对应的内外参数,如表2所示。
2.2.3 双目测距
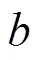
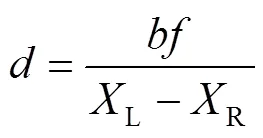
表2 双目相机参数
Tab.2 Binocular camera parameter

图12 双目立体视觉模型
3 Delta机械臂
3.1 Delta机械臂设计
文中执行系统Delta机器人的结构设计如图13所示,该系统由静平台、主动臂、从动臂、动平台等组成。将伺服电机固定在静平台上,通过电机输出轴连接主动臂,在主动臂、从动臂与动平台之间分别通过球形铰链连接。Delta机械臂的基本参数如表3所示。
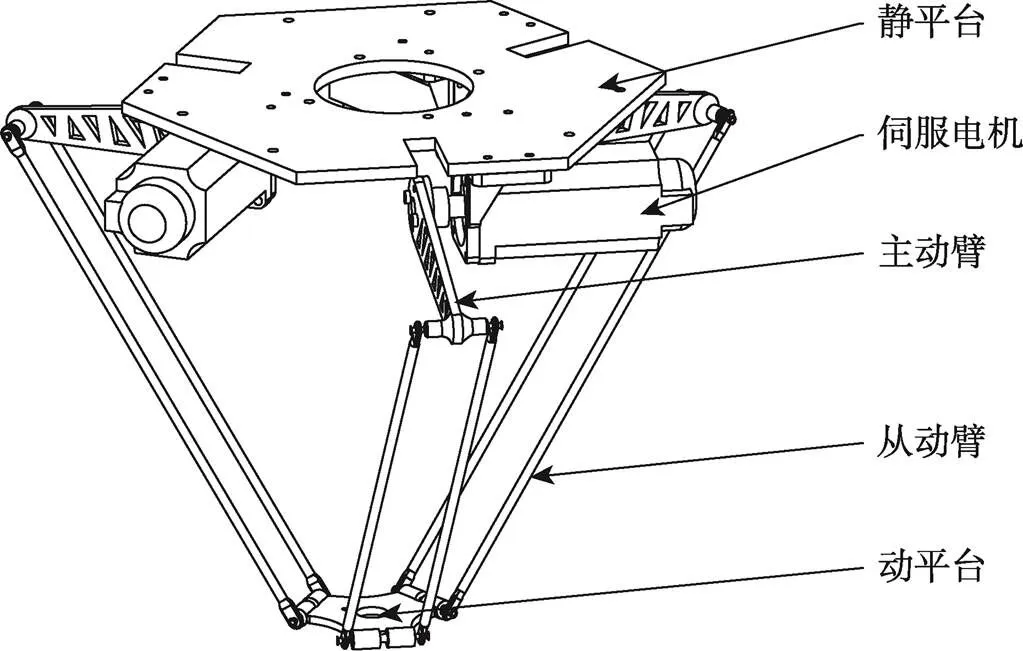
图13 Delta机器人的结构
表3 Delta机械臂参数

Tab.3 Delta robot arm parameter
3.2 Delta机械臂运动学分析
3.2.1 运动学反解
在已知目标药盒坐标(,,)的情况下,通过运动学反解求解3个主动臂需要转过的角度1、2、3,使机械臂调整至抓取姿态进行抓取,求解过程见式(10)~(12)。
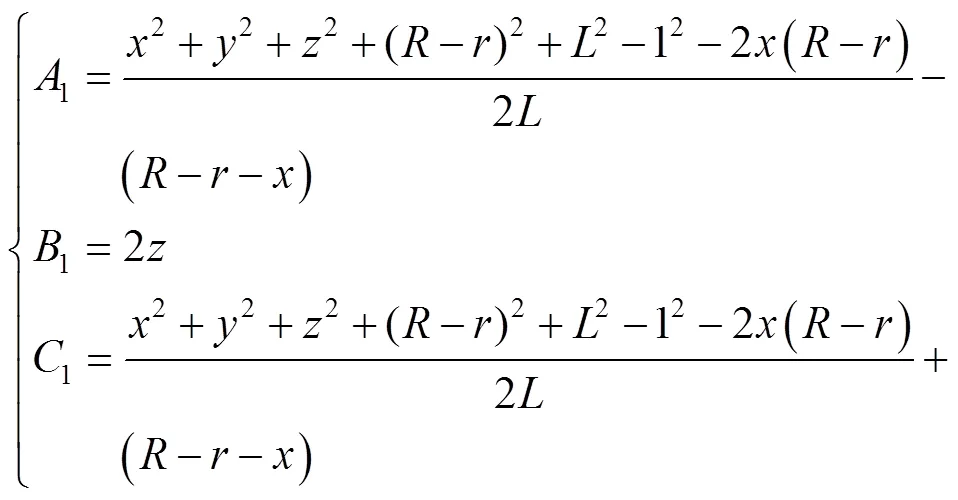
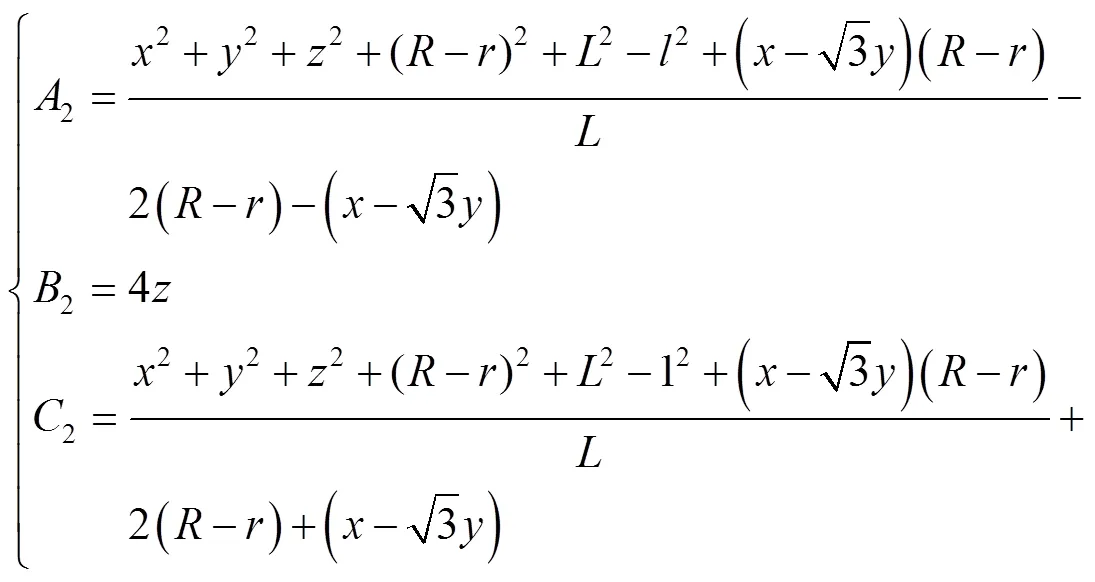
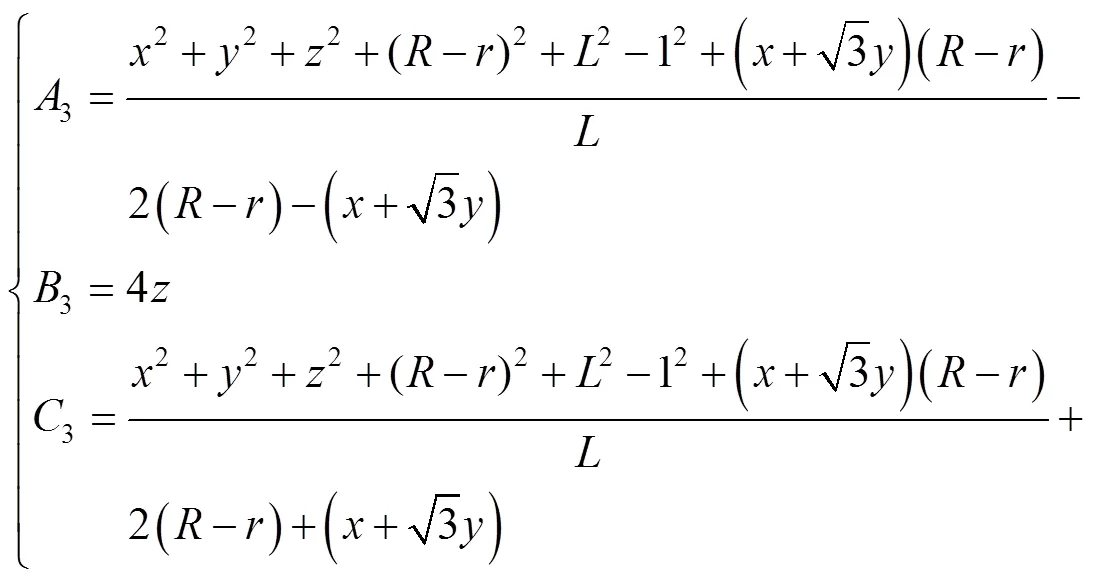
式中:、、、分别为主动臂长度、从动臂长度、静平台半径、动平台半径;(,,)为动平台相对于静平台中心的相对坐标。将式(10)、(11)、(12)中得到的A、B、C(=1, 2, 3)代入式(13),得到伺服电机转动的角度。
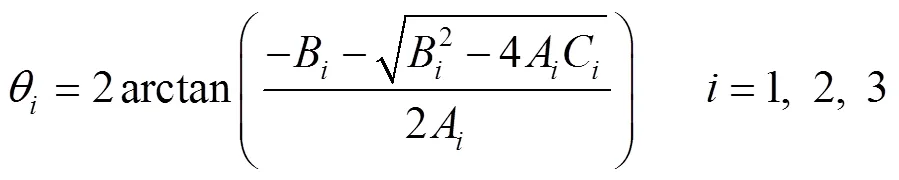
3.2.2 工作空间求解
通过逐点验算法,获得机械手末端的空间位置。模拟机械臂的工作空间,计算出机械臂的工作空间位置大约在–400≤≤–200、–200≤≤–200、–200≤≤200,如图14所示。
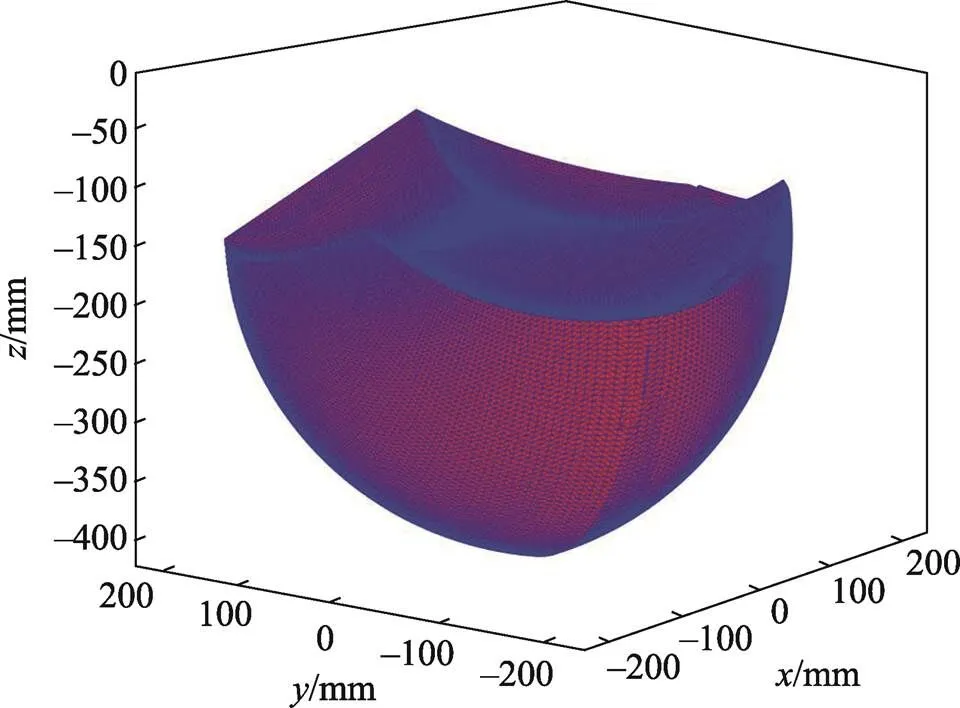
图14 Delta机械臂工作空间
4 实验
4.1 参数
装置实物设计与实验环境如图15所示。为了验证提出方法的有效性,将目标药盒放置在传送带上进行测试,测试设备为笔记本电脑(CPU: i5-7300HQ; GPU: RTX1050ti-4 G; RAM: 16 G, 2 400 MHz),相机采用双目摄像头(型号为PayCam c4008),PLC采用西门子s7-1200。将传送带上的目标物体运动至相机检测抓取区域,在传送带两端的对射光开关检测到物体时,传送带停止,通过相机对其拍照、识别、定位,并引导机械臂进行抓取,整个识别过程只需272.2 ms,如图16所示。
4.2 结果和分析
4.2.1 定位
在传送带不同位置放置不同姿态的单目标药盒进行抓取实验,对比有图像分割与无图像分割的抓取误差,实验结果见表4。
由上述实验结果可知,采用YOLO算法,药盒方向的定位误差最大值为3.9 mm,方向的定位误差最大值为4.3 mm,方向的定位误差最大值为2.9 mm;加入U-NET后,药盒方向的定位误差最大值为2.7 mm,方向的定位误差最大值为2.9 mm,方向的定位误差最大值为2.7 mm。由此可见,通过目标检测算法加入图像分割,能够提高药盒的定位精确度。
4.2.2 抓取结果对比分析
在30 mm/s的传送带上,通过有无添加U-NET的2种算法,抓取不同数量目标药盒的结果如表5所示。

图15 实验环境

图16 识别深度
表4 定位结果
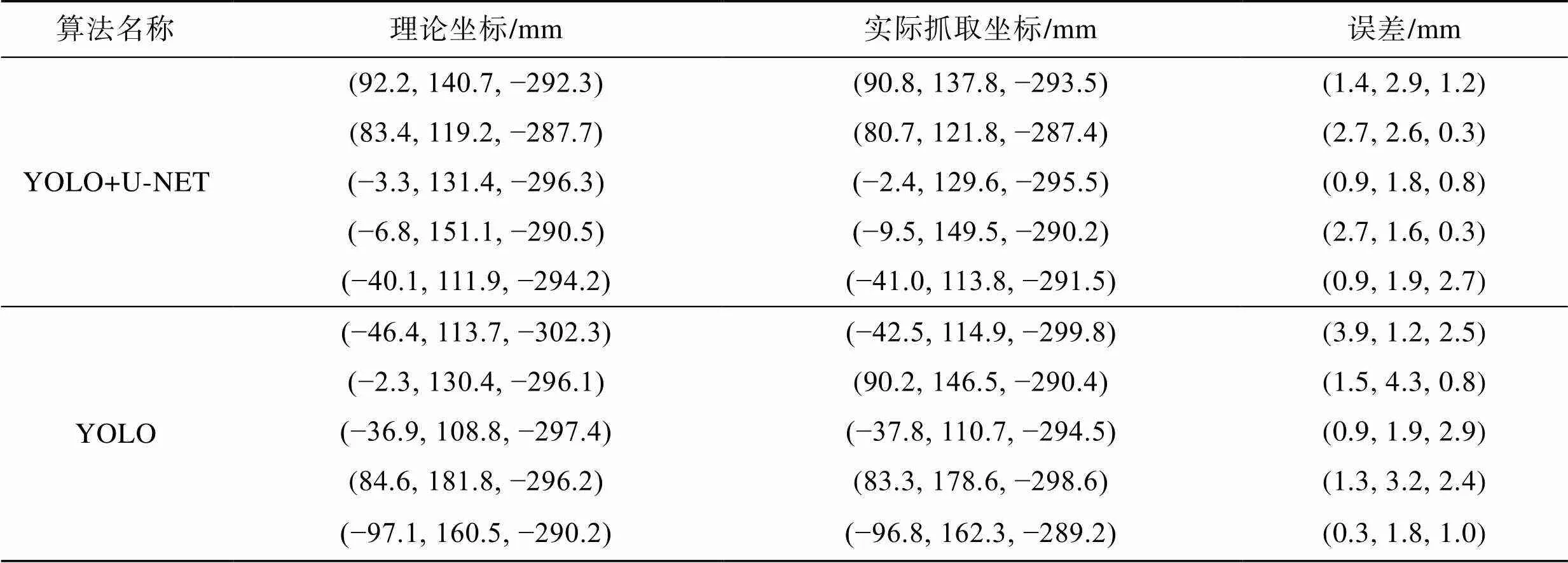
Tab.4 Positioning result
表5 抓取结果

Tab.5 Grasping result
添加U-NET后,在单目标情况下无漏抓,平均单个抓取时间为2.3 s。在视野中有多个目标物时,需要进行多次抓取,引入U-NET能够有效地提高抓取成功率。
5 结语
针对传统机器视觉对多目标及复杂背景下定位、抓取存在的问题,提出了一种深度学习目标检测与图像分割相结合的Delta机器人多目标药盒抓取系统。将YOLOv5与U-NET相结合,能够自动对目标进行识别和精确定位,相较于传统目标检测,加入图像分割后能够更加有效地定位到二维图像目标的位置信息,并通过立体匹配算出目标的深度信息。经实验验证,在多目标传送带上采用深度学习图像检测结合图像分割的抓取算法能够快速、有效地分割出多目标药盒和背景,有效地提高了抓取成功率。
实验中抓取的理论位置完全通过双目摄像头采集的图像计算得到,在实际应用中实际抓取位置会因机械臂振动、传送带转速等因素而出现偏差。基于目前摄像头精度不高、算法处理速度较慢等因素,当目标增加、传送带速度提升时抓取准确性会下降,后续将进一步对算法进行改进,从而提高其精度和处理速度,使其满足高速、高效的要求。同时,增加数据集的数量和多样性,使检测模型应对不同工作环境时都具有较高的检测精度。
[1] DOTOLI M, FAY A, MIŚKOWICZ M, et al. An Overview of Current Technologies and Emerging Trends in Factory Automation[J]. International Journal of Production Research, 2019, 57(15/16): 5047-5067.
[2] HUANG T Y, GU H R, NELSON B J. Increasingly Intelligent Micromachines[J]. Annual Review of Control, Robotics, and Autonomous Systems, 2022, 5: 279-310.
[3] BOURSIANIS A D, PAPADOPOULOU M S, DIAMANTOULAKIS P, et al. Internet of Things (IoT) and Agricultural Unmanned Aerial Vehicles (UAVs) in Smart Farming: A Comprehensive Review[J]. Internet of Things, 2022, 18: 100187.
[4] DANIELCZUK M, MAHLER J, CORREA C, et al. Linear Push Policies to Increase Grasp Access for Robot Bin Picking[C]// 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE). IEEE, 2018: 1249-1256.
[5] 李慧霞. 室内智能移动机器人规则物体识别与抓取[D]. 北京: 北京交通大学, 2016: 2-6.
LI H X. Rule Object Recognition and Grasping of Indoor Intelligent Mobile Robot[D]. Beijing: Beijing Jiaotong University, 2016: 2-6.
[6] NAM C, LEE S, LEE J, et al. A Software Architecture for Service Robots Manipulating Objects in Human Environments[J]. IEEE Access, 2008, 8: 117900-117920.
[7] MARKOVIC M, DOSEN S, POPOVIC D, et al. Sensor Fusion and Computer Vision for Context-Aware Control of a Multi Degree-of-Freedom Prosthesis[J]. Journal of Neural Engineering, 2015, 12(6): 066022.
[8] HASEGAWA H, SUZUKI Y, MING A G, et al. Robot Hand whose Fingertip Covered with Net-Shape Proximity Sensor-Moving Object Tracking Using Proximity Sensing[J]. Journal of Robotics and Mechatronics, 2011, 23(3): 328-337.
[9] SEPÚLVEDA D, FERNÁNDEZ R, NAVAS E, et al. Robotic Aubergine Harvesting Using Dual-Arm Manipulation[J]. IEEE Access, 1889, 8: 121889-121904.
[10] YU M C, LI G F, JIANG D, et al. Application of PSO-RBF Neural Network in Gesture Recognition of Continuous Surface EMG Signals[J]. Journal of Intelligent & Fuzzy Systems, 2020, 38(3): 2469-2480.
[11] LIU L, OUYANG W L, WANG X G, et al. Deep Learning for Generic Object Detection: A Survey[J]. International Journal of Computer Vision, 2020, 128(2): 261-318.
[12] ZHAO Z Q, ZHENG P, XU S T, et al. Object Detection with Deep Learning: A Review[J]. IEEE Transactions on Neural Networks and Learning Systems, 2019, 30(11): 3212-3232.
[13] MINAEE S, BOYKOV Y, PORIKLI F, et al. Image Segmentation Using Deep Learning: A Survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(7): 3523-3542.
[14] GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition ACM, 2014: 580–587.
[15] REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(6): 1137-1149.
[16] YAN B, FAN P, LEI X Y, et al. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5[J]. Remote Sensing, 2021, 13(9): 1619.
[17] IBTEHAZ N, RAHMAN M S. MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation[J]. Neural Networks, 2020, 121: 74-87.
Design of Multi-target Medicine Box Grasping System Based on YOLOv5 and U-NET
YUAN Bin, LANG Yujian, CHEN Lingpeng,LI Chen
(School of Mechanical and Energy Engineering, Zhejiang University of Science and Technology, Hangzhou 310023, China)
The work aims to propose a new deep learning grasping recognition and positioning system, in order to solve the problem of poor target positioning accuracy caused by the inaccuracy of multi-target and complex-target background segmentation in traditional machine vision robot grasping system. A hardware system composed of Delta robot arm, PC host computer and binocular camera was built to compare and study the YOLO series algorithms commonly used in industrial deployment. YOLO and U-NET were combined for target detection and segmentation. When the pixel regions belonging to the target and the background target were divided, the edge and center position information were calculated, the three-dimensional position was obtained by stereo vision technology and converted into the world coordinate system, and the robot arm was guided by the PC to complete the grasp. The system combining deep learning target detection and image segmentation had better target positioning accuracy than the algorithm without image segmentation in complex background and multi-target scenes. The target positioning and grasping method combining YOLOv5 and U-NET has high robustness and meets the grasping requirements of parallel robot arms. This method can be applied to other multi-degree-of-freedom robot arms and has good application value.
Delta robot arm; binocular vision; grasping method; YOLOv5; deep learning; U-NET
TP23;TB486+.2
A
1001-3563(2024)09-0141-09
10.19554/j.cnki.1001-3563.2024.09.018
2023-08-08
国家自然科学基金(62103340)
