基于高光谱成像技术的山楂产地判别研究
2024-05-12刘子健顾佳盛王游游王宏鹏白瑞斌
刘子健,顾佳盛,周 聪,王游游,杨 健,黄 俊,王宏鹏,*,白瑞斌,*
(1.浙江科技大学生物与化学工程学院,浙江杭州 310023;2.中国中医科学院中药资源中心道地药材品质保障与资源持续利用全国重点实验室,北京 100700;3.江西省道地药材质量评价研究中心,江西南昌 330000)
山楂(Crataegus pinnatifida)是蔷薇科山楂属植物,是典型的“药食同源”植物[1-3],在我国广泛分布于吉林、辽宁、河北、河南、山东、山西等地区。我国山楂年产量超过150 万吨,市场前景广阔,但由于不同产地山楂的各类营养成分含量存在差异[4-5],因此在价格上也有所区分,而当今山楂市场上产地混用、以次充好等现象屡见不鲜,使许多消费者上当受骗,这些现象严重破坏了市场秩序。因此,目前市场亟需一种能够快速准确对山楂进行产地溯源的方法。
目前对于各类农产品产地的溯源主要是依靠化学分析技术,如高效液相色谱技术(High Performance Liquid Chromatography,HPLC)[6]、气相-质谱联用技术(Gas Chromatography-Mass Spectrometry,GC-MS)[7]、超高效液相色谱(Ultra Performance Liquid Chromatography,UPLC)[8]等,这些方法通常在测量前需要对样本进行粉碎或匀浆处理,并使用有机溶剂对样本中的化学成分进行萃取,这一过程不但会损坏样本,同时有机溶剂还可能会对环境造成污染。与之相比,高光谱成像技术是一种基于非常多窄波段的影像数据技术,可以在样本完好的情况下对其进行定性或定量分析[9-10],具有快速、无损、无污染检测的特点。目前,基于高光谱成像技术对各类水果进行产地识别的研究已有很多:张立欣等[11]基于高光谱成像技术,结合多种机器学习算法实现对不同产地的苹果进行区分,其最佳识别模型为MSC-CARSSVM,预测集准确率达到100%;Sun 等[12]采集了不同产地水蜜桃的高光谱数据,并利用HPLC 分析解释样本的“高光谱指纹”,最终建立的分类器准确率达到99.3%。以上研究表明,高光谱成像技术在水果产地识别领域具有广阔的应用前景。然而,目前使用高光谱成像技术对山楂进行产地溯源却鲜有报道。
基于上述背景,为满足市场需求,本文旨在探究高光谱成像技术在山楂产地识别中的应用及不同采样方向对于模型分类性能的影响,利用高光谱成像系统(410~2500 nm),分别采集山楂样本果梗面、侧面及底面的光谱数据,结合多种机器学习算法分别建立产地识别模型,最终实现基于高光谱成像技术对山楂进行产地溯源的目的。
1 材料与方法
1.1 材料与仪器
山楂样品 山楂样品均采自2022 年10 月至12 月,其中山东省2 批、山西省3 批、辽宁省2 批、河北省3 批、河南省1 批。每个批次随机选择80~100 粒品相完好、大小相近的山楂,最终共采集900 粒样品。使用干布擦拭样品表面残留泥土,然后于4 ℃环境中冷藏保存,便于后续图像采集。
高光谱成像系统 高光谱成像系统由成像模块、卤钨灯、水平移动平台和Teflon 白板组成。其中成像模块包含两个镜头,分别为SN0605 VNIR、N3124 SWIR;卤钨灯 挪威Norsk Elektro Optikk公司;水平移动平台 立陶宛Standa translation stage 公司;Teflon 白板 中国双利合谱公司。
1.2 实验方法
1.2.1 高光谱数据采集 样本图像采集前,关闭环境灯光,打开卤钨灯并对高光谱成像系统进行预热。为探究摆放方式对山楂产地识别模型的影响,将山楂样本以果梗朝上(G)、侧面朝上(C)和底面朝上(D)三种方式摆放(图1),分别拍摄图像。采集图像时,将15~20 粒样本放置在水平移动平台上,在样本排列末端放置Teflon 白板,分别采集三个方向的图像数据,光谱仪镜头与样品的距离为25 cm,平台移动速度为1.5 mm/s,SN0605 VNIR 镜头的积分时间为3500 μs,帧时间为18000,光谱范围410~990 nm,共108 个波段;N3124 SWIR 镜头积分时间为4500 μs,帧时间46928,光谱范围950~2500 nm,共288 个波段,两个镜头的光谱分辨率均为6 nm。

图1 三种样本摆放方式Fig.1 Placement methods of three samples
为减小环境以及仪器对图像数据的影响,在图像采集完成后使用软件(HySpex RAD,Norsk Elektro Optikk,挪威)对原始光谱数据进行RAD 校正。随后进行黑白板校正以消除空气等外界因素对图像的影响并得到相对反射率,相对反射率计算公式如下:
式中:R 表示相对反射率;Rraw表示原始反射率;Rw表示白板反射率,即Teflon 白板反射率(反射率接近1);Rd表示黑板反射率(反射率接近0)。
校正完成后,使用软件ENVI 5.3 在图像中手动选取感兴趣区域(ROI),对于不同拍摄方向的样本图像,分别取其相应部位(即果梗面、侧面和底面)作为ROI,以ROI 平均反射率作为样本的光谱值。手动合并两个镜头得到的光谱数据,最终得到包含396个波段反射率的数据集。将样本按照7:3 的比例随机划分为训练集和预测集,用于后续分类建模。
1.2.2 主成分分析 主成分分析(Principal Components Analysis,PCA)是一种常用的聚类分析方法[13],其基本原理是通过线性变换的方式,将原始数据转换成一组线性无关的“特征”,而每个“特征”称为“主成分”,是一种通用的统计方法。本研究在得到样本光谱原始数据后,首先利用PCA 方法,对样本数据进行初步的可视化分析。
1.2.3 光谱数据预处理方法 受仪器和光散射等因素的影响,样本的原始光谱数据中存在很多噪声[14],会影响后续的建模分析,因此对原始光谱数据进行预处理可以有效提高后续建模的准确率[15]。本研究为消除噪声的影响,分别采用多元散射校正(Multiplicative Scatter Correction,MSC)、一阶导数(Derivative,D1)、SG 平滑(Savitzky-Golay,SG)和标准正态变量变换(Standard Normal Variate Transformation,SNV)四种方式对原始光谱数据进行预处理,再使用预处理后的数据进行分类建模。
1.2.4 特征波长提取方法 由于高光谱图像包含波段多,数据维度高,在分类建模时经常会面临Hughes 现象和维数灾难问题[16],而特征波长提取是一种常见的降维方式,可以有效降低模型复杂度,从而提升模型运算速度[17]。本研究在建立全波段分类模型后,为降低模型复杂度,分别采用连续投影算法(Successive Projections Algorithm,SPA)和竞争性自适应重加权采样算法(Competitive Adaptive Reweighted Sampling Algorithm,CARS)对原始光谱数据进行特征波长提取,然后基于特征波长数据建立分类模型,为山楂专属小型高光谱设备的开发提供参考。
1.2.5 分类模型的建立 对原始数据进行预处理或特征波长提取后,基于处理得到的数据,分别采用以下方法建立分类模型,并综合对比各项评估指标以筛选出最优模型。偏最小二乘判别分析(Partial Least Squares Discriminant Analysis,PLS-DA)是一种常见的线性判别模型。偏最小二乘法的原理是通过协方差极大化准则,分解自变量数据和因变量数据,建立相互对应的回归关系方程[18]。而PLS-DA 则是基于偏最小二乘法建立自变量和分类变量之间的回归模型,提取出与分类相关的特征变量,实现样本的类别预测[19]。本研究将特征变量的个数控制在10~15 个,以防止模型过拟合。
支持向量机(Support Vector Machine,SVM)的基本思想是将样本特征数据映射到n 维空间中,n 的大小取决于核函数和样本特征维数,然后在空间中构造最优的分类超平面[20]。SVM 在样本数量较少的情况下也能取得较好结果,具有优秀的泛化能力。核函数是支持向量机映射数据的重要手段[21],本研究使用径向基核函数的支持向量机进行分类建模,并通过网格搜索筛选最优模型参数(惩罚系数和核宽度)。
随机森林(Random Forests,RF)由预先设定数量的分类决策树组成。决策树可以表示样本属性与其特征值之间的映射关系,树中每一个节点表示对象属性的判断条件[22],随机森林通过对所有决策树的预测值进行平均或投票得到最终结果[23]。本研究通过网格搜索找出最佳的决策树数量和深度。
1.2.6 模型评估标准 模型建立完成后,分别通过以下指标筛选出最优模型:准确率(Accuracy)是分类问题最常用的评价指标;精确率(Precision)和召回率(Recall)则反映了模型对于正例的敏感程度,三个指标计算公式如下:
式中:TP 表示真阳性样本个数;FP 表示假阳性样本个数;TN 表示真阴性样本个数;FN 表示假阴性样本个数。
混淆矩阵可以直观呈现模型预测结果,通常由m 行m 列组成(m 取决于样本类别总数),每一列代表模型预测值,每一行则代表真实值。本研究通过建立混淆矩阵,综合对比模型指标,筛选出最优分类模型。
1.3 数据处理
高光谱图像的采集和校正分别使用仪器自带软件HySpex GROUND 和HySpex RAD 实现;样本反射率数据使用软件ENVI5.3 进行提取;PCA 分析、原始数据预处理、特征波长提取及分类模型的建立均基于Pycharm(Python 3.10)软件实现;光谱曲线绘图基于Origin 2023b 软件完成。
2 结果与分析
2.1 原始光谱曲线分析
在进行分类建模前,首先对各产区样本的光谱特征进行分析并探究部分特征峰的成因,不同产区样本的平均光谱曲线如图2 所示。对比发现不同产区山楂样品的平均反射率总体趋势相似;但是同产区山楂平均反射率在不同数据集(C、G 和D)上有所不同,这可以归因于样品表面信息的差异。另外,不同产区山楂样品的反射率数值存在一定差异,这些差异主要与样品的表面信息(如果皮、果斑颜色)和品质特性有关,其中山东产区的山楂在400~800 nm 波段下的反射率明显高于其他产区,区域特征较为明显,根据杨晓宁等[4]的研究报道:相比于其他产区,山东产区山楂的有机酸含量较高,这与上述现象相吻合。不同产区山楂在600~700 nm 处的吸收峰略有不同,但总体趋势相似;对于短波红外波段(short wave infrared,SWIR),各产地反射率曲线趋势相近,但在1000~1200 nm 处的吸收峰有所区分。对不同波段下的吸收峰进行分析,700~800 nm 处的吸收峰可归因于样本中的叶绿素[24];970 nm 附近的吸收峰可能是水中O-H 键的伸缩振动造成[25-26];1200 nm 附近的吸收峰可能与C-H 的第二拉伸泛音有关,可归因于碳水化合物和脂肪[27],总体而言,各产地样本所含化学成分种类相似,但具体含量存在差异,这与张悦等[28]报道的不同产地陈皮光谱曲线规律一致。
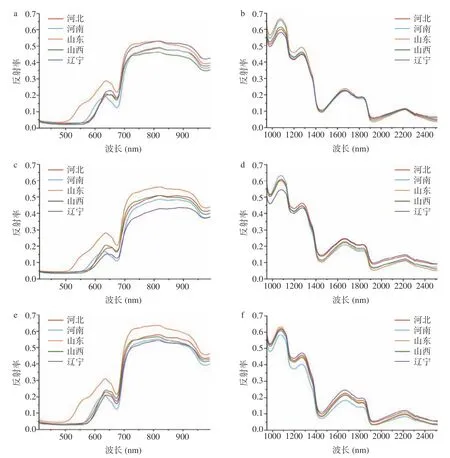
图2 不同产地在VNIR 和SWIR 波段下的平均反射率曲线Fig.2 Average reflectance curves of different origins in VNIR and SWIR bands
对比各数据集的平均反射率曲线(图2),发现G 数据集在700~1000 nm 处反射率略高于其他数据集,而此波段反射率与样品水分及叶绿素含量密切相关,因此推测山楂样本不同部位所含成分略有不同。山东与辽宁产区样品的平均反射率在三个数据集上都表现出了较大差异(山东产区样品反射率较高,而辽宁产区样品则偏低),说明两组样品差异明显。光谱平均反射率曲线虽然展现出样本的部分差异,但是仅凭这些特征很难对样本进行产地溯源。综上所述,有必要建立分类模型以挖掘样品光谱数据的潜在特征。
2.2 样本数据PCA 分析
使用主成分分析(PCA)对三个数据集进行初步的可视化分析,绘制的PCA 得分图见图3,保留了前两个主成分。初步分析发现,无监督模型分类效果并不好,三个数据集前两个主成分能解释的方差占比之和在75%左右。山东与辽宁产地的样本区分相对较好,这与原始光谱分析时得出的结论相符。对于大部分样本,使用无监督算法进行分类的效果并不理想,因此后续还需要采用PLS-DA、SVM 和RF 方法进行有监督分类建模。
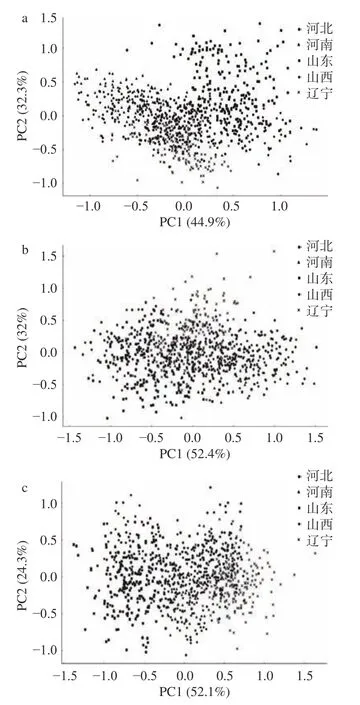
图3 原始数据PCA 得分图Fig.3 Raw data PCA score plot
2.3 基于全波段的建模分析
2.3.1 预处理及分类建模方法筛选 为筛选出最佳预处理和分类建模方法,分别采用4 种预处理方法和3 种分类建模方法建立模型,以样本底面数据为代表,各模型分类准确率见表1。对比四种预处理数据分类模型准确率可以发现,引入预处理方法之后,大部分模型的分类精度得到了提高,而D1 对于三种分类模型(PLS-DA、SVM 和RF)均为最优预处理方式。对比三种不同模型(PLS-DA、SVM 和RF)分类准确率,发现无论采用哪种预处理方式,采用RF 建立的分类模型虽然有较高的训练集准确率,但是预测集准确率一般;采用PLS-DA 和SVM 建立的分类模型训练集和预测集准确率良好,其中以SVM 模型分类准确率最高。综上所述,对于底面数据,D1 为最佳预处理方式,采用SVM 建立的分类模型分类准确率高,且具有优秀的稳定性和泛化能力。为进一步验证结论,分别使用C 和G 数据集进行建模对比,均呈现相同的规律,故判断D1 为最优预处理方式,SVM 为最佳分类建模算法,后续均采用D1-SVM(经D1 预处理后建立的SVM 模型)方式进行分类建模。

表1 不同预处理分类模型准确率Table 1 Accuracy of different preprocessing classification models
2.3.2 不同采样方式分类建模分析 本研究为探究不同采样方向对模型分类结果的影响,分别收集了样本侧面朝上(C)、果梗面朝上(G)和底面朝上(D)的高光谱图像。同时为模拟实际应用时随机拍摄到的高光谱数据,将三个数据集进行等比混合建立一个新数据集(R),使用四个数据集分别进行分类建模,建模方法均采用D1-SVM,综合对比各项指标筛选出最优模型。各模型分类准确率结果见表2。

表2 不同方向数据分类模型准确率Table 2 Accuracy rate of data classification model in different directions
对于使用R 数据集建立的分类模型,其准确率较高(100%,96.7%),根据图4 并由公式(3)和公式(4)计算得出,不同产区的精确率和召回率均超过90%。对比四个数据集模型的准确率可以发现,三种单面数据集(C、D 和G)模型准确率均高于使用R 数据集建立的模型,这说明对于山楂样本,在高光谱数据采集时保持样品方向一致可以有效提高分类模型准确率,这一规律与Mansuri 等[29]在玉米真菌感染检测中的发现一致。横向对比C、G 和D 三个模型,其中使用D 数据集建立的分类模型准确率最高,训练集和预测集准确率均达到100%,各产区样本全部预测正确。为避免过拟合现象,对D-D1-SVM 模型进行十折交叉验证,其平均准确率为98.8%。综上所述,D-D1-SVM 模型对于不同产区山楂的分类效果最优。
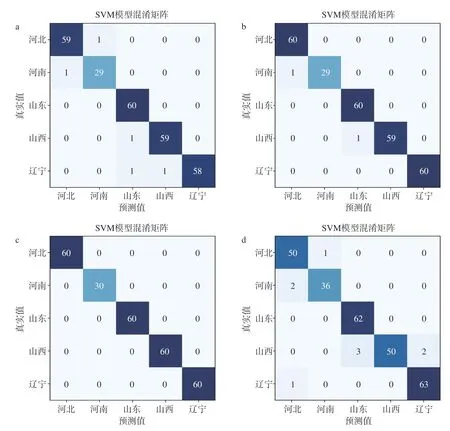
图4 全波段模型混淆矩阵Fig.4 Confusion matrix of full band model
2.4 基于特征波长的建模分析
2.4.1 特征波长的选择 为筛选出最佳特征提取方法,分别使用2 种提取方式提取4 个数据集的特征波长,最终得到的波长见表3 及图5。对比两种方法提取得到的特征波长数量发现,使用SPA 提取出的特征波长数量明显少于CARS,进一步观察特征波长分布(图5),发现使用SPA 提取出的特征波长分布均匀,各个波段均有涉及;而CARS 提取的特征波长分布较为集中,主要分布于750、2000 及2250 nm处的三个特征峰。观察各组特征波长重合的部分,发现750、1700 和2200 nm 附近的重合波长较多,说明这三处吸收峰可能包含不同产区样本的差异信息。对这些特征峰进行深入分析,700~800 nm 处的吸收峰来自于样品内部的叶绿素,也受样品的外部颜色特征影响;1700 nm 附近的吸收峰可归因于酰胺基团[30];2200 nm 处的吸收峰为C-H 和C-O 的联合吸收峰[31]。

表3 不同方法提取特征波长数量Table 3 Number of feature bands extracted by different methods
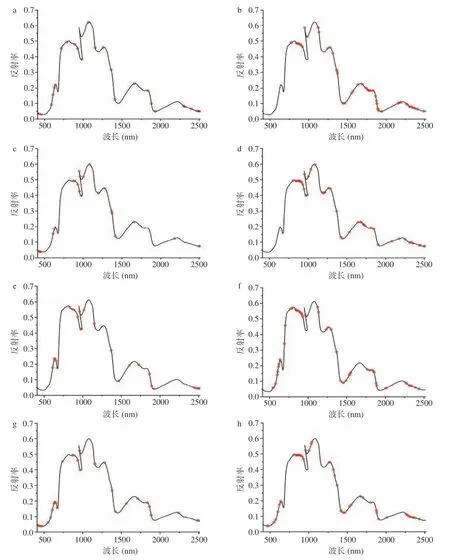
图5 不同数据集特征波长Fig.5 Feature bands of different datasets
2.4.2 特征波长建模分析 使用4 个数据集的特征波长分别建立SVM 模型,其准确率见表4。观察发现使用SPA 筛选特征波长建立的模型分类准确率优于CARS,这一现象在G 和D 数据集上尤为明显。综合考虑波长数量和模型准确率,SPA 筛选的波长数量更少,模型复杂度较低,且准确率更高。与本研究得到的结果不同,李涛等[32]在基于特征波段建立红景天分类模型时,发现CARS 为最佳特征波段提取方法,这说明对于不同的检测对象,应当选用不同的特征提取方法,而对于山楂样本,SPA 相比于CARS 特征波长提取效果更好。
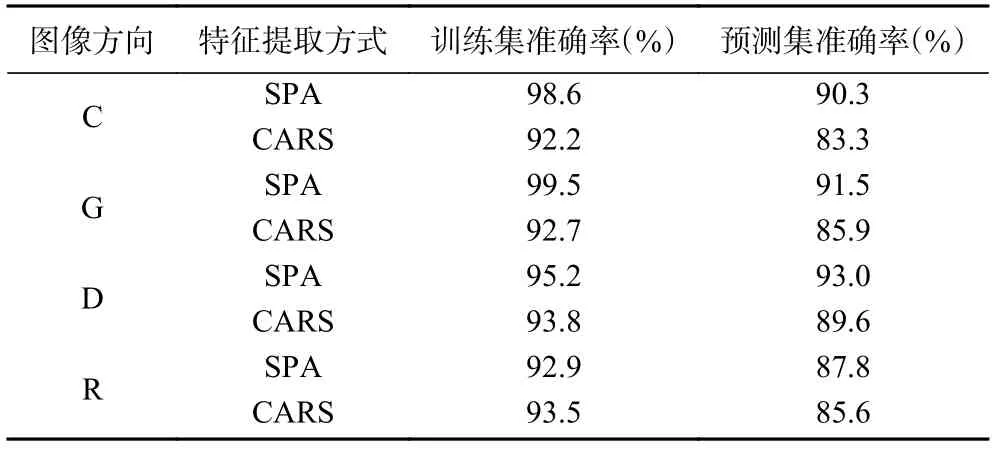
表4 特征波长建模准确率Table 4 Accuracy of feature band model
采用SPA 提取特征波长的分类模型预测集混淆矩阵见图6,对比四个数据集的准确率(表4)看出,R-SPA 模型预测集准确率为87.8%,根据其混淆矩阵(图6d)并由公式(3)和公式(4)计算得出,模型对于河北产区的精确率和召回率仅为79.2%和82.4%,分类能力一般。而C-SPA、G-SPA 和D-SPA 三个模型准确率均超过90%(分别为90.3%、91.5%和93%),这一现象再次证明在高光谱数据采集时,保持样品方向一致可以有效提高分类模型准确率。综合对比所有模型,D-SPA 模型拥有最高的分类准确率,训练集和预测集准确率分别为95.2%和93%,根据其混淆矩阵(图6c)并由公式(3)和公式(4)计算得出,模型对于各产区的精确率和召回率均超过90%(其中山东产区精确率和召回率最低,分别为91.6%和90%);且这一模型涉及的特征波长数量最少,在保证分类准确率的情况下拥有较低的模型复杂度。

图6 特征波长模型混淆矩阵Fig.6 Confusion matrix of feature band model
综上所述,采集高光谱数据时保持样品摆放方式一致有助于提高模型分类准确率。采用SPA 提取特征波长建立的产地分类模型复杂度较低且准确率良好。可以在波长数量有限的情况下对山楂产地进行判别,为后续山楂专属小型化高光谱设备的开发提供了方法参考。
综合考虑全波段模型和特征波长模型的分类结果,发现采集样本光谱数据时,样本的摆放方式会影响后续分类建模准确率。无论全波段还是特征波长模型,使用D 数据集建模分类效果都明显优于R 数据集(提高了约5%),相对于C 和G 数据集也有所提高。观察山楂样品的外部特征,发现样品底面存在萼片部位,结合宁素云等[33]的研究报道:山楂不同部位的化学成分含量存在差异,推测不同产地山楂其萼片部位各成分含量的差异相比于其他部位更大,进而导致分类特征更加明显。
3 结论
本研究基于高光谱成像技术建立了山楂产地识别模型。为探究样本拍摄方向对分类结果的影响,采集了山楂样本三个不同方向(C、G 和D)的光谱数据,分别使用偏最小二乘判别分析(PLS-DA)、支持向量机(SVM)和随机森林(RF)三种方法建立模型,通过对比模型分类准确率得到最优建模方法,最终成功区分了5 个不同省级产区的山楂,为山楂无损检测设备的开发提供了参考。经过对比筛选发现,一阶导数(D1)为最优预处理方式,SVM 为最优建模算法;使用连续投影算法(SPA)提取特征波长数量少且分类模型准确率高。全波段最优建模方法为D-D1-SVM,训练集和预测集准确率均达到100%;特征波长最优建模方法为D-SPA-SVM,训练集和预测集准确率分别为95.2%和93%。本研究证明基于高光谱成像技术对山楂产地进行溯源是可行的,为维护山楂市场秩序提供一种新的识别方式;同时验证高光谱图像采集方向会对检测结果产生影响,为后续开发山楂专属高光谱检测设备提供理论依据和参考。
© The Author(s) 2024.This is an Open Access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by-nc-nd/4.0/).
