基于动态常识推理与多维语义特征的幽默识别
2024-05-09吐妮可吐尔逊闵昶榮林鸿飞张冬瑜
吐妮可·吐尔逊,闵昶榮,林鸿飞,张冬瑜,杨 亮
(1. 大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2. 大连理工大学 软件学院,辽宁 大连 116620)
0 引言
幽默作为一种修辞手法,是人类交际中不可或缺的一部分,在使得人与人之间的沟通更加流畅的同时,营造了轻松愉悦的交流氛围。得益于社交媒体飞速发展所带来的海量文本数据,自然语言处理领域的文本幽默识别研究在近年来取得了长足进展。文本幽默识别的主要目标是通过计算方法来理解文本中的幽默表达并判断该文本是否为幽默。幽默识别不仅能够应用于文本生成、机器翻译以及隐喻识别等任务,还能够赋予机器理解幽默的能力,提升现实中人机交互的效果。因此,从文本中理解幽默产生的机制并识别幽默文本变得尤为重要。
从语言学与心理学的角度,主要存在三种观点来解释幽默的产生,分别是: 优越论[1]、宽慰论[2]以及乖讹论[3]。其中,优越论认为幽默是一种表达并强调自我价值与地位的方式,它强调通过取笑、讽刺或嘲笑他人来获取优越感;宽慰论认为幽默有助于缓解人们的压力和紧张情绪;乖讹论又称为不一致性理论,它的表达中通常会包含一些出人意料的不一致性,通过产生违背人们常识和期望的事物的感知,来引发人们的笑声和关注。基于上述理论,研究者们从多个角度提取文本中的幽默特征,同时通过设计不同结构的神经网络模型来学习幽默的深层次语义,基于此判断该文本是否为幽默。例如,Chauhan等人[4]认为幽默与情感和情绪密切相关,提出了利用Transformer和情绪感知嵌入(SE-Embedding)的多任务框架来进行幽默检测。Liu等人[5]基于“优越论”和“宽慰论”的观点,结合情感特征对语篇单元中的情感关系建模,证明了情感信息能更有效地解决对话幽默识别问题。Li等人[6]使用“乐观幽默类型”和“悲观幽默类型”的情感极性来标注数据集中“积极”和“消极”情绪类别,采用双向长短时记忆网络结合注意力网络的方法,捕捉俚语和微博表情符号在情感分析中的影响,为深入了解俚语和微博表情符号对中文情感分析提供了新视角。
从上述工作中可知,文本内蕴含的情感特征对于识别幽默表达十分重要,这些工作主要通过外部词典匹配的方式来捕捉文本内的情感特征。然而,本文发现在幽默表达中很多情绪往往是隐式表达的,如表1所示,其中第二个幽默样本表达了“悲伤”或者“愤怒”的情绪,但是该样本并没有包含直接表达情绪的词汇,而是通过短语“got fired”来表达,这种方式称为隐式情感表达。现存的幽默识别方法主要采用外部情感词典来捕捉文本内的情感信息。显然,这种方式无法有效识别出这些隐式情感表达,降低了模型识别文本幽默的能力。

表1 幽默样本以及包含的情绪信息
从认知角度,理解这些隐式情绪表达不仅需要结合上下文信息,还需要充分利用外部常识。尽管现有的预训练语言模型(PLM)能够高效地捕捉文本的上下文信息, 但是由于其是在大规模通用语料上训练,因此无法有效感知这些文本背后的隐式情绪。
为了解决这一问题,本文提出一种动态常识与多维语义特征驱动的幽默识别方法(Commonsense and Multi-dimensional Semantics Based Humor Detector,CMSOR)。该方法主要是利用外部常识,根据文本的上下文信息,动态地推断文本中的隐式情绪,并将其作为文本情绪特征的一部分,参与幽默识别。
具体地,该方法首先根据文本内容利用预训练常识推理工具COMET[7]根据上下文信息动态推断文本的内蕴情感信息,然后将文本内容与推断出的情感信息拼接融合,通过预训练语言模型BERT进一步将显式情感融入到文本语义当中,形成显式情感增强的文本表示。同时,利用外部词典WordNet[8]计算语义距离以及同义词数量,分别形成文本的不一致性特征以及模糊性特征。最后,将上述三种特征进行结合,形成多维幽默语义表示,输入到分类器中,得到幽默预测结果。
本文研究工作主要内容如下:
(1) 提出了一种动态常识驱动的幽默识别方法CMSOR,利用外部常识动态捕捉文本的隐式情感特征,同时利用外部词典建模模糊性与不一致性特征,从多个维度构建幽默语义,实现幽默识别。
(2) 在Pun of the Day、SemEval21以及ColBERT三个公开数据集上进行了实验,实验结果表明,本文所提出的CMSOR模型相比于现有方法在四项评价指标上有明显提升,证明了方法的有效性。
1 相关工作
由于幽默表达本身的复杂性,幽默识别在近些年来一直是一项极具挑战性的任务。早期的幽默识别方法主要是基于特征工程,将统计机器学习方法作为分类器,在幽默理论的基础上设计不同的幽默特征提取方案。这些人工提取的特征包括通用语言学特征以及面向幽默的文本特征。例如,Mihalcea和Strapparova[9]定义了头韵、反义词和成人俚语三种幽默特征,通过实验证明了他们在one-liner数据集中幽默识别的有效性。Mihalcea等人[10]将幽默文本分为“铺垫”和“笑点”两部分,通过计算两者的语义相关性进行幽默识别。Yang等人[11]深入探讨幽默潜在语义特征,构造了四种幽默特征,分别是语音特征、歧义特征、不一致性特征和情感特征。Morales 和Zhai[12]针对Yelp评论使用概率模型结合背景文本资源进行幽默识别。Cattle和Ma[13]利用单词关联的语义关联特征进行幽默识别。上述这些工作大多是利用统计或者匹配的方法来提取文本中的浅层幽默特征,无法对幽默的深层次潜在语义进行表示,从而限制了幽默识别的性能。
随着计算能力的提高以及社交媒体数据的增长,深度学习在不同领域被广泛用于辅助或替代传统的特征工程。与其他领域相比,深度学习在幽默识别任务中应用较晚。这些基于深度神经网络的幽默识别方法主要是利用预训练语言模型表示文本,然后设计不同结构的神经网络实现对于幽默特征的深层次提取。例如,Bertero等人[14]认为幽默情景剧是一种具有独特特点的喜剧形式,背景笑声可以视为观众对于搞笑场景的反应,自动标注这些笑声可以有效地识别笑点,便在此基础上使用长短时记忆网络(LSTM)对幽默情景剧中的对话进行建模,同时提取对话语义特征和声音特征来识别笑点。Cuza和Buenod等人[15]针对西班牙推文结合了语言特征和基于注意力的递归神经网络进行幽默识别。Blinov等人[16]收集大量笑话和趣味对话构造俄语数据集,并微调语言模型用于幽默识别。Kao 和Levy 等人[17]提出模糊性和独特性两个特征,使用语言模型识别幽默语句。Weller和Seppi[18]使用Transformer架构识别幽默。Hasan等人[19]使用循环神经网络进行多模态幽默识别。Diao等人[20]提出一种基于不一致性、模糊性、情感因素和语言学潜在语义结构的识别模型。Fan等人[21]基于Bi-GRU网络融合语音特征和歧义性特征进行幽默检测。Annamoradnejad和Zoghi[22]改进BERT模型在自创建的幽默数据集ColBERT上进行实验,证实了提出的模型能够有效地检测幽默。Zhang等人[23]利用卷积神经网络结合标签转移关系提出多任务学习模型识别幽默。Ren等人[24]结合幽默和双关语识别任务,提出一种基于注意力的多任务学习模型来进行幽默检测。Ren等人[25]提出一种基于注意力机制的神经网络来验证发音、句法与词法特征对于幽默识别任务的重要性。
与上述工作类似,本文同样考虑了情感特征在幽默表达中的重要作用。不同的是,本文针对幽默文本中隐式情感表达难以被词典有效识别的问题,采用动态常识推理,从文本中推断内蕴的隐式情感,并结合模糊特征与不一致特征,从多个维度对于文本的幽默语义进行刻画。
2 动态常识与多维语义特征驱动的幽默识别模型(CMSOR)
2.1 问题描述
2.2 CMSOR模型框架
本文所提出的基于动态常识推理与多维语义特征的幽默识别(CMSOR)模型如图1所示。该模型主要由三个部分组成: 情感特征提取层、语义特征提取层、模糊性特征提取层。其中,情感特征提取层主要是考虑到幽默表达中存在大量隐式情感表达,利用外部常识推断文本中的隐式情感表达,充分挖掘文本中的情感特征;语义特征提取层主要是通过计算句子内部词对之间的语义关联来学习文本内部的不一致性特征;模糊性特征提取层主要是利用外部词典捕捉文本中存在歧义性的词汇,通过循环神经网络学习其模糊性特征。最后,将幽默的三个维度特征进行拼接,通过分类器获得文本的幽默预测结果。

图1 CMSOR模型框架图
2.3 外部常识驱动的情感特征提取
幽默表达与情感有着极大的关联。一些带有强烈感情色彩的词会增加受众对于作者表述的认同感,使得读者的情绪被更为充分地调动,从而达到幽默的效果[26]。然而幽默内存在的隐式情感表达使得通过外部词典捕捉文本情感特征变得十分困难。为了解决这一问题,本文采用预训练常识推理模块COMET根据上下文信息动态推断文本内所蕴含的情感特征。COMET作为一种常识推理工具,在给定上下文的情况下,能够根据不同的事件关系来推理相应的结果。COMET是以Transformer为基础架构,并在ATOMIC[27]数据集上训练得到。该数据集共提供23种事件关系,而本文主要采用[xReact]这一关系。它的功能是根据上下文推断句子中主语的内心情绪,并以文本形式输出。
具体地,以幽默文本序列x=(w1,w2,…,wm)作为输入,COMET能够根据x推理出说话者可能的内心情绪。在这里,本文选择概率最高的前l个可能结果,并得到说话者情绪候选集K={k1,k2,…,kl}。其中,ki表示第i个情绪词。然后,将初始文本序列x与情绪候选集拼接,得到显式情绪增强的幽默文本序列,如式(1)所示。
xe={w1,w2,…,wm,[SEP],k1,k2,…,kl}
(1)
其中,[SEP]为句子分割符。本文采用BERT对xe进行上下文编码。具体计算如式(2)所示。
其中,ve为编码后得到的句子表示,W0为BERT的可学习参数。
一方面,BERT能够有效地捕捉上下文信息,将幽默文本x中的单词wi与情绪候选集K中的情绪单词ki从语义层面上关联起来,进而有效捕捉文本内的情绪特征。另一方面,BERT内的多头注意力机制能够为文本中的每个单词赋予不同的权重,通过降低与幽默文本无关的情绪词的权重,来避免引入过多噪声信息。在得到上下文编码后,采用双向长短时记忆神经网络(Bi-LSTM)对于上下文语义信息进行进一步学习,最后通过注意力机制获取潜在情感特征ze,其计算公式如式(3)、式(4)所示。
其中,ue∈R1×p为输出的幽默文本表示,p为Bi-LSTM的隐藏层维度。W1为Bi-LSTM的可学习参数,W2为注意力机制的可学习参数。
2.4 基于语义距离的不一致性特征提取
一些语言学研究[28]认为幽默的本质在于表现出两种不一致的思想或概念。同样的,Raskin等人[29]也指出幽默的产生往往借助于一些有意义但含义不同或相反的词语或短语的组合,通过制造错觉或矛盾感而达到幽默的效果。例如,
例1I am deeply aware that I am a superficial person.
例1中“deeply”可以翻译成“深刻”,“superficial”可以翻译成“肤浅”。这个句子的中文翻译是“我深刻地意识到我是个肤浅的人”,其中“深刻”和“肤浅”有相反的含义,从而达到幽默效果。上述例子也可以说明幽默中的不一致特征具有隐晦和抽象的特点,并与深层次语义关联紧密。从听者角度,需要具有背景知识才能够推断出词汇或者短语之间的隐含关系。因此,需要引入外部知识更好地捕捉幽默的不一致性特征。
具体地,给定一个输入文本序列x=(w1,w2,…,wm),本文首先通过预训练语言模型将文本序列中的每个词进行向量化表示并得到V=(v1,v2,…,vm)∈Rm×d。 其中d表示词向量维度。然后,针对于x中的每个词wi,利用WordNet获取其词义特征,并得到H=(h1,h2,…,hm)∈Rm×d′,d′表示其词义特征维度。将词义信息H与深层次语义信息V进行拼接,得到V′=(v′1,v′2,…,v′m)∈Rm×(d+d′)。 为了计算词级语义不一致性,首先采用两个平行语义编码器对文本表示V′进行压缩。编码器由全连接神经网络实现,具体计算如式(5)、式(6)所示。

2.5 基于同义词的模糊性特征提取
Reyes和Rosso[30]认为幽默是一个单词的多个含义令句子产生不同的理解,借助语义和语境的歧义来产生的。Miller和Gurevych[31]指出,模糊性是幽默的关键因素,是幽默中常见的语言现象。随之Reyes等人[32]得出结论: 幽默的表达往往伴随着语义的模棱两可。如下例:
例2Why did the tomato turn red? Because it saw the salad dressing!
例3My trip to the grand canyon cost a hole lot of money and gorged my bank account butte it was worth it.
例2中“salad”一词既可以被解释为用于沙拉的一种酱汁,也可以表示“穿衣服”的意思,从而导致句子产生两种截然不同的意义来产生幽默效果。例3中,首先“hole”的字面含义为“洞”,但在口语中也可表示为“大量”或“很多”,其次“butte”的字面含义为“丘陵”,但在句中被用作双关词,与“but”相呼应。句子通过“hole”和“butte”的双关含义,使得例3既可描述为旅行花费了大量的钱,也可暗示这个花销像一个巨大的洞一样,吞噬了大量的资金。结合上述例子,幽默通过词汇的多个含义来创造幽默,达到幽默效果。由此可见,模糊性是判断文字是否幽默的重要因素之一,是幽默文本的重要组成部分。综上所述,本文为提高幽默识别的性能,利用外部资源WordNet捕获句子中的歧义词。
在WordNet数据库中,名词、动词、形容词和副词都被存储为同义词集合的形式,每一个同义词集合被称为一个Synset,包含一组具有相似意义的单词。不同的Synset之间可以通过语义关系和词性关系等边相连接,这些关系可以帮助人们理解这些单词之间的联系和含义。
针对于输入文本序列x=(w1,w2,…,wm),首先利用WordNet中的同义词集合Synset计算每个单词wi的同义集数量n。 本文认为单词的同义词数量越多,会导致句子理解存在很多歧义,从而模糊性程度就会增加,因此本文将同义集数量最多的词汇设置为最容易出现歧义的词汇,停用词在句子中不承载实际的语义信息,因此可以被移除或忽略,从同义词集合和同义词数量中删除停用词汇及其个数。针对于同义词集的数量,定义如式(7)所示的规则来描述每个词的模糊程度。
由式(7)得到x的模糊程度序列c=(c1,c2,…,cm),其中,0表示模糊程度最低,4表示模糊程度最高,对于文本中的停用词,其模糊程度统一设定为0。然后,将该序列c进行one-hot表示,得到模糊程度矩阵Vc=[c1,c2,…,cm]∈Rm×d。将Vc与文本表示V=[v1,v2,…,vm]∈Rm×d通过拼接方式进行融合,并利用模糊特征编码器Gfuz学习包含模糊特征的文本表示,该编码器由Bi-LSTM及注意力机制实现。其计算如式(8)所示。
其中,zf为模糊性特征表示,W5为可学习参数,⊕表示拼接操作。
2.6 幽默标签预测以及损失函数
在获得幽默文本的情感特征ze、不一致性特征zs=MaxPooling(S)以及模糊性特征zf之后,将三种特征通过拼接方式进行融合,得到多维度融合幽默特征z=ze⊕zs⊕zf。 通过注意力机制进一步学习三种特征之间的内在关联,具体计算如式(9)所示。
其中,W6表示注意力机制层的可学习参数。在此基础上,将其输入到由全连接层构成的幽默分类器fh中,获得文本x的幽默标签预测。具体计算如式(10)所示。
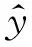
最后,CMSOR在分类中采用交叉熵(Cross Entropy)作为损失函数。其损失计算如式(11)所示。
3 实验与分析
本节首先详细描述数据集、实验数据和实验设置,然后对比了基线方法和本文提出的CMSOR方法的幽默识别性能,最后结合对比实验以及消融实验结果来讨论模型的性能,并验证本文模型方法的有效性。
3.1 数据集
为了证明方法的有效性,本文实验中使用了三个公开的数据集,其统计信息如表2所示。具体介绍如下:

表2 数据集统计信息
PunofTheDay[33]: 该数据集的构建是Yang等人通过在互联网上收集幽默文本而完成的,包括了各种类型的幽默,如双关语、笑话、俏皮话等等。为确保数据的准确性和可靠性,通过人工标注和质量控制的方式对数据进行了筛选和整理。该数据集目前广泛使用于幽默识别中。
SemEval 2021 Task7-1a[34]: 该任务是一项国际评测,Task7子任务一是识别文本是否为幽默文本,该数据集可以用来进行幽默检测,本文利用Task7子任务一涉及数据来判断是否为幽默文本。
ColBERT[22]: 该数据集是一个大规模的幽默数据集,它包含了20万个来自网络的英文幽默文本,其中10万正样本由Reddite收集得到,另外10万负样本来源于新闻头条。
3.2 实验数据与设置
实验在Python 3.7和Keras 2.2.4环境下进行。对于本文提出的CMSOR模型,其中常识知识层本文采用12层的BERT-base-cased(1)https://huggingface.co/bert-base-cased作为预训练语言模型编码,其中向量维度为768,共110M个参数;语义特征提取以及模糊性特征提取采用GloVe,维度为100,词嵌入在训练的过程中固定,不在词汇表中出现的单词使用(-0.01,0.01)上的平均分布随机初始化;使用WordNet获取单词同义词集合;Bi-LSTM的神经元数量为128;Dropout为0.3;Batch大小为64;模型采用Adam Optimzation优化算法更新模型参数;采用了学习率衰减和早停机制以防止过拟合现象。此外,采用准确度(Accuracy)、精确率(Precision)、召回率(Recall)和F1值(F1-Score)作为实验结果的评价指标,并且所有实验均进行五倍交叉验证,取平均值作为实验结果。
3.3 基线方法
本文采用如下基线模型进行对比:
(1) LSTM[35]: 通过经典LSTM模型提取幽默特征进行幽默识别。
(2) Bi-LSTM: 利用可以更好地捕捉双向语义依赖关系的Bi-LSTM模型。
(3) Bi-LSTM+ATT: 使用Bi-LSTM模型结合注意力机制提取幽默特征进行幽默识别。
(4) CNN: 采用卷积神经网络(Convolutional Neural Network, CNN)获取幽默语句的潜在语义及模糊性特征进行幽默识别。
(5) BERT[36]: 使用预训练BERT模型在幽默数据集上进行微调。
(6) IEANN[21]: 通过结合内部及外部注意力神经网络构建两种注意力机制,以捕捉幽默文本中的不一致性和模糊性特征。
(7) ABML[24]: 通过联合幽默和双关语检测的多任务学习模型进行幽默识别。
(8) ANPLS[25]: 通过结合发音、词汇和句法幽默特征的注意力网络,提取幽默特征进行幽默识别。
3.4 对比实验
实验结果如表3所示,对实验结果进行具体分析可以得到如下结论:

表3 对比实验结果
(1) 本文提出的CMSOR方法在三个数据集上均取得了最好的结果,在三个数据集上的F1值相比于现存的最优结果分别提升了0.25%、0.31%、0.67%,证明了从情感、不一致性以及模糊性三个维度构建幽默语义并应用于幽默识别是有效的。
(2) 从表中可以看出,相比于基于CNN的幽默识别方法,基于Transformer的方法(BERT以及CMSOR)在四项评价指标上有明显性能提升,这说明Transformer能够通过全局注意力机制更好地捕捉幽默文本的上下文信息。
(3) CMSOR方法能够通过深度神经网络结构,在外部知识驱动下,自动构建幽默特征,相比于BERT在Pun of The Day数据集上取得了明显的性能提升(F1值提高2.79%)。这也验证了深度学习模型结合外部知识能够在幽默理论约束下学习到幽默相关特征。
(4) 相比于基于RNN的方法, 基于CNN的方法在Pun of The Day和SemEval数据集上F1值取得了明显的提升,如在SemEval数据集上, CNN相比于BI-LSTM+ATT在F1值提高了1.18%。这说明幽默表达可能与局部语义信息(Ngram)有着一定的关联。
(5) 与采用情感词典捕捉文本内部情感信息的IEANN相比,本文提出的CMSOR方法在Pun of The Day、SemEval以及ColBERT数据集上F1值分别提升了1.35%、1.32%和1.6%。这说明利用动态外部常识信息能够更准确地推断文本内部情感。
(6) ABML模型在Pun of The Day和SemEval数据集上ACC值高于IEANN和ANPLS。ACC值达到最高。ABML模型不仅考虑双关语的特点,还考虑了幽默和双关语之间共同的潜在语义信息。这意味着模型能够更好地理解双关语的双重含义,并将其与幽默特征联系起来,有效地增强模型对幽默的识别能力。
3.5 消融实验
为了验证CMSOR中不同组件的有效性,本文在三个数据集上进行消融实验,并设计以下模型变体: CMSOR-C表示仅使用情感特征;CMSOR-I表示仅使用语义不一致性特征;CMSOR-A表示仅使用模糊性特征;CMSOR-CI表示融合情感特征和语义不一致性特征;CMSOR-CA表示融合情感特征和模糊性特征;CMSOR-IA表示融合语义不一致性特征和模糊性特征。
三个数据集上的消融实验结果如表4所示。从表中可以得到如下结论:

表4 消融实验结果
(1) 当分别移除情感特征(CMSOR-IA)、模糊特征(CMSOR-CI)以及不一致性特征(CMSOR-CA)之后,模型在SemEval 2021 Task7-1a数据集上的四项指标均有明显下降(F1值分别下降3.26%,1.82%,1.45%),这说明三种情感特征在幽默识别任务中的有效性。然而,在Pun of The Day数据集上,当移除情感特征后,模型在召回率R上有了提升,这可能是因为BERT在学习情感增强的文本表示时,将错误的情绪信息融入到语义表示当中,所以导致该指标下降。而在ColBERT数据集上,精确率P得到了提升,这可能是因为情感特征与其他特征存在冗余,即它们所携带的信息在一定程度上是重叠的。当移除情感特征时,模型可能更加依赖于其他更为关键的特征,从而提高了精确率。
(2) 当只保留模糊性特征的时候,模型在Pun of The Day 和ColBERT数据集上的表现相比于CMSOR下降得最少,在Pun of The Day数据集上精确率P得到了提升,这说明模糊性特征在构建幽默语义的过程中相比于情感特征以及不一致性特征更加重要。然而,对于SemEval 2021 Task7-1a数据集,情感特征更加重要。
4 参数分析
图2展示了不用数量的常识信息对于模型性能的影响。从图中可以观察到,在Pun of The Day和ColBERT数据集上,当知识数量为1时,模型效果最差。随着候选知识数量的不断增加,模型的表现逐渐提升,并且在l=5时取得最好的结果。这说明有效处理隐式情感表达对于CMSOR建模幽默语义具有重要作用,并且显式情感信息的增加会提升模型对于文本情感特征的捕捉效果。对于SemEval 2021 Task7-1a数据集而言,变化趋势与其他两个数据集不同。随着知识数量的增加,模型表现在性能略微提升之后,呈现出下降趋势,并且在l=4时取得最差的结果,但是l=5时结果最优。这可能是因为当将知识数量增加到5时,一些样本的隐式情感表达才能够被COMET有效推理出来。

图2 不同数量的知识候选对模型性能的影响
5 总结
针对于现有幽默识别方法没有充分捕捉文本内部的情感特征,忽略了幽默文本中的隐式情感表达这一问题,本文提出一种动态常识与多维语义特征驱动的幽默识别方法CMSOR。该方法首先利用外部常识信息从文本中动态推理出说话者的隐式情感表达,然后引入外部词典WordNet计算文本内部词级语义距离,进而捕捉不一致性,同时计算文本的模糊性特征。最后,根据上述三个特征维度构建幽默语义,实现幽默识别。本文在三个公开数据集上进行实验,结果表明本文所提方法 CMSOR相比于当前基准模型性能有明显提升。未来,本文将尝试把常识信息应用到幽默生成、多模态幽默识别等任务当中。
