古汉语通假字资源库的构建及应用研究
2024-05-09王兆基张诗睿胡韧奋张学涛
王兆基,张诗睿,胡韧奋,张学涛
(北京师范大学 国际中文教育学院,北京 100875)
0 引言
与现代汉语及其他语种不同的是,古籍文本中的文字通假较为常见,这为准确理解文意造成了困难。具体来说,通假指的是古人本有其字而不用,反而借用一个音同或音近字的现象,其中,被借用的字称作通假字,被代替的字称为正字或本字[1-2]。例如,在“庄公寤生,惊姜氏。”(出自《左传》)中,“寤”为通假字,所通正字为“牾”,“牾生”即逆生,表示难产。
通假现象不仅常见于传世古籍,在出土文献中也有较高频率。据钱玄等人[3]统计,现存《老子》(据唐傅奕校《道德经古本篇》) 约 5 500余字,其中用通假字30多个,而马王堆帛书《老子》( 乙本) 使用通假字320个,占全书的6%。整理古籍时,通假字识别对于准确理解文意来说十分重要,如王引之在《经义述闻·经文假借》中所述, “学者改本字读之,则怡然理顺;依借字解之,则以文害辞。”除了专业学者整理古籍时需要释读通假字,在中学文言文教学中,通假字也是一项重点和难点,掌握文言文常见通假字的用法是文言文阅读的基本功[4]。值得一提的是,对于汉语史研究来说,通假字与被通假字之间的音同或音近关系可以为汉语古音和语音史研究提供宝贵的参考资料[5-6];同时,字与字之间的通假关系亦有助于厘清词汇形式和词义演变的脉络,从而服务于词汇发展变化和词汇语义研究[7]。可以说,无论是服务于通假字识别,还是汉语史研究,高质量的通假字资源库都必不可少。柳建钰和周晓文[8]从辅助校勘需求出发,提出了构建通假字资源库的设想,拟基于各类通假字字典搜集整理通假字表,预计收录字头6 000个左右,涵盖传世文献和出土文献的通假字。然而,目前除了字典和辞书以外,通假字相关数据资源的建设仍十分罕见。
近年来,伴随古籍整理利用的转型升级,古汉语信息处理资源建设和算法研究受到了越来越多的关注,涉及任务包括句读标点、分词和词性标注、词义消歧、命名实体识别、自动校勘和文本生成等[9-15]。需要指出的是,在古汉语信息处理研究中,通假字识别是词义注释、文本校勘和文白翻译等技术的基础,目前学界尚无针对通假字自动识别的研究。当下,即使ChatGPT、GPT-4等大模型具备极强的自然语言理解能力,其处理包含通假字的文本时仍会“以文害辞”,如表1所示。因此,对于古汉语信息处理来说,通假字资源库的建设及自动识别技术研究具有其现实价值和迫切性。

表1 基于GPT-4的文白翻译实例
为了更好地辅助通假字的人工判别和机器处理方法等,本文首先构建了一个涵盖标注语料库、知识库和评测数据集的通假字资源库。其中,标注语料库收录了11 000余条包含通假字用例标注的语料,知识库以汉字为节点,通假关系为边,从字音、字形、字义多个角度对通假字与正字的属性进行加工,共包含4 185个字节点、7 700对通假字关联信息、650对通假字之间的形声关系信息;评测数据集分为基础版和拓展版,支持通假字检测和正字识别两个子任务的评测,收录评测数据19 678条。在此基础上,本文搭建基线模型,开展了通假字检测和正字识别实验,并探讨了资源库在古籍整理、人文研究和文言文教学中的应用。
1 通假字资源库构建
为了让资源库更好地服务于与通假字有关的文史研究和自动识别算法研发,本文设计并构建了三个开源资源库,均以JSON格式发布(1)数据下载地址: github.com/frederick-wang/tongjiazi-resources,包括通假字标注语料库、通假字知识库与通假字识别评测集。
1.1 通假字标注语料库
目前,学界尚无专门标注通假字的文言文语料库,包含通假字的句篇信息主要见于各类辞书,其中也包括专门的通假字字典,如高亨《会典》收录了传世文献材料中的通假字用法,《简帛古书通假字大系》侧重于依据战国秦汉出土简帛文献。考虑到与通假字相关的辞书存在应用场景区别,为兼顾古汉语信息处理、文史研究与文言文教学的一般性需求,本文选择以《汉语大词典》为数据源,构建通假字标注语料库。该库可为通假字相关研究和应用提供高质量的基础性数据,亦可结合具体需求进行筛选、优化和扩充。
《汉语大词典》所收条目分为单字条目与多字条目。多字条目按“以字带词”的原则,列于单字条目之下。一个单字有两个以上字头的,在字头旁以阿拉伯数字标注序号。字头下依次标注现代音与古音,其中,现代音用汉语拼音字母标注,古音用反切标注。释义时,通假义用“通‘×’”和“‘×’的被通假字”表示。据此,我们以《汉语大词典》的标注为准,采集通假现象涉及的释义及例句,例如,在《汉语大词典》中,字头“耗3”的内容如表2所示,该字可通“眊1”,表示“昏乱不明”,词典收录了来自《荀子·修身》与《汉书·景帝纪》的两则包含通假字的例句。

表2 通假字标注语料库语料原文示例

表3 通假字标注语料库语料示例
经自动提取和人工校对,我们从《汉语大词典》中采集了较大规模的通假字属性及用例数据,在此基础上构建了高质量的通假字标注语料库,共包含11 000余句繁体中文语料,覆盖2 479个通假字。其中,用例最多的为“辨”,存在通“辯”“變”“班”“般”等字的126条用例,同时,也有不少通假字的例句数量较少,例如,有833个通假字仅包含1条用例语料。
如表2所示,语料库中的每一条语料包含11个属性: 语料ID、语料文本、标注位置、通假字字头、正字(2)资源库中采用“正字”标识被通假字。字头、出处、时代、释义、拼音、注音和古音。
1.2 通假字知识库
本文采用图数据结构设计通假字知识库,其中,汉字为节点(Node),通假关系和形声关系为边(Edge)。在汉语史研究中,对通假这种字用现象的分析往往会从字音、字形、字义等多个角度展开,因此,我们在构建知识库时也分别针对音、形、义进行了属性标注。
在字音方面,我们在通假关系边中标记了与其对应的注音和古音属性,同时参考胡韧奋等人[16]加工的形声字数据,添加了字和字之间的形声关系边。
在字形方面,我们在字节点上标记了部首、部件和结构信息,其中汉字部件信息参考了Yan等人[17]构建的数据集。
在字义方面,字节点之间的通假关系考虑了义项的差别,即A字通B字时根据语境差别有多种含义,因此一对字节点之间允许有多个通假关系边相连。通假字知识库的详细规范参见附录A。
为了更好地服务于汉语史及通假字自动识别研究,本文在《汉语大词典》的基础上,进一步从康熙字典(3)使用“汉典”版的《康熙字典》数据。、汉典(4)汉典: www.zdic.net、国学大师网汉语字典(5)国学大师网汉语字典: www.guoxuedashi.net/zidian/中采集了与通假用法相关的多源异构数据,共计315万字,融合构建了通假字知识库。在融合数据时,对字而言,以字形为标准与其他来源的数据合并。对通假关系而言,以通假字、正字、释义为标准与其他来源的数据合并。最终,通假字知识库收录了4 185个字节点、7 700对通假关系、650对形声关系。
图1以“辟”为例,展示了知识库中节点和边的属性。其中,字节点属性标注在点划线框内;实线有向边表示通假关系, 通假关系的详细属性参见实线框,与通假关系相关联的语料以点线框标注;短划线有向边表示形声关系,对应的短划线框为形声关系的具体属性。

图1 通假字知识库示例“辟”限于空间,图中仅展示了“辟”与“譬”之间的详细关系及部分关联语料,与“辟”有通假或形声关系的其他字仅在图中呈现节点,如“擗”、“繴”等。
由图中内容可见,“辟”与“譬”之间存在3条通假关系连边,对应三种释义,同时,二者之间还包括一条形声关系连边,标识“辟”是“譬”的声符。
通假字知识库对通假字与正字之间的关系进行了详细加工,相关信息可以从数据和特征两个维度为通假字的自动识别提供支持(参见本文第2节)。同时,通假字与正字之间的音、形、义关联也可为汉语史领域的相关研究提供参考。首先,它可以帮助相关研究者更高效地开展传统研究,常见的应用场景包括:
(1) 字词考证通假字知识库可以帮助我们迅速辨别出通假字,识别出这是常用的通假还是在特定语境中出现的借字。例如,在图1中,“辟”字与“譬”字之间的通假关系,可以帮助我们了解到“辟”字在某些语境下可以作为“譬”的通假字使用。
(2) 词汇语义研究通假字知识库可以帮助我们将某些和本义无关的假借义从词义引申中剔除,例如图1中“辟”通“譬”对应的三种释义。此外,通假字关联网络还能帮助系联同义、近义或词义相关的词,从而辅助词汇语义研究。
(3) 形声字研究知识库中的字节点之间除了通假关系边,还有形声关系边,如在图1中,“譬”字是一个形声字,其声旁为“辟”。通假与形声关联数据可以辅助我们进一步研究形声字及语音的发展规律。
值得一提的是,通假字知识库能够提供传统辞书无法呈现的大规模通假字关联网络信息,这也为汉语史研究提供了新的视角,潜在的应用场景包括:
(1) 量化通假强度在传统研究中,字与字之间的通假关系仅分为“有”和“无”,但这种粗粒度的判断方式并不精确。事实上,有些通假关系应用广泛,而有些仅为辞书中的孤例。基于通假字图知识库,我们可以通过字与字之间不同义项的通假关系数量(边数)以及相关联的语料数量来量化“通假关系的强度”,为后续研究提供更多可能性。
(2) 利用子图探究通假规律在传统研究范式下,由于人的时间和精力有限,研究通常仅针对一个字的通假关系及其相关的几个被通假字进行,相当于仅能研究图中的几个节点及其边。借助图数据库,我们可以根据分割条件迅速将所有数据划分为多个子图,研究子图中所有通假字节点与通假关系边的内在规律,并探讨子图间的联系。这将有助于我们发现更多的通假规律。例如,研究一个通假字的所有通假变化轨迹,实际上就是寻找该节点所在的子图并获得一个子图的生成树。
(3) 辅助古汉语语音演变研究通假关系存在的前提是字之间的音同或音近,而不少汉字的读音在历史上经历了较大变化。利用通假字图知识库,我们可以为相关语音研究提供支持。例如,我们可以根据通假关系边关联语料的“出处”数据,获取不同时期的字与字之间的通假关系并生成关联子图,进而量化估计在某一特定时代两个字的发音可能相同,而在另一时代这两个字的发音可能不同。如此一来,我们便能从历史角度利用图知识库为语音演变研究提供支持。
1.3 通假字识别评测集
为了推动通假字自动识别算法研究,我们基于高质量的通假字标注语料库构建了通假字识别评测集。评测集分为两个子任务: 通假字检测与正字识别。为了更好地评估模型的泛化能力,每个子任务均分为基础版与拓展版,其中,基础版任务的训练集与测试集覆盖的目标字范围一致,而拓展版任务的测试集中则包含训练集未出现的通假用法,其自动探测和识别的难度更高。接下来,本节将介绍两个评测子任务的形式及评测数据集的构建方法。
1.3.1 评测任务设计
表4给出了两个子任务的示例,其中,通假字检测任务旨在识别古汉语文本中的通假字位置,即给定一段输入文本,需输出文本中所有通假字的位置(从0开始计数)。如果该文本中没有通假字,则输出“[]”。计算精确率和召回率时,使用(句子,位置)二元组作为计算单位。

表4 评测任务示例
正字识别任务的目标是识别出古汉语文本中通假字所对应的正字,输入一段文本和通假字位置,需输出该位置的通假字所对应的正字。计算精确率和召回率时,使用(句子,位置,正字)三元组作为计算单位。
1.3.2 评测数据集的构建
考虑到通假字标注语料库主要收录目标字作为通假字使用的数据,为了评测模型的判别能力,兼使其适应真实应用情境,我们从词典中的其他义项例句中补充了目标字非通假用法的数据,构成正负例,如下面示例所示。
例1:惠心燭千仞,雄風扇八區。(正例,通“慧”,表“明慧”含义。)
例2: 必也君亂之,君終之,君之惠也。(负例,表“恩惠”含义)
考虑到通假字的常用度存在差异,且有必要对模型的泛化能力进行评估,本文构建了基础版和拓展版两类评测数据集。基础版评测旨在识别常用通假用法,其中,每个通假字收录至少10条正例,最多不超过20条(6)为确保数据分布的均衡性,如果通假字在标注语料库中的例句大于20条,则随机抽取20句。。同时,尽量补充与正例数量相等的负例,即目标字非通假用法的例句。进一步地,将每个通假字的正例和负例均按照8∶2的比例拆分,分别划入训练集和测试集,从而保证训练集与测试集的数据分布相同。最终,基础版数据集覆盖了279个常见通假字,包含7 962条语料,其中,训练集6 190条,测试集1 772条。
针对用例并不充足的通假字,我们又额外构建了拓展版评测数据。拓展版训练集与基础版训练集保持一致,拓展版测试集则在基础版测试集的基础上,额外补充了2 200个通假字的正例和负例,其中,每个通假字的正例少于10句,负例与其数量相当,共计增补了11 716条语料,因此拓展版测试集共收录13 488条语料。由于拓展版测试集中收录了大量训练集未覆盖的通假用法,这便要求模型结合语境识别出训练时未见过的通假字,无疑挑战性极高,也更加接近真实的应用情境。
2 通假字自动识别评测
基于上节介绍的评测任务和数据,我们就通假字的自动识别开展了初步探索,以期为未来学界的相关研究提供基线结果(7)github.com/frederick-wang/tongjiazi-evaluation。接下来,将首先介绍本文引入的基线方法,然后将分别报告通假字检测(基础版)、通假字检测(拓展版)、正字识别(基础版)和正字识别(拓展版)任务的评测结果,并展开分析和讨论。
2.1 实验方法
为了服务于通假字探测和正字识别,我们首先参考文本纠错的实验,设定构建了一个“通假字-正字”混淆集。混淆集数据采集自通假字知识库和评测训练集中的“通假字-正字”字对。由于测试集中的语料来自《汉语大词典》,为避免测试数据的字对信息泄露,我们在使用通假字知识库中的字对数据时,排除了来自《汉语大词典》的数据。
2.1.1 通假字检测任务
在通假字检测任务中,我们采用了四类基线模型:N-gram语言模型、GPT-2语言模型、BERT MLM语言模型和基于BERT的通假字检测微调模型。

基于GPT2语言模型的通假字检测方法与N-gram 模型类似,即利用困惑度和混淆集信息标记通假字位置。实验采用了Hugging Face中两个开源的古汉语GPT-2模型,分别基于殆知阁和四库全书语料训练,后文用DaizhigeGPT2(8)huggingface.co/uer/gpt2-chinese-ancient和SikuGPT2(9)huggingface.co/JeffreyLau/SikuGPT2指代。
利用BERT MLM语言模型进行实验时,我们依次判断句中的每一个字是否位于混淆集中。若在,则将该位置用[MASK]遮罩,并输出Mask LM的预测结果,从而得以比较原字与混淆集中对应字的预测概率,如果存在混淆字的预测概率高于原字,则将该字所处位置标记为通假字位置。
除了BERT MLM模型外,我们还引入了BERT微调方法。具体来说,通假字检测可建模为token序列标注任务,句中非通假字对应的标签为0,通假字的标签为1。微调阶段,采用BERT+全连接层的结构进行token标签学习。训练模型时,Torch、NumPy和random模块的随机数种子数设为42,Batch大小设为8,Epoch数设为5,采用AdamW优化器、学习率设为5×10-5。按照9∶1的比例将训练数据划分为训练集与验证集,RandomState同样设为42。推理阶段,如果句中某字既被模型标记为1,又是混淆集中收录的通假字,则将该字所在的位置标记为通假字位置。同时,我们也引入了一个无需混淆集的版本,只要该字被模型标记为1,就将对应位置标记为通假字位置。实验中,为了与前面三种方法对应,我们采用了基于殆知阁语料库训练的古汉语BERT模型和Hugging Face上开源的SikuBERT模型(10)huggingface.co/SIKU-BERT/sikubert,经微调,得到了TongjiaziDetection-DaizhigeBERT模型与TongjiaziDetectionSikuBERT模型。
2.1.2 正字识别任务
与检测任务类似,正字识别任务也可基于N-gram 语言模型、GPT-2语言模型、BERT MLM语言模型和BERT微调模型实现。
对于N-gram、GPT-2模型来说,我们将判断句中给定位置的字符是否在混淆集中,如果不在,将该字符直接作为识别的正字;如果在,则依次计算混淆字替换该字符后的句子困惑度,并与句子的初始困惑度进行比较,取句子困惑度最小的字作为识别的正字。BERT MLM模型的识别方法与之类似,如果给定位置的字符不在混淆集中,则将该字符作为识别的正字;如果在,则将该字符用[MASK]遮罩,利用Mask LM获取原字符与所有混淆字的预测概率,取预测概率最大的字作为识别的正字。
关于BERT微调方法,我们借鉴Mask LM任务的形式,要求模型预测出句中通假字所对应的正字,其余位置的字符不参与训练。在微调模型时,Torch、NumPy和Random模块的随机数种子、Batch大小、Epoch数、优化器,学习率、训练数据划分方法均与前文的TongjiaziDetectionBERT模型相同。经过微调,模型加强了正字和上下文语境信息之间的关联,在推理阶段,采用与上述BERT MLM模型一致的方法获取正字识别结果。后文用ZhengziRecognition指代经微调训练的识别模型。
2.2 实验结果
2.2.1 通假字检测任务
表5和表6分别列出了通假字检测任务在基础版和拓展版数据集上的评测结果。在基础版测试集上,模型检测最优F1值达到66.94%,拓展版测试集的最优检测F1值为21.63%,可见通假字检测是一个极有挑战性的任务,在处理模型训练未见过的通假用法时尤为困难。通过对比不同模型,我们发现以下几个要素或对模型的检测性能产生影响。

表5 通假字检测任务(基础版)实验结果 (单位:%)
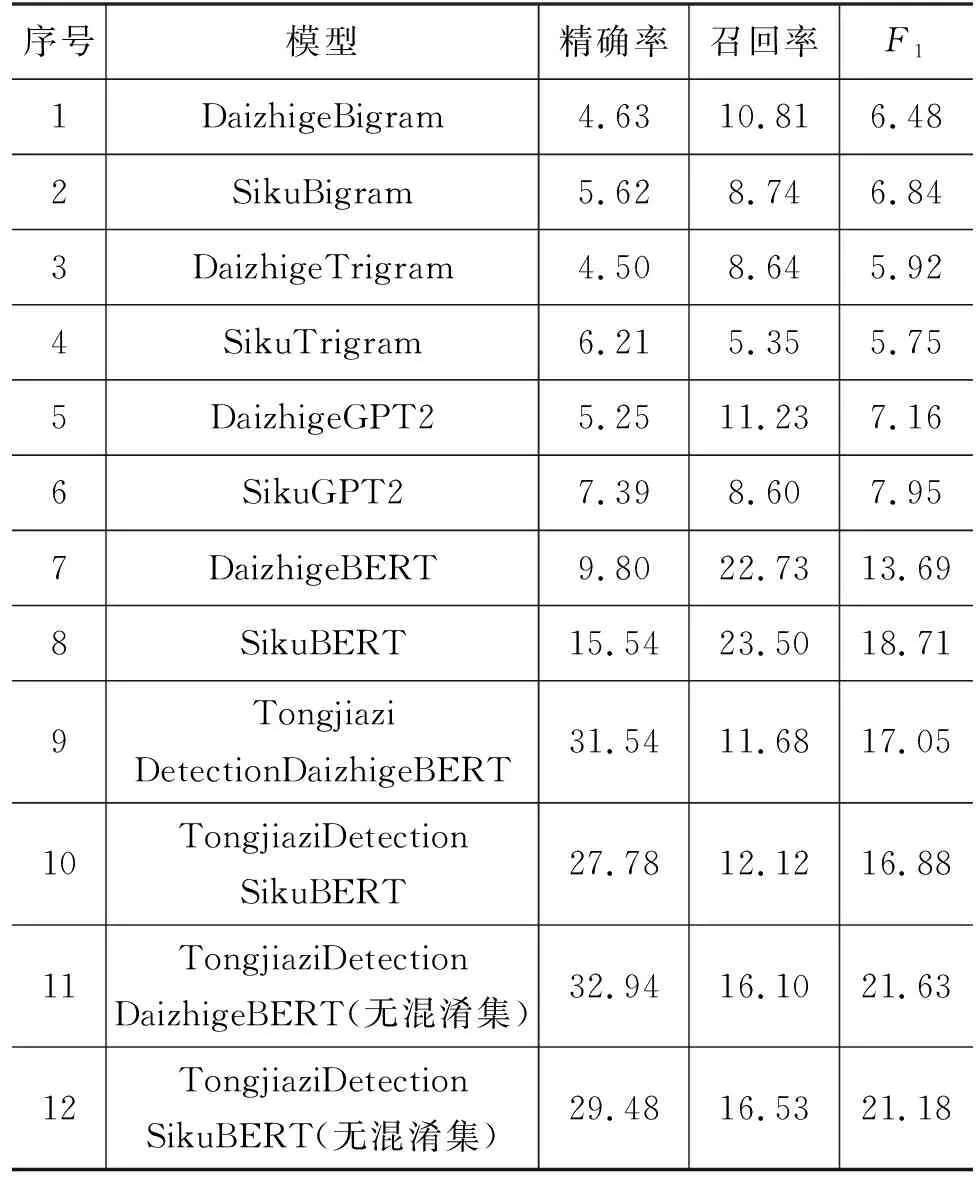
表6 通假字检测任务(拓展版)实验结果 (单位:%)
(1) 模型结构与复杂度
实验结果显示,预训练语言模型具有较好的语境信息编码能力,在一定程度上能够辅助探测通假字。其中,基于BERT模型的方法效果普遍最优,GPT-2模型次之,N-gram模型最弱。推测这一方面与模型的复杂程度有关,N-gram模型最为简单,对上下文信息的捕捉能力最弱;另一方面,这与和模型结构有关,与GPT-2单向自回归训练机制不同,BERT在预训练阶段的双向编码机制使其更擅长利用上下文语境信息进行字符判断。
(2) 预训练数据
在不同类型的模型上,基于文渊阁版繁体四库全书数据训练的模型表现普遍优于基于殆知阁数据训练的模型。殆知阁语料库规模更大,繁简混合,而文渊阁版四库全书(繁体)数据规模偏小,全部为繁体。考虑到我们的评测数据均为繁体中文,因而与四库版预训练模型更为匹配。
(3) 微调机制的引入
在基础版评测数据集上,无论是DaizhigeBert还是SikuBERT,微调后精确率和召回率均有显著提升,相较之下,精确率提升幅度更大,这意味着微调前,模型倾向于将非通假用法识别为通假字,而经过在训练数据上的微调,模型熟悉了常见通假字的用法,探测精确率得到显著提高。
在拓展版评测数据集上,微调同样提升了BERT模型的精确率,但也使其召回率出现了明显下降,推测这主要是由于拓展版测试集中收录了大量训练集未覆盖的通假用法,在训练集上微调使得模型聚焦于用例较多的常见通假字,对训练中未见过的通假用法不再关注,从而降低了识别的召回率。
(4) 混淆集的使用
在通假字检测任务(基础)中,使用混淆集的TongjiaziDetectionBERT精确率略高于无混淆集版,召回率二者几乎一致。但是,在拓展版任务中,无混淆集的TongjiaziDetectionBERT无论是精确率还是召回率都优于带混淆集版,这主要是由于拓展版数据集中存在不少混淆集未覆盖的通假用法,使用混淆集反而在一定程度上限制了模型的识别效果。
2.2.2 正字识别任务
表7为正字识别的实验结果,在基础版测试集上,模型最优准确率为65.64%,在拓展版评测集上,模型最优准确率为19.88%。与通假字检测任务类似,BERT系列模型普遍表现最优,同时,引入微调机制能够进一步提升识别效果,微调给基础版测试集带来的性能提升比拓展版更为显著。对于未经微调的模型来说,基于四库全书训练的模型效果普遍优于基于殆知阁语料训练的模型。

表7 正字识别任务实验结果 (单位:%)
2.3 实验分析
由前文实验结果可见,对现有基线模型来说,通假字检测和正字识别均为十分具有挑战性的任务,拓展版评测集的难度大大高于基础版。为了进一步探析模型的识别能力和泛化能力,我们将拓展版测试集按照目标字是否在训练集中收录分为两部分,分别计算了通假字检测和正字识别的实验结果,分别如表8和表9所示。

表8 TongjiaziDetectionSikuBERT(无混淆集)模型的通假字检测任务(拓展版)实验结果 (单位:%)

表9 ZhengziRecognitionSikuBERT模型的正字识别任务(拓展版)实验结果
对于通假字检测任务来说,从表8可以发现,首先,对于训练数据中未出现的通假字,模型也可以检测出来一部分,并且具有较高精确率,这说明模型具有一定的泛化能力,能够探测出少量训练阶段未见过的通假用法,如例3中的“考”字。其次,对于训练数据收录的常见通假字,模型探测的召回率较高,但精确率却不理想,经过进一步分析,发现主要有两点原因: (1)模型倾向于将在训练数据中见过的通假字的非通假用法也判定为通假字,如例4中的“皇”字。(2)模型实际预测正确,《汉语大词典》中的例句仅针对字头标注通假用法,句中还可能包括其他通假字,数据标注存在少量缺失情况,如例5中的“皇皇”。
例3陳登者,善術,夜過吉甫家,羣即捕登掠考,上言吉甫陰事。(“考”通“拷”,“考”字通假用法在训练集中未出现,模型正确预测其为通假字)
例4真宗皇帝爲之嘉嘆,面可其奏。(训练集中收录了“皇”的通假用法,但此处“皇”字并非通假,模型错误预测其为通假字)
例5孔子三月無君,則皇皇如也,出疆必載質。(此处“皇”通“惶”,模型正确预测其为通假字,但由于该句取自《汉语大词典中》“質”通“贄”的例句,其中“皇”的通假用法未被标注,导致评测时误将此例计为误探测条目。)
在正字识别任务中,如表9所示,ZhengziRecognitionSikuBERT模型同样具有一定的泛化能力。对于训练数据中未覆盖的通假字,来自通假字知识库的混淆集发挥了作用,帮助模型将它们识别了出来。对于未识别出的正字,经分析,发现主要包括两种错误类型: 第一,模型认为该位置填通假字比填正字更合适,如表10所示,在识别句中“台”的正字时,只有常见的通“鮐”被成功识别,而相对罕见的通“嗣”未被识别;第二,一个通假字对应着多个正字,模型错误地识别为其他正字,例如在识别“共”的正字时,存在通“恭”和通“供”两种通假用法,模型将部分通“恭”用法识别为了通“供”,如表10中的最后一例:“唯是桃弧、棘矢以共王事。”进一步查阅文献发现,不同学者对通假释读方式的理解存在差异: 唐代陆德明《经典释文》注此句中“共”音“恭”,成为清代之前学者共识,《汉语大词典》亦用此说。而以清代俞樾《群经平议》为代表的清人观点认为该字通“供”,并为现代人所继承,如杨伯峻《春秋左传注》、中华书局版《左传》(郭丹等译注)皆同此观点。可见,模型判定虽不同于“标准答案”,但有其合理之处。

表10 拓展评测集上的正字识别结果示例
总之,通假字的检测和识别是一个复杂的问题,本文搭建的基线模型能够识别部分通假用法,但泛化能力尚显不足,对微调训练时未能覆盖的通假字,往往无法检测到或准确识别出本字。在识别本字时,对于不常见的通假关系,模型也往往无法正确识别。未来我们仍需要在设计模型时充分集合上下文语义信息与通假字、正字的释义信息,提升模型泛化能力,加强其对不常见通假关系的识别能力。
3 总结
通假是古汉语中的一种常见用字现象,为了服务于通假字的人工判别和机器处理,本文构建了一个涵盖标注语料库、知识库和评测数据集的多维度通假字资源库。在此基础上,本文基于N-gram、BERT和GPT-2等主流语言模型开展了通假字自动检测和正字识别实验,为通假字检测和正字识别任务提供了基线结果: 在收录常见通假字用法的基础版测试集上,通假字检测的F1值达到66.94%,正字识别的准确率达到65.64%;在拓展版测试集上,模型具备一定泛化能力,能够识别出少量在训练集中未见过的通假字及其正字,但识别效果远远低于基础版评测集。通过对比不同的基线模型,本文发现,模型结构、预训练数据、微调机制和混淆集的使用均会对两个子任务产生不同程度的影响。进一步地,本文对模型的预测误例及原因进行了初步分析。
需要指出的是,本文所开展的通假字资源库建设和通假字识别算法的研究只是该领域的初步探索性工作,研究还存在不少待改进之处。例如,在资源库的建设上,本研究基于《汉语大词典》采集基础性标注语料,但该词典仅针对字头给出通假例句,例句中仍可能存在其他通假字,有待在后续工作中通过人工标注进行补充;同时,《汉语大词典》所收录的通假用法旨在覆盖基础性、一般性需求,未来还有必要基于面向出土文献和传世文献的通假字辞书资源引入更大范围的通假用例数据,对现有的语料库和知识库进行扩充,从而更好地辅助汉语史领域的相关研究。在自动识别技术方面,本研究搭建了通假字检测和正字识别的基线方法,由实验结果可见,通假字检测和正字识别是极具挑战性的自然语言处理任务,目前模型具有一定识别能力,但其准确性和泛化能力还有待进一步提升。此外,基于GPT-4等大模型开展通假字识别是一个值得探索的方向。
最后,在资源库和识别技术的应用上,仍有不少可以开展的工作。例如,通假字资源库及识别算法可以接入古籍整理或古文献检索平台,为该领域研究者提供可能的通假字用例及相关语料信息,辅助专家释读文献,提升古籍整理效率。如前文所述,基于图结构的知识库能够提供传统辞书无法呈现的大规模汉字通假关系网络信息,从而可为古汉语字用现象、词汇发展、词义关联、语音演变等研究提供新视角、新方法。此外,资源库中的高频常用通假字数据可以为文言文教学材料编写、考试命题提供参考,基于该资料库和其他古汉语领域现有语言资源(如词性标注语料库、词义标注语料库、文白翻译平行语料库等)还可进一步研发辅助文言文学习的工具应用,提升学生的文言文阅读理解能力。
附录A 通假字知识库体例
通假字知识库采用图数据结构,以汉字为节点(node),字节点之间有通假关系和形声关系两类连边(edge),节点、边及其属性均以JSON Object形式存储。通假关系边属性会引用语料信息,这些语料没有像“通假字标注语料库”中的语料那样经过详细的标注与校对,只是将不同来源的语料去重后,解析为简单的结构化对象并存储。
字节点具有以下五个属性:
(1) 节点ID: 用于唯一标识字对象的编号,如“248”“1764”。
(2) 字形: 字的书写形态,如“辟”“譬”。
(3) 部首: 汉字的构造部分,用于分类和检索字,如“辛”“言”。
(4) 部件: 汉字的基本构成单元,包括部首和其他部分,如“卩口辛”“辟言”。
(5) 结构: 汉字的构造方式,如“左右结构”“上下结构”等。
通假关系边具有以下八个属性:
(1) 通假字关系ID: 用于唯一标识通假关系对象的编号,如“638”。
(2) 通假字: 在该通假关系中通其他字的字,是有向边的起点,如“辟通譬”通假关系中的“辟”。
(3) 正字: 被通假的字,是有向边的终点,如“辟通譬”通假关系中的“譬”。
(4) 拼音: 该通假关系中字音的拼音表示,如“pì”。
(5) 注音: 该通假关系中字音的注音表示。
(6) 古音: 该通假关系中字音的古代发音。
(7) 释义: 该通假关系中字的意义或用法解释,如“墨子提出的逻辑推理的方法之一。谓举旁例以喻所说的论题。”。
(8) 关联语料ID: 与通假关系对象相关的语料对象的编号列表,用逗号分隔,如“8440, 8804”。
形声关系边具有以下三个属性:
(1) 形声关系ID: 用于唯一标识形声关系对象的编号,如“644”。
(2) 形声字: 具有特定形声构造的汉字,是有向边的起点,如“譬”。
(3) 声旁: 形声字的声旁,是有向边的终点,如“辟”。
关联语料具有以下四个属性:
(1) 语料ID: 用于唯一标识语料对象的编号,如“8806”。
(2) 语料文本: 包含通假字与通假关系的文本内容。
(3) 语料出处: 语料的来源文献,如“《荀子·王霸》”。
(4) 语料来源: 语料的来源,为“汉语大词典”“汉典”或“国学大师网汉语字典”。
