基于技能网络的通用自然语言生成模型
2024-05-09廖俊伟
廖俊伟,程 帅
(电子科技大学 计算机科学与工程学院,四川 成都 611731)
0 引言
Transformer模型[1]诞生后,其灵活性促进了一系列多任务模型的发展[2-4]。多任务模型是指仅使用一个模型来处理多个不同任务。这些模型一般都是典型的“稠密”(Dense)模型——当执行任何一个任务的时候,模型的参数被全部激活。但对于这种不同任务共享所有参数的模型,并不清楚模型中的每一部分参数分别学到了什么知识或者能力。这带来了两个问题: 一方面,尽管处理不同自然语言任务需要不同的技能[5],稠密模型的这个特性使我们无法根据不同任务显式地选择激活不同的技能;另一方面,当使用训练好的稠密模型来执行新的任务时,不管模型中包含的技能是否与新的任务相关,这些技能都会用于新任务的学习,从而导致不相关的技能影响模型学习新的任务。
为解决上述问题,本文提出了一种基于技能网络的通用自然语言生成模型(SkillNet-NLG)。模型的基本思想是其网络结构中包含了多个技能模块,其中每一个模块代表一种独特的技能。这些技能的定义如表1所示。

表1 SkillNet-NLG的技能及其定义
与传统的稠密模型在执行某一任务时激活所有的参数不同,SkillNet-NLG仅激活与特定任务相关的技能模块。如图1所示,为了执行对话生成任务,SkillNet-NLG需要的能力包括生成开放式文本的能力(Sopen-end),理解对话的上下文的能力(Sconversation)以及理解基于自然语言的问题的能力(Squestion)。因此,对应于Sopen-end,Sconversation,Squestion和Sgeneral(1)Sgeneral定义为一种通用技能,该技能是完成任何一个任务所需要的缺省能力,默认总是处于激活状态。四种能力的技能模块被激活。

图1 SkillNet-NLG模型示意图
本文提出的SkillNet-NLG是基于Transformer[1]架构实现。Transformer是一种编码器-解码器(Encoder-Decoder)模型,其编码器和解码器分别包含多个结构相同的Transformer层,而每个Transformer层又是由多头注意力网络(Multi-Head Attention Network)和前馈网络(Feed-Forward Neural Network,FFN)构成。具体来说,SkillNet-NLG针对Transformer结构的改动如下: 对于编码器与解码器中的Transformer层,每间隔一层将其中的FFN替换为多个结构相同的FFN。每一个FFN对应于一种技能。当模型处理某个任务时,只有与执行该任务所需的技能相关的FFN被激活。
本文在多个中文自然语言生成任务上进行了大量的实验,验证SkillNet-NLG的效果(2)本文提出的方法与具体的语言无关。在后续研究中将尝试将SkillNet-NLG用于其他语言的生成任务。。在多任务训练阶段,使用了五种自然语言生成任务,包括文本摘要生成、广告生成、问答、对话生成以及语法纠错。经过多任务训练后的SkillNet-NLG,在五种任务中的其中四种任务上,超过了之前工作中针对特定任务单独训练的表现最好的模型的性能。同时,SkillNet-NLG的性能也优于另外两种常用的多任务模型,即稠密模型和混合专家模型(Mixture-of-Expert,MoE)。此外,本文还将经过多任务训练的 SkillNet-NLG通过微调应用于与多任务训练阶段不同的其他文本生成任务,包括主题到文章的生成、复述生成和故事生成。实验结果表明,SkillNet-NLG的表现优于前述的所有基线模型。
1 相关工作
SkillNet-NLG是一种通用的自然语言生成模型,即使用一个模型执行多种自然语言生成任务。其在模型训练阶段采取了多任务的训练方法,因此与传统的多任务模型有相似之处。从模型结构上来看,SkillNet-NLG的主要特征是引入了技能模块,在执行某一任务时,根据预先定义的任务技能,选择部分技能模块激活,因此是一种稀疏激活的模型。
1.1 多任务模型
传统的多任务模型[2-4]通常包括一个所有任务共享的特征表示层(Feature Representation Layer)和多个针对特定任务的预测层(Task-Specific Prediction Layers)。在多任务训练阶段,共享的特征表示层从数据中学习到通用的特征表示,而预测层则学习到与任务相关的特征表示,但是并不清楚在特征表示层学习到了什么知识或者技能。与之不同,SkillNet-NLG包含清晰定义的技能模块,这些技能模块根据任务需要被选择性地激活。直观地说,SkillNet-NLG不是学习如何针对某个特定任务进行优化,而是学习如何对每个特定技能模块进行优化,以及如何组合多个技能模块来完成某项任务。因此,SkillNet-NLG可以更好地泛化到模型在训练阶段从未见过的新任务上。
1.2 稀疏激活模型
另外一类典型的稀疏激活模型是混合专家模型(Mixture-of-Expert,MoE)[6-9]。混合专家模型包含多个并列的专家模块(Expert Modules),这些专家模块通常具有相同的网络结构。混合专家模型通过一个参数化的门控模块(Gating Module)来控制激活部分或者全部的专家模块。但是并不清楚每个专家模块学到了什么类型的知识,同时也无法解释为什么选择激活某些专家模块而不激活另外一些专家模块。与之不同,SkillNet-NLG具有定义清晰的技能模块,具体激活哪些技能模块则是根据任务的需要,由人工进行判断。
2 模型与方法
本节首先介绍了作为SkillNet-NLG基础的Transformer结构(2.1节);其次,对SkillNet-NLG模型的实现思路和细节进行描述(2.2节);最后介绍了如何对任务分解相关技能(2.3节),以及如何对SkillNet-NLG进行多任务训练(2.4节)。
2.1 背景介绍
SkillNet-NLG是基于Transformer的一种改进模型。下面简单介绍一下Transformer的结构。
Transformer是一种具有多层结构的编码器-解码器模型。在编码器端,如图2(a)所示,Transformer的每一层由一个多头自注意力网络(Multi-head Self-attention Network, Attention)和一个前馈网络(Feed-Forward Network,FFN)组成。对于给定的Transformer某一层输入特征hin=(h1,h2,…,hn),该层的输出计算如式(1)所示。

图2 Transformer与SkillNet-NLG的层结构对比
hout=FNN(Attention(hin))
(1)
在多头注意力机制中,输入特征通过不同的权值矩阵被线性映射到不同的信息子空间,并在每个子空间完成相同的注意力计算,以对文本潜在的结构和语义进行充分学习。其中第i个头的注意力headi计算过程如式(2)~式(4)所示。
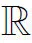
Attention(hin)=Concat(head1,…,headN)WO
(5)
其中,N是注意力头个数,WO是参数矩阵。
前馈网络FFN对多头注意力输出进行两次线性变换,并在两次变换之间使用了ReLU激活函数,如式(6)所示。
FFN(x)=Max(0,xW1+b1)W2+b2
(6)
其中,x表示FFN的输入,即多头注意力的输出;W1、b1、W2、b2是学习参数。
Transformer解码器的每层结构与编码器类似,不同之处在于解码器的每层中额外增加了一个多头注意力网络。这个增加的多头注意力网络在解码器的输入和编码器的输出之间进行多头注意力的计算操作。
2.2 SkillNet-NLG
SkillNet-NLG的基本设计思想是模型包含多个技能模块,当模型执行某一个任务时,仅激活完成任务所需的技能对应的技能模块。SkillNet-NLG对Transformer结构上的改动如图2(b)所示(3)图中以Transformer的编码器层为例进行说明,解码器层与之类似。。SkillNet-NLG将Transformer层中的单个FFN替换为多个相同结构的FFN,每个FFN都对应于一种技能。当模型处理某个任务时,仅激活该任务所需技能对应的FFN。例如,对于对话生成任务需要的四种技能(Sopen-end,Sconversation,Squestion和Sgeneral),模型仅激活这四种技能对应的FFN,而其余的两个技能(Snon-open-end和Sdata-to-text)对应的FFN并没有被激活。对于某个特定技能k的FFNk,其功能与原始的FFN类似,生成该技能的特征表示如式(7)所示。
hk=FFNk(Attention(hin))
(7)
由于激活的技能子模块随任务不同而变化,为了计算SkillNet-NLG的每层输出的特征表示,对所有激活技能的特征表示进行平均池化操作如式(8)所示。
(8)
其中,S代表激活的技能集合。例如,对于图1所示的对话生成任务,S={Sopen-end, Sconversation, Squestion, Sgeneral}。为避免增加过多的模型参数,参考Lepikhin等人[7]的做法,上述对Transformer层的改动不是针对所有的Transformer层进行,而是选择每间隔一层进行。
2.3 任务分解
SkillNet-NLG的基本设计思想是模型包含多个技能模块,当模型执行某一个任务时,仅激活完成任务所需的技能对应的技能模块。因此在模型执行任务之前,需要分析完成任务需要哪些技能。
从“输入-输出”信息变换的角度,自然语言生成可分为开放式语言生成(Open-end Language Generation)和非开放式语言生成(Non-open-end Language Generation)[10]。在非开放式语言生成任务中,输入信息在语义上提供了完备甚至更多的信息,模型需要将这些信息用语言文字表述出来。例如在文本摘要任务中,输入给出了比输出语义空间中更多的信息,模型需要通过信息过滤来选择合适的信息表达在输出文本中。因此,模型为完成文本摘要任务,需要非开放式语言生成能力(Snon-open-end)。对应的,开放式语言生成是指输入信息不完备、不足以引导模型得到完整输出语义的任务。例如,问答是典型的开放式语言生成任务,模型根据提问生成回答。这个场景下输入信息有限,模型需要利用其他信息(如外部知识库)或者生成输入中未指定或未约束的部分内容。这类任务普遍具有“一到多”的特点,即同一个输入存在多种语义显著不同的输出文本,因此针对这类任务需要模型具备开放式语言生成能力(Sopen-end)。此外,问答任务需要在理解提问的基础上生成适当的回答,因此模型还需要具备理解自然语言问题的能力(Squestion)。
将多任务训练的SkillNet-NLG用于新任务的时候,虽然模型在训练阶段没有见过该任务,但是可以通过组合新任务所需要的技能,使模型能够快速将多任务阶段学习到的知识迁移到新任务的学习上。以主题到文章生成任务为例,该任务是根据输入的一组与主题相关的关键词生成一篇围绕主题的文章。根据任务定义,该任务需要开放式的语言生成能力(Sopen-end)。此外,由于给定的输入是一组关键词,模型还需要具备从结构化数据生成文本的能力(Sdata-to-text)。
采用与上述类似的分析,本文对常见的自然语言生成任务定义了所需的技能(表2)。表中各个任务的介绍参见第3.1节。
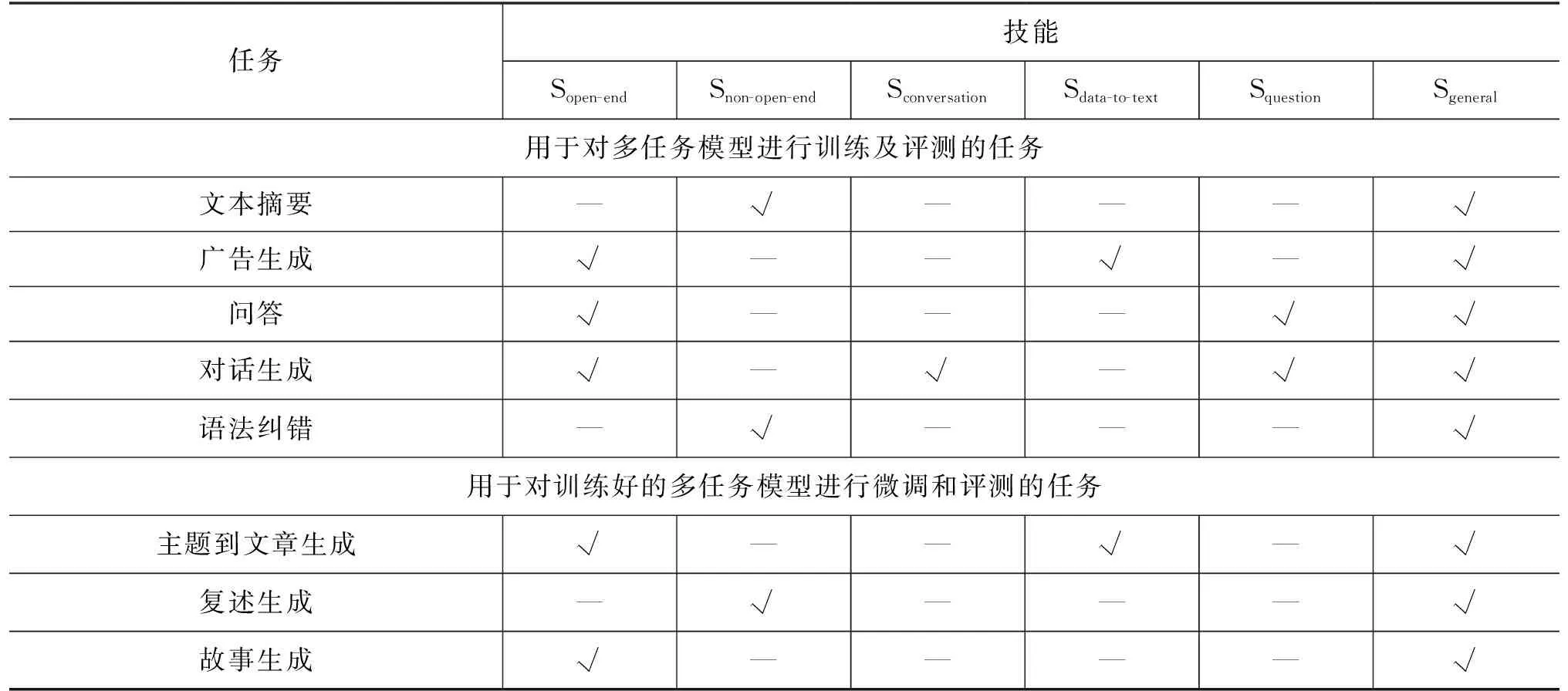
表2 常见自然语言生成任务的技能定义
2.4 模型训练
对SkillNet-NLG进行多任务训练是通过混合所有任务的训练数据进行的。在模型训练过程中的每一步,首先从参与训练的多个任务中选择一个任务的一个小批量数据(Mini-batch),然后在输入数据中添加代表该任务的特殊前缀。模型计算生成的文本与参考文本之间的交叉熵损失(Cross-Entropy Loss),并进行后向传播(Back Propagation)更新模型参数。由于各个任务的训练数据存在数量不均衡的情况,参考Raffel等人[3]的方法,本文采用了基于温度调节(Temperature-Scaled)的数据采样混合策略。具体来说,根据概率{p1,…,pN}从N个任务中随机选择一个任务并采样该任务一个小批量数据。其中,概率pi计算如式(9)所示。
(9)
其中,ni表示第i个任务的训练数据数量;K表示人为设置的数据大小上限,以避免某个任务的数据量过大从而导致采样比率过高;T表示采样温度。当T= 1时,上述分布等于原始的数据分布;当T较大(如T=1 024)时,此时的分布接近于均匀分布。关于选择不同T对模型训练的影响请参见第3.6节中的分析。
3 实验与结果分析
本节描述了实验设置,并对实验结果进行了分析与讨论(4)实验代码、数据集和模型下载地址https://github.com/david-liao/skillnet_nlg。
3.1 任务及数据集
本文在常见的自然语言生成任务的中文基准数据集上开展实验,任务种类、每个任务使用的数据集统计信息和评测指标如表3所示。表中第一组五个任务的数据集用于SkillNet-NLG的多任务训练及训练后的模型在每个任务上的性能评测。表中第二组三个任务的数据集用于对训练好的SkillNet-NLG进行微调,并评测微调后模型在新任务上的性能表现。

表3 实验数据集统计信息
以下详细介绍所有用到的数据集:
(1) 文本摘要任务的目的是对输入的文本内容进行总结以获得其主旨大意,便于人们快速理解文本含义。LCSTS是从新浪微博收集的大规模中文短文本摘要数据集[11]。本文中采用了与Shao等人[12]相同的数据集划分及评测指标。
(2) 广告生成任务是根据给定的一组商品属性与属性值对生成一段广告文案。AdGen来自中国最大的电子商务平台,包含约12万条与服装有关的属性与属性值对和对应的广告文案。本文采用了与Shao等人[12]相同的数据预处理过程,将输入数据表示为属性与属性值对的列表。
(3) 问答任务是根据提出的问题生成使用自然语言的回答。MATINF-QA是一个大规模中文开放域问答数据集[13],包括107万条来自健康领域的问答数据。
(4) 对话生成任务是基于历史对话记录生成对话的下一句的回复。KdConv是一个多领域基于知识驱动的对话数据集,其中,包含4 500条来自三个不同领域的对话数据。本文参照Sun等人[14]对数据进行划分和预处理,并且从输入数据中移除了知识三元组。
(5) 语法纠错任务主要是纠正文本中的拼写、标点符号、语法以及用词等错误。NLPCC来自NLPCC 2018 Shared Task(5)http://tcci.ccf.org.cn/conference/2018/taskdata.php[15],包含1 200万条由非母语人士撰写的中文文本,其中的语法错误已由母语人士进行了注释和修正。本文使用官方提供的评测脚本(6)http://www.comp.nus.edu.sg/nlp/software.html计算MaxMatch(M2)得分作为评测指标。
(6) 主题到文章生成任务根据输入的一组与主题相关的关键词生成一篇围绕主题的短文。ZhiHu是从中文问答网站知乎收集整理的主题到文章生成的数据集[16],包含约100个高频主题词以及长度在50至100之间的中文短文。本文采用了与Yang等人[17]相同的数据划分和评测指标(7)数据集下载地址https://pan.baidu.com/s/17pcfWUuQTbcbniT0tBdwFQ。
(7) 复述生成任务生成与输入句子表达意思相同但是用词和语法有所变化的句子。PKU Paraphrase Bank (PKUPB)是一个包含509 832条复述语句对的句子级别的中文复述生成语料库(8)https://github.com/pkucoli/PKU-Paraphrase-Bank。本文分别从原始语料中随机采样1万条作为验证集和测试集,剩下部分作为训练集。
(8) 故事生成任务根据给出的一段提示生成一篇合乎情理的故事。生成的故事必须保持通篇主题一致并且具有一定的独创性。OutGen是由Guan等人[18]创建的基于大纲的故事生成任务数据集,该任务要求根据给定的人物和事件大纲生成一篇连贯的故事。其中的大纲是一组打乱顺序的短语。本文使用了与Guan等人[18]一致的数据划分和评测指标(9)数据和评测脚本的下载地址https://github.com/thucoai/LOT-LongLM。。
3.2 参数设置
本文提出的SkillNet-NLG基于Huggingface Transformers开发库(10)https://github.com/huggingface/transformers[19]的BART-large模型[4]实现。模型由分别为12层的编码器和解码器组成,模型的隐层维度(Hidden State Dimensions)为1 024,前馈网络维度(Feed Forward Dimension)为4 096。所有的技能模块(FFNk)使用本文自己预训练的中文BART模型对应Transformer层的FFN参数进行初始化。SkillNet-NLG在多任务训练阶段,设置参数更新步数为10万步,最大输入序列长度(Maximum Source Length)为512,最大输出序列长度(Maximum Target Length)为200,批量大小(Batch Size)为512。使用Adam[20]优化器(β1=0.9,β2=0.999,ε=1e-8),并且设置学习率在训练的前1万步逐渐预热(Warmup)至峰值3e-5,随后线性下降。多任务训练阶段的每个任务的训练损失学习曲线如图3所示。在2.4节中用于计算训练数据采样策略的数据大小上限K设置为221,采样温度(Sampling Temperature)T在候选集{1,2,4,8,16,1 024}中进行超参搜索后选择了4。模型推理(Inference)阶段使用了集束搜索(Beam Search)的解码方法,所有任务的集束大小(Beam Size)均设置为4。

图3 多任务训练阶段各任务的学习曲线
在基于多任务训练的SkillNet-NLG上分别微调三个新任务的超参数设置如表4所示。表中未列出的其他参数与多任务训练阶段相同,不再赘述。

表4 模型微调超参数设置
3.3 基线模型
为了评价SkillNet-NLG在多任务上的性能,引入多种典型模型进行实验对比,其中包括分别针对每个任务单独训练的模型和另外两种多任务模型。以下详细介绍所有参与比较的模型:
(1) 针对特定任务单独训练的模型(Task-specific): 基于本文自己预训练的中文BART模型[4](以下简称BART模型),分别在每个任务数据集上单独微调的模型。因此,对于用于多任务训练阶段的五个任务,一共训练了五个模型。与此相对,SkillNet-NLG与其他基线模型都是多任务模型,即仅使用一个模型执行五个任务。
(2) 多任务训练的稠密模型(Dense): 该模型是在五个任务数据集上使用2.4节中介绍的方法训练的BART模型。
(3) 多任务训练的混合专家模型(MoE): 该模型是在BART模型的基础上,参照Lepikhin等人[7]实现的混合专家模型。对于输入的每个词元(Token),模型使用一个门控网络选择激活前两名(top-2)的专家模块。为了与SkillNet-NLG可比较(包含六个技能模块),本文实现的MoE模型包含了六个专家模块(Expert Module)。MoE模型使用了BART模型参数进行初始化,并在五个任务数据集上使用2.4节中介绍的多任务训练方法进行训练。
实验中用到的所有模型参数数量统计信息如表5所示。由于SkillNet-NLG和MoE模型都属于稀疏激活的模型,表中最后一列列出了模型在实际使用过程中激活的参数数量。从表中可以看出,SkillNet-NLG的实际激活参数数量依赖于其执行特定任务时激活的技能模块数量。
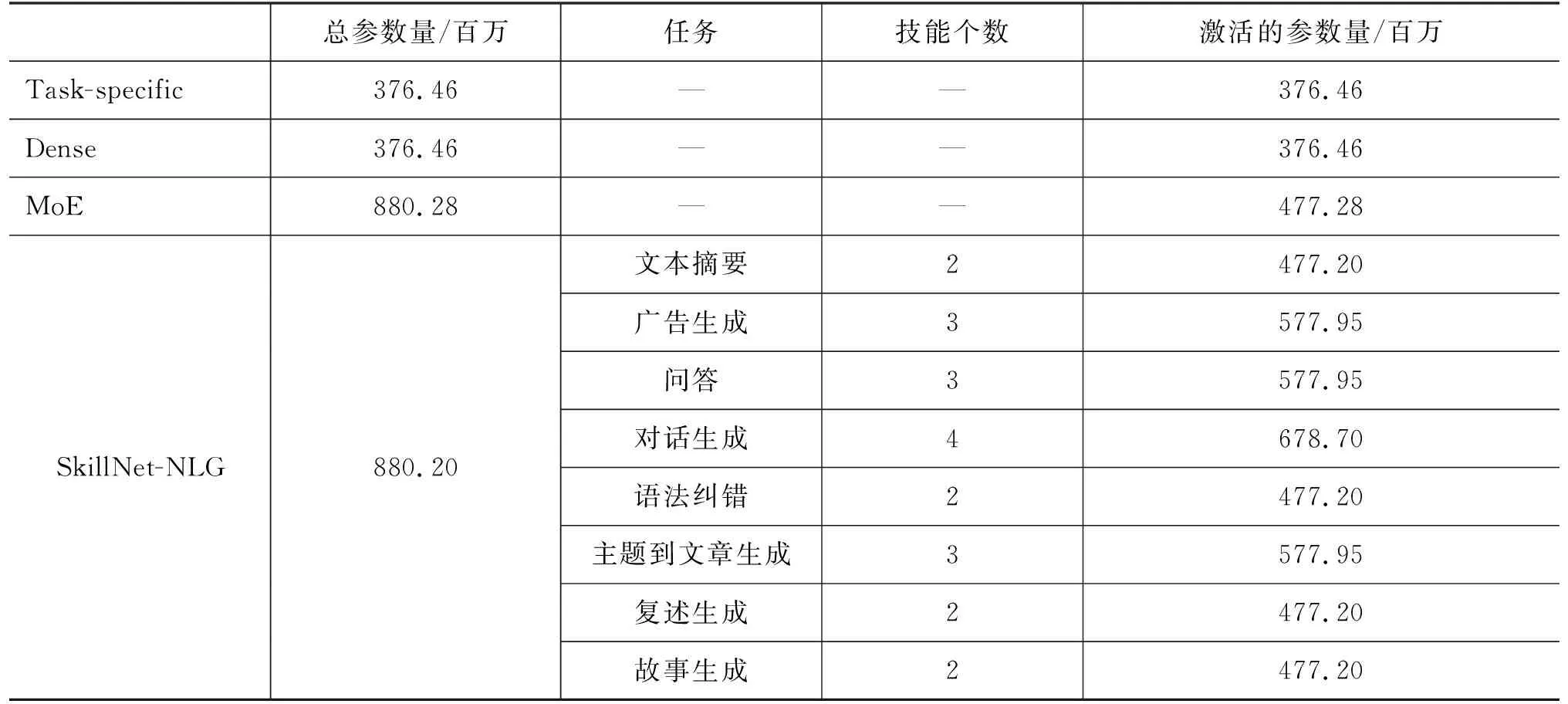
表5 模型参数量统计
3.4 模型性能对比
表6展示了 SkillNet-NLG 和所有基线方法在参与多任务训练的五个任务上的结果。为了便于与最新研究成果对比,表中第一行给出了当前在任务数据集上性能表现最好系统的结果。其中,LCSTS,AdGen和MATINF-QA的结果来自 CPT-Large[12],KdConv的结果来自 mBART-Large[21],NLPCC的结果来自Mask GEC[22]。同时为便于比较整体性能,表中最后一列给出模型在所有任务上的结果的平均值。

表6 不同模型在用于多任务训练的五个任务数据集上的实验结果
从实验结果上看,SkillNet-NLG在所有任务的平均得分上表现优于针对特定任务单独训练的模型(Task-specific)和另外两个多任务模型(Dense和MoE)。我们分别对每个任务使用 Paired Bootstrap Resampling[23-24]方法计算了模型SkillNetNLG和Task-specific的实验结果之间的p-value值: 0.243 2(LCSTS),0.180 3(AdGen),0.718 2(MATINF-QA),0.769 2(KdConv),0.366 4(NLPCC)。结果表明在显著性水平α= 0.05 的情况下,不能完全拒绝两种方法之间没有显著性差异的假设(p>0.05)。在仅使用一个模型的执行所有任务的情况下,SkillNet-NLG在五个任务中的四个上面表现均优于目前性能最好的系统。可见本文提出基于技能网络的稀疏激活方法对于模型在多任务上的性能提升起到了重要作用。
表7展示了所有模型在三个新任务上的实验结果,其中的Dense、MoE、SkillNetNLG是指在上述多任务实验中训练好的模型基础上针对新任务分别微调得到的模型。表中第一行给出了目前在任务数据集上性能表现最好系统的结果。其中,ZhiHu的结果来自SCTKG(Gold-Senti)[25], OutGen的结果来自LongLMlarge[18]。
表7 不同模型在三个新任务数据集上的实验结果
从实验结果上看,SkillNet-NLG在三个新任务上的表现均优于针对特定任务单独训练的模型和其他两个多任务模型。SkillNet-NLG在Zhihu数据集(主题到文章生成任务)上取得了与Qiao等人[25]工作中记录的最好结果相近(BLEU-2分值仅差0.04)的性能。后者的方法使用了外部的知识库(Knowledge Base)来辅助文章的生成,而SkillNet-NLG没有使用任何额外知识。特别值得注意的是,SkillNet-NLG在OutGen数据集(故事生成任务)上超过了Guan等人[18]的LongLMlarge模型1.22的BLEU-2分值,后者的模型使用了更多参数(约10亿参数)并且在大规模的领域内的数据上进行了预训练。
3.5 消融实验
本文根据2.3节中描述的方法对任务中使用的技能进行了分解(表2)。为了验证分解方案的有效性,我们分别对模型在多任务和新任务两种场景下进行了消融实验。
模型在多任务训练阶段的五个任务上的技能分解方案如表8所示。其中,①使用预定义的技能,即表2中定义的技能分解方案。②每个任务对应一种技能,各个技能之间没有重叠。③ 每个任务随机分配一组技能。由于模型实际激活参数数量依赖于其执行特定任务时使用的技能个数(表5)。为与SkillNet-NLG的激活参数数量进行公平对比,随机分配的技能的个数与表2中定义的技能个数保持一致。④在预定义方案中通用技能Sgeneral是完成任一任务所需要的缺省能力,默认总是处于激活状态。因此一种可供比较的分解方案是每个任务都固定包含Sgeneral,其他的技能则采用与③中类似的方法随机分配。表中结果显示使用其他技能分解方案的模型性能相较预定义的技能分解方案均有不同程度的下降,表明了SkillNet-NLG任务技能分解的有效性。此外,方案④由于包含通用技能,能够学习完成所有任务所需的具有共性的能力,表现优于完全使用随机分配技能的方案,即方案③。

表8 模型在用于多任务训练的五个任务上消融实验结果
模型在三个新任务上的技能分解方案如表9所示。其中,方案②使用了预定义技能集合的补集(表1 中定义了技能集合的全集)。例如,对于故事生成任务(OutGen),预定义的技能集合是 {Sgeneral,Sopen-end},预定义外的技能集合则是 {Sopen-end,Sdata-to-text,Sconversation,Squestion};方案 ⑤在预定义的技能基础上再随机分配一个技能; 方案⑥随机分配与预定义技能个数一致的一组技能。表中结果显示,使用其他技能分配方案的模型性能较预定义的方案(见表2)均有不同程度下降,表明了SkillNet-NLG技能分解方案对新任务的有效性。

表9 模型在三个新任务上的消融实验结果
3.6 数据采样策略分析
在SkillNet-NLG的多任务训练阶段(2.4节),为了克服任务数据量不均衡的问题,使用了基于温度调节(Temperature-Scaled)的数据采样混合策略。该策略根据数据采样温度T计算的概率选择任务训练数据。为了进一步考察采样温度T对模型在各个任务上的性能影响程度,选取了有代表性的T值进行对比实验,以提供T值选择的依据。在参与多任务训练的五个任务的验证集上的实验结果如图4所示。

图4 不同采样温度对实验结果的影响
当设置T= 1时,数据采样策略按照每个任务的实际训练数据大小的比例进行采样,这导致用于多任务训练的五个数据集大小极不平衡(见表3中数据集统计信息)。从图中可以看出,此时高资源任务LCSTS(216万条训练数据)在不同T设置中取得最大值;而低资源任务KdConv(6.3万条训练数据)在不同T设置中值最小。随着T值逐渐增大,高资源任务和低资源任务之间的数据不均衡现象逐渐得到缓解。高资源任务的分值开始下降,而低资源任务的分值开始上升。当T= 4时,模型在两种极端情况之间达到一种平衡状态。此时模型在五个任务上面的平均分值最高。根据这一实验结果,本文在所有多任务训练实验中均采用了T= 4的设置。
4 总结与展望
本文提出了一种称作SkillNet-NLG的通用自然语言生成模型,该模型能够仅使用一个模型处理多种自然语言生成任务。SkillNet-NLG的核心思想是执行某一任务时,根据预先定义的任务所需要的技能,稀疏激活模型中与该技能相关的模型参数。这种模型设计思路的优势在于使得模型在学习新任务的时候可以选择与任务相关的技能迁移过去,从而避免不相关技能的负面影响。在多种自然语言生成任务上对模型进行评估的实验结果表明,SkillNet-NLG性能优于常用的基线模型,充分验证了其在自然语言生成任务上的有效性。
未来的研究工作中,可以探索将本文提出的方法应用在中文以外的其他自然语言生成任务中,以验证方法的通用性。另外,本文中模型是通过修改Transformer的前馈网络层来实现的,可以考虑其他实现方法,例如,改动Transformer的多头注意力层,进一步提升模型性能。最后,可以考虑引入探查性的任务来研究模型的技能模块学习到的知识,使模型具有更强的可解释性。
