异构工业控制网络多源目标入侵自动识别研究
2024-05-07饶广
饶 广
(内江职业技术学院信息与电子学院,四川 内江 641100)
0 引言
目前,工业控制网络应用范围逐渐扩大,在3D模拟、数控机床工作以及数据传感等领域呈现多样化发展趋势。随着工控网络处理数据量的不断上升,与网络搭载的多种平台均离不开云计算和大数据技术。这两种技术作为数据处理的核心和前提,具备较强的数据转换、数据模拟以及数据分类等能力。由于云计算异构工业控制网络中存在多种结构类型数据,并且多源节点之间的工作环境和负荷要求均不相同,导致网络中容易出现泄漏和故障点。这会造成网络入侵现象,从而影响网络整体运行的稳定性和安全性。根据工业控制网络的环境和运行特点对多源目标进行入侵自动识别,可改善工业网络运行环境。
结合目前研究现状,多位研究者给出了相关入侵目标解决策略。文献[1]提出1种基于主动学习的工业互联网入侵识别检测方法。该方法建立主动学习系统,通过系统提取工业网络相关节点数据并将数据引入学习查询策略中,从而通过入侵网络参数查询完成入侵识别。由于多源工业网络中存在多种干扰因素,该方法只考虑了单一入侵种类的识别,导致识别方法限制过多、误差较大。文献[2]采用1种融合动态贝叶斯网络(dynamic Bayesian network,DBN)和双向长短期记忆(bidirectional long short-term memory,BiLSTM)的工业互联网入侵识别方法。该方法首先采集互联网数据进行预处理,然后根据非线性特征和信赖数据提取各节点特征,接着建立BiLSTM分类器进行分类处理,最后通过阈值比对的方式完成识别。该方法没有划分入侵目标特征,导致逐步比对的整体耗用较高、实际应用效果较差。文献[3]提出1种基于特征选择的工业互联网入侵检测分类方法。该方法首先预处理数据集,利用皮尔逊相关系数评估特征之间的相关性,以确定最佳阈值;然后利用机器学习和深度学习进行二分类和多分类试验,并进行全面评估。该方法的有效性在真实的工业互联网实践中得以验证。文献[4]提出1种无需依赖于协议和特定领域的工业入侵检测方法。该方法不限于特定的领域或协议,可以在受限的区域执行。但是该方法在面对多种网络攻击环境时不能完成精准识别。
异构工业控制网络多源目标特征不断变化,且特征具有起伏性,导致入侵识别精准度较低。针对该问题,本文提出1种云计算下的异构工业控制网络多源目标入侵自动识别方法。该方法通过设定归一化入侵特征空间,将所有网络数据转换到该空间内,并根据最大值和最小值对超出范围的数据进行归一化处理。在入侵特征提取方面,该方法选择时域矩阵偏度特征、峰度特征和包络起伏度特征作为不同类别的入侵特征。针对工控网络,该方法计算3种特征数据的大小。基于这些特征表现参数,该方法将入侵数据样本转换为聚类中心值,并计算待识别目标与聚类中心之间的欧氏距离。根据欧氏距离的大小,该方法可以自动识别入侵目标。本文方法专门考虑到了不同特征数据之间的表达差异,可根据不同数据特征给出不同的识别阈值,因而环境适应性较强、应用效果较好。
1 多源目标数据归一化处理
异构网络和多源目标的特征种类较多,因而受环境影响因素较大。为了改善异构数据对目标识别的混淆影响,需要提前采集网络节点数据,并进行归一化处理。数据归一化处理的过程为:首先将工业控制网络中的冗余数据全部剔除,然后按照属性特征将数据映射到特定的高纬空间中,以便后续特征的提取和入侵目标的识别。
在多源目标入侵自动识别过程中,入侵特征目标识别是关键和重点环节。为提高识别对比范围和精准度,本文分析几种目前常见的目标类型,以便实现高精度的识别对比。
工业控制网络多源入侵目标类型特征如表1所示。

表1 工业控制网络多源入侵目标类型特征
根据表1,本文进行特征差异的归一化处理。归一化处理的目的是消除多源和异构数据之间的特征差距。本文设定归一化后的样本特征空间为[0,1]。
(1)
式中:f(x)为异构工业控制网络中分布在[0,1]区间内的特征属性值;xmax、xmin分别为属性特征x的最大值和最小值。
完成归一化处理后,本文提取网络入侵信号特征参数。
2 网络入侵信号特征参数提取
在完成异构工业控制网络数据归一化处理基础上对具有标识的节点进行特征提取,是实现入侵识别的重要基础。本文给出时域偏度、时域峰度、包络起伏度这3种入侵特征值类型。这3种类型涵盖了异构工业控制网络中的大部分入侵种类数据特征。本文将其作为特征提取的关键阈值,对不同类型数据进行特征提取。具体操作步骤如下。
①基于时域偏度的特征提取。
由于网络存在自我保护机制,其中的不同数据的时域表达各不相同,导致时域变化差距较大[5]。本文设定工业控制网络的时域波形偏度变动范围,并对该范围内的网络节点进行特征提取。工业网络时域信号偏度值a′为:
(2)
式中:β为时域信号在观测周期内的振动幅值,db;σ为信号在观测周期内的振动标准差值,db;E为信号幅度均值,db;(x,y)、(x″,y″)分别为普通信号和时域信号[6],db。
②基于时域峰度的特征提取。
通常情况下,正常信号和干扰信号之间的信号峰值差距较大,陡峭程度和峰值大小之间存在关联关系[7]。因此,在时域峰度特征提取过程中,需要对信号进行时域分离,从而得到普通信号和入侵信号之间的特征差异。在观测周期f内,各信号之间的工业网络时域信号峰度b′为:
(3)
式中:β″为时域峰值信号在观测周期内的振动幅值,db;σ′为时域峰值信号在观测周期内的振动标准差值,db;E″为时域峰值信号的幅度均值,db。
③基于包络起伏度的特征提取。
基于异构工业控制网络中干扰信号的走势,本文根据信号的波动程度观测周围信号的峰值变化程度。由此可得网络中全部信号的包络起伏度特征Y1。
(4)
式中:R为包络起伏度。
本文按照式(4)提取具备时域偏度、时域峰度以及包络起伏度特征标记的信号值,并以此作为后续信号特征峰分离的依据[8],从而实现入侵自动识别。
得到上述信号特征值后,本文利用卷积神经网络进行信号特征分离[9]。用于信号特征分离的卷积神经网络结构如图1所示。
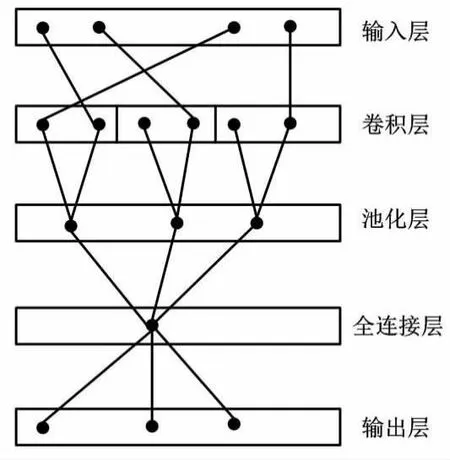
图1 用于信号特征分离的卷积神经网络结构
3 多源目标入侵自动识别方法实现
根据网络入侵信号特征参数提取结果,在云计算环境下,由于异构工业控制网络中的数据量和基数较大,入侵目标识别相对困难且会受一定影响。为保证自动目标识别的精准度和效率,本文以异构网络和多源目标为切入点,对采集的数据特征进行统计与分类。本文建立入侵自动识别模型,通过特征分类完成自动识别。实现多源目标入侵自动识别方法的伪代码如下。
Input:Data initialization,
Ouput:The results of SPEA2.
1x=(x1,x2,x3,…,xN)
2f(x)=1
3 disMatrix=CalDistancetoOthers(A);
4 EISE
Delete(second);
END IF
END WHILE
在上述伪代码的基础上,本文描述分类方法实施过程。
(5)
式中:δa、δb、δc、δd均为网络中的原始特征数据;er为特征参数;e1为首位特征;D1、D2均为向量集合;c1、c2为不同位置的隶属度系数[10];A1~A4为不同的聚类位置数据。
通过式(5)可得数据特征与聚类中心的欧氏距离,由此判定不同数据能否归类到同一识别区域范围内。特征之间的关系函数F(n)为:
F(n)=er×(A1+A2+A3+A4)
(6)
通过式(6)可判定出工业网络中不同特征数据之间的相对关系。通过特征之间的对应关系,可以识别入侵目标,并统一处理相同特征,从而大幅降低识别时间、提高识别效率。
根据上述过程进行整合处理,即可确定入侵目标函数。本文设定识别的最大迭代条件,并根据阈值对比判定网路中是否出现异常或被入侵。识别过程如下。
①设i={ia,ib,ic,id}为工业网络中采集到的原始数据值;i1~i4为网络中的异常数据;{A,B,C,D}为聚类中心。其中:i1为迭代处理的最大基数数据;i4为迭代处理的最小基数数据。
②根据工业网络现场实时数据更新{A,B,C,D}。
③对网络中的异常数据i1~i4进行迭代比对处理。
④将数据i1~i4与聚类中心进行对比。
⑤按照式(7)完成入侵数据识别。
(7)
式中:Sx为入侵判定阈值。
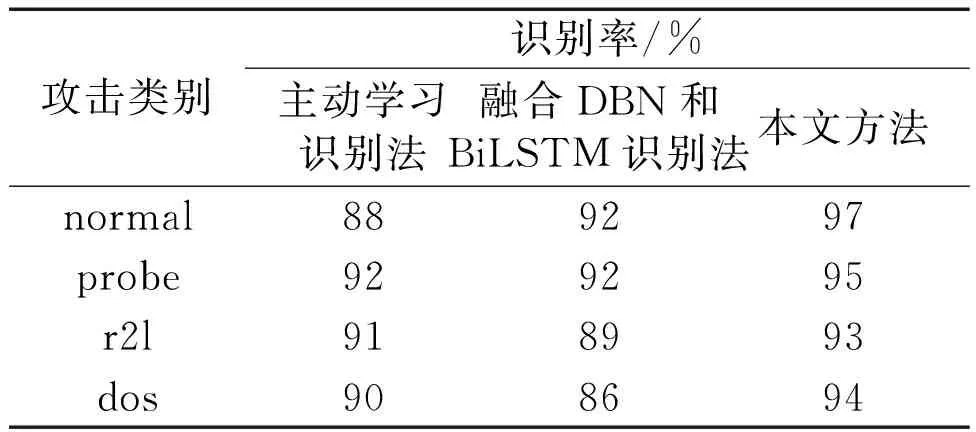
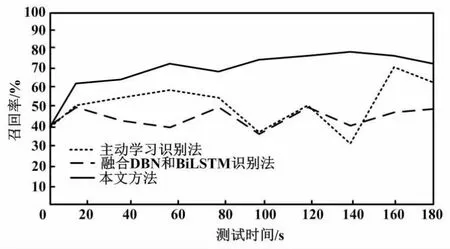
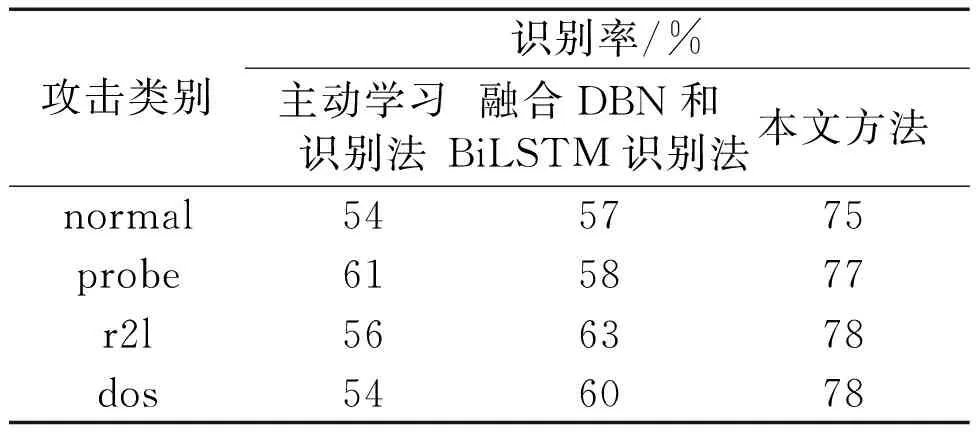
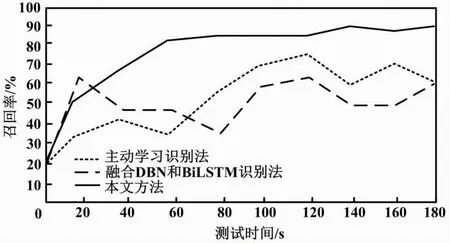
当Sx 为确保试验的有效性,本文选取了来自美国某大学的工业网络数据库作为试验数据集。该数据库具备一定的标准性和公正性。其中包含众多种类的数据,且数据规模较大,能够满足试验高质量需求。每条数据均以X=(x1,x2,…,xn,yn)的形式进行储存。其中:xn为测试数据的特征值;yn为该数据在网络中的标签属性值。测试数据集中包含32个特征属性以及1个决策属性值。由于数据特征之间具有离散性,需要在识别前进行预处理。试验所使用的数据集相关参数如下:传输数据的速率为54 Mbit/s,实际吞吐量为25 B/s。工作制式采用正交频分复用(orthogonal frequency division multiplexing,OFDM)模式。射频波段为5 GHz。这些参数与无线通信系统中的通信协议和频率相关。传输数据的频率范围频宽设置为20 MHz,带宽设置为5 MHz。试验数据集中的数据量大小空间流量设置为 8 GB/s,网络节点为32个。 为有效验证入侵自动识别方法的有效性,本文使用识别率和召回率这2个指标进行分析。在测试环境中,本文选择2个测试样本集(即5 000个数据量和20 000个数据量)进行测试,并与文献[1]基于主动学习的工业互联网入侵检测方法、文献[2]融合DBN和BiLSTM的工业互联网入侵检测方法进行对比。在测试过程中,识别率和召回率的计算式如下。 ①识别率JC为: (8) 式中:TP为被模型检测为正的正样本数,个;TN为被模型检测为负的负样本数,个;FP为被模型检测为正的负样本数,个;FN为被模型检测为负的正样本数,个。 ②召回率CH为: (9) 试验给出了normal、probe、r2l以及dos这4种网络攻击类别,其中包含黑客、入侵、篡改、木马以及其他。normal作为普通攻击手段,主要通过篡改进行入侵。probe为探测攻击,通过查找网络薄弱点进行入侵。r2l为时间流量攻击,针对时间节点进行入侵。dos为黑客攻击,通过输入病毒造成网络瘫痪。不同方法入侵自动识别率对比结果(5 000个数据量)如表2所示。 表2 不同方法入侵自动识别率对比结果(5 000个数据量) 不同方法入侵识别召回率对比结果(5 000个数据量)如图2所示。 图2 不同方法入侵识别召回率对比结果(5 000个数据量) 由表2、图2可知,在5 000个数据量的测试环境下,3种方法的识别率和召回率差异不大。但通过细节对比可知,在多种攻击类型下,本文方法的识别率和召回率略高于其他2种方法。其原因是本文方法利用特征之间的关系函数判定出工业网络中不同特征数据之间的相对关系,并通过该关系进行入侵目标识别。在识别过程中统一处理相同特征的数据,一定程度上有利于提高识别率和召回率。由此可知,本文方法的识别精准度和效率更高。 不同方法入侵自动识别率对比结果(20 000个数据量)如表3所示。 表3 不同方法入侵自动识别率对比结果(20 000个数据量) 不同方法入侵识别召回率对比结果(20 000个数据量)如图3所示。 图3 不同方法入侵识别召回率对比结果(20 000个数据量) 由表3、图3可知,在20 000个数据量下,3种方法的识别结果存在较大差距。其中,识别率和召回率依旧是本文方法最高。在大部分攻击类型中,本文方法均能保证较好且稳定的识别结果、保证识别精准度和效率不受环境中其他因素影响,从而在短时间内完成精准的入侵自动识别。其原因是本文方法以异构网络和多源目标为切入点采集网络数据,对采集的数据进行统计与分类,以建立入侵自动识别模型。通过行为特征完成自动识别,可大幅降低识别时间、提高识别精准度和效率。 工业控制网络运行安全是实现网络在更多领域得到广泛应用的重要基础。本文根据工业网络运行特点,提出1种异构工业控制网络多源目标入侵自动识别方法。该方法结合当下异构网络环境特点,采用归一化数据管理,经过处理可大幅提升后续自动识别的效率并降低误差。识别方法以网络信号入侵矩阵峰值、偏度以及包络度为对比指标,通过计算各节点与入侵聚类中心之间的距离来判定识别结果。试验数据也证明了本文识别方法具备一定的有效性。在5 000个数据量环境和20 000个数据量环境下,本文方法的识别率和召回率更高。4 性能测试
4.1 测试数据集
4.2 识别率和召回率对比结果
5 结论
