基于概率图与功率优化模型的户变关系识别
2024-05-07胡慧琳孙智卿金旻昊
胡慧琳,李 梁,孙智卿,宣 羿,金旻昊
(1.上海电力大学电气工程学院,上海 200090;2.国网浙江省电力有限公司杭州供电公司,杭州 310014)
随着新型电力系统的不断发展,对配电网供电满意度提出了更高的要求。低压配电网位于配电网的末端,直接面向用户供电[1],其运行维护管理的智能化水平和精益化水平将直接影响用户满意度的高低[2]。户变关系是指配电变压器与其供电的终端用户间的电气连接关系,目前,低压配电网的户变关系信息管理依赖人工维护,不仅费时费力,而且精度不高,无法实时更新[3]。准确的户变关系是线损管理、负荷均衡、故障抢修、三相不平衡维护等业务开展的基础和保证[4-5]。一方面,低压配电网点多、面广、量大,面对的用户数量庞杂,导致户变台账管理混乱;另一方面,电网建设和发展引起的频繁变动(如迁建、扩容、割接、布点),导致户变关系信息不能及时更新。低压配电网户变关系识别方法包括信号注入和数据驱动两种。信号注入法通过用户处的信号发生单元发出载波信号,配变处信号汇集单元接收信号来实现户变关系识别,不仅需要安装额外的设备,增加投资,而且受环境因素影响大,准确率不高[6]。近年来,随着智能电表的普及,积累了海量低压配电网的数据,数据驱动的方法开始出现,已被应用在户变关系识别领域[7]。
基于数据驱动的户变关系识别方法主要分为3 类:①基于配变与用户电压曲线相似性分析的方法,采用皮尔逊相关系数[8]、导数动态时间规整DDTW(derivative dynamic time warping)算法[9]、离散弗雷歇距离[10]、T型灰色关联度[11]度量配变与用户电压时间序列曲线的相似性进行户变关系识别;②基于同一配变供电用户的电压特征相似的聚类方法,采用K-medoids 聚类[12]、K 均值聚类[13]、谱聚类[14]、综合层次聚类BIRCH(balanced iterative reducing and clustering using hierarchies)[15]、基于密度的聚类算法DBSCAN(density-based spatial clustering of applications with noise)[16]等进行户变关系识别。然而,低压配电系统供电范围小,用户用电行为相似,导致电压波动近似,难以仅通过电压相关性分析识别;③基于能量平衡原理的方法,利用功率数据[17]和电量数据[18]构建损耗最小的优化模型实现户变识别。该类方法的优化参数维度受用户数量影响,随着用户数量的增加,鲁棒性降低。
综合以上分析,本文提出一种基于概率图与功率优化模型的低压配电网户变关系识别方法。首先,利用马尔可夫随机场MRF(Markov random fields)概率图模型来描述终端用户间的电气关系,系统地分析用户间电压的相关性;然后,将电压相关性高的用户归集为新的用户,得到聚类后的用户集合作为下一步优化模型的用户集输入,在避免低功率或零功耗用户影响的同时,有效降低用户数量,减少优化计算维度;最后,基于功率平衡原理建立配电变压器与用户集合的功率优化模型,实现低压配电网户变关系的准确识别。并通过实际数据和现场验证,证明所提方法的有效性和鲁棒性。
1 低压配电网户变关系概况及识别基本原理
1.1 户变关系基本概况
图1 给出了整个中、低压配电系统的拓扑结构。变电站通过10 kV电缆或架空线向配电变压器供电,每个配电变压器向其供电区域内的终端用户供电。配电变压器及其供电的终端用户构成一个低压配电网。户变关系是指终端用户与配电变压器之间的电气连接关系,即每个配电变压器及其供电的终端用户之间的隶属关系。实质上,户变关系识别就是为了确定配电变压器供电的用户。
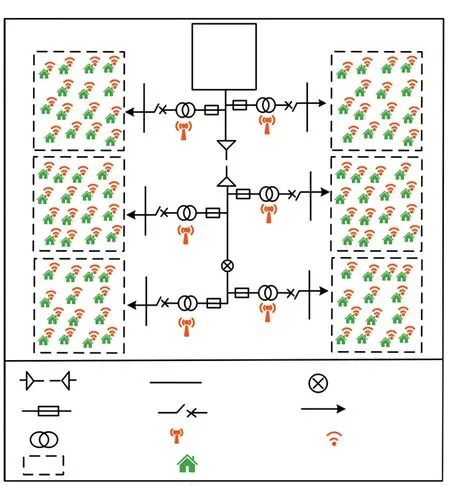
图1 户变关系表示图Fig.1 Diagram of transformer-customer relationship
随着高级量测架构的普及,电网公司可以从配变终端获取配电变压器的电压、功率量测数据,从智能电表获取终端用户的电压、功率量测数据。这为低压配电系统的户变关系识别提供了数据基础。但是,由于量测设备和通信环境的限制,不同的量测装置获取的量测数据存在误差大、精度不一致、时间不同步等问题,对数据驱动的户变关系识别也增加了挑战。
1.2 户变关系识别基本原理
1)电压相关性原理
终端用户电压受基尔霍夫定律和欧姆定律的制约,因此在本质上是相互关联的。连接到同一个配电变压器的用户具有更紧密的电气连接,更相似的电压曲线和更强的电压相关性。图1中,在同一个配电变压器供电区域内,用户的电压时间序列曲线往往更相似。然而,电气距离长的用户,不在一个供电区域内的用户,其电压曲线的差异性较大。因此,配电变压器和用户之间的物理连接关系可以通过分析用户节点之间的电压相关性来确定。
2)功率平衡原理
在任意时刻,配电变压器提供的功率和其供电区域内的终端用户消耗的功率都是平衡的。但由于不可避免的线路损耗,在下游方向的功率会略有下降。因此,可以构建优化模型,使线路损耗最小,找到配电变压器和用户之间的物理连接关系。即
式中:Pjt为t时刻第j个配电变压器的功率;Ωj为第j个配电变压器供电的所有用户集合;Pit为t时刻第i个用户的功率;γ为由线路损耗、量测、噪声等造成的误差。
1.3 户变关系识别流程
图2 给出了户变关系的识别流程,其具体步骤如下。
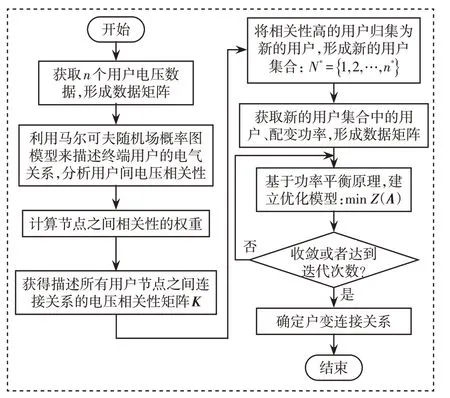
图2 户变关系识别流程Fig.2 Flow chart of transformer-customer relationship identification
步骤1获取n个用户电压数据,经过处理成电压数据矩阵。
步骤2利用MRF 概率图模型来描述终端用户间的电气关系,系统地分析用户间电压的相关性。
步骤3计算节点之间的相关性权重,获得描述所有用户节点之间的电压相关性矩阵K。
步骤4将相关性高的用户归集为一个新的用户,形成新的用户集合。新用户的功率为归集全部用户的功率总和。
步骤5获取新用户的功率与配变的功率,经过处理成为功率数据矩阵。
步骤6基于功率平衡原理,建立优化模型。
步骤7根据优化目标,求解优化变量,直至收敛或者达到迭代次数。
步骤8输出表示户变连接关系的矩阵A,获得识别的户变关系。
2 户变关系识别方法
2.1 基于概率图的电压相关性用户归集
电压相关性反映了用户之间的相互依赖性或电气距离。一般来说,连接到同一台配电变压器的用户有更紧密的电气连接和更强的电压相关性。首先,利用MRF 来映射多个低压终端用户的整体电气关系。然后,提出基于MRF 的概率图模型,来获得用户之间的电压相关性。最后,对相关性高的用户进行归集。
假设低压配电网有n个用户形成用户集合,利用智能电表上传的数据,选择固定时间间隔(通常15 min 为1 个量测点)的F个量测点的电压测量数据,形成n×F电压数据矩阵,即
式中:V为n个用户电压数据向量集合;vi为第i个用户的电压数据向量;vit为第i个用户的第t个时间点的电压数据。
利用MRF构建概率图模型来描述用户节点的连接关系。用户节点连接关系的MRF模型可定义为
式中:σ为一组代表所有用户的节点;δ为一组边,代表这些节点之间的联系;Φ、Ψ为概率图中的势函数,描述用户节点和边缘变量之间相关性。
对于有n个终端用户的低压配电网,势函数Φ和Ψ的指数形式分别定义为
式中:e为指数形式;i∈σ为概率图的节点;(i,j)为节点i和j之间的边,代表节点i和节点j之间的关联性。为了简单表示,将其进一步定义为
式中:Li为节点i的权重为节点i和节点n之间的关联性;Wij为节点i和节点j边的权重;为节点n与节点i和节点j边的关联性;L={Li|i=1,2,…,n} 、W={Wij|(i,j)∈δ} ,L和W中的元素代表电压向量V元素之间的关联性。
根据MRF建立的电压变量联合概率分布为
式中:H为归一化因子,确保P(Y)构成概率分布,并定义为V所有可能赋值的和;P(Y)为联合概率分布。MRF 模型描述了用户电压变量的联合概率分布,通过学习MRF模型的参数L和W可以获得用户节点的电压相关性。
似然估计是获取参数的最优方法,模型参数Θ=(δ,L,W)的对数似然定义为
学习模型参数的问题就等价于最大似然估计的问题,即
最大似然估计法存在两个显著的缺点:①涉及计算全局分区函数,在计算上难以处理并且需要大量时间进行计算;②在有限数据的情况下,由于模型中存在大量参数,最大似然法可能会过度拟合训练数据。为了克服以上缺点,伪似然[19]被用来近似真实似然函数,即
式中,i*为用户节点i的所有相邻用户节点集合。此外,还添加了范数正则化作为惩罚项,以避免参数训练过程中的过度拟合问题。V的范数可表示为
惩罚项定义为
式中,α、β均为正则化参数,用于确定较高权重的惩罚程度。因此,最终目标函数可修改为
采用梯度下降法求解目标函数,得到边权参数W,节点间相关性的权重由指数函数定义为
式中:u,v={1,2,…,n} ,u≠v;为Wij中的元素。
获得描述所有用户节点之间整体连接关系的电压相关性矩阵为
式中,对角线元素设置为0。K中元素的值反映了用户节点之间的电压相关性。具有较高电压相关性的用户连接到同一配变,根据得到的用户电压相关性矩阵K,将相关性最高的用户归集为新的用户,形成新的用户集合N*={1,2,…,i,…,n*} 。例如,用户节点1与用户节点2相关性最大,用户节点2与用户节点3相关性最大,则这3个用户节点归集为一个新的用户节点。因此,形成新的用户集合减少了用户数量,为下一步识别优化模型大大降低了计算维度。
2.2 基于功率平衡的户变关系识别优化模型
根据形成新的用户集合N*={1,2,…,i,…,n*}和配变集合M={1,2,…,j,…,m} 构建户变关系数学模型,设置所有配变和用户之间的连接关系为邻接矩阵A,将其表示为
式中:n*为用户数量;m为配变数量;Aj为第j个配变和所有用户的连接关系矩阵;aji={ }0,1 为第j个配变和第i个用户之间的连接关系,若用户i属于配变j,则aji=1;若用户i不属于配变j,则aji=0。
建立基于功率平衡的户变关系识别优化模型,通过优化邻接矩阵的二进制变量,找到最优解能够满足功率平衡的要求,从而获得准确的户变关系。
以配变和新用户的功率作为输入,将其表示为
式中:Pcu为新用户功率矩阵,新用户功率是归集用户的功率和;pit为t时刻第i个用户的功率;pjt为t时刻第j个配电变压器的功率;Ptf为配变功率矩阵。
构建基于功率平衡的户变关系识别模型为
式中,γ为由线路损耗、测量、噪声等引起的误差矩阵。
户变关系识别问题本质上为配变与用户对应关系变量的整数规划求解问题,构建优化模型为
式中:Pjt为t时刻第j个配变的功率;PLt为t时刻的全部用户功率,PLt=[p1tp2t…pit…pn*t]T;Z(A)为功率损耗系数。
利用求解器进行对户变关系优化模型求解,能够直接输出模型的优化解,满足功率平衡的要求,从而获得代表用户与配变之间连接关系的邻接矩阵A。
3 案例分析
本文选取浙江某地区的小区包含8 个配变,451 个用户,采集2022 年3 月1 日—7 日每天96 个时间点(15min一个点)的功率量测数据和电压量测数据。首先,对基于MRF 概率图的用户电压进行相关性分析;然后,分析基于功率平衡原理的户变关系识别结果,并对有无电压相关性归集识别结果的影响进行分析;最后,对不同方法的识别结果比较分析,证明了本文方法的有效性、鲁棒性和可行性,能够应用在工程实践且具有一定的指导作用。
采用识别准确率作为评判户变关系的指标,将识别结果和现场核查结果进行比对。以浙江某地区小区的现场实际情况为例,T1—T8 表示配变,C.1—C.451表示用户。
3.1 基于MRF 概率图的电压相关性分析
利用用户电压数据,根据MRF 构建概率图模型来描述终端用户间的电气关系,系统地分析用户间电压的相关性,从而获得用户节点间的电压相关性。同时,计算用户电压曲线之间的皮尔逊系数来度量节点间的电压相关性。两种方法的电压相关性可视化热力图如图3 所示。根据现场用户实际情况按照各个配变供电用户顺序排列。
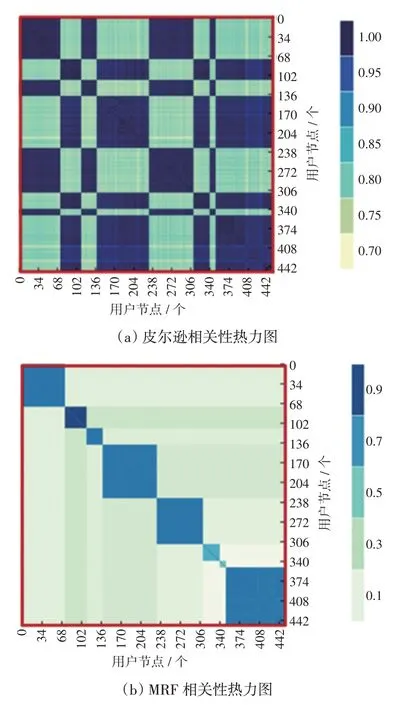
图3 节点间电压相关性热力图Fig.3 Heat map of correlations between voltages at different nodes
热力图颜色越深,代表用户之间的相关性越强。图3(a)为采用皮尔逊系数来度量用户节点的相关性,可以发现计算出的同一配变供电下的用户相关性系数高,但和其他配变供电的用户相关性系数也很高,导致无法找出配变和用户之间的连接关系。造成方法效果差、准确率低的原因可能为:①计算皮尔逊系数方法对低压配电网中的数据质量问题具有较低的抵抗力,从而无法适应低压配电网的复杂情况;②不同配变供电的终端用户的相似电压曲线可能导致错误的识别。
图3(b)为基于MRF概率图模型获得用户节点的电压相关性,可以发现由同一配变供电的用户电压相关性更强,能够明显区别其他配变供电的用户。由图3(a)、(b)对比可知,基于MRF 概率图的电压相关性方法比皮尔逊相关系数法能够更准确地计算出用户间的电压相关性。基于MRF 概率图的电压相关性方法获得的相关性高的用户由同一个配变供电。
根据MRF 概率图的电压相关性方法获得相关性高的用户,归集为新的用户,归集的用户都是确定属于同一个配电。表1 为归集后各配变供电用户数量。由表1可知,经过计算电压相关性将用户进行归集,归集后各配变供电的用户数量大幅度减少,从451 个用户减少到只有67 个用户,为后续户变关系识别模型大大减少数据量。

表1 归集后各配变供电用户数量Tab.1 Number of customers supplied by each distribution transformer after aggregation个
3.2 本文方法的识别结果分析
户变关系识别结果如图4 所示。由图4 可知,本文提出的方法,将446个用户都准确匹配到对应的配变,识别准确率达到98.89%。然而,没有经过电压相关性归集用户,只是基于功率平衡建立优化模型进行识别的方法并不能准确识别户变关系,只能将一部分的用户准确匹配到对应的配变,识别准确率只有70.07%。由于低压配电网用户数量大,只利用功率数据建立优化模型,可能造成维度爆炸,难以找到最优解。
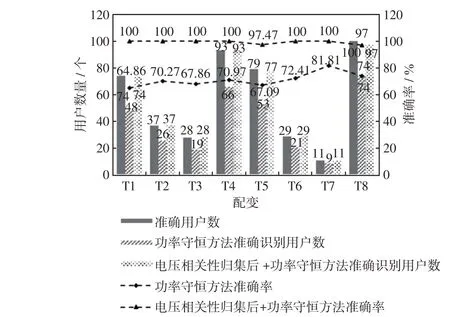
图4 户变关系识别结果Fig.4 Identification results of transformer-customer relationship
设置优化模型迭代次数20 000,选择配变T4功率曲线、归集后优化识别出配变T4 供电的用户功率和曲线,以及未归集优化识别出配变T4 供电的用户功率和曲线可视化。配变与用户功率曲线如图5所示,由图5可知,经过归集后优化识别出配变T4 供电的用户功率和与配变T4 的功率误差很小,两条功率曲线波动一致,表示获得的识别结果正确;未经过归集优化识别出配变T4 供电的用户功率和与配变T4 的功率误差很大,两条功率曲线波动不一致,表明没有识别出全部准确的用户。通过对比可得,本文提出的方法能够准确将用户匹配到对应的配变,有很高的识别准确率。
3.3 不同方法识别结果比较分析
不同方法的识别结果统计如表2所示。在表2中基于用户电压特征相似的各种聚类方法和基于电压曲线相似方法的识别准确率均只能达到80%左右。在实际工程中,低压配电网获得配变的电压数据精度低于用户的电压数据,从而给度量配变与用户电压曲线相似性增加了困难,造成基于电压曲线相似的方法识别准确率不高。同时,由于有些配变电气距离相近,导致存在不同配变供电的用户间的电压特征相似,从而基于用户电压特征相似的聚类方法难以区分电压曲线相似的用户,无法将全部用户准确匹配到对应的配变。

表2 识别结果统计Tab.2 Statistics of identification results%
由表2 可知,基于能量平衡的优化方法的识别准确率只有70.07%,因为用户数量多,造成输入优化模型的数据维度庞大,难以找到最优解,甚至可能无解。利用地址聚类+GMM聚类+关联卷积优化的方法有90.69%较高的识别准确率,但该方法用到地址信息并不能减少很多的用户数量及地址信息相近的用户可能是属于不同配变供电,导致这样的用户进行合并会造成识别错误。同时,这种方法用到聚类及配变电压数据和聚类的簇进行匹配,配变电压数据精度不高,导致识别准确率还有待提高。本文提出的基于MRF 构建概率图模型能够最大程度的计算用户间的电压相关性,确保电压相关性强的用户属于同一配变进行归集,再进行功率平衡优化,能够获得98.89%的识别准确率。不同方法的计算时间如表3所示,由表3可知,本文提出的方法能够大大降低计算时间,提升识别效率,可应用于工程实践中。

表3 不同方法的计算时间Tab.3 Calculation time of the different methods
4 结 论
本文提出了一种基于概率图与功率优化模型的低压配电网户变关系识别方法,解决了由于人工维护,户变关系不能及时更新,造成户变关系不准确的问题,能够为实际低压配电网管理提供一定的指导作用和提供户变关系识别新的研究思路。本文的主要贡献如下。
(1)提出基于MRF 构建的概率图模型来描述终端用户间的电气关系,系统地分析用户间电压的相关性.将相关性高的用户归集成新的用户,形成新的用户集合。进一步优化模型的用户集输入,在避免了低功率或零功耗用户影响的同时,有效降低了用户数量,减少了优化计算维度。
(2)利用新用户集合的功率数据,建立基于功率平衡的优化模型能够准确识别户变关系,克服配变电压数据精度不够,用户电压曲线相似而造成识别准确率不高的困难。
(3)提出的户变关系识别流程框架能够适用于复杂且用户数量多的低压配电网,自动维护低压配电网台账,从而实现自动更新户变关系。
为使本文方法更具普适性,还需考虑实际工程问题,使其能够适用于电气量不同数据情况的研究;应用于更多的实际低压配电网,推进新型电力系统数字技术支撑体系的建设,推动“全面提升电网可观测、可描述、可控制能力,实现全网透明化”。
