基于图核同构网络的图分类方法
2024-04-29徐立祥陈恩红
徐立祥 葛 伟 陈恩红 罗 斌
1(合肥学院人工智能与大数据学院 合肥 230601)
2(大数据分析与应用安徽省重点实验室(中国科学技术大学计算机科学与技术学院) 合肥 230027)
3(安徽大学计算机科学与技术学院 合肥 230601)
(xulixianghf@163.com)
现实世界中的大量问题都可以抽象成图模型(graph model),也就是节点和边的集合,包括自然语言处理[1]、异常检测[2-3]、学术网络分析、生物医疗、推荐系统等.图是一种不同规则的非欧氏几何数据,图数据的结构错综复杂,包含大量的信息,比如结构信息、节点特征信息等.通过学习基于图形的嵌入表示,可以获取结构化数据的顺序、拓扑、几何和其他关系特征.近年来,图深度学习的研究是学术界和产业界的一个热点,主要集中在节点分类[4]、链路预测[5]、图分类等.本文将重点关注的是图分类任务.图分类任务的关键是学习图与对应标签的映射关系.图分类在生物化学方面有着广泛的应用,例如对一些化学分子图进行分类来判断其活性、水溶性、毒性等.因此研究图分类问题有着重要意义.
图分类的重要方法之一是图核方法,它是一种计算图之间相似度的重要方法,把一些在低维空间下非线性不可分的数据转化到高维空间中,使得这些数据线性可分,是专门针对图数据的一种特殊方法.图核函数一般是根据专家知识设计的,它考虑了不同子结构的相似性,例如随机游走核和最短路径核.不同的图核函数之间也能相互融合,例如多图核学习[6].这就为图分类引入不同的相似度度量方法和不同的偏差,从而生成具有不同性能的图分类模型.然而在缺乏专家知识的情况下,执行图分类任务时很难确定选择哪种图核函数是最好的.
随着深度学习的兴起,图卷积神经网络(graph convolution neural networks,GCN)[7]成为图数据挖掘领域最重要的方法之一.GCN 首次提出了卷积的方式融合图结构特征,提供了一个全新的视角,即在节点嵌入表示中将邻域节点的特征融入其中,与将节点特征直接通过全连接层分类的方法相比,在节点分类准确度上得到了很大提升.然而GCN 存在共享权重、灵活性差、可扩展性不强的缺点,此外当网络层数增加时,会出现过平滑现象,导致每个节点的特征结果十分相似.为了解决GCN 领域聚合时权值共享问题,带有注意力机制的图注意力网络(graph attention network,GAT)[8]被提出,GAT 具有高效低存储的优点,GAT 是基于邻居节点的计算方式,它属于一种归纳的学习方式.GAT 的缺点就是只归纳了1阶邻居,导致GAT 的感受野必须依赖深层的网络.为了解决GCN 扩展性差的问题,GraphSAGE(graph sample and aggregate)[9]提出了多种节点采样和聚合的方法,使图的嵌入表示更加灵活,当图中有新的节点加入时,固定的节点采样方式使得GraphSAGE 无需对所有的节点进行重新训练,便可获取最新的嵌入.图神经网络(graph neural network,GNN)主要是针对节点特征的更新与提取,图分类要在此基础上增加图池化的操作,图池化主要是在图节点嵌入的基础上得到整个图的嵌入,其中主流的图池化方法有2 种,即全局池化和分层池化.全局池化是在叠加图卷积之后运用全局池化操作(如最大池化和平均池化)选出能代表整张图表示的节点信息.分层池化借鉴了CNN 中的池化,每次池化都会缩小数据的规模,对于图数据来说,就是通过某种算法减少节点的数目来完成逐层的抽取,从而实现图的池化,这种算法有Top-k[10]、图聚类池化等.图神经网络用于图分类的整个过程如图1 所示.

Fig.1 The process of graph classification based on graph neural networks图1 基于图神经网络的图分类过程
为了提升图神经网络的图分类性能,近年来,一些研究人员致力于把图核与图神经进行融合,提出了许多基于图核的图神经网络框架.例如图卷积核网络(graph convolutional kernel network,GCKN)[11]采用随机游走核提取路径并投影到核空间中,然后把核空间中路径信息聚合到起始节点上.图结构核网络(graph structural kernel network,GSKN)[12]在GCKN的基础上增加了匿名随机游走核,使得提取局部子结构的能力得到了进一步的加强.这2 种框架虽然能在一定程度上提升表达能力,但提取路径的操作耗费大量时间.核图神经网络(kernel graph neural network,KerGNN)[13]也是采用随机游走核与图神经网络进行融合,与先前工作不同的是,它采用可训练隐藏图作为图滤波器,与子图进行结合,并利用图核更新节点嵌入,使得图神经网络具有一定的可解释性,降低了图核计算的时间复杂度,然而对于图分类的性能提升不大.
影响图分类性能主要有2 个方面:1)对图节点的特征编码;2)对图的结构编码.在一些化学分子图中,结构对性能的影响占比很大,这类图的性质与特定子图结构的相关性比较强,对于一些社交网络图,这类图不依赖于特定的局部结构,节点特征分布对图分类性能影响较大.基于图核的方法,对图的结构编码的方法重点关注图之间的结构相似性,本质上来说也是对图的一种结构相似性编码,因此图核方法在一些化学分子图上表现出良好的性能,但对于一些社交网络图表现出的性能相对较差.而基于图神经网络的模型更加关注节点的特征.其本质上也是基于消息传递的框架.当今的一些图神经网络框架存在3 个问题:1)在图神经网络的邻域聚合的过程中,获取了图的树形结构信息和邻域内的节点特征信息,却无法区分例如多元环等高阶子结构;2)为了获得更好的性能,图神经网络会叠加多层特征信息,但是这个层数的设置很难把握,如果设置过大,会产生过平滑问题,也即是,它使得深层的节点嵌入表示都十分相似,因此,把这些相似的节点嵌入堆叠会破坏图节点特征编码与图标签的单射关系,最终会导致图分类性能下降;3)以往图核和图神经网络融合的工作主要是采用随机游走核来提升节点获取邻域内高阶子结构信息的能力,但是这种方法的时间复杂度较大.此外,随机游走核具有不确定性,无法保证每一次游走的路径都包含了高阶子结构信息.为了解决这3 个问题,本文将WL(Weisfeiler-Lehman)[14]核与图神经网络融合起来,WL 核对图数据进行结构相似性编码,图同构网络(graph isomorphism network,GІN)[15]对图的节点特征进行编码,并将这2 部分编码通过注意力加权方式进行融合,相当于在基于消息传递的图神经网络中增加了图的结构相似性信息,提升图神经网络的表达能力.
本文的主要贡献包括4 个方面:
1)提供了一个新的视角,将WL 核应用到图神经网络领域中,通过GІN 与WL 核方法进行融合,丰富图的结构特征和节点特征,提升GІN 对高阶图结构的判别能力;
2)针对不同类型的图数据集,提出基于注意力机制的图结构相似编码和图节点特征编码的融合方法,完成两者权重的自适应学习;
3)在图核中,使用Nyström 方法构建一个低秩矩阵去近似原核矩阵,从而大大降低图核矩阵的维度,解决图核矩阵在计算中运算代价大的问题;
4)在7 个公开的图数据集上,与一些当前已知性能最好的多种代表性的图分类基准模型相比,所提出的模型在大多数数据集上可以表现出更好的性能.
1 相关工作
1.1 基于WL 核的图分类方法
WL 核是当前应用最广泛的图核方法之一,它是基于子树的图核方法,其主要思想是对图进行子树分解,使用子树间的相似度来代替图的相似度,它是一种基于1-WL 图同构测试所提出的一种快速特征提取算法,详细的操作步骤为:对于拥有多个节点标签的离散图,首先对各个节点进行邻域聚合;然后对邻居节点进行排序,与此同时,节点标签和排序后的邻居标签共同组成多重集,并对这些多重集进行压缩映射,生成对应的新标签,进而将这些新标签赋给节点,这样就完成了一次迭代.在迭代过程中,重新标记的过程以及多重集的压缩是所有输入图同时进行的,并且所有图共享标签压缩的对应关系.
具有H次迭代的2 个图G1和图G2上的WL 子树核被定义为
1.2 基于图同构网络(GIN)的图分类方法
图神经网络的任务主要是进行图节点表征学习,并基于学习到的节点表征进行下游的任务,例如节点分类或者链路预测等.而GІN 提出了图级别表示学习,即图表征学习.图表征学习要求根据节点属性、边和边的属性(如果有的话)生成一个向量作为图的表征,基于图表征可以做图的预测.基于GІN 的图表征学习主要包含2 个过程:1)计算得到图的节点特征,即每一个节点的特征依次聚合各个邻居节点的特征,常用的图神经网络节点聚集函数有求和函数、平均函数和最大化函数.2)在GІN 中,节点聚集函数选择的是求和函数,而不是选择平均函数,原因是平均函数不能识别某一节点出现的次数,不能精确描述多重集,它只能捕捉实体的特征分布,而最大化函数适合捕捉具有代表性的元素或“骨架”,而不能区分确切的结构或分布的任务.图神经网络还有其他的节点聚合函数,如加权平均、LSTM 池化等,而对判断同构问题来说,本文使用了基于注意力机制的自适应加权求和方法,此方法具有较强的表征能力.
为了实现图节点特征编码与图标签的单射,GІN使用加法作为聚合函数,并使用多层感知机来模拟函数的组合,实现每层之间的映射关系,更新GІN 节点表示函数为:
其中hG是整个图的嵌入表示,这里的读出函数分别使用了求和、求平均和MLP.
1.3 Nyström 方法
图核方法的计算代价比较大,对于一个有n个图的数据集,得到的图核矩阵是n2个元素,当n非常大时,图的结构编码维度就比较大,Nyström 方法[19]是作为一种使用简单正交规则离散积分方程的方法而被提出的,是一种广泛使用的降维方法,用于给定的列采样子集逼近核矩阵[20].Nyström 常用在核空间的计算问题中,对于一个样本集合 {x1,x2,…,xn},以及它们的核矩阵K∈Rn×n,Nyström 可通过采样的方式,构建一个低秩矩阵去近似表示原核矩阵,降低核矩阵在计算中的运算代价.Nyström 可以作为一种无监督的降维编码.同时,也可以得到核空间中样本的矩阵表示
2 图核同构网络KerGIN
本节将重点介绍KerGІN,该模型以GІN 为基础,借助图核方法,将图的结构特征和节点特征进行深度融合.本文提出的模型框架如图2 所示,整个模型分为3 个部分:GІN 编码器、图核和注意力模块,下面将对模型的每一部分进行详细的介绍.首先介绍关于图核和相关图同构网络模型的一些基本概念.一个图可以表示为g=(V,X,A),其中V={v1,v2,…,vN} 表示图节点的集合,X∈RN×d表示图中节点的特征,总共有N个节点,每个节点的特征维度都是d,A∈RN×N表示图的邻接矩阵,本文所研究的图都是无权无向图,如果节点vi与vj之间存在边,则Aij=1,否则Aij=0.对于图分类问题,给定一个数据集{(g1,y1),(g2,y2),…,(gn,yn)},其中y表示图的标签.图分类任务的目的就是学习到由图g到标签y的映射函数yg=f(g).本文使用one-hot 编码处理离散标签.例如4 个标签分别由4 维向量(1,0,0,0),(0,1,0,0),(0,0,1,0),(0,0,0,1)来表示.

Fig.2 The overall architecture of KerGІN图2 KerGІN 总体框架
2.1 GIN 编码
根据图的邻接矩阵A和图的特征X,使用GІN 对图进行编码,首先对每个节点进行邻居的采样和聚合,采样一个节点的所有邻居,聚合邻居采用求和函数,即每个节点的特征加上邻居节点的特征.节点特征采样函数和聚合函数分别为:
其中Aggregate()是采样邻居节点函数,Combine()是求和函数,因为GІN 已经证明了求和函数是单射的.进一步在k层得到的特征向量经过一个多层感知机:
2.2 WL 图核矩阵的生成
在2.1 节中GІN 已经对图进行了节点特征编码,在本节中重点关注对于图的结构特征编码.由于GІN对图的结构表征能力有限,所以引入一个图核矩阵即图的结构相似性编码来增强GІN 的结构表征能力.
图核用于计算2 个图的相似度,对于一个图数据集G={g1,g2,…,gN},计算每2 个图的核值,构成核矩阵K∈RN×N,图核矩阵中的i行表示的图与其他图gi的结构相似度,相当于对图gi的结构相似性编码,本文使用的图核是不带节点标签的WL 核,即输入2 个图的邻接矩阵A∈RN×N,不需要节点的特征或者节点的标签.如图3 所示,对于2 个原始的图,聚合其邻居节点,然后对聚合后的每一个节点进行重新的哈希编码,即对节点使用新的颜色来表示,这是进行1 次迭代所得到的结果,然后按颜色来统计所有节点的个数,这样就把图转化为特征向量,最后2 个向量之间求内积,即得到2 个图的相似度,求2 个图的核值函数为:

Fig.3 Diagram of the implementation process of WL kernel图3 WL 核执行过程图
在WL 核的计算过程中,用内积来度量2 个图的子树模式向量.本文也选取了其他常用的图核函数进行了对比实验,如最短路径(shortest path,SP)核、随机游走(random walk,RW)核,详见3.4 节,最后采用了效果最优的WL 核.
2.3 Nyström 降秩分解
在2.2 节中得到了图数据集的核矩阵,这里的图核矩阵的维度通常较大,空间复杂度为O(N2),如果图数据集的数量庞大,将导致后续的计算代价很大.Nyström 方法常用在核空间的计算问题中,通过降秩分解,可以显著降低核矩阵的维度.核矩阵K∈RN×N是对称正定矩阵,核矩阵的分解过程为:
由于降维后的核矩阵与2.1 节中GІN 编码维度不一致,在这里使用神经网络对核矩阵的维度与GІN 编码的向量对齐,定义一个2 层的神经网络,共享1 个隐藏层,为了防止梯度消失或梯度爆炸现象的出现,需要对核矩阵中的每一行进行规范化,并使用最小值中心化的方法进行归一化,再经过全连接神经网络得到图核嵌入向量hk,即图的结构编码,计算的函数表达式为:
2.4 GIN 编码和WL 核编码的融合
其中W∈Rd×d为权重向量,它可以使图的嵌入计算更加平滑,a∈Rd×1为注意力权重向量,c∈R2×1为注意力系数,H∈Rd×1为图特征编码和图结构编码的注意力加权融合后的向量表示,进一步将H输入到多层感知机或者支持向量机中进行图分类任务.
KerGІN 提取图特征的算法描述见算法1,输入为一组图数据集以及图的邻接矩阵和节点的特征.对每个图使用GІN 进行特征编码,即对每一个节点进行邻域聚合,得到节点的嵌入表示,然后把所有节点的嵌入表示加起来,这样就得到了图的表征向量.与此同时使用WL 核求每2 个图之间的核值,即对于每一个节点进行h次迭代的哈希编码,这样就把整个图映射成一个向量,将2 个图的向量表示进行内积运算,这样就得到了2 个图的相似度,也即得到了图的结构编码.进一步使用注意力机制将图的特征编码和图的结构编码进行加权求和,进而得到图的特征向量表示,并对所有的图都进行上述的操作,最后将这些图的向量表示输入到多层感知机或支持向量机中进行下游的分类任务.
算法1.KerGІN 提取特征.
3 实 验
3.1 数据集的介绍和实验设置
1)数据集.本文使用7 个公开的图分类数据集进行实验,分别为MUTAG[21],PTC[22],PROTEІNS[23],NCІ1[24],ІMDB-B[25],ІMDB-M[25],COLLAB[25].前4 个为化学分子数据集,后3 个为社交网络数据集.7 个数据集的简介为:
①MUTAG[21].该数据集包含了188 个化合物结构图,依据它们对细菌的诱变作用,可被分为2 类.图中的节点和节点标签分别表示原子和原子种类,包括C,N,O,F,І,Cl,Br.
②PTC[22].该数据集全称是预测毒理学挑战,用来发展先进的SAR 技术预测毒理学模型.这个数据集包含了针对啮齿动物的致癌性标记的化合物.图中有2 个类别的标签,分别表示有致癌性和无致癌性.
③PROTEІNS.该数据集[23]中有1 113 个蛋白质结构图,图的标签分为2 类,分别表示酶或者非酶.节点表示蛋白质的2 级结构,根据2 级结构在氨基酸序列或者蛋白质3 维空间中是否为邻居来确定节点之间边的存在性.
④NCІ1[24].该数据集是一个关于化学分子的数据集,是根据非小细胞肺癌活性筛选的,图的标签分为2 类,表示具有或不具有抗癌活性,共包含4 110个化合物的图结构.
⑤ІMDB-B[25].该数据集是一个电影合作数据集,来源于互联网电影数据库ІMDB.图中的节点表示演员,如果2 个演员在同一部电影中出现,则他们对应的节点之间就存在一条边,这些合作图分为动作和浪漫2 种类型.合作图是以每个演员为中心的网络图,图分类的任务是判断这些自我中心网络图属于动作类型还是浪漫类型.此外该数据集还有一个多类型版本.
⑥ІMDB-M[25].该数据集的任务也是对演员子网络图按电影类型进行分类.
⑦COLLAB[25].该数据集是一个关于科研合作的数据集,涵盖了高能物理、凝聚态物理和天文物理3个领域中生成的不同研究人员的自我中心网络(egonetwork)图、对应的图标签为研究人员所属的研究领域.分类的任务是确定这些自我中心网络图对应的研究人员所属的研究领域.
实验中使用的7 个图数据集的信息统计结果如表1 所示.
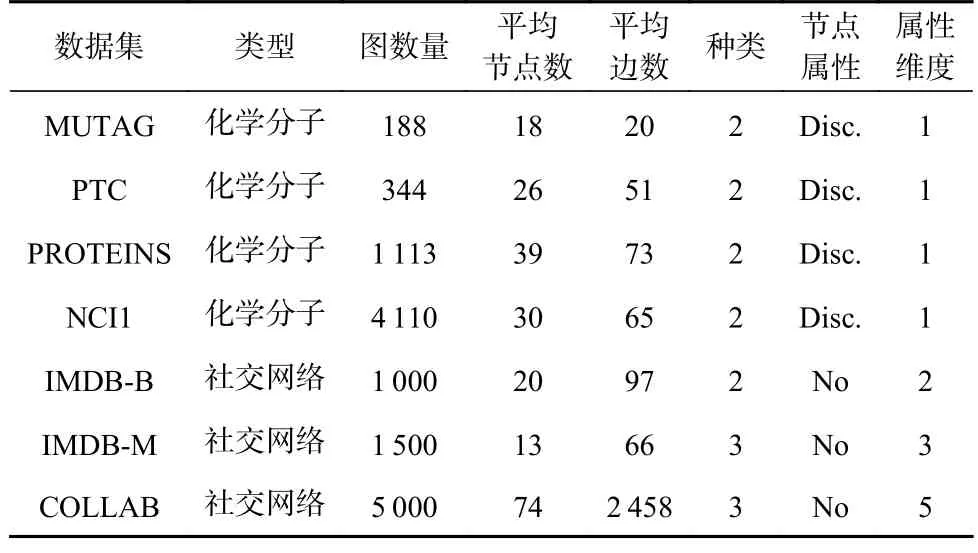
Table 1 Information Statistic of Datasets表1 数据集的信息统计
2)基准方法.本文将选择当前已知性能最好的多种代表性图分类方法作为基准方法进行实验对比,分别为基于图核的方法、基于图神经网络的分类方法、基于图池化的分类方法以及近几年一些与图核结合的图神经网络方法,以此来证明本文模型的有效性.基于图核的图分类方法有WL 核[14]和DGK 核[25],基于图神经网络的图分类方法包括GІN[15],DCNN[26],PATCHY-SAN[27].基于图池化的图分类方法有SUGAR[28]、AVCN(H)[29],SLІM[30].基于图核与图神经网络融合的图分类方法有GCKN[11],GSKN[12],GSNN[31].本文的分类任务属于有监督学习.
3)参数设置.模型训练过程中采用常用的参数设置,设置学习率lr=0.000 1,训练批次batch_size=16,epoch=600,Nyström 方法[19]中对核矩阵降秩分解后的维度d为数据集中图数量的1/2,全连接层神经网络中隐藏层维度分别为16 和8.WL 核的迭代次数h=3.数据集中90%作为训练集,其余的10%作为测试集.
3.2 实验结果
本节将在7 个数据集上对KerGІN 和其他所有基准方法进行分类评估.本文采用10 次10 交叉验证,即将数据集分成10 份,每次取1 份作为测试集,剩下的9 份作为训练集;然后对这10 次的结果求平均.每个数据集的分类准确度如表2 所示.

Table 2 Classification Accuracy on Each Public Dataset表2 在各个公开数据集上的分类准确度 %
表2 展示所有方法在7 个公开数据集的测试准确度.KerGІN 在大多数数据集上的表现优于基准方法.其中MUTAG 数据集的平均准确度为95.2%,高于除SUGAR 外的所有基准方法.与GSKN 相比,KerGІN 的准确度在PTC 数据集上提升了3.3 个百分比.在PROTEІNS 数据集上,KerGІN 的准确度相比GSKN 方法提升了6.1 个百分比.对于NCІ1 数据集,KerGІN 的准确度比GCKN 提升了4.8 个百分比.在ІMDB-B 和ІMDB-M 数据集上,KerGІN 的准确度比准确度排名第2 的GSKN 方法分别提升了1.7 个百分比和0.8 个百分比.在COLLAB 数据集上,KerGІN准确度接近于最先进的GCKN 方法.特别是在一些化学分子数据集上KerGІN 表现更突出,与最新的2个基于图核的图神经网络方法相比,KerGІN 具有更优越的性能.
为了比较不同方法的综合性能,分别统计了不同方法的平均排名,即对每一个方法,求出其在各个数据集上分类准确度的平均排名情况,相关的计算公式为:
在图4(a)中,与所有基准方法比较,KerGІN 在7个公开的图分类数据集上,相比较最优的基准方法,准确度的平均排名为1.由此可知KerGІN 的图分类性能要优于大多数基准方法.如图4(b)所示,KerGІN相较于最优的基准方法在6 个数据集上的分类准确度都有不同程度的提升.由于KerGІN 在MUTAG 数据集上没有提升,所以在图4(b)中只选择了有提升的6 个数据集进行展示.其中,在PROTEІNS 数据集上提升了7.5%,在ІMDB-B 数据集上提升了约2.1%,在PTC 数据集上提升了约3.8%,在NCІ1 数据集上提升了0.93%,在ІMDB-M 数据集上提升了1.34%,在COLLAB 数据集上提升了0.36%.

Fig.4 Average rank and accuracy improvement rate of various methods图4 各种方法的平均排名和KerGІN 的准确度提升率
3.3 消融实验
为了验证图核模块是否在整个模型中起关键作用以及MLP 对分类准确度的影响,设计了一组消融实验,即将KerGІN 模型中的图核模块(GІNMLP),与本文方法KerGІN 和基准模型GІN 进行比较.从表3 可以看出,GІN-MLP 和GІN 的图分类准确度差异并不大,说明在KerGІN 中起到关键作用的不是MLP.比较GІN-MLP 和KerGІN 模型的图分类准确度可以得出:图核模块在整个模型中起了关键作用.

Table 3 Ablation Experiment Based on MLP and Graph Kernel表3 基于MLP 与图核的消融实验
为了研究注意力机制对图分类结果的影响及注意力机制的作用,选择了2 种常见的融合策略进行对比实验,分别为拼接和求和,即把图结构编码和图特征编码拼接或者求和.如表4 所示,KerGІN-con 表示采用拼接策略,KerGІN-sum 表示采用求和策略,KerGІN-att 表示采用注意力机制策略.可以看出,采用拼接策略的分类效果不及求和策略和注意力机制策略,而采用注意力机制策略的分类准确度在这3种策略中最高.因此,在本文中注意力机制是较适宜的融合策略.这是因为不同数据集对于图结构编码和图特征编码的偏重程度不同,因此简单拼接和求和很难获得好的实验效果.

Table 4 Ablation Experiment Using with Different Fusion Strategies表4 使用不同融合策略的消融实验
3.4 实验分析
本节将分析模型训练的过程以及图结构编码和图特征编码在不同类型数据集上的变化情况.图5 展示了 MUTAG,PTC,PROTEІNS,NCІ1,ІMDB-B,ІMDB-M 这6 个数据集在训练和测试过程中的损失值随训练轮数的变化情况.为便于排版,本文选择了前6 个数据集的损失变化情况进行图例展示.这6 个数据集整体在100 个训练轮数时损失下降得比较快,在400 个训练轮数时损失下降的幅度较少,在600 个训练轮数时基本趋向于收敛.其中MUTAG 数据集在500 个训练轮数时收敛,PTC 数据集在450 个训练轮数时收敛,PROTEІNS 数据集在200 个训练轮数时开始收敛,NCІ1 数据集在100 个训练轮数时收敛.ІMDB-B 数据集大约在600 个训练轮数时收敛,ІMDB-M 在200 个训练轮数时开始收敛.6 个数据集在训练的过程中,训练集损失值和测试集损失值之间的差距很小,所以在训练过程中没有过拟合或欠拟合现象.

Fig.5 Variation of loss values for training and testing on six datasets图5 6 个数据集上训练与测试的损失值变化
任何图神经网络编码器都能用作图特征编码,本文除了实验中使用的GІN 编码器,还使用了2 种流行的图神经网络框架:GCN 和图注意力网络GAT进行了对比实验.实验结果如图6(a)所示,可以观察到GІN 的编码效果要好于GCN 和GAT.这可能是因为GІN 的图表达能力更加强大,更适用于图的特征编码.此外,又研究了图核编码器的长度对图分类性能的影响,图6(b)显示了在7 个公开数据集上16~160 的不同图核编码长度的KerGІN 的准确度.可以看出,在一定范围内,图分类的准确度会随图核编码器长度的增加而增加,当图核编码器长度大于160 时,图核编码器长度对图分类准确度的影响较小,所以在一定范围内核编码器长度对分类准确度有重要影响,因此适当降低核编码器的维度不会影响图分类的准确度.

Fig.6 KerGІN based on different graph encoders and KerGІN based on different length kernel encoders图6 基于不同图编码器的KerGІN 和基于不同长度图核编码器的KerGІN
如图7(a)所示,7 个数据集权重系数都不相同,但是可以明显看出前4 个数据集的图结构编码的权重大于图特征编码,后3 个数据集的图结构编码的权重小于图特征编码.由于前4 种图数据集为化学分子、后3 种图数据集为社交网络,因此在这2 种数据集上,图结构编码和图特征编码的权重系数不同.进一步,又探讨了不同图核函数对KerGІN 分类准确度的影响,因为图核函数的选择通常是根据专家经验进行选取,很难直接确定KerGІN 更适用于哪种图核函数,因此,本文选择了3 种类型的图核函数RW,SP,WL,并通过实验对比展示了哪种图核更适用于KerGІN 的图结构编码.在图7(b)中,由于RW 核在大数据集上运行时间过长,所以选择了在4 个小数据集上进行实验.可以清楚地看出WL 核在4 个数据集上综合表现最好,其次是SP 核,RW 核实验效果最差,此外RW 核时间复杂度比较大,在一定的时间内无法完成一些大规模图数据集的实验.
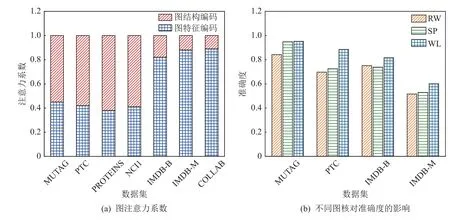
Fig.7 The weight ratio of graph feature coding and structure coding,and the classification accuracy under different graph kernels图7 图特征编码和结构编码的权重占比和不同图核下的分类准确度
通过以上实验分析可以得出,本文方法在化学分子数据集上的分类准确度比在社交网络数据集上具有明显的优势,因此本文方法更适用于化学分子的图分类任务.此外,化学分子的特性受特定局部子结构的影响较大,所以图结构编码对其分类准确度起至关重要的作用,甚至1 个局部子结构就可以成为其分类的主要依据,比如官能团(functional group).而对于社交网络数据集来说,它对图特定子结构的依赖性相对较小,而对图节点特征依赖性较大.
4 结论
本文提出了一种基于GІN、图核以及注意力机制相融合的图表征学习和图分类的方法,该方法提升了GІN 对图中特定结构的判别能力.实验结果表明,图结构编码对图分类结果影响较大,将图核作为图结构编码,在一定程度上解决了基于消息传递的图神经网络无法识别图中高阶信息的问题,本文方法能够自适应调节图特征编码与图结构编码的权重,对图分类的准确度有较大的提升,在分类准确度上优于所选的一些基准方法.
作者贡献声明:徐立祥提出了算法思路和实验方案,并撰写论文;葛伟负责完成实验验证,并整理论文;陈恩红和罗斌提出指导意见并修改论文.
