Light-HGNN:用于圈层内容推荐的轻量同质超图神经网络
2024-04-29金福生李荣华王国仁段焕中路彦雄
李 挺 金福生 李荣华 王国仁 段焕中 路彦雄
1(北京理工大学计算机学院 北京 100081)
2(腾讯科技(北京)有限公司 北京 100080)
(litingbit@163.com)
社交网络平台的繁荣为社会的生产生活提供了相当程度的便利,极大地改变了人们的生活方式和行为方式.如今,互联网上的大多数创作都是由平台上的用户发布和消费的,一个更高效、更个性化的推荐算法可以更能理解用户的意图,帮助用户在平台上找到感兴趣的内容,缩短内容生产者和消费者之间的距离,提高平台的用户粘性[1].得益于用户数据量的迅速增长,通过平台内的画像研究可以发现,偏好相似的用户更有可能形成一个相互关联的圈层,即根据特定条件或方法聚集得到的用户群体,并在圈层中倾向分享彼此的交互,从而形成自发的协同过滤推荐.这是微博和推特等公共社交网络平台中的常见现象.基于这样的社会学发现[2],在实践中,不仅要考虑用户的偏好,还要关注他们的“朋友”,即存在社交关系的用户的交互数据,以改善推荐的效果.
现有的根据关系数据进行协同过滤的思路随着图神经网络理论的发展得到了深入研究,基于普通图的堆叠方法在一定程度上可以捕获多跳的社交关系[3],相关的研究已经得到了一些优秀的结果.但在实际场景中,社交关系与用户兴趣分布的不相关性给用户表征的学习带入噪声,同时用户和项目的交互非常复杂,用户之间也存在着更高阶的复杂关系信息,这种信息无法依靠简单成对关系建模.图卷积网络层的过度堆叠容易导致中间层表征的过度平滑[4],从而在稀疏场景下的用户建模、用户相似性发现与挖掘方面能力较弱.也有些工作提出使用超图对用户之间、用户与项目之间的关系进行高维建模,但异质超图神经网络(hypergraph neural network,HGNN)多选择将用户和项目等多种不同属性的节点统一到同一个图中进行模式挖掘[5-8],其中的复杂结构增加了超图卷积操作的复杂度,并降低了模型的训练效率.另一方面,由于平台内容的快速增长和用户对平台的使用习惯不同,以腾讯微信“搜一搜”等内容平台为代表的应用产生了极大的用户活跃度和高度稀疏的生态数据分布.上述高度稀疏场景与传统场景有所不同,用户频繁交互形成的交互对象集合的重叠度极低(即交互呈现“孤岛”型分布),这提高了从交互拓扑中挖掘用户兴趣关联性的难度,对生态内的推荐算法提出了挑战,即如何完成高度稀疏数据场景下的个性化推荐任务并保证推荐效果和用户表示的可解释性.在场景中,面对根据用户所属群体的画像进行内容推荐的圈层内容推荐任务,单纯依靠拓扑关系进行图学习的现有模型很难达到令人满意的效果,且这些模型输出的用户与项目表征在可解释性上存在短板,难以胜任群体行为模式挖掘的相关任务.
出于解决高度稀疏数据场景下的圈层内容推荐和提高用户表征可解释性的任务考虑,针对圈层内容推荐任务,本文提出了一个新的轻量同质超图神经网络(lightweight homogeneous hypergraph neural network,Light-HGNN)模型,模型以项目为核心来构建连接用户节点的超边,从而构造用户节点同质超图来直接建模用户拓扑关系,降低了模型复杂性并缩小了参数规模,提升了训练的效率.如图1 所示,模型忽略用户间的关系,并根据用户的交互历史数据提取蕴含在项目中的用户的兴趣信息,并结合超图拓扑关系和项目内容表示进行编码、输出用户在表示空间的表征,改善了表示的可解释性.
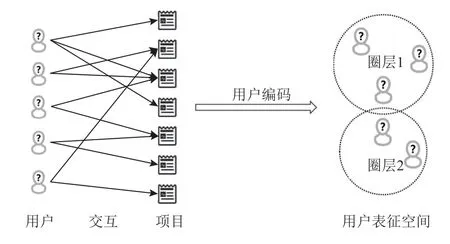
Fig.1 Іllustration of transferring interactions into circles of users图1 用户交互转化为用户圈的示意图
本文模型通过用户交互数据至超图的转化、卷积生成用户表征序列、用户表征计算与过滤来实现用户表示的编码.模型首先将用户-项目交互数据转化为只含用户节点的同质超图,并计算得到用户表征解耦序列初始值,随后根据超图拉普拉斯过滤矩阵进行信息传播与序列值的迭代生成,通过不使用激活层的卷积方法简化模型结构,并根据提出的均值差跳跃知识(jump knowledge,JK)注意力机制为每个序列值生成权重矩阵.最终,通过对解耦序列的加权求和、过滤完成对用户表示的编码.在训练阶段,本文模型通过计算采样的贝叶斯个性化排名[9]损失来优化参数,通过相关测试指标的结果来确定、比较模型的效果.
本文的主要贡献有4 点:
1)提出了一种将传统的用户-项目二元关系转化为同质超图的新方法来对用户数据进行建模.方法根据用户表征的聚类来迭代地构建同质超图,从而生成用户表征序列,使构建的模型更加轻量、复杂性更低.
2)提出了根据交互对象的内容表示构建用户的表征的方法,从而提高表征的可解释性.
3)设计了新的更轻量的均值差JK 注意力机制来生成用户表征序列对应的权重矩阵序列,并根据这一注意力机制完成高度稀疏数据条件下的圈层内容推荐任务中的编码任务.
4)在真实数据集上进行了模型对比实验,证明了模型相对更好的效果.
1 相关工作
本节主要从超图神经网络、个性化推荐以及协同过滤的相关方法与模型3 个方面回顾相关领域的研究现状.
1.1 超图神经网络
超图中的超边可以同时连接多个节点,比图结构中的普通成对关系的表达能力更强,具备了对数据的高维属性进行建模的能力.此外,图和超图之间结构的相似性使得图神经网络领域的现有方法更容易通过一些自适应调整后在超图上应用.
一些现有的工作已经证明了将图领域方法应用到超图领域的可行性与有效性.Feng 等人[10]在2019 年发表超图神经网络研究论文,在超图中实现了类似图卷积网络[11](graph convolutional network,GCN)的操作方法.Zhang 等人[12]发表了模型Hyper-SAGNN,这个模型具有灵活处理多种形式超图的能力.在后续的研究中,许多超图神经网络模型都开始借鉴其他网络模型中使用的机制,如Bai 等人[13]在研究中提出的超图卷积注意力机制,Hu 等人[14]使用拉普拉斯平滑过滤器替代冗余的权重矩阵进行嵌入表示的迭代等.这种尝试在各自针对的任务中表现出极好的适应性.
1.2 个性化推荐
个性化推荐的效果部分依赖于模型通过用户偏好挖掘得到的表示的质量.最初的尝试主要集中在分析用户的查询、点击和参与主题等记录的工作上来提取用户的偏好,并得到用户浅层兴趣和深层兴趣的合适表示.Teevan 等人[15]以及Dou 等人[16]分别在各自的工作中提出了衡量文档得分的方法,即分析用户历史操作中的点击来衡量文档的点击率.在主题的研究领域,手动设计特征的巨大研究成本促使相关研究探索自动学习文档中涉及的主题表示的方法,根据相关分析[17],许多使用排序学习方法处理组合特征的方法的效果比传统方法表现得更好.
随着推荐系统中数据量的快速增长,图与关系数据已经成为当前实践中数据源的重要组成.深度学习的发展启发了许多研究者在图表示学习任务中采用神经网络方法并取得了显著成效.Wang 等人[18]提出的神经图协同过滤(neural graph collaborative filtering,NGCF)是较为经典的编码模型之一,可以在图结构中学习嵌入表示,显式地将协同过滤信号放入到嵌入过程中.He 等人[19]完成对NGCF 模型结构解析的工作后提出了LightGCN 模型,通过简化卷积层的设计来提高其对推荐任务的适用性,得到了优于NGCF的结果.同时,基于对用户社交关系的研究也有些令人印象深刻的成果.Wang 等人[3]提出了顺序组推荐问题,并设计通过“组”这种结构来综合学习长短期用户表示.Zhou 等人[1]提出通过朋友关系网和相似搜索行为构建朋友圈,来解决用户搜索历史不足的问题.
随着研究的深入,部分研究关注到了图模型表达能力的局限,将关注点延伸至超图.Ai 等人[20]提出的模型通过在不同用户和商品的知识以及静态和动态的关系的联合建模来构建知识图谱.Liu 等人[21]利用从用户-查询-商品中学习的逻辑结构表示和在逻辑路径上的不同实体之间的协作信号来改进个性化商品搜索.Xia 等人[6]提出了一种双通道超图卷积网络,将会话数据建模为超图,并将自监督学习融入到网络训练中.Yu 等人[2]通过研究超图结构上的用户间和用户与项目间的拓扑关系构建了自监督多通道卷积网络.后续研究中Wu 等人[7]将自监督对比学习任务和推荐系统的监督学习任务相结合,提出了一种应用于用户-物品二分图推荐系统的图自监督学习框架.
但在很多情况下,社会关系的复杂性意味着社交关系与兴趣分布不一定正相关.推荐算法研究的另一个有效方向是进行元路径,即交替的实体和关系序列的研究.有些方法遵循这种思路研究了不同任务场景下异质图的元路径模式以挖掘用户潜在的搜索意图,这些工作有助于提高推荐结果的可解释性.Hu 等人[22]提出基于相关任务上下文的元路径的方法,通过使用协作注意力机制来生成基于特定交互的推荐结果.但元路径模式的设计需要大量的经验,且任务间多不能通用,如何控制元路径的长度来平衡推荐效果和计算资源成本也是制约效果的瓶颈.
1.3 协同过滤算法
在不同研究思路的协同过滤算法中,基于模型的协同过滤算法通过已知的用户和项目之间的交互来形成模型,以便推荐系统能够识别具有更高复杂度的模式,并在用户表示的帮助下获得推荐.在该研究思路上有聚类方法[23]、贝叶斯网络[24]、关联算法[25]以及奇异值分解(SVD)[26]等方法.在这些方法中,矩阵分解(MF)[27]将所有用户和物品投影到一个共享的潜在因子空间,并根据表示的内积计算结果进行预测.算法因其性能和高扩展性曾被认为是最有效的协同过滤方法之一.此外还有Rendle 等人[9]提出的使用成对log-sigmoid 函数进行优化的贝叶斯个性化排名(Bayesian personalized ranking,BPR)也是较为经典的算法框架;He 等人[28]提出了Neural MF,使用多层感知机来学习交互.
当前也有很多研究的注意力集中在用户和项目进行交互所生成的图结构中.一些工作已经产生了很好的结果,例如SimRank[29],当被相似的对象引用时,将2 个项目视为相似的对.同时其他方法如ІtemRank[30]和 BiRank[31]则是受到标签传播机制的启发.图卷积层的引入为协同过滤任务创造了另一个可行的路线.GCMC[32]将其应用于用户和项目之间的交互模型.而在另一些模型中,PinSage[33]参考了GraphSAGE[34]的思路,将卷积层结构嵌入到商业推荐系统中.而Ji 等人[8]提出的DHCF 模型尝试使用基于高阶连通性的跳跃超图卷积(jump hypergraph convolution,JHConv)方法将用户和项目表征进行同步优化,对许多现有研究都具有启发性.
2 方法介绍
本节将深入地介绍Light-HGNN 模型的结构,并基于细节具体解释如何构建模型、优化模型并将模型应用到圈层内容推荐任务中.
图2 总体展示了Light-HGNN 的结构.模型第1步根据用户和项目的关联关系将原始交互数据转化为超图,并结合项目表示矩阵完成对用户表示和用户表示序列的初始化.在第2 步生成用户表示序列的过程中,模型通过“用户聚类、同类用户交互扩展、构建超图、超图卷积”的方式迭代地生成用户表示序列,每一个轮次的超图都是根据上一个轮次生成.第3 步,整个序列经过注意力机制生成对应的权重序列.在第4 步对解耦序列加权求和、过滤得到最终的用户表示矩阵.在整个流程中,模型根据用户的聚类进行基于用户表示相似性的交互扩展,并使用超图卷积方法加强被相同项目连接的用户间的信息流动.这样将属于相同圈层用户的交互内容进行“共享”,来达到挖掘用户的显式与隐式偏好、进行协同过滤的目的.

Fig.2 Іllustration of Light-HGNN图2 Light-HGNN 示意图
2.1 定 义
定义1.圈层.圈层指根据某些条件或方法聚集起来的用户群体或用户集合.用户可以同时属于根据不同划分确定的不同圈层来进行不同任务.
定义2.朋友圈与兴趣圈.朋友圈指根据用户之间的社交关系(图3 中实线关系,如微信中的好友关系、微博等社交网络的关注关系等)构成的同质图结构,图可以不是完全图或连通图.兴趣圈是根据用户在兴趣表征空间中的分布情况构成的节点聚类(图3中圈),在每一个聚类中,用户的兴趣表示具有一定的相似性.如图3 所示.
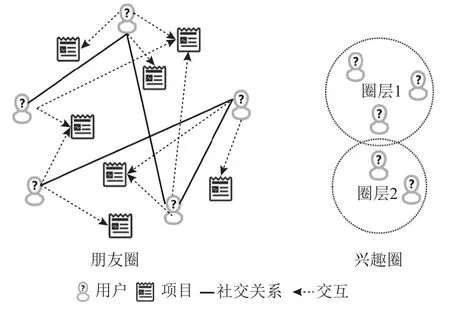
Fig.3 Іllustration of friend circle and interest circle图3 朋友圈与兴趣圈示意图
定义3.圈层内容推荐.圈层内容推荐任务属于个性化推荐任务,在圈层内容推荐任务中,模型只学习用户交互的项目的内容数据,不考虑用户间关系,输出带有圈层性的用户表征,即兴趣表示相似的用户在空间中聚集.同时,模型需要根据用户的数据输出用户的表示,对于给定的候选项序列,模型需要根据用户的表示和候选项的表示来计算候选项的分数,该分数在某种程度上预测了用户对项目的兴趣程度,或与用户可能和项目发生交互的概率正相关,从而根据分数对候选项进行排序并生成推荐.
圈层内容推荐任务可以用公式化语言进一步描述.对给定项目表征矩阵E和给定交互数据集Dataset,其中交互指用户和项目有交互,例如,用户阅读某文档是一次交互.Dataset的定义如式(1)所示.
其中Setuser,Setitem表示用户集合与项目集合,模型M应输出用户集合的表示矩阵U,并根据用户u的表示和给定候选项集D={Di| 0<i≤n}对应输出候选项集的评分集P={Pi| 0<i≤n},其中Pi=M(u,Di).
定义4.超图.一般地,一个超图可以被定义为G=(V,ξ,X,W),其中V为节点集,ξ为超边集,X∈ R|V|×F为节点表示矩阵,F为节点表征向量的维度,W为超边的权重矩阵.超图中的节点与超边的连接情况可以用关联矩阵H来描述,一般来说,每个位置为0 或1,如式(2)所示.
其中vu∈ed表示超边d连接节点u.根据超图关联矩阵,可以进一步计算节点和超边的度矩阵.
2.2 超图建模与表征序列生成
2.2.1 超图建模
1)交互数据转化为超图.最终的用户表示是由用户表征序列根据对应权重加权求和并过滤得到的,而用户表征序列是由初始值通过迭代超图建模后计算得来的.如式(1)所示的原始交互数据集Dataset中的数据,可对应地构建用户和项目的关联矩阵Hori.其具体步骤为:将矩阵初始化为|Setuser|×|Setitem|维度的零矩阵,对任意交互记录(u,d),对Hori对应位置赋值使Hori对应位置的值为1.此时可以得到原始交互数据转化来的关联矩阵.如果将每一个项目视作超边的核心,即以项目作为超边连接所有与之发生交互的用户,则可以将原始数据转化为一个超图,如图4所示,用户和项目的交互数据经处理对应构成了同质超图.以用户A,C,D与项目a发生的交互为例,在超图中的用户A,C,D将被项目a转化得到超边连接.原始数据转化得到的超图视作原始超图,Hori是它的关联矩阵.

Fig.4 Іllustration of transferring interactions data into hypergraph图4 交互数据转化超图示意图
2)用户表征序列初始化.获得超图关联矩阵Hori后,可以根据交互情况计算此时用户表征矩阵.用户u初始表示向量可以由交互项目的表示向量Ed相加得到.对用户u的初始表示向量,如式(3)所示.
其中Ed表示项目d的表示向量.项目的向量表示可以来自上游任务,对于文档、视频等内容可以是关键词的多热或独热向量,亦或采集标题后使用自然语言处理模型输出,如词向量相加,Sentence2Vec 或TFІDF 以及其他广泛接受的语料库.
对整个用户集和项目集,可以进行矩阵尺度的计算,如式(4)所示.
其中E表示项目表征矩阵,则用户表征序列可以初始化为series={X(0)}.从上述内容中可以得出,本文提出的模型以用户“交互”的对象的表示为基础进行用户编码,从而将用户与项目映射至相同的表征空间.这里的“交互”包含实际发生的交互以及扩展得到的可能交互.
2.2.2 表征序列生成
得到初始化的用户表征序列后,可以根据表示序列预设长度K和当前最新的用户表示进行超图建模从而迭代地生成完整用户表示序列.其具体做法是:首先对上一轮的用户的表示X(i-1)(1 ≤i≤K-1)中的向量进行聚类,并根据聚类标签进行用户划分.随后,在每个用户划分内部,对任意成对的用户进行交互扩展,即对每个用户对,在保留自身交互记录的同时,将自己的交互记录“分享”给对方,作为对方的扩展交互记录.由于扩展的记录并非是用户的实际交互,所以在生成交互数据时需要记录的是形如(用户u,项目d,置信度c)的三元组,其中置信度为扩展时2 个用户表示之间的相似度,采用2 个用户表示的余弦值并只取值在{0,1}(负值取0,原始交互数据中的置信度默认为1).为了减少可能带入的噪音,可以在扩展时设置相似度阈值gate来减少低相似度的扩展,扩展示意如图5 所示,以A和B构成的聚类为例,其中(A,b)与(B,a)的交互记录是根据2 个用户的表征相似性交互扩展得到的.经过这样的处理就可以将式(1)中所示的原始交互数据Dataset进行扩展,得到式(5).
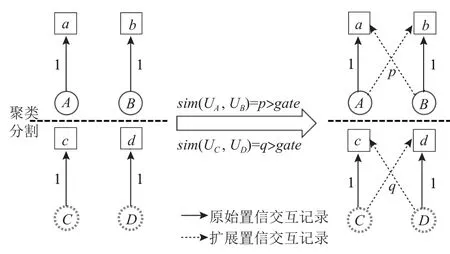
Fig.5 Іllustration of extension of interactions图5 交互扩展示意图
关联矩阵的生成和初始值生成类似,此时将置信度赋值到对应位置.对任意交互记录(u,d,c),将H(i-1)对应位置赋值使得=c.获取上一轮的经扩展后的超图邻接矩阵H(i-1),则可以根据它计算节点度矩阵和超边度矩阵对上一轮的矩阵表示进行卷积后可以得到
其中 γ为取值在[0,1]的超参数,W可以设为相对应维度的单位矩阵.γ在式(6)中起到了限制信息流入规模的作用.通过不使用激活层的卷积方法可以对表示矩阵进行快速迭代,实现模型结构的简化与轻量化.
根据文献[14]可以对式(6)进行化简,得到
其中I是单位矩阵.取超图拉普拉斯过滤矩阵
则卷积表达式经过化简,可得
通过以上过程可以扩充用户表示序列series,直至series的长度达到设定长度K.由于每一轮的邻接矩阵是变化的,从而每一轮的超图也是在动态变化的.算法1 描述了序列生成的全部过程.
算法1.用户表征序列的动态生成.
2.3 注意力机制下的用户表征输出
得到用户表征序列后的工作是将用户表征序列进行加权求和并过滤,最终得到输出的表征.这个过程可以用式(10)表述为
其中Wi表示序列中的X(i)的对应权重,MLP2表示模型中使用的第2 多层感知机,是一个由多组线性层堆叠生成的网络层.表示序列对应的权重Wi是根据注意力机制决定的.
JK 注意力机制[35]的目的是在更大尺度上为每个节点构建扩展特征,从而对序列值对应的权重学习起作用.模型构建的均值差跳跃知识(average difference jump knowledge,AD-JK)注意力机制希望在构建更广特征域的同时,提升各节点注意力信息的差异性,使序列中每个值感知其与序列均值的矢量距离.具体做法是将每一个值与整个序列均值的差值作为该值的额外信息输入至第1 多层感知机,并作为用户表征序列中每个值的特征扩展.从用户维度来看,扩展后的用户表示输入至权重激活层,并得到权重向量的输出.在获得了全部权重向量的基础上,对所有权重向量进行Softmax 处理,获得最终的权重向量序列.
通过注意力机制可以从用户的维度输出权重向量;在表示矩阵上进行操作时,可以得到表示矩阵对应的权重矩阵;通过加权和的过滤,得到最终的向量表征矩阵.
2.4 候选项评分与排序
在完成编码步骤后,可以根据用户的表示与候选项的表示来计算用户对候选项的评分.本文所述方法采用内积操作,以2 个向量的内积结果作为评分输出.这要求最终输出的用户表示和项目表示具有相同的维度,而本文方法将用户和项目映射至相同的表征空间,很好地满足了这个要求.对任意用户u和项目d,且u∈Setuser,d∈Setitem,u对d的评分可以计算为
其中Xfeature,u表示从用户表征矩阵中抽取u的表示向量,Ed表示从项目表征矩阵中抽取d的表示向量.则对任意用户u和候选项集D,且满足相关条件u∈Setuser,D⊆Setitem,u对D的评分向量可以计算为
其中ED表示根据候选项集中项目抽取的候选项表示矩阵.
2.5 模型训练与参数优化
在训练阶段,模型在训练集上进行多个轮次的随机采样生成训练集,在每个轮次上计算贝叶斯个性化排名[9]损失(BPR loss)并根据损失函数优化模型中的参数.
具体地,首先在训练集上进行随机采样.在采样阶段需要根据用户的交互记录以[用户,正例,负例]的方式进行测试用例采集,其中正例为在训练集上与用户发生了交互的项目,负例为在训练集上未与用户发生交互的项目.结合数据集的规模进行上述方式的采集后,可以在训练集上进行模型损失的计算,即
其中Sample表示采样训练集,pos 和neg 表示一个测试用例里的正例和负例,Θ表示模型中所有多层感知机的网络层的参数,λ控制参数的L2 正则化的强度.在模型训练阶段采用Adam 优化器,并以mini-batch的方式对模型进行训练.
2.6 模型分析
1)可解释性分析.用户表征的可解释性依赖于项目表征的可解释性.在构建用户表征序列时,模型根据用户的交互数据进行初始化.而在进行交互扩展时,用户将“看到”同一聚类中的其他用户的交互,根据扩展得到的交互构建同质超图,并根据卷积结果构建新的聚类.通过这样的方法,将用户和项目映射到相同的表征空间.而项目的表征空间可以有多种方法确定可解释性,如项目标签的独热或多热向量,或word2vec 等其他自然语言处理模型输出的词向量模型.结合项目表示向量和交互记录,用户表征向量可以被理解为表示了“某个内容领域有多大兴趣”的用户,可解释性得到了加强.
目前主要的图与超图模型多采用拓扑关系学习用户和项目的向量表示,将用户和项目表征作为模型参数,将维度作为模型的超参数,以此在训练中进行表征的优化,使表征分布符合用户的拓扑特征.在高度稀疏数据场景下用户不具备鲜明拓扑特征时,模型往往达不到满意的效果.
2)轻量化分析.本文提出的模型中主要的网络层来自注意力机制和过滤层的第1 与第2 多层感知机.模型的用户表征序列生成部分采用了不使用网络层与激活函数的卷积方法,如式(6)~(9)所示,从而帮助实现用户表征矩阵的快速迭代.在式(11)~(13)所示的均值差JK 注意力机制中,第1 多层感知机的输入维度比原始JK 注意力机制要小,能够降低模型网络层的复杂度与整体的训练成本.同时,对比将用户和项目表征作为模型参数的方法,在面对大规模数据集时,模型需要更新优化的参数规模要小得多.有关轻量化分析将在实验部分通过模型训练效率和网络参数规模对比进行验证.
3 实验结果与分析
本节将对实验阶段使用的数据集以及实验结果部分进行分析讨论.在说明使用数据集时,将详细讨论数据集的特点以及其给模型带来的挑战;实验结果与分析的讨论部分将介绍实验评价指标、基准模型、实验环境、超参设置以及实验结果的分析等5 个方面的内容.
3.1 实验数据
本文使用的数据集是来自腾讯微信的非公开数据集(Wechat-Set).微信是国内使用最广泛的社交平台应用之一,整合了公众日常生活中应用的众多入口,每天产生海量的用户数据.使用的微信数据集主要是针对用户在生态内容搜索引擎“搜一搜”内发出的搜索请求和点击阅读的文档的记录,通过数据搜集生成了时间跨度大约1 个月的查询记录,涉及101 852个匿名处理的用户和27 982 299 个请求关键字与点击阅读的文档标题,并经过清洗形成这个高度稀疏的数据集.表1 展示了选取的非公开数据集和常用公开数据集的参数对比.其中的Wechat-Set Sample 数据集是从Wechat-Set 交互记录中随机采样得到的子集,涉及2 026 个用户在1 212 934 个文档上产生的1 672 129个交互记录.数据集中,将用户阅读了某文档作为一次交互.

Table 1 Details and Comparison of Parameters of Experimental Datasets表1 实验数据集参数详情与对比
从表1 可知,相较于经典的公开数据集,腾讯数据集具有非常高的交互稀疏度(交互记录/(项目×用户))和比密度(项目/用户).这反映了微信生态内数据的高度稀疏以及项目数远大于用户数的特点,也对生态内的推荐算法提出了挑战,即如何完成高度稀疏数据场景下的推荐任务并保证输出的效果和学习得到的用户表示的可解释性.本文方法在这方面的性能与效果将在实验阶段进行更加详细的说明.
3.2 评价指标与基准模型
实验主要在测试集上计算3 个基础的评价指标来确定本文模型和基准模型的效果对比.采用的评价指标为精准度(Precision@TOPK)、召回率(Recall@TOPK)和F1 分数(F1-Score).
精准度和召回率在推荐领域属于较为重要的基础概念.精准度指检索出的相关项目数与检索出的项目总数的比值,衡量的是方法的查准率;而召回率指检索出的相关项目数与相关项目总数的比值,衡量的是方法的查全率.具体地,精准度和召回率计算为
而F值为精准度和召回率的调和平均值,较为常用的F1 值的计算方法为
从而可以在一定程度上客观地衡量模型的效果.
在基准模型的选取上,本文在实验阶段主要选取了MF,NGCF,LightGCN 这3 个方法,通过模型最终的评价指标计算结果来比较模型在选定的数据集上的表现.
1)MF[27](矩阵分解).矩阵分解是较早时期主流的推荐算法,将隐向量的概念加入协同过滤算法中的共现矩阵,从而使模型处理稀疏矩阵的能力得到加强.该算法期望为每一个用户和项目构成一个隐向量,将用户和项目定位到相同的表征空间上使距离相近的用户具有相似的兴趣特点.
2)NGCF[18].NGCF 模型研究认为早期矩阵分解等方法中隐藏在用户和项目间的信息难以在编码的过程中表示,编码可能难以捕获协同过滤效果.NGCF 可以在图结构中学习表示,显示地将协同过滤信号放入编码过程并表达高维特征.但是,模型的节点更新较复杂,且容易在小规模数据上出现过拟合问题.
3)LightGCN[19].LightGCN 简化了图卷积层的设计,只包含了用于协同过滤的邻域聚合组件.在用户和项目的交互图上,模型通过线性传播用户和项目的表示来进行表示学习,并根据所有聚积层上得到的嵌入表示输出最终的嵌入生成,模型更简洁且容易实现和训练.
3.3 实验环境与基本参数
基准模型与本文模型均在相同的实验环境下进行实验.
基本的硬件与软件参数如表2 所示.在基准模型与本文模型的相关参数方面,学习率统一为0.001,正则化系数为0.000 1,卷积层数、表征序列长度均为5;在内存允许的要求下,表示向量维度为100,所有中间层维度为128,Light-HGNN 中的多层感知机层数为2;Light-HGNN 的 γ=0.1,聚类数默认为12,扩展阈值将默认为0.9.
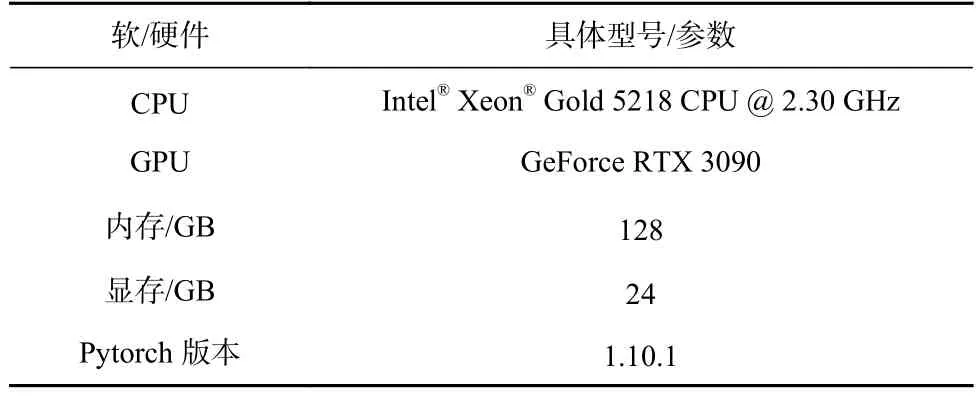
Table 2 Experimental Parameters of Software and Hardware表2 实验软硬件参数
在测试中,每个用户取头部20 个项目来进行相关指标计算,所有模型的训练轮次设定为300,在训练过程中每10 个轮次进行1 次模型测试获取指标数据点,生成相关指标的曲线.
3.4 实验结果与分析
1)模型结果分析.模型的评价指标计算结果如表3 所示.其中Light-HGNN(JK)表示采用了原始JK注意力机制的模型,Light-HGNN(AD-JK)表示采用了均值差JK 注意力机制的模型.对表3 中的结果分析可知,优化了输入规模的更加精简的均值差JK 注意力机制与原JK 注意力机制得到了更好的模型效果,而本文模型的效果,不论在原始JK 注意力机制还是在改进的均值差JK 注意力机制下,效果都要好于基准模型.
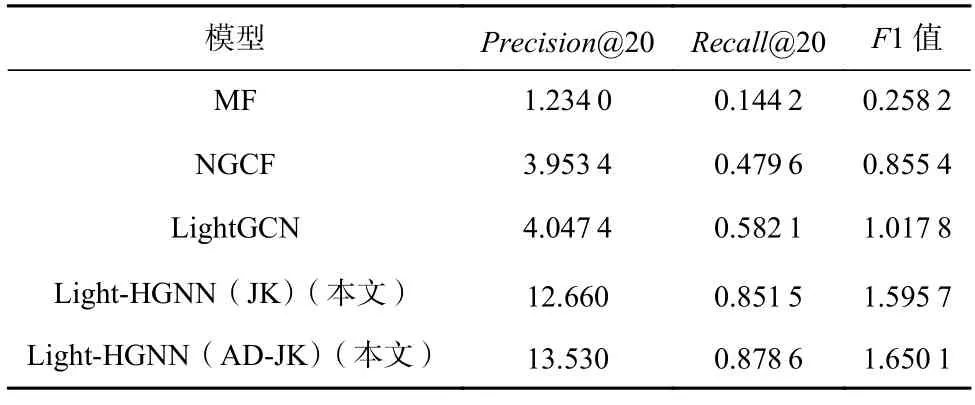
Table 3 Calculation and Comparison of Evaluation Indicators of Models表3 模型评价指标计算与对比 ‰
造成本文模型与基准模型的效果差异的原因可能是数据的高度稀疏特征.如前所述,腾讯微信的数据集拥有相对更低的交互密度和相对更高的比密度.这导致数据集中的很多项目的交互用户很少甚至是唯一的,与此同时,对用户群体而言,同时存在多个用户与1 个项目交互的情况也是极少的.这使得依靠用户与项目的拓扑关系很难挖掘出独特的结构特征,且很多项目节点的表征很难在迭代中进行更新,此时将用户表征和项目表征同时作为参数进行优化时会带来较大的不确定性.本文模型结合了超图与源数据中的拓扑关系并以内容为导向、以项目表征来学习用户的表示,能够使用户的表示更好地反映用户的兴趣分布,从而提高模型的效果.
图6 和图7 展示了各模型在实验数据集上取得的相关指标的变化曲线.Light-HGNN 在各项指标上要优于其他基准模型,在精准度指标上的优势更加明显.除前文所述的相关分析,在模型的结构设计上,根据用户聚类进行交互扩展并卷积的做法能使用户直接“感受”到更多的感兴趣的项目;相较于Light-GCN 对表征序列直接求平均的方法,加入的注意力机制能够更好地挖掘隐藏在用户表征序列中的用户特征,并对输出进行适应性调整,从而提高模型的效果.
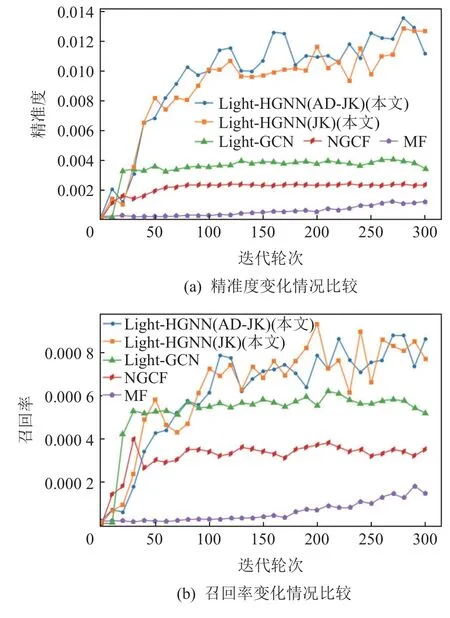
Fig.6 Variation curve of precision and recall图6 精准度和召回率变化曲线

Fig.7 Variation curve of F1 value图7 F1 值变化曲线
2)模型轻量化分析.表4 展示了相同软/硬件条件下的模型训练时间与参数规模对比来对模型进行轻量化分析.从表4 中可以看出,Light-HGNN 的轮次训练平均时长要远小于Light-GCN 和NGCF.这2 个模型将用户和项目的表征作为参数进行优化,而Light-HGNN 的模型设计主要优化模型的第1、第2多层感知机和权重激活层的参数.因此,根据数据集内的项目数和用户数,Light-GCN 和NGCF 将产生海量需要更新的参数,参数规模远大于Light-HGNN 的参数规模.每轮训练时间的比较也证明了本文模型的轻量化特点.

Table 4 Comparison of Training Time and Optimized Scale of Parameters表4 模型训练时间与参数优化规模对比
4 结论
本文针对微信“搜一搜”的圈层内容推荐任务提出了一个新的轻量同质超图神经网络模型.模型采用同质超图对用户数据进行建模,简化了模型设计、降低了复杂度、提高了表征的可解释性.在序列值的迭代生成过程中,根据提出的均值差JK 注意力机制为每个序列值生成权重矩阵,对序列进行加权求和,过滤后得到用户表示,通过用户表示和项目表示的内积得到用户评分,实现了高度稀疏数据条件下的圈层内容推荐任务.在真实数据集上进行的实验验证了模型更优的效果.在后续研究中,将继续探索更有效的注意力机制来进一步提升模型的效果,并对存在时序属性的交互数据的建模进行研究.
作者贡献声明:李挺撰写论文,设计实验及测试系统;金福生负责理论和研究框架设计指导及论文撰写;李荣华指导论文撰写;王国仁负责理论指导;段焕中和路彦雄负责实验指导.
