RR-SC: 边缘设备中基于随机计算神经网络的运行时可重配置框架
2024-04-29宋玉红沙行勉诸葛晴凤
宋玉红 沙行勉 诸葛晴凤 许 瑞 王 寒
(华东师范大学计算机科学与技术学院 上海 200062)
(yhsong@stu.ecnu.edu.cn)
随着人工智能的发展,深度神经网络(deep neural network,DNN)作为典型的机器学习模型已经被广泛地应用于边缘设备上[1-2],例如自动驾驶、智能家居、智慧医疗等应用领域.然而,边缘设备拥有的资源(如能源、计算单元和存储单元等)是十分有限的,这限制了DNN 在边缘设备上的高效部署.尽管许多压缩技术[3-9]通过减少神经网络模型参数在一定程度上能够节省资源的使用,但随着压缩率的持续升高,模型推理准确率会产生明显的下降.随机计算(stochastic computing,SC)[10-12]作为一种新兴的计算技术由于其特殊的数据表示和计算模式,使得其对于神经网络在硬件上的部署具有低能耗、低开销的优势.SC 通过使用简单的逻辑门近似运算以替代传统浮点数计算中复杂的算术单元,大大降低了计算单元单位时间内的能耗,以及计算单元和存储单元的使用量.
SC 使用一个随机的0/1 比特串来表示数据,它不同于传统的二进制比特串—每个位置具有不同的权重值.对于SC 数据来说,每个位置的权重都是一样的.因此,SC 数据在噪声环境中具有很高的数据容错性,1 个比特位发生翻转,对整体数值的影响并不大.SC 数据具有2 种数据类型:单极(unipolar)数据和双极(bipolar)数据.单极数据表示的是[0,1]范围内的实数,双极数据表示[-1,1]范围内的实数.对单极数据来说,对任意的实数x(0 ≤x≤1),0/1 比特串中的每个比特都有x的概率为1,都有 1-x的概率为0,即x=P(串中出现1).图1(a)(c)中的比特串A,B,C均为单极数据表示.例如,比特串A:11010100 的长度为8,其中出现4 个1,因此该比特串表示的数据xa=4/8=0.5.SC 也可以表示-1~1 的数据x,即双极数据.这种数据表示方式只需要对比特串中1出现的概率进行简单地变换即可,即x=2×P(串中出现1)-1.因为概率P的范围一定是[0,1],因此双极数据x通过线性变换被调整到[-1,1]范围内.图1(b)(d)中的比特串A,B,C均为双极数据表示.例如,比特串A:11000000 的长度为8,其中出现2 个1,则P=2/8=0.25,那么数据xa=2×0.25-1=-0.5.对于SC 数据来说,数据精度由比特串长度决定,数据比特串的位数越长数据表示越精确.

Fig.1 Examples of SC based arithmetic units图1 基于随机计算的算术单元示例
基于这样的数据表示方式,传统计算中的算术运算就可以利用概率知识来近似计算.利用SC 技术,传统浮点数运算中复杂的加法器、乘法器等算术单元可以用简单的逻辑门代替.例如,对于单极数据来说,可以利用一个简单的与门(AND)来近似乘法运算(见图1(a)).它是利用概率计算中,2 个独立事件A,B,P(A∩B)=P(A)×P(B) 来近似计算,即P(A∧B)=xa×xb.对于双极数据的乘法来说(见图1(b)),可以用同或门(XNOR)来近似.在概率计算中,P(A⊙B)=P(A⊙B)的结果正好就是xaxb结果的双极数据表示.因此,双极数据的乘法可以用同或门来近似见.类似地,单极数据和双极数据的加法都可以用或门来近似,见图1(c)(d).利用概率计算,SC 算术单元的复杂度被极大地简化,这减少了算术单元的运行能耗和硬件使用面积.但是,这种近似方式会产生较大的计算误差.因为要满足上述的概率计算公式,比特流A和流B的生成需要是独立事件,且在用或门近似加法运算时需要满足A,B是互斥事件.因此,对于SC 来说,设计高准确率的算术单元至关重要.
现有的基于SC 的工作[13-16]大多集中于设计高准确率的算术电路,接着利用这些算术电路将DNN 模型部署到硬件设备上进行推理.这种部署往往通过启发式的方法确定一组模型配置(如模型结构、数据比特串长度等)用于硬件实施.并且,这种部署不会考虑动态改变的硬件环境(例如,电池电量会随着消耗而减少).这些设计往往能够获得较高的推理准确率,却忽略了硬件效率和电池使用时间.另外一些工作[17-18]考虑设计数据精度缩放方法以灵活地改变数据比特串长度,但是神经网络依然被运行在固定的硬件配置上,使得硬件的使用效率没有被充分发挥.
因此,面对有限且动态变化的硬件资源,为了满足模型推理的时间约束和准确率要求,本文针对基于SC 的神经网络创新性地提出了一个运行时可重配置的框架RR-SC.对于电池搭载的边缘设备来说,面对动态变化的电池电量,本文提出利用动态电压和频率调节(dynamic voltage and frequency scaling,DVFS)技术来进行硬件层面重配置以节省能源使用.DVFS 根据剩余的电池电量情况,对硬件的电压和频率进行相应的调节.在电池电量充足时,使用较高的电压/频率(voltage/frequency,V/F)等级使模型保持在一个较快的速度上进行推理;在电池电量降低到一定程度时,切换至较低的硬件V/F 等级以降低单位时间内的推理能耗,使得模型能够在有限的能源内运行更多次数,以延长电池的使用时间.除了硬件层面使用DVFS 进行重配置外,RR-SC 还结合了软件层面的重配置以满足模型推理的实时性约束.如果在模型推理时仅仅在不同的电量对硬件的V/F 等级进行切换,会使得一组模型配置在高V/F 等级时能够满足时间约束,而切换到低V/F 等级时推理时间变长,预先设定的时间约束无法被满足.因此,我们设计了RR-SC 框架自动地为不同的V/F等级选择出最佳的软件配置.RR-SC 利用强化学习(reinforcement learning,RL)[19-20]技术一次性为不同的V/F 等级生成对应的模型配置,即模型结构、SC 算术单元、数据比特串长度等,以满足模型推理的时间约束和不同V/F 等级下的准确率要求,同时尽可能地延长电池的使用时间.为了实现运行时的轻量级切换,RR-SC 只生成1 组模型结构作为主干网络,从而能够在不同的硬件配置下快速切换.
本文的主要贡献包括3 个方面:
1)为了满足基于SC 的神经网络推理的实时性要求,并尽可能地延长电池搭载的边缘设备的使用时间,本文创新性地提出将硬件重配置和软件重配置相结合.
2)基于自动机器学习技术提出了一个运行时可重配置的框架RR-SC,以自动地生成硬件配置对应的模型配置(即软件重配置).选择的软件配置拥有最好的准确率和运行效率的权衡.除此之外,模型运行时在一个搜索出来的主干网络上进行软件配置切换,以实现轻量级软件重配置.
3)实验结果表明,RR-SC 能够保证在所有硬件级别下满足实时约束,并且可以在准确率损失仅为1%的情况下将模型推理次数增加7.6 倍.同时,它还能在110 ms 内满足不同软件配置的轻量级切换.
1 相关工作
SC 近似计算产生的高计算误差使得基于SC 的DNN 实现的相关研究[13-16]主要集中于设计高准确率的硬件电路.由于乘积累加(multiply-accumulate,MAC)运算是DNN 实现中的基本运算,因此我们主要讨论乘法器和加法器的设计与实现.文献[13]提出使用同或门作为乘法器,并且提出了一个基于多选器树(MUX-tree)的加法器,我们称这个算术电路为XNORMUX.XNOR-MUX 受制于比特流间的相关性问题(即概率近似失效),使得计算误差较大.文献[14]将正负数据分开计算,并利用与门作为乘法器.同时,它提出一种新的加法器,这种加法器分别计算正数数据的和(POS)与负数数据的和(NEG),最后利用对结果进行巧妙地转换,这种转换只需要一个MUX 门,使得单极数据计算的结果正好为双极数据表示下正数部分和负数部分的差.我们称这个电路为AND-SEP.但当输入数据数量较多时,该加法器在没有数据缩放时会产生计算溢出问题使得计算误差较大.文献 [15]为双极数据设计了新的乘法器uMUL 和加法器uNSADD,并利用并行计数器来缓解输入的相关性问题.但在某些特殊情况下会出现冗余1 或缺失1 的问题从而产生计算误差,这种电路被称为uGEMM.文献[16]进一步提出了一种基于累加器的块内加法器以减少计算错误,并设计了一种输出修正方案来解决块之间的冗余/缺失1 的问题.块内的算术电路被称为AND-ACC,带有输出修正方案的电路被称为AND-LOOP.这些设计虽然相比传统的二进制电路具有更低的运行能耗,但它们都没有考虑电池搭载的边缘设备电量动态改变的情况,因此没有涉及任何软件和硬件的重配置.当神经网络被部署到硬件上时,模型推理始终运行在相同的V/F 等级下,模型的推理会快速消耗电池电量,使得模型最终推理总次数较少.
另一方面,文献[17-18]考虑了运行时比特串长度的动态改变.文献[17]提出一个新的计算提前终止方法,使得模型推理时可以只利用较少位数的比特串就能获得较好的推理准确率.文献[18]扩展了文献[21]的方法并设计了新的数据表示方式,使得输入、输出数据的精度可以在运行时任意更改.这些工作虽然实现了运行时软件层面的重配置,一定程度上延长了电池的使用时间,但它们都运行在固定的硬件配置下,使得硬件资源没有被充分利用.
因此本文提出一种软/硬件协同重配置的方式,利用硬件重配置以尽可能地延长电池使用时间,增加模型的推理总次数.同时搭配软件重配置以满足机器学习任务的实时性要求.本文提出的方法充分利用硬件资源,实现高效实时的模型推理.同时,保证了模型推理的准确率.
2 动机和问题定义
2.1 动 机
动机1:电池搭载的边缘设备的能源是有限且动态变化的.大多数移动设备都是电池供电的,例如手机、无人机、机器人等[22].延长能源有限的电池使用时间是很重要的.同时,任务执行需要符合实时性要求.面对有限的能源资源,许多模型压缩方法[3-5]通过减小模型大小和参数数量在一定程度上提高模型推理速度以降低能源消耗.但是这些压缩方法依然依赖于复杂的浮点数算术电路运算,在能源消耗方面仍有很大的优化空间.SC 利用新的数据表达方式和简化的算术电路进一步降低模型推理能耗,但由于数据表示精度、电路计算误差等问题,使得许多研究者都致力于研究高准确率的算术电路,忽略了硬件的效率和动态变化的硬件资源.因此,面对逐渐减少的电池电量情况,DVFS[23]技术常被用于硬件重配置,以节省能源使用.表1 展示了 Odroid-XU3 平台中Cortex A7 内核的可用V/F 等级.本文针对电池搭载的边缘设备,在电池电量较高时配置较高的V/F 等级;当电池电量降低到一定程度时,切换到更低的V/F 等级.在本文中,我们称这种动态电压和频率等级调节为硬件重配置.

Table 1 V/F Levels Supported by ARM Cortex A7 Core in Odroid-XU3 Mobile Platform表1 Odroid-XU3 移动平台中 ARM Cortex A7 内核支持的电压/频率等级
动机2:仅仅使用硬件重配置无法满足实时性要求.我们通过对比实验验证了硬件重配置能够延长电池使用时间,实验结果展示在表2 中.为了度量电池的使用时间,本文用模型在一定能源总量下的推理总次数来表示,表2 中所有的方法都具有相同的能源总量.实验设置S1 和S2 使用了相同的多层感知机(multi-layer perceptrons,MLP)模型.我们设定MLP模型的结构为784-100-200-10,表示MLP 的3 层全连接层分别有100,200,10 个神经元,784 表示输入数据的大小.模型推理时使用AND-ACC 算术电路.在本实验中的模型配置均使用默认设置,但对于RRSC 方法,模型的配置通过优化方法确定.实验设置S1 仅使用一种模型配置,且模型推理运行在固定的硬件配置下,这里的SC 数据使用32 b 的0/1 串表示.在实验设置S2 中使用了硬件重配置(即DVFS),S2一共设置了3 个V/F 等级F,N,E.F 模式表示使用高V/F 等级下的快速执行模式;N 模式表示使用中间V/F 等级下的普通速度执行模式;E 模式表示使用低V/F 等级下的节省能耗的执行模式.相应地,我们选择表1 中的l6,l4,l3分别作为F 模式、N 模式和E 模式下的V/F 设置.从表2 中我们可以看出,在S2 实验设置下,由于配置了DVFS 技术,模型的总的推理次数相比于S1 实验设置提升了1.4 倍,这表明DVFS 能够在一定程度上延长电池使用时间.然而,当V/F 等级降低时,如S2 实验设置下的N 模式和E 模式的模型推理时间无法满足时间约束.因为当频率降低时,计算速度也相应地变慢.在本实验中,我们设置的时间约束为45 ms.

Table 2 Running Results Comparison of Three Experimental Settings with the Time Constraint of 45 ms表2 时间约束 45 ms 下的3 种实验设置运行结果对比
为了解决仅使用硬件重配置无法满足实时性要求的问题,我们探索了软件重配置以搭配不同的硬件配置.在不同的硬件V/F 等级下搭配不同的数据精度,以降低运行的时间和能耗、满足实时性要求和增加模型推理总次数.我们同样用实验来证明,如表2中的S3 实验设置:结合硬件重配置和软件重配置.实验结果表明,S3 设置下模型推理总次数是S1 模式下的2.3 倍,并且相比于S2 模式提升了近40%.与此对应的是,模型推理准确率产生了一定程度的损失.通过搭配DVFS,模型推理总次数显著增加,电池一次放电的使用时间延长.接着搭配软件重配置,也就是不同的模型配置,模型推理的时间约束能够被满足.
2.2 问题定义
本文为了解决动机1 和动机2 对应的问题,提出了一个完整的基于自动机器学习的框架,能够为不同的硬件配置一次性选择多种软件配置.本文的问题定义为:
定义1.给定边缘设备能源总预算TE,推理时间约束TC,一组运行时用于切换的V/F 等级L={l1,l2,…,li,… },各等级下的准确率约束AC={Ac1,Ac2,…,Aci,…},本文框架主要用于决定:
1)一个主干网络模型结构BM;
2)一个随机计算算术电路C;
3)多组用于软件重配置的比特串长度BL={bl1,bl2,…,bli,…}.
运行时,硬件根据剩余的能源(即电池电量)切换相应的V/F 等级,被选择出来的主干模型BM使用算术电路C进行推理运算,根据不同的V/F 等级切换相应的数据精度BL.通过RR-SC 选择出来的软件配置可以满足时间约束TC和各级准确率约束AC,同时最大化模型BM在不同V/F 等级下的推理次数总和以及模型推理准确率.本文使用模型在总能源预算TE下的推理次数来表示硬件的效率.因此本文的优化问题可以表示为:
其中Runs表示模型在V/F 等级L下的总运行次数,Acc表示多个模型推理的平均准确率,lati和Ai分别表示各V/F 等级下的模型推理时间和准确率.
3 RR-SC 框架设计
3.1 总体设计
图2 展示了RR-SC 框架的整体设计.我们建立了一个基于循环神经网络(recurrent neural network,RNN)的RL 控制器(见3.2 节),用来从预先定义好的离散的搜索空间选择出相应的软件配置.RL 控制器利用深度机器学习的方法,可以通过训练优化以预测出更好的结果.离散搜索空间由模型结构(包括层数、每层神经元个数、卷积核大小等)、SC 算术电路库、数据精度(即数据比特串长度)组成.RL 控制器选择出来一组模型结构作为主干网络BM,在不同的V/F 等级下均使用相同的SC 算术单元C推理以节省能耗和切换开销.同时RL 控制器生成多种数据精度BL,以在不同的V/F 等级下进行轻量级切换.当模型配置确定后,主干网络接着被训练和推理以获得各等级的能耗、时延和准确率(见3.3 节).这些指标被输入设计好的反馈函数(见3.4 节)得到奖励值R,R值被用于更新RL 控制器参数使其能够快速收敛.RL 控制器的选择过程被执行EP次,每次通过从环境中获得的奖励值R来更新RNN 网络的参数以指导下一次的参数选择.
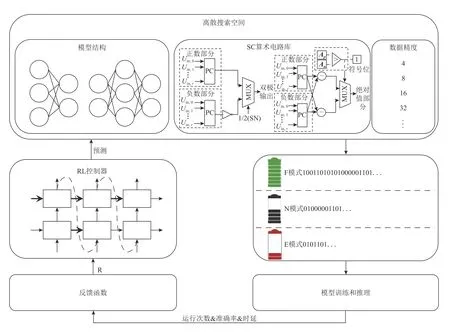
Fig.2 RR-SC framework图2 RR-SC 框架
3.2 强化学习控制器
为了一次性地获得能够满足时间约束TC和准确率约束AC的软件配置,本文利用RL 技术来为基于SC 的DNN 智能、高效地选择最好的参数,以在固定能源总量下获得最多的模型推理次数和最好的推理准确率.RL 控制器是RR-SC 框架的核心部件,它的设计基于深度学习网络模型.DNN 的应用使得RL控制器在收敛到全局最优解方面具有很大的优势.智能体(agent)每次自动地观察环境状态并通过奖励值进行参数的自我更新,以在未来的执行过程中得到更好的动作预测结果.
1)状态空间(state space).本文使用基于SC 的DNN在相应参数配置下的推理准确率Acc,及在给定能源总量和V/F 设置下的推理总次数Runs来表征当前的环境状态,如表3 所示.RL 控制器利用以往动作及相应的反馈值作为输入以学习以往的经验,用以训练自身网络,使其未来能够预测出拥有更高反馈值的参数组合.反馈函数中的性能值能够全面反映模型在嵌入式设备上推理时的不同方面,即推理总次数反映了运行时的硬件效率,平均推理准确率反映了模型的分类水平.它们能够使智能体更好地理解复杂的系统,并能及时捕捉环境的动态变化.
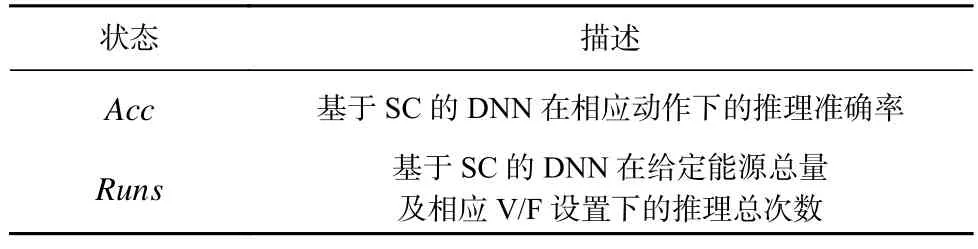
Table 3 State Space of RL Controller表3 RL 控制器的状态空间
2)动作空间(action space).本文的强化学习的动作空间由3 类参数的组合空间组成:模型结构、SC算术电路以及数据精度.其中,模型结构决定了推理模型的大小,它包括模型的层数、每层的神经元个数、卷积核大小、卷积步长、输入通道数等要素,包含哪些要素由具体的模型决定.接着,本文根据现有的SC算术电路设计工作构建SC 算术电路库,包括XNORMUX,AND-SEP,uGEMM,AND-ACC,AND-LOOP 这5 种电路.数据精度指不同的SC 数据表示位数,越长的数据表示越高的数据精度.值得注意的是,RR-SC是一个可重新配置的框架,它允许将其他因素包含在内,动作空间的值可以根据不同的需求和场景进行调整.
3)智能体.在RR-SC 的设计中,强化学习中的智能体被称为RL 控制器.RL 控制器的实现基于一个RNN 网络,这和文献[24]中的实现类似.RNN 相关的网络能够很好地处理序列相关的输入,提取和保留序列中的上下文关系及信息,因此RL 控制器有助于通过学习以往动作中的经验,不断训练出更好的RNN 网络以做出更好的选择.首先,RL 控制器从动作空间内预测出一组模型结构,一个SC 算术单元和多组数据精度用于在不同的V/F 等级下进行切换,这种预测是基于一个Softmax 分类器.选择出来的参数用于构建主干模型.接着进行模型的预训练和硬件推理,通过训练和推理,模型的能耗、时延和准确率会被获得以用于构建反馈函数.接着,基于反馈函数计算得到奖励值R,一个蒙特卡罗策略梯度算法[25]被应用于更新RL 控制器中的参数 θ.更新 θ的计算公式为:
其中,m表示RNN 输入的批次大小,T表示每次选择的步数.奖励值R在每一步都按指数因子减少,基线b是R的平均指数移动.θ的更新是为了让RL 控制器在下一轮的搜索中选择拥有更高R值的配置,使其可以更快地收敛到全局最优解.
为了获得更稳定的结果[26],我们对RR-SC 执行多次,并以拥有最高R值的配置作为我们最终的结果.RR-SC 的搜索时间开销以多次运行的平均时间计算得到.
3.3 模型训练和推理
当RL 控制器选择出来一组模型配置后,模型训练和推理过程被启动.RL 控制器选择出来的模型配置包括模型结构,即模型层数、每层神经元个数、卷积层核数、步长等,SC 算术电路和多种数据精度.当选择出来的模型配置通过性能预测器(见3.4 节)计算得到的推理时间满足设定的时间约束TC时,开始相应的训练器和模型推理过程.如果任意V/F 等级下的时间约束和准确率约束没有被满足,那么模型的训练和推理过程被提前终止,以节省RR-SC 的搜索开销.图3 展示了模型训练和推理模块的主要流程.首先,对于选择出来的参数,模型结构被解析,对应结构的浮点数模型被构建.接着,浮点数模型被预训练多次,以获得拥有高准确率的模型参数,即权重和偏置.为了获得模型在硬件上的推理准确率,基于SC 的模型被建立.模型的结构与选择出来的主干网络模型相同,只是数据的表示由浮点数据转换为SC数据,即单极数据和双极数据.所有浮点数输入数据和模型参数均通过随机数生成器(stochastic number generator,SNG)转换成SC 的数据比特串.随后,选择出来的算术电路C被用于实现基于SC 的DNN 模型.对于不同的硬件配置,即V/F 等级来说,被选择出来的多个数据精度分别对应多个V/F 等级,应用不同数据精度的模型通过算术电路C推理得到各自的准确率.多个模型推理的平均准确率用于计算奖励值R.理论上讲,当硬件配备高V/F 等级时,相应的高数据精度被选择出来,也就是更长的比特串长度.这样,在硬件能源(即电池电量)相对充足时,模型推理能够尽可能的准确.当硬件能源减少到一定程度后,数据精度也相应地被调低,这样在损失一定准确率的情况下,能够尽可能降低模型推理能耗,以延长电池的使用时间.

Fig.3 Model training and inference stages used for obtaining energy,latency and accuracy图3 模型训练和推理阶段用以获得能耗、时延和推理准确率
3.4 性能预测器和反馈函数
为了获得基于SC 的模型推理时间,我们设计了一个性能预测器.我们在高级综合(high-level synthesis,HLS)工具上模拟基于SC 的加法器和乘法器,并获得当前数据精度下每个操作数计算所需的时间.接着,我们根据选择出来的模型结构计算所有操作的数量.这样,就可以获得模型在当前V/F 等级下的推理时间.那么当模型被切换至其他V/F 等级时,推理时间可以通过频率的线性变换计算得到.频率越高,推理的速度越快,推理时间越短.另外,为了获得当前硬件设置下的模型推理次数,我们通过总能源TE和模型一次推理所需要花费的能耗Ei计算得到.模型一次推理所花费的能耗Ei通过功率乘以时间得到,即Ei=Poweri×lati.其中,当前V/F 等级下的功率和时延通过模型在HLS 中模拟得到.那么模型的推理总次数Runs即为当前等级的总能源TEi与一次推理所需的能耗Ei的比值,即
本文假定在相同的工作负载和不变的物理环境下设计,因此忽略工作负载和环境变化带来的功率的动态变化.除此之外,温度对能耗也有一定的影响,但本文所使用的随机计算技术是一种显著降低模型推理能耗的技术,低能耗技术对工作温度的影响很小甚至没有[27].并且,本文在相同的起始温度下对不同的软硬件配置进行能耗预估,温度对能耗的影响对于最后的配置的选择几乎没有影响.因此本文不考虑温度对能耗的影响.
经过模型训练和推理过程,以及模型预测器的高级综合之后,可以得到模型在各个V/F 等级下的推理次数和准确率.接下来,当前轮的奖励值R可以通过反馈函数计算用以更新RL 控制器.反馈函数同时也用来表示我们的优化目标,即在时间约束TC及准确率约束AC下,最大化模型推理次数和准确率.反馈函数的计算公式为:
在介绍具体的函数之前,我们先介绍5 个符号:1)Rrs指的是多个模型推理总次数的归一化值,它的范围在[0,1];2)lati表示每一种V/F 等级下模型的推理时间;3)Ai表示各种V/F 等级下的模型推理准确率,Au和Al是我们预先设置的最高准确率和最低准确率,用以对准确率进行归一化;4)Aci表示各V/F 等级下的准确率约束;5)cond是一个二值条件,cond=True表示对于 ∀i<j,我们有Ai>Aj,意味着运行在高V/F等级的模型拥有更高的推理准确率,否则cond=False,在这种情况下我们会给奖励值R一个惩罚pen.
那么,对于计算奖励值R有3 种情况:
1)如果 ∃lati>TC或者 ∃Ai<Aci意味着时间约束TC和准确率约束AC并不是在任意的V/F 等级下都被满足,这里我们直接设置R=-1+Rrs.这意味着,当通过性能预测器得到的模型在选择的动作参数下无法满足边缘设备要求的时间约束TC时,就不需要进行真正的模型训练和推理以获得准确率,因此直接将准确率反馈值设置成-1.这样,RR-SC 的搜索开销在一定程度上就可以减少.同样地,如果基于SC 的神经网络模型在某些V/F 等级下的推理准确率无法满足预期的要求,那么其他V/F 等级下的模型就不需要再耗费时间和资源进行推理.
2)如果任意V/F 等级下的推理时间约束和准确率约束都能够被满足,并且cond=True,也就是期望拥有高V/F 等级的硬件配置能够获得更高的准确率,那么我们使用归一化后的平均准确率和模型推理总次数作为奖励值R.这种情况对应着本文优化问题的目标函数,RR-SC 期望在满足时间约束和准确率约束的情况下,最大化运行总次数和推理准确率.
3)否则,我们在第2 种情况下的奖励值R增加一个惩罚值pen.因为RR-SC 更希望能够在高V/F 等级下拥有更高的推理准确率,给定一个惩罚值相当于告诉智能体这是一种不被期望的结果.
4 实验结果及分析
4.1 实验设置
1)实验方法对比.首先,我们将RR-SC 框架与之前的基于SC 的工作[13-16]进行对比.本文方法结合了软件和硬件的重配置,在满足实时性约束的前提下最大限度地延长电池使用时间.通过利用RL 技术一次性选择多种软件配置对应于多种硬件配置.硬件配置根据剩余能源电量进行V/F 等级的调整,选择出来的软件配置对应各个硬件配置.而现有的前沿工作主要针对算术电路进行设计,缺少硬件和软件重配置.同时,RR-SC 框架选择出来的模型被可视化以便于展示.接着,我们利用RR-SC 选择出来的模型结构和配置,进一步探究软件重配置和硬件重配置分别对推理时间和能源消耗的影响.
2)实验指标及平台设置.我们使用MNІST 数据集在MLP 和LeNet 模型上评估本文方法,使用Cifar10数据集在AlexNet 模型上验证.搜索空间的设置包括模型结构、SC 算术单元、数据精度3 个部分.通过探究,我们将搜索空间内所有因素的值都收缩到一个合理的范围内,本文实验设置的搜索空间被总结在表4 中.对于硬件指标,算术电路由 Bluespec SystemVerilog实现,然后编译为 Verilog 以在Vivado v2020.2 上评估能耗、时间等硬件指标.对于准确率指标,我们在2×NVІDІA Tesla P100 GPU 服务器(16 GB GPU 内存)上进行模型推理和RL 的搜索过程.实验在 Python 3.6.0,GCC 9.3.0,PyTorch 1.5.1 和 CUDA 10.1 环境上进行.对于边缘设备,我们使用移动平台 Odroid-XU3[28].在实现SC 模型中,Sobol[29-30]随机数生成器被用于从浮点数到SC 数据的转换.
本文使用LSTM 网络作为RL 控制器,LSTM 输入的批次大小m=35,每次选择的步数T=50,学习率lr=0.99.本文实验探究2 种时间约束下的RR-SC搜索结果:对于MLP 来说,本文选择95 ms 和120 ms这2 种时间约束来进行实验探究;对于LeNet 来说,时间约束分别为540 ms 和2 700 ms;对于AlexNet 来说,时间约束分别设置为21 000 ms 和125 000 ms.本文共设置3 种V/F 等级,从高到低分别为表1 中的l6,l4,l3这3 个等级.相应地,对于在MNІST 数据集上进行训练的MLP 和LeNet 这2 种模型来说,3 种V/F 等级下的模型推理准确率约束分别设置为95%,90%,85%;对于在Cifar10 数据集上进行训练的AlexNet 模型来说,3 个V/F 等级下的模型推理准确率约束分别设置为90%,85%,80%.同时,对于反馈函数中的Au和Al分别设置为98%和60%.
4.2 RR-SC 框架评估
首先对于RR-SC 框架的评估,我们与现有的SC相关工作[13-16]进行对比.这些工作主要针对SC 算术电路进行设计,没有充分考虑硬件环境的动态改变.为了对比公平,将SC 相关的工作与通过RR-SC 搜索到的模型结构设置成一样的,并且数据精度取RRSC 方法中搜索出来的最高精度,然后对它们的模型推理准确率、时延及模型推理次数进行比较.
MLP 模型在不同时间约束下的结果与SC 相关工作的对比展示在表5 和表6 中.表5 展示了时间约束设置为95 ms 时的结果,表6 展示时间约束为120 ms时的结果.表5 实验得到的MLP 的模型结构为784-200-32-10,表示模型具有3 层全连接层,并且全连接层的神经元的个数分别为200,32,10.表6 实验得到的模型结构为784-128-100-10 这2 组实验选择的SC算术电路均为AND-LOOP.我们将RR-SC 选择出来模型结构及相应的算术电路进行可视化展示,如图4 所示.RR-SC 实验中的硬件配置均设置成表1 中的l6,l4,l3.对于其他对比工作来说,V/F 等级设置为l6.从实验结果中可以看出,AND-LOOP 方法[16]拥有最高的推理准确率,XNOR-MUX 方法[13]拥有最低的推理准确率.RR-SC 方法的平均准确率仅比ANDLOOP 分别低1 个百分点和1.5 个百分点.然而,RRSC 的推理次数是AND-LOOP 推理次数的2.0 倍和2.8 倍.在众多参数中,RR-SC 找到了最好的配置.对于XNOR-MUX 和uGEMM 来说,它们的模型推理准确率和时间约束都无法满足我们的要求的.同时,RRSC 在推理次数方面实现了高达7.6 倍的提升.对于AND-SEP 和AND-ACC 来说,它们在MLP 784-200-32-10 模型能够满足我们的时间约束要求,但是在MLP 784-128-100-10 这个模型上的时间约束要求无法被满足.从准确率和推理时间来说,AND-ACC 是最具竞争力的一个方法.对于推理次数来说,由于结合了硬件重配置和软件重配置,RR-SC 比AND-ACC 实现了约1.8 倍的性能提升.RR-SC 方法可以在满足一定的时间约束和准确率约束的情况下,最大化模型推理次数和平均准确率,拥有最好的性能权衡.
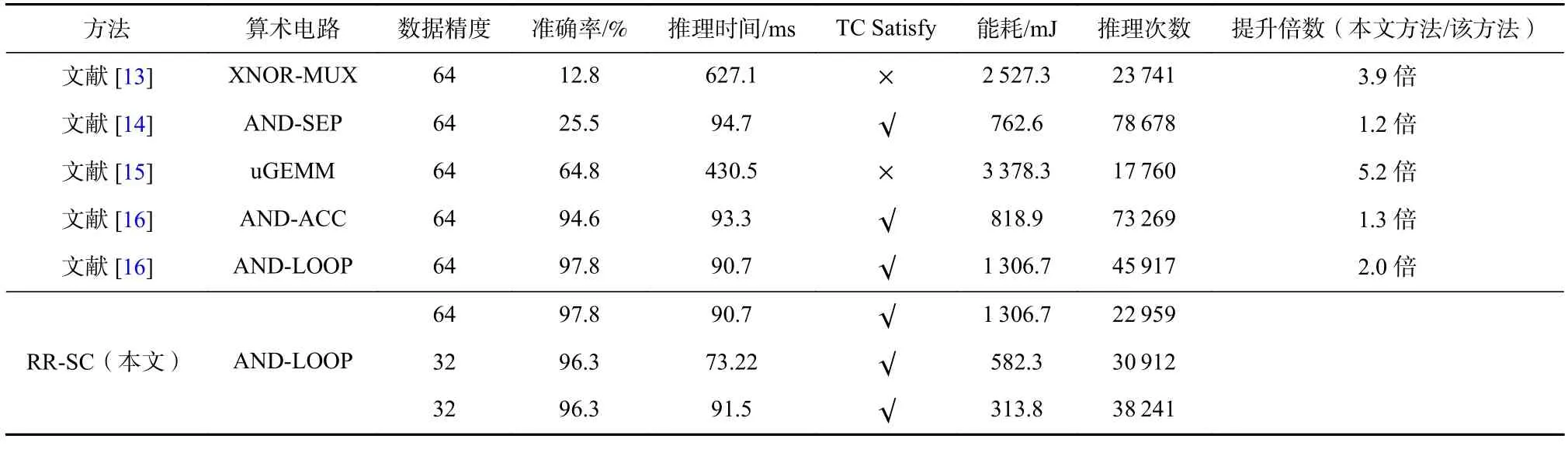
Table 5 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 95 ms on MLP表5 MLP 上SC 相关工作和RR-SC 在时间约束为95 ms 时的比较结果
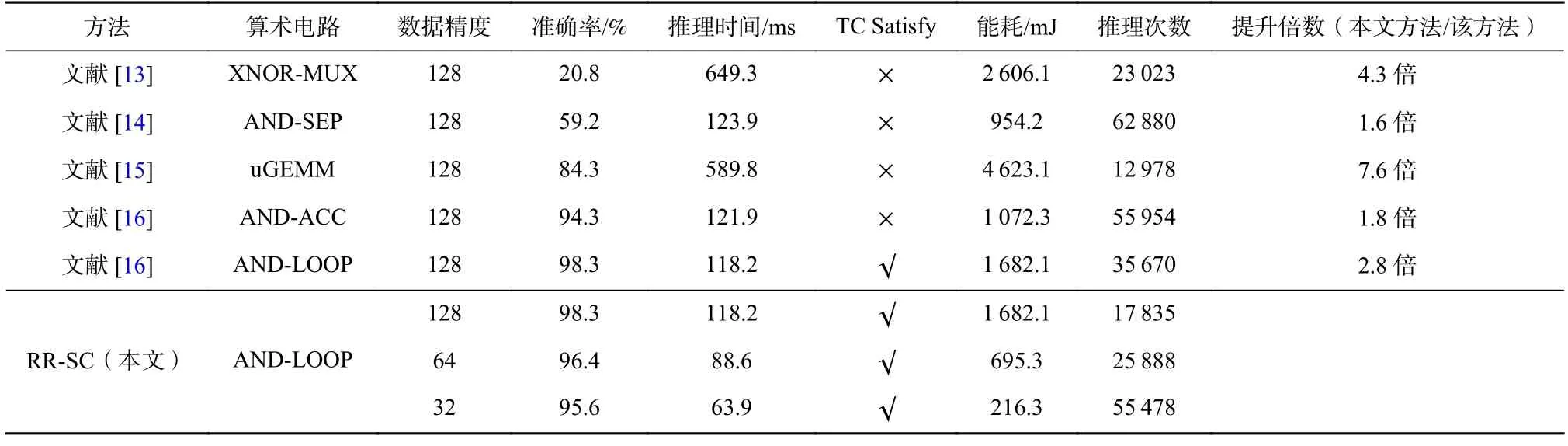
Table 6 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 120 ms on MLP表6 MLP 上SC 相关工作和RR-SC 在时间约束为120 ms 时的比较结果
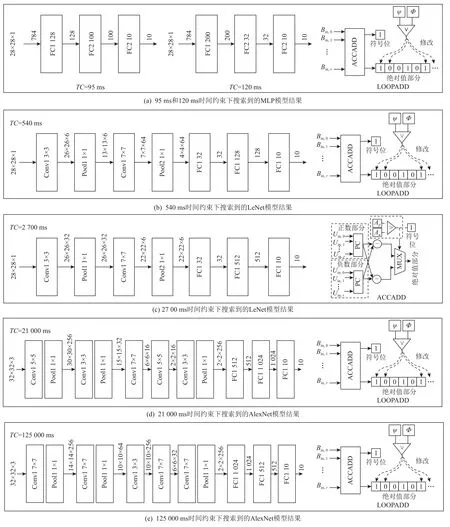
Fig.4 Visualization of the model architecture and SC arithmetic circuit searched by RR-SC图4 RR-SC 搜索到的模型架构和SC 算术电路可视化
对于LeNet 来说,同样地,一个较紧的时间约束实验结果和一个较松的时间约束实验结果分别被展示在表7 和表8 中.表7 中的实验设置时间约束为540 ms,表8 实验设置时间约束为2 700 ms.AlexNet的实验结果被展示在表9 和表10 中,设置时间约束分别为21 000 ms 和125 000 ms.因为LeNet 和AlexNet相较于MLP 更大、也更复杂,因此我们设置了更长的时间约束.对于表7 中的实验,一个结构为Conv1(k=3,s=1,c=6)-Pooling1(k=1,s=2)-Conv2(k=7,s=1,c=64)-Pooling2(k=1,s=2)-FC1(32)-FC2(128)-FC3(10)的 主干网络被选择出来.对于表8 中的实验来说,主干网络结构为Conv1(k=3,s=1,c=32)-Pooling1(k=1,s=1)-Conv2(k=5,s=1,c=6)-Pooling2(k=1,s=1)-FC1(32)-FC2(512)-FC3(10).其中,k表示卷积层或池化层的核大小,s表示卷积层和池化层的滑动步长,c表示卷积层的输出通道数.在卷积层和池化层之后紧接2 个全连接层.对于AlexNet 网络来说,表9 实验下选择出来的主干网络模型为Conv1(k=5,s=1,c=256)-Pooling1(k=1,s=1)-Conv2(k=3,s=2,c=32)-Pooling2(k=1,s=1)-Conv3(k=7,s=2,c=16)-Conv4(k=5,s=2,c=16)-Conv5(k=3,s=1,c=256)-Pooling3(k=1,s=1)-FC1(512)-FC2(1 024)-FC3(10),表10 实验下选择出来的主干网络模型为Conv1(k=7,s=2,c=256)-Pooling1(k=1,s=1)-Conv2(k=7,s=1,c=64)-Pooling2(k=1,s=1)-Conv3(k=3,s=1,c=256)-Conv4(k=7,s=1,c=32)-Conv5(k=7,s=1,c=256)-FC1(1 024)-FC2(512)-FC3(10).同样地,对于LeNet 和AlexNet 的实验中选择出来的模型参数也被展示在图4 中.对于LeNet 来说,当TC=540 ms 时,RR-SC 选择出来的SC 算术电路是AND-LOOP,对于TC=2 700 ms 时,RR-SC 在ANDACC 上有更好的表现.从准确率的角度来说,ANDLOOP 依然能够获得最高的推理准确率,但RR-SC 在产生高达3.1 倍的硬件效率的同时,只产生了1.2%的准确率丢失.从推理时间的角度来说,有些SC 工作在推理时能够满足我们约定的时间约束,但由于缺乏软件和硬件的重配置,使得硬件效率没有被充分发挥.对比所有的方法,RR-SC 能够产生最高4.4倍的性能提升.对于AlexNet 来说,当TC=21 000 ms时,RR-SC 能够产生高达4.9 倍的硬件效率提升,但比拥有最高准确率的AND-LOOP 电路只产生了1.7%的准确率损失.类似地,当TC=125 000 ms 时,RR-SC比其他方法最高能达到7.3 倍的运行数提升,相比AND-LOOP 电路准确率损失只有0.9%.同时,RR-SC也能够满足设定的时间约束和准确率约束.

Table 7 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 540 ms on LeNet表7 LeNet 上SC 相关工作和RR-SC 在时间约束为540 ms 时的比较结果
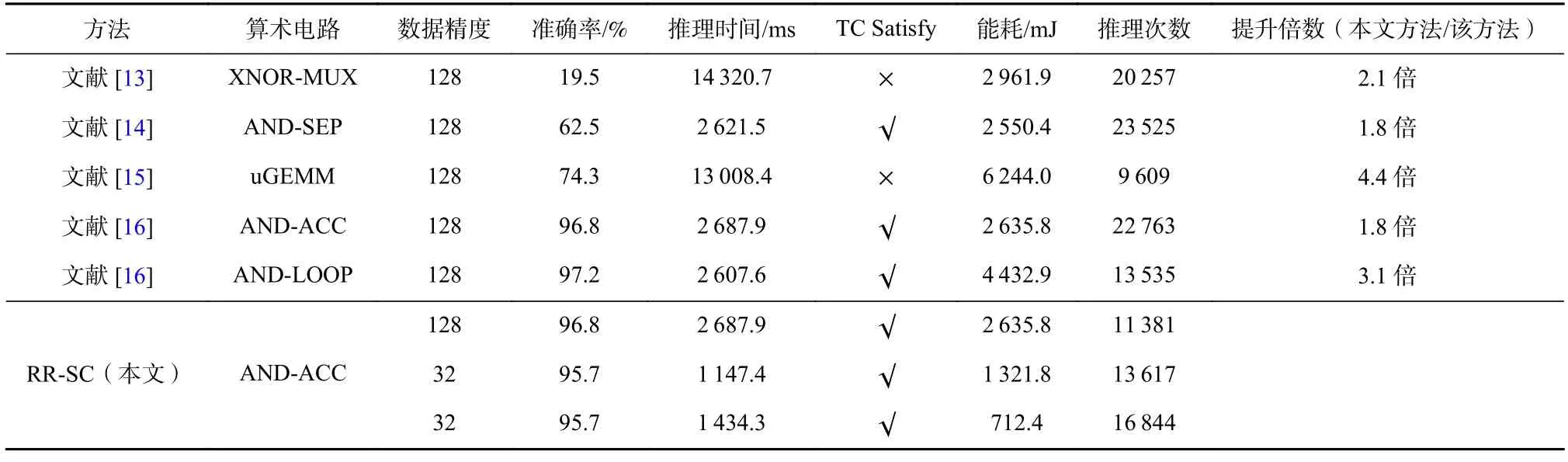
Table 8 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 2 700 ms on LeNet表8 LeNet 上SC 相关工作和RR-SC 在时间约束为2 700 ms 时的比较结果
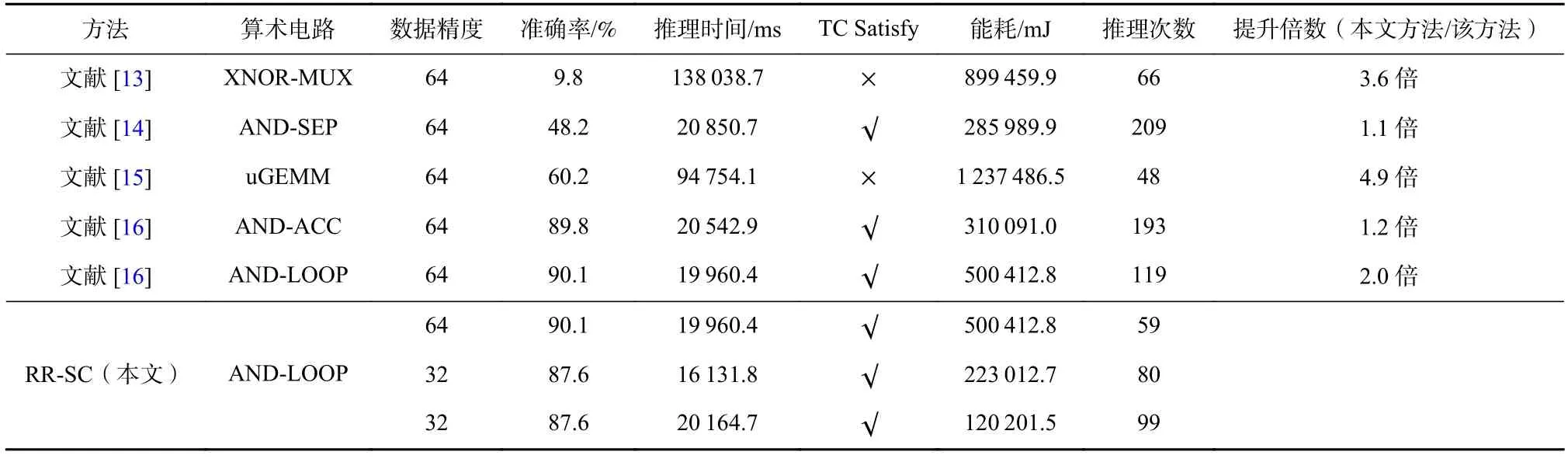
Table 9 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 21 000 ms on AlexNet表9 AlexNet 上SC 相关工作和RR-SC 在时间约束为21 000 ms 时的比较结果

Table 10 Comparative Results of SC Relative Work and RR-SC with the Time Constraint 125 000 ms on AlexNet表10 AlexNet 上SC 相关工作和RR-SC 在时间约束为125 000 ms 时的比较结果
除此之外,RR-SC 产生的模型在不同配置中进行切换时产生的开销也非常小.对于MLP 来说,模型切换需要约9 ms;对于LeNet 来说,模型切换需要约110 ms;对于AlexNet 来说,模型切换需要约4 030 ms.RR-SC 支持实时轻量级的模型切换.MLP,LeNet,AlexNet 每次因V/F 等级切换而切换数据精度时产生的能耗开销分别为18 μJ,220 μJ,8.1 mJ.
4.3 硬件和软件重配置方法评估
在本节中,我们对软硬件重配置方式进行比较.MLP,LeNet 和AlexNet 的配置使用RR-SC 选择出来的模型结构、算术电路和数据精度进行实验对比.我们分别对比了无任何重配置、只有硬件重配置(HW)、只有软件重配置(SW)和结合软硬件重配置(RR-SC)4 种方法.对于所有的方法,MLP 结构设置为784-200-32-10,LeNet 结构设置为Conv1(k=3,s=1,c=6)-Pooling1(k=1,s=2)-Conv2(k=7,s=1,c=64)-Pooling2(k=1,s=2)-FC1(32)-FC2(128)-FC3(10),AlexNet 模型结构设 置为Conv1(k=5,s=1,c=256)-Pooling1(k=1,s=1)-Conv2(k=3,s=2,c=32)-Pooling2(k=1,s=1)-Conv3(k=7,s=2,c=16)-Conv4(k=5,s=2,c=16)-Conv5(k=3,s=1,c=256)-Pooling3(k=1,s=1)-FC1(512)-FC2(1 024)-FC3(10),均使用在相对低的时间约束下RR-SC 选择出来的模型结构.为了公平比较,这4 种方法均使用相同的SC 算术电路,即AND-LOOP.对于硬件重配置来说,3 个V/F 等级依然设置为l6,l4,l3.类似地,只有软件重配置的设置和只有硬件重配置的其他配置被展示在表11、表12 和表13 中.

Table 11 Experimental Results of Methods with/Without Hardware and Software Reconfiguration on MLP表11 MLP 模型上搭配/不搭配软硬件重配置方法的实验结果
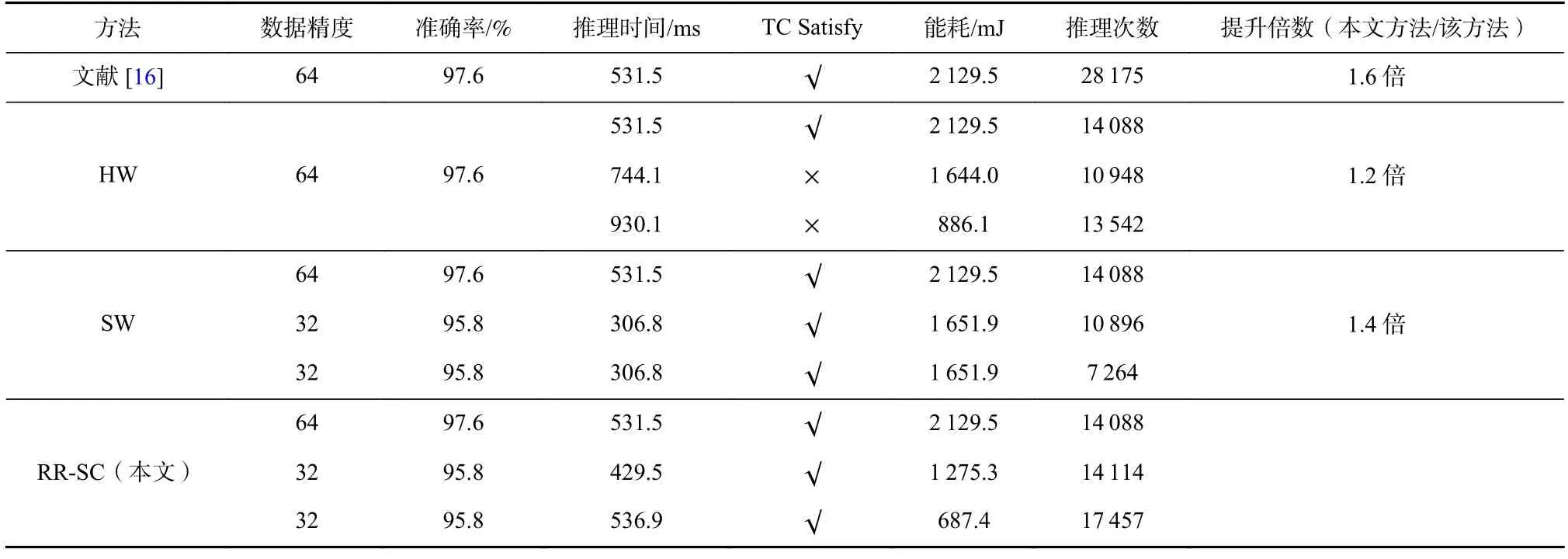
Table 12 Experimental Results of Methods with/Without Hardware and Software Reconfiguration on LeNet表12 LeNet 上搭配/不搭配软硬件重配置方法的实验结果

Table 13 Experimental Results of Methods with/Without Hardware and Software Reconfiguration on AlexNet表13 AlexNet 上搭配/不搭配软硬件重配置方法的实验结果
表11~13 实验结果表明,当模型不搭配任何的软硬件重配置时,虽然其拥有最高的推理准确率,且时间约束能够被满足,但是它能进行的模型推理次数是最少的.当模型只搭配硬件重配置时,模型推理的时间约束无法被满足,但其对延长电池使用时间有一定的优化.对于只有软件重配置的实验来说,模型的时间约束都能被满足,但推理准确率有一定的下降,且推理次数也比只搭配硬件和RR-SC方法更少.对于RR-SC 方法来说,能够在满足时间约束的条件下,最大限度延长电池的使用时间,相比于无任何软硬件配置的实验有接近2.0 倍的性能提升;对比只有硬件重配置或只有软件重配置的方法来说,能够达到1.5 倍的性能提升;而且,RR-SC相比于最高的准确率来说,在MLP,LeNet 和AlexNet中分别只产生了1.0 个百分点,1.2 个百分点,1.7 个百分点的下降.
5 结论
对于电池搭载的边缘设备来说,能源(即电池电量)是有限且动态改变的.面对这种硬件环境,本文针对基于SC 的神经网络创新性地提出了硬件和软件重配置相结合的方法以最大限度地延长电池使用时间.对于不断改变的电池电量来说,本文设置电量阈值以便于在电量降低到一定程度之后进行硬件配置的切换(即切换V/F 等级).同时,为了选择最好的软件配置,本文提出一个运行时可重配置框架RRSC,在满足模型推理时间约束和准确率约束的前提下,最大化模型推理准确率和推理总次数.RR-SC 利用强化学习技术能够一次性选择多组软件配置以对应不同的硬件配置.每组配置能够同时满足规定的时间约束和准确率约束.同时,多个模型配置在同一个主干网络上进行切换,从而在运行时实现轻量级的软件重配置.实验结果表明,RR-SC 在给定能源总量的情况下最高可以将模型推理次数增加7.6 倍,且精度损失相较于最高准确率方法小于1.7 个百分点.同时,可以在110 ms 内进行LeNet 模型配置的轻量级切换,并且可以满足不同硬件配置下的实时性要求.
作者贡献声明:宋玉红提出论文方案,完成实验和撰写论文;沙行勉提出指导意见和分析方案;诸葛晴凤提出指导意见和讨论方案;许瑞和王寒参与方案讨论和修改论文.
