基于引用情感的跨学科知识内化规律* 以我国图书情报学科为例
2024-04-25顾继光
姜 霖 顾继光
(1.南通大学经济与管理学院 南通 226019;2.江苏省数据工程与知识服务重点实验室 南京 210023)
0 引 言
随着大科学时代的到来,科学系统及其学科分类日渐复杂。各门学科之间不再相互独立,而是表现出相互联系、彼此交叉融合的特征[1]。近年来,越来越多的学科交叉领域逐渐成为科学前沿,许多重大突破性科学成果的产生和复杂科学性问题的解决都得益于学科知识的交叉融合[2]。学科交叉的本质是整合来自多个研究领域的理论、方法、工具、概念等,为复杂科学问题的解决提供更全面的视角[3]。学科交叉融合已逐步成为现代知识创新发展的新动力。
现有的学科交叉研究多关注宏观层面的跨学科态势分析,以学术论文的引证关系为研究对象,探究学科交叉程度的测度方法以及跨学科知识的转移规律[4]。而从引用内容角度出发,从微观层面对学科交叉中知识整合过程的研究相对较少。学科交叉中知识整合过程可理解为对不同学科的知识进行吸纳并内化到本学科核心知识体系中的过程。在对交叉领域知识整合过程进行分析时,知识内化过程是核心。探究学科交叉中知识的内化过程,对于深入了解学科间交叉融合现象产生的动力因素,理解新学科边界的形成和发展,进而推动学科知识的创新和发展都有着重要意义。
近年来,引文内容分析被视为一种传统引文分析的替代方法[5]。引文内容中蕴藏着被引文献在施引文献中被提及的具体知识内容,是研究学科间知识流动的有效平台[6]。在学科交叉研究中,将引文内容纳入分析框架,有助于从微观层面深度揭示学科之间的知识关联,为显性观察学科交叉的知识吸纳和内化过程提供必要条件。引用情感作为引文内容研究的一部分,蕴含在引用内容中,表达了施引文献作者对被引文献的情感态度,可以进一步反映跨学科知识点在本学科知识体系整合过程中被接纳的程度。本文结合引文分析和情感分析方法,通过挖掘引文内容、参考文献原文以及领域自身核心知识体系之间的知识匹配关系,借此理清交叉学科知识的来龙去脉,揭示学科交叉中知识的内化过程、推动因素以及规律。本文以图情领域作为研究对象,探究该学科内的知识内化规律,期望从知识来源的角度揭示跨学科知识的融合过程,丰富微观层面学科交叉规律的研究,为交叉领域知识发现和知识创新提供路径指导。
1 相关研究
1.1 学科交叉知识整合过程研究
学科交叉领域的概念最早源于“Interdisciplinary(学科交叉/跨学科)”一词,由Woodworth于1926年在美国社会科学研究委员会议上提出,认为跨学科是超越一个已知学科的边界而进行的涉及两个或两个以上学科的研究领域[7]。交叉领域的产生和演化表现为对来自不同学科的知识单元进行知识整合。早期关于交叉领域的研究主要通过引证关系来理解学科交叉的程度和揭示知识从相关学科流动到交叉领域的规律。
不同学科领域知识点在相互吸收和融汇互通的过程中,伴随着对跨学科知识点的吸收与内化[8]。近年来,一些学者开始关注学科之间的知识关联,研究学科交叉领域知识内容层面的规律。Ba[9]等利用共词分析方法构建知识点网络,探究医学信息学和计算机科学两个学科的知识整合关系。温芳芳[10]等选取Web of Science核心集中有关新冠肺炎主题的论文为研究对象,利用关联规则挖掘方法探究新冠病毒研究领域的多学科知识融合特征,挖掘从知识吸收、知识内化到知识输出的关联性。这些研究所得的成果和发现有助于发现和揭示多学科知识整合的规律,但它们多局限于某个领域文献的元数据层面,尚未升入到引文内容中,一些研究者发现,通过深入到引文内容中可以进一步揭示交叉领域的知识整合过程[11]。
1.2 引用情感分析
2012年,Ding等提出了基于引文内容分析研究框架,并指出引文内容分析是下一代引文分析的一个重要研究方向[12]。引用内容指的是在论文正文中有引用标识(如[1]、[1、2]、[1-3]等)的句子的集合,它可以是一组句子,一句话或一个句子的部分。引文内容中不但蕴藏着被引的具体知识内容,还隐藏着作者的引用动机,引用情感等深层次信息,是研究学科知识交流过程的有效平台。从学科交叉研究的角度来看,从引文内容出发,可以将不同学科间的知识流转过程具象化,从而更深入地挖掘不同学科间知识的关联性,为研究不同学科间的知识吸收与内化过程提供了必要条件。引文内容分析主要可以分为两个部分,一部分是引用中文本内容的研究,另一部分是引用中情感的研究。
引文情感反映了施引文献作者对被引文献的情感态度和情感倾向[13]。在引用情感研究方法方面,Moravcsik等通过对引文内容的人工解读来判断引文情感,并将其分为肯定引用、否定引用等五个维度[14]。但是由于当时技术水平的限制,引用情感识别主要通过问卷调查和人工判读的方法,存在效率低、主观性强等不足。随着自然语言处理技术的发展,引文情感识别的相关研究取得了一些进展。Teufel等提出了一种基于监督学习的引用情感自动分类框架,通过自动化情感分析技术准确地进行引用情感识别[15];刘盛博等提出了一种基于数据挖掘的引用情感识别方法,通过引用内容的语义判断引用情感,从而构建了一个基于引用内容的引文评价平台[16]。通过对引文内容中作者对吸纳知识反应的情感态度,可以进一步反映跨学科知识单元在学科知识体系中被接纳的程度,有助于发现新的学科知识生长点和推动知识创新。
2 研究思路和方法
2.1 研究思路
为了有效探究跨学科知识吸纳和内化过程,本文以词汇作为跨学科知识单元的观察对象,通过识别引用内容中蕴含的知识单元来观察跨学科知识在学科间的流动过程,利用情感分析技术,对跨学科知识在内化过程中被本学科接纳和吸收的程度进行量化分析,希望借此探寻跨学科知识从吸纳到内化过程中存在的规律。具体研究思路如下:以学科领域内的参考文献集为起点,基于参考文献来源期刊的所属学科,识别参考文献集中的跨学科引用,将跨学科知识的吸纳具象化为跨学科引用文本内容中对被引文献包含的跨知识单元(词汇)的使用。而知识内化则是指本学科学者在对前人知识(词汇)进行吸纳的基础上,将这些知识应用于本学科研究领域内复杂问题的解决,知识的传播和共享,推动本学科其他学者进行吸纳和理解,并进一步应用于知识创新的过程。
本文将跨学科知识的“吸纳-内化”过程操作化为从跨学科文献中吸纳的知识单元(词汇)进一步被整合到本学科知识体系结构中的过程。通过对引用内容文本中的知识点匹配,观察跨学科知识在学科内部的流动,并利用情感分析技术识别、量化跨学科知识在吸纳和内化节点上被本学科知识体系所接纳的程度。具体实施方法路径如图1所示。

图1 跨学科知识内化研究框架图
2.2 实现方法
2.2.1数据采集
首先,获取学科文献的全文数据,本文选取知网(CNKI)作为学术文献资源获取平台,利用网络爬虫对选取的期刊数据全文本进行下载,并将全文本数据解析成文献元数据、文本内容信息和参考文献信息,利用XML语言对获取的数据进行整理和持久化。通过使用正则表达式对参考文献的文内引用标识进行识别匹配,进一步将参考文献与引用文本内容关联起来。
2.2.2内化知识的识别和情感量化
①跨学科知识吸纳识别。跨学科知识主要通过跨学科引用融入到本学科知识体系中,本文借鉴学科专业目录使用人工标识参考文献来源期刊所属学科的方法,来识别本学科借鉴的跨学科文献。虽然在学科交叉、学科融合的当下,学科界限日益模糊,但大部分期刊所刊载的研究文献依然各自集中在本学科领域,通过学术期刊的学科归属来辨别跨学科知识的来源具有一定的合理性和可行性。本文借助FudanNLP工具包(复旦大学自然语言处理实验室编写的中文自然语言处理开源项目,提供了包括分词、词性标注、句法分析、关键词提取等多种功能,下载地址: https://github.com/FudanNLP/fnlp),挖掘文献跨学科引用内容中蕴含的关键词,并将其作为吸纳的跨学科知识,具体的跨学科知识识别样例如图2所示。

参考文献卢海阳, 郑逸芳, 黄靖洋.公共政策满意度与中央政府信任———基于中国16个城市的实证分析[J].中国行政管理, 2016 (8) :92-99.期刊名称中国行政管理所属学科管理学(公共管理)文献引用内容公共政策的顺利推行是社会运行的基础, 而政策受众支持度作为政府事前评估的一项重要指标, 一方面可辅助相关部门的最终决策, 另一方面也会对当局产生强大的舆论监督, 显著影响民众对政府的信任机制[1,2]吸纳知识点公共政策 受众支持度 事前评估 舆论监督 信任机制参考文献高阳, 严建峰, 刘晓升.朴素并行LDA[J].计算机科学, 2015 (6) :243-246期刊名称计算机科学所属学科工学(计算机科学与技术)文献引言内容PLDA相较于LDA模型, 可以有效减少分析大规模文档集或语料库中潜藏的主题信息的计算时间[20], 提高算法的运行效率和并行的加速比, 而且在精度方面也能得到充分保证。吸纳知识点PLDA LDA模型 语料库 算法 运行效率
②跨学科知识内化识别。本文从多学科层面,认为跨学科知识的内化过程本质上是吸纳的多学科知识被进一步整合到本学科知识体系结构中的过程。本文利用标注的跨学科参考文献,识别跨学科引用内容中包含的学科知识,随着该文献蕴含的跨学科知识再次被样本文献集中本学科的文献引用和吸纳,跨学科知识也随之融入到本学科的知识体系中。为了能够观察引用内容中跨学科知识随着引用路径的迁移过程,本文借鉴了知识点匹配算法[17],采用了2种匹配方式。
a.词-词匹配。对两个来源(跨学科吸纳引用文本内容和内化引用文本内容)中的关键词实施一对一匹配;
b.相似词匹配。对两个来源中的关键词实施词相似度匹配。以样本集中的文献标题、关键词、摘要、引用内容作为词向量训练样本集,通过word2vec模型得到词向量,通过余弦相似度算法对关键词实施匹配,余弦相似度的阈值设定为0.9。
由于引用内容中知识点关键词提取不准确,包含“算法”“领域”“研发”这样的泛化词,所以实际进行知识点匹配时,当有超过3个词匹配时,才认为指代的是相同的知识点。
③引用情感量化。本文认为学科领域专家在引用内容中表达出的对于跨学科知识的情感态度,对于跨学科知识融入到本学科知识体系中的过程存在促进或者抑制作用。具体的吸纳和内化情感变化样例如图3所示。

被引跨学科文献标题基于Python自然语言处理工具包在语料库研究中的运用跨学科知识来源学科工学(计算机科学与技术)吸纳文献标题基于LDA和战略坐标的专利技术主题分析———以石墨烯领域为例吸纳引用内容Python语言是一门功能强大的编程语言, 尤其是基于计算机编程语言Python的NLTK工具包是一个可用于对自然语言进行清洁、赋码、检索、语法及语义分析等处理的工具包, 适合用于处理语言数据, 且功能全面, 可以组合起来解决复杂问题[16], 因此, 本文技术名词提取阶段主要借助Python完成, 把专利文档转换成由多个技术名词所构成的特征向量, 为下一阶段的主题模型识别奠定基础吸纳知识点Python;编程语言;NLTK;自然语言;主题模型;特征;向量;技术;名词;专利情感词强大 全面情感倾向正向内化文献标题基于Chunk-LDAvis的核心技术主题识别方法研究内化引用内容伊惠芳等[18]结合LDA模型和战略坐标图方法进行专利技术主题分析, 识别出其中的核心技术主题及其结构特征, 对于客观合理地追踪技术前沿、提高研发效率具有重要意义内化知识点战略坐标;技术;前沿;专利;LDA模型;主题;特征情感词合理 提高情感倾向正向
本文借鉴了图传播算法[18],对蕴含在引用文本内容中的情感倾向进行识别和量化。采word2vec构建词向量模型,通过余弦相似度,作为词语之间的相似性,并将这一结果将作为后续分析中两词之间的图形距离。任何词与其自身的距离均为1。情感词表自动构建初始,需通过人工选择方式分别向正向种子词集和负向种子词集中添加该极性引用情感中表达程度最深的词。例如,可向正向种子词集中添加“大大提高”,向负向种子词集中添加“极差”,通过比较每个词到正、负词集中词的平均距离,计算词的情感极性值。详细算法步骤如下所示。
输入:假设输入为无向边加权图G=(V,E),其中Wi,j∈[0,1]是边的权重(vi,vj)∈E,V表示包含在情感词典中的候选词集,G表示节点之间的语义相似性。P,N,γ∈R,T∈NP代表正向情感种子集,N代表负向情感种子集,γ代表阈值,当词极性绝对值小于该阈值时,认为该词的词性为中性,T代表候选词集中的词总数。
输出:pol∈R|v|(pol代表词的极性)
初始化:poli,pol+i,pol-i=0,对于所有词i
pol+i=1 对于所有正向词集中的向量vi∈P
pol-i=-1 对于所有负向词集中的向量vi∈N
1.设置αii=1 ,和αij=0 对于所有的i≠j
2.对于向量vi∈Ρ
3.F={vi}
4.对于t:1…T
5.对于(vk,vj)∈E所以vk∈F
6.αij=max{αij,αik?ωkj}
F=F∪{vj}
7.对于所有的vj∈V
8.pol+j=∑vi∈Pαij
9.重复1-8,使用N来计算pol-
10.β=∑ipol+i∕∑ipol-i
11.poli=pol+i-βpol-i,对于所有的i
12.如果|poli|<γ就使poli=0.0 ,对于所有的i
通过阈值的设定可以去除引用内容中包含的大部分中性词,较为准确地识别出情感词及强度。但由于引用情感的复杂性和特殊性,如“训练时间长”“大量人工参与”等语义词组中,单个词并不具有明显的情感倾向,如“训练时间”“长” “大量”“人工参与”,只有在作为词组时,才能体现出在引用情感上的变化,所以本文利用添加外部词表的方式,在分词时将这些特殊的词组视为一个整体,整体识别出语义情感倾向和强度。
2.2.3知识内化量化分析指标
本文主要从两个方面来探究跨学科知识的内化规律:跨学科知识的内化总体特征和不同来源学科知识被本学科内化和接纳的特征。
本文使用表1的各项指标来衡量跨学科知识的内化特征。首先借鉴了部分前人的研究成果[19],从吸纳的跨学科知识数量、内化知识数量、知识内化率和知识内化时滞指标,考察整个学科领域跨学科知识融入的总体状况。然后,利用引用情感作为评价交叉领域中不同学科知识被本学科接纳和吸收程度的重要指标,并将每年跨学科引用内容中蕴含的吸纳情感和内化情感融合起来,设置了内化情感驱动指数以衡量不同学科内的跨学科知识被接纳的程度。希望通过这些指标的测度来深入揭示不同来源学科知识与本学科知识之间的存在的知识关联,以及被本学科知识体系接纳和吸收的程度。
3 实证分析
3.1 数据来源
本文以我国图情领域作为研究对象,选择了中文核心期刊目录(CSSCI)图情领域期刊中具有较高学术影响力和影响因子的6本期刊作为具体数据来源,包括《中国图书馆学报》《情报学报》《图书情报工作》《情报杂志》《情报理论与实践》《情报资料工作》,采集了期刊2017—2021年发表的文献全文本,共6 971篇(去除了荐读、序、通知等非规范论文)。经过识别统计,数据集中包含的规范性学术引用共132 461条,其中跨学科引用61 611条,每年的跨学科引用情况分布如图4所示。
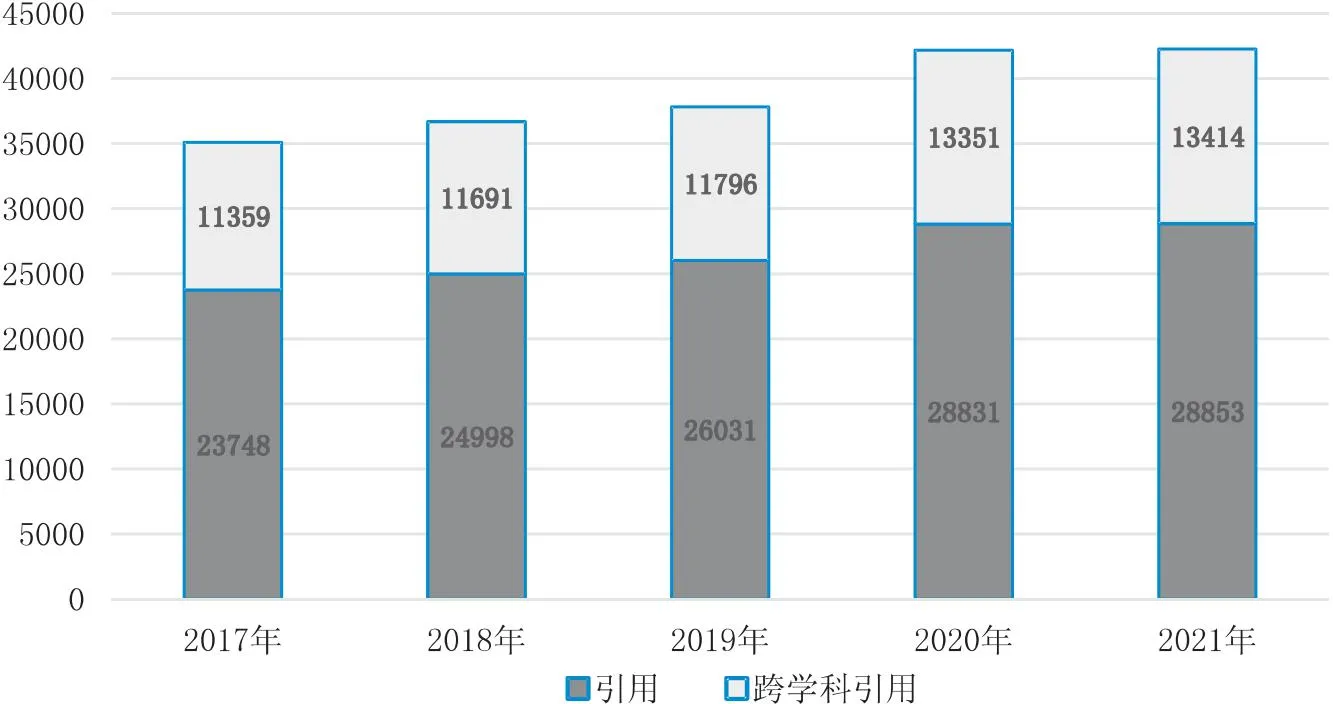
图4 学科引用情况年份分布图
由图4可知,国内图情领域研究中与其他学科存在较多的交叉研究内容,总体引用中有超过40%的引用来自于其他学科的期刊资源,并且近年来跨学科引用的数量呈现逐年递增的趋势。
3.2 内化跨学科核心知识识别
文献关键词可视为对全文核心知识内容的凝练,本文选取代表领域核心知识的特定关键词,并以该关键词作为领域核心知识,从图情领域文献样本集中,共识别出37 213个不重复的吸纳知识,12 795个领域核心知识,以及4 012个内化知识。利用关键词匹配算法,对吸纳知识,领域知识,内化知识中的核心关键词进行了词频统计。图5给出了出现频次前20的吸纳知识和前20的领域核心知识关键词,并在统计时对同义词进行了合并。交叉部分体现了这些吸纳的跨学科知识在图情领域研究中的落脚点以及新的跨学科知识生长方向。从图中可以看到,图情领域和较多学科都存在交叉,存在交叉较多的学科有计算机科学、法学、心理学、社会学以及统计学,主要的交叉方向集中在专利、大数据、网络舆情、智慧城市、数据治理、知识共享、区块链、情感分析以及健康信息等方向。
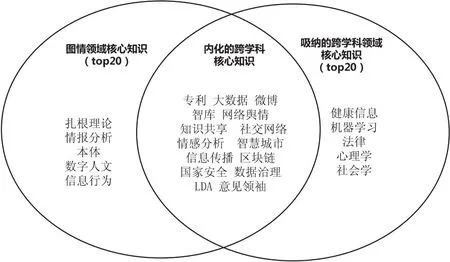
图5 跨学科吸纳知识、内化知识和图情领域核心知识集合(部分)
3.3 跨学科知识内化总体特征
根据表3中提出的知识吸纳和内化指标分析跨学科知识内化总体特征。图6统计了每年吸纳知识和内化知识的数量,图7呈现了吸纳知识在未来的某一年中转化为内化知识的比例,即知识内化率。从图7中可以观察到,近年来跨学科知识的内化率呈现出逐年稳步上升的趋势,这一现象表明,国内图情领域对于跨学科知识的吸纳呈现更加积极的态度,并且图情领域的研究范围越趋综合化,越来越多地依赖于多学科知识的融入。但同时图7也显示2017年左右的跨学科知识内化率较低,这是因为跨学科知识的内化存在一定的时滞效应,而本文选取了2017年这个时间节点,因此当年吸纳的跨学科知识尚未全部内化,所以在截取节点附近,跨学科知识内化率会显著偏低,但之后会随之呈现为较为缓和的趋势,综合来看图情领域的跨学科知识内化率大致稳定在0.16左右。

图6 吸纳知识和内化知识数量年份分布
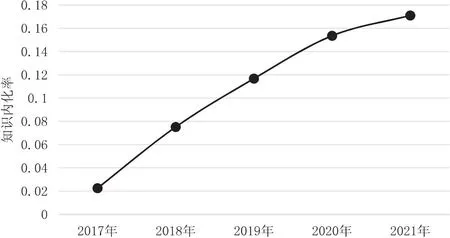
图7 知识内化率年份分布
本文也对国内图情领域跨学科知识内化的时滞效应进行了探究。知识内化时滞是指样本文献集中借鉴的跨学科知识从吸纳到融入本学科知识体系的时间间隔。图8显示了近5年内化知识的时滞均值随时间呈现逐渐减小的趋势。这说明,图情领域对于新知识的接纳周期在逐渐缩短,新跨学科知识的引入对于图情领域复杂问题的解决,学科的发展起到了越来越重要的作用。2021年左右呈现的时滞时间显著较低主要是因为数据采集截点是2021年,2021年左右吸纳的跨学科知识尚未被完全内化。
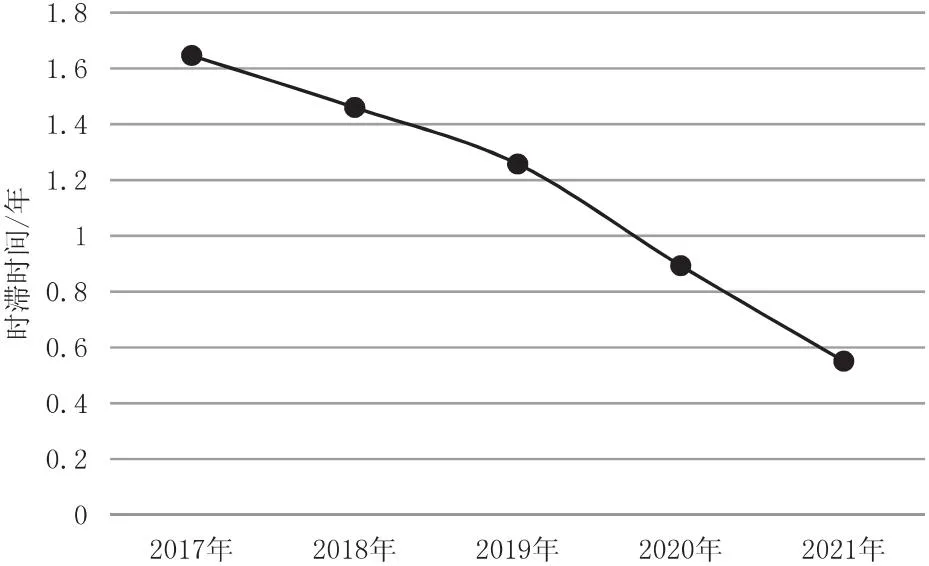
图8 跨学科知识内化时滞年份分布
3.4 不同来源学科的知识内化特征
表2统计了不同来源学科的跨学科引用数量。通过观察表2可知,国内图情领域跨学科知识主要来源于工学、教育学、法学、理学、文学和管理学方向。管理学较少是因为图情领域本身属于管理学,并且与管理学中其他研究方向存在较小的学科差异,导致部分跨学科知识来源不明显。除上述学科外,其他来源的学科知识被引数量并不大,且受社会环境影响存在较大的波动性。同样,近年受疫情影响,有关医学的研究方向受到广泛关注,被引知识数量逐年攀升。

表2 不同学科引用数量年份分布表 单位:条
结合表3通过对比不同学科知识融合时滞时间,图情领域中跨学科知识的“吸收-内化”过程大致都需要经历一年半左右的时间。法学和教育学的知识内化时滞相较于其他学科而言会稍短一些,这可能与新法律法规的出台,新型教育理念的提出都具有其时代性特征,所以相对而言这些知识的吸纳会具有时效性,因此时滞时间会偏短。从知识内化率来分析,工学内化率最高,其次是管理学和理学。工学中主要是计算机科学中相关新算法模型的知识,管理学主要是关于政府数据开放、数据治理,以及理学中与统计学相关的复杂网络、评价指标方法等跨学科知识的融入对于图情领域的发展有重要影响且较容易被吸纳和内化。

表3 不同学科跨学科知识特征年份分布表
为进一步分析和比较跨学科知识内化率和情感驱动指数间的关系,利用SPSS统计分析软件对两项指标进行了斯皮尔曼秩相关分析。秩相关系数,也称为“等级相关系数”,是常用的反映相关程度的统计分析指标[20-21],结果显示在0.01水平(双侧)两项指标显著相关,相关系数为0.772,说明情感驱动指数与知识内化率高度正相关,并能很好地反映跨学科知识在本学科内部被接纳的程度,为预测哪些学科的新进展会为图情领域带来新的发展契机提供帮助。
结合图9、图10以及表5中可知,总体而言,近5年越来越多的跨学科知识在图情领域被接纳和认可,知识内化率也同步稳步提升。从交叉学科来看,2018年至2019年计算机领域中关于神经网络、人工智能方向的研究,教育学中2018至2019年间,对于高等教育体系中健康信息、数据素养的研究,在2020年到2021年间,法学研究方向中关于数据保护、信息保护的研究,2020至2021年间,理学中利用统计学理论和方法对于大数据环境下谣言传播、社会网络的研究,在2019至2020年间,文学中对于新闻环境下舆情反转、传播学的研究,以及2017至2018年间,管理学中对于政府数据开发、数据治理的研究,都为图情领域的研究注入了新的活力和带来了新的发展契机。

图9 不同学科知识内化率年份分布

图10 不同学科情感驱动指数年份分布
4 结 语
学科交叉研究一直以来都是科学计量学领域关注的热点主题。其重要性体现在学科交叉对于增强复杂科学问题的理解和认知以及推动知识创新等方面具有重要作用。近年来,有关学科交叉的研究已经从单纯的宏观层面上,对学科交叉测度、学科交叉态势分析转向更微观层面的学科交叉内容主题探究。本文在前人研究的基础上,从引用内容出发,利用情感分析方法捕捉文献主体(作者)对于跨学科知识表现出的情感态度,揭示学科体系中对于跨学科来源知识的整个“吸纳-内化”过程,并以图情领域为例验证了方法的有效性。
本文一方面从跨学科知识来源视角,理清图情领域跨学科知识整合的微观形成和内化过程;另一方面,通过对不同来源学科所提供的知识的内化特征差异的比较,深度揭示不同来源学科与图情领域研究存在的内在知识关联,深入理解不同来源学科知识在图情领域中的贡献角色差异,有助于探索图情领域新的知识点生长的方向。但是,本研究也存在诸多不足和局限性,例如,在数据方面,本文仅使用了图情领域6本期刊进行案例分析,数据规模较小,挖掘出的规律难以被泛化到各个学科。下一步工作将获取更多的实验数据,以取得更加有效和一般性的结论。
