高光谱喷墨打印墨水数据的非线性降维及分类建模方法研究
2024-04-23李硕,崔岚,付沛
李 硕,崔 岚,付 沛
(中国刑事警察学院 刑事科学技术学院,辽宁 沈阳 110035)
数字化的进步和科技的发展促进了喷墨打印机的使用。在文件检验领域,喷墨打印文件的鉴定已成为重点内容。目前,喷墨打印文件的鉴定方法已经十分成熟,如薄层色谱法(TLC)[1]和气相色谱-质谱联用(GC-MS)[2]等理化检验法,以及利用傅里叶红外光谱[3]和拉曼光谱[4]等仪器进行检验的方法。这些方法各有优势,但理化检验具有破坏性,且局限性较大;傅里叶红外光谱和拉曼光谱虽可实现无损检验,但无法实现更精细的墨水型号区分[4]。考虑到法庭科学对物证完整性的要求,理想的检测方法应具有非破坏性、稳定性以及准确性的特点。
高光谱成像技术(HSI)是一种生成光谱变化空间图的技术,数据以三维数据立方体的形式表示,包含大量的光谱信息。高光谱成像技术最初用于卫星成像[5],后来广泛应用于其他领域,如食品质量[6]、医学成像[7]和材料科学[8]等。目前,高光谱成像技术在刑事科学技术领域中的使用频率也越来越高。如在痕迹物证检验相关研究中,Glomb等[9]使用高光谱成像技术实现了纺织物上潜在枪弹残留物的自动标识。El-Sharkawy 等[10]使用高光谱相机对三硝基甲苯(TNT)、环三亚甲基三硝胺(RDX)和环四亚甲基四硝胺(HMX)等常见爆炸物进行了远程识别。在文件物证检验相关研究中,王书越等结合高光谱成像技术和深度学习,分别提出了一种快速无损识别黑色签字笔墨水种类[11]和印台油墨类型[12]的新方法。刘猛等[13]采用高光谱成像技术实现了激光打印墨粉的种类鉴别。上述研究成果表明,高光谱成像技术在物证种类鉴定方面具有优势。
不同品牌、型号的喷墨打印墨水的化学成分不同,进而对光源的吸收度不同。本文基于高光谱成像技术对喷墨打印墨水进行种类鉴别。选择占喷墨打印机市场95%以上份额的3 种品牌(惠普、佳能、爱普生)的喷墨打印机,采用均匀流形逼近与投影技术(UMAP)和T 分布随机近邻嵌入技术(t-SNE)两种降维算法处理采集到的高光谱墨水数据,然后分别使用极致梯度提升(XGBoost)、轻量级梯度提升机器学习(LightGBM)和支持向量机(SVM)3 种算法构建分类模型,通过准确率和精确率评估模型性能,筛选最佳算法组合,实现了对喷墨打印墨水的精确分类。
1 实验部分
1.1 仪器与材料
采用加拿大蒙特利尔Photon etc. 公司生产的GRAND-EOS 高光谱仪器提取高光谱图像。其由CCD相机、过滤器、滤光轮、环形卤素灯光源和载物台组成,可采集的光谱波长范围为400~1000 nm,光谱分辨率为1 nm。
选择市面常见的3种品牌(惠普、佳能、爱普生)不同型号的14台喷墨打印机共计56种原装墨水进行实验,打印机型号和原装墨水型号见表1,并将打印机按1~14依次编号。统一使用亚太森博品牌A4型号75 g复印纸作为承印纸张,采集每台打印机PGBK/BK、C、M、Y四种纯色料的样品,打印模式选择打印测试页;每台打印机打印5份样品,共计280份样品。

表1 喷墨打印机型号和原装墨水型号Table 1 Inkjet printer models and original ink models
1.2 图像采集
图像采集时保证室内处于黑暗环境,防止外界光线对实验的影响。首先,调整载物台高度,使物镜下的样品呈现面积为20 mm×20 mm。然后将样品置于载物台上,在样品下方放置产商提供的黑白方格纸,用于后续的配准矫正。调整相机曝光时间至0.5 s,光谱波长范围为400~1000 nm,间隔为5 nm,执行采集任务。
1.3 图像处理与光谱数据采集
采集图像时,仪器噪声、暗电流和背景等因素会对图像产生干扰。为了更好地进行数据分析和解释,确保数据的可比性和一致性,通过系统提供的控制和分析软件PHySpec 对高光谱图像依次进行去暗噪、配准校正、波长矫正和强度归一化处理。
处理后的图像包含了样品的空间和光谱信息,每个高光谱图像代表一个波长的强度图,可以查看与像素相关的反射光谱。提取样品中感兴趣区域(ROI)的光谱信息,在每种样品色料饱满的区域提取6个ROI点位,每种颜色各420条数据,共1680条高光谱数据。
1.4 模型建立
1.4.1 降维算法原理高光谱数据包含了大量的光谱信息,每个数据点都是一个高维向量。降维算法能够有效去除数据中的冗余信息、改善可视化、提高分类模型性能[14]。Devassy等[15]分别使用主成分分析(PCA)和t-SNE对高光谱数据进行降维处理,结果表明t-SNE更适用于高光谱中性笔油墨数据的降维。Myasnikov[16]从分类质量的角度比较了UMAP 和PCA、等高线图、局部线性嵌入等降维方法的效果,结果显示UMAP 降维的效果最好。综上,非线性降维算法更适合高光谱数据的降维处理。本研究选择t-SNE 和UMAP 两种非线性降维算法对高光谱喷墨打印墨水数据进行降维处理,并选用散点图实现降维效果的可视化。
(1)t-SNE 是Maaten和Hinton 于2008年提出的算法[17],其主要原理是通过保留数据点之间的相似性关系尤其是在高维空间中较远的数据点之间的相对距离,将数据点映射到低维空间。首先,需要计算高维数据中每对数据点i和j之间的相似度(通常使用高斯分布的条件概率来度量),计算公式如式(1)所示。
式中,xi和xj分别为数据点i和j的高维表示,σi是根据数据点i到其最近邻的距离自适应确定的高斯分布方差。
其次,计算低维空间中每对数据点i和j之间的相似度q(i,j),公式如式(2)所示。
式中,yi和yj分别为数据点i和j在低维空间中的表示,yk表示低维空间中的另一个数据点,用于计算与yi和yj之间的相似性。
最后,使用梯度下降等优化方法,最小化两个相似度分布之间的差异,通过最小化损失函数来实现,函数见式(3)。
(2)UMAP 是McInnes 等于2018年提出的算法[18],其基于拓扑数据分析和流形学习的思想,主要目标是保留数据之间的拓扑结构和流形特性。首先通过计算每对数据点之间的局部相似性度量来构建一个高维空间的邻接图,再使用优化技术将高维空间中的数据映射到低维空间。这个相似性度量通常使用高斯核距离或T分布相似性来度量,公式见式(4)和式(5)。对于数据点i和j,相似性度量表示为s(i,j)。
式中,xi和xj分别为数据点i和j的高维表示,k为高斯核带宽,α为T分布参数。
通过KL散度来实现低维嵌入中点对之间T分布相似性和高维空间中相似性之间差异的最小化,计算公式见式(6)。
式中,p(i,j)为高维空间中的相似性度量,q(i,j)为低维嵌入中的T分布相似性。
1.4.2 分类模型构建为比较不同模型在样品数据分类精度方面的差异,选择XGBoost、LightGBM和SVM3种算法构建分类模型。
(1)XGBoost 由Chen 和Guestrin 在2016年首次提出[19],是一种基于梯度提升决策树的机器学习算法。其基本原理是通过将多个决策树组合成一个强大的模型,从而提高预测准确性。决策树是一种用于分类和回归的树状结构,其中每个叶子节点代表一个类别或一个预测值。XGBoost 通过迭代训练多个决策树来提高预测准确性。在每次迭代中,算法会训练一个新的决策树,以纠正前一轮迭代中产生的误差。这种迭代过程会一直持续,直到算法达到预定的停止条件。在该过程中,XGBoost通过引入一些特殊的技术来提高梯度,提升决策树的效率和准确性。例如使用梯度优化算法来最小化损失函数,以确保每个新的决策树都会贡献最大化的预测准确性。
(2)LightGBM 是微软亚洲研究院(MSRA)于2017年提出的提升框架[20],也是一种基于决策树的梯度提升集成方法。LightGBM 使用基于直方图的方法,其中使用分布直方图将数据划分到图格中,使用图格(而不是每个数据点)进行迭代、计算增益和拆分数据,使用基于梯度的一侧采样(GOSS) 对LightGBM中的数据集进行采样,是一种快速、分布式、高性能的基于决策树算法的梯度提升框架。
(3)SVM 是Cortes和Vapnik 在1995年提出的分类算法[21],是一种二分类模型。其基本原理是求解能够正确划分训练数据集并且几何间隔最大的分离超平面,即通过寻找一个能够将两类样本分开的超平面,使得该超平面到两类样本的最近点的距离最大化,从而实现分类。在实际应用中,SVM 也可以使用核函数将数据映射到高维空间中,使数据在高维空间中线性可分。其常用的核函数有线性核、多项式核和高斯核等。
使用准确率(Acc)和精确率(Pre)评价上述模型,计算公式如式(7)和式(8)所示。
式中,TP为真正例;FP为假正例;TN为真负例;FN为假负例。
实验使用Anaconda 虚拟环境的python3.11 解释器,配置XGBoost、LightGBM、sklearn. SVM、sklearn. model_selection、sklearn. manifold和sklearn. metrics 等Python模块来进行编码和数据分析,相关分析均在一台配置为Intel 8th core i7 CPU、16 GB 内存、NVDIA GEFORCE GTX1050ti显卡、1T 硬盘的电脑上完成。实验流程图如图1所示。
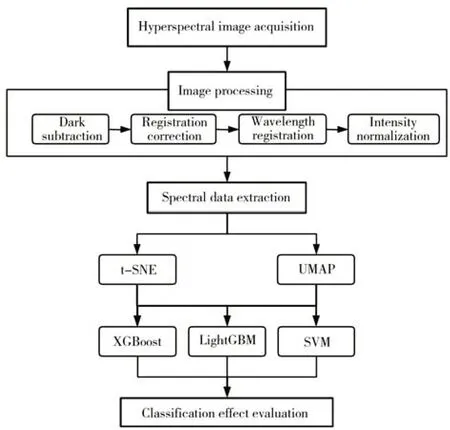
图1 实验流程图Fig.1 Experimental flowchart
2 结果与讨论
2.1 光谱特征分析
所有喷墨打印墨水样品的原始谱图如图2 所示。谱图纵坐标代表吸光度,呈负值显示是由图像降噪时强度归一化所导致。归一化的作用在于使高光谱图像中不同波长或频率的信号强度具有相对一致的尺度,以使不同区域或不同时期的光谱图像更容易进行比较和分析。从图2A 中可以看出黑色墨水的谱图走势基本一致:在400~590 nm波段内呈匀速下降的趋势,590~600 nm 波段内的吸光度急剧下降,660 nm 波段处曲线开始上升;600~680 nm 波段处出现低反射区,并在640 nm波段附近形成一个波谷。从图2B 中可以看出:青色墨水的曲线在400~590 nm波段内有一部分呈下降趋势,而另一部分保持平缓,然后在580~600 nm 波段处急剧下降,并在640 nm 波段处开始上升;其在600~680 nm波段处出现低反射区,并在640 nm 波段附近形成一个波谷。从图2C 可以看出,品红色墨水的曲线在400~560 nm 波段分3 部分并均呈下降趋势,随后在560~630 nm波段上升,之后逐渐汇聚在一起。其中两种样品在590~600 nm处的吸光度呈急剧下降趋势,然后继续上升。从图2D 可以看出,黄色墨水在400~520 nm 波段处开始下降,部分缓慢下降,部分迅速下降;在520 nm波段左右形成波谷后,曲线呈上升趋势。
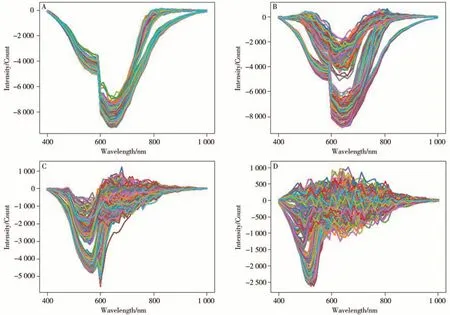
图2 黑色(A)、青色(B)、品红色(C)和黄色(D)样品的原始谱图Fig.2 Original spectra of black(A),cyan(B),magenta(C) and yellow(D) samples
从原始谱图曲线走势来看,有两类黑色墨水的成分差异较大,青色墨水中3 类样品的成分差异较大,而品红色和黄色墨水的谱图较为混乱。由于通过高光谱原始谱图对喷墨打印墨水种类进行区分的效果不理想,本文借助机器学习对上述高光谱喷墨打印墨水数据进行种类分析。
2.2 光谱数据降维
2.2.1 t-SNE 降维方法由t-SNE 原理可知,影响降维结果的主要参数包括投影维度、困惑度和学习率等。使用网格搜索(GridSearch)寻找最佳超参数配置,并以KL散度作为评估指标。KL值越小表示t-SNE 降维后的数据与原始数据之间的差异越小。最佳参数配置见表2,t-SNE 的降维可视化效果如图3所示。从散点图来看,t-SNE算法具有很好的可视化效果。
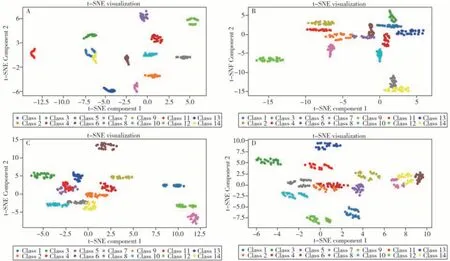
图3 t-SNE对黑色(A)、青色(B)、品红色(C)和黄色(D)样品数据降维后的散点图Fig.3 Scatter plots of t-SNE for black(A),cyan(B),magenta(C),and yellow(D) sample data class 1-14 were the sample numbers
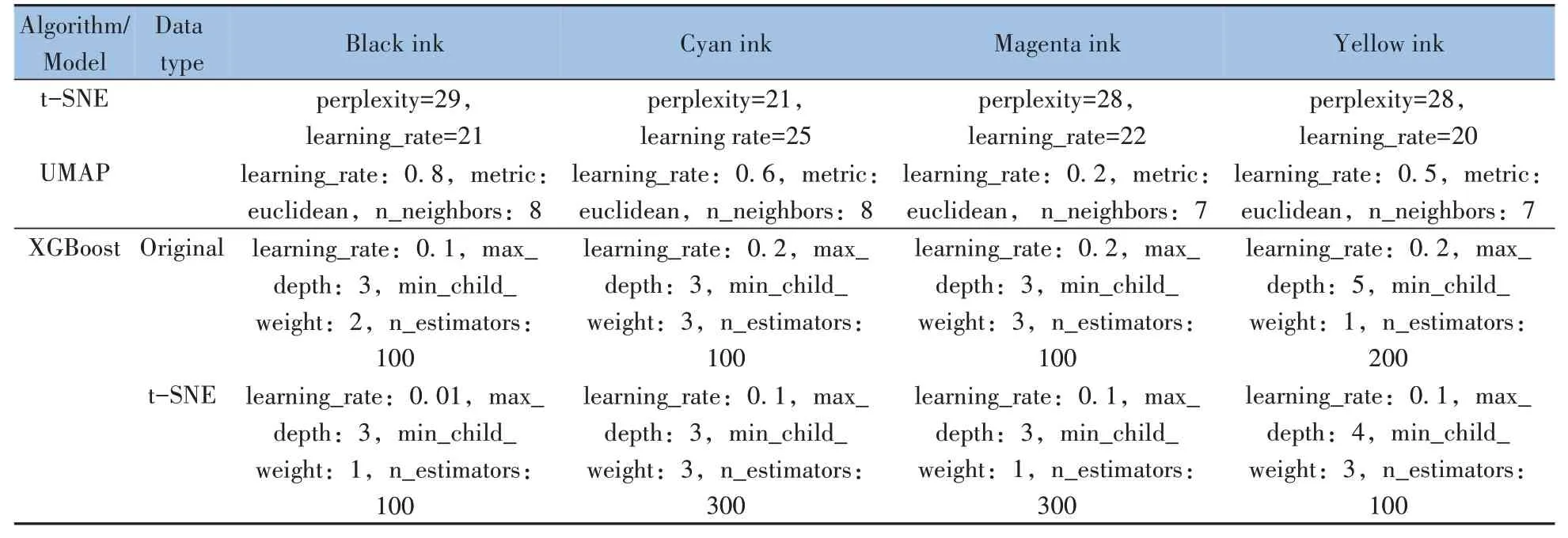
表2 不同方法的最优参数Table 2 Optimal parameters of different methods
2.2.2 UMAP 降维方法影响UMAP 降维结果的主要参数包括维度数量、近邻数量和距离度量等。寻找最佳参数组合的方法与t-SNE 相同,最佳参数配置见表2。UMAP 降维的可视化效果如图4 所示。从散点图可见,UMAP算法的可视化效果较好。
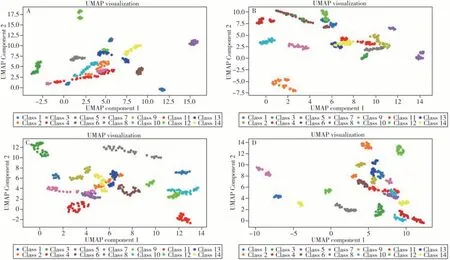
图4 UMAP对黑色(A)、青色(B)、品红色(C)和黄色(D)样品数据降维后的散点图Fig.4 Scatter plots of UMAP for black(A),cyan(B),magenta(C),and yellow(D) sample data class 1-14 were the same as those in Fig.3
2.3 数据分类效果与评价
使用XGBoost、LightGBM 和SVM 模型分别对原始高光谱数据、t-SNE 降维后数据和UMAP 降维后的数据进行分类,以1∶4 的比例确定测试集和训练集。为达到最佳分类效果,利用网格搜索来调试3种模型的参数,尝试不同的参数组合,并使用5折交叉验证评估每个组合的性能。3种模型对样品的分类精度结果见表3。最佳参数配置见表2。

表3 XGBoost、LightGBM和SVM模型对样品分类的精度Table 3 Accuracy of XGBoost,LightGBM,and SVM models for sample classification
2.3.1 XGBoost 模型由XGBoost 模型对喷墨打印墨水样品的分类精度结果可知,XGBoost 对原始数据进行分类的效果最差,青色墨水的精度值为81.38%,品红色和黄色墨水的精度值分别为88.31%和84.11%,而黑色墨水的精度值最低,为60.59%;对t-SNE 和UMAP 降维后,分类的精度明显升高,青色、品红色和黄色墨水的精度值均在96%以上,而黑色墨水的精度值偏低,仅为88%左右。
2.3.2 LightGBM 模型由LightGBM 模型对喷墨打印墨水样品的分类精度结果可知,其对原始数据分类的精度最低,黑色墨水的精度值为61.11%,青色墨水的精度值为81.98%,品红色和黄色墨水的精度值分别为89.35%和86.70%;对经t-SNE 降维的数据的分类效果较好,青色和品红色墨水的精度值分别为98.95%和99.30%,黄色墨水精度值为96.21%,而黑色墨水的精度值仅有88.36%;对经UMAP 降维的数据分类的效果最好,其中青色、品红色和黄色墨水的精度值均为100.00%,但黑色墨水的精度值为89.04%,效果较差。
2.3.3 SVM 模型由SVM 模型对喷墨打印墨水样品的分类精度结果可知,其对原始数据分类的效果最差,青色、品红色和黄色墨水的精度值均在90%左右,黑色墨水的精度值为62.35%;对t-SNE 降维后的数据的分类效果较好,其中黑色墨水的精度值为88.18%,青色和黄色墨水相近,精度值分别为97.04%和96.38%,品红色墨水的精度值为99.30%;对UMAP 降维后的数据的分类效果最好,其中青色、品红色和黄色墨水的精度值均为100.00%,黑色墨水的精度值为88.18%。
2.3.4 分类结果讨论综上所述,UMAP 降维算法结合SVM 分类模型对高光谱墨水数据的分类效果最好,能够有效区分不同品牌、型号的喷墨打印墨水。究其原因,首先,在降维算法上,t-SNE 在一些情况下可能陷入局部最优,但UMAP 通常在大规模数据和全局结构的保持方面更出色;其次,在分类模型中,XGBoost和LightGBM侧重于构建集成的决策树模型,通过多个弱学习器的组合来提高整体性能,而SVM在高维空间中能够更好地处理复杂的决策边界,UMAP的降维过程则有助于提取数据中的关键特征,为SVM提供更有价值的信息量的输入,有助于提高SVM在高光谱墨水数据上的分类性能。
为了探究黑色墨水分类精度偏低的原因,列出了3种模型对经UMAP和t-SNE降维后的黑色墨水数据进行分类的混淆矩阵图,如图5 所示。由图5 可知,对UMAP 降维后的数据进行分类时,XGBoost 模型和LightGBM 模型将9 号墨水的5 个样品错分到10 号,将10 号墨水的9 个样品错分到9 号;SVM 模型将10 号墨水的所有样品全部错分到9 号。对t-SNE 降维后的数据进行分类时,XGBoost 模型和LightGBM 模型把9号墨水的4个样品错分到10号,把10号墨水的10个样品错分到9号;SVM模型把10号墨水的所有样品全部错分到9 号。由此可见9 号和10 号黑色墨水样品错分情况严重,10 号样品常常被错分为9 号,导致分类精度较低。说明9 号和10 号样品的成分相近,难以区分,而其余型号的黑色墨水的分类准确率较高。

图5 XGBoost(A)、LightGBM(B)和SVM(C)对黑色墨水数据分类的混淆矩阵图Fig.5 Confusion matrix plot of XGBoost(A),LightGBM(B),and SVM(C) for black ink data classification
3 结 论
本文以不同品牌、型号的喷墨打印墨水为研究对象,使用高光谱成像技术提取墨水的光谱数据,将数据非线性降维后构建模型,比较分类效果。结果显示:UMAP 算法结合SVM 模型对高光谱喷墨打印墨水数据的分类效果最好。除黑色样品因有两种成分相近导致分类精度在90%左右外,其余颜色样品的分类精度均达到100%,能够实现对喷墨打印墨水的精确区分。该研究为喷墨打印文件的检验鉴定提供了一种无损、准确的方法。
