结合坐标转换和时空信息注入的点云人体行为识别
2024-04-22尤凯军侯振杰梁久祯钟卓锟施海勇
尤凯军,侯振杰,梁久祯,钟卓锟,施海勇
常州大学计算机与人工智能学院,常州 213000
0 引言
随着计算机视觉的不断发展,行为识别在视频监控和人机交互等诸多领域中展现出广泛的应用前景和研究价值。利用深度图序列(许艳 等,2018;李兴 等,2019;施海勇 等,2023)进行人体行为识别是机器视觉和人工智能中的一个重要研究领域,广泛使用的深度图序列尽管可以提供深度信息,但易受其他因素影响,行为数据的时空结构信息大量丧失。点云(Guo等,2021b;陶帅兵 等,2021)的出现弥补了深度图数据的劣势。点云就是分布在三维空间中的离散点集,它对复杂场景以及物体的外形表达具有独特的优势,但由于点云分布不规则且无序的性质,在点云上应用深度学习是不容易的。点云学习可分为基于多视图的、基于体积的和基于点的方法。基于多视图的方法首先将一个三维形状投影到多个视图中,并提取视图特征,然后融合这些特征进行精确的形状分类;基于体积的方法通常是将点云体素化为三维网格,然后应用三维卷积神经网络(convolutional neural network,CNN)对其进行形状分类;基于点的方法根据每个点的特征学习所使用的网络架构,独立地对每个点建模,然后使用对称聚合函数聚合全局特征。PointNet(Qi 等,2017a)是点云深度学习的开山之作。PointNet 的核心思想是利用一组多层感知机(multilayer perceptron,MLP)抽象每个点来学习其对应的空间编码,然后通过一个对称函数将所有单独的点特征集合起来得到一个全局的点云特征。但是PointNet 缺乏对局部特征的提取及处理,而且现实场景中的点云往往是疏密不同的,而PointNet 是基于均匀采样的点云进行训练的,导致了其在实际场景中准确率的下降。因此提出了一个分层网络PointNet++(Qi 等,2017b),PointNet++的特征提取由3 部分组成,分别为采样层、分组层和PointNet 层,这3个层构成一个抽象层,PointNet++由几个抽象操作集合组成,PointNet++通过几个抽象层的层级结构逐步利用局部区域信息学习特征,网络结构更具有鲁棒性,但随机的最远距离点采样(farthest point sample,FPS)不可避免地会损失点云数据的时空信息。
为了解决上述问题,本文提出了一种结合坐标转换和时空信息注入的点云人体行为识别网络,该网络将深度图序列进行了信息转换,生成点云序列,并对其进行时空建模。网络由两个模块组成,即特征提取模块和时空信息注入模块。特征提取模块将每个点云框架抽象为一个外观轮廓的特征向量,以此来捕捉复杂的时空结构。在时空信息注入模块中,为点云的外观轮廓特征向量注入时空信息,其中借助可学习的正态分布随机张量的方法寻找空间结构信息上的特征变化,不仅能更好地表示数据的空间结构信息,也能加快网络的运行速度。在进行三维动作识别之前,将网络中的不同尺度特征串联起来。在结合坐标转换和时空信息注入的点云人体行为识别网络中,不同的点云框架在最终的分类网络层之前共享相同的网络架构和网络权重。
本文的主要贡献如下:1)提出一种结合坐标转换和时空信息注入的点云人体行为识别网络,通过点云特征提取模块和时空信息注入模块,解决了深度图序列时空结构信息的利用率不足的问题;2)通过构造时空信息注入模块,为静态点云序列注入动态信息(点云序列间的时序信息和运动帧的空间结构信息),弥补了点云抽象操作下采样时部分信息丢失的不足;3)设计了点间注意力机制模块,通过可学习的正态分布随机张量将数据映射到相应的空间中,不断寻找最优的投影空间,得到最佳的空间结构信息权重矩阵,以此表征运动帧的空间结构特征。用运动帧的空间结构特征替代点云帧的点特征。
1 相关工作
由于点云分布不规则且无序的性质,在点云上应用深度学习是不容易的,基于点云序列的三维人体动作识别是一项具有挑战性的新任务。PointNet是点云深度学习的开创之举。PointNet 利用多层感知机、最大池化和刚性变化来保证置换和旋转下的不变性。PointNet++在此基础上通过几个抽象层的层级结构逐步学习局部特征,网络结构更具有鲁棒性。点云数据在时空维度上展现了不规则性和无序性,不同帧中点的出现也无法保证一致性。为此Fan 等人(2022)提出了PST 卷积(point spatiotemporal convolution)来编码点云序列的时空局部结构。PST 卷积首先解开点云序列的时空纠缠。此外,将PST 卷积用分层的方式合并到一个深网络PSTNet 中模拟点云序列。为了避免点跟踪,Fan 等人(2021)提出了P4Transformer(point 4D Transformer)网络建模点云视频。P4Transformer包括一个点4D 卷积和一个Transformer。Xu 等人(2021)介绍了一种用于三维点云处理的通用卷积运算PAConv(position adaptive convolution),通过动态组装存储在权重库中的基本权重矩阵来构造卷积核,使得PAConv 比2D 卷积具有更大的灵活性,可以更好地处理不规则且无序的点云数据。Li等人(2023)对称构造了两个点云特征图,从点云序列中识别人类行为,即点云外观图(point cloud appearance map,PCAM)和点云运动图(point cloud motion map,PCMM)。为了构建PCAM,Li 等人(2023)设计了一种类似MLP 的网络架构,用于在虚拟动作序列中捕获人类动作的时空外观特征;使用类似MLP 的网络架构在虚拟动作差分序列中捕获人体动作的运动特征来构建PCMM,最后,将两个点云特征图描述符连接起来并发送到一个全连接的分类器,以进行人类行为识别。
此外,Transformer 也逐渐应用于图像视觉任务,且效果优于流行的卷积网络。其中,Guo 等人(2021a)提出了一种新的点云学习框架PCT(point cloud Transformer),PCT 的核心思想是利用Transformer 固有的顺序不变性,避免定义点云数据的顺序,并通过注意力机制进行特征学习,注意力权重的分布与部分语义高度相关,并且不会随空间距离而严重衰减。Song 等人(2022b)提出了一种用于三维点云分析的新型增强型局部语义学习Transformer,其中局部语义学习点云互感器(local semantic learning point cloud Transformer,LSLPCT)不仅可以学习3D 点云的全局信息,还可以端到端地增强对局部语义信息的感知,局部语义学习自我注意机制(local semantic learning self-attention,LSL-SA)可以并行感知全局上下文信息并捕获更细粒度的局部语义特征。Liu 等人(2022)提出了一个新的端到端优化双流框架,称为几何Transformer(geometrymotion-Transformer,GMT),GMT 使用特征提取模块(feature extraction module,FEM)在不使用体素化过程的情况下在帧之间生成一对一的对应关系,从原始点云中显式提取几何和多尺度运动表示,并提出了一种改进的基于Transformer 的特征融合模块(feature fusion module,FFM),以有效地融合双流特征。
结合坐标转换和时空信息注入的点云人体行为识别网络根据将点云的时间和空间维度进行解耦,处理每个点云框架的空间结构和时间变化,从而进行时空特征提取。使用位置编码为点云抽象特征加入时序信息,通过可学习的随机张量对空间结构进行投影,寻找最佳的空间结构信息权重。最后将网络中不同层次的特征聚合后进行行为识别。
2 网络结构介绍
本文提出的结合坐标转换和时空信息注入的点云人体行为识别网络总体结构如图1 所示。网络由特征提取模块和时空信息注入模块组成,在特征提取模块中,输入每一帧的点云集,输出对应帧外观轮廓的时空特征向量,以此表征时空信息。通过时空信息注入模块给所有帧加入时序信息和空间尺度信息。之后将多尺度的人体运动特征数据和时空特征数据有效融合,并利用全连接神经网络进行动作分类识别。
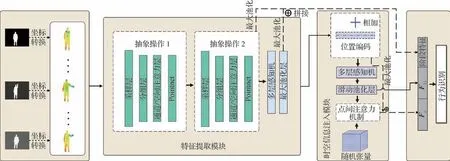
图1 结合坐标转换和时空信息注入的点云人体行为识别网络模块图Fig.1 Module diagram of human behavior recognition network in point cloud based on coordinate transformation and spatiotemporal information injection
2.1 深度坐标系到点云坐标系的转换
人体行为识别的研究大量采用了深度图像序列。与RGB 图像相比,深度图像基本不受自然光线影响,并提供了三维信息数据,但该数据只代表在可视范围内目标与深度摄像机的距离,数据冗余量大,对时空结构信息的表达也不充分。点云是在同一空间参考系下表达目标空间分布和目标表面特性的海量的点集合。点云的获取方式有多种,如通过各种类型的3D 扫描仪、激光雷达和RGB-D 相机。点云数据可以提供丰富的几何、形状和尺度信息,这是深度图所不能比拟的。通过坐标转换将深度图序列转换为点云序列,可以很容易地找到相邻点信息,弥补了深度图数据的不足。
深度图到点云数据的转换通常采用坐标系变换的方法,通过将图像坐标系转换为世界坐标系,深度图转换为点云数据。其中,图像坐标系转换为世界坐标系计算为
式中,x,y,z为点云坐标系,D为深度值,fx,fy分别为镜头x,y方向的焦距,x′和y′是图像坐标系。得到图像点到世界坐标点的变换关系,具体为
式中,cx,cy分别是光心在图像坐标系下的坐标。
通过上述公式的变化,深度图序列中的每一帧深度图像转换成对应的点云帧,组成点云序列,相应深度数据集转换为点云数据集后作为网络的输入,如图2所示。
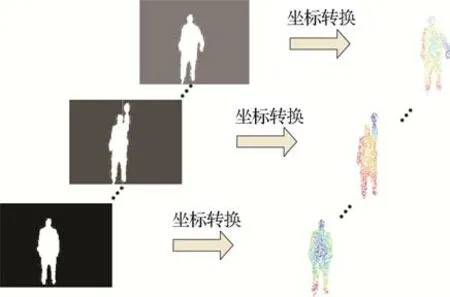
图2 深度序列转换为点云序列Fig.2 Graph of depth sequence to point cloud sequence
2.2 特征提取模块
受PointNet++的启发,本文构建了特征提取模块。该模块由两个抽象操作层、一组多层感知机和最大池化层组成。
抽象操作层由采样层、分组层、通道,空间注意力层(convolutional block attention module,CBAM)和PointNet层组成。
1)在采样层,使用最远距离点采样(FPS)从N个点的点集中选择n个点,降低数据集规模。FPS算法的流程为:首先随机选取一个点作为初始点加入初始点集,计算剩余点到初始点的欧氏距离,选距离最远的点加入到初始点集中,然后计算其余点到初始点集的距离,其余点中某个点到初始点集中所有点的欧氏距离中最小的值作为这个点到初始点集的距离,选取其余点中到初始点集距离最大的点加入初始点集,以此类推,直到初始点集长度为n。寻找初始点集及FPS算法的过程描述为
式中,P代表初始点集,‖x-P‖代表点到初始点集的欧氏距离,xi代表初始点集中以及即将加入初始点集的点,范围是1 到n。xj代表初始点集外的其余点,范围为1 到N-i+1。定义Pt={x1,x2,…,xn}为第t帧的点云集,PT=为T帧的点云序列。
2)在分组层,通过质心点与周围相同半径内的局部点组成局部邻域,便于网络学习点与点之间的空间结构关系。球半径查询方法可以查找在质心点半径范围内所有点。第1 个分组层的输入是一组大小为n×(d+c)(具有d维坐标和c维点特征的n个点)的点集和一组大小为n′×d的质心的坐标,输出是一组大小为n1×k×(d+c1)的点集,其中每组对应一个局部区域,k是质心点邻域中的点数。
3)在通道注意力和空间注意力层,使用通道注意力和空间注意力沿着通道和空间两个维度进行注意力权重学习,对点云特征进行自适应调整,获取重要特征,压缩不重要特征,表征每一帧人体行为静态外观的时间信息和空间结构,如图3 所示。为了有效计算通道注意力,需要对输入特征图的空间维度进行压缩,对于空间信息的聚合,常用的方法是平均池化。另外,最大池化可以收集到难区分物体之间更重要的线索,以获得更详细的通道注意力,所以平均池化和最大池化的特征是同时使用的。因此,通道注意力模块同时使用平均池化和最大池化后的点云特征,然后将它们依次送入一个共享权重的多层感知机中,最后将输出的特征向量进行合并。空间注意力主要聚焦于哪部分的有效信息较丰富,这是对通道注意力的补充。通过最大池化和平均池化各获得一张特征图,而后将它们拼接成一张2D 特征图,再送入标准7×7 卷积进行参数学习,最终得到一幅1D 的权重特征图,该图编码了需要关注的位置。从空间的角度来看,通道注意力是全局的,而空间注意力是局部的。本文CBAM 模块的结构表达为
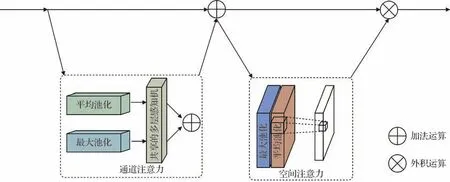
图3 通道注意力和空间注意力Fig.3 Channel attention and spatial attention
式中,A()表示通道注意力和空间注意力操作,in表示模块的输入,MLP表示多层感知机操作,m和n表示平均池化和最大池化操作,σ表示激活函数。
4)在PointNet 层,由一组MLP 和一个最大池化操作组成,通过MLP 和最大池化操作来表征局部区域特征。在这一层中,输入的是数据为n1×k×(d+c1+1)的n1个局部区域,输出数据为n1×(d+c1),由n1个具有d维坐标的子采样点和总结本地上下文的新c1维特征向量组成。输出中的每个局部区域都是其质心和质心邻域的局部抽象特征的连接。
抽象操作2 与抽象操作1 类似,输入的数据为n1×(d+c1),输出为n2×(d+c2),将输出记为fab。
最后,通过一组多层感知机和最大池化层表征整个点云框架的时空信息,计算为
式中,f为一帧点云帧通过多层感知机和最大池化操作后的特征向量,MAX表示最大池化操作,所有点云帧通过特征提取模块的输出为F=,T为一个行为动作的总帧数,f的大小为1×do,F的大小为T×do,do为输出通道的大小。
2.3 时空信息注入模块
通过点云对深度图像进行信息表征弥补了深度图数据时空信息不足的缺点,但点云序列的转换以及随机最远点采样会使原本的时空结构信息损失完整性,在一定程度上损失一部分时空结构信息,所以有必要对点云序列进行额外时空结构信息注入。
2.3.1 时序信息注入
由图1 所示,经过特征提取模块形成的外观轮廓的时空特征向量序列F=在进入时空信息注入模块后首先进行时序信息注入。为了对人体动作的时间信息进行编码,使用位置编码、共享MLP层和滑动块最大池化层。位置编码层为特征向量序列注入时间位置信息。共享的MLP 层对每个独立的特征向量执行一组MLP,以提取每个点云框架的时空信息。采用滑动块最大池化层在多个时间尺度上提取序列空间信息。
1)位置编码层。给定输入特征向量序列F=,通过加入位置编码注入顺序信息。因为正弦和余弦函数在无序方向中,每个向量的位置具有唯一性和很好的鲁棒性,所以使用不同频率的正弦和余弦函数作为时间位置编码。
式中,PE表示二维矩阵,大小和ft相同,p表示时间位置。l表示特征向量的位置,dm表示特征向量的维度。偶数位置使用正弦函数,奇数位置使用余弦函数。将位置编码函数与ft聚合以此加入时间位置信息生成特征向量是经过位置编码后的新的特征向量。
2)共享的MLP 层。经过时间位置嵌入层后,将顺序信息简单地嵌入到空间信息序列中。为了进一步提取时空信息,对每个特征向量应用一组MLP,即
3)滑动块最大池化层。在这一层中,使用最大池化操作对多个特征向量进行聚合。为了捕获点云序列内的子动作和更有鉴别性的运动信息,提出滑动块最大池化策略,将向量序列分成与点云帧等量的块,其中前e个块组成滑动块,然后对滑动块进行最大池化操作,生成相应的子特征。之后将滑动块向后滑动m个点云帧距离,再进行最大池化操作并生成子特征,直到滑动块到达序列末为止。最后,所有的子特征被简单地连接起来,形成人类行为的时间子特征FTi。
为了获得更充足的人体运动时空信息,从位置编码前的不同阶段整合人体动作特征(如图1 中阶段特征),以此丰富时间特征序列。整合方法为
2.3.2 空间信息注入
Li等人(2022)指出了强空间结构和弱时间变化的人类行为特性,即当人们观察多帧的人体动作时,即使时间顺序杂乱,也可以通过静态外观表象进行大致有效的动作识别,说明空间结构信息表征在动作识别时的重要性,意味着点云序列动作识别中强空间结构信息的学习和表征对网络性能有着不可或缺的作用,而原始PointNet++中的抽象操作使用FPS采样,在加大感受野的同时,也不可避免地损失其余的空间信息。在经过滑动池化层后,将带有时序信息的特征向量称为三维向量关系序列(即FTi)。如图4 所示,三维向量关系序列同一组可学习的kaiming正态分布的随机张量进行乘积,将三维向量关系序列投影到相应的维度空间中,再通过网络学习随机张量的系数,寻找更能关注点云间结构关系的最优投影空间。
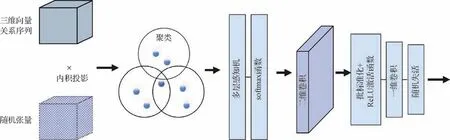
图4 点间注意力机制(空间信息注入)Fig.4 Inter-point attention mechanism(spatial information injection)
聚类之后进入点间注意力机制模块,通过点间注意力机制进一步学习点云数据点与点之间的结构关系,并生成可以表征点云数据空间结构关系的权重系数矩阵。
1)随机张量。为了更好地进行点云深度学习,让网络自主地学习到更适合表征数据空间结构的关系矩阵,采用一组设定好大小但数据随机的张量集,通过迭代不断学习更优的数据参数,寻找最优投影空间。张量是一种强大的表示方向和空间的方法,通过张量不仅能更好地表示数据的空间结构信息,也能加快网络的运行速度。
2)点间注意力机制。点间注意力机制由一组多层感知机和softmax 函数等组成,多层感知机可以很好地学习到点云数据中更关键点的时空信息,再经过softmax 函数层转换成权重系数,即生成了可以表征点云数据空间结构关系的权重系数矩阵,其表现形式为
式中,Fs表示生成的可以表征点云数据空间结构关系的权重系数矩阵(时空特征1),R表示随机张量,C表示聚类操作,Φ表示特征映射操作,即为softmax后的卷积和批正则化等操作。
为了将点间关系与点云序列数据各点相结合,使用的方法为
式中,FTi为经过时序信息注入后生成的三维向量关系序列,将其抽象(时空特征2)并与时空特征1 结合,生成空间结构信息特征向量序列Fo。
最后,将时间特征向量序列TTime和空间结构特征向量序列Fo进行简单的拼接,然后发送到一组全连接层中进行人类动作识别。
3 实验
3.1 数据集
在两个大型公共动作识别数据集NTU RGB+d60(Shahroudy 等,2016)和NTU RGB+d120(Liu 等,2020a)以及一个小型公共数据集MSR Action3D(Li等,2010)上评估了所提出的方法。
NTU RGB+d60 数据集由60 个动作的56 880 个深度视频序列组成,是最大的人类动作数据集之一。
NTU RGB+d120 数据集是目前最大的三维动作识别数据集,是NTU RGBD 60 数据集的扩展。NTU RGB+d120 数据集由120 个动作的114 480 个深度视频序列组成。
MSR Action3D 数据集包含来自10 个受试者的20 个动作的557 个深度视频样本,每个动作由每个受试者执行2或3次。
3.2 实现细节
首先,从点云集合中随机抽取2 048 个点。然后,利用PFS 算法从2 048 个点中选取512 个点。在特征提取模块中,对每个点云框架进行两次集合抽象操作,采用SequentialPointNet 中获取的最佳参数设置。在第1组抽象操作中,选择128个质心来确定点组,组半径设置为0.06。每个点组中的点数设置为48。在第2 组抽象操作中,选择32 个质心来确定点组,组半径设置为0.1。每个点组的点数设置为16,如表1 所示。在进行提取空间结构信息前,首先使用聚类生成三维向量关系序列,聚类半径设置为20。在进行提取空间结构信息时,随机张量大小设置为(8,64,64),dropout 设置为0.5。用Adam 作为优化器。学习速率从0.001 开始,每10 个epoch 以0.5的速率衰减,使用交叉熵损失函数。
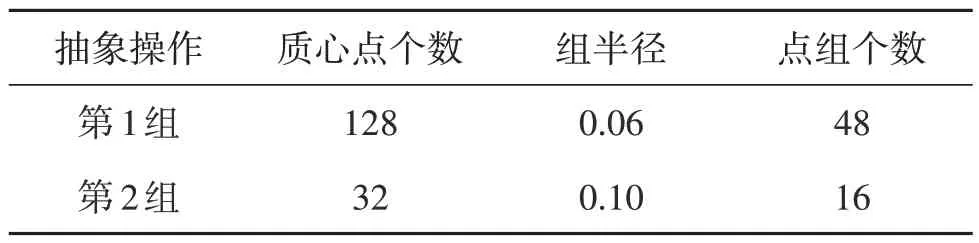
表1 特征提取实验设置Table 1 Feature extraction experiment set
3.3 实验过程
为了探索哪种数据更有利于空间信息的提取,以及不同数据库对于不同数据提取方式的效果,本文进行了不同的对比实验,寻找最适合的实验方法。
使用MSR Action3D 小数据集进行实验,首先使用两种不同的数据作为时空信息注入模块的输入,其中之一为原始三维点云数据,即为抽象操作之前的三维点云数据;另外一种数据为经过位置编码,已经进行特征提取后,通过聚类生成的三维向量关系序列(以下分别称为原始数据和关系数据)。之后进行多次实验并记录最后的实验结果,如表2所示。

表2 MSR Action3D数据集上的实验过程Table 2 The experimental process on MSR Action3D dataset
由表2 实验1—实验4 可以看出,当批次大小相同都设置为8、迭代次数为100 时,使用原始数据作为输入且注入时空特征的准确率为89.71%,使用关系数据作为输入且注入时空特征的准确率为91.91%,而当批次大小设置为150 时,使用原始数据的准确率为92.65%,使用关系数据的准确率达到了93.01%。由此可见,使用关系数据作为输入比使用原始数据作为输入效果更优。再结合实验6 和7可得出结论,当迭代次数为150 时,准确率趋于平稳且最优。
由表2 实验4—实验9 可以看出,当批次大小都设置为8、迭代次数为150 时,使用关系数据作为输入的前提下,只注入时空特征1或时空特征2的准确率分别为86.76%和91.18%,均低于未注入时空特征的准确率,其中只注入时空特征1的准确率比原来低5.18%,而将时空特征1与时空特征2融合后注入,准确率达到93.01%。由此可见注入完整时空特征的重要性。再由表2 中实验4 和5 可知,MSR Action3D小数据集上的批次大小设置为8最为合适。
使用MSR Action3D 小数据集得出结果后,将参数迁移,开始对NTU RGB+d120 和NTU RGB+d60 大数据集进行实验,使用关系数据作为时空信息注入模块的输入,并记录结果,如表3所示。
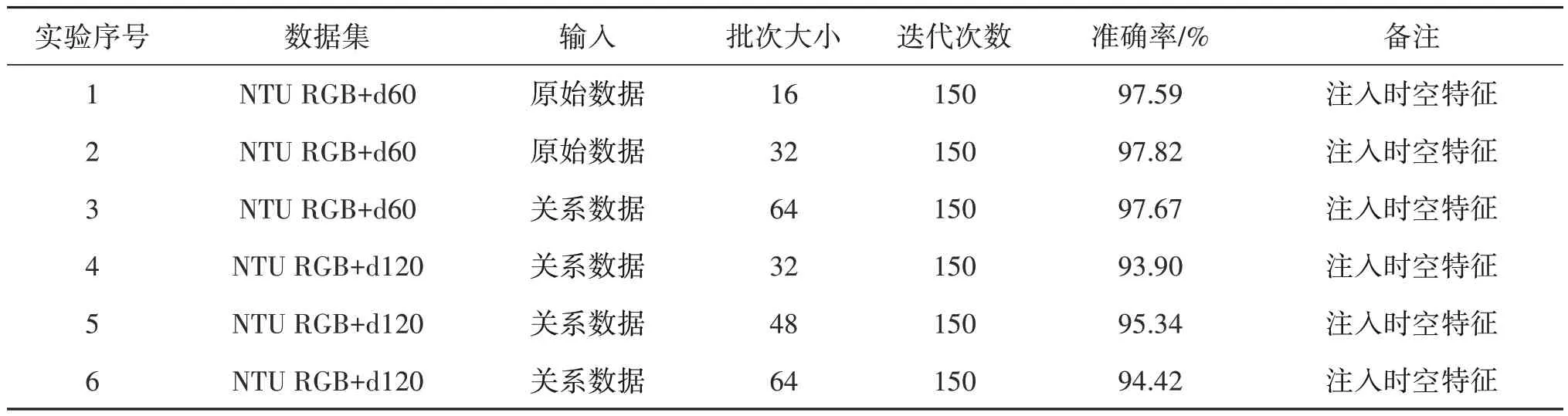
表3 NTU RGB+d60/120数据集上的实验过程Table 3 The experimental procedure on NTU RGB+d60/120 dataset
通过实验对比寻找NTU RGB+d60/120 数据集最适合的批次大小。由表3 实验1—实验3 结果可知,准确率的大小与批次大小不是正相关关系,当批次大小设置为32时,结果为97.82%且最优,当批次大小为16 和64 时,准确率有所下降。在NTU RGB+d120 大数据集上,准确率的大小与批次大小也不是正相关的关系,当批次大小设置为48 时,结果为95.34%且最优,这也直接证明了时空信息注入的合理性和可行性。由NTU 数据集的实验可得出结论,该网络模型结构对于人体行为识别的分类具有较好的优越性。
3.4 与最先进的方法比较
为了验证网络的性能,在NTU RGB+d60 数据集、NTU RGB+d120 数据集和MSR Action3D 数据集上实现了与其他先进方法的对比实验。
1)NTU RGB+d60 数据集。首先比较结合坐标转换和时空信息注入的点云人体行为识别网络和NTU RGB+d60 数据集上的最先进的方法。NTU RGB+d60 数据集是一种大规模的室内人类活动数据集。如表4 所示,结合坐标转换和时空信息注入的点云人体行为识别网络的准确率达到了97.8%。本文方法表现出与其他方法相当甚至更好的性能,达到了最先进的性能。
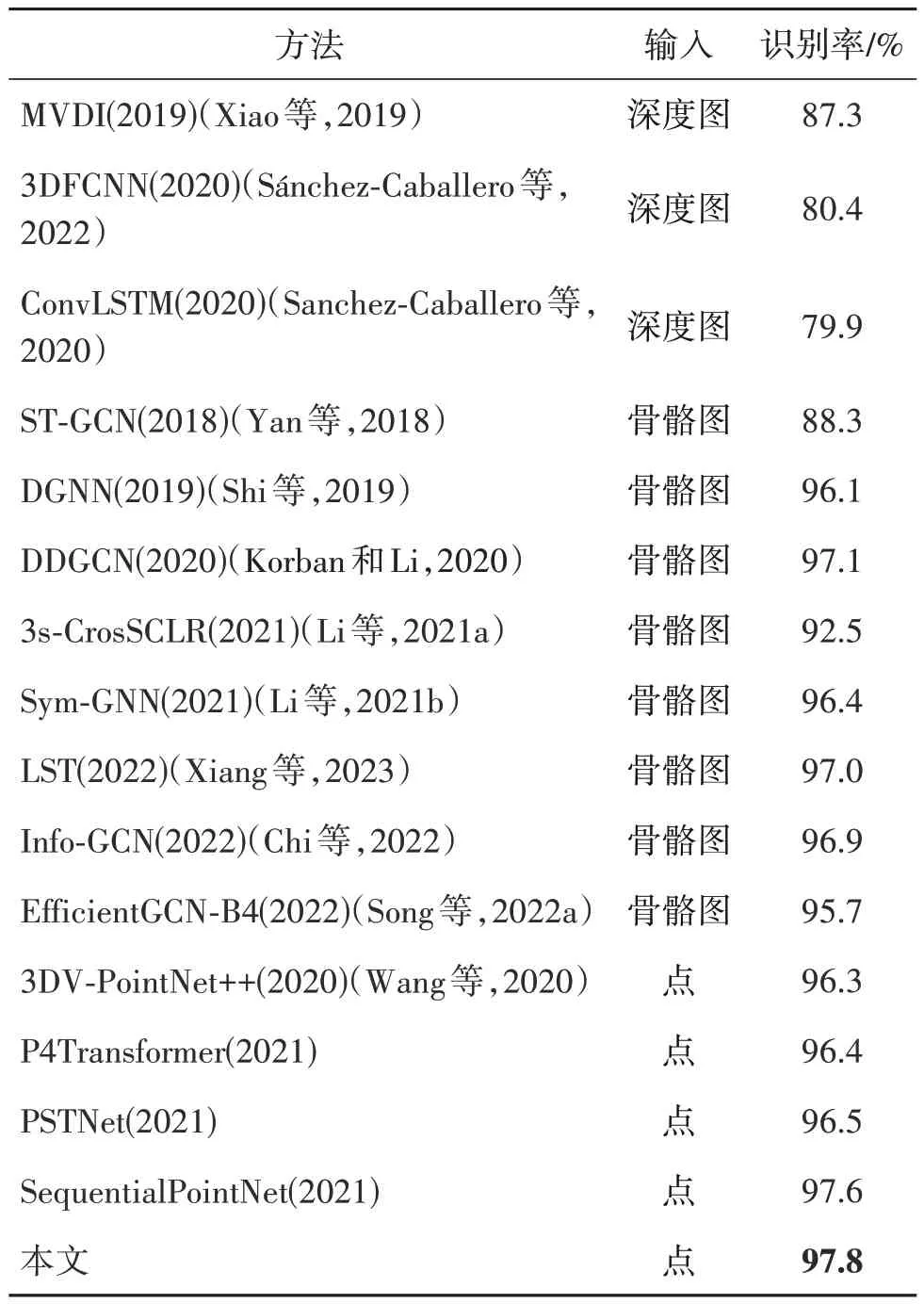
表4 NTU RGB+d60数据集上的行为识别准确率Table 4 Behavior recognition accuracy on NTU RGB+d60 dataset
2)NTU RGB+d120 数据集。将结合坐标转换和时空信息注入的点云人体行为识别网络与NTURGB+d120 数据集上的最先进的方法进行比较。NTU RGB+d120 数据集是用于3D 动作识别的最大数据集。与NTU RGB+d60 数据集相比,在NTU RGB+d120 数据集上进行三维人体动作识别更具挑战性。如表5 所示,结合坐标转换和时空信息注入的点云人体行为识别网络的准确率达到了95.3%,仅低于SequentialPointNet,并且展现出比其他网络更优秀的性能。

表5 NTU RGB+d120数据集上的行为识别准确率Table 5 Behavior recognition accuracy on NTU RGB+d120 dataset
3)MSR Action3D 数据集。为了综合评价本文方法,在小型MSR Action3D 数据集上进行了对比实验。为了缓解小尺度数据集上的过拟合问题,将批量大小设置为8,其他参数设置与两个大规模数据集上的设置相同。表6 展示了不同方法的识别精度,结合坐标转换和时空信息注入的点云人体行为识别网络在MSR Action3D 数据集上取得了最先进的性能。

表6 MSR Action3D数据集上的行为识别准确率Table 6 Behavior recognition accuracy on MSR Action3D dataset
根据表4—表6的对比结果可知,在NTU两个数据集上,本文方法领先于绝大部分网络,展现出较好的准确率优势,而在MSR Action3D 小数据集上,本文方法以明显的优势领先于其他网络,其中准确率比SequentialPointNet 提升了1.07%。由此可见,本文方法在大数据集和小数据集上都表现良好,尤其更有利于小数据集的识别。
本文提出的结合坐标转换和时空信息注入的点云人体行为识别网络为了提高时空结构信息的利用率,提出特征提取模块和时空信息注入模块,为静态点云序列注入动态信息,弥补了点云的不足。其中点间注意力机制可以寻找最优的投影空间,得到了最佳的空间结构表征,这也导致了本文方法良好的性能。
为了进一步证明结合坐标转换和时空信息注入的点云人体行为识别网络的性能,在原来识别率指标的基础上引入NTU RGB+d60 数据集和NTU RGB+d120 数据集的另外3 个指标cross-subject、cross-view 和cross-setwp。不同指标的区别为训练集和测试集划分方式的不同。NTU RGB+d60 和NTU RGB+d120 的cross-subject 根据受试者ID 划分;NTU RGB+d60 的cross-view 根据相机ID 划分;NTU RGB+d120 的cross-steup 指定id 为偶数的样本进行训练,id 为奇数的样本进行测试。实验结果如表7 和表8所示。本文方法在8 个结果中仅NTU RGB+d120 上的cross-setup 低于SequentialPointNet 0.1%。其中,在NTU RGB+d60 上的cross-subject 和cross-setup 识别率分别高于SequentialPointNet 0.3%和0.2%,在NTU RGB+d120 上的cross-subject 识别率高于SequentialPointNet 0.5%,这也进一步表明了本文方法的优越性。

表7 SequentialPointNet与本文方法在NTU RGB+d60数据集上的对比实验Table 7 Comparison of SequentialPointNet and the method of ours on NTU RGB+d60 dataset

表8 SequentialPointNet与本文方法在NTU RGB+d120数据集上的对比实验Table 8 Comparison of SequentialPointNet and the method of ours on NTU RGB+d120 dataset
在SequentialPointNet 的时空结构中,空间结构和时间变化是独立建模的,SequentialPointNet 提出的强空间结构和弱时间变化的观念,SequentialPoint-Net 着重强调对空间结构特征的提取。Sequential-PointNet 认为将空间信息和时间信息同等对待是不合理的,因为人的行为在空间维度上是复杂的,而在时间维度上是简单的。本文方法同等对待时间和空间特征的地位,在最终特征聚合阶段,时间特征和空间特征以同等维度大小融合。在某些动作,例如NTU RGB+d120 中的嗅闻(A117)或耳语(A79)等微小动作(这类动作id 大多为奇数)中,空间结构的重要性大于时序信息,这导致本文方法在NTU RGB+d120 上的cross-setup 识别率相比于SequentialPoint-Net较低。
4 结论
本文提出了一个结合坐标转换和时空信息注入的点云人体行为识别网络。该网络采取坐标转换的方式,将深度图序列转换为三维点云序列进行人体行为信息的表征,弥补了深度信息空间信息与几何特征不足的缺点,提高了时空结构信息的利用率。网络由两个模块组成,即特征提取模块和时空信息注入模块。特征提取模块提取点云序列的空间结构特征和时间变化特征。为了捕获时空结构,使用两个抽象操作将每个点云框架抽象为一个外观轮廓的特征向量。在时空信息注入模块中,采用时间位置编码和滑动池化策略对特征向量序列进行时序信息注入。此外,通过一组可学习的正态分布随机张量寻找最优的投影空间,在最优投影空间中,通过点间注意力机制输出最佳的空间结构信息权重系数矩阵,为了保留原有的空间结构,系数矩阵与三维向量关系序列进行特征聚合,从而注入空间结构信息。最后对人体动作的多层次特征进行了融合与分类。在本文方法中,不同的点云框架共享相同的网络架构和权重。
在3 个公共数据集上进行的大量实验表明,结合坐标转换和时空信息注入的点云人体行为识别网络展现了其优异的性能,其中,在MSR Action 3D 数据集上,本文方法以明显的优势领先于其他网络,准确率比SequentialPointNet 提升了1.07%;本文方法在NTU RGB+d120 数据集上的准确率仅次于SequentialPointNet。原因在于SequentialPointNet 与本文方法在时空特征权重的处理上不同。SequentialPointNet 更加侧重于对空间结构特征的提取,对于微小动作的分类更加准确,因此,在cross-setup 指标下本文方法的准确率比SequentialPointNet 低0.1%。但在cross-subject 和cross-view 指标下,本文方法均比SequentialPointNet准确率高0.2%以上。
由于NTU 数据集的规模较大,将训练小数据集的网络参数迁移,从而进行训练大数据集并不能完全展现网络的性能,下一步研究应探究不同的网络参数对于大数据集行为识别的影响,并增强网络的轻便性。未来工作将聚焦在研究点云人体行为识别的轻量性和实用性方面。在探究降低参数量实现网络轻量化的同时,设计适用于不同动作的时空特征融合方式,从而加强网络对不同动作,特别是微小动作的识别能力,提高网络的泛化性,并将结合坐标转换和时空信息注入的点云人体行为识别网络进一步应用于智能驾驶等领域中。
