有限色彩空间下的线稿上色
2024-04-22陈缘赵洋张效娟刘晓平
陈缘,赵洋,张效娟,刘晓平*
1.安徽大学互联网学院,合肥 230039;2.合肥工业大学计算机与信息学院,合肥 230601;3.青海师范大学计算机学院,西宁 810008
0 引言
在艺术绘画领域,一幅精美的画作从早期的线稿草图绘制到选取合适的颜色进行涂色再到细节润色完善,整个过程需要耗费创作者大量的时间和精力。随着卡通、绘画、图形设计及其他相关产业的发展,高效的内容生成和创作成为一个重要的需求。除去前期构图、风格设计等这些需要发挥人的创造性和艺术性的工作,线稿上色成为最烦琐、重复性工作量最大的过程之一。尽管近些年出现了一些计算机辅助绘图工具,可以大大提高效率,但这些仍需要熟练的上色人员手工操作。对于普通用户来说,想要进行精美的画作上色仍较为烦琐。从简单稀疏的线稿草图自动生成彩色图像本身也是具有一定难度的任务,因此,便捷高效的线稿上色方法研究无论是对学术界还是对工业界都有较高的价值。
线稿上色,一般是指对线条构成的草图进行着色的过程。随着深度神经网络(deep neural network,DNN)的蓬勃发展,近些年一些基于DNN 的上色方法取得了一定成果。然而,大多数研究是针对自然灰度图像的彩色化(曹丽琴 等,2019;Zhao 等,2021;Weng等,2022;Huang等,2022;Yun等,2023),这与线稿上色有一定差异。如图1 所示,灰度图像包含像素的灰度值以及纹理信息,而线稿图像仅由稀疏抽象的线条构成,局部细节的语义理解更加困难。其次,灰度图像彩色化可以看做图像到图像的翻译任务或图像复原任务,从而可以使用像素级的严格约束进行学习。然而线稿图像仅提供边缘信息,这更类似于困难的生成任务。目前,仅有少部分研究针对线稿自动上色,且大多数针对特定的线稿类型,如人脸上色(Li等,2019;Chen 等,2020),动漫人物上色(Liu等,2019;Zhang和Zhou,2022,Cao等,2023),动漫场景上色(朱松 等,2020)。Hicsonmez等人(2021)通过引入对抗分割损失提出一种线稿自动上色方法。然而,目前自动地理解稀疏线条语义信息以及选取合适的颜色仍然是一个困难的问题,例如线稿中的一个圆圈,可以代表太阳、水珠、眼睛等多种含义,因此时常出现不合理的上色结果,如红色的草地、黑色的太阳等,即使确定了语义是眼睛,给眼睛上何种颜色也难以保证符合创作预期。
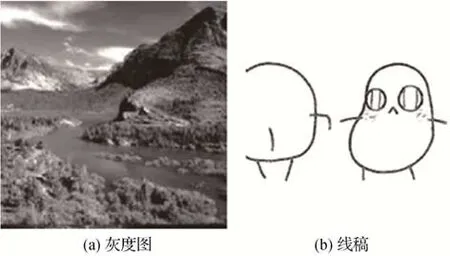
图1 灰度图和线稿对比Fig.1 Comparison of gray image and sketch draft((a)gray image;(b)sketch draft)
由于用户交互可以显著降低语义分析和最优颜色决策的难度,目前半自动上色方法比全自动方法数量多。这些半自动上色方法依据交互策略可以进一步分为3种类型,即基于参考图像引导的方法、基于颜色提示的方法和基于文本描述的方法。基于参考图像引导的上色方法(Huang 等,2021;Liu 等,2022;Cui等,2022)通常使用一幅语义相似的彩色图像作为参考,设计模型学习从参考图像到目标图像的映射建立对应关系,再向目标图像注入相应颜色。这种方法可以降低线稿的语义理解难度,但难以灵活控制局部上色结果。为了方便用户指定不同位置的颜色偏好,基于颜色提示的方法(Hati 等,2019;Yuan 和Simo-Serra,2021;窦智 等,2022;Cho 等,2023)可以更好地满足用户需求。一般是指用户事先在线稿图像上用彩色点或线条的方式提供上色指导。而基于文本描述的上色方法(Zou 等,2019;Kim等,2019;Gao 等,2020)对非专业用户更加友好,用户仅需要提供简单的文字描述即可获得彩色上色结果,如蓝色的车、粉色的衣服等。但其中输入的文本描述和线稿之间未知的间接映射是一个难点。整体来看,这些半自动的上色方法虽然可以获得更合理的上色结果,但需要额外的用户交互,不够便捷高效。
在很多实际应用中,观察到上色任务的目标颜色空间通常是固定且有限的,而不是在完整的颜色空间下自由上色。如,给一部特定动画的帧上色,必须符合该动画的整体用色风格。类似地,特定的绘画风格也会有相对固定且有限的色彩风格,特定的画师会有其相对固定的用色习惯。以藏式绘画(唐卡、彩绘)为例,它们的用色通常是固定的,因为其颜料是由当地的金、银、珍珠、玛瑙、珊瑚、松石、孔雀石、朱砂等珍贵的天然矿物宝石和藏红花、大黄、蓝靛等植物制成。在西藏、青海和尼泊尔等不同地区也逐渐形成了不同的用色风格。基于这些观察,本文聚焦于有限色彩空间下的线稿自动上色方法研究。与一般的线稿自动上色方法相比,利用色彩空间的有限性可以有效降低颜色选择和空间色彩推理的难度。同时,固定的颜色先验可以有效地避免不合理的上色以及保持特定的绘画风格。此外,颜色先验也可以作为一种可选的交互手段,用户可以自由调整颜色或尝试新的颜色风格。
本文提出了一种针对特定有限色彩空间下的线稿自动上色网络,其输入为待上色线稿图像及颜色先验。为了降低学习难度,该模型分为两个阶段。第1 阶段采用U-Net 结构对线稿图像补充线条和细节,形成灰度图像;在第2 阶段,提出了一种多尺度生成对抗模型来对灰度图像进行着色。首先对颜色先验特征进行编码,获取适合该线稿的色彩子空间,之后在感受野最大的最小尺度上,与图像内容特征相结合,推理得到相应空间位置的初步着色。再使用另外两个尺度来融合颜色信息并逐渐产生高分辨率的结果。
本文的主要贡献如下:1)观察到在许多实际线稿着色场景中,颜色空间通常是有限的。通过引入有限色彩空间先验可以有效降低自动上色中理解和选择合理色彩的难度。2)提出一种两阶段的多尺度线稿自动上色网络,并取得了良好的性能。通过解耦颜色推理和着色模块,该模型可以从输入的颜色先验中学习建立特定的颜色子空间并进行颜色推理。因此,经过训练的模型可以使用不同的颜色先验为线稿草图着色,而无需再使用每类颜色先验进行微调。用户可以简单地通过修改颜色先验来获得多样的绘制风格。3)建立了3 个具有特定颜色先验的线稿上色数据集,包括热贡藏式彩绘数据集、热贡唐卡元素数据集和特定卡通数据集。这些数据集将被公开供相关研究使用。
1 本文方法
1.1 两阶段多尺度上色网络
如前文所述,对仅包含稀疏线条的输入线稿的语义信息理解是一个困难的问题,直接学习线稿自动上色难度较大。因此,为了减轻一次性上色难度,本文采用了分阶段、多尺度策略。整体网络框架如图2所示,第1阶段通过灰度图生成器对稀疏线条进行细节和灰度值的补充,为第2 阶段的上色提供更多语义信息;第2 阶段首先从颜色先验中构建有限色彩子空间,再根据图像内容从色彩子空间中推理选择相应位置的颜色并完成上色。下面将分阶段介绍具体细节。
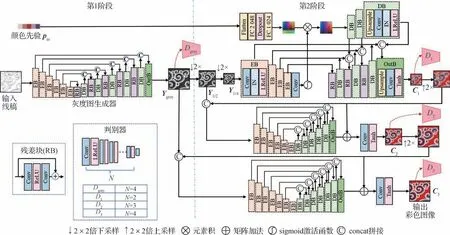
图2 所提方法框架图Fig.2 Framework of the proposed method
在第1阶段,提出一个将输入稀疏线稿转化为稠密灰度图像的子网络,采用常用的U-Net 结构。因U-Net结构可以获得较大的感受野,有利于高层语义信息的理解。之后在第2阶段,提出一个多尺度生成对抗网络,通过对颜色先验的推理融合为第1阶段生成的灰度图像着色。如图2所示,本文方法共使用了3个尺度,第1阶段生成的灰度图记为Ygray,对它分别进行2倍和4倍下采样得到Y1/2和Y1/4。
在最小尺度上,包含若干主色彩向量的颜色先验pin被用来指导色彩推理。首先使用两个全连接层(fully connected,FC)将主色彩向量扩展至连续颜色子空间,使用编码块(encoder block,EB)从输入的灰度图像Y1/4中提取内容特征。每个编码块包含一个3×3的卷积层(convolutional layer,Conv)、一个实例正则化层(instance normalization layer,IN)以及一个渗漏整流线性单元函数(leaky rectified linear unit,LReLU)。由于颜色特征和内容特征具有不同的语义和分布,直接拼接这些特征可能会产生不自然效应。因此,受注意机制的启发,本文利用一个卷积层和一个sigmoid 激活函数将内容特征转换为一种空间注意力。然后将空间注意力与颜色特征相乘,感知初步的颜色推理。
随后,使用两个独立的解码器分别处理原始灰度内容特征和颜色特征。如图2 所示,处理颜色特征的解码器中的每个解码块(decoder block,DB)由双线性插值上采样层、卷积层、实例正则化层以及LReLU 激活函数构成。处理灰度内容特征的解码器中包含3 个与处理颜色特征的解码器中结构一样的解码块,以及1 个不同的输出块(out block,OutB)。输出块包含双线性插值上采样层、卷积层和Tanh 激活函数,以保证输出图像取值范围在(-1,1)。需要注意的是,本文方法使用了实例正则化层,而非批正则化层,因为需要在生成任务中保证每个图像实例之间的独立性。最后颜色特征解码器中每个解码块的输出与灰度特征解码器中相应解码块的输出相拼接,以实现颜色信息与内容信息的融合。此外,在每一次拼接操作后,都会增加一个残差块(residual block,RB)(He 等,2016)以处理特征信息融合。
将最小尺度输出的彩色图像C1上采样后与Y1/2一起作为第2 个尺度的输入。第2 尺度的子网络采用与最小尺度相同的编码器和解码器结构。本文使用第2 尺度来细化初步着色结果,以获得更高分辨率的图像C2。与超分辨率方法中常用的残差学习结构类似,该子网络仅学习残差部分以降低学习难度。类似地,第3 尺度用于进一步获得视觉质量和分辨率更高的最终输出C3。
因整体网络采用生成对抗学习,所提方法的每个阶段及每个尺度均有其相应的判别器,因此,总共有3 个尺度的判别器和一个用于灰度图像生成的判别器。如图2 所示,判别器具体结构是由N个卷积层和LReLU激活函数简单组合而成。
1.2 损失函数
所提两阶段网络采用端到端的学习方式。首先使用一个中间损失函数来指导第1 阶段的灰度图像生成,具体为
式中,Ygray表示生成的灰度图像,Ygt是对应真值彩色图像的Y通道图像。
与大多数图像回归任务一样,本文也使用基本的像素级损失来约束输出彩色图像和真值图像的一致性,即
式中,Ci(i=1,2,3)表示第i个尺度的输出彩色图像,Gi表示其相对应的真值图像。
为了提高生成图像的保真度和多样性,本文的对抗训练采用的是Least-squares GAN(Mao 等,2017)中的对抗损失,具体为
式中,Di(·) 表示第i个尺度的判别器,Dgray(·)表示用于灰度图像生成的判别器。
此外,常用的TV(total variation)损失LTV也被用来进一步平滑生成结果。本文中总损失函数为
式中,权重λ1,λ2,λ3,λ4通过实验分别设置为100、100、1、0.000 1。
在对抗训练过程中,判别器损失的计算式为
1.3 颜色先验的生成及数据集构建
如前文所述,在许多实际场景中,特定的颜色集合可以视为颜色先验,这有利于降低线稿自动着色难度。在本文中,训练阶段使用5 个主色彩向量构成的颜色先验,这些主色彩向量是通过K-means方法从图像集中聚类获得的。当然,实际生产中,主色彩向量可以是人工直接给定,也可以是对给定的样稿、前几集已完成的动画视频等,使用色彩直方图统计、聚类方法等来获得主色彩向量。在前向推理阶段,创作者可以指定颜色或给出设计图,也可以不做任何输入,从而使用默认的主色调进行自动上色。
考虑到实际应用场景,本文建立了3 个数据集,包括热贡藏式彩绘数据集、热贡唐卡(一种藏族地区传统绘画艺术)元素数据集和特定卡通数据集。这3 个数据集分别包含9 900 幅、4 478 幅和9 416 幅图像。前两个数据集是在青海的藏族寺庙及画院拍摄采集,然后使用梯形校正、直方图均衡化、去噪以及锐化等传统图像处理方法对原始照片进行处理后获得。第3 个卡通数据集中的图像是从名为《请吃红小豆吧》的特定动画中提取的图像帧。如图3 所示,每个数据集包含图像和其对应的线稿图像、主色彩向量。在训练阶段,线稿图像是使用SketchKeras(Zhang,2017)方法提取获得,该方法可以提取类似手绘效果的线稿图像。

图3 数据集示例Fig.3 Examples of three datasets((a)Regong Tibetan painting dataset;(b)Regong Thangka(Tibetan scroll painting)elements dataset;(c)specific cartoon dataset)
与传统的收集大量图像混合构成上色训练集不同,这3 个训练集即代表典型的有限色彩空间上色任务。以热贡藏式彩绘及唐卡为例,由于采用当地的矿、植物天然颜料并经历多代传承,对色彩的使用已形成鲜明的地方风格。在卡通动画制作中,同一部动画也须保持上色风格的一致性。如图3 所示,为了更符合此类上色任务的应用场景,这些数据集整体保持了较为一致的色调风格,而具体图像又包含多种多样的不同细节颜色。
2 实验
2.1 实验设置
3 个数据集中图像尺寸均为256×256 像素,训练和测试图像数量按照 9∶1随机划分。所提方法与基线方法Pix2Pix 以及一些线稿自动上色方法进行对比,包括AdvSegLoss(Hicsonmez 等,2021),PaintsChainer(Yonetsuji,2017)和 Style2Paints V4.5(Zhang 等,2022)。为公平比较,本文使用原作者提供的官方代码在本文建立的数据集上重新训练了Pix2Pix 及AdvSegLoss 模型。而PaintsChainer 和Style2Paints 是直接使用的上色工具,因此没有重新训练。在训练阶段,使用Adam 优化器,初始学习率为 2×10-4,使用等间隔调整方式衰减学习率。代码使用Tensorflow 框架,在一块NVIDIA RTX 3060Ti GPU上训练。
2.2 定量分析
在定量对比实验中,使用峰值信噪比(peak signal to noise ratio,PSNR)、结构相似性(structural similarity index measure,SSIM)和均方误差(mean squared error,MSE)指标来衡量输出的彩色图像的客观质量;使用色彩丰富度分数(colorfulness score,ColorS)(Hasler 和Suesstrunk,2003)来衡量输出图像的颜色生动性。
表1 列出了不同方法的PSNR、SSIM 和MSE 值,这里使用的是归一化后的MSE 值。可以看出,所提方法在3 个数据集基本都取得最高的PSNR 和SSIM值以及最低的MSE 值。在热贡藏式彩绘数据集,PSNR 值比Pix2Pix 和AdvSegLoss 分别高1.702 4 dB和0.187 7 dB,SSIM 值高0.108 7 和0.081 5。在热贡唐卡元素数据集,PSNR值比Pix2Pix和AdvSegLoss分别高1.574 3 dB 和2.573 9 dB,SSIM 值高0.049 0和0.132 8。在特定卡通数据集,本文方法的PSNR值略低于Pix2Pix,比AdvSegLoss高0.088 1 dB,SSIM值比Pix2Pix和AdvSegLoss分别高0.016 2和0.004 6。可以推测因为Pix2Pix 使用像素级约束,在数据量小的情况下,容易出现过拟合现象,从而PSNR 值接近真实图像。此外,PaintsChainer 和Style2Paints V4.5在3 个数据集上的失真度指标均不太理想,表明这两种方法的上色结果失真较大,难以获得与真实彩色图像一致的结果。

表1 不同上色方法在各数据集上的平均PSNR、SSIM值和MSE值Table 1 Average PSNR,SSIM and MSE values of different methods on different datasets
表2 列出了不同方法生成结果的色彩丰富度分数。可以看出,所提方法在3 个数据集上均取得了最高分数。在热贡藏式彩绘数据集上,比Pix2Pix和AdvSegLoss 分别高19.462 0 和23.000 3。在热贡唐卡元素数据集上,比Pix2Pix 和AdvSegLoss 分别高7.973 8 和19.203 8。在特定卡通数据集上,分别高5.302 0 和3.552 1。而PaintsChainer 和Style2Paints V4.5 取得了较低的分数,表明这两种方法难以自动选择合适、丰富的颜色为线稿上色。这些定量实验结果表明,本文方法可以获得与真实图像接近、失真程度低的结果,可以为线稿绘制更丰富的颜色。

表2 不同方法的色彩丰富度指标ColorS值Table 2 Colorfulness score of different methods
2.3 定性分析及用户调查
尽管定量分析已经表明本文方法的有效性,但对于线稿上色任务而言,人的主观感受评价更为重要。因此,本文进行了主观实验对比以及用户调查。
图4 展示了一些不同方法的上色结果,每个数据集展示了两个示例。可以明显地看出,PaintsChainer 和 Style2Paints(S2PV4.5)在全自动的情况下无法给这些线稿合理着色。相比之下,Pix2Pix和AdvSegLoss 可以获得相对较好的结果,然而也存在一些不和谐的颜色,如线稿不闭合导致的色彩泄露及色彩不均等其他不自然效应。图4 中红色框标出了部分不合理细节,如花朵颜色的混合、卡通角色舌头的颜色等。总体来看,本文方法可以绘制出色彩和谐、视觉质量更好的结果。

图4 不同上色方法的结果对比Fig.4 Qualitative comparison of different methods((a)input sketchs;(b)Pix2Pix;(c)AdvSegLoss;(d)PaintsChainer;(e)Style2Paints V4.5;(f)ours;(g)ground truths)
如前文所述,训练阶段的颜色先验是通过K-means 算法获得的,这只是为了方便训练。在实际推理阶段,颜色先验可以通过多种方式给出,如预先聚类的主色调或用户指定的颜色。图5 展示了一些使用不同颜色先验的着色结果。“输出”列表示输出图像是用其对应的真值彩色图像聚类获得的颜色作为颜色先验着色的。“主色调”列表示输出图像是用根据其图像类型聚类获得的颜色先验着色的。由于在实际应用中,根据每一幅图像给定颜色先验仍是非常烦琐的,因此,本文提供了“主色调”上色方式,即对整个绘画类型或整部动画赋以相同的色彩空间先验,从而在推理阶段不用给每幅图像单独提供色彩向量。同时,由于本文模型中采用了解耦的颜色推理和融合模块,输出图像的颜色可以随输入颜色先验的不同而灵活调整,如“不同颜色先验”列所示。

图5 所提方法使用不同颜色先验的结果示例Fig.5 Examples of our method using different color priors as input
此外,本文进行了用户调查的感知实验。具体来说,从每个数据集中随机选择8 幅图像,并向15个不同的用户展示输入草图及Pix2Pix、AdvSegLoss、PaintsChainer、Style2Paints V4.5 和本文方法的相应上色结果。这些结果图像均打乱顺序并且不包含算法名称。每个用户都可以凭借自身主观感受从5 幅结果中选择1 幅上色结果最好的图像,其统计结果如图6 所示,横坐标表示选择某种方法的人数所占百分比。需要注意的是,评价时让用户从两个方面衡量,一种是关注颜色的选取及其对于该线稿的合理性,另一种是关注上色后图像的整体质量。从图6 中可以看出,没有用户选择PaintsChainer 和Style2Paints V4.5 的上色结果,这与图4中展示的情况吻合,表明这些为特定类型(如动漫人物)设计的上色工具无法对其他类型差异较大的线稿完成上色。大多数用户无论在颜色选择和整体质量上都更加偏爱本文所提方法的结果,表明本文方法可以获得与人的主观审美感受较一致的结果。
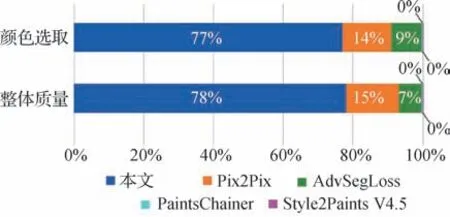
图6 用户调查结果Fig.6 User survey results
2.4 消融实验
为了进一步验证所提各模块的有效性,进行了消融实验,包括训练单阶段模型、单尺度模型以及无色彩空间限制模型。单阶段模型即不使用先生成灰度图像再生成彩色图像的两阶段方法,而是直接从线稿生成彩色图像。单尺度是指在第2 阶段仅使用单一尺度,即直接生成最终分辨率的彩色图像。无色彩空间限制模型表示仅输入线稿,而没有颜色向量信息。图7展示了一些定性结果,表3中列出了定量结果。可以看出无论是客观指标还是主观感受上,单阶段模型的性能最差,上色结果有很多不自然效应,这也证实了分阶段上色可以有效降低自动上色难度。此外,单尺度的模型性能低于多尺度模型,这表明了使用多尺度策略的有效性,可以逐步生成高质量图像。而无色彩空间限制时,本文方法即一般意义上的全自动上色,其难度较大。如图7 所示,通过分阶段多尺度策略也可以改善全自动上色结果,但其色彩预测仍存在不可控性,且易受训练集中色彩分布影响。例如第3 行白色角色会被误上色,虽然上色结果已较一些对比算法更优,但仍不符合创作预期。通过引入色彩子空间,可以有效降低合理色彩选取的难度,且色彩可控性增强。
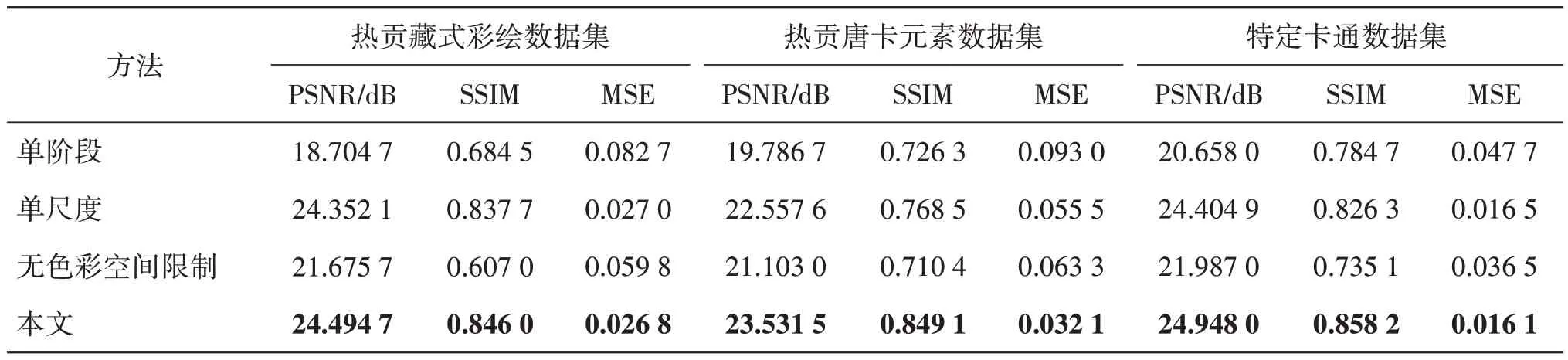
表3 消融实验结果Table 3 Results of ablation experiment

图7 消融实验结果的主观对比Fig.7 Subjective results of ablation experiment
3 结论
线稿自动上色是一项非常困难的任务,因为线稿草图只包含稀疏的线条,其能提供的语义信息较少。现有的线稿自动上色方法大多需要额外的用户指导如参考图像、文字提示等,或聚焦于特定类型的线稿上色。观察到在许多实际情景下,对线稿上色所使用的颜色通常是固定且有限的,因此,本文使用特定的颜色集作为色彩先验,以降低线稿全自动上色的难度。具体地,本文提出了一种两阶段多尺度的上色网络,首先根据输入线稿生成中间灰度图像,然后根据输入的颜色先验推理得到适用于该线稿的颜色子空间,再利用多尺度生成对抗网络逐步融合灰度图像内容信息和颜色信息以完成线稿的着色。在热贡藏式彩绘数据集、热贡唐卡元素数据集和特定卡通数据集3 个数据集上的定量和定性评价结果表明,本文方法能够有效地为线稿自动上色,且上色后图像的视觉质量优于其他对比方法。此外,所提方法实现了颜色推理和着色过程的解耦。因此,用户可以简单地通过修改颜色先验来获得多样的绘制风格。
然而本文方法也存在一定的不足,对于包含复杂、凌乱的线条的线稿,本文方法会出现上色不佳的情况。因此,未来的研究需要进一步设计网络结构以理解卡通线稿中的细微结构,并在语义理解的前提下进行合理着色。此外,自动上色难以保证完全符合创作者的设计预期,因此上色后修色的用户交互方案也是未来的研究内容之一。
